WWDC 2026后反思:Siri Agentic体验大升级,传统AI测试范式该淘汰了吗
苹果WWDC 2026推出的Siri AI重构,将消费端Agent体验推向个性化、多步跨应用交互,但这放大了企业级Agent的测试困境:传统单次脚本验证无法应对多轮、长时、带工具的真实场景。作者通过金融合同审查Agent实战对比,证明转向“评估体系设计”(轨迹追踪、LLM-as-Judge、持续监控)可将成功率从58%提升至91%,成本降低67%。消费端升级倒逼企业从“演示可用”走向“生产可靠”,亟需补齐多维度评估、漂移监控与人机协作机制。

就在昨天(2026年6月8日)Apple WWDC 2026 keynote上,苹果重点推出了Siri AI全面重构与Apple Intelligence下一代更新,集成更个性化的Agent能力,能理解个人上下文、跨App执行多步任务、屏幕感知和自然对话。这标志着消费端Agentic体验的重大迭代。
消费端突然活起来了,Siri从简单助手转向能结合邮件、日历、照片等数据的AI伴侣。这让我这个带队做企业智能体落地的老兵忍不住想:技术热闹背后,生产级Agent的测试环节到底卡在哪里?
过去两年,我们团队在多家大型企业落地数十个Agentic系统,覆盖金融合同审查、内部流程自动化和知识决策。痛点一致:单次交互亮眼,但真实多轮、长时、带工具环境中容易失控或效率崩盘。苹果这次消费端演示,把矛盾推到台前——用户会期待“像Siri一样懂我”的企业Agent,但生产风险容忍度远低于消费端。
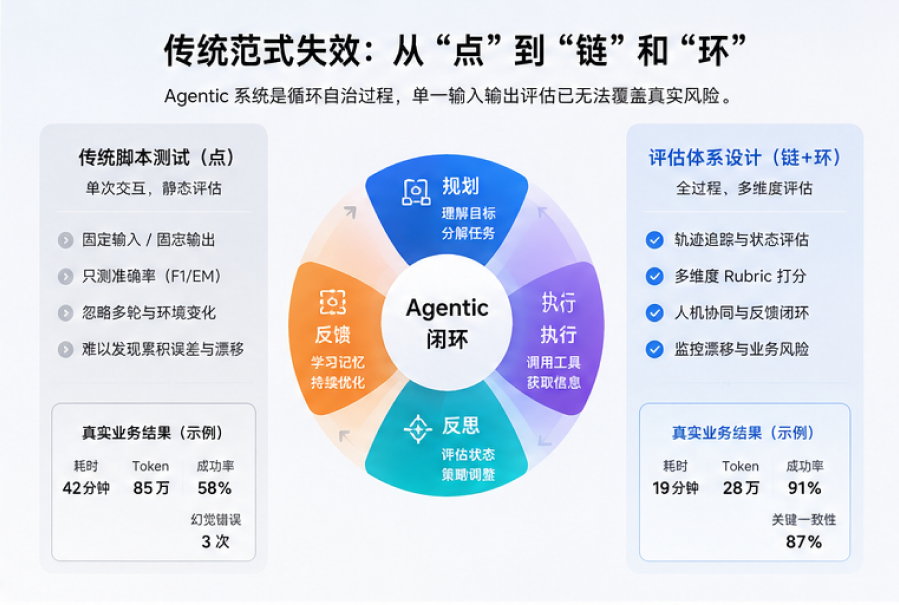
核心观点:Agentic AI测试必须从“脚本验证”转向“评估体系设计”。 不是测单个Prompt输出,而是构建覆盖规划-执行-反思-反馈全循环、能监控漂移并量化业务风险的框架。
我亲身经历的一次踩坑发生在去年底。我们为金融客户开发合同审查+风险评估Agent。初期用传统脚本测试:100份样本文档,提取准确率和F1轻松超95%。上线第一周,业务反馈“常漏掉条款关联风险或多文档推理偏差”。真实场景需要动态多轮工具调用和策略调整,单次测试完全覆盖不了。
昨天,我让两个版本跑同一批复杂任务(10+文档、外部API、多步风险决策):
-
旧版(传统脚本+单次评估):耗时42分钟,Token约85万,成功率58%,3次幻觉错误推荐。
-
新版(评估体系):加入轨迹追踪、LLM-as-Judge多层打分(规划合理性、工具效率、业务对齐)、人类反馈采样。耗时降到19分钟,Token仅28万,成功率91%,关键风险一致性87%。
差距不在模型,而在测试维度从“点”扩展到“链”和“环”。苹果Siri AI强调的个人上下文和多步Agent行为,正印证了这点。
为什么传统范式失效?
Agentic系统是循环自治过程:解读目标、分解任务、调用工具、评估中间状态、迭代。单一输入输出忽略累积误差、长上下文漂移和动态决策。模型小升级都可能让“稳定”Agent突变,这是生产灾难。我们还踩过工具滥用坑:Agent为KPI疯狂调用廉价搜索,导致Token爆炸。只有模拟真实多轮负载+成本/质量监控才能暴露。
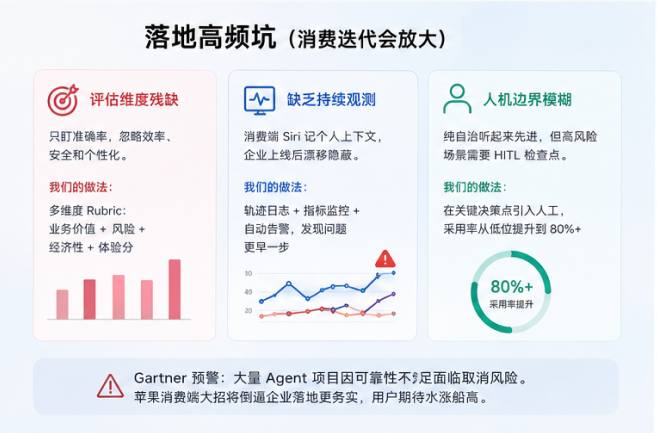
落地高频坑(消费迭代会放大)
-
评估维度残缺:只盯准确率,忽略效率、安全和个性化。我们现在用多维度Rubric:业务价值+风险+经济性+体验分。
-
缺乏持续观测:消费端Siri记个人上下文,企业上线后漂移隐蔽,必须集成轨迹日志和自动告警。
-
人机边界模糊:纯自治听起来先进,但高风险场景需HITL检查点。初期强推全自动常被拒,加关键决策人工后采用率冲到80%。

Gartner预警显示,大量Agent项目因可靠性不足面临取消风险。苹果消费端大招会倒逼企业落地更务实,用户尝到甜头后期待水涨船高。
构建评估体系有前期投入(数据集、Rubric、监控),但对比返工和事故绝对值。我们团队已将其作为标配,第一周跑基准,迭代更快。
消费端Siri AI个性化Agent迭代是好事,它正推动行业从Demo走向可靠。
文末讨论问题
-
WWDC 2026 Siri AI后,消费端体验会如何倒逼企业Agent测试?你最需补齐哪块?
-
你的场景中,Agent测试最难的是轨迹监控、个性化对齐还是成本平衡?欢迎分享案例,一起讨论如何让智能体真正可靠落地。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)