一、Ceph 开局指导手册之服务器初始化配置篇
一、环境说明
- 节点数量:三台 —— 这是 Ceph 集群的最小规模,满足 mon 的奇数选举要求(至少 3 个 mon 节点),同时也能完整演示 OSD 数据分布与故障域隔离。
- 服务器型号:R4900 G3 —— 新华三的通用机架式服务器,支持 12 块 3.5 寸硬盘位,PCIe 插槽充足,非常适合作为 Ceph 存储节点。
- 操作系统:openEuler —— 华为开源的 Linux 发行版,内核针对多核 NUMA 和大页内存做了优化,与 Ceph 的异步 IO 和 RDMA 特性配合良好。
- 单节点硬盘配置:
- 2 块 558.91GB HDD 系统盘(RAID1)—— 用于安装操作系统和 Ceph 管理组件,RAID1 提供磁盘冗余,避免单盘故障导致节点失联。
- 2 块 1.92T SSD 缓存盘(直通盘)—— 作为 OSD 的写缓存(WAL/DB 或 Bcache),直通模式避免 RAID 卡缓存策略干扰 SSD 的低延迟特性。
- 6 块 8T HDD 数据盘(直通盘)—— 承载实际数据,直通模式让 Ceph 直接管理磁盘,充分发挥 CRUSH 算法的数据分布能力。
- ⚠️ 环境限制说明:在企业生产环境中,系统盘建议用 SSD 以加速系统启动和日志写入,缓存盘建议用 NVMe 以获得更高的 IOPS 和更低的延迟。
- 内存:128G —— 每节点 128GB 内存,其中约 4GB 留给操作系统,其余分配给 OSD 的 Page Cache 和 mon/mgr 进程,确保大文件读写时缓存命中率。
- 处理器:Intel® 2块8核16线程 —— 双路 CPU 共 16 核 32 线程,足以支撑 8 个 OSD 的 scrubbing、rebalance 和客户端 IO 并发处理。
- 管理网单网卡速率:1000Mb/s —— 运维管理。
- 存储网 & 业务网单网卡速率:10000Mb/s —— 10GbE 是 Ceph 生产环境的入门带宽,承载客户端读写 IO 和 OSD 间数据复制,建议与业务网 VLAN 隔离,避免流量争抢。
二、安装操作系统
⚠️ 以下操作三台节点都要执行,这里我拿第一台举例!!!
2.1 配置系统盘
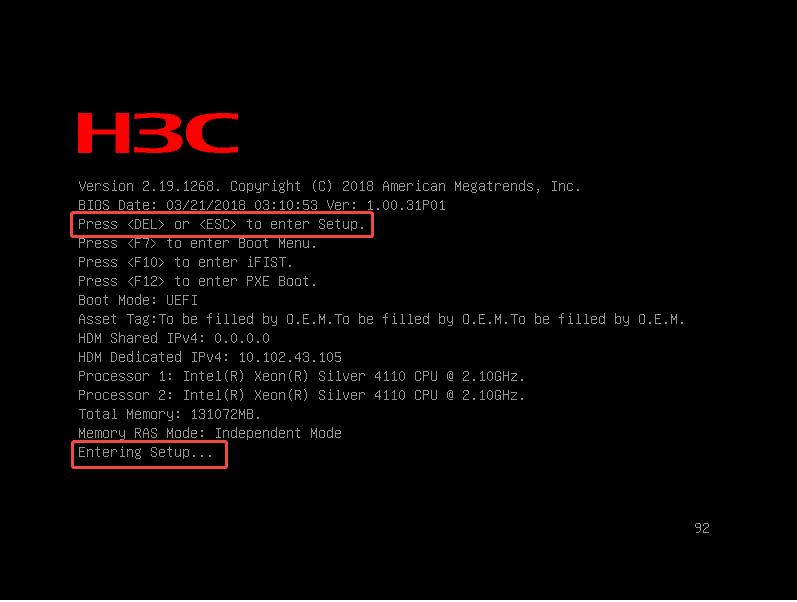
- Press ESC to enter BIOS configuration: 系统配置界面,是一套固化在主板 ROM 中的底层管理软件(不是操作系统)。通过它你可以直接查看和修改服务器的硬件参数、工作模式、启动顺序等核心设置。
- Advanced ——> PMC maxView Storage Manager
Advanced: 管理和配置服务器上所有非核心的板载设备、外插卡(网卡、RAID卡)的工作模式,以及一些底层系统行为。
PMC maxView Storage Manager: PMC-Sierra 是 RAID 卡的芯片厂商。进入这里,就是配置这台服务器上插的那张 RAID 卡(做阵列、看硬盘状态、设热备盘等)。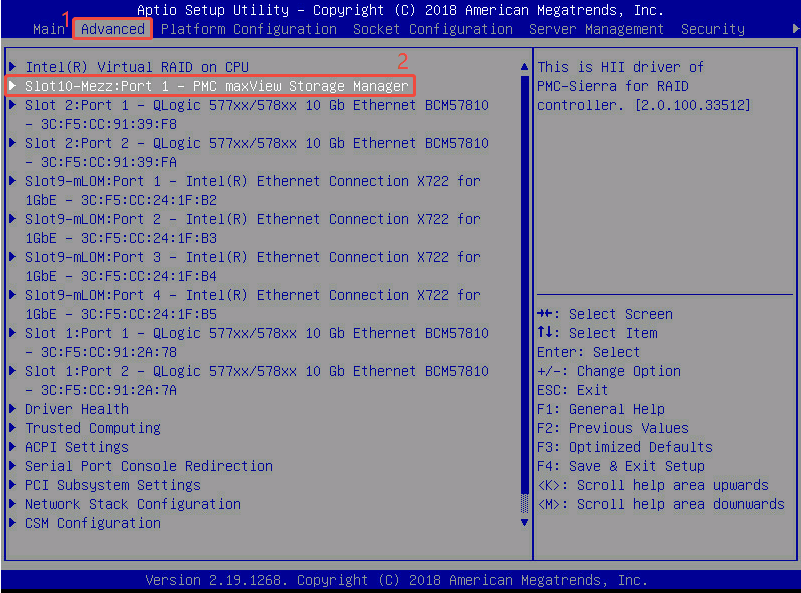
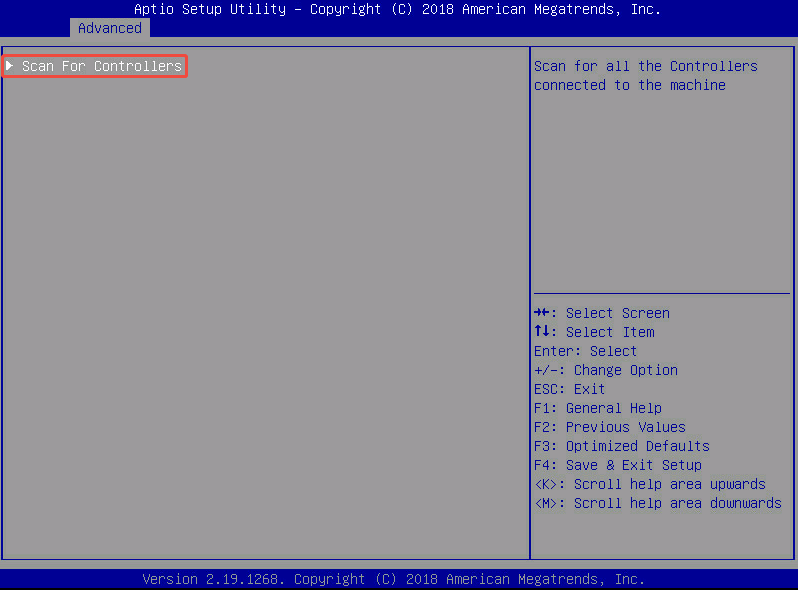
- Scan For Controllers: 让 BIOS / RAID 卡固件去检测当前服务器上插了几块 PMC 品牌的 RAID 卡,以及每块卡上连接了哪些物理硬盘。
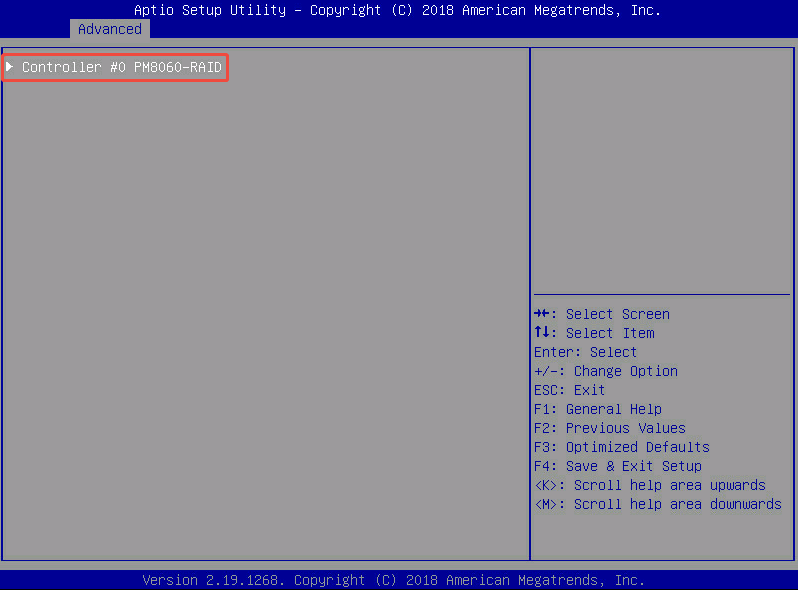
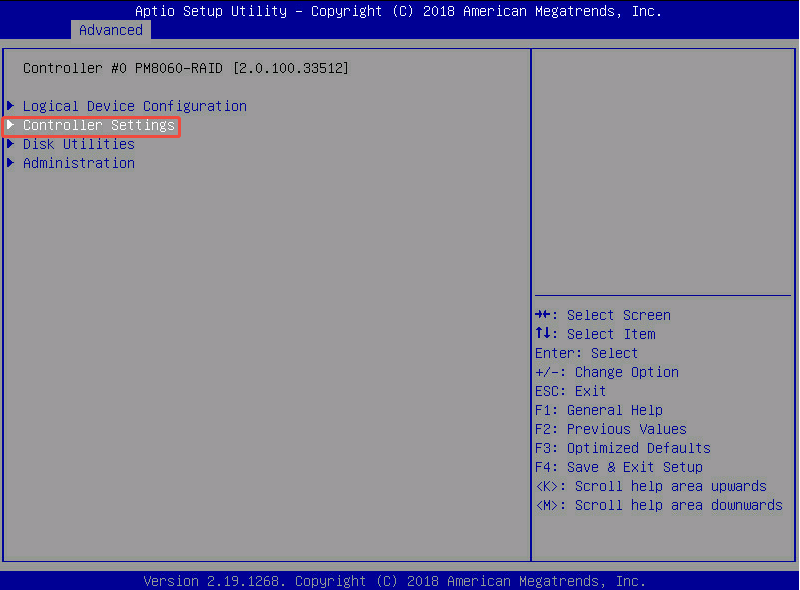
- Controller #0 PM8060-RAID: 我们之前执行了“Scan For Controllers”(扫描控制器),现在 BIOS 已经成功找到了这台服务器上的 第 0 号 RAID 卡,型号是 PM8060-RAID。
- Logical Device Configuration: 我们之前选择了 Controller #0 PM8060-RAID 并按回车后,就进入了这张 RAID 卡的控制界面。这里选择配置逻辑设备(也就是 RAID 阵列)。
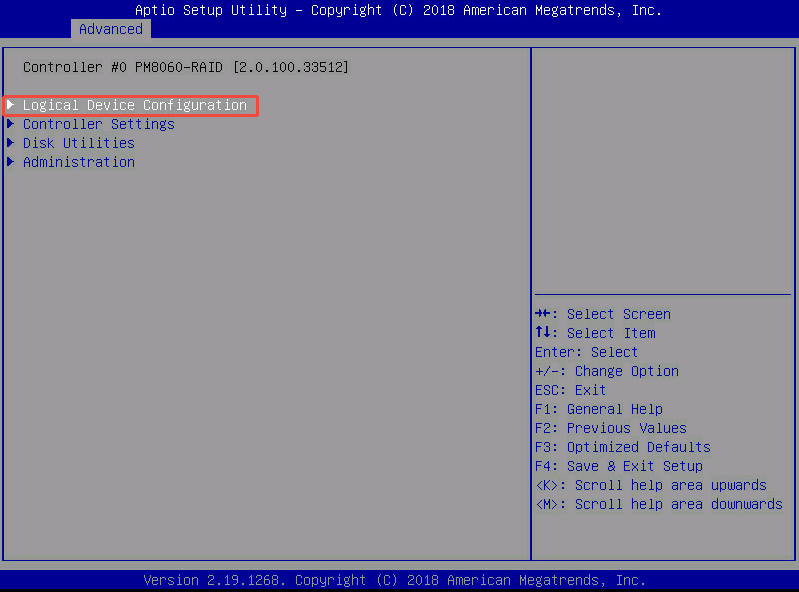
- Initialize Drives (Execute this step before creating RAID): 初始化硬盘。对单块硬盘进行初始化(会清除硬盘上的 RAID 元数据,使其变成“未配置”状态,可用于组建新阵列)。
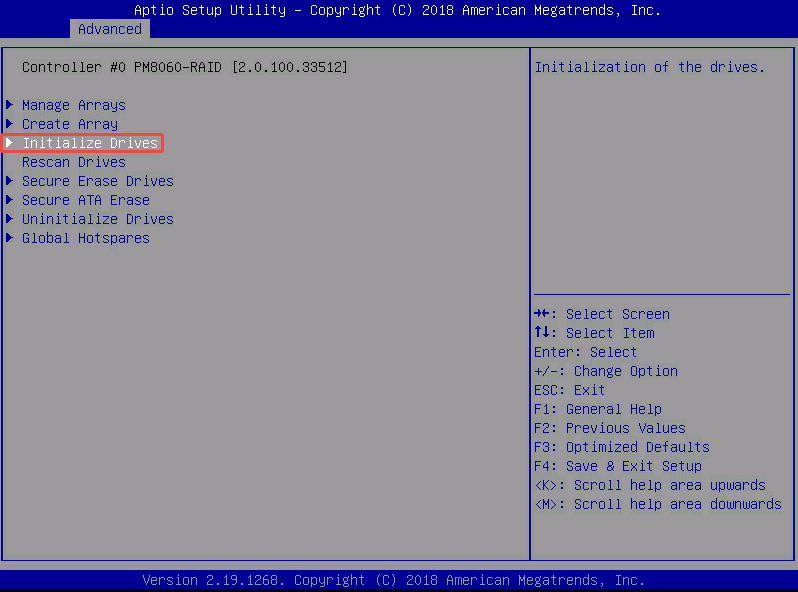
- 将两块 557.9GB 的系统盘选择为 [Enabled]
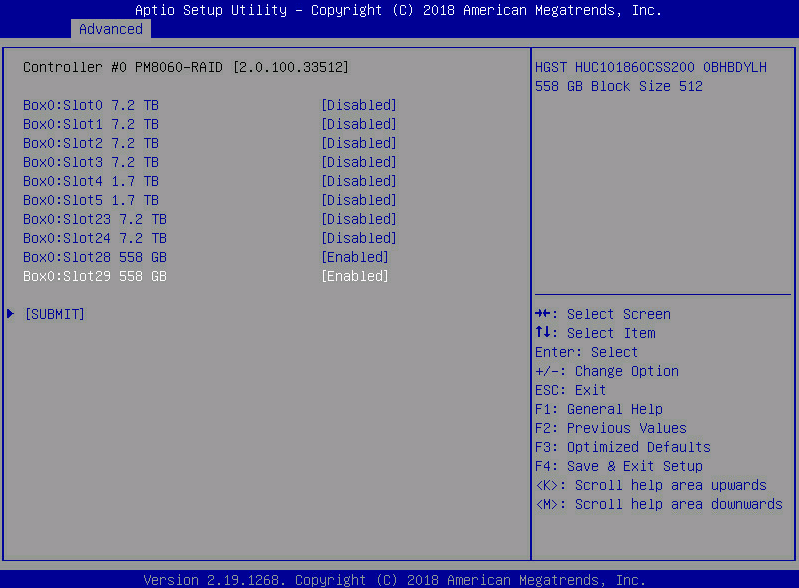
- Create Array: 创建新的 RAID 阵列(装系统前最常用)。
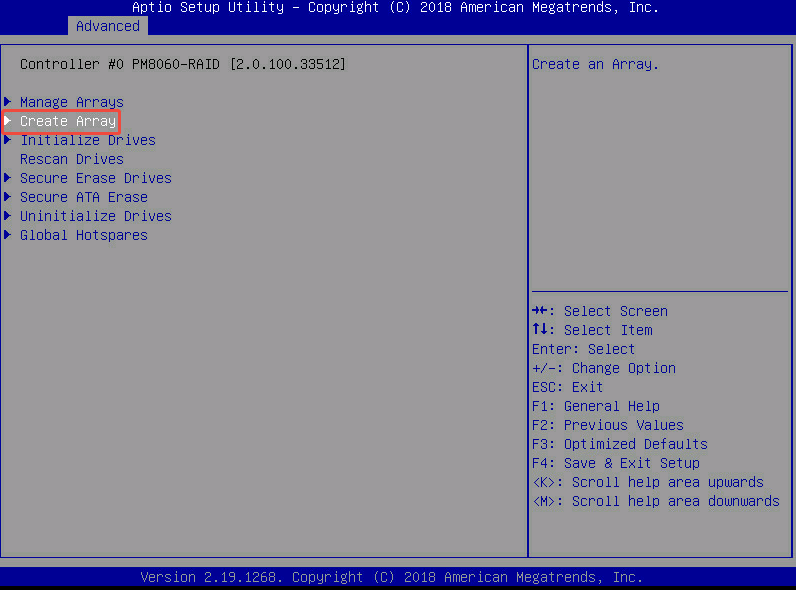
- 将这两块 557.9GB 的系统盘组成 RAID 阵列 ——> [PROCEED]
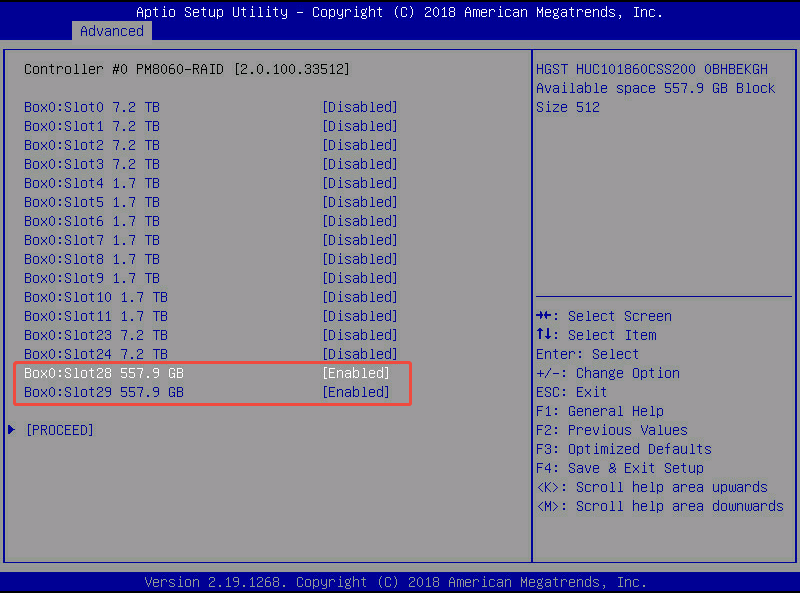
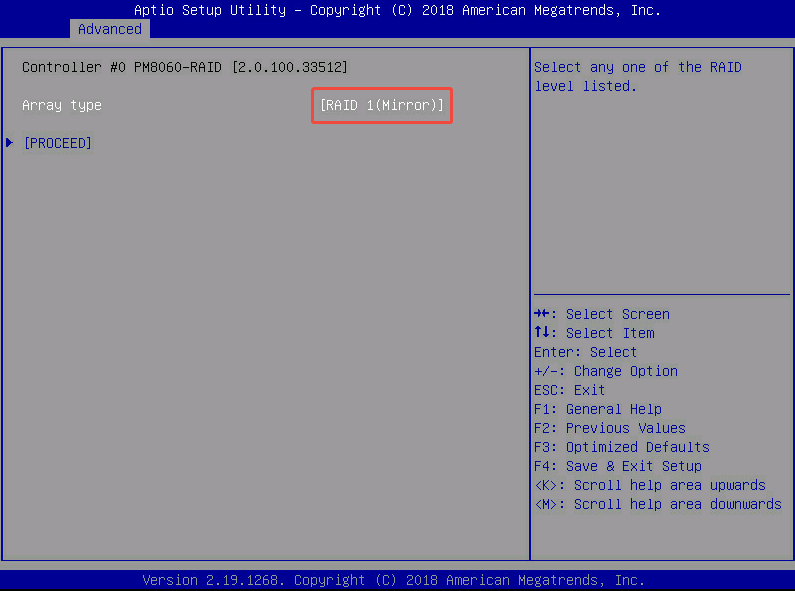
- Array type: 选择 RAID 级别,这里我们配置成 RAID 1(镜像模式,写数据时要同时写到这两块系统盘里面,所以两块系统盘存的数据是一模一样的)如果其中一块系统盘故障,不会影响系统正常运行。也是系统盘 RAID 常见的使用模式。
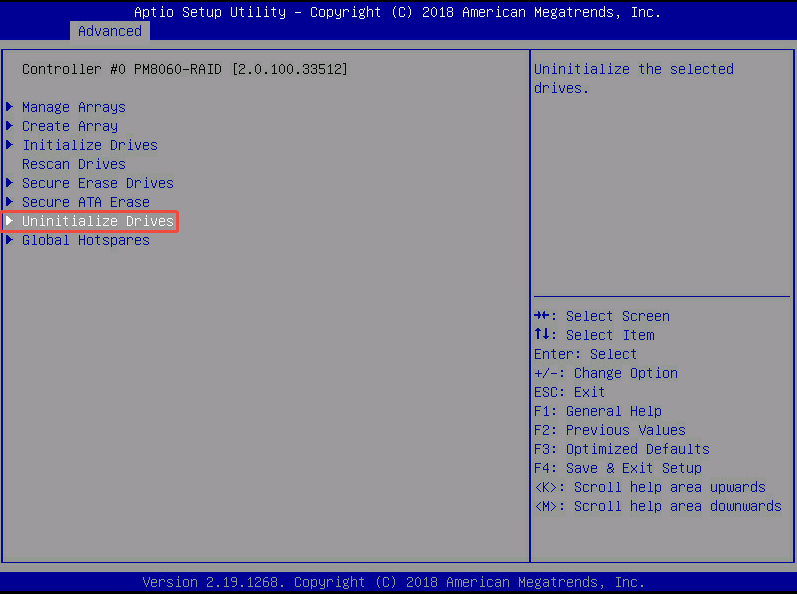
2.1 配置数据盘
- Uninitialize Drives: 清除硬盘上的RAID配置信息,让硬盘回到"干净"的初始状态。为了让硬盘能被系统直接识别,还需要将RAID卡本身设置 expose RAW 模式,这样这些 Uninitialize 的盘就变成了我们传统意义上的直通盘。
