二、Ceph 开局指导手册之存储集群配置篇(BuleStore data与db分离部署+Bcache)
文章目录
如果大家对服务器初始化感兴趣,也可以先看这篇文章
一、Ceph 开局指导手册之服务器初始化配置篇
https://blog.csdn.net/lss0516/article/details/161828899?spm=1011.2415.3001.5331
前言
Ceph 作为一款开源的分布式存储系统,以其高可靠性、高扩展性和高性能的特点,在云计算、大数据等领域得到了广泛应用。然而,Ceph 的部署与配置过程相对复杂,涉及操作系统配置、网络设置、硬件优化等多个环节,对于初学者和运维人员来说具有一定的挑战性。
本文旨在提供一份详细的 Ceph 集群部署与操作指南,从最基础的环境准备开始,逐步讲解 Ceph 的安装、配置、优化及基本使用。文章内容基于实际生产环境经验,涵盖了从Ceph 集群部署、rbd 块设备操作的全流程,并提供了大量的命令行示例和配置说明。
本文适合的读者:
- 对 Ceph 有一定了解,但缺乏实际部署经验的运维人员
- 需要搭建 Ceph 集群进行测试或生产的系统管理员
- 希望深入学习 Ceph 部署细节的技术爱好者
通过阅读本文,您将能够:
- 掌握 Ceph 集群部署前的系统环境配置要点
- 理解 Ceph 各组件(mon、mgr、osd)的部署流程
- 学会使用 rbd 创建和管理块存储设备
- 了解 Ceph 性能调优的基本方法
文章结构清晰,按照实际操作流程分为环境说明、安装部署前配置、Ceph 开局部署、rbd 基本操作等几个主要部分,每个部分都配有详细的步骤说明和代码示例,方便读者按步骤实践。
让我们开始 Ceph 的部署之旅吧!
一、创建管理和监控节点
1.1 安装 Ceph 软件
以下操作三台节点都要执行,这里我拿第一台举例!!!
我的包用的是 OpenEuler 系统自带的,如果你们的机器不通外网,可以用挂载镜像,做个本地 Yum,或者去 OpenEuler Repo 找一下。https://dl-cdn.openeuler.openatom.cn/openEuler-22.03-LTS-SP4/update/x86_64/Packages/
[root@ceph01 ~]# mkdir /mnt/cdrom/iso_mirror //本地Yum配置方法
[root@ceph01 ~]# mount -o loop openEuler-22.03-LTS-SP4-x86_64-dvd.iso /mnt/cdrom/iso_mirror
cat > /etc/yum.repos.d/local.repo <<'EOF'
[local]
name=local
baseurl=file:///mnt/cdrom/iso_mirror
gpgcheck=0
enabled=1
EOF
dnf clean all
dnf makecache
[root@ceph01 ~]# dnf install ceph ceph-common ceph-mon ceph-mgr ceph-osd
1.2 部署 Monitor
1.2.1 在 ceph01 生成集群配置
- mkdir -p /etc/ceph 是创建 Ceph 配置目录。
- FSID=$(uuidgen) 是生成集群唯一 ID,后面所有节点都必须属于同一个 fsid,否则它们不会被当成同一套集群。
- ceph.conf 里这几个参数是启动集群最关键的全局配置。
- mon initial members 指定初始 monitor 的主机名,解决第一次组集群时“谁是第一批 mon”的问题;
- mon host 指定 monitor 的地址,客户端和其他 daemon 靠它找到集群;
- public_network 指定前端通信网段;
- auth_* = cephx 是强制启用 Ceph 的认证机制;
- osd_pool_default_size = 3 和 osd_pool_default_min_size = 2 表示默认三副本、最少保留两副本才允许继续 I/O;
- osd_crush_chooseleaf_type = 1 表示副本按 host 级别分散,避免同一对象的多个副本落在同一台主机上。这些配置本质上是在定义这套集群的“身份、入口地址、认证方式和默认冗余策略”。
[root@ceph01 ~]# mkdir -p /etc/ceph
[root@ceph01 ~]# FSID=$(uuidgen)
[root@ceph01 ~]# echo $FSID
[root@ceph01 ~]# cat >/etc/ceph/ceph.conf <<EOF
[global]
fsid = $FSID
mon initial members = ceph01,ceph02,ceph03
mon host = 10.102.33.4,10.102.33.9,10.102.33.10
public_network = 10.102.33.0/24
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd_pool_default_size = 3
osd_pool_default_min_size = 2
osd_crush_chooseleaf_type = 1
EOF
1.2.2 在 ceph01 生成 mon key、admin key、monmap
[root@ceph01 ~]# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
[root@ceph01 ~]# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring \
--gen-key -n client.admin \
--cap mon 'allow *' \
--cap osd 'allow *' \
--cap mds 'allow *' \
--cap mgr 'allow *'
[root@ceph01 ~]# ceph-authtool /tmp/ceph.mon.keyring \
--import-keyring /etc/ceph/ceph.client.admin.keyring
[root@ceph01 ~]# monmaptool --create \
--add ceph01 10.102.33.4 \
--add ceph02 10.102.33.9 \
--add ceph03 10.102.33.10 \
--fsid $FSID /tmp/monmap
1.2.3 从 ceph01 分发到 ceph02/ceph03
scp /etc/ceph/ceph.conf、scp ceph.client.admin.keyring、scp /tmp/ceph.mon.keyring、scp /tmp/monmap 的作用,就是让 ceph02、ceph03 拿到和 ceph01 一致的配置和引导材料。因为三台 monitor 必须基于同一个 fsid、同一个 monmap、同一套认证体系启动,否则它们不会形成一个 quorum。这里分发的是“启动种子”,不是随便同步文件。
[root@ceph01 ~]# for h in ceph02 ceph03; do
ssh $h "mkdir -p /etc/ceph"
scp /etc/ceph/ceph.conf root@$h:/etc/ceph/
scp /etc/ceph/ceph.client.admin.keyring root@$h:/etc/ceph/
scp /tmp/ceph.mon.keyring root@$h:/tmp/
scp /tmp/monmap root@$h:/tmp/
done
1.2.4 mon mkfs
以下操作三台节点都要执行,这里我拿第一台举例!!!
- mkdir -p /var/lib/ceph/mon/ceph-ceph01 是创建 monitor 的本地数据目录,monitor 的状态、map、auth 数据最终都放在这里。chown -R ceph:ceph、chmod 的原因很直接:ceph-mon 实际是以 ceph 用户运行的,所以它必须能读 monmap 和 keyring,也必须能写自己的数据目录。
- ceph-mon --mkfs -i ceph01 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring 的本质是“初始化 monitor 文件系统”,把 monitor 身份、集群 fsid、初始 monmap 和 auth 数据写进本地 mon store。只有做完这一步,这个节点才算真正具备了当 mon.ceph01 的资格。
[root@ceph01 ~]# mkdir -p /var/lib/ceph/mon/ceph-ceph01
[root@ceph01 ~]# chown -R ceph:ceph /var/lib/ceph/mon/ceph-ceph01
[root@ceph01 ~]# chown ceph:ceph /tmp/ceph.mon.keyring /tmp/monmap
[root@ceph01 ~]# chmod 600 /tmp/ceph.mon.keyring
[root@ceph01 ~]# chmod 644 /tmp/monmap
[root@ceph01 ~]# sudo -u ceph ceph-mon --mkfs -i ceph01 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
1.2.5 启动 Monitor
以下操作三台节点都要执行,这里我拿第一台举例!!!
