大数据处理全家桶:Hadoop 是什么?Spark、Flink 们都是啥关系?
大数据处理全家桶:Hadoop 是什么?Spark、Flink 们都是啥关系?
大数据处理全家桶:Hadoop 是什么?Spark、Flink 们都是啥关系?
一篇写给小白的“大数据生态”地图,帮你理清那些听起来很像、但分工完全不同的技术。
1. 从一个超大的 Excel 表格说起
你在一家全国连锁超市做数据分析。
老板扔给你一个任务:统计过去一年所有门店的销售总额。
数据量有多大?一年有 10 亿条交易记录。
你打开 Excel,准备用 SUM 函数……
然后电脑风扇狂转,鼠标转圈,最后弹窗:“程序未响应”。
为什么?因为你的电脑内存只有 16GB,硬盘读写速度也跟不上。
一台电脑放不下、也处理不了这么大的数据。
这就是 大数据问题。
2. 大数据的核心思路:分而治之
既然一台电脑搞不定,那就 多找几台电脑一起来干。
思路很简单:
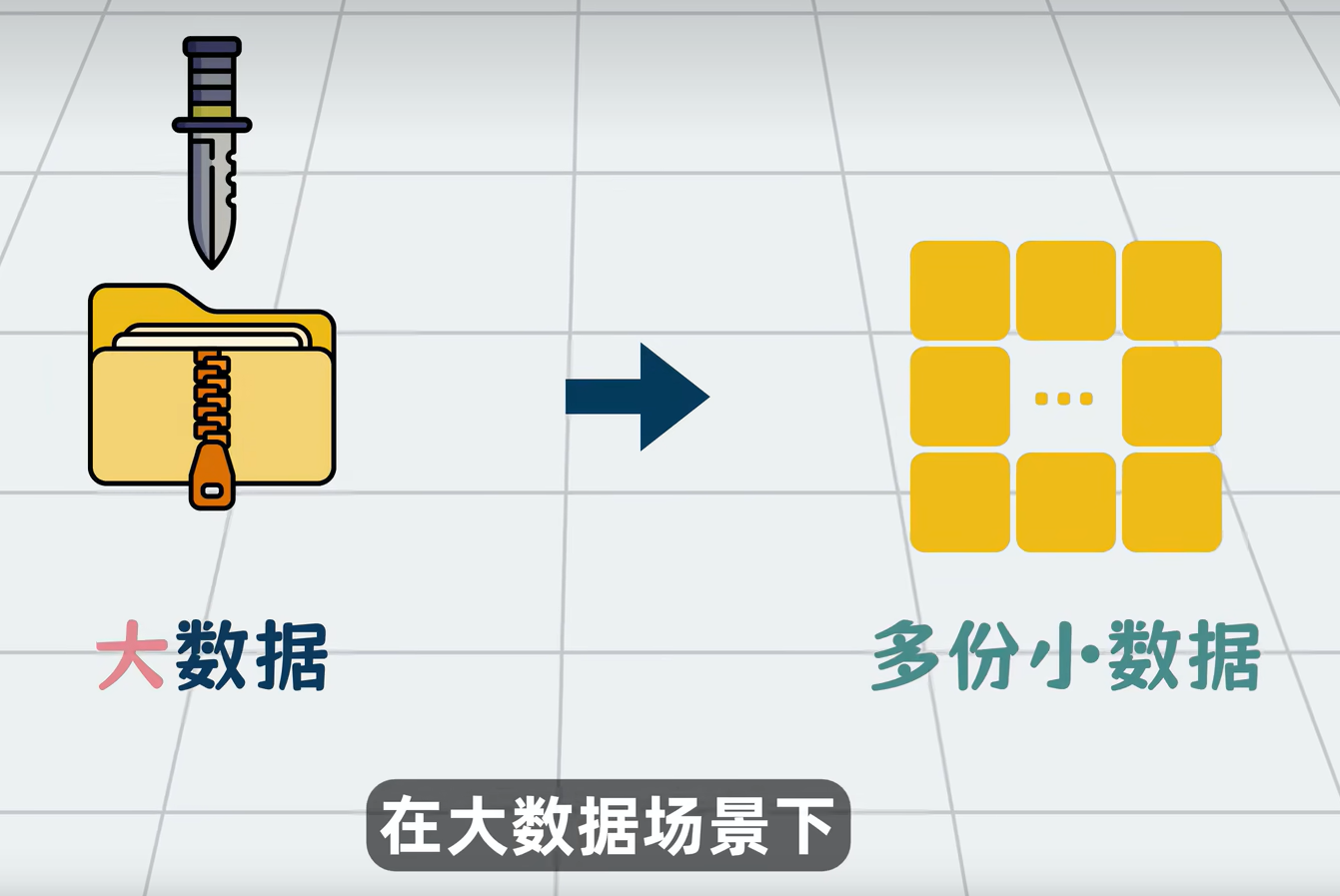
- 把 10 亿条数据 拆成 100 份,每份 1000 万条。
- 找 100 台普通电脑,每台处理一份。
- 每台电脑算出自己那份的销售额。
- 最后把 100 个结果 加起来,得到最终总额。
这就是大数据处理的核心思想:分而治之 + 并行计算。
但实际操作中会遇到三个现实难题:
- 谁来把数据拆分到 100 台电脑上?
