RAG + 向量引擎从零落地:Windows 和低配 Linux 上,我怎么在 Milvus、FAISS 和向量 API 中转之间做选择
如果只看标题,很多人会以为这篇文章是在比工具。实际上,我更关心的是,哪一种组合最适合小团队真的把项目做出来。
做过几轮 RAG 之后,我越来越确认一件事:向量引擎不是最贵的那一层,最贵的是反复返工;API 中转也不是“多余的外壳”,它有时只是给后续切换留一道门。
我写这篇记录,出发点很简单:站在实际开发者视角,把“能跑、能维护、能迁移”这三件事放在一起看。Windows 适合做本地验证,低配 Linux 适合做轻服务,Milvus 和 FAISS 各有边界,向量 API 中转则更像一个统一入口,而不是检索引擎本身。
如果你做的是知识库问答、内部文档检索、客服辅助、代码仓库搜索,或者任何一种“先检索再生成”的应用,这篇文章都可以当作一个偏实战的起点。
先把三层职责拆开
我现在做 RAG,不会先问“谁更强”,而是先问“哪一层最容易出错”。
大部分项目里,向量相关的东西其实可以拆成三层:
| 层级 | 主要职责 | 典型问题 | 更适合的场景 |
|---|---|---|---|
| 向量 API 中转 | 统一入口、鉴权、路由、限流、日志、模型切换 | 上游接口频繁变、业务代码被供应商绑定 | 需要多后端切换或统一入口的项目 |
| 向量引擎 / 向量数据库 | 向量存储、索引、相似度检索、过滤、召回 | 维度不一致、索引策略选择、迁移成本 | 所有做 RAG 的项目 |
| RAG 编排层 | 切块、清洗、召回、重排、上下文拼接、生成 | chunk 太粗、元数据太少、上下文塞太满 | 直接面向业务的应用 |
很多争论,其实都是把这三层混在了一起。
比如有人会问:FAISS 和 Milvus 到底谁更快?这个问题只有在“你到底想解决什么”的前提下才有意义。如果你只是想在本地快速验证一套语义检索流程,FAISS 的路径很短;如果你想做一个能让多人共用、能过滤、能持久化、能远程访问的服务,Milvus 的边界就更完整。
而向量 API 中转,解决的是“调用层怎么稳定”,不是“检索层怎么聪明”。它像一个统一的前门,让你后面无论换 embedding 模型、换生成模型、换供应商,业务层都不用跟着重写。
这三层拆开之后,很多项目会突然变简单。因为你不再把所有压力都压在某一个工具身上。
Windows 上,我通常先这样落地
Windows 上最现实的思路,不是追求“原生大而全”,而是先把流程跑通。
1. 先用 Milvus Lite 做本地验证
如果你现在还在做原型,我通常会先看 Milvus Lite。
它适合的不是那种一上来就要高并发、复杂分片、多人协作的场景,而是本地笔记本、Jupyter、PoC、个人知识库原型这种“先证明方法可行”的阶段。它的好处很直接:不用先起一堆服务,就能把向量存储、检索和过滤串起来。
