向量引擎不是“接个库”就结束:RAG 从零搭建、Milvus/FAISS 部署和向量 API 中转实测对比
先说结论:如果你做的是 RAG、知识库问答、文档检索、代码检索这类应用,最先稳住的不是模型,而是向量引擎、切分策略和接入层。模型负责生成,向量引擎负责召回,接入层负责稳定调用。三者各管一段,谁都替代不了谁。
我这几年做 AI 应用开发,有一个感受一直没变:很多项目一开始看上去都很顺,真正上线以后才开始暴露问题。不是回答不够“聪明”,而是文档切得不对、索引建得不稳、请求链路太散、日志太少、更新机制不清楚。换句话说,RAG 的难点从来不只是“把文档扔进去”,而是“让系统长期能找回正确内容,并且在普通机器上也能持续跑”。
这篇文章我尽量按中小团队和独立开发者的现实来写,不讲太虚的架构图,也不把问题说成“只要上某个大模型就能解决”。预算有限、机器一般、运维人手少,这才是大多数项目的真实起点。下面我会把向量引擎、RAG、Milvus、FAISS、向量 API 中转这几件事拆开讲,重点放在实操和判断标准上。
如果你只想先抓一个核心结论,那就是:
- 本地验证和单机知识库,先 FAISS。
- 服务化、多用户、后面要扩展,再 Milvus。
- 接入层要不要上向量 API 中转,看你的调用复杂度,不看宣传话术。
- 真正决定 RAG 结果的,往往是 chunk、metadata、rerank、日志和更新机制。
一、向量引擎、RAG、接入层,先分清楚职责
很多文章会把这几个词混着讲,我觉得容易把人带偏,所以先拆开。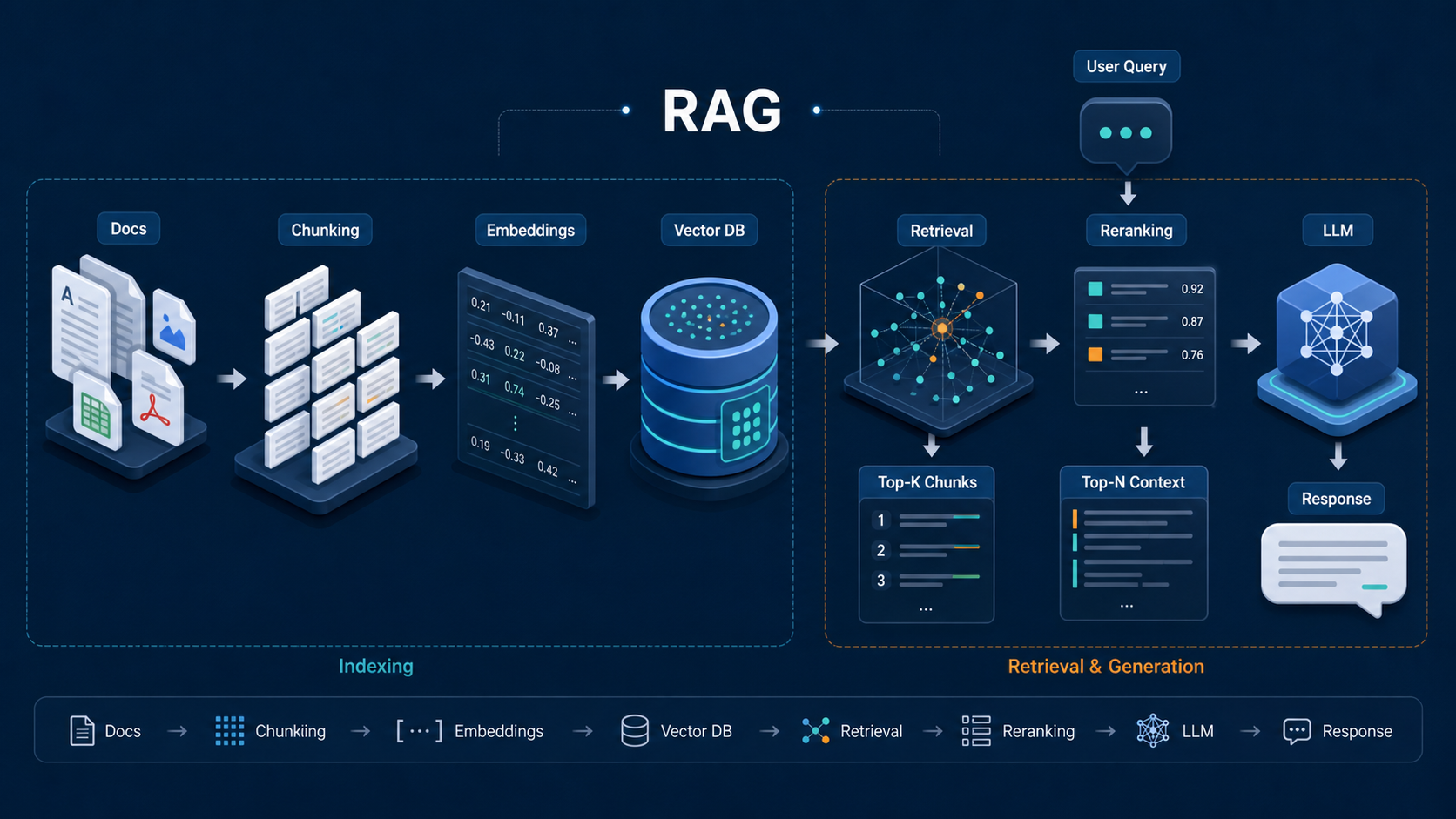
1. 向量引擎解决什么
向量引擎解决的是“相似内容怎么找”。你把文本、代码、知识片段转成 embedding,再存进向量索引,查询时把用户问题也转成向量,找语义上最接近的内容。它负责的是召回,不负责最终答案。
2. RAG 解决什么
RAG 是检索增强生成。它不只是检索,还要把检索结果组织成上下文,再交给大模型生成答案。它解决的是“找到内容以后,怎么回答得更像事实”。
3. 接入层解决什么
接入层负责把上游接口统一起来,减少 key 管理、日志散落、切换成本和波动风险。它解决的是“怎么接、怎么切、怎么管”,不是“答案对不对”。
这三层如果混在一起,最容易出现一种误判:把答案不稳、响应慢、检索不准都归到同一个地方。实际上,很多时候根本不是同一个问题。
二、我为什么先看检索链路,而不是先看模型
很多人做 RAG 的第一句话是“你用的什么模型”,但我在真实项目里,第一眼看的是检索链路。
原因很简单:模型再强,如果取回来的上下文不对,回答照样会偏;反过来,只要检索链路足够稳,哪怕模型不是最新的,整体效果也能先达到“能用”的水平。
我遇到过最常见的几类问题:
- 文档切得太碎,语义断裂,模型拿到的是半句话。
- 文档切得太大,召回到了,但上下文塞不进。
- 文档有内容,但没有 metadata,查到了也不知道出处。
- 向量检索看起来命中了,实际上只是语义接近,不是问题对口。
- 没有 rerank,前几条噪声太多,模型会被带偏。
- 更新以后旧 chunk 没删干净,结果新旧内容混在一起。
- 中文 PDF 没处理好,抽出来的文本顺序乱了。
这些问题看上去像“模型发挥不稳定”,其实很多都出在检索和索引设计上。
所以我现在看一个 RAG 方案,不会先看它用了哪个大模型,而是先看下面这些东西:
- 文档怎么清洗。
- chunk 怎么切。
- embedding 是否统一。
- 检索是否带 metadata 过滤。
- 是否有 rerank。
- 是否保留来源和版本。
- 出错时怎么降级。
- 更新时怎么删除旧数据。
- 日志里能不能回溯到具体 chunk。
这些东西看起来没那么“炫”,但决定了系统能不能持续工作。