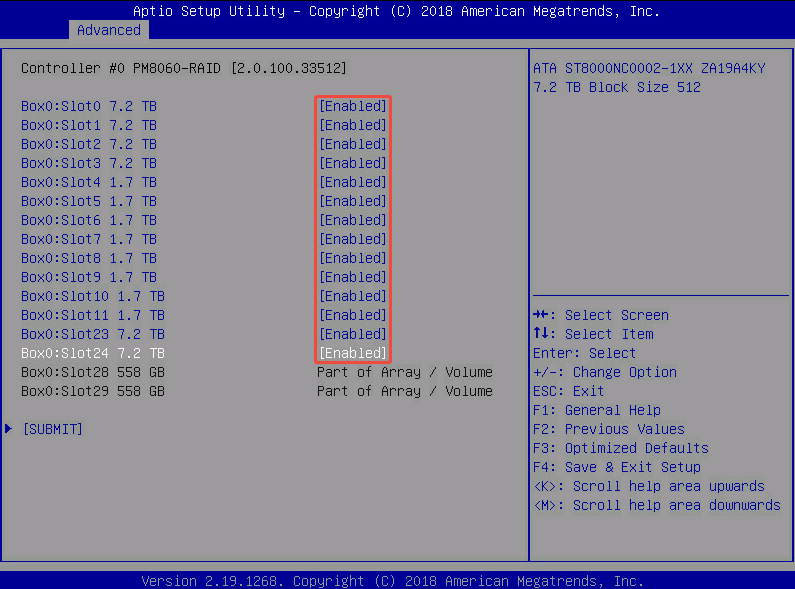
- 把所有数据盘都选成[Enabled] ——> [SUBMIT]
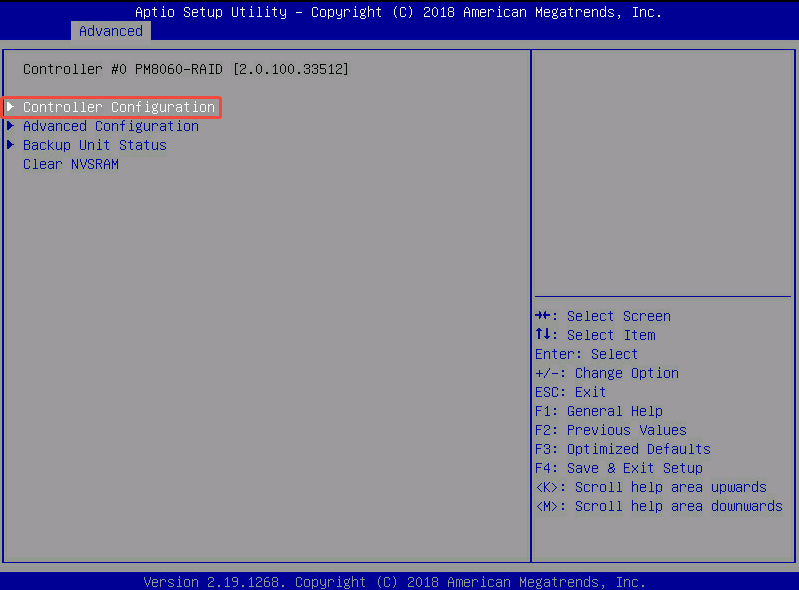
- Controller Settings——> Controller Configuration: PMC RAID 卡的“控制器高级管理菜单”,这里面藏着我们之前要找的 Controller Mode(RAID / HBA / Mixed)切换选项。
- Controller Mode: 设置控制器工作模式
[RAID: expose RAW] 将物理硬盘以“原始设备”(Raw Device)的形式直接暴露给操作系统,但同时 RAID 卡仍然可以管理这些硬盘(例如监控健康状态、设置热备等),只是不在硬件层面组装 RAID 阵列。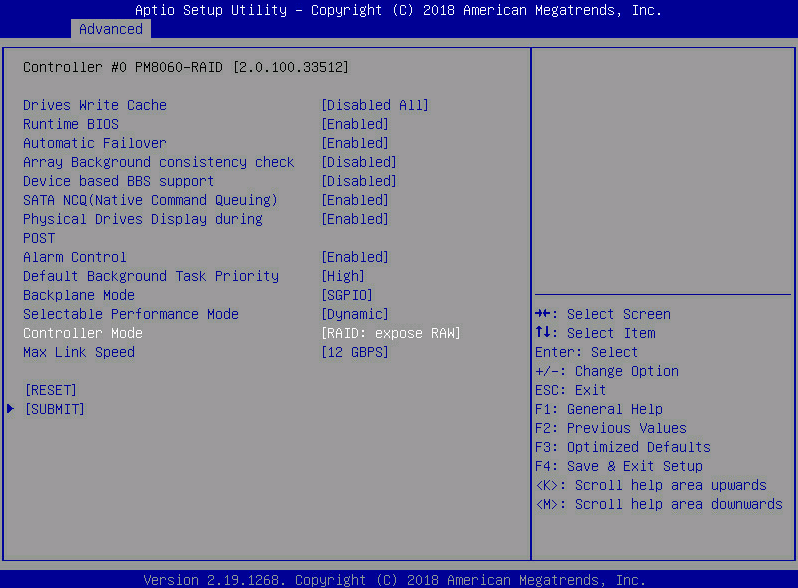
2.3 选择启动引导文件
- 镜像挂载: 这个界面是 H3C 服务器的 HDM(硬件管理控制器)的“镜像挂载”功能页面。简单说,就是通过网络把 ISO 镜像文件虚拟成服务器的光驱(CD/DVD),用来给服务器远程安装操作系统、运行诊断工具或更新固件。
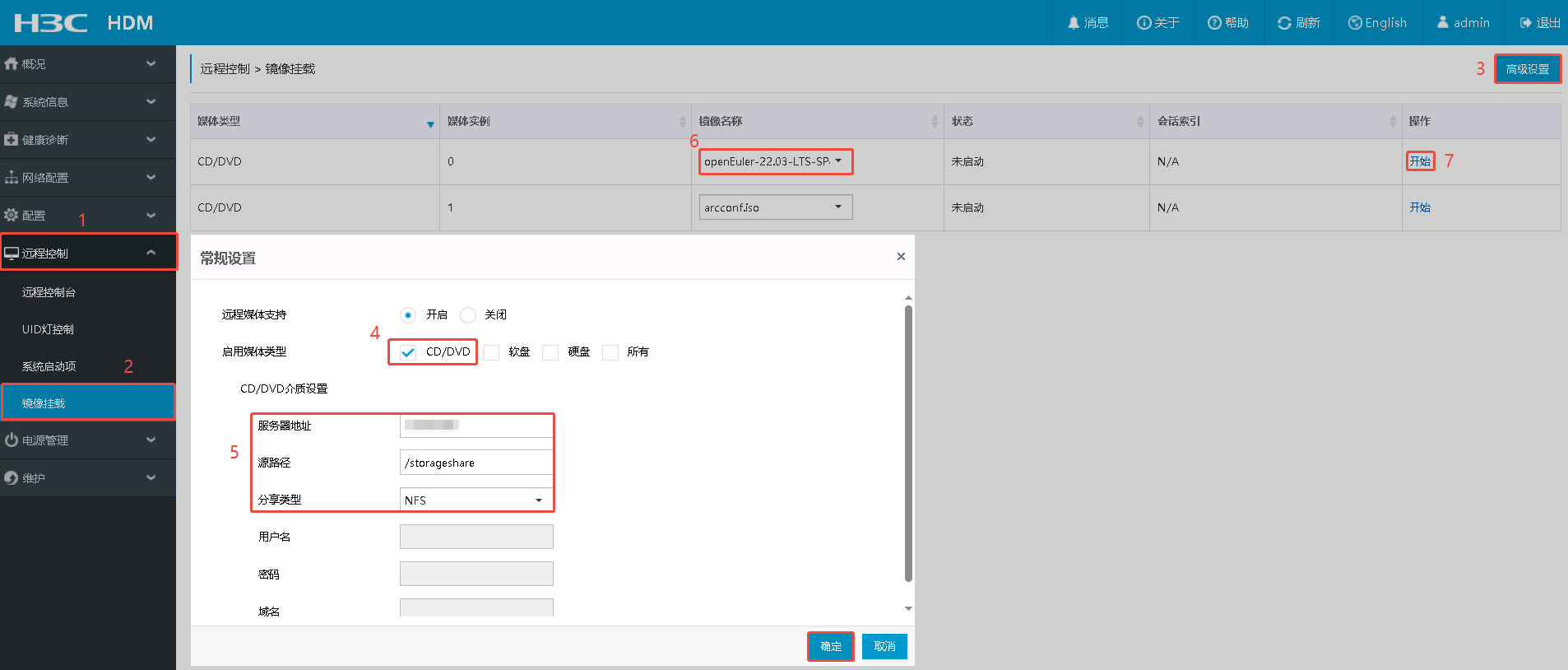
- 系统启动项: 这是一个“一次性启动覆盖”设置,用来告诉服务器下次启动时临时从某个设备(这里是用我们的镜像 openEuder-22.03…iso)启动,不影响永久启动顺序。
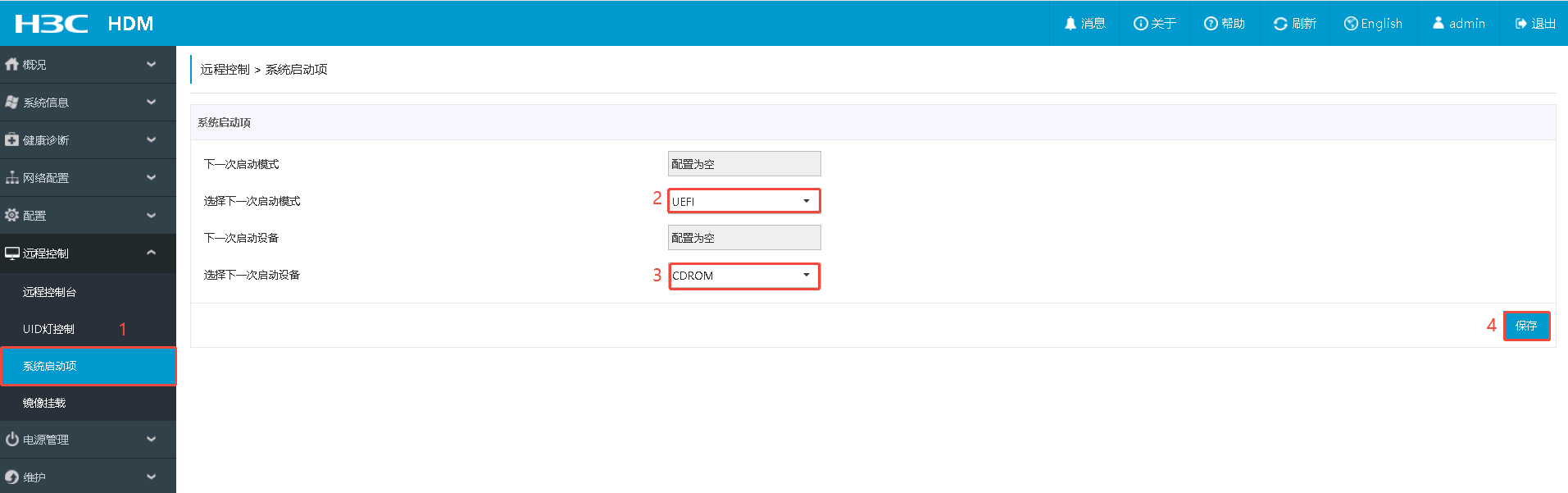
- Boot ——> Boot Option#1: 选择启动镜像 [CD/DVD],保险起见,这里再设置一次用[CD/DVD]启动。
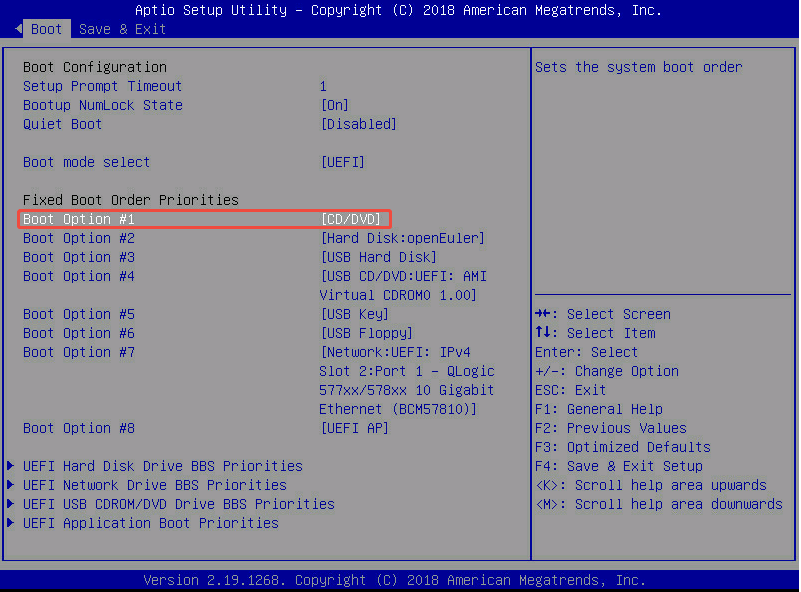
- Save & Exit ——> Save Changes and Reset 保存更改并重启。
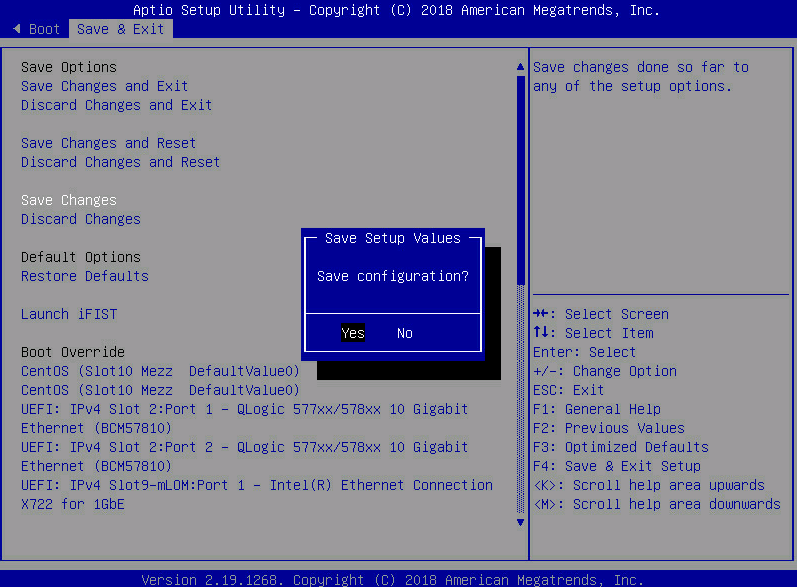
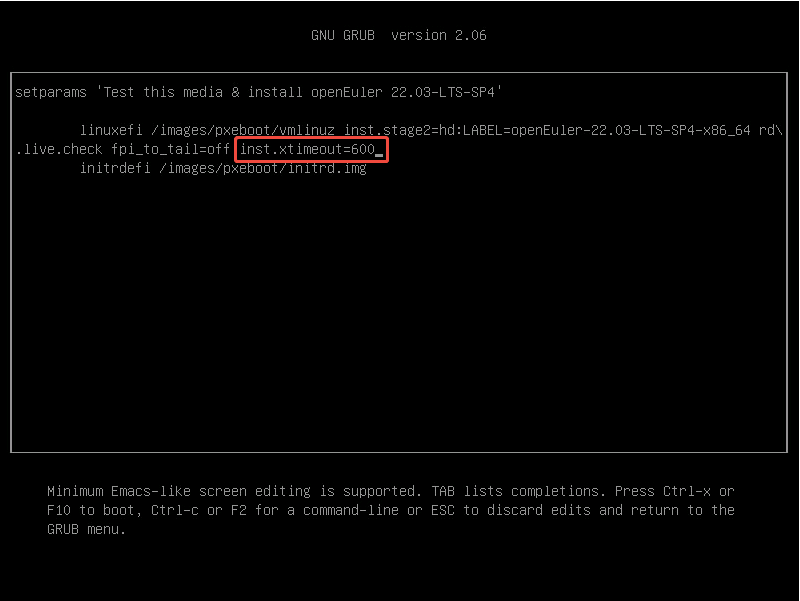
⚠️ 由于互联网连接的速度较慢,图形安装程序可能不可用,根据提示在操作系统引导界面添加“inst.xtimeout=”选项来延长服务器加载时间。在操作系统引导界面按“e”键,在配置文件中添加 inst.xtimeout=600 ,按“Ctrl+x”继续安装,等待服务器加载安装程序,加载完成后即可进入图形化界面。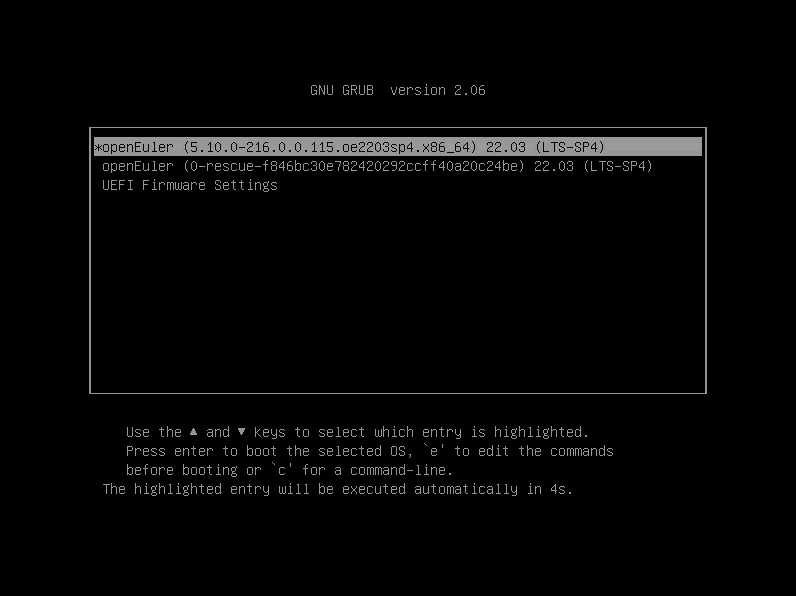
2.4 系统盘分区规划
- 这是一个“总览面板”,汇总了安装系统前需要配置的所有项目。
Installation Destination: 选择系统安装磁盘,因为还没有选择,所以这里显示红色警告。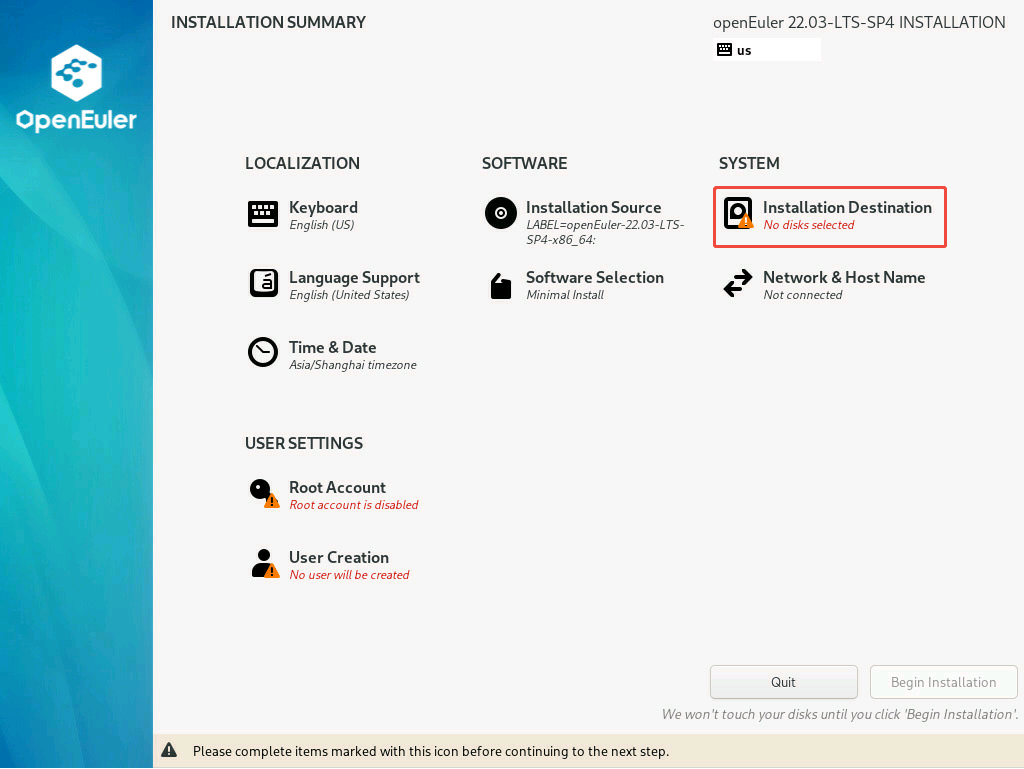
- 选择系统安装磁盘
sda(前面我们做成 RAID 1的两块 557.99GiB 系统盘) ——> Custom(自定义分区)——> Done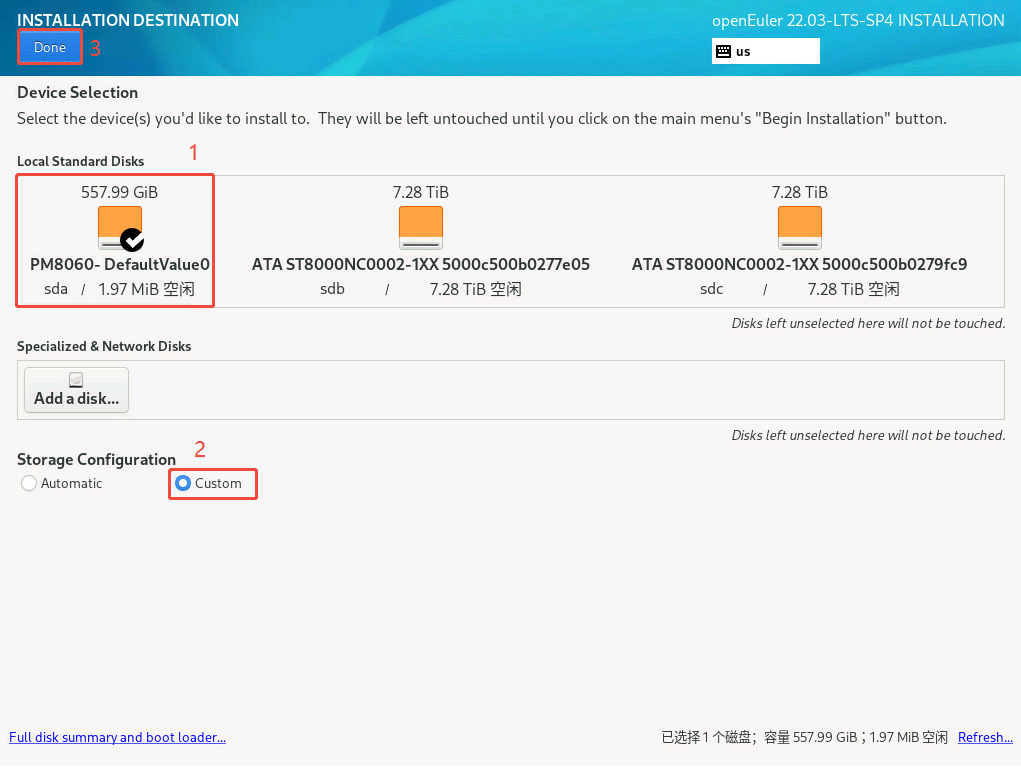
- Click here to create them automatically 单击此处自动创建它们
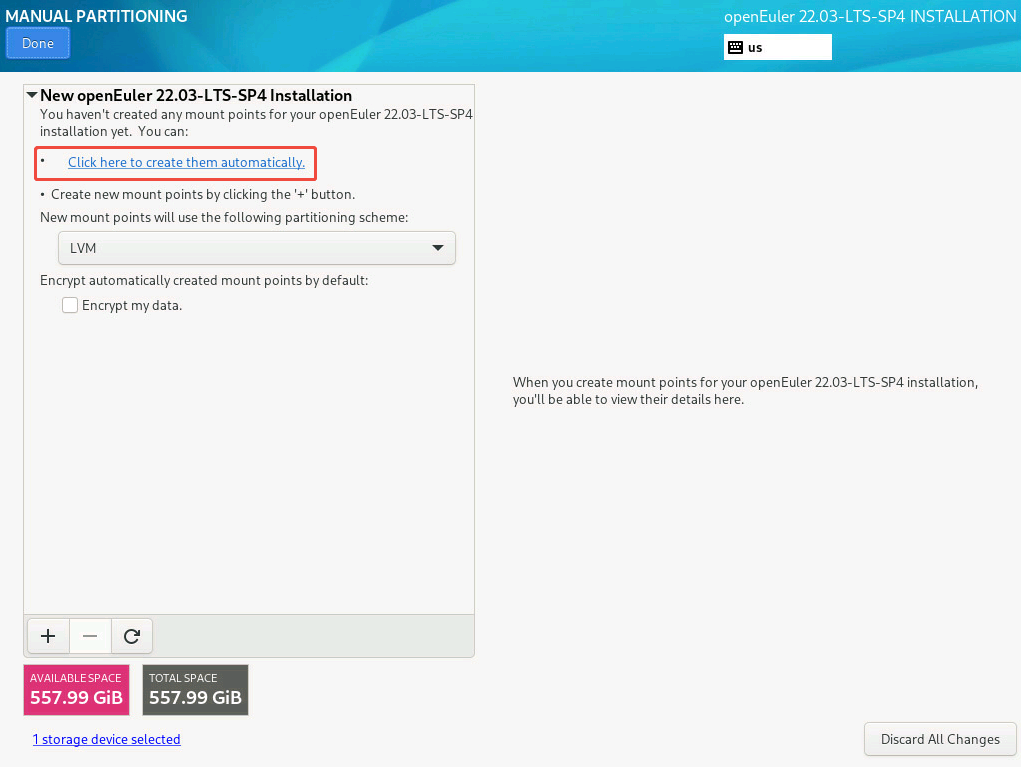
- 创建系统分区 ——> Done
/ 剩余所有空间
/boot/efi 1G
/boot 1G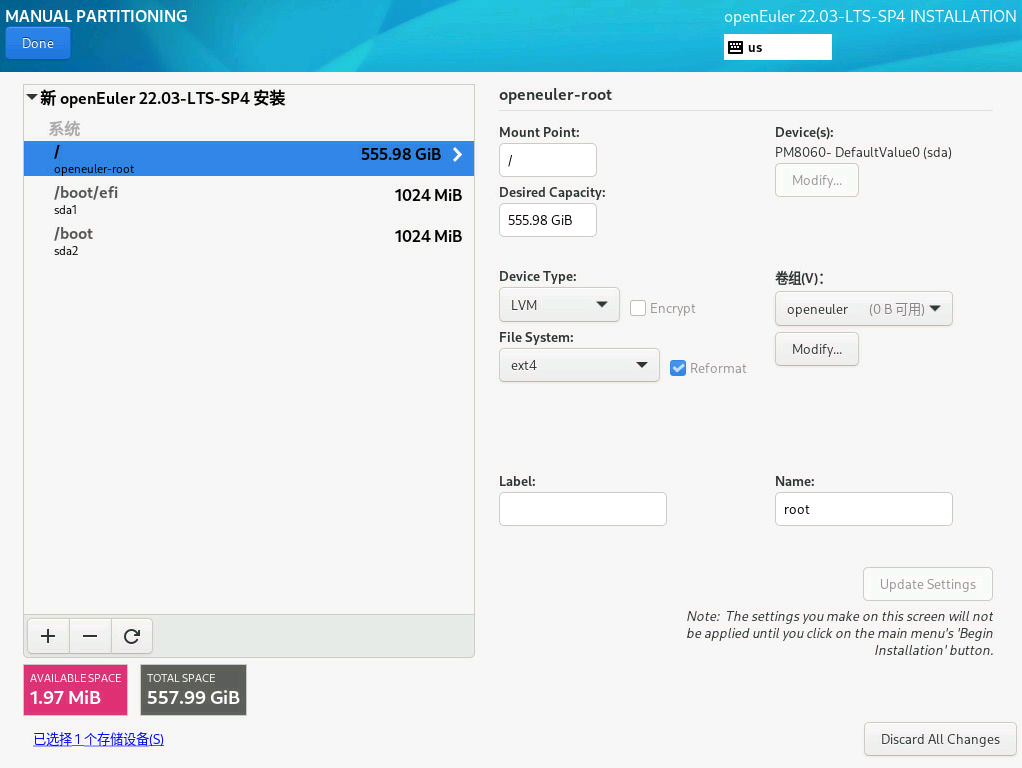
- Reboot System 重启系统
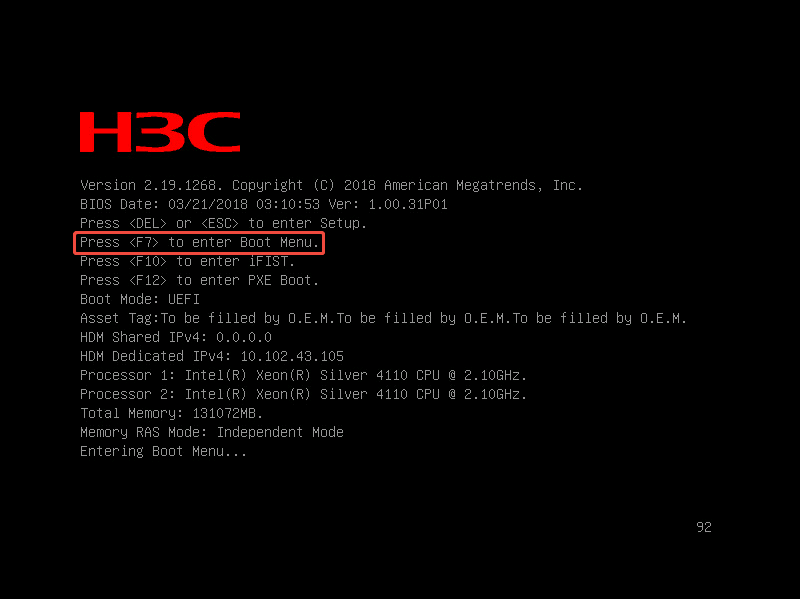
- F7 进入Boot Menu: 临时选一次启动设备(不改永久顺序),到这里系统已经做完了,我们选择新系统启动。
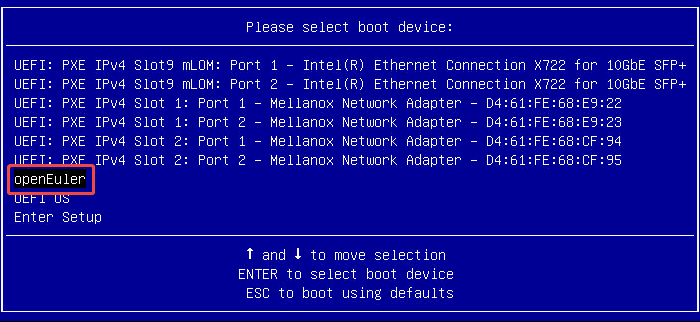
- 选择 openEuler,这个是做好的系统,不要再用cd/dvd了
三、服务器初始化配置
3.1 配置节点网络
- Admin网络
本文采用enp61s0f0和enp61s0f1两个千兆网口做bond0(mode4)用于管理网 - Gateway/Public/Platform网络
本文采用对应系统网卡名称为ens1f0、ens2f0两个万兆网口做bond1(mode4)用于存储前端网 - Cluster网络
本文采用对应系统网卡名称为ens1f1、ens2f1两个万兆网口做bond2(mode4)用于存储后端网
⚠️ 千万不要把同一张网卡上的两个网口绑成一个 bond。因为如果那张网卡整个坏了(比如烧了),两个口就全没了,绑定的链路也就全断了。正确的做法是交叉接线:比如把网卡A的一个口和网卡B的一个口绑在一起,这样坏掉任何一张网卡,都不会断网。给大家画了图参考。
⚠️ 配置IP时,务必保证配置的IP不能和现有IP冲突。
⚠️ 配置文件中不能有中文字符,包括中文的空格和换行等信息,使用cat -A /etc/sysconfig/network-scripts/ifcfg-ethxxx 可以进行确认,ifcfg-ethxxx是特定需要确认的网卡名称。
3.1.1 创建 bond 逻辑接口并配置静态 IP 和静态路由
- bond(网卡绑定):就是把好几块物理网卡在系统里绑成一个逻辑网口。这样其中一块网卡坏了,其他网卡还能继续干活,网络不会断。
- mode 4(LACP 聚合):这个模式下,多根网线可以同时跑数据,带宽叠加,比如两根千兆网口绑一起,理论带宽就是两千兆。不过这个模式需要交换机也配好 LACP。这是数据中心里最常用的聚合方式。
创建 bond0 逻辑接口并配置静态 IP 和静态路由,其中 mode=802.3ad 表示 LACP 聚合模式(mode 4是另一种配置形式),miimon=100 为每 100 毫秒检测链路,lacp_rate=fast 使 LACP 报文每秒发送一次,xmit_hash_policy=layer3+4 基于 IP 和端口哈希实现负载均衡;类似的命令分别创建 bond1(带默认网关)和 bond2(仅 IP),根据你们网络规划配就行。