我喜欢这种方式的原因,不是它“高级”,而是它足够像正常代码。今天你在本地跑通了,后面换成远程服务,业务逻辑基本不用动。
from pymilvus import MilvusClient
# 本地文件路径就是一个轻量库
client = MilvusClient("./milvus_demo.db")
# 迁到远端时,只改连接信息
client = MilvusClient(uri="http://localhost:19530", token="username:password")
对小团队来说,这种迁移路径很重要。因为很多项目不是死在技术能力上,而是死在“第一次迁移就要重写一遍”。
2. 如果要更接近生产,再上 Docker Desktop + WSL2
Windows 上做服务化,我更倾向于 Docker Desktop + WSL2 的方式,而不是把所有东西都硬装成“本地程序”。
原因也不复杂。向量引擎一旦进入服务化阶段,你就会开始面对端口、卷挂载、日志、权限、数据目录、启动顺序这些问题。与其把问题藏起来,不如把它们放在一个相对标准化的容器环境里处理。
我的习惯是:
- 数据目录单独挂载。
- 配置文件单独管理。
- 启动脚本只负责“起来”和“检查状态”。
- 业务代码不要直接写死服务地址。
这样做的好处是,后面不管你是换机器、换目录、换版本,还是从本地验证切到正式服务,排障路径都比较清晰。
3. FAISS 在 Windows 上的意义
FAISS 其实非常适合 Windows 上的轻量场景。
我对它的理解很简单:它是一个库,不是一个完整服务。这个判断很重要,因为它决定了你要不要自己补很多周边能力。
FAISS 的优点是:
- 启动快。
- 依赖少。
- 单机检索非常顺手。
- 你能完全控制元数据和业务逻辑。
FAISS 的代价也很明确:
- 持久化要自己做。
- 元数据要自己管。
- HTTP 接口要自己封。
- 权限、监控、备份都要自己补。
如果你只是做一个个人笔记问答、局部知识检索、文档原型,FAISS 很可能已经够用。尤其是在 Windows 上,CPU 版就能先把事做出来。
按照官方文档的思路,Windows x86-64 上的 faiss-cpu conda 包是可以直接用的。如果你不想一开始就碰 GPU 编译,先把 CPU 版跑起来,通常是最省心的。
import faiss
import numpy as np
d = 384
xb = np.random.random((1000, d)).astype("float32")
faiss.normalize_L2(xb)
index = faiss.IndexFlatIP(d)
index.add(xb)
xq = np.random.random((1, d)).astype("float32")
faiss.normalize_L2(xq)
scores, ids = index.search(xq, 5)
print(ids)
print(scores)