三、RAG 真正难的,不是“做向量”,而是“做流程”
如果只做一个 demo,RAG 很简单。真正麻烦的是把它变成一个能稳定维护的流程。
我自己通常把 RAG 看成一条链:
- 数据收集。
- 文本清洗。
- 结构化切分。
- embedding 生成。
- 索引构建。
- 检索召回。
- rerank 重排。
- 上下文组装。
- 生成答案。
- 日志记录和评估。
- 增量更新和删除旧数据。
只要其中任何一环有问题,最后的答案都会受到影响。
1. 数据收集不是越多越好
很多人第一步就想“把所有资料都倒进去”,但我更倾向先从高频问答和高价值文档开始。
比如:
- 产品文档。
- FAQ。
- 接口说明。
- 规章制度。
- 历史工单。
- 代码 README。
- 技术手册。
先拿最容易被问到的内容做样本,效果通常更快看得出来。
2. 清洗不是删得越狠越好
清洗的目标是去噪,不是去内容。
常见要清的东西有:
- 页眉页脚。
- 重复目录。
- 导航菜单。
- 模板残留。
- 无意义版本号。
- 页面底部的版权和广告残留。
但标题层级、列表编号、表格结构、术语定义这些信息,最好保留。很多时候它们比正文还重要。
3. 切分 chunk,别只看字数
这是我踩过最多坑的地方。只按固定字数切,看上去简单,实际经常翻车。
更实用的切分方式是按语义边界切:
- FAQ 一问一答尽量放在一起。
- 技术文档按标题层级切。
- 长段落按语义断点切。
- 代码说明按函数、类、模块切。
- 表格尽量保留为结构化文本,不要硬拆成碎片。
- OCR 识别出来的扫描文档,要先做顺序修正,再切分。
如果切得太碎,语义断裂;切得太大,召回到了但上下文塞不进。实际项目里,最好的 chunk 往往不是“字数刚刚好”,而是“问题边界刚刚好”。
4. metadata 比很多人想得更重要
我现在做 RAG 时,几乎都会给每个 chunk 配 metadata。常见字段包括:
- source_id
- title
- section
- version
- created_at
- updated_at
- product_line
- language
- security_level
- hash
这些字段不是摆设。后面你要做过滤、回溯、版本更新、删除旧数据、定位问题,全靠它们。
5. 不是所有检索都适合纯向量
实际项目里,我很少只靠纯向量。很多时候会加关键词检索、metadata filter,或者做混合检索。
原因很现实:
- 纯向量擅长语义接近。
- 关键词擅长精确命中。
- metadata 适合缩小范围。
- rerank 负责把结果再排一遍。
纯向量不是不行,而是它通常不够完整。尤其是中文技术文档、接口文档、规则文档,混合检索往往更稳。
四、FAISS 和 Milvus 怎么选,我的顺序一直比较保守
先说我的判断:如果你是本地验证、单机知识库、个人项目、PoC,我通常先 FAISS;如果是服务化、多用户、长期维护、后面要扩展,再考虑 Milvus。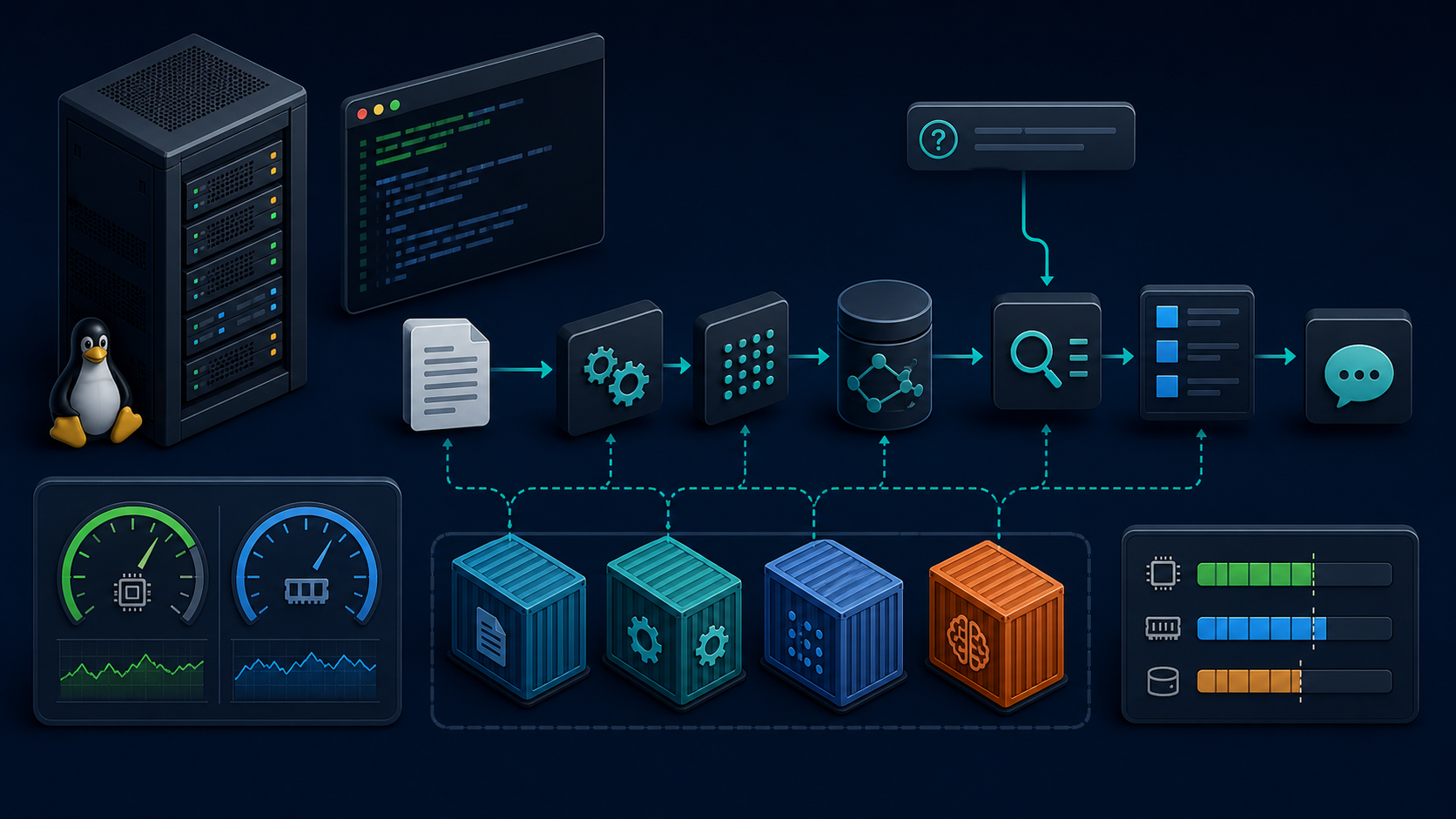
1. FAISS 更像本地检索工具
FAISS 的特点是轻、快、直接。它更像一个可以嵌入到应用里的向量检索库,适合先把流程跑通。
它适合这些场景:
- 单机本地测试。
- 中小规模知识库。
- 需要快速验证切分和召回效果。
- 不想先引入额外服务。
- 想先把工程骨架搭起来,再决定要不要上服务化。
2. Milvus 更像服务型向量数据库
Milvus 更适合服务化场景。它的价值不只是“能存向量”,而是后续扩展、管理、过滤、并发、服务边界都更清晰。
它适合这些场景:
- 多人共用知识库。
- 需要统一访问入口。
- 数据规模会持续增长。
- 后面可能接更多业务系统。
- 要做更完整的生命周期管理。