- 如果某台电脑中途崩溃了,谁负责重新跑它的任务?
- 100 台电脑之间怎么协调、通信?
Hadoop 就是来解决这三个问题的框架。
3. Hadoop:大数据时代的开山鼻祖
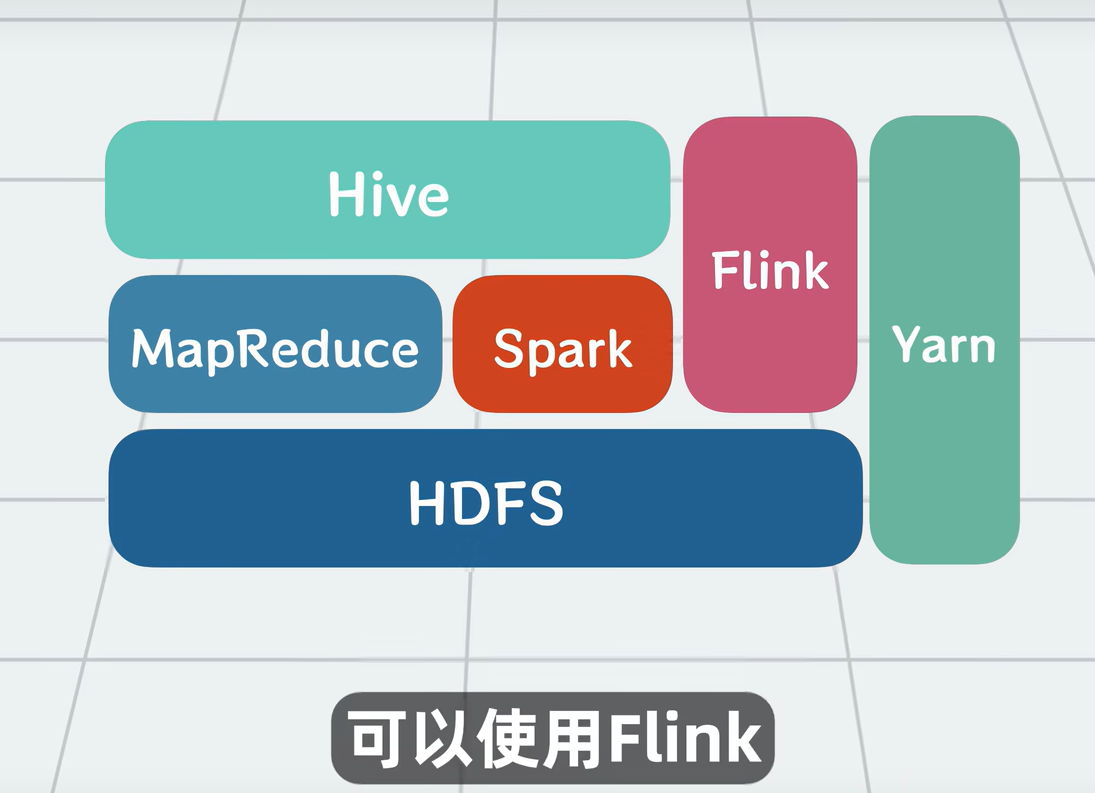
Hadoop 不是一个软件,而是一个 生态系统,核心有两大块:
3.1 HDFS(Hadoop Distributed File System)—— 分布式存储
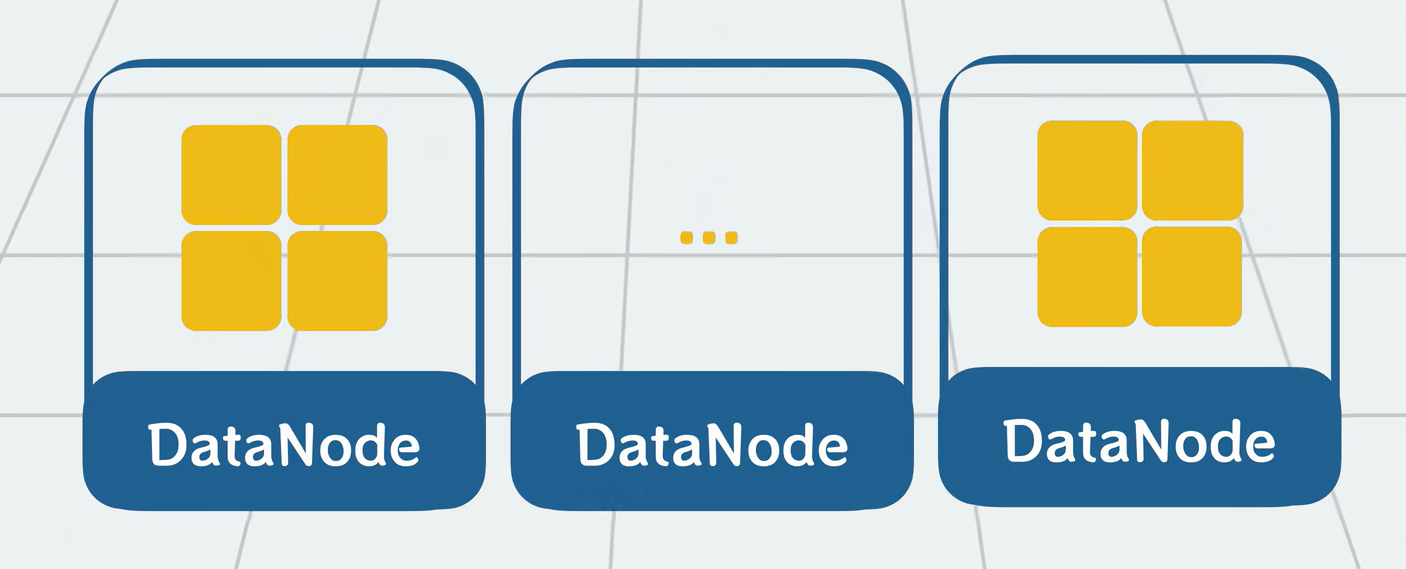
HDFS 的作用:把一个大文件拆成很多小块,分散存储在多台电脑上。
- 默认每个文件块(block)大小是 128MB。
- 每个块会复制 3 份,存放在不同机器上(防止某台机器硬盘坏了丢数据)。
比喻:
你有一本 1000 页的《战争与和平》,你把它拆成 100 个 10 页的小册子,然后复印 3 份,分给 100 个读者人手一册。这样谁丢了小册子,还有备份可以补。