systemctl enable --now ceph-mon@ceph01 是把 ceph01 这个 monitor 作为 systemd 实例服务启动并设置开机自启。三台都启动后,ceph -s 和 ceph mon stat 用来确认是否形成 quorum。quorum ceph01,ceph02,ceph03 说明 3 个 mon 已经互相看见并完成选举。
[root@ceph01 ~]# systemctl enable --now ceph-mon@ceph01
[root@ceph01 ~]# ceph -s
cluster:
id: 3c9c2a6d-0c72-437a-b5cf-5b9e66fc461d
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
- 这里两条后续配置要补充一下:ceph mon enable-msgr2 是集群级配置,从任意一个管理节点执行一次就行,不需要三台都各执行一遍;它的作用是给 monitor 增加 msgr2 地址,消除 3 monitors have not enabled msgr2 告警。
- ceph config set mon auth_allow_insecure_global_id_reclaim false 也是集群级配置,目的是关闭兼容旧客户端的 insecure global_id reclaim,消除安全告警;也是执行一次即可。之所以建议这样配,是因为 Pacific 默认更推荐启用 msgr2 并关闭旧式不安全兼容行为。
[root@ceph01 ~]# ceph mon stat
e1: 3 mons at {ceph01=v1:10.102.33.4:6789/0,ceph02=v1:10.102.33.9:6789/0,ceph03=v1:10.102.33.10:6789/0}, election epoch 6, leader 0 ceph01, quorum 0,1,2 ceph01,ceph02,ceph03
[root@ceph01 ~]# ceph mon enable-msgr2 //消除3 monitors have not enabled msgr2告警
[root@ceph01 ~]# ceph config set mon auth_allow_insecure_global_id_reclaim false //消除mons are allowing insecure global_id reclaim
1.3 部署 mgr
1.3.1 在 ceph01 生成 3 个 mgr key
ceph auth get-or-create mgr.ceph01 … 这三条命令是在创建 3 个 manager 实体各自的 key。mgr 不是 mon,但它负责 dashboard、prometheus、orchestrator、性能统计等管理平面能力,现代 Ceph 基本离不开它。之所以给每台单独创建 mgr.ceph01、mgr.ceph02、mgr.ceph03,是因为每个 daemon 都应该有独立身份,便于主备切换、权限隔离和排障。
[root@ceph01 ~]# ceph auth get-or-create mgr.ceph01 mon 'allow profile mgr' osd 'allow *' mds 'allow *' -o /tmp/mgr.ceph01.keyring
[root@ceph01 ~]# ceph auth get-or-create mgr.ceph02 mon 'allow profile mgr' osd 'allow *' mds 'allow *' -o /tmp/mgr.ceph02.keyring
[root@ceph01 ~]# ceph auth get-or-create mgr.ceph03 mon 'allow profile mgr' osd 'allow *' mds 'allow *' -o /tmp/mgr.ceph03.keyring
1.3.2 分发给ceph02、ceph03
[root@ceph01 ~]# scp /tmp/mgr.ceph02.keyring root@ceph02:/tmp/
[root@ceph01 ~]# scp /tmp/mgr.ceph03.keyring root@ceph03:/tmp/
1.3.3 三台创建并启动 mgr
以下操作三台节点都要执行,这里我拿第一台举例!!!
mkdir -p /var/lib/ceph/mgr/ceph-ceph01、复制 keyring、chown -R ceph:ceph,本质上是在给 mgr 准备自己的数据目录和身份凭据。systemctl enable --now ceph-mgr@ceph01 则是把 manager 进程拉起来。
[root@ceph01 ~]# mkdir -p /var/lib/ceph/mgr/ceph-ceph01
[root@ceph01 ~]# cp /tmp/mgr.ceph01.keyring /var/lib/ceph/mgr/ceph-ceph01/keyring
[root@ceph01 ~]# chown -R ceph:ceph /var/lib/ceph/mgr/ceph-ceph01
[root@ceph01 ~]# systemctl enable --now ceph-mgr@ceph01
ceph -s 里看到 mgr: ceph01(active), standbys: ceph02, ceph03 就说明 active/standby 已建立。OSD count 0 < osd_pool_default_size 3 这个告警在还没创建 OSD 时是正常的,因为默认副本数要求是 3,但实际 OSD 还是 0。
[root@ceph01 ~]# ceph -s
cluster:
id: 3c9c2a6d-0c72-437a-b5cf-5b9e66fc461d
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mgr: ceph01(active, since 32s), standbys: ceph02
[root@ceph01 ~]# ceph mgr stat
{
"epoch": 6,
"available": true,
"active_name": "ceph01",
"num_standby": 2
}
1.4 创建 OSD bootstrap key
mkdir -p /var/lib/ceph/bootstrap-osd 和 ceph auth get-or-create client.bootstrap-osd mon ‘profile bootstrap-osd’ -o … 是在准备后面创建 OSD 时用的“引导账号”。它不是管理员账号,而是一个最小权限账号,只允许做 OSD 注册相关动作。后面 ceph-volume lvm create 或 ceph osd new 时,需要先通过这个 key 去向 monitor 申请 OSD ID、注册 OSD 身份、拿到初始认证材料。如果不用这个 bootstrap key,而是直接 everywhere 用 client.admin,虽然也能干活,但权限太大,不符合最小权限原则。所以这里单独准备 client.bootstrap-osd,就是为了把“部署 OSD”这件事的权限收敛到一个更安全的范围。把它分发到 ceph02/ceph03,是因为这三台后面都要本地创建 OSD。
1.4.1 在 ceph01 创建 OSD bootstrap key
[root@ceph01 ~]# mkdir -p /var/lib/ceph/bootstrap-osd
[root@ceph01 ~]# ceph auth get-or-create client.bootstrap-osd mon 'profile bootstrap-osd' -o /var/lib/ceph/bootstrap-osd/ceph.keyring
1.4.2 分发给 ceph02、ceph03
[root@ceph01 ~]# for h in ceph02 ceph03; do
ssh $h "mkdir -p /var/lib/ceph/bootstrap-osd"
scp /var/lib/ceph/bootstrap-osd/ceph.keyring root@$h:/var/lib/ceph/bootstrap-osd/ceph.keyring
done
二、创建 OSD
以下操作三台节点都要执行,这里我拿第一台举例!!!
2.1 创建 SSD 分区
2.1.1 清空数据盘
wipefs -af /dev/… 是先把这些盘上原来的文件系统、LVM、bcache、分区签名全部清掉,避免后面 make-bcache、parted、ceph-volume 因为“盘上有旧元数据”报错。
[root@ceph01 ~]# wipefs -af /dev/sdb /dev/sdc /dev/sdd /dev/sdf /dev/sdn /dev/sdo /dev/sde /dev/sdg
2.1.2 给两块 SSD 硬盘分区
parted -s -a optimal /dev/sde mklabel gpt 是给 SSD 重建 GPT 分区表;mkpart cache 1MiB 1100GiB 是从每块 SSD 里先切出约 1.1T 给 bcache 当缓存区;mkpart db … 是把剩余空间留给 BlueStore 的 block.db。后面再把这块剩余空间细分成 3 个 200G 分区,是因为一块 SSD 要服务 3 个 OSD,每个 OSD 单独给一个 block.db 分区,管理更清晰,故障隔离也更好。之所以每个 block.db 给 200G,是因为 8T HDD 对应 200G 大约占 2.4%,落在 Ceph 官方常见建议的 1% 到 4% 区间里,通常能兼顾 RocksDB 性能和 SSD 空间利用率。
[root@ceph01 ~]# parted -s -a optimal /dev/sde mklabel gpt
[root@ceph01 ~]# parted -s -a optimal /dev/sde mkpart cache 1MiB 1100GiB
[root@ceph01 ~]# parted -s -a optimal /dev/sde mkpart db 1100GiB 100%
[root@ceph01 ~]# parted -s -a optimal /dev/sdg mklabel gpt
[root@ceph01 ~]# parted -s -a optimal /dev/sdg mkpart cache 1MiB 1100GiB
[root@ceph01 ~]# parted -s -a optimal /dev/sdg mkpart db 1100GiB 100%
[root@ceph01 ~]# lsblk /dev/sde /dev/sdg
sde 8:64 1 1.7T 0 disk
├─sde1 8:65 1 1.1T 0 part
└─sde2 8:66 1 688.5G 0 part
sdg 8:96 1 1.7T 0 disk
├─sdg1 8:97 1 1.1T 0 part
└─sdg2 8:98 1 688.5G 0 part
2.2 Bcache 配置
以下操作三台节点都要执行,这里我拿第一台举例!!!