3. 我为什么不一上来就上 Milvus
原因不是 Milvus 不好,而是很多项目根本还没到需要它的阶段。
如果你还在验证期,最重要的是把 RAG 闭环跑通。先能稳定回答,再谈扩展。很多人反过来,一开始就把架构做重,结果最先卡住的是部署和资源,而不是检索本身。
4. 迁移路径比“直接选对”更重要
我现在更看重迁移路径,而不是一次性选型。因为真实项目经常会变:
- 早期先 FAISS。
- 数据和用户量上来后,再切 Milvus。
- 中间还可能加 rerank、加缓存、加过滤。
- 甚至会从单机变成分层服务。
所以我通常会先把检索逻辑抽象成接口,不把业务代码和底层向量库绑死。这样以后从 FAISS 迁移到 Milvus,不需要重写整条链路。
一个比较常见的抽象方式是:
class VectorStore:
def upsert(self, ids, vectors, metadatas):
raise NotImplementedError
def query(self, vector, top_k, filter=None):
raise NotImplementedError
def delete(self, ids):
raise NotImplementedError
真正迁移时,通常只换实现,不换业务逻辑。
5. Windows 和低配 Linux 的现实情况
Windows 上跑 Milvus,通常要走 Docker Desktop + WSL2。官方安装说明可以看 Milvus 官方安装说明。
FAISS 的安装相对轻一些,官方文档里也有比较明确的安装路径,可以看 Faiss 官方安装文档。
如果机器条件一般,我的优先级通常是:
- 先 FAISS 跑通。
- 再看是否需要 Milvus。
- 最后再考虑多机、权限、分片、备份这些扩展问题。
这个顺序看起来慢一点,但通常更稳。
五、我怎么测向量 API 中转,为什么把它放在工程中间看
我自己做接入层测试时,会把一个中转入口单独拉出来观察,比如 https://178.nz/dn。我对这类入口的态度一直很简单:它是接入层,不是答案层,也不是知识层。它的意义在于把上游接口、日志、错误、切换和调用收口,不是替代 RAG 本身。
我测试这类中转层时,通常看四件事:
- 响应是否稳定。
- 错误是否透明。
- 切换是否方便。
- 日志是否能排障。
1. 什么时候值得用
如果你遇到这些情况,中转层通常是有价值的:
- 多个项目共用一套上游。
- 你经常切换不同服务。
- key 管理比较散。
- 你需要统一日志和统计。
- 你需要在波动时做切换或 fallback。
2. 什么时候不值得用
如果你的项目很简单,或者只是单点调试,中转层未必值得加一层。
- 单项目,调用路径短。
- 接口调用量不高。
- key 数量少。
- 没有统一日志要求。
- 不需要复杂的切换策略。
这种情况下,直连上游更省事。
3. 我更关心的不是“有没有中转”,而是“中转之后可不可以排障”
一个中转层如果只负责转发,但看不到:
- 请求耗时
- 错误类型
- 超时来源
- 上游波动
- key 使用情况
- 切换记录
那它就只是在增加一个黑盒。
如果它把这些信息都收得很清楚,那它就是一个比较实用的工程工具。
六、Windows 上怎么落地,我一般先从最小环境开始
1. FAISS 的 Windows 最小环境
我一般会先把环境搭到能跑一个最小 demo。对本地验证来说,这一步比“上来就做完整系统”更重要。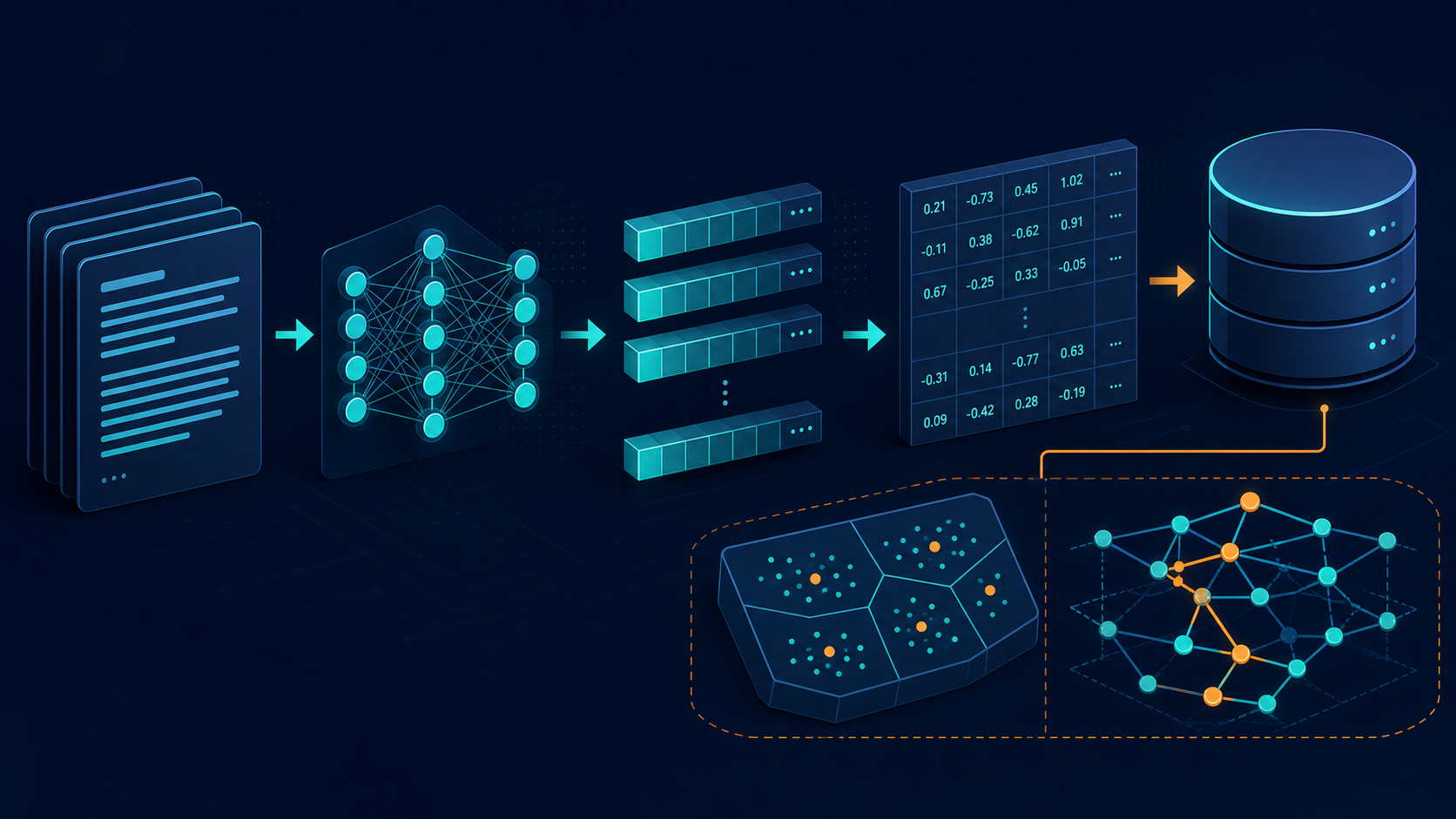
一个比较常见的最小环境可以这样组织:
conda create -n rag python=3.10 -y
conda activate rag
conda install -c pytorch faiss-cpu -y