[root@ceph01 ~]# nmcli connection add type bond ifname bond0 con-name bond0 bond.options "mode=802.3ad,miimon=100,lacp_rate=fast,xmit_hash_policy=layer3+4" ipv4.method manual ipv4.addresses "10.102.43.4/24" ipv4.routes "10.0.8.0/24 10.102.8.254" ipv6.method disabled autoconnect yes
[root@ceph01 ~]# nmcli connection add type bond ifname bond1 con-name bond1 bond.options "mode=802.3ad,miimon=100,lacp_rate=fast,xmit_hash_policy=layer3+4" ipv4.method manual ipv4.addresses "10.102.33.4/24" ipv4.gateway 10.102.33.254 ipv6.method disabled autoconnect yes
[root@ceph01 ~]# nmcli connection add type bond ifname bond2 con-name bond2 bond.options "mode=802.3ad,miimon=100,lacp_rate=fast,xmit_hash_policy=layer3+4" ipv4.method manual ipv4.addresses "10.101.6.4/24" ipv6.method disabled autoconnect yes
3.1.2 将物理网络加入 bond
将物理网口添加为对应 bond 的从属接口,确保冗余和带宽叠加。重启服务时整个系统来完全应用。
[root@ceph01 ~]# nmcli connection add type bond-slave ifname enp61s0f0 master bond0
[root@ceph01 ~]# nmcli connection add type bond-slave ifname enp61s0f1 master bond0
[root@ceph01 ~]# nmcli connection add type bond-slave ifname ens1f0 master bond1
[root@ceph01 ~]# nmcli connection add type bond-slave ifname ens2f0 master bond1
[root@ceph01 ~]# nmcli connection add type bond-slave ifname ens2f1 master bond2
[root@ceph01 ~]# nmcli connection add type bond-slave ifname ens1f1 master bond2
[root@ceph01 ~]# nmcli connection reload
[root@ceph01 ~]# systemctl restart NetworkManager
3.1.3 配置网卡 rx/tx buffer
增大每个物理网卡的接收(rx)和发送(tx)环形缓冲区大小,以减少高流量下的丢包风险(不同网卡硬件最大值可能不同,如 4096 或 4078)。
[root@ceph01 ~]# ethtool -G enp61s0f0 rx 4096 tx 1024
[root@ceph01 ~]# ethtool -G enp61s0f1 rx 4096 tx 1024
[root@ceph01 ~]# ethtool -G ens2f0 rx 4078 tx 1024
[root@ceph01 ~]# ethtool -G ens1f0 rx 4078 tx 1024
[root@ceph01 ~]# ethtool -G ens2f1 rx 4078 tx 1024
[root@ceph01 ~]# ethtool -G ens1f1 rx 4078 tx 1024
3.1.4 检查配置
- 检查网卡和bond聚合关系
通过 nmcli connection show 查看所有连接配置,确认 bond 及其 slave 关系正确。
[root@ceph01 ~]# nmcli connection show
NAME UUID TYPE DEVICE
bond1 3f2d0749-4b59-446c-bb3a-d95a7cf73765 bond bond1
bond0 166acf87-9f98-443f-b046-ba7135bebc2e bond bond0
bond2 a45f9938-0efb-4fd1-9628-f64d32fcf1f7 bond bond2
bond-slave-enp61s0f0 ddc29753-aef6-47d8-b3b3-321386341022 ethernet enp61s0f0
bond-slave-enp61s0f1 7d1a2088-c67e-4fe9-918c-9425953632c8 ethernet enp61s0f1
bond-slave-ens1f0 457c3bb0-229c-4e0e-bea7-d06324530d8e ethernet ens1f0
bond-slave-ens1f1 22e0ee77-c6bd-4ec3-98dc-a060e503a921 ethernet ens1f1
bond-slave-ens2f0 c58b6082-1dcb-4211-b793-4cb8487cc36f ethernet ens2f0