2.2.1 安装 Bcache
- dnf install bcache-tools 是安装 bcache 用户态工具;
- modprobe bcache 是加载内核模块;
- lsmod | grep bcache 和 grep BCACHE /boot/config-$(uname -r) 是确认当前内核确实支持 bcache,而且是以模块方式支持。
- which make-bcache、which bcache-super-show 是确认关键工具存在。这里这样做,是因为 bcache 不是单纯装个命令就能用,它必须同时满足“用户态工具已装”和“内核模块已支持”这两个条件。
[root@ceph01 ~]# dnf install bcache-tools
[root@ceph01 ~]# modprobe bcache //无报错
[root@ceph01 ~]# lsmod | grep bcache //模块已经加载
bcache 339968 0
[root@ceph01 ~]# grep BCACHE /boot/config-$(uname -r) //内核是以模块方式支持 bcache
CONFIG_BCACHE=m
CONFIG_FS_MBCACHE=m
[root@ceph01 ~]# which make-bcache
/usr/sbin/make-bcache
[root@ceph01 ~]# which bcache-super-show
/usr/sbin/bcache-super-show
2.2.2 创建 bcache
- make-bcache -C /dev/sde1、make-bcache -C /dev/sdg1 是把两块 SSD 上的第一个大分区初始化成 cache device;
- -C 的意思就是“把这个设备做成缓存设备”。
- make-bcache -B /dev/sdb 到 -B /dev/sdo 是把 6 块 HDD 初始化成 backing device,也就是后面真正存放 OSD 主数据的后端盘。
- udevadm settle 是等 udev 把 /dev/bcache0 到 /dev/bcache5 这些设备节点都创建完整,不然马上往下做 attach 可能找不到设备。
[root@ceph01 ~]# make-bcache -C /dev/sde1
/dev/sde1 blkdiscard beginning...done
[root@ceph01 ~]# make-bcache -C /dev/sdg1
/dev/sdg1 blkdiscard beginning...done
[root@ceph01 ~]# make-bcache -B /dev/sdb
[root@ceph01 ~]# make-bcache -B /dev/sdc
[root@ceph01 ~]# make-bcache -B /dev/sdd
[root@ceph01 ~]# make-bcache -B /dev/sdf
[root@ceph01 ~]# make-bcache -B /dev/sdn
[root@ceph01 ~]# make-bcache -B /dev/sdo
[root@ceph01 ~]# udevadm settle
[root@ceph01 ~]# ls /dev/bcache*
/dev/bcache0 /dev/bcache1 /dev/bcache2 /dev/bcache3 /dev/bcache4 /dev/bcache5
2.2.3 attach bcache
bcache-super-show /dev/sde1 | awk ‘/cset.uuid/’ 是读出 SSD 缓存分区所属的 cache set UUID,因为 bcache 不是自动猜哪块 HDD 该挂到哪块 SSD 缓存上,必须显式告诉它。后面 echo $CACHESET1 > /sys/block/bcache0/bcache/attach 这些命令,就是把 bcache0/1/2 三块 HDD backing device 挂到 sde1 这块 SSD 缓存集上,把 bcache3/4/5 挂到 sdg1 上。这样形成的是 3 块 HDD 共用 1 块 SSD cache set 的结构。
[root@ceph01 ~]# CACHESET1=$(bcache-super-show /dev/sde1 | awk '/cset.uuid/ {print $2}')
[root@ceph01 ~]# CACHESET2=$(bcache-super-show /dev/sdg1 | awk '/cset.uuid/ {print $2}')
echo $CACHESET1 > /sys/block/bcache0/bcache/attach
echo $CACHESET1 > /sys/block/bcache1/bcache/attach
echo $CACHESET1 > /sys/block/bcache2/bcache/attach
echo $CACHESET2 > /sys/block/bcache3/bcache/attach
echo $CACHESET2 > /sys/block/bcache4/bcache/attach
echo $CACHESET2 > /sys/block/bcache5/bcache/attach
2.2.4 压低 dirty 比例
echo writeback > /sys/block/bcache$i/bcache/cache_mode 是把 bcache 模式设成 writeback,意思是写请求可以先落到 SSD 缓存,再异步回写到 HDD,写性能会明显好于 writethrough。echo 10 > …/writeback_percent 是限制脏数据比例最多占缓存的 10%,这样做是为了别让太多“还没刷回 HDD 的数据”堆在缓存里,既降低掉电和恢复风险,也避免 SSD 缓存被脏数据长期占满。
[root@ceph01 ~]# for i in 0 1 2 3 4 5; do
echo writeback > /sys/block/bcache$i/bcache/cache_mode
echo 10 > /sys/block/bcache$i/bcache/writeback_percent
done
2.2.5 创建 DB 分区
以下操作三台节点都要执行,这里我拿第一台举例!!!
- parted -s -a optimal /dev/sde mkpart db0 1100GiB 1300GiB 这组命令,是把前面预留出来的 DB 空间进一步切成 3 个独立的 200G 分区,对应 3 个 OSD;sdg 也同样切 3 个。原因是 BlueStore 的 block.db 最好单独给每个 OSD 一个设备或分区,这样每个 OSD 的 RocksDB/BlueFS 元数据互不干扰,运维时也更直观。
- lsblk 里看到 sde1 下挂着 bcache0/1/2,而 sde2/3/4 只是普通分区,这正好说明这块 SSD 被一分为二:前半段做 bcache cache,后半段做 3 个 OSD 的 DB。
[root@ceph01 ~]# parted -s -a optimal /dev/sde mkpart db0 1100GiB 1300GiB
[root@ceph01 ~]# parted -s -a optimal /dev/sde mkpart db1 1300GiB 1500GiB
[root@ceph01 ~]# parted -s -a optimal /dev/sde mkpart db2 1500GiB 1700GiB
[root@ceph01 ~]# parted -s -a optimal /dev/sdg mkpart db3 1100GiB 1300GiB
[root@ceph01 ~]# parted -s -a optimal /dev/sdg mkpart db4 1300GiB 1500GiB
[root@ceph01 ~]# parted -s -a optimal /dev/sdg mkpart db5 1500GiB 1700GiB
[root@ceph01 ~]# lsblk /dev/sde /dev/sdg
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sde 8:64 1 1.7T 0 disk
├─sde1 8:65 1 1.1T 0 part
│ ├─bcache0 252:0 0 7.3T 0 disk
│ ├─bcache1 252:128 0 7.3T 0 disk
│ └─bcache2 252:256 0 7.3T 0 disk
├─sde2 8:66 1 200G 0 part
├─sde3 8:67 1 200G 0 part
└─sde4 8:68 1 200G 0 part
sdg 8:96 1 1.7T 0 disk
├─sdg1 8:97 1 1.1T 0 part
│ ├─bcache3 252:384 0 7.3T 0 disk
│ ├─bcache4 252:512 0 7.3T 0 disk
│ └─bcache5 252:640 0 7.3T 0 disk
├─sdg2 8:98 1 200G 0 part
├─sdg3 8:99 1 200G 0 part
└─sdg4 8:100 1 200G 0 part
2.3 创建 OSD
以下操作三台节点都要执行,这里我拿第一台举例!!!