pip install numpy
然后用一个最小脚本验证索引是否可用:
import faiss
import numpy as np
dim = 768
index = faiss.IndexFlatIP(dim)
vectors = np.random.randn(1000, dim).astype("float32")
faiss.normalize_L2(vectors)
index.add(vectors)
query = np.random.randn(1, dim).astype("float32")
faiss.normalize_L2(query)
scores, ids = index.search(query, 5)
print("Top-5 ids:", ids[0])
print("Top-5 scores:", scores[0])
这段代码的价值不在于“随机向量会搜出什么”,而在于确认三件事:
- 环境能否正常跑通。
- 索引是否能写入和查询。
- 后续 embedding 接上以后,链路会不会出明显问题。
2. Milvus 的 Windows 路线
如果在 Windows 上跑 Milvus,我通常不会上来就改配置,而是先按官方 Docker Compose 的方式把服务拉起来。因为大多数问题不是 Milvus 本身,而是环境前置条件没满足。
通常的思路是:
- 安装 Docker Desktop。
- 确认 WSL2 可用。
- 使用官方 compose 文件。
- 启动服务后查看容器状态和日志。
- 确认应用端能连上。
这里最重要的不是“看起来启动了”,而是容器状态、日志和连通性都要能解释清楚。
3. 一个适合本地验证的一键启动脚本
下面这个 PowerShell 脚本不追求生产级,只是为了省掉重复操作:
param(
[ValidateSet("faiss", "milvus")]
[string]$Mode = "faiss"
)
$ErrorActionPreference = "Stop"
if ($Mode -eq "milvus") {
if (-not (Get-Command docker -ErrorAction SilentlyContinue)) {
throw "未检测到 Docker,请先确认 Docker Desktop 和 WSL2。"
}
if (-not (Test-Path ".\docker-compose.yml")) {
throw "当前目录缺少 docker-compose.yml,请放入官方 compose 文件后再试。"
}
docker compose up -d
docker ps
Write-Host "Milvus 启动完成。"
}
else {
if (-not (Get-Command conda -ErrorAction SilentlyContinue)) {
throw "未检测到 conda,请先安装 Anaconda 或 Miniconda。"
}
conda run -n rag python .\faiss_demo.py
}
如果你更习惯 Linux,下面这个 bash 版本也可以直接拿去改:
#!/usr/bin/env bash
set -euo pipefail
MODE="${1:-faiss}"
if [ "$MODE" = "milvus" ]; then
if ! command -v docker >/dev/null 2>&1; then
echo "未检测到 Docker,请先确认 Docker 和 Docker Compose 可用"
exit 1
fi
[ -f "./docker-compose.yml" ] || { echo "缺少 docker-compose.yml"; exit 1; }