bond-slave-ens2f1 390d1363-1f0d-49d3-a2e7-908006c14f2f ethernet ens2f1
- 检查 bond 速率
使用 ethtool bond0、ethtool bond1、ethtool bond2 检查每个 bond 的聚合速率(如 2000Mb/s 或 20000Mb/s)
[root@ceph01 ~]# ethtool bond0
Speed: 2000Mb/s
[root@ceph01 ~]# ethtool bond1
Speed: 20000Mb/s
[root@ceph01 ~]# ethtool bond2
Speed: 20000Mb/s
- 检查网络通信情况
使用ping命令,确保配置所有IP都可以互通测试节点间的网络连通性。包括管理网、存储前端网、存储后端网络的连通性,保证各个节点的各个网络平面互相可达。并且保证存储部署完成后的网络健壮。
[root@ceph01 ~]# ping 10.102.43.9
64 bytes from 10.102.43.9: icmp_seq=1 ttl=64 time=0.140 ms
1 packets transmitted, 1 received, 0% packet loss, time 0ms
[root@ceph01 ~]# ping 10.102.33.9
1 packets transmitted, 1 received, 0% packet loss, time 0ms
64 bytes from 10.102.33.9: icmp_seq=1 ttl=64 time=0.116 ms
[root@ceph01 ~]# ping 10.101.6.9
64 bytes from 10.101.6.9: icmp_seq=1 ttl=64 time=0.117 ms
1 packets transmitted, 1 received, 0% packet loss, time 0ms
- 检查网卡 rx/tx buffer
遍历所有属于 bond 的物理网口,查看它们的 rx/tx 缓冲区实际值,验证ethtool -G 设置是否生效。
[root@ceph01 ~]# for i in `ip a | grep "master bond" | awk -F":" '{print $2}'`; do ethtool -g $i ; done
3.2 配置节点主机名
集群管理工具(如 Ceph、K8s)依赖主机名来区分节点,重复或默认的 localhost 会导致选举混乱、日志无法追踪
⚠️ 所有节点的主机名需要不一致,不能为localhost、default、maintain
[root@ceph01 ~]# hostnamectl --static set-hostname ceph01
3.3 配置节点 hosts 文件
多分布式软件默认使用主机名通信,配置hosts文件后,节点间可通过主机名互相通信
[root@ceph01 ~]# cat /etc/hosts
10.102.43.4 ceph01
10.102.43.9 ceph02
10.102.43.10 ceph03
[root@ceph01 ~]# scp /etc/hosts root@ceph02:/etc
[root@ceph01 ~]# scp /etc/hosts root@ceph03:/etc
3.4 配置防火墙和 SELinux
3.4.1 配置防火墙和 iptables
分布式存储需要大量自定义端口(如 Ceph 的 3300、6789、6800-7300 等),开放所有端口远比逐条加规则简单可靠。
[root@ceph01 ~]# systemctl stop firewalld
[root@ceph01 ~]# systemctl disable firewalld
[root@ceph01 ~]# systemctl stop iptables
[root@ceph01 ~]# systemctl disable iptables
[root@ceph01 ~]# systemctl status firewalld.service
Active: inactive (dead)
[root@ceph01 ~]# systemctl is-enabled firewalld.service
disabled
[root@ceph01 ~]# systemctl status iptables.service
Active: inactive (dead)
[root@ceph01 ~]# systemctl is-enabled iptables.service
disabled
3.4.2 配置 SElinux
SELinux 会严格限制进程对文件、网络、设备的访问。Ceph 等存储软件涉及大量自定义路径和 socket 文件,很容易触发 SELinux 拒绝访问,导致 OSD 无法启动、mon 无法通信。SELinux 配置需要重启生效。
[root@ceph01 ~]# setenforce 0
[root@ceph01 ~]# vi /etc/selinux/config
SELINUX=disabled
[root@ceph01 ~]# reboot
[root@ceph01 ~]# getenforce
Disabled
3.5 配置节点时间同步
- 分布式存储系统(如 Ceph)、数据库集群、容器平台等对时间一致性要求极高。如果各节点时间相差较多,会出现各种奇怪问题。
- 在内部网络搭建一个 NTP 服务器,让其他节点同步它,可以保证整个集群内完全一致。这里我们将 ceph01 设置成NTP服务器,ceph01 用本地时间,ceph02、ceph03 同步它的时间。
3.5.1 Server 端配置
[root@ceph01 ~]# yum -y install chrony
[root@ceph01 ~]# vi /etc/chrony.conf