2.3.1 创建 OSD
- ceph-volume lvm create --bluestore --crush-device-class hdd --data /dev/bcache0 --block.db /dev/sde2 这一类命令,是正式把前面准备好的设备变成 Ceph OSD。
- 这里 --bluestore 表示使用 BlueStore;
- –data /dev/bcache0 表示 OSD 主数据设备是 bcache 之后的块设备,也就是“底层是 HDD,但前面挂了 SSD 缓存”;
- –block.db /dev/sde2 表示把 BlueStore 的 RocksDB/BlueFS 元数据放到 SSD 分区上;
- –crush-device-class hdd 的意思是虽然前面有 SSD cache,但这类 OSD 的容量主体和介质属性仍然是 HDD,所以在 CRUSH 里仍归为 hdd 类,后面建池和规则时才不会把它误认为纯闪。
- ceph-volume lvm create 背后会自动做很多事:向集群申请 OSD ID、在数据设备上创建 Ceph 专用 VG/LV、初始化 BlueStore、生成 /var/lib/ceph/osd/ceph-N 目录、建立 block 和 block.db 软链接、注册并启动 ceph-osd@N 服务。所以看到后面 pvs/vgs/lvs 里每个 /dev/bcacheX 都被做成了一个单独的 Ceph VG,并且里面只有一个 osd-block-* LV,这是 ceph-volume lvm 的标准行为。
[root@ceph01 ~]# ceph-volume lvm create --bluestore --crush-device-class hdd --data /dev/bcache0 --block.db /dev/sde2
[root@ceph01 ~]# ceph-volume lvm create --bluestore --crush-device-class hdd --data /dev/bcache1 --block.db /dev/sde3
[root@ceph01 ~]# ceph-volume lvm create --bluestore --crush-device-class hdd --data /dev/bcache2 --block.db /dev/sde4
[root@ceph01 ~]# ceph-volume lvm create --bluestore --crush-device-class hdd --data /dev/bcache3 --block.db /dev/sdg2
[root@ceph01 ~]# ceph-volume lvm create --bluestore --crush-device-class hdd --data /dev/bcache4 --block.db /dev/sdg3
[root@ceph01 ~]# ceph-volume lvm create --bluestore --crush-device-class hdd --data /dev/bcache5 --block.db /dev/sdg4
2.3.2 检查配置
- ceph -s 里 18 osds: 18 up, 18 in 说明 3 台机器总共 18 个 OSD 都已经加入集群并正常服务,HEALTH_OK 说明当前没有告警。
- ceph osd tree 里每个 OSD 都显示为 CLASS hdd,并且按 host ceph01/02/03 分布,说明 CRUSH 拓扑和设备类别都正确。
[root@ceph01 ~]# ceph -s
cluster:
id: 3c9c2a6d-0c72-437a-b5cf-5b9e66fc461d
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph01,ceph02,ceph03 (age 35m)
mgr: ceph01(active, since 78m), standbys: ceph02, ceph03
osd: 18 osds: 18 up (since 0.337705s), 18 in (since 31s)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 3.3 TiB used, 124 TiB / 127 TiB avail
pgs: 1 active+clean
[root@ceph01 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 134.50836 root default
-3 44.83612 host ceph01
0 hdd 7.47269 osd.0 up 1.00000 1.00000
1 hdd 7.47269 osd.1 up 1.00000 1.00000
2 hdd 7.47269 osd.2 up 1.00000 1.00000
3 hdd 7.47269 osd.3 up 1.00000 1.00000
4 hdd 7.47269 osd.4 up 1.00000 1.00000
6 hdd 7.47269 osd.5 up 1.00000 1.00000
-5 44.83612 host ceph02
5 hdd 7.47269 osd.6 up 1.00000 1.00000
7 hdd 7.47269 osd.7 up 1.00000 1.00000
8 hdd 7.47269 osd.8 up 1.00000 1.00000
9 hdd 7.47269 osd.9 up 1.00000 1.00000
10 hdd 7.47269 osd.10 up 1.00000 1.00000
11 hdd 7.47269 osd.11 up 1.00000 1.00000
-7 44.83612 host ceph03
12 hdd 7.47269 osd.12 up 1.00000 1.00000
13 hdd 7.47269 osd.13 up 1.00000 1.00000
14 hdd 7.47269 osd.14 up 1.00000 1.00000
15 hdd 7.47269 osd.15 up 1.00000 1.00000
16 hdd 7.47269 osd.16 up 1.00000 1.00000
17 hdd 7.47269 osd.17 up 1.00000 1.00000
lsblk 里能看到 /dev/sdb -> bcache0 -> ceph-…/osd-block-…,这说明一块原始 HDD 先被 bcache 包成了 bcache0,然后又被 ceph-volume 放进了一个 Ceph 的 LVM LV 里作为 OSD block 设备;sde2、sde3、sde4 没再继续做 LVM,而是直接作为 block.db 分区使用。
[root@ceph01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sdb 8:16 1 7.3T 0 disk
└─bcache0 252:0 0 7.3T 0 disk
└─ceph--87f90372--8829--47a0--a5ef--a2a0b8c79875-osd--block--f7be7787--71ea--4ffb--8d4d--4f6d6217f110 253:1 0 7.3T 0 lvm
sdc 8:32 1 7.3T 0 disk
└─bcache1 252:128 0 7.3T 0 disk
└─ceph--4b74e369--d6f0--4b02--a24f--2969dde40820-osd--block--b1344a90--5995--4640--806b--a2f6864f5eaf 253:2 0 7.3T 0 lvm
sdd 8:48 1 7.3T 0 disk
└─bcache2 252:256 0 7.3T 0 disk
└─ceph--51275087--f875--4ddc--9e0c--dee86228aeb6-osd--block--81d2b042--3b25--437c--8828--0962162f2786 253:3 0 7.3T 0 lvm
sde 8:64 1 1.7T 0 disk
├─sde1 8:65 1 1.1T 0 part
│ ├─bcache0 252:0 0 7.3T 0 disk
│ │ └─ceph--87f90372--8829--47a0--a5ef--a2a0b8c79875-osd--block--f7be7787--71ea--4ffb--8d4d--4f6d6217f110 253:1 0 7.3T 0 lvm
│ ├─bcache1 252:128 0 7.3T 0 disk
│ │ └─ceph--4b74e369--d6f0--4b02--a24f--2969dde40820-osd--block--b1344a90--5995--4640--806b--a2f6864f5eaf 253:2 0 7.3T 0 lvm
│ └─bcache2 252:256 0 7.3T 0 disk
│ └─ceph--51275087--f875--4ddc--9e0c--dee86228aeb6-osd--block--81d2b042--3b25--437c--8828--0962162f2786 253:3 0 7.3T 0 lvm
├─sde2 8:66 1 200G 0 part
├─sde3 8:67 1 200G 0 part
└─sde4 8:68 1 200G 0 part
sdf 8:80 1 7.3T 0 disk
└─bcache3 252:384 0 7.3T 0 disk
└─ceph--89d27bd5--8606--4324--88d3--fcab7aec6535-osd--block--e336b041--bbf7--42df--b766--9be6bfeb7a96 253:4 0 7.3T 0 lvm
sdg 8:96 1 1.7T 0 disk
├─sdg1 8:97 1 1.1T 0 part
│ ├─bcache3 252:384 0 7.3T 0 disk
│ │ └─ceph--89d27bd5--8606--4324--88d3--fcab7aec6535-osd--block--e336b041--bbf7--42df--b766--9be6bfeb7a96 253:4 0 7.3T 0 lvm
│ ├─bcache4 252:512 0 7.3T 0 disk
│ │ └─ceph--be693416--454e--48e4--a885--72d67855a0ba-osd--block--142f1fa1--d7e9--4369--a73d--58115e256f03 253:5 0 7.3T 0 lvm
│ └─bcache5 252:640 0 7.3T 0 disk
│ └─ceph--bb82f7d6--978d--4593--b313--8cd775b7279c-osd--block--c196d2ea--8381--4bff--9edd--d84143a93fbb 253:6 0 7.3T 0 lvm
├─sdg2 8:98 1 200G 0 part
├─sdg3 8:99 1 200G 0 part
└─sdg4 8:100 1 200G 0 part
sdn 8:208 1 7.3T 0 disk
└─bcache4 252:512 0 7.3T 0 disk
└─ceph--be693416--454e--48e4--a885--72d67855a0ba-osd--block--142f1fa1--d7e9--4369--a73d--58115e256f03 253:5 0 7.3T 0 lvm
sdo 8:224 1 7.3T 0 disk
└─bcache5 252:640 0 7.3T 0 disk
└─ceph--bb82f7d6--978d--4593--b313--8cd775b7279c-osd--block--c196d2ea--8381--4bff--9edd--d84143a93fbb 253:6 0 7.3T 0 lvm
bcache tree 最关键,它直接告诉你缓存关系:/dev/sde1 给 /dev/sdb、/dev/sdc、/dev/sdd 三块盘做缓存,/dev/sdg1 给 /dev/sdf、/dev/sdn、/dev/sdo 三块盘做缓存,这正好对应设计的 3+3 结构。
[root@ceph01 ~]# bcache tree
.