这个例子当然只是示意,但它能说明一件事:如果你只是想先把相似度搜索跑起来,FAISS 的路径非常短。你不需要先理解一整套服务架构。
低配 Linux 上,我通常会更谨慎
低配 Linux 服务器最怕的不是“能力不够”,而是“什么都想要”。
如果机器配置普通、内存不富余、又没有专门运维人手,我一般不会上来就把完整的服务栈堆满。因为向量检索本身未必最吃资源,真正把机器拖慢的,往往是服务层、持久化层、日志层、监控层和容器层一起上。
1. 轻服务方案:先用 FAISS
如果目标只是单机检索、局部验证、临时知识库,FAISS 往往是最轻的一步。
你可以把它做成一个很薄的服务,甚至直接嵌在业务进程里。元数据可以放到 SQLite 或 PostgreSQL,向量索引用 FAISS,查询逻辑自己包一层。这样做的好处是:
- 启动快。
- 资源占用低。
- 代码结构清楚。
- 出问题时很好排查。
它的短板也很明显:一旦你要做更复杂的过滤、远程访问、多人共享、权限控制、在线扩容,自己补的内容会越来越多。
2. 服务化方案:Milvus 更完整
如果你已经明确要做成一个给团队用的向量服务,或者未来有多个业务共用同一套检索能力,我会更认真地看 Milvus。
Milvus 的价值不是一个“更好听”的名字,而是它把服务化场景里常见的东西组织得比较完整:存储、索引、过滤、查询、持久化、远程访问,这些能力一旦都要自己补,项目维护成本会明显上升。
对小团队来说,Milvus 更像是一个“少造轮子”的选项。前期配置确实比 FAISS 复杂一些,但如果后面真要给多人使用、真要接入多个数据源、真要加过滤条件和审计记录,这个复杂度是会回收的。
3. 低配 Linux 的实话
我现在的经验是:如果机器资源紧张,又没有必须服务化的诉求,先用 FAISS,通常比强行上完整服务更稳。
因为很多项目的初始阶段,本来就不是为了极致性能,而是为了验证两件事:
- 检索链路能不能跑通。
- RAG 的回答质量是不是有提升。
当这两件事成立之后,再讨论服务化,顺序会自然很多。
我更看重的,不是跑分,而是这些维度
我不太喜欢那种只列性能数字、不讲背景的对比。对实际项目来说,下面这些维度往往更重要。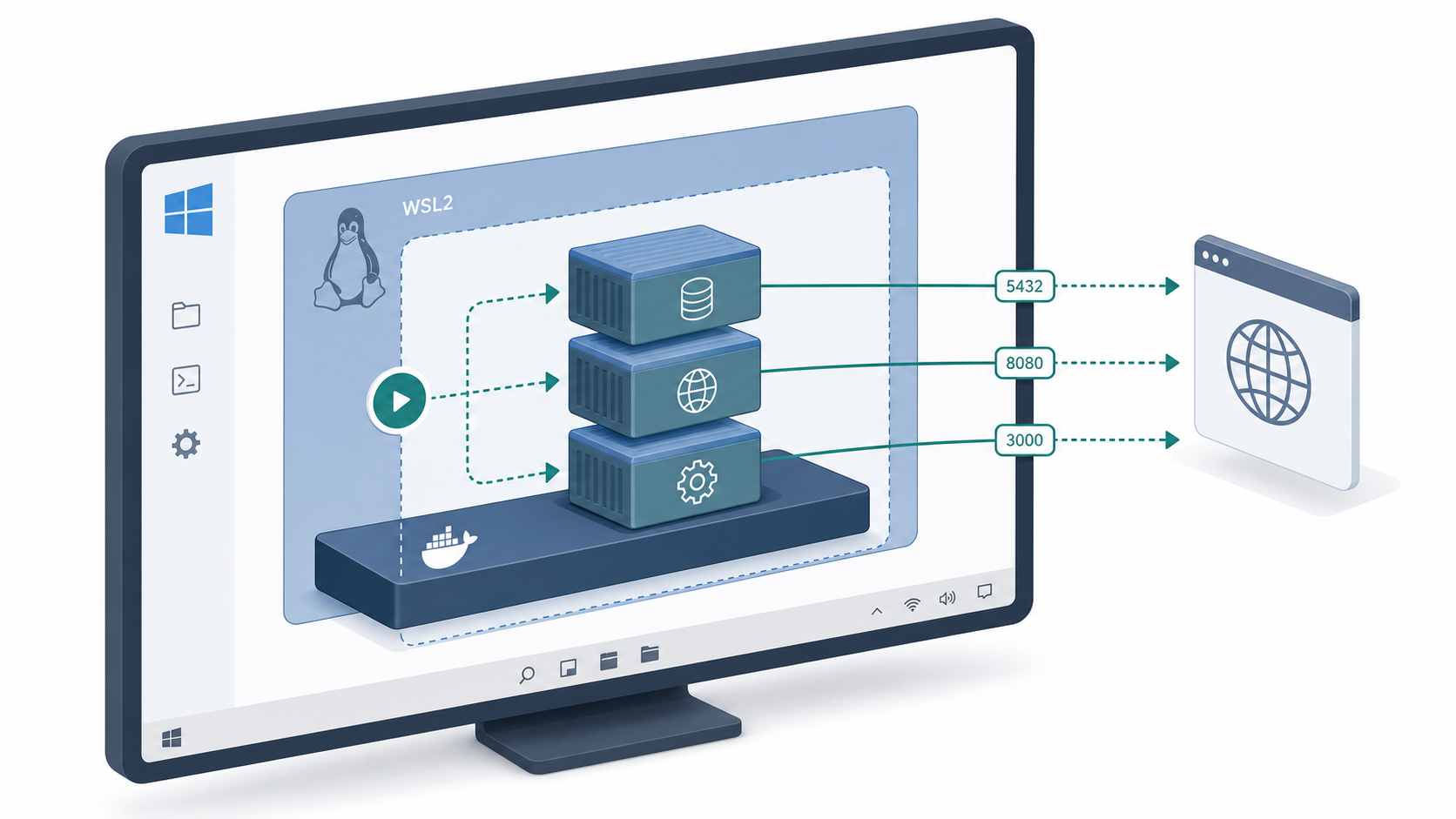
| 维度 | Milvus Lite | Milvus 服务化 | FAISS | 向量 API 中转 |
|---|---|---|---|---|
| 启动难度 | 最低 | 中等 | 低 | 低 |
| 资源占用 | 很低 | 中等到偏高 | 很低 | 低 |
| 持久化 | 有 | 有 | 要自己补 | 无 |
| 过滤查询 | 有边界 | 更完整 | 要自己做 | 无 |
| 多人协作 | 一般 | 更适合 | 不适合直接做 | 只适合入口统一 |
| 迁移成本 | 低 | 中等 | 中等 | 低 |
| 排障难度 | 低 | 中等 | 低 | 低 |
如果只看这张表,我的直觉判断通常是这样的:
Milvus Lite 更像一个本地工作台,适合从 demo 走向原型。
Milvus 服务化更像一个可长期使用的组件,适合有多人访问和过滤需求的项目。
FAISS 更像一把特别顺手的刀,轻、快、直,但你要自己准备刀鞘。
向量 API 中转则像“统一接口的门牌号”,它解决的是入口稳定,不是检索质量。
RAG 真正影响效果的地方,其实不在引擎名字
这部分是我越来越确定的一件事:很多 RAG 项目效果不好,不是因为你没选对 Milvus 或 FAISS,而是因为你把大头精力花在选型上,没花在数据上。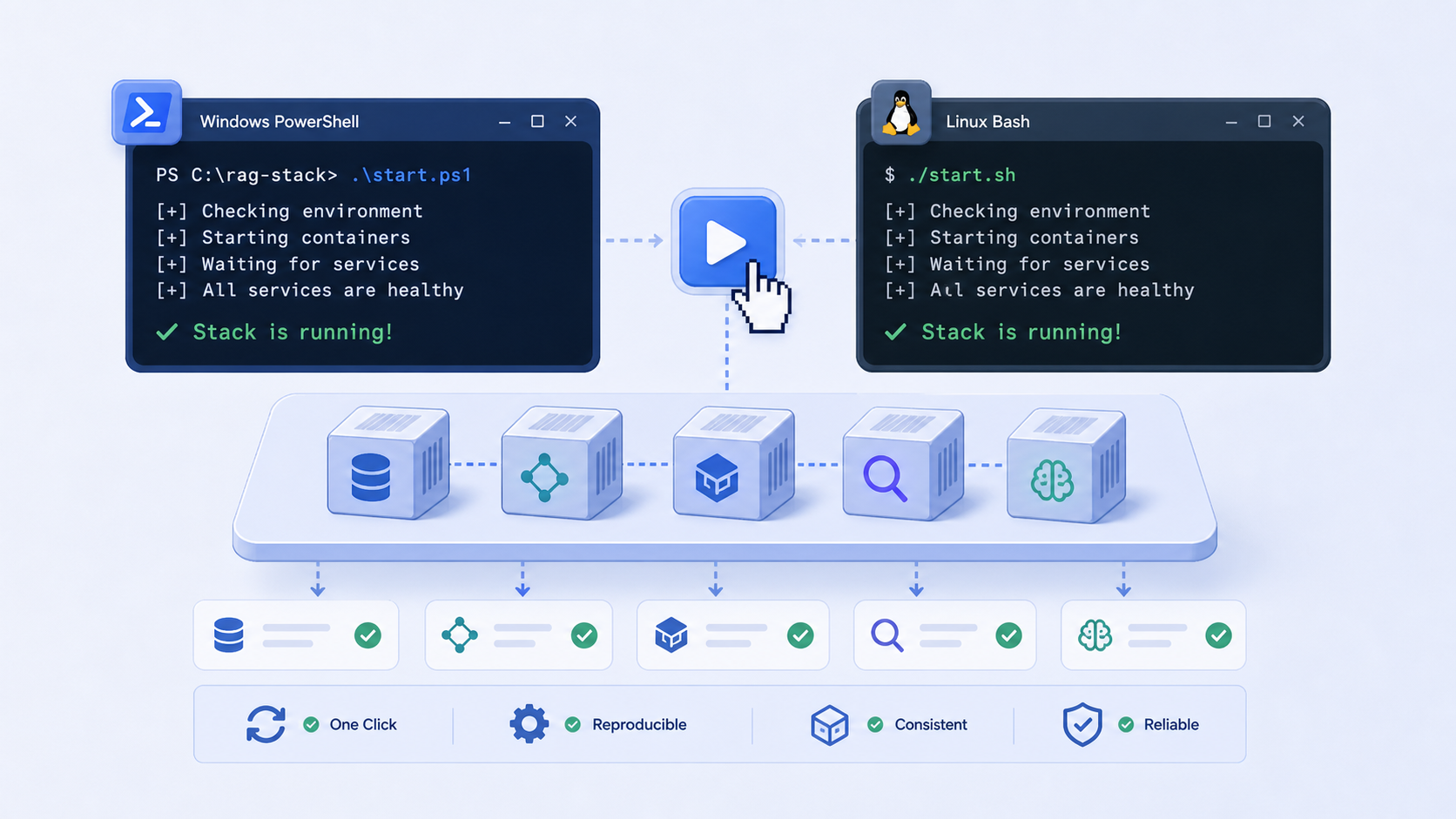
1. 切块方式比很多人想得更重要
块太大,召回后上下文会很肥,模型容易被噪音带偏。
块太小,语义不完整,检索出来以后看起来“命中了”,实际回答却拼不成完整意思。
我更喜欢按语义边界切,而不是机械按字符切。对不同类型内容,切法也不一样:
- 文档类,优先保留标题层级和段落边界。
- FAQ 类,尽量一问一答成块。
- 代码类,优先按函数、类、模块来切。
- 表格类,尽量保留行列关系,不要切碎到看不出字段含义。
2. 元数据不是装饰
source、title、section、updated_at、tags、tenant_id 这些字段,平时看着不起眼,一旦你要做过滤、回溯、分组、排序,它们就会变成关键能力。
FAISS 本身不会替你管理这些信息,所以你要自己配一个轻量 metadata 存储层。Milvus 在这方面会省事一些,因为它的服务化形态本来就更适合把向量和字段一起管理。
3. 向量维度和归一化要稳定
最常见的坑之一,是两个 embedding 模型的维度不一样。
比如一个模型输出 384 维,另一个模型输出 768 维,索引看起来建好了,数据却根本没法混。还有一个常见问题是只看内积,忘了先做归一化,最后排序看起来能跑,结果并不稳定。
如果你已经确定要用余弦相似度,通常要先把向量归一化,再用对应的内积方式去做检索。这个步骤看上去很基础,但很多项目就是在这里出问题。
4. 重排往往比换引擎更有效
向量召回只是第一步。
真正决定答案质量的,经常是重排和上下文组织。很多时候,向量库只负责给你一组候选,最后能不能答到点上,还是要靠后面那层 rerank 和 prompt 结构。
这也是为什么我很少把“引擎更换”当成提升效果的第一步。很多时候,先调切块、再补元数据、再做重排,比换一个更重的向量系统更有效。
5. 缓存和增量更新别忽略
如果你的数据不是一次性导入完就不动了,而是会持续更新,那么缓存和增量更新就很重要。
我通常会至少区分三类缓存:
- 查询缓存,减少重复问答的消耗。
- embedding 缓存,避免同一段文本反复算向量。
- 候选缓存,减少重复召回。
再加上增量更新策略,你的系统会比“每次重建索引”稳定得多。
向量 API 中转应该放在哪
我现在对向量 API 中转的理解很明确:它是基础设施,不是核心答案。