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
ntpdumpdir /var/lib/chrony
logdir /var/log/chrony
local stratum 10
allow 10.102.43.0/24 #管理网段
[root@ceph01 ~]# systemctl restart chronyd
[root@ceph01 ~]# systemctl enable chronyd
[root@ceph01 ~]# hwclock --systohc //同步时间到主板
3.5.2 Client 端配置
[root@ceph02 ~]# vi /etc/chrony.conf
server 10.102.43.4 iburst
[root@ceph02 ~]# systemctl restart chronyd
[root@ceph02 ~]# systemctl enable chronyd
[root@ceph01 ~]# hwclock --systohc //同步时间到主板
[root@ceph03 ~]# vi /etc/chrony.conf
server 10.102.43.4 iburst
[root@ceph03 ~]# systemctl restart chronyd
[root@ceph03 ~]# systemctl enable chronyd
[root@ceph01 ~]# hwclock --systohc //同步时间到主板
3.5.3 检查配置
^* 代表正常
[root@ceph02 ~]# chronyc sources -v
===============================================================================
^* ceph01 10 6 377 33 +4523ns[ -960ns] +/- 31us
[root@ceph02 ~]# timedatectl
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes
NTP service: active
[root@ceph03 ~]# chronyc sources -v
===============================================================================
^* ceph01 10 6 377 33 +4523ns[ -960ns] +/- 31us
[root@ceph03 ~]# timedatectl
Time zone: Asia/Shanghai (CST, +0800)
System clock synchronized: yes
NTP service: active
3.6 配置 ssh 免密
该操作需要在作为“监控角色”(通常也为管理角色节点)的服务器上执行。
[root@ceph01 ~]# ssh-keygen
[root@ceph01 ~]# ssh-copy-id root@ceph01
[root@ceph01 ~]# ssh-copy-id root@ceph02
[root@ceph01 ~]# ssh-copy-id root@ceph03
[root@ceph01 ~]# ssh root@ceph01
[root@ceph01 ~]# ssh root@ceph02
[root@ceph01 ~]# ssh root@ceph03
四、RAID 卡和硬盘配置
4.1 配置数据盘为直通盘
💡 原生 Ceph 常把数据盘设成 JBOD 或 RAW,本质上是为了让每块盘以最原始、最透明的方式直接交给 Ceph 管理,避免 RAID 卡再额外做 RAID、缓存、I/O 重排和状态隐藏,这样 Ceph 才能准确感知磁盘真实状态、正确控制刷盘语义和故障恢复,也更符合 OSD/BlueStore 由上层软件自己负责数据保护与一致性的设计思路。
💡 如果不做成直通盘,而是先让 RAID 卡把数据盘做成逻辑盘再交给 Ceph,那么 RAID 卡就会把底层磁盘的很多真实信息和行为包起来,比如缓存、刷盘时机、故障状态、重建过程和 I/O 调度,这样 Ceph 看到的就不再是“真实磁盘”,而是“RAID 卡加工后的设备”,结果就是 Ceph 对磁盘健康、性能瓶颈和故障恢复的判断会变得不准确,轻则性能不可预期、排障困难,重则在掉电、盘故障或重建场景下影响一致性语义和恢复效率,所以这等于让 RAID 卡和 Ceph 同时管理同一层存储逻辑,职责重叠且容易互相干扰。
4.1.1 PMC RAID卡
[root@ceph01 ~]# for i in {8..32}; do arcconf uninit 1 0 $i; done //{8..32} 是 Physical ID
[root@ceph01 ~]# arcconf list 1
Physical 0,8 : Raw (Pass Through) (SATA, 512 Bytes, 7630885MB, ATA, ST8000NC0002-1XX, Hard Drive) 5000C500B03D17E2, [Enclosure 0, Slot 0(Connector 0, Connector 1)]
Physical 0,9 : Raw (Pass Through) (SATA, 512 Bytes, 7630885MB, ATA, ST8000NC0002-1XX, Hard Drive) 5000C500B03A16F2, [Enclosure 0, Slot 1(Connector 0, Connector 1)]
Physical 0,10 : Raw (Pass Through) (SATA, 512 Bytes, 7630885MB, ATA, ST8000NC0002-1XX, Hard Drive) 5000C500B0393AA8, [Enclosure 0, Slot 2(Connector 0, Connector 1)]
