LangChain知识点复习
LangChain
Agent入门
├── Model
│ ├── 基于init_chat_model
│ └── 基于Model
├── Messages
│ ├── 消息分类
│ ├── 系统提示词
│ │ ├── 提示词工程
│ │ └── few-shot
│ ├── 结构化输出
│ └── 多模态消息
│ ├── 图片
│ └── 音频
├── Tool
│ ├── @tool装饰器
│ ├── 自定义约束
│ └── 内置工具
└── Memory
├── 记忆分类
│ ├── 短期记忆
│ └── 长期记忆
├── InMemorySaver
├── SqliteSaver
└── 记忆管理(消息压缩和摘要)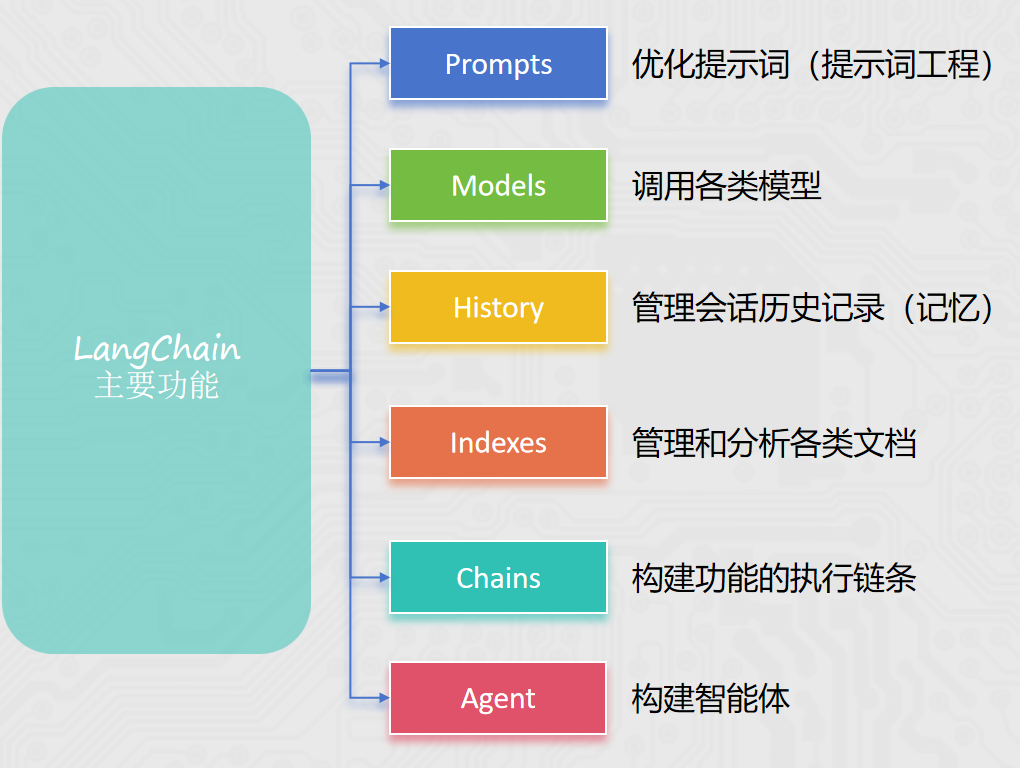
model是调用各种模型
我一般是用init_chat_model
# 我们收到加载环境变量中的base_url和api_key
import os
base_url = os.getenv("DASHSCOPE_BASE_URL")
api_key = os.getenv("DASHSCOPE_API_KEY")
model = init_chat_model(
model="qwen-max", # 模型名称,这里可以自定义,我们用的是阿里的qwen-max
model_provider="openai", # 如果是Langchain不支持的模型,需要指定模型提供者(虽然我们用的是阿里,但是阿里兼容openai,所以这里用openai)
base_url=base_url,
api_key=api_key,
temperature=1.5
)调整模型参数 除了修改模型提供者以外,init_chat_model函数允许我们调整模型参数,例如: - temperature: 控制生成文本的随机性,值越小越确定,值越大越随机 - max_tokens: 控制生成文本的最大长度 - top_p: 控制生成文本的多样性,值越小越多样,值越大越确定 - timeout: 控制生成文本的超时时间 - max_retries: 控制生成文本的最大重试次数 - ...