docker compose up -d
docker ps
echo "Milvus 启动完成"
else
python3 ./faiss_demo.py
fi
七、低配 Linux 服务器上怎么落地,重点不是“能不能跑”,而是“能不能稳”
低配 Linux 是很多中小项目最真实的环境。机器不大,任务不少,预算有限,谁都想一次上线,但最后往往只能靠一点点加法去堆出稳定性。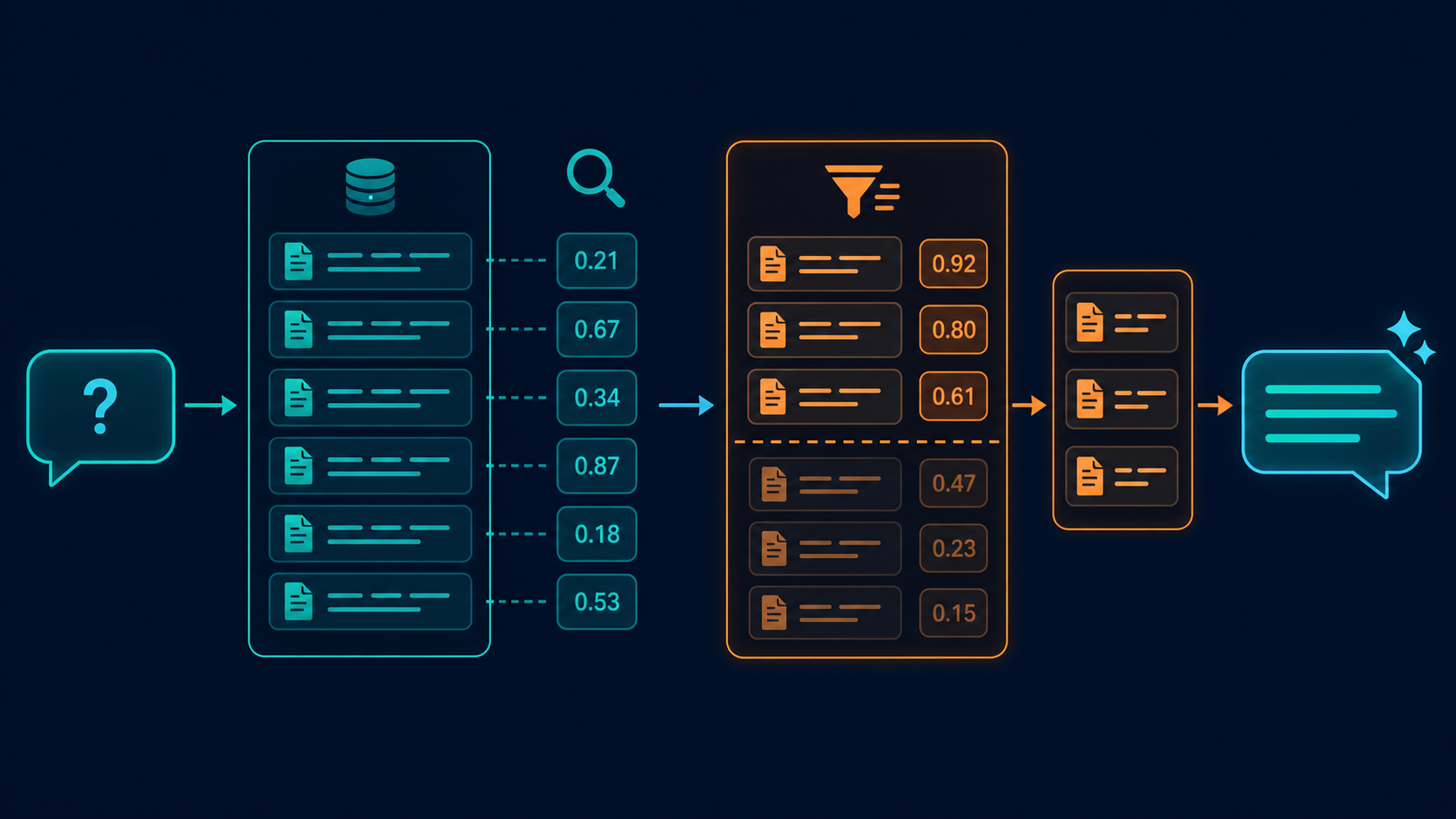
1. 先判断机器是不是适合直接上 Milvus
如果你只有 2 核 4G、4 核 8G 这类常见配置,我一般会先问自己一个问题:这台机器上还要不要同时跑数据库、应用服务和推理服务?
如果答案是“要”,那我更倾向先 FAISS 或者更轻量的方案。
2. 低配机器最怕什么
低配机器最怕的不是“功能少”,而是“服务太满”。
典型问题包括:
- 内存被挤爆。
- 容器频繁重启。
- 响应延迟忽高忽低。
- 日志太多,排障困难。
- 某个组件挂了,整条链路都跟着不稳。
3. 我常用的折中方式
我的折中方式一般是:
- 先让本地索引跑起来。
- 先验证向量召回和生成闭环。
- 先保留最少的服务依赖。
- 再决定要不要引入独立向量数据库。
- 再决定要不要拆成多服务。
这不是保守,而是现实。很多项目真正浪费时间的地方,不是写代码,而是写了太多暂时还用不上的基础设施。
4. Linux 上我会看哪些基础指标
我上线前通常会先看这些:
free -h,确认内存是不是够。df -h,确认磁盘是不是够。docker stats,看容器是不是吃太多资源。top或htop,看 CPU 是否持续打满。docker logs,看是否有重复报错。
如果机器本身就很紧,先让 FAISS 跑起来通常会更实际。等数据量、并发量和维护需求都上来以后,再考虑 Milvus。
八、RAG 从零搭建,我更倾向按这条链走
我做 RAG 不喜欢先谈概念,通常直接拆流程。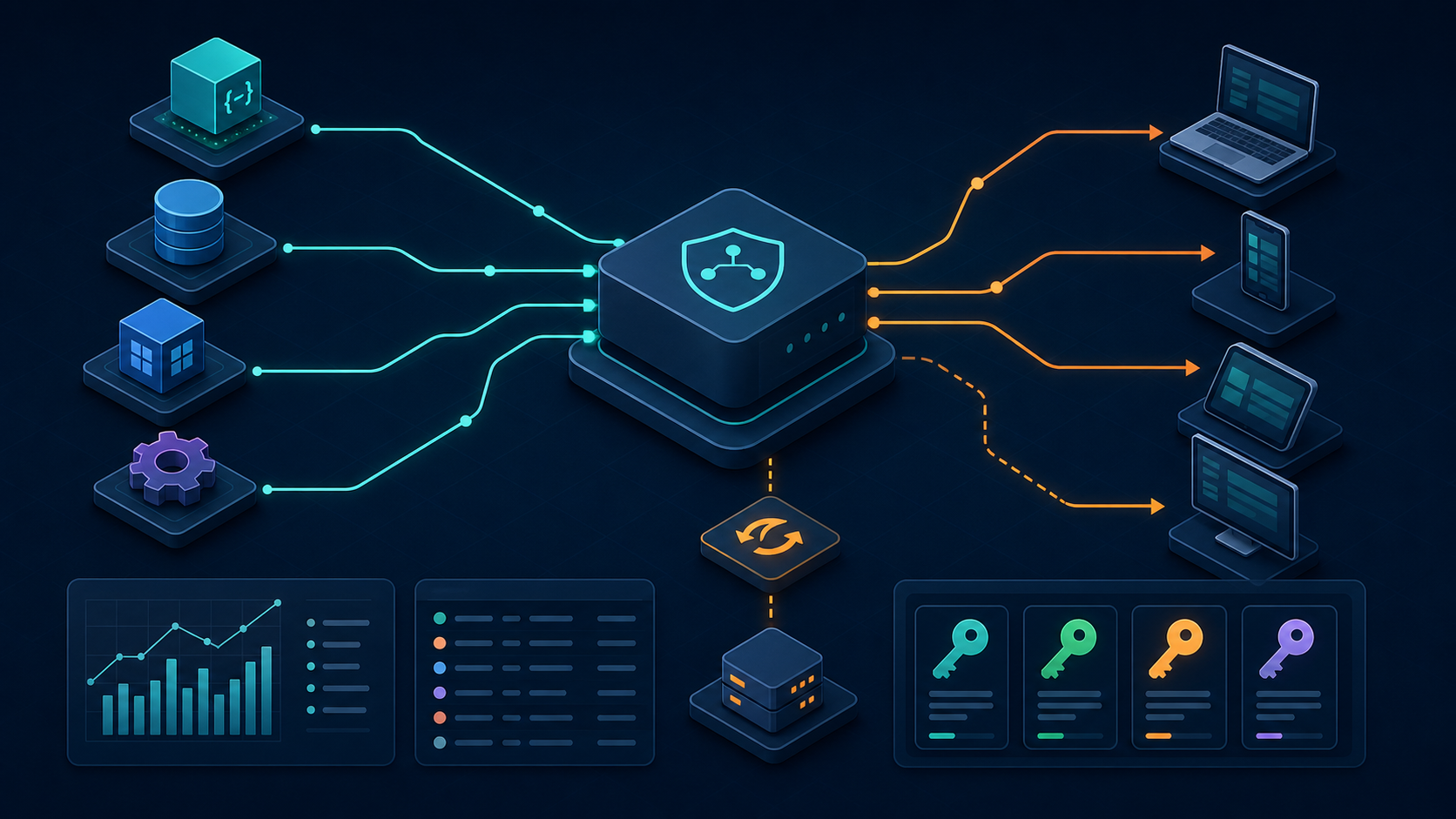
1. 数据收集
先收集真实会被问到的内容,而不是只挑看起来“漂亮”的材料。
可用的数据包括:
- 产品文档。
- FAQ。
- 接口说明。
- 技术手册。
- 历史工单。
- 代码注释和 README。
2. 清洗文本
清洗的目标不是删得越多越好,而是把无意义噪声去掉。
常见要清的东西有:
- 页眉页脚。
- 重复目录。
- 导航菜单。
- 无意义版本信息。
- 模板残留。
- 扫描 PDF 里的重复页码和页眉。
3. 切分 chunk
这一步很关键。切分不是按照固定字数机械截断,而是按语义边界来。
我更常见的做法是:
- FAQ 一问一答尽量放在一起。
- 技术文档按标题层级切。
- 长段落按语义断点切。
- 代码说明按函数或模块切。
- 表格尽量保留结构,不要硬拆。
- OCR 文档先纠顺序,再切分。
4. 生成 embedding
embedding 最怕不统一。索引和查询尽量保持同一模型、同一维度、同一归一化方式。否则你会遇到“能搜,但不准”的问题。
5. 建索引
索引类型先不要追最复杂的,先让结果稳定。
6. 查询和召回
先把 top_k 控制在一个保守范围,再根据业务决定是否加过滤条件。
7. rerank
如果你的文档相似度高,或者问题很模糊,rerank 的作用通常比大家想象的大。
8. 生成答案
生成阶段要尽量让模型基于检索结果回答,而不是自由发挥。
9. 记录与评估
没有评估集,RAG 很容易做成“感觉能用”。
至少要记录这些信息:
- 用户原始问题。
- 命中的 chunk。
- chunk 来源。
- 最终答案。
- 响应时间。
- 失败原因。
- 使用了哪个上游接口。