Physical 0,11 : Raw (Pass Through) (SATA, 512 Bytes, 7630885MB, ATA, ST8000NC0002-1XX, Hard Drive) 5000C500B03A4856, [Enclosure 0, Slot 3(Connector 0, Connector 1)]
Physical 0,12 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB41563F, [Enclosure 0, Slot 4(Connector 0, Connector 1)]
Physical 0,13 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB41333F, [Enclosure 0, Slot 5(Connector 0, Connector 1)]
Physical 0,14 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB52483F, [Enclosure 0, Slot 6(Connector 0, Connector 1)]
Physical 0,15 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB41933F, [Enclosure 0, Slot 7(Connector 0, Connector 1)]
Physical 0,16 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB41543F, [Enclosure 0, Slot 8(Connector 0, Connector 1)]
Physical 0,17 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB41313F, [Enclosure 0, Slot 9(Connector 0, Connector 1)]
Physical 0,18 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB41373F, [Enclosure 0, Slot 10(Connector 0, Connector 1)]
Physical 0,19 : Raw (Pass Through) (SATA, 512 Bytes, 1831420MB, ATA, INTEL SSDSC2KB01, Solid State Drive) 00000000BB412B3F, [Enclosure 0, Slot 11(Connector 0, Connector 1)]
Physical 0,31 : Raw (Pass Through) (SATA, 512 Bytes, 7630885MB, ATA, ST8000NC0002-1XX, Hard Drive) 5000C500B028A589, [Enclosure 0, Slot 23(Connector 0, Connector 1)]
Physical 0,32 : Raw (Pass Through) (SATA, 512 Bytes, 7630885MB, ATA, ST8000NC0002-1XX, Hard Drive) 5000C500B039D769, [Enclosure 0, Slot 24(Connector 0, Connector 1)]
Physical 0,36 : Online (SAS, 512 Bytes, 572325MB, HGST, HUC101860CSS200, Hard Drive) 5000CCA07D4D29B3, [Enclosure 0, Slot 28(Connector 0, Connector 1)]
Physical 0,37 : Online (SAS, 512 Bytes, 572325MB, HGST, HUC101860CSS200, Hard Drive) 5000CCA07D4D336B, [Enclosure 0, Slot 29(Connector 0, Connector 1)]
Physical 2,0 : Ready (SES2, Not Applicable, Not Applicable, H3C-Exp, SXP 36x12G, Enclosure Services Device) 588DF9E5E650F07E, []
4.1.2 LSI RAID卡
[root@LSI ~]# for i in {0..11}; do storcli /c0/e64/s$i set jbod; done
----------------------------------------------------------------------------------
EID:Slt DID State DG Size Intf Med SED PI SeSz Model Sp Type
----------------------------------------------------------------------------------
64:0 2 JBOD - 1.746 TB SATA SSD N N 512B INTEL SSDSC2KB019T8 U -
64:1 3 JBOD - 1.746 TB SATA SSD N N 512B INTEL SSDSC2KB019T8 U -
64:2 12 JBOD - 3.492 TB SATA SSD N N 512B INTEL SSDSC2KB038T8 U -
64:3 10 JBOD - 7.277 TB SATA HDD N N 512B ST8000NC0002-1XX112 U -