访问模型两个形式:
- invoke:阻塞式访问 - stream:流式访问
stream = model.stream("你是谁?") # ➊ 拿到一个“流式生成器”
print(type(stream)) # 输出:generator(生成器)
for chunk in stream: # ➋ 逐字遍历
print(chunk.content, end="", flush=True) # ➌ 不换行、立刻刷新输出
response = model.invoke([
{"role": "system", "content": "你扮演火箭队的武藏,以武藏的性格口吻回答用户的问题。"},
{"role": "user", "content": "你是谁?"}
])
print(response.content)
Messages
系统提示词也是messages的一部分:有zero-shot(不给样本);few-shot(有例子)
四大部分:身份角色;指令说明;对话示例;背景信息
SystemMessage、HumanMessage、AIMessage
在LangChain中,我们并不需要自己创建BaseMessage对象,LangChain已经把常见消息根据角色(Role)创建了对应的BaseMessage的子类: - SystemMessage:role是system,代表系统消息,用于设定模型角色和交互背景 - HumanMessage:role是user,代表用户输入的消息 - AIMessage:role是assistant,代表LLM生成的响应,包含:文本、工具调用、元数据 - ToolMessage:role是tool,代表工具调用时产生的结果

tools:
在LangChain中,定义工具需要用到@tool装饰器,我们可以通过装饰器来定义工具名、工具的作用:
from langchain_core.tools import tool
@tool("square_root", description="Calculate the square root of a number")
def tool1(x: float) -> float:
return x ** 0.5还有预定义tool