/dev/sdg1
├─/dev/sdf bcache3
├─/dev/sdo bcache5
└─/dev/sdn bcache4
/dev/sde1
├─/dev/sdd bcache2
├─/dev/sdb bcache0
└─/dev/sdc bcache1
pvs/vgs/lvs 是从 LVM 角度验证 ceph-volume 的工作结果:每个 /dev/bcacheX 被初始化成一个 PV,再生成一个独立 VG,里面有一个 osd-block-* LV;这也解释了为什么明明传给 ceph-volume 的是 /dev/bcache0,最后在 OSD 目录里看到的 block 却指向 /dev/ceph-…/osd-block-…,因为 Ceph 最终实际使用的是它自己创建的 LV。
[root@ceph01 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/bcache0 ceph-87f90372-8829-47a0-a5ef-a2a0b8c79875 lvm2 a-- <7.28t 0
/dev/bcache1 ceph-4b74e369-d6f0-4b02-a24f-2969dde40820 lvm2 a-- <7.28t 0
/dev/bcache2 ceph-51275087-f875-4ddc-9e0c-dee86228aeb6 lvm2 a-- <7.28t 0
/dev/bcache3 ceph-89d27bd5-8606-4324-88d3-fcab7aec6535 lvm2 a-- <7.28t 0
/dev/bcache4 ceph-be693416-454e-48e4-a885-72d67855a0ba lvm2 a-- <7.28t 0
/dev/bcache5 ceph-bb82f7d6-978d-4593-b313-8cd775b7279c lvm2 a-- <7.28t 0
/dev/sda3 openeuler lvm2 a-- 555.98g 0
[root@ceph01 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
ceph-4b74e369-d6f0-4b02-a24f-2969dde40820 1 1 0 wz--n- <7.28t 0
ceph-51275087-f875-4ddc-9e0c-dee86228aeb6 1 1 0 wz--n- <7.28t 0
ceph-87f90372-8829-47a0-a5ef-a2a0b8c79875 1 1 0 wz--n- <7.28t 0
ceph-89d27bd5-8606-4324-88d3-fcab7aec6535 1 1 0 wz--n- <7.28t 0
ceph-bb82f7d6-978d-4593-b313-8cd775b7279c 1 1 0 wz--n- <7.28t 0
ceph-be693416-454e-48e4-a885-72d67855a0ba 1 1 0 wz--n- <7.28t 0
openeuler 1 1 0 wz--n- 555.98g 0
[root@ceph01 ~]# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
osd-block-b1344a90-5995-4640-806b-a2f6864f5eaf ceph-4b74e369-d6f0-4b02-a24f-2969dde40820 -wi-ao---- <7.28t
osd-block-81d2b042-3b25-437c-8828-0962162f2786 ceph-51275087-f875-4ddc-9e0c-dee86228aeb6 -wi-ao---- <7.28t
osd-block-f7be7787-71ea-4ffb-8d4d-4f6d6217f110 ceph-87f90372-8829-47a0-a5ef-a2a0b8c79875 -wi-ao---- <7.28t
osd-block-e336b041-bbf7-42df-b766-9be6bfeb7a96 ceph-89d27bd5-8606-4324-88d3-fcab7aec6535 -wi-ao---- <7.28t
osd-block-c196d2ea-8381-4bff-9edd-d84143a93fbb ceph-bb82f7d6-978d-4593-b313-8cd775b7279c -wi-ao---- <7.28t
osd-block-142f1fa1-d7e9-4369-a73d-58115e256f03 ceph-be693416-454e-48e4-a885-72d67855a0ba -wi-ao---- <7.28t
root openeuler -wi-ao---- 555.98g
cat /sys/block/bcache*/bcache/cache_mode 里看到 [writeback] 被方括号包起来,说明当前生效模式就是 writeback。
[root@ceph01 ~]# cat /sys/block/bcache*/bcache/cache_mode
writethrough [writeback] writearound none
writethrough [writeback] writearound none
writethrough [writeback] writearound none
writethrough [writeback] writearound none
writethrough [writeback] writearound none
writethrough [writeback] writearound none
/var/lib/ceph/osd/ceph-0/ 里的 block -> /dev/ceph-…/osd-block-… 和 block.db -> /dev/sde2 这两个软链接最有代表性,它们分别说明:OSD 主数据走的是 Ceph 管理的 block LV,元数据走的是 SSD 分区;whoami 是 OSD ID,fsid 是这个 OSD 自己的 UUID,ceph_fsid 是整套集群的 FSID,keyring 是这个 OSD 的认证密钥,mkfs_done 和 ready 则表示这个 OSD 已完成初始化并可启动。
[root@ceph01 ~]# ll /var/lib/ceph/osd/ceph-0/
total 68
-rw-r--r--. 1 ceph ceph 454 Jun 6 20:40 activate.monmap
-rw-------. 1 ceph ceph 11 Jun 6 20:40 bfm_blocks
-rw-------. 1 ceph ceph 4 Jun 6 20:40 bfm_blocks_per_key
-rw-------. 1 ceph ceph 5 Jun 6 20:40 bfm_bytes_per_block
-rw-------. 1 ceph ceph 14 Jun 6 20:40 bfm_size
lrwxrwxrwx. 1 ceph ceph 93 Jun 6 20:41 block -> /dev/ceph-87f90372-8829-47a0-a5ef-a2a0b8c79875/osd-block-f7be7787-71ea-4ffb-8d4d-4f6d6217f110
lrwxrwxrwx. 1 ceph ceph 9 Jun 6 20:41 block.db -> /dev/sde2
-rw-------. 1 ceph ceph 2 Jun 6 20:40 bluefs
-rw-------. 1 ceph ceph 37 Jun 6 20:41 ceph_fsid
-rw-r--r--. 1 ceph ceph 37 Jun 6 20:41 fsid
-rw-------. 1 ceph ceph 55 Jun 6 20:41 keyring
-rw-------. 1 ceph ceph 8 Jun 6 20:40 kv_backend
-rw-------. 1 ceph ceph 21 Jun 6 20:41 magic
-rw-------. 1 ceph ceph 4 Jun 6 20:41 mkfs_done
-rw-------. 1 ceph ceph 41 Jun 6 20:41 osd_key
-rw-------. 1 ceph ceph 6 Jun 6 20:41 ready
-rw-------. 1 ceph ceph 3 Jun 6 20:41 require_osd_release