3.2 MapReduce —— 分布式计算框架
MapReduce 定义了如何并行处理分散在 HDFS 上的数据。
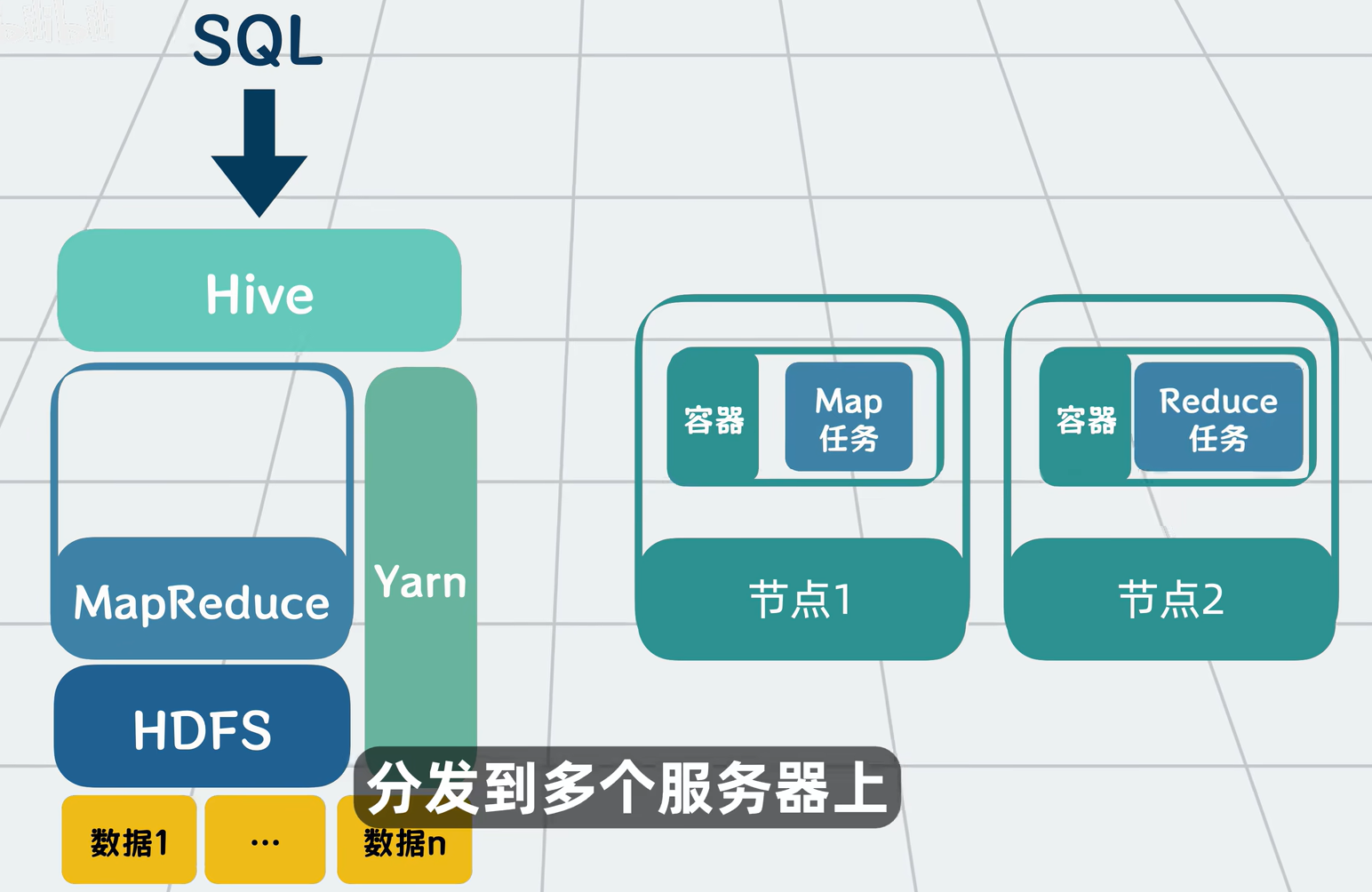
- Map 阶段:每台机器处理自己本地的数据块,产出中间结果(比如每台机器算出自己那份的销售额)。
- Reduce 阶段:把所有的中间结果汇总,得出最终答案。
MapReduce 还自动处理了容错:如果一个 Map 任务失败了,框架会把这个任务重新调度到另一台有备份数据的机器上重跑。
比喻:
Map 阶段像“分组调查”——每个调查员负责一个小区,统计小区人数。
Reduce 阶段像“总部汇总”——把所有小区的人数加起来,得到全市总人口。
但是,MapReduce 有一个致命缺点:慢。
因为它每次 Map 和 Reduce 的结果都要写入磁盘(而不是内存),对于需要多次迭代的算法(比如机器学习、图计算)效率很低。
于是,后起之秀 Spark 和 Flink 出现了。