64:4 4 JBOD - 7.277 TB SATA HDD N N 512B HGST HUS728T8TALE6L4 U -
64:5 13 JBOD - 3.492 TB SATA SSD N N 512B INTEL SSDSC2KB038T8 U -
64:6 16 JBOD - 7.277 TB SATA HDD N N 512B HGST HUS728T8TALE6L4 U -
64:7 8 JBOD - 3.492 TB SATA SSD N N 512B INTEL SSDSC2KB038T8 U -
64:8 14 JBOD - 3.492 TB SATA SSD N N 512B INTEL SSDSC2KB038T8 U -
64:9 7 JBOD - 7.277 TB SATA HDD N N 512B ST8000NC0002-1XX112 U -
64:10 17 JBOD - 3.492 TB SATA SSD N N 512B INTEL SSDSC2KB038T8 U -
64:11 15 JBOD - 3.492 TB SATA SSD N N 512B INTEL SSDSC2KB038T8 U -
64:28 1 Onln 0 446.625 GB SATA SSD N N 512B INTEL SSDSC2KG480G8 U -
64:29 0 Onln 0 446.625 GB SATA SSD N N 512B INTEL SSDSC2KG480G8 U -
----------------------------------------------------------------------------------
4.2 配置逻辑盘控制器缓存(RAID卡层面)
💡 先介绍下逻辑盘控制器缓存有哪些:
wt:write through- 主机发来的写请求,必须真正写到底层磁盘后,RAID 控制器才向操作系统返回“写完成”。也就是说,写 I/O 的完成点在磁盘上,不在控制器缓存里。这种模式最保守、最稳,掉电时风险最低,因为主机看到“写成功”时,数据通常已经真的落盘了。它的代价就是性能偏慢,尤其是 HDD 场景下,小块随机写时延会更高,所以一般用于更重视稳定性的场景,或者 SSD 系统盘这类本身介质已经够快、不需要依赖控制器写缓存提速的场景。
wb:write back- 主机发来的写请求,先写进 RAID 控制器缓存,只要进入缓存,控制器就先向操作系统返回“写完成”,后面再异步刷到底层磁盘。也就是说,写 I/O 的完成点在控制器缓存里,而不是磁盘上。这样做的好处是写性能会明显提升,特别是 HDD 场景下,小块随机写和突发写入会快很多,因为控制器可以先把零散写入收进缓存,再慢慢整理后刷盘。但它的风险也最大,如果数据还在缓存里、还没落盘时突然掉电或控制器故障,就可能丢数据,所以 wb 本质上是用更高性能换更高风险,通常不建议直接用于强调安全性的生产系统盘。
wbb:write back with battery/ZMM- 本质上还是写回缓存,但它比 wb 多了一层前提:只有在 RAID 卡的 BBU、电池、超级电容或者 ZMM 状态正常时,才允许启用写回;如果保护模块不存在、状态异常或者没 ready,控制器就会自动关闭写回,避免缓存里的数据在异常断电时丢失。它的核心思路就是“有掉电保护时才享受写回性能,没有保护时就自动回到更安全的模式”,所以它兼顾了性能和安全,是生产环境里最常见、也最推荐的 HDD 系统盘写缓存策略。
roff:read cache off- 关闭 RAID 控制器对这个逻辑盘的读缓存,也就是控制器不会专门把最近读过的数据留在自己的缓存里,后续读请求更多还是直接去底层磁盘或 SSD 取数据。这样做的好处是 I/O 路径更简单、行为更可预期,也不会占用控制器缓存资源。对于 SSD 来说,由于 SSD 本身随机读延迟已经很低,RAID 卡再加一层读缓存的收益通常不大,所以系统盘如果是 SSD,常见做法就是 roff,避免多一层意义不大的缓存逻辑。
ron:read cache on- 开启 RAID 控制器对这个逻辑盘的读缓存,控制器会把最近读过的一部分数据暂时放在自己的缓存里;如果后面又读到同一块数据,或者读到附近的热点数据,就有机会直接从缓存返回,而不必再次访问底层磁盘。它利用的是热点数据重复访问这个特性,所以对 HDD 尤其有价值,因为机械盘最慢的地方就是寻道和旋转等待,能少读一次底层盘,时延就可能明显降低。因此 ron 更适合 HDD 系统盘这类会频繁读取启动文件、目录、元数据和小文件的场景,用它的目的就是尽量减少机械盘重复读带来的开销。
口诀:逻辑盘是 SSD 时,读写缓存都关闭,逻辑盘是 HDD 读写缓存都开启。 考虑到大家环境都不一样,以下有主流 RAID 卡配置方法,供参考:
4.2.1 PMC RAID 卡
[root@PMC ~]# arcconf setcache 1 logicaldrive -h
Usage: SETCACHE <Controller#> LOGICALDRIVE <LogicalDrive#> <logical mode> [noprompt] [nologs]
Usage: SETCACHE <Controller#> DEVICE <Channel# ID#> <physical mode> [nologs]
Usage: SETCACHE <Controller#> DEVICEALL <policy> [noprompt] [nologs]
Example: SETCACHE 1 LOGICALDRIVE 0 ron
Example: SETCACHE 1 DEVICE 0 0 wt
Example: SETCACHE 1 DEVICEALL drivespecific
===================================================================================
Changes a device's cache mode.