-rw-------. 1 ceph ceph 10 Jun 6 20:41 type
-rw-------. 1 ceph ceph 2 Jun 6 20:41 whoami
三、创建 crush rule 和 pool
3.1 创建 crush rule
- ceph osd crush rule create-replicated rule_hybrid_hdd default host hdd 的作用,是新建一条名为 rule_hybrid_hdd 的复制型 CRUSH 规则。
- default 表示从 CRUSH 根桶 default 下面选盘
- host 表示副本按主机级别分散
- hdd 表示只从设备类是 hdd 的 OSD 里选。
为什么要单独建这条规则,而不是直接用默认 replicated_rule?因为默认规则是从整个 default 根桶里选 OSD,并不限制设备类别;你现在虽然集群里只有 hdd 类 OSD,看起来默认规则也能用,但后面一旦再加纯 SSD OSD 做闪存池,默认规则就可能同时选到 hdd 和 ssd,不利于池的性能边界清晰。
[root@ceph01 ~]# ceph osd crush rule create-replicated rule_hybrid_hdd default host hdd
- ceph osd crush rule ls 和 ceph osd crush rule dump rule_hybrid_hdd 是验证这条规则到底长什么样。
- item_name: “default~hdd”,说明 Ceph 实际上已经把“根桶 + 设备类过滤”组合成了一个 default~hdd 视图;后面的 chooseleaf_firstn type host 表示副本选择时按 host 分散。
- ceph osd pool get device_health_metrics crush_rule 和 ceph osd crush rule dump replicated_rule 这两条,是顺手对比默认系统池还在用 replicated_rule。这也说明系统池和业务池可以使用不同 CRUSH 规则,各自独立。
[root@ceph01 ~]# ceph osd crush rule ls
replicated_rule //默认的
rule_hybrid_hdd
[root@ceph01 ~]# ceph osd crush rule dump rule_hybrid_hdd
{
"rule_id": 1,
"rule_name": "rule_hybrid_hdd",
"ruleset": 1,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -2,
"item_name": "default~hdd"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
[root@ceph01 ~]# ceph osd pool get device_health_metrics crush_rule
crush_rule: replicated_rule
[root@ceph01 ~]# ceph osd crush rule dump replicated_rule
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
3.2 创建 POOL
- ceph osd pool create rbd_hybrid 512 512 replicated rule_hybrid_hdd 是创建名为 rbd_hybrid 的复制型池,并显式指定使用 rule_hybrid_hdd。
- 512 512 是初始 pg_num 和 pgp_num,也就是创建时先给一个较大的 PG 基数。
- ceph osd pool set rbd_hybrid size 3 和 min_size 2,是把池的副本数设为 3,最小副本数设为 2,跟前面全局默认值保持一致:正常存 3 份,极端情况下少于 2 份就不再接受写入。
- ceph osd pool set rbd_hybrid pg_autoscale_mode on 是开启 PG 自动伸缩,让 Ceph 后面根据池的实际数据量自动调整 PG 数。
- rbd pool init rbd_hybrid 很关键,它不是普通“初始化目录”那种意思,而是给这个 pool 写入 RBD 所需的元数据结构,这样 Ceph 才知道这是一个给 RBD 使用的池。
[root@ceph01 ~]# ceph osd pool create rbd_hybrid 512 512 replicated rule_hybrid_hdd
[root@ceph01 ~]# ceph osd pool set rbd_hybrid size 3
[root@ceph01 ~]# ceph osd pool set rbd_hybrid min_size 2
[root@ceph01 ~]# ceph osd pool set rbd_hybrid pg_autoscale_mode on
[root@ceph01 ~]# rbd pool init rbd_hybrid
ceph osd pool ls detail 里 rbd_hybrid 的 application rbd 说明这个池已标记给 RBD 使用;
- crush_rule 1 对应的正是新建的 rule_hybrid_hdd;
- device_health_metrics 仍然用默认 replicated_rule 是正常的,因为这是 Ceph 自带系统池。
[root@ceph01 ~]# ceph osd pool ls
device_health_metrics
rbd_hybrid
[root@ceph01 ~]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 18 flags hashpspool stripe_width 0 pg_num_min 1 application mgr_devicehealth
pool 2 'rbd_hybrid' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 502 pgp_num 480 pg_num_target 32 pgp_num_target 32 autoscale_mode on last_change 132 lfor 0/132/130 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
ceph df / ceph df detail 里 CLASS 只有 hdd,也符合当前集群还没有纯 SSD OSD 的现状;MAX AVAIL 41 TiB 表示三副本规则下,这个池对用户可用的大致容量,并不是原始 135TiB 全给你用,因为副本会吃掉原始容量。
[root@ceph01 ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 135 TiB 131 TiB 3.5 TiB 3.5 TiB 2.61
TOTAL 135 TiB 131 TiB 3.5 TiB 3.5 TiB 2.61
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 41 TiB
rbd_hybrid 2 502 19 B 1 12 KiB 0 41 TiB
[root@ceph01 ~]# ceph df detail
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 135 TiB 131 TiB 3.5 TiB 3.5 TiB 2.61
TOTAL 135 TiB 131 TiB 3.5 TiB 3.5 TiB 2.61
--- POOLS ---
POOL ID PGS STORED (DATA) (OMAP) OBJECTS USED (DATA) (OMAP) %USED MAX AVAIL QUOTA OBJECTS QUOTA BYTES DIRTY USED COMPR UNDER COMPR
device_health_metrics 1 1 0 B 0 B 0 B 0 0 B 0 B 0 B 0 41 TiB N/A N/A N/A 0 B 0 B
rbd_hybrid 2 501 19 B 19 B 0 B 1 12 KiB 12 KiB 0 B 0 41 TiB N/A N/A N/A 0 B 0 B
[root@ceph01 ~]# ceph osd pool ls