- 命中的是哪个版本文档。
10. 增量更新和删除旧数据
这一点很多人会忽略,但线上很重要。
当文档更新时,不能只“追加新内容”,还要处理旧 chunk:
- 通过 source_id 定位旧数据。
- 通过 version 或 hash 判断是否变化。
- 只重建变更的部分。
- 删除过期 chunk。
- 保留必要的历史版本以便回滚。
如果没有这一层,RAG 很容易变成“越跑越乱”。
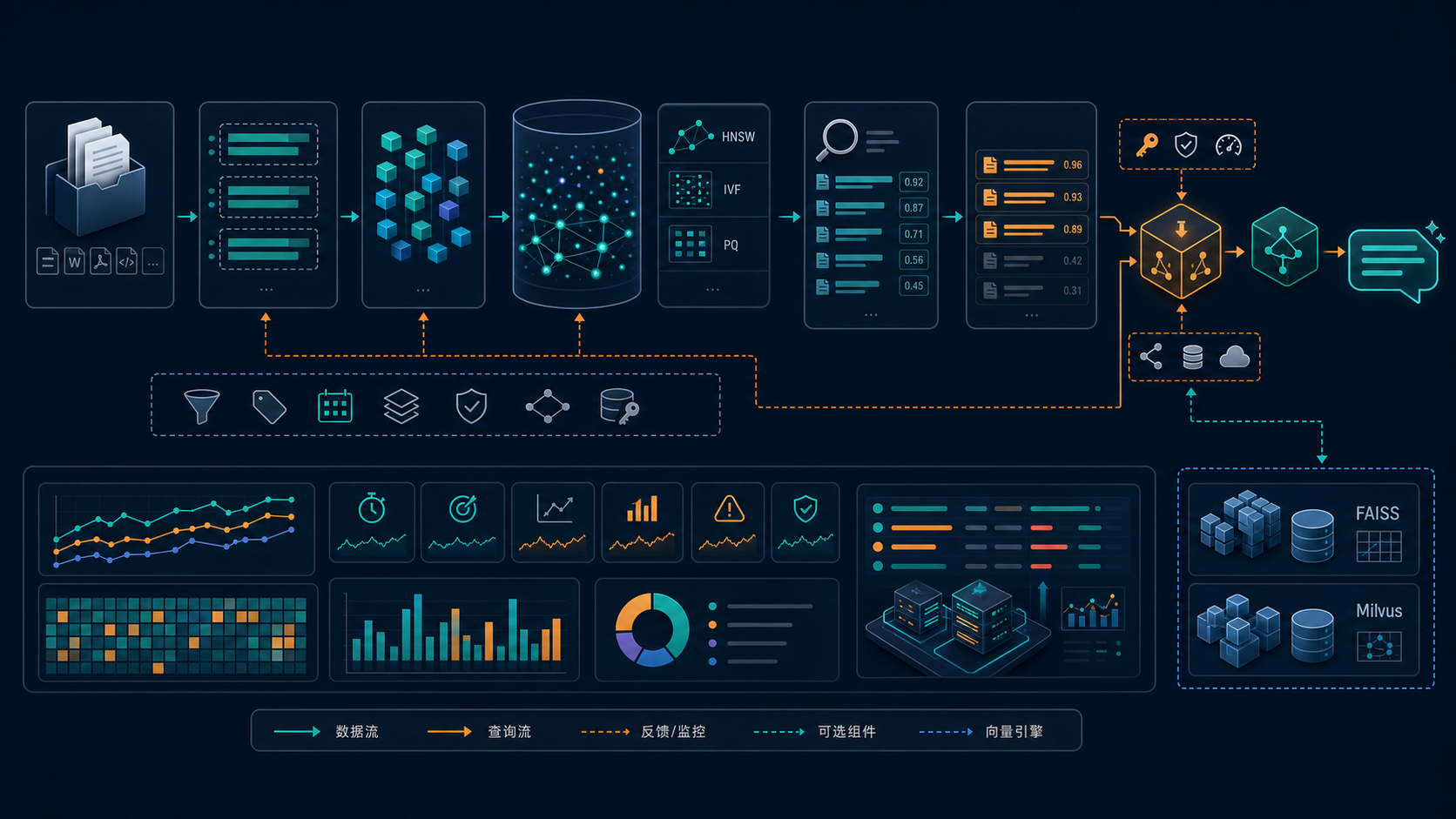
九、我怎么看这条链路里的“中转层”和“检索层”
如果把整个系统拆开,我通常会把它分成三层: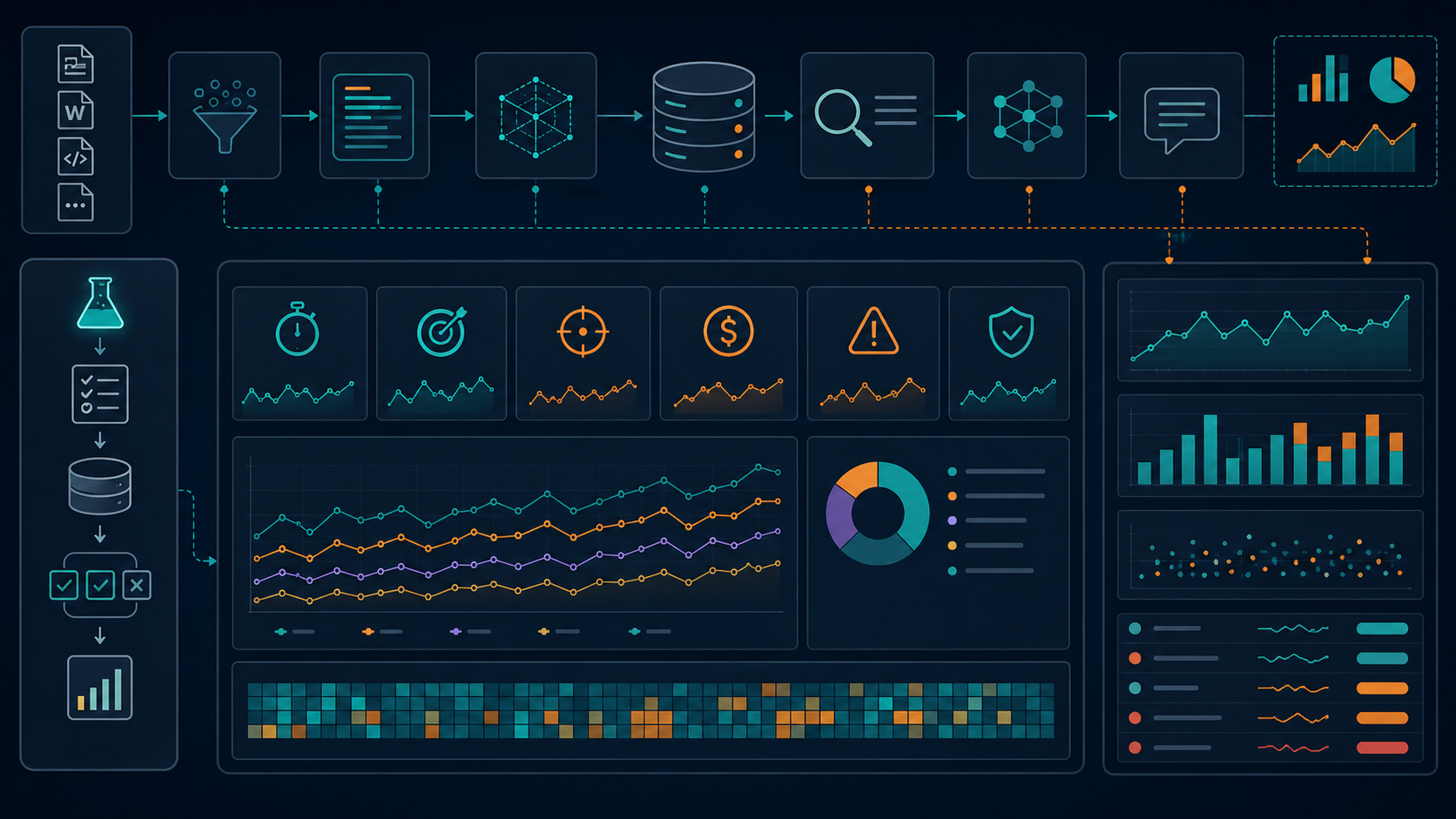
1. 上游接口层
它负责提供 embedding、生成、rerank 或其它能力。
2. 中转接入层
它负责把上游接口统一起来,减少 key 管理、日志散落和切换成本。
3. 检索与应用层
它负责 chunk、索引、召回、重排、生成和输出。
这三层里,中转层常常是最容易被误解的一层。它不是知识库,也不是答案引擎。它最大的作用,是让你不用为了换一个上游接口就改一堆代码。
如果你要把它放进工程里,我一般会先看这些点:
- 是否支持统一日志。
- 是否能快速切换上游。
- 错误是否能原样返回。
- 超时和重试逻辑是否可控。
- 接口返回是否足够干净。
- 失败时有没有明确的 fallback。
如果这些做得清楚,它就能帮你节省很多接入成本;如果这些做得很模糊,它就会变成一个额外的不确定因素。
十、怎么做实测对比,我更看重哪些指标
很多人评测向量引擎,第一眼就看速度。我不反对看速度,但我更看重稳定性。
1. 我会怎么测
我通常会拿几类问题来测:
- 定义类问题。
- 追问类问题。
- 对比类问题。
- 边界类问题。
- 否定类问题。
- 版本类问题。
- 需要多跳推理的问题。
- 需要从多个文档拼接答案的问题。
2. 我会看什么
我不只看“能不能回答”,还看:
- 有没有命中正确来源。
- 回答是不是前后自洽。
- 同一个问题多次问,结果会不会漂。
- 失败的时候能不能快速定位。
- 延迟是出在检索、生成还是上游接口。
- 更新后是否还能稳定命中新版本。
3. 我会记录哪些日志
我通常会记录这些字段:
- request_id
- user_query
- source_doc_id
- source_chunk_id
- top_k
- score
- latency_ms
- proxy_node
- upstream_model
- error_code
- retry_count
这些信息不是为了“看起来专业”,而是为了后面能排障。
4. 为什么我不喜欢只看单次 demo
因为单次 demo 很容易掩盖问题。
一个系统可能在演示的时候很顺,但一旦真实用户的问题开始变长、变杂、变模糊,问题就会立刻暴露出来。尤其是 RAG,真实问题往往不是标准答案题,而是带上下文、带追问、带隐含条件的问题。
5. 我更信什么样的测试集
我更信真实问题集,而不是只靠人造样例。
如果有条件,我会拿一批真实问句来测,问句里最好包含:
- 简单定义。
- 版本差异。
- 对比选择。
- 否定条件。
- 追问。
- 跨文档引用。
- 特殊名词和缩写。
- 中文夹英文的混合问法。
十一、我踩过的坑,基本都和“以为差不多”有关
1. 以为 embedding 一致就够了
其实不够。切分、归一化、metadata、rerank 都会影响结果。
2. 以为 top_k 越大越稳
不一定。top_k 过大,噪声一起上来,模型反而更容易被带偏。
3. 以为存向量就够了
不够。没有来源、标题、时间、版本,后面很难查回去。
4. 以为中转层能解决所有问题
不能。它只能减少接入层摩擦,不能替你把检索设计做好。