LOGICALDRIVE parameters
LogicalDrive# : Number of the logical device whose cache will be altered
Logical Modes : ron - read cache enabled
roff - read cache disabled
wt - write through
wb - write back
wbb - write back with battery/ZMM
con - cache enabled
coff - cache disabled
DEVICE parameters
Channel# ID# : Channel and ID of the device whose cache will be altered
Physical Modes : wt - write through
wb - write back
DEVICEALL parameters
Policy : enable - write back for all physical drives
disable - write through for all physical drives
drivespecific - user can set for an individual physical drive
4.2.2 LSI RAID 卡
[root@LSI ~]# storcli /c0/v0 set -h
storcli /cx/vx set wrcache=WT|WB|AWB
storcli /cx/vx set rdcache=RA|NoRA
我这里系统盘是 HDD 的,所以我这样配置:
[root@ceph01 ~]# arcconf getconfig 1 ld //先查一下系统盘的 Logical Device number,这里是0
Logical Device number 0
[root@ceph01 ~]# arcconf setcache 1 logicaldrive 0 ron
[root@ceph01 ~]# arcconf setcache 1 logicaldrive 0 wbb
[root@ceph01 ~]# arcconf getconfig 1 ld
Read-cache setting : Enabled
Write-cache setting : On when protected by battery/ZMM
Segment 0 : Present (572325MB, SAS, HDD, Enclosure:0, Slot:28) 0BHBEJUH
Segment 1 : Present (572325MB, SAS, HDD, Enclosure:0, Slot:29) 0BHBG5WH
4.3 配置 JBOD 物理盘的磁盘写缓存(RAID 卡层面)
控制器是否允许这些 JBOD 物理盘自身的 write cache 开启。
💡 在 Ceph 场景下,如果数据盘以 JBOD、HBA 或直通方式提供给操作系统使用,原则上不建议让 RAID 卡控制器缓存参与这些数据盘的读写路径。 直通盘的设计目的,就是让磁盘尽可能以原始设备形态暴露给 Ceph,由 Ceph 自身负责副本、一致性、刷盘语义、恢复和故障处理;如果 RAID 卡再额外对这些盘进行读缓存、写回缓存、I/O 重排或延迟落盘,就会在主机和磁盘之间增加一层 Ceph 无法感知和控制的缓存语义,轻则影响性能判断,重则影响故障场景下的数据一致性和恢复行为。因此,对于 Ceph 的直通数据盘,RAID 卡应尽量工作在“转发”而不是“加速”的角色上,也就是尽量不使用面向逻辑盘的 WT/WB/AWB、ron/roff 这类缓存策略;这些策略更适合系统盘所在的 RAID 逻辑盘,而不适合 OSD 数据盘。实际配置时,应优先将 Ceph 数据盘设置为 JBOD/HBA/Pass-through 模式,不给数据盘做传统 RAID,也不依赖 RAID 卡控制器缓存提升 OSD 性能;如果控制器支持针对物理盘的缓存开关,则对 HDD 数据盘通常建议关闭物理盘写缓存,避免底层盘在未真正落盘前就向上层过早确认写完成。企业级 SSD 数据盘/DB/WAL 盘:如果有完善掉电保护,可以按厂商建议决定;保守做法仍是先关,验证后再开。
4.3.1 PMC RAID 卡
这张 PMC 卡支持控制器侧统一配置物理盘写缓存策略,包括这种 Raw (Pass Through) 直通盘。
[root@ceph01 ~]# arcconf setcache 1 deviceall enable|disable noprompt
[root@ceph01 ~]# arcconf getconfig 1 pd | grep "Write Cache"
Write Cache : Disabled (write-through)
4.3.2 LSI RAID 卡
这张 LSI 卡不支持 JBOD Write cache 这个控制器级功能。
[root@LSI ~]# storcli /c0 show all | grep -i cache
Support JBOD Write cache = No
[root@LSI ~]# storcli /c0 set jbodwritecache=on|off //如果支持,执行这条命令控制
4.4 配置硬盘自身缓存(硬盘层面)
💡 企业级 SSD 通常具备掉电保护能力(PLP),即使开启硬盘自身写缓存,缓存中的数据在异常断电时也有较大概率被安全落盘,因此既能获得更低的写时延和更好的写性能,又不会明显增加数据风险;而机械硬盘的自身写缓存大多属于易失性缓存,通常缺少可靠的掉电保护,一旦意外断电,尚未来得及落盘的缓存数据就可能丢失,因此在对数据一致性要求较高的场景下,通常建议开启企业级 SSD 的自身缓存,而关闭 HDD 的自身缓存。
💡 需要修改的三个地方(确保设备真实状态和内核视图对齐)
- sdparm --get/–set WCE /dev/sdX:这是设备真实状态,改的是磁盘自己的 WCE 位。它最接近“这块盘到底有没有开自身写缓存”。真正决定硬盘自己有没有开缓存的,是 WCE。
- /sys/class/scsi_disk/…/cache_type:这是 SCSI 磁盘驱动层的接口。官方文档说明它能直接开关 drive write/read cache,write back 对应 WCE=1,write through 对应 WCE=0;写 temporary … 表示只临时生效。真正让 Linux/SCSI 层按这个模式工作的,是 cache_type。
- /sys/block/sdX/queue/write_cache:这是 Linux block 层的视图。官方文档特别说明了,写这个文件只会改变内核对设备的看法,不会改变设备真实状态。必须和前两层保持一致。
因为内核会根据它判断这块盘是不是 write back 设备,进而决定 flush / FUA 语义怎么处理。
如果这里显示 write through,但设备实际 WCE=1,就会出现“盘其实有易失性缓存,但内核以为没有”的危险不一致。
4.4.1 安装 sdparm 工具
后面用它直接读写磁盘的 WCE(Write Cache Enable,写缓存开关)参数。
[root@ceph01 ~]# dnf install -y sdparm //先装工具
4.4.2 创建配置脚本
[root@ceph01 ~]# cat >/usr/local/sbin/set-disk-write-cache.sh <<'EOF'
1 #!/bin/bash
2 set -u
3
4 # 不想动的盘写在这里,比如系统盘:SKIP_DEVICES="sda"
5 SKIP_DEVICES="sda"
6
7 for sysdev in /sys/block/sd*; do
8 dev=$(basename "$sysdev")
9
10 case " $SKIP_DEVICES " in
11 *" $dev "*) continue ;;
12 esac
13
14 [ -b "/dev/$dev" ] || continue
15
16 rota=$(cat "$sysdev/queue/rotational")
17 scsi=$(basename "$(readlink -f "$sysdev/device")")
18 cache_file="/sys/class/scsi_disk/$scsi/cache_type"
19
20 if [ "$rota" = "1" ]; then
21 [ -w "$cache_file" ] && echo "temporary write through" > "$cache_file" || true
22 command -v sdparm >/dev/null 2>&1 && sdparm --clear=WCE "/dev/$dev" >/dev/null 2>&1 || true
23 else
24 [ -w "$cache_file" ] && echo "temporary write back" > "$cache_file" || true
25 command -v sdparm >/dev/null 2>&1 && sdparm --set=WCE "/dev/$dev" >/dev/null 2>&1 || true
26 fi
27 done
EOF
[root@ceph01 ~]# chmod 755 /usr/local/sbin/set-disk-write-cache.sh
4.4.3 创建 systemd 服务
前面脚本里很多设置是运行时生效,机器重启后可能丢失,用 systemd 就能保证每次开机自动重新套用策略。
[root@ceph01 ~]# cat >/etc/systemd/system/disk-write-cache.service <<'EOF'
[Unit]
Description=Set disk write cache policy by media type
After=systemd-udev-settle.service
Wants=systemd-udev-settle.service
[Service]
Type=oneshot
ExecStart=/usr/local/sbin/set-disk-write-cache.sh
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
EOF
4.4.4 启用 systemd 服务并立即执行
[root@ceph01 ~]# systemctl daemon-reload
[root@ceph01 ~]# systemctl enable --now disk-write-cache.service
[root@ceph01 ~]# systemctl status disk-write-cache.service
4.4.5 检查配置
- SSD 硬盘:写缓存打开(write back)
[root@ceph01 ~]# lsblk -d -o NAME,ROTA
NAME ROTA
sde 0
[root@ceph01 ~]# cat /sys/block/sde/queue/write_cache
write back
[root@ceph01 ~]# ls -d /sys/class/scsi_disk/*/device/block/sde
/sys/class/scsi_disk/0:1:12:0/device/block/sde
[root@ceph01 ~]# cat /sys/class/scsi_disk/0:1:12:0/cache_type
write back
[root@ceph01 ~]# sdparm --get=WCE /dev/sdf
/dev/sdf: ATA ST8000NC0002-1XX CN02
WCE 0 [cha: y, def: 0, sav: 0]
- HDD 硬盘:写缓存关闭(write through)
[root@ceph01 ~]# lsblk -d -o NAME,ROTA
NAME ROTA
sdf 1
[root@ceph01 ~]# cat /sys/block/sdf/queue/write_cache
write through
[root@ceph01 ~]# ls -d /sys/class/scsi_disk/*/device/block/sdf
/sys/class/scsi_disk/0:1:11:0/device/block/sdf
[root@ceph01 ~]# cat /sys/class/scsi_disk/0:1:11:0/cache_type
write through
[root@ceph01 ~]# sdparm --get=WCE /dev/sde
/dev/sde: ATA INTEL SSDSC2KB01 0142
WCE 1 [cha: y, def: 1, sav: 1]
好了,到这里我们就配置完成了,如果大家对 Ceph 部署感兴趣,可以去看我的另一篇博客。
二、Ceph 开局指导手册之存储集群配置篇(BuleStore data与db分离部署+Bcache)
https://blog.csdn.net/lss0516/article/details/161694126?spm=1011.2415.3001.5331

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)