device_health_metrics
rbd_hybrid
[root@ceph01 ~]# ceph osd pool get rbd_hybrid crush_rule
crush_rule: rule_hybrid_hdd
[root@ceph01 ~]# ceph osd pool get device_health_metrics crush_rule
crush_rule: replicated_rule
四、rbd 基本操作
4.1 创建 image
- rbd create rbd_hybrid/vm-001 --size 100G --image-feature layering,exclusive-lock,object-map,fast-diff,deep-flatten 是在 - rbd_hybrid 池里创建一个名为 vm-001 的 RBD 镜像,大小 100G。
- 这里这些 feature 都是 format 2 镜像常见的增强特性:
- layering 让镜像支持克隆/快照层级;
- exclusive-lock 让单客户端独占锁定镜像,很多高级特性依赖它;
- object-map 记录对象使用情况;
- fast-diff 依赖 object-map,用于快速比较增量;
- deep-flatten 支持更彻底地打平克隆关系。为什么这里一次把这些 feature 开齐?因为你这个池显然是准备给虚机盘/块存储用的,这些 feature 是现代 RBD 的常见标准组合。
[root@ceph01 ~]# rbd create rbd_hybrid/vm-001 --size 100G --image-feature layering,exclusive-lock,object-map,fast-diff,deep-flatten
[root@ceph01 ~]# rbd ls rbd_hybrid
vm-001
rbd ls、rbd info 则用来确认镜像真的创建好了,大小、对象数量、feature、格式都符合预期。order 22 表示对象大小为 4MiB,因为 2^22 = 4MiB。
[root@ceph01 ~]# rbd info rbd_hybrid/vm-001
rbd image 'vm-001':
size 100 GiB in 25600 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 617d32f8a5ed
block_name_prefix: rbd_data.617d32f8a5ed
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sat Jun 6 21:30:41 2026
access_timestamp: Sat Jun 6 21:30:41 2026
modify_timestamp: Sat Jun 6 21:30:41 2026
4.2 映射 image 到本机当块设备
- modprobe rbd 是加载 Linux 内核的 RBD 模块,让内核能够把 RADOS 块镜像映射成 /dev/rbdX 设备。
- rbd map rbd_hybrid/vm-001 的作用,是把这个镜像映射成本机块设备;返回 /dev/rbd0 说明成功。rbd showmapped 是查看当前有哪些镜像已经映射到本机;
- lsblk /dev/rbd0 则从系统块设备层确认它现在就是一块 100G 的“磁盘”。
这里之所以要先 modprobe rbd,是因为 rbd map 走的是内核 krbd 路径,没有这个模块,镜像就不能变成本地块设备。把 RBD 映射为 /dev/rbd0 后,Linux 上层看它和本地磁盘几乎没区别,你可以分区、格式化、挂载、跑 fio,都是对这个块设备进行。
[root@ceph01 ~]# modprobe rbd
[root@ceph01 ~]# rbd map rbd_hybrid/vm-001
/dev/rbd0
[root@ceph01 ~]# rbd showmapped
id pool namespace image snap device
0 rbd_hybrid vm-001 - /dev/rbd0
[root@ceph01 ~]# lsblk /dev/rbd0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
rbd0 251:0 0 100G 0 disk
4.3 映射 image 到客户端当块设备
- yum install -y ceph-common fio 是在客户端装通用 Ceph 工具和 fio 压测工具。这里真正必须的是 ceph-common,因为 rbd 命令就在这个包里,fio 只是后面压测方便一起装。
- modprobe rbd 还是一样,加载内核 RBD 模块。
- scp ceph.conf ceph.client.admin.keyring root@客户端:/etc/ceph/ 是把客户端访问集群所需的配置和认证文件拷过去;没有 ceph.conf,客户端不知道 mon 在哪;没有 keyring,客户端没有权限连集群。
- 然后客户端上执行 rbd -p rbd_hybrid -map vm-001,就能把同一个镜像映射成本地块设备。
[root@client ~]# yum install -y ceph-common fio
[root@client ~]# modprobe rbd
[root@ceph01 ~]# scp ceph.conf ceph.client.admin.keyring root@客户端地址:/etc/ceph/ //ceph01执行
[root@client ~]# rbd -p rbd_hybrid map vm-001
4.4 格式化并挂载
- mkfs.xfs /dev/rbd0 是在这个 RBD 块设备上创建 XFS 文件系统;
- mkdir -p /mnt/rbdtest 创建挂载点;mount /dev/rbd0 /mnt/rbdtest 把它挂载起来;
- df -h /mnt/rbdtest 则是验证挂载后的容量和使用情况。
这样做的意义在于:RBD 本质上只是“块设备”,不能直接拿来存文件,必须先像本地盘一样做文件系统,挂载后才能正常按目录和文件去使用。也就是说,这一步相当于把“Ceph 里的一个虚拟块盘”,变成了“Linux 本机可读写的文件系统”。后面对 /mnt/rbdtest 的读写,最终都会落到这个 rbd_hybrid 池里的 vm-001 镜像对象上。
[root@ceph01 ~]# mkfs.xfs /dev/rbd0
[root@ceph01 ~]# mkdir -p /mnt/rbdtest
[root@ceph01 ~]# mount /dev/rbd0 /mnt/rbdtest
[root@ceph01 ~]# df -h /mnt/rbdtest
4.5 fio 压测
我是拿ceph01、02、03同时压测的,底层对磁盘的请求会更分散一些,能接近真实业务场景,文档里以ceph01举例,实际上三台节点都需要执行。
先说这几条 fio 命令里反复出现的公共参数是什么意思:
–filename=/mnt/rbdtest/test.txt:在挂载好的 RBD 文件系统里,用这个文件做压测目标
–ioengine=libaio:使用 Linux 异步 I/O 引擎
–direct=1:绕过 Linux 页缓存,尽量测真实后端存储能力
–iodepth=32:单 job 队列深度 32,表示允许同时挂 32 个未完成 I/O
–numjobs=4:开 4 个并发 job,一起压
–time_based=1:按运行时长压测,而不是写满即停
–runtime=600:持续压 600 秒
–ramp_time=10:前 10 秒热身,不计入最终统计
–group_reporting=1:把多个 job 的结果汇总成一份,便于看总性能
4.5.1 4M 把盘写满
这条命令的作用,是先用 4M 顺序写把测试文件完整写一遍,相当于“预填充”:
- 避免后面的随机读随机写只打到“空洞文件”或稀疏区域;
- 避免第一次分配对象、第一次写入文件系统元数据,把结果搞得失真;
- 让后续测试更接近“真实业务盘已经有数据”的状态。
[root@ceph01 ~]# fio --name=write --filename=/dev/rbd0 --ioengine=libaio --direct=1 --rw=write --bs=4M --size=100G --iodepth=8 --numjobs=1 --ramp_time=10 --group_reporting=1
4.5.2 4k 随机写