如果你只有一个模型、一个供应商、一个调用路径,而且短期内也不会变,那它甚至可以先不加。
但如果你已经开始出现下面这些情况,它就有价值了:
- embedding 模型会切换。
- 生成模型会切换。
- 上游接口经常调整。
- 你想统一日志和限流。
- 你想预留 fallback。
- 你想把成本统计放到一个入口里看。
我的习惯是,把它当成环境变量或配置项来管理,而不是散落到业务逻辑里。
比如说,项目里可以这样写:
VECTOR_API_BASE_URL=https://178.nz/dn
VECTOR_API_TIMEOUT=30
VECTOR_EMBEDDING_MODEL=text-embedding-3-large
我更愿意把这类东西看成“系统参数”,而不是文章里最后才出现的一个链接。它放在配置里,读起来就像一个普通的基础设施地址,不会显得突兀。
如果你要做的是统一入口层,那么它的职责应该很清楚:
- 统一鉴权。
- 统一请求格式。
- 统一日志。
- 统一限流。
- 统一后端切换。
它不负责把检索质量变好,也不负责把文档切得更合理。
一键启动脚本,我通常只保留最小责任
很多技术文章喜欢把部署写得很复杂,但对小团队和个人来说,脚本越长,越不容易维护。
我的习惯是,脚本只做三件事:
- 检查依赖是否存在。
- 启动服务。
- 打印状态。
Windows PowerShell
如果你已经按官方文档把 compose 文件放好了,Windows 下我会写得非常简单:
$ErrorActionPreference = "Stop"
if (-not (Get-Command docker -ErrorAction SilentlyContinue)) {
throw "Docker 不可用,请先确认 Docker Desktop 已安装。"
}
docker compose up -d
docker ps
这个脚本看起来朴素,但它的好处是:你不会在“启动逻辑”里再掺进去太多业务判断。
Linux Bash
Linux 下我也喜欢保持同样的思路:
#!/usr/bin/env bash
set -euo pipefail
command -v docker >/dev/null 2>&1 || {
echo "docker not found"
exit 1
}
docker compose up -d
docker ps
如果你做的是 Milvus Lite,那更简单,甚至连容器都不需要起。安装 pymilvus[milvus-lite] 之后,直接在 Python 里指定一个本地文件名,程序就能跑起来。
这也是我为什么会把 Milvus Lite 放在前面的原因:它不是“缩水版”,而是一个特别适合本地验证的起点。
几个典型场景,我会怎么选
如果只讲“工具名”,很多人还是会模糊。把场景拆开之后,判断会更清楚。
| 场景 | 我更常见的起步方案 | 原因 |
|---|---|---|