下一个是memory,有三种策略,第一个是会裁剪消息,就是限定几条,第二个是删除消息,第三个是用一个llm去总结消息摘要(用middleware)
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
from langchain.chat_models import init_chat_model
model1 = init_chat_model(
model="qwen-max",
model_provider="openai"
)
# 初始化checkpointer
checkpointer = InMemorySaver()
# 初始化中间件
middleware = SummarizationMiddleware(
model=model,
trigger=("messages", 3), # 触发时机,当消息数超过3时,进行总结
keep=("messages", 1) # 保留的会话数,超过2条
)
# 创建agent
model1 = init_chat_model(
model="qwen3-max",
model_provider="openai"
)
agent = create_agent(
model=model1,
middleware=[middleware],
checkpointer=checkpointer,
)
config: RunnableConfig = {"configurable": {"thread_id": "thread_3"}}
# 制造长会话历史
agent.invoke({"messages": [HumanMessage(content="你好,我是小白.")]}, config)
agent.invoke({"messages": [HumanMessage(content="我最喜欢的运动是乒乓")]}, config)
agent.invoke({"messages": [HumanMessage(content="我最喜欢的动物是狗")]}, config)
# 测试效果
final_response = agent.invoke({"messages": HumanMessage(content="你还记得我吗?")}, config)还有用存储的(sqlite)