5. 以为低配机器也能堆全套
很多时候真不行。服务太多,最先不稳的不是业务逻辑,是机器资源。
6. 以为更新就是重新上传
不完全对。更新涉及旧 chunk 删除、版本切换、索引重建、缓存失效和回滚策略。
7. 以为中文文档和英文文档一样处理
也不完全对。中文 PDF、扫描件、表格、代码块、混合术语的处理方式往往更复杂。
8. 以为有 rerank 就万事大吉
rerank 很重要,但它不是万能的。切分错了、metadata 没做、原文质量差,rerank 也救不了全部问题。
十二、我更推荐的落地顺序
如果你现在要开始做,别一下把所有目标都叠上去。我更建议这样走:
- 先用 FAISS 把最小闭环跑通。
- 先把文档切分和 metadata 做顺。
- 再决定要不要加 rerank。
- 再决定要不要换成 Milvus。
- 最后再考虑中转层、切换策略和多项目共用。
这个顺序看起来“慢”,但它更符合真实团队的节奏。很多工程问题不是靠一次性堆满,而是靠一层一层确认边界。
如果你一开始就把向量库、上游服务、中转层、生成层全铺开,后面你会很难判断到底是哪一层出了问题。
十三、一个比较完整的 RAG 伪代码流程
如果把整个过程缩成伪代码,大概会是这样:
docs = load_documents()
docs = clean_documents(docs)
chunks = split_into_chunks(docs, strategy="semantic")
embeddings = embedder.encode(chunks)
vector_store.upsert(ids, embeddings, metadatas)
query_vec = embedder.encode([user_query])[0]
candidates = vector_store.query(query_vec, top_k=8, filter=metadata_filter)
if reranker:
candidates = reranker.rank(user_query, candidates)
context = build_context(candidates)
answer = llm.generate(
prompt=build_prompt(user_query, context)
)
log_request(
query=user_query,
candidates=candidates,
answer=answer
)
这段伪代码看起来简单,但每一步都可能出问题。
真正落地的时候,我会重点检查:
- 文档加载是否有缺失。
- 清洗后文本是否丢了关键标题。
- chunk 边界是否合理。
- embedding 是否一致。
- 查询时是否带过滤条件。
- rerank 是否把前几条噪声压下去。
- prompt 是否过长。
- 日志是否能回溯。
十四、常见问题,我尽量说得直接一点
Q1:FAISS 和 Milvus 到底怎么选?
如果是本地验证、个人项目、数据量不大,先 FAISS。
如果是服务化、多用户、要扩展,再考虑 Milvus。
Q2:Windows 上能不能直接跑 Milvus?
可以,但更现实的是 Docker Desktop + WSL2。官方文档就是这个路线。
如果你不想在环境上花太多时间,先用 FAISS 更省事。
Q3:向量 API 中转是不是必须有?
不是。它适合复杂一点的接入场景,不适合每个项目都强行加。
Q4:为什么检索命中了,答案还是偏?
常见原因是 chunk 切分不合理、rerank 不够、metadata 缺失、或者生成阶段没有约束住模型。
Q5:低配 Linux 上最稳的做法是什么?
先少服务,先闭环,先验证。别一开始就把整套系统堆满。