| 文档问答 | Milvus Lite 或 FAISS | 文档类数据最先要解决的是切块和召回,先把流程跑通更重要 |
| 代码仓库搜索 | FAISS + 额外 metadata | 代码检索更看重结构化信息,函数名、文件路径、模块名都很关键 |
| 客服辅助 | Milvus 服务化 | 这类场景更容易出现过滤、版本、租户、审计等需求 |
| 内部知识库 | Milvus Lite 起步,后续迁移到服务化 | 便于从个人验证过渡到团队共用 |
我自己在项目里通常会先问四个问题:
- 数据是不是会持续更新。
- 是否需要多人共用。
- 是否需要复杂过滤。
- 未来会不会换模型或换供应商。
如果这四个问题里有两个以上的答案是“会”,那我通常就不会只把它当一个本地小脚本来做了。
迁移时要检查什么
迁移的时候,我通常会做一个很朴素的清单:
- 向量维度有没有变。
- 切块策略有没有变。
- metadata 字段有没有缺失。
- 索引类型有没有变化。
- 查询端 top_k 和阈值有没有重新评估。
- 是否需要保留老数据的回滚入口。
这几项看起来不多,但只要少一项,迁移后就很容易出现“代码能跑,但答案味道不对”的情况。
我一般怎么迁移
我现在做这类项目,通常会按这个顺序走:
- 先用 Milvus Lite 或 FAISS 在本地验证流程。
- 把切块、embedding、检索、重排、生成这条链路跑通。
- 再决定是否需要服务化。
- 只有在多人访问、过滤、持久化、远程管理真的出现之后,再升级到 Milvus 服务化。
- 如果上游调用路径变多,再加 API 中转。
这个顺序的好处是,你不会过早地把自己锁在一个重架构里。
很多项目最麻烦的地方,不是技术不够,而是第一版就写得太满。后面每改一次,就像搬一次家。
常见错误,我踩过的不少

下面这些坑,很多我都踩过,或者至少见别人踩过。
- 只比较工具名字,不看自己的业务阶段。
- 切块只按字符数,不看语义边界。
- 维度不一致,后面却硬把不同 embedding 混在一个索引里。
- 忘了做归一化,最后相似度排序不稳定。
- 元数据字段太少,后面想过滤时只能返工。
- 过早上复杂服务,结果部署成本比业务代码还高。
- 一开始就追 GPU 或集群,实际上 CPU 都够验证前期逻辑。
- 把 API 中转当成检索能力,最后入口统一了,答案质量还是没提升。
- 只关注向量检索,忽略了重排和上下文组织。
- 没有增量更新策略,每次改一处就全量重建。
这些问题的共同点是:看起来都不大,但叠在一起,项目就会越来越难维护。
什么时候我会明确选 FAISS
如果你要的是“先把事做出来”,FAISS 往往是最务实的答案。
我会优先选它的情况一般有这些:
- 你只有单机。
- 你不需要多人共用。
- 你还不确定最终数据量有多大。
- 你更看重快速验证。
- 你愿意自己管理 metadata 和持久化。
FAISS 的优点不是“功能多”,而是“足够干净”。它把最核心的事情交给你,然后你可以按自己的节奏补齐周边。对独立开发者来说,这种控制感很重要。