from langgraph.checkpoint.sqlite import SqliteSaver
import sqlite3
# 初始化checkpointer
checkpointer = SqliteSaver(sqlite3.connect("resources/personal_chief.db", check_same_thread=False))
# 自动建表
checkpointer.setup()
from langchain.agents import create_agent
system_prompt = """
你是一名私人厨师。收到用户提供的食材照片或清单后,请按以下流程操作:
1.识别和评估食材:若用户提供照片,首先辨识所有可见食材。基于食材的外观状态,评估其新鲜度与可用量,整理出一份“当前可用食材清单”。
2.智能食谱检索:优先调用 web_search 工具,以“可用食材清单”为核心关键词,查找可行菜谱。
3.多维度评估与排序:从营养价值和制作难度两个维度对检索到的候选食谱进行量化打分,并根据得分排序,制作简单且营养丰富的排名靠前。
4.结构化方案输出:把排序后的食谱整理为一份结构清晰的建议报告,要包含食谱信息、得分、推荐理由,帮助用户快速做出决策。
请严格按照流程,优先调用 web_search 工具搜索食谱,再搜索不到的情况下才能自己发挥。
"""
agent = create_agent(
model=multimodal_model,
tools=[web_search],
system_prompt=system_prompt,
checkpointer=checkpointer
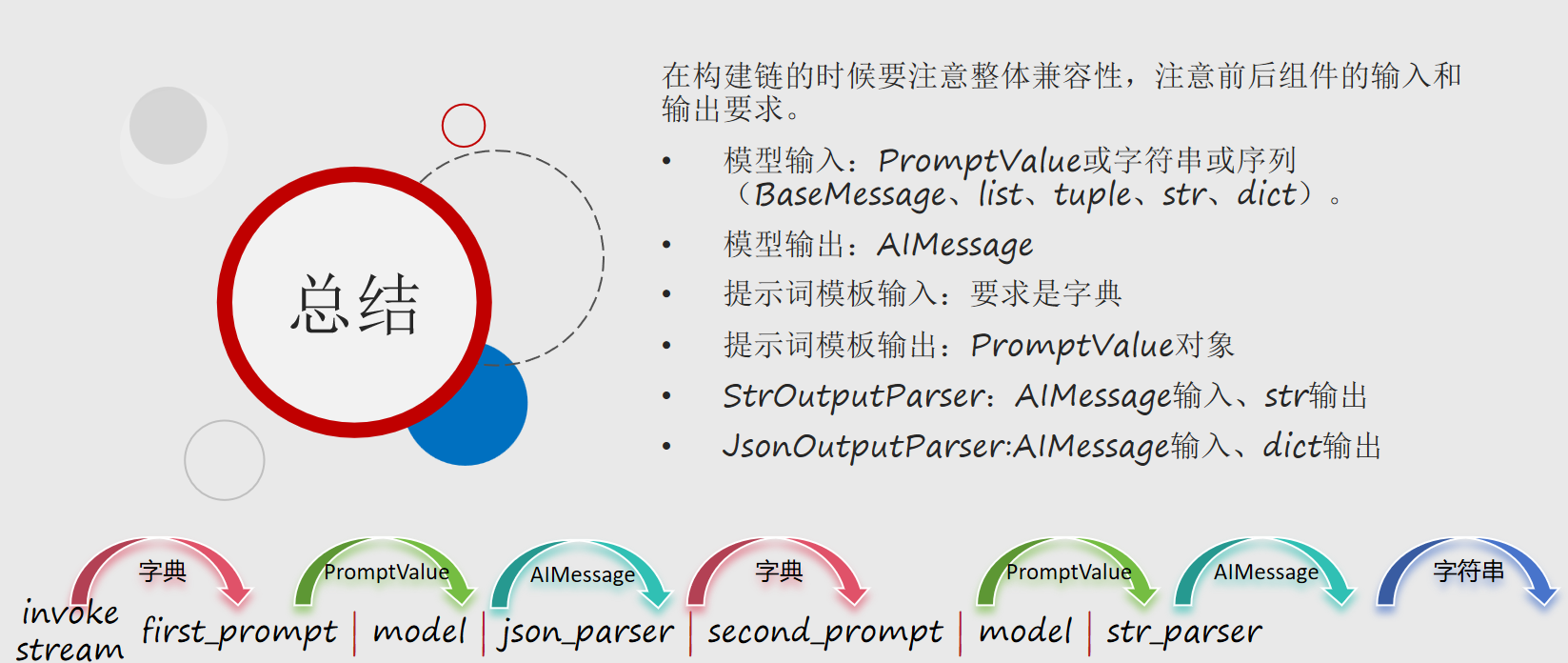
)在chain中,消息也需要合适的格式,用到LangChain组件StrOutputParser解析器
parser = StrOutputParser()
chain = prompt | model | parser | model
invoke|stream 初始输入 提示词模板 模型 数据处理 提示词模板 模型 解析器 结果