Q6:CPU 能不能做 RAG?
可以,而且很多中小项目其实更适合先用 CPU 跑通。别把 GPU 当成前提。
Q7:向量引擎和数据库是一回事吗?
不是。它们解决的问题不一样。RAG 里可以组合用,但职责要分开。
Q8:为什么我换了向量库,结果差异很大?
通常不是“向量库本身谁更强”,而是索引类型、归一化方式、chunk 策略、top_k、rerank 和过滤条件都变了。
Q9:为什么更新后老答案还会出现?
多半是旧 chunk 没删干净,或者缓存没刷新,或者版本没有纳入过滤条件。
Q10:什么时候不该急着上向量数据库?
当你的文档量还不大、问法很固定、并发也不高时,先把 FAISS 跑通通常更实际。
十五、最后的判断标准
如果让我把这篇文章压成三句话,我会这么说:
- 先把检索链路做稳,再谈模型有多强。
- 先把本地闭环跑通,再考虑服务化扩展。
- 中转层是接入工具,不是答案核心。
向量引擎真正的价值,不是“看起来很先进”,而是它能不能让你的知识稳定被找回、让你的答案稳定能落地、让你的项目在普通机器上也能继续跑。
对中小团队来说,这种稳定比任何演示都重要。
如果你做的是长期项目,我更建议把注意力放在这些具体问题上:
- 文档有没有结构。
- chunk 有没有边界。
- metadata 有没有留下来。
- 检索能不能命中。
- rerank 能不能把噪声压下去。
- 更新能不能只改变更部分。
- 日志能不能定位问题。
- 低配机器能不能持续运行。
这些事情看起来不“酷”,但它们决定了系统是不是能真正落地。
如果你后面要继续做下一版,通常我会建议把内容拆成三个方向:一篇专讲 FAISS 本地验证,一篇专讲 Milvus 部署和服务化,一篇专讲向量 API 中转和接入层对比。这样更容易按场景复用,也更容易让读者看明白自己到底该选哪条路。
十六、最后再补几句
如果把这篇文章再往回收一下,我自己的结论其实很朴素:RAG 不是“把文档接到模型上”这么简单,它更像一条工程链路。链路里每一层都不难单独做,但要把它们串成一条能长期维护、能稳定回答、能持续更新的系统,就会很考验细节。
我现在做这类项目时,思路会比以前更保守一点。先不追最复杂的架构,不急着把所有服务一次铺满,而是先让最小闭环跑通:文档能进来,chunk 能切对,embedding 能稳定生成,向量库能正确召回,答案能根据检索结果生成,日志能把问题定位回来。只要这一层闭环成立,后面的优化才有意义。
很多看起来“更先进”的方案,真正落地时未必更省时间。比如服务化向量数据库不是不能上,但如果你的数据量还不大、并发也不高、团队里又没有太多运维资源,那先用 FAISS 把流程跑通,往往比一开始就上完整服务更实际。再比如中转层,它能帮你统一接口、收口日志、减少切换成本,但它本身不是知识质量的保证。它只是接入层,不是答案层。
所以我越来越相信一件事:RAG 的核心竞争力,不在于“用了什么新名词”,而在于你能不能把最基础的几件事做扎实。
- 文档结构是否清楚。
- 切分是否合理。
- metadata 是否完整。
- 检索是否稳定。
- rerank 是否有效。
- 更新是否可控。
- 出错后是否能回溯。
这些事情都不新鲜,但它们决定了一个系统是不是能从 demo 走到真实使用。
如果你现在正准备做自己的知识库、文档问答、代码检索,或者任何依赖向量召回的应用,我的建议还是那句老话:先把最小可用版本做出来,再把每一层都慢慢补齐。不要一开始就追“完美架构”,因为绝大多数真实项目,最后拼出来的都不是最复杂的方案,而是最能持续跑、最容易维护、最少出错的方案。
做到这一步,RAG 才算真正开始进入工程阶段,而不是停留在演示阶段。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献98条内容
已为社区贡献98条内容

所有评论(0)