测典型小块随机写能力:
- 4k 是最常见的小块随机 I/O 粒度之一
- randwrite 很接近虚机盘、数据库日志、元数据更新这类压力
- numjobs=4 + iodepth=32 能把后端并发能力压出来
[root@ceph01 ~]# fio --name=randwrite --filename=/dev/rbd0 --ioengine=libaio --direct=1 --rw=randwrite --bs=4k --size=50G --iodepth=32 --numjobs=4 --time_based=1 --runtime=600 --ramp_time=10 --group_reporting=1
测试结果: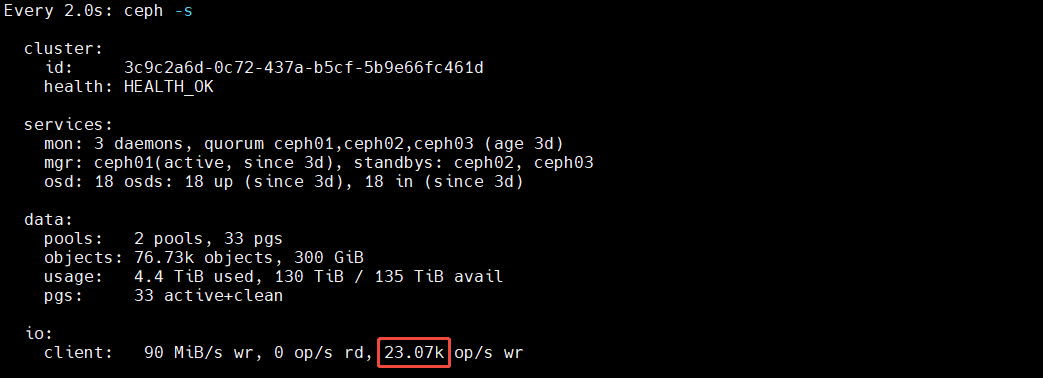

结果分析:
先来看一下不同硬盘型号,单盘性能预估的典型数据,帮助我们计算集群性能是否正常。
| 介质类型 | IOPS(读) | IOPS(写) | BW(读) | BW(写) | 典型时延(读) | 典型时延(写) |
|---|---|---|---|---|---|---|
| HDD | 200 | 200 | 150M | 150M | 10ms | 10ms |
| SSD | 100K | 30K | 500M | 400M | 100us | 200us |
| NVME | 500K | 300K | 3000M | 2000M | 20us | 20us |
按经验粗略估算,这套集群共有 6 块 SSD,若单盘 4K 随机写能力按约 30K IOPS 计算,则在三副本前提下,再考虑 BlueStore 元数据、RocksDB/WAL、bcache 以及协议栈等附加开销后,集群前台有效随机写能力落在 2 万到 3 万 IOPS 这个量级是合理的。对于 SSD,%util 不能像 HDD 一样直接等同于是否达到极限,但当缓存 SSD 的写 IOPS 已达到约 21K,同时 iostat 显示该盘处于持续高负载状态,而后端 HDD 并未成为主要写瓶颈时,可以判断当前 4K 随机写性能的主要限制因素已经落在 SSD 层。 由于本次压测是在存储节点本机发起,网络往返和客户端协议开销相对较小,因此最终测得集群总 IOPS 稳定在约 20K 左右,与单块缓存 SSD 实际可承载的性能上限基本吻合,可以认为这套集群的 4K 随机写性能表现正常。
4.5.3 4k 随机读
测小块随机读能力:
- 4k randread 很适合看虚机启动、目录索引、数据库热点读取这类场景
- 随机读对缓存命中、SSD DB、bcache 热数据加速比较敏感
[root@ceph01 ~]# fio --name=randread --filename=/dev/rbd0 --ioengine=libaio --direct=1 --rw=randread --bs=4k --size=50G --iodepth=32 --numjobs=8 --time_based=1 --runtime=600 --ramp_time=10 --group_reporting=1
测试结果:
刚开始执行的 iops,持续了 1分钟左右 100K,非常高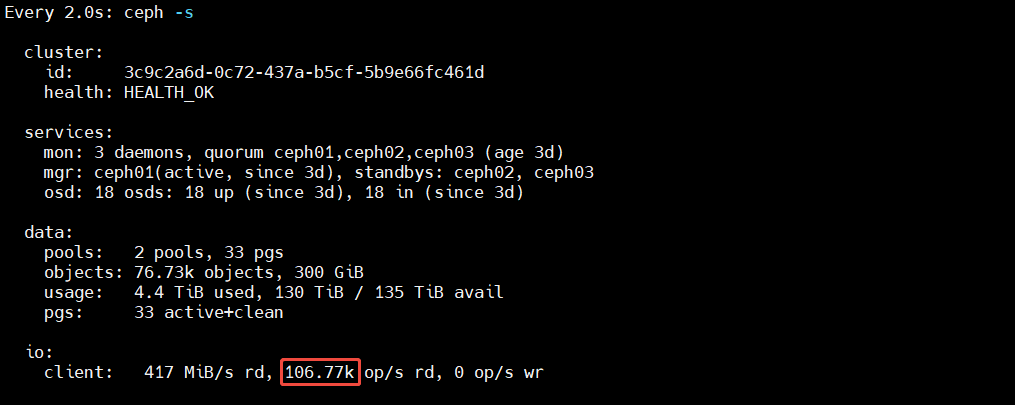

到后面,悬崖式跌落到 3k 左右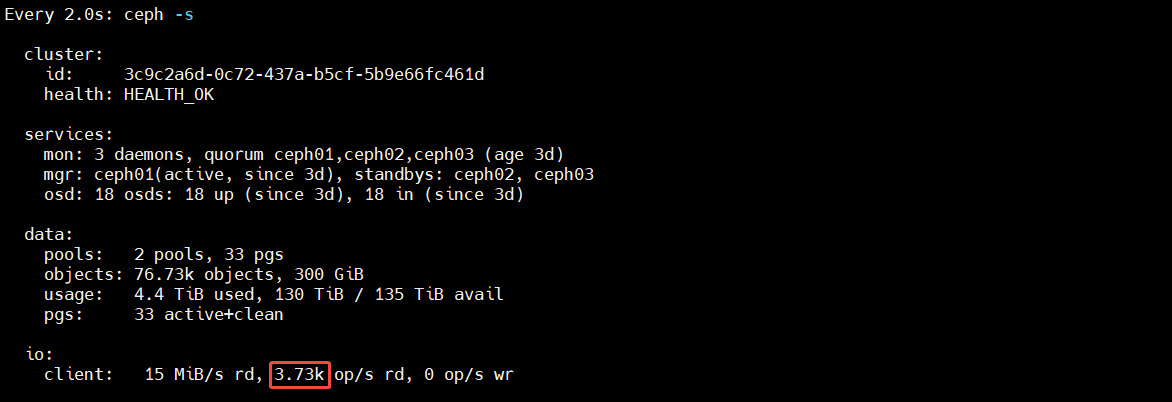

结果分析:
- 本次 4K randread 压测前期约 1 分钟能跑到 100K IOPS,并不代表这套集群的“冷读持续能力”有 100K,而是说明前期大量请求命中了缓存。原因可能是在随机读前已经对同一个 RBD image 做过 4k 随机写,这些最近写入的数据在 bcache writeback 模式下很可能仍然大量停留在 SSD 缓存层。因此,测试初期访问到的是一批“刚写过、仍然很热”的数据,随机读自然会优先命中 SSD 层,于是出现了约 100K IOPS 的高值。由于整套集群共有 6 块企业级 SATA SSD,单盘随机读能力本身就在数万到近十万 IOPS 量级,所以前期集群出现 100K IOPS 的瞬时热点读性能是合理的。
- 随着测试持续进行,访问范围逐渐超出当前缓存能稳定覆盖的工作集,缓存命中率快速下降,读请求开始大量回落到后端 HDD。此时从 iostat 可以看到,前期主要忙的是 sde/sde1 这类 SSD 缓存层,而后期则变成 sdc、sdf、sdn、sdo 等机械盘承担主要随机读压力,这说明后期性能已经由 HDD 主导。机械盘 4K 随机读能力本身有限,按 18 块 HDD、单盘大约 100~200 IOPS 粗略估算,总体冷读能力落在 1800~3600 IOPS 量级是合理的,再考虑 Ceph/RBD 调度和协议开销,最终集群稳定在约 3K~4K IOPS 完全符合预期。
4.5.4 4M 顺序写
测大块顺序写吞吐:
- 大块顺序 I/O 更适合看带宽能力
- 接近镜像导入、大文件顺序写、备份写入这类场景
[root@ceph01 ~]# fio --name=write --filename=/dev/rbd0 --ioengine=libaio --direct=1 --rw=write --bs=4M --size=50G --iodepth=16 --numjobs=8 --time_based=1 --runtime=600 --ramp_time=10 --group_reporting=1
测试结果: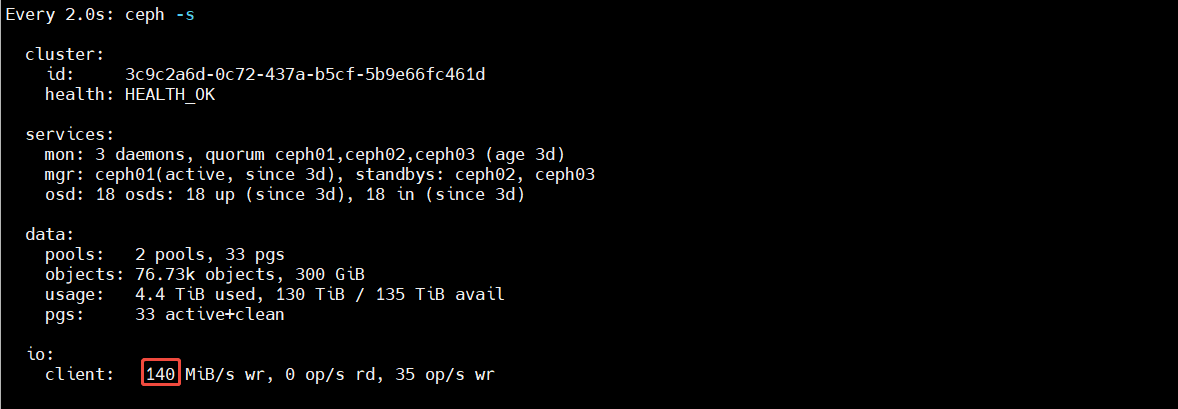

4.5.5 4M 顺序读
大块顺序读吞吐:
- 顺序读能比较直接反映这套池子的带宽能力
- 对备份读取、大文件扫描、镜像导出这类场景更有参考意义
[root@ceph01 ~]# fio --name=read --filename=/dev/rbd0 --ioengine=libaio --direct=1 --rw=read --bs=4M --size=50G --iodepth=16 --numjobs=8 --time_based=1 --runtime=600 --ramp_time=10 --group_reporting=1
测试结果: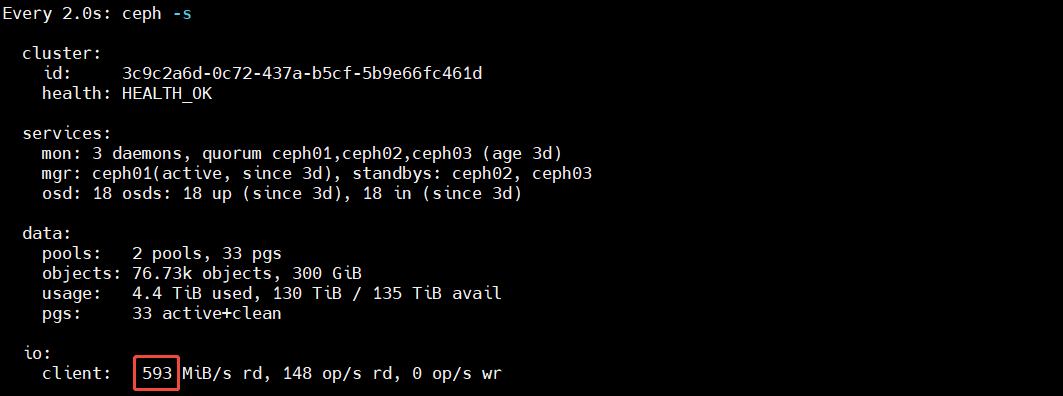
4.6 卸载 image
- umount /mnt/rbdtest:先卸载文件系统,确保没有进程再使用这个 RBD 块设备
- rbd unmap /dev/rbd0:再把 RBD 镜像从本机块设备层解绑
[root@ceph01 ~]# umount /mnt/rbdtest
[root@ceph01 ~]# rbd unmap /dev/rbd0
总结
本文详细记录了从零开始部署一个三节点 Ceph 集群并进行基本功能验证的全过程。主要步骤与核心内容总结如下:
-
创建管理和监控节点:这是集群的基础。我们首先在所有节点上安装 Ceph 软件,然后依次部署了 Monitor (Mon) 和 Manager (Mgr) 服务,并创建了用于 OSD 引导的密钥,为数据存储层做好了管理准备。
-
创建 OSD(对象存储守护进程):这是存储数据的核心组件。过程包括:
- 准备存储设备:清空数据盘,并为用作缓存的 SSD 硬盘进行分区。
- 配置 Bcache:安装 Bcache 工具,创建并挂载 Bcache 设备,通过调整
dirty比例优化写入性能,并最终在 Bcache 上创建用于 OSD 的 DB 分区。 - 部署与验证 OSD:使用准备好的设备创建 OSD,并进行了一系列详细的配置检查,确保每个 OSD 状态健康、配置正确。
-
创建 CRUSH 规则和存储池:在 OSD 就绪后,我们定义了数据分布规则(CRUSH rule)并创建了实际的存储池(Pool),为上层应用提供了可用的存储空间。
-
RBD 基本操作与性能验证:最后,我们通过 RBD(RADOS Block Device)块存储服务验证了集群的可用性和性能。步骤包括:
- 创建 RBD 镜像(Image)。
- 将镜像映射到本地和远程客户端作为块设备。
- 对映射的设备进行格式化、挂载。
- 使用
fio工具进行全面的性能压测,包括 4K 随机读写、4M 顺序读写等关键场景,以评估集群的 IOPS 和带宽性能。 - 完成测试后卸载镜像。
通过以上步骤,我们成功搭建了一个具备管理、监控、数据存储和块设备服务功能的 Ceph 集群,并通过实际的操作和性能测试验证了其基本功能的完整性与稳定性。本文可作为一份手把手的实践指南,供需要在生产或实验环境中部署 Ceph 的运维人员和开发者参考。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)