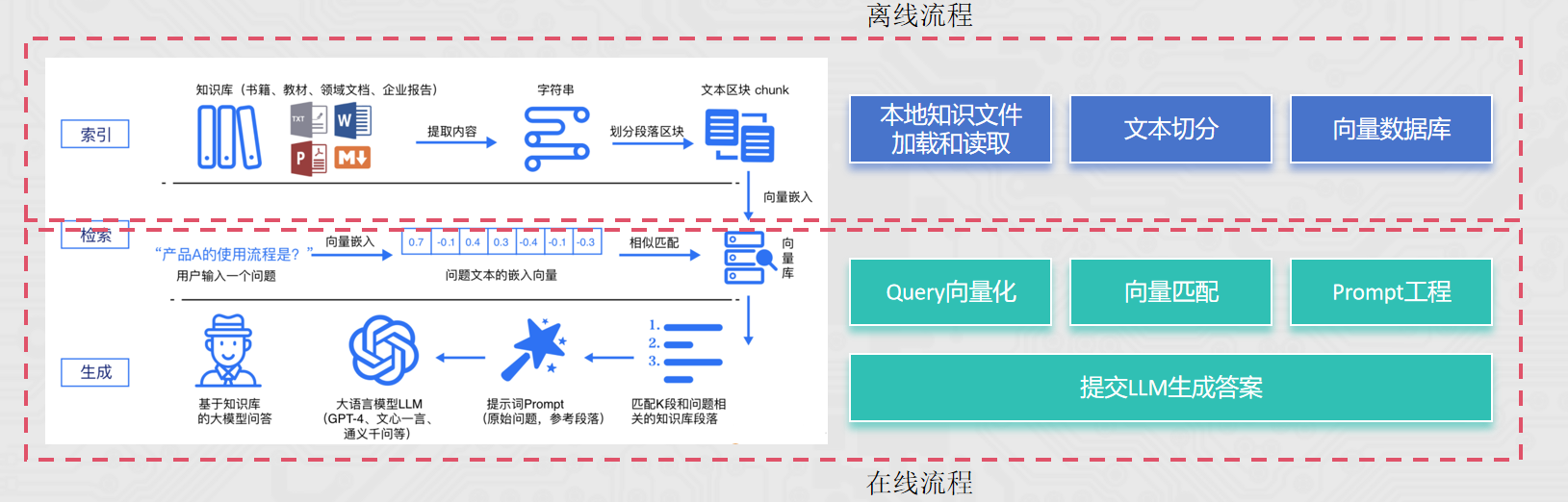
针对rag,还用到了很多文本加载器
from langchain_core.documents import Document
document = Document(
page_content="Hello, world!", metadata={"source": "https://example.com"}
)
from langchain_community.document_loaders.csv_loader
import CSVLoaderLangChain内置了许多文档加载器,详细参见官方文档:https://docs.langchain.com/oss/python/integrations/document_loaders
我们简单的学习如下几个常用的文档加载器: CSVLoader JSONLoader PDFLoader
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="", # 文件路径必填
mode='page', # 读取模式,可选page(按页面划分不同Document)和single(单个Document)
password='password', # 文件密码
)
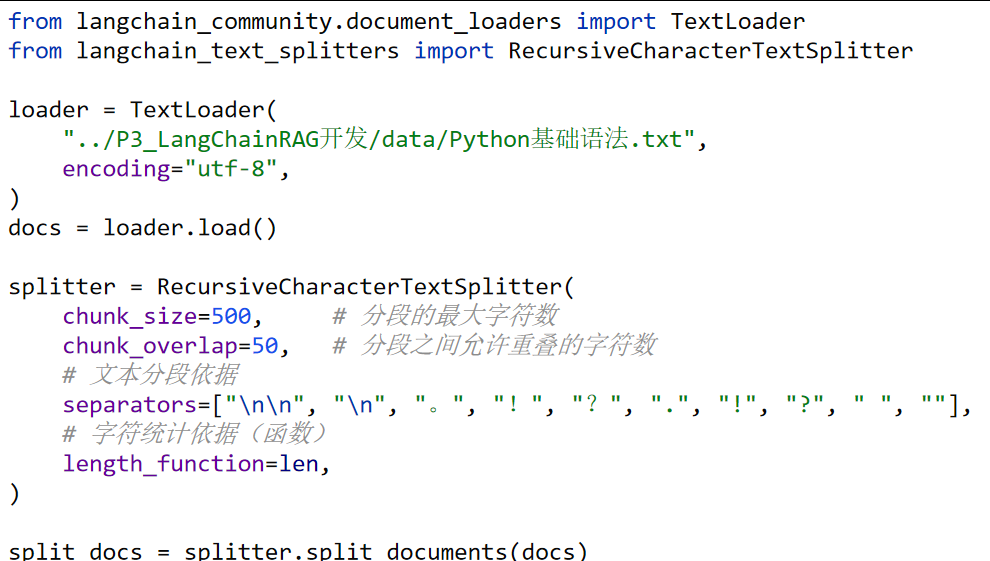
RecursiveCharacterTextSplitter,递归字符文本分割器,主要用于按自然段落分割大文档。 是LangChain官方推荐的默认字符分割器。 它在保持上下文完整性和控制片段大小之间实现了良好平衡,开箱即用效果佳。
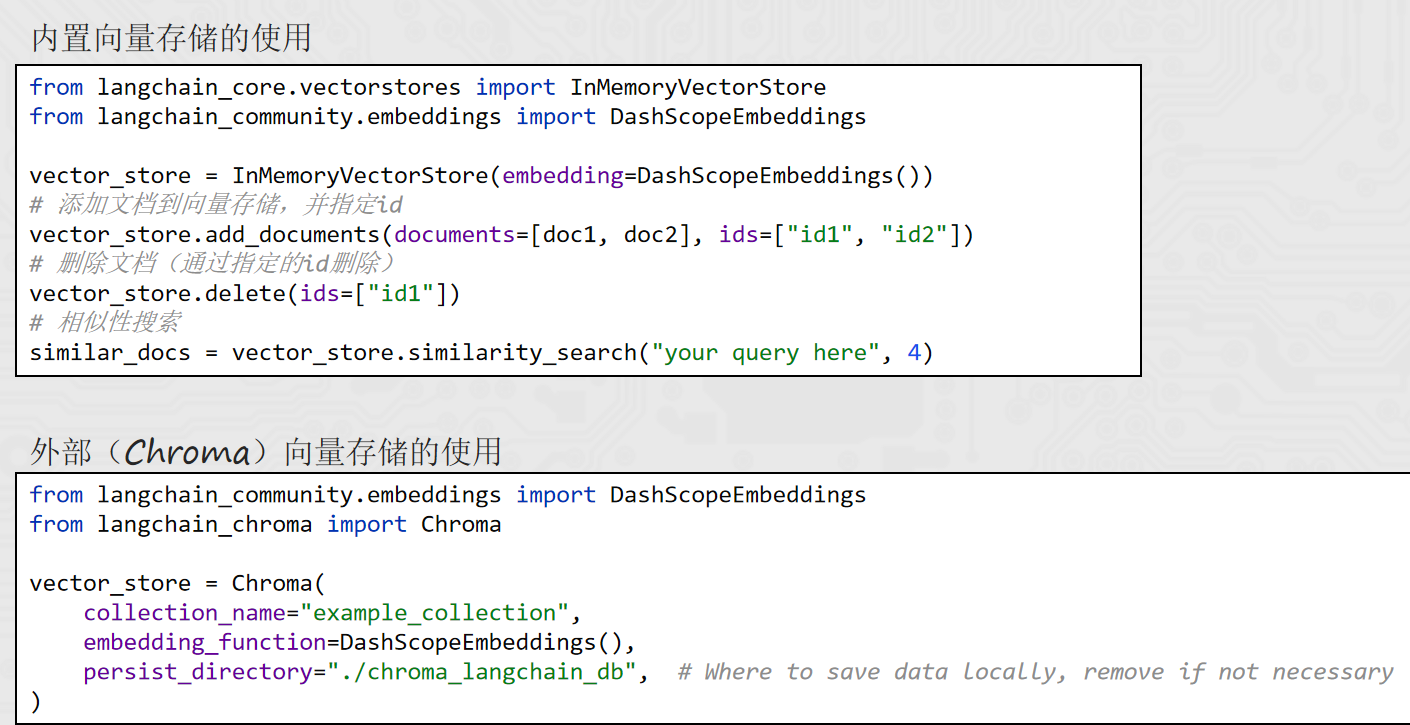
 还有vector stores方面
还有vector stores方面
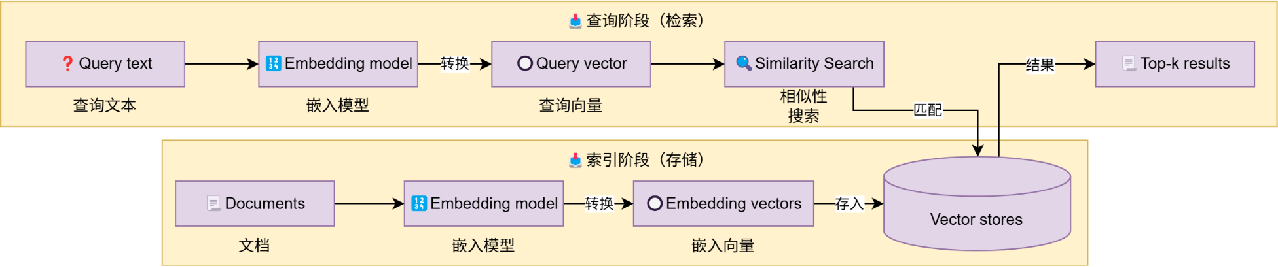
LangChain有内置和数据库存储两种
下面做一个示例,食谱推荐智能体

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)