不过如果项目后来长大了,你也要接受它的边界:你自己搭的东西越多,维护成本越会回到你身上。
什么时候我会明确选 Milvus
如果你已经能确定这不是一个“只跑一次”的原型,而是一个会持续用、持续扩的服务,那我会更认真地看 Milvus。
我会偏向它的情况通常是:
- 需要持久化和远程访问。
- 需要过滤、分组、租户隔离。
- 需要多人共享。
- 需要把向量检索做成单独服务。
- 未来可能会接入多个业务系统。
Milvus 的价值不在于“显得专业”,而在于它能减少你自己补周边的工作量。只要你明确知道自己要的是服务化,它的复杂度就不是负担,而是前期换来的稳定性。
什么时候我会加向量 API 中转
我通常不把中转层作为起点,而是把它放在“系统快要变复杂”的阶段。
典型情况是:
- 你的 embedding 模型要切换。
- 你的生成模型要切换。
- 你想统一鉴权和日志。
- 你想统一限流和错误处理。
- 你想把成本统计放在一个地方。
- 你想留一个 fallback 入口。
如果你的项目已经有上游调用层,我会把它收敛成配置项,例如:
VECTOR_API_BASE_URL=https://178.nz/dn
VECTOR_API_TIMEOUT=30
VECTOR_EMBEDDING_MODEL=text-embedding-3-large
我更愿意把它看成“系统参数”,而不是文章里最后才出现的一条链接。它放在配置里,读起来就像一个普通的基础设施地址,不会显得突兀。
这也是我比较认可的一种思路:把工具变成参数,把调用变成配置,把切换变成低成本动作。这样后面真的要迁移时,不会每一步都牵动业务代码。
我看 RAG 的几个关键指标
如果只是说“效果好不好”,太笼统。落到项目里,我通常看这些指标。
1. 召回准确率
也就是你检索出来的候选里,有多少是“真的相关”。
这个指标受切块、向量模型、归一化、索引方式影响很大。很多项目看起来是“搜到了”,其实只是命中了相似词,不是真正的语义相关。
2. 排序稳定性
同样的问题重复问,结果不要飘得太厉害。
如果排序总变,很可能是检索阈值、索引参数、分词切块或者 rerank 有问题。稳定性在内部知识库里尤其重要,因为用户更在意“每次问都差不多”,而不是“偶尔特别准”。
3. 上下文密度
喂给大模型的上下文不是越多越好。
太少,信息不够;太多,噪音太大。真正好的结果通常是“命中高、上下文短、答案清楚”。这部分很多时候不是向量引擎决定的,而是检索后的拼装方式决定的。
4. 更新成本
知识库不是一次性导入就完了。
如果你的业务文档、产品文案、工单、FAQ 会持续变化,那么更新成本会直接影响系统寿命。一个能轻松增量更新的方案,实际体验往往比一开始跑分高但维护麻烦的方案更好。
5. 排障成本
这个指标我特别看重。
因为项目里最常见的不是“完全不能用”,而是“能用但不稳定”。这时候你能不能快速定位问题,就决定了这个系统有没有持续演进的可能。
如果我要从零做一个小型 RAG 项目
我大概率会这么开始:
- 先选 FAISS 或 Milvus Lite。
- 先把切块策略确定下来。
- 先把 metadata 字段定义好。
- 先做最小召回,不追求复杂功能。
- 再加重排。
- 再加缓存。
- 最后再考虑服务化和统一入口。
这个顺序听起来很慢,但其实更快。因为它避免了你一开始就在不必要的基础设施上花时间。
对很多小团队来说,真正的竞争力不是“我一上来就上最复杂的架构”,而是“我能在最少返工的前提下把系统跑起来”。
常见问题
Q1:Windows 上能不能直接把 Milvus 当成一个本地程序跑?
可以做本地验证,但我更建议把它理解为 Milvus Lite 或者容器化服务,而不是一个单纯的 exe。前者适合原型,后者更接近真实部署。
Q2:FAISS 和 Milvus 是二选一吗?
不是。很多项目先用 FAISS 做单机原型,后面再迁移到 Milvus,这条路很常见,也很合理。
Q3:向量 API 中转能替代向量数据库吗?
不能。它解决的是调用入口,不解决向量存储和检索。它像前门,不像仓库。
Q4:为什么我已经检索到内容,回答还是不准?
通常不是引擎错了,而是切块、元数据、重排、上下文拼接出了问题。检索命中只是第一步,真正决定效果的是后面的组织方式。
Q5:低配 Linux 上到底该先上哪个?
如果只是单机验证,我通常先选 FAISS;如果你明确需要服务化、过滤、多人共享和持久化,再考虑 Milvus。
Q6:Milvus Lite 和服务化 Milvus 的关系是什么?
我更愿意把它理解成迁移路径的一部分。先在本地文件里跑通,再切到远程服务,代码结构会更顺。
Q7:GPU 是不是向量项目的必选项?
不是。很多时候,真正耗资源的是 embedding 和重排,不一定是向量检索本身。前期验证阶段,CPU 往往足够。
Q8:到底什么时候该把中转层加进去?
当你的模型、供应商、鉴权、限流、日志开始变复杂的时候。太早加会增加复杂度,太晚加会让业务代码越写越散。
结尾
做 RAG 这件事,越往后做,我越觉得一个朴素的原则最有用:先把链路做薄,再把能力做厚。
向量引擎是底座,API 中转是入口,RAG 编排是业务逻辑。底座没选对,系统会很难扩;入口没分清,代码会越写越乱;编排没做好,最后效果也上不去。
对小团队来说,最稳的路线通常不是“一次性选最重的方案”,而是先选一个能持续用下去的方案。能用 FAISS 解决的事情,不一定非要上完整服务;需要服务化和过滤的时候,再让 Milvus 站出来;需要统一调用和切换的时候,再加一层中转。这样走,成本更低,回头路也更少。
如果只记一句话,我会记这个:
RAG 的核心不只是“找到向量”,而是“把正确的内容,以最少的复杂度,稳定地送到模型面前”。
参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献98条内容
已为社区贡献98条内容

所有评论(0)