4. Spark:让计算飞起来的内存引擎
Spark 和 Hadoop MapReduce 一样,也是分布式计算框架,但它的核心区别是:
- MapReduce:每一步计算结果都存磁盘 → 慢。
- Spark:尽量把中间结果放在内存中,只有内存不够才落盘 → 快 10~100 倍。
Spark 还提供了比 Map 和 Reduce 更丰富的操作(filter、groupBy、join 等),写代码更简单。
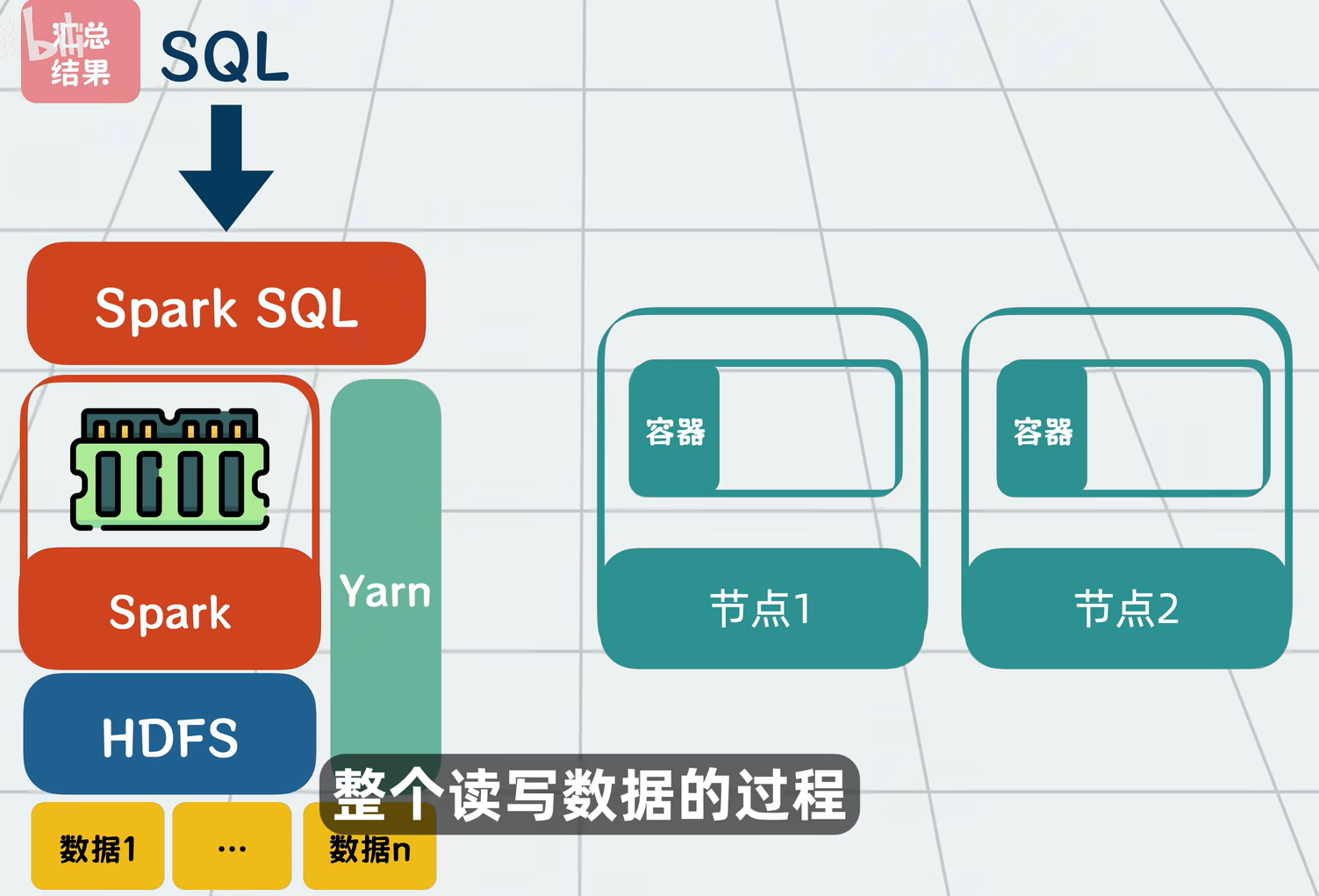
Spark 能跟 Hadoop 配合使用
- 数据可以仍然存在 HDFS 上。
- Spark 取代 MapReduce 做计算。
比喻:
如果说 MapReduce 是“货车运输队”(每次都要入库再出库),Spark 就是“高铁网络”(全程高速、少停站)。
Spark 适合什么场景?
- 批量数据处理(ETL、报表)。
- 机器学习迭代训练(MLlib)。
- 图计算(GraphX)。
- 流处理(Spark Streaming,但不如 Flink 实时)。
5. Flink:真正的实时流计算引擎
Spark Streaming 虽然能处理流数据,但它本质上是把流切成一串小批量(微批),延迟通常有几秒到十几秒。
Flink 是真正的纯流式计算引擎:数据来一条,处理一条,延迟可以低到毫秒级。
- Flink 也支持批处理(把它当作有限流)。
- 它在状态管理、事件时间处理、精确一次语义上比 Spark Streaming 更强。
比喻:
Spark Streaming 像“公交车”(每隔几分钟发一趟)。
Flink 像“出租车”(随叫随走)。
Flink 适合什么场景?
- 实时风控(信用卡盗刷秒级识别)。
- 实时大屏(双十一销售额实时刷新)。
- 实时数据同步(CDC 监听数据库变更)。
6. Hive:用 SQL 查询大数据
有了 HDFS 存储和 MapReduce/Spark 计算,但难道程序员每次都要写 Java 代码来处理数据吗?
太麻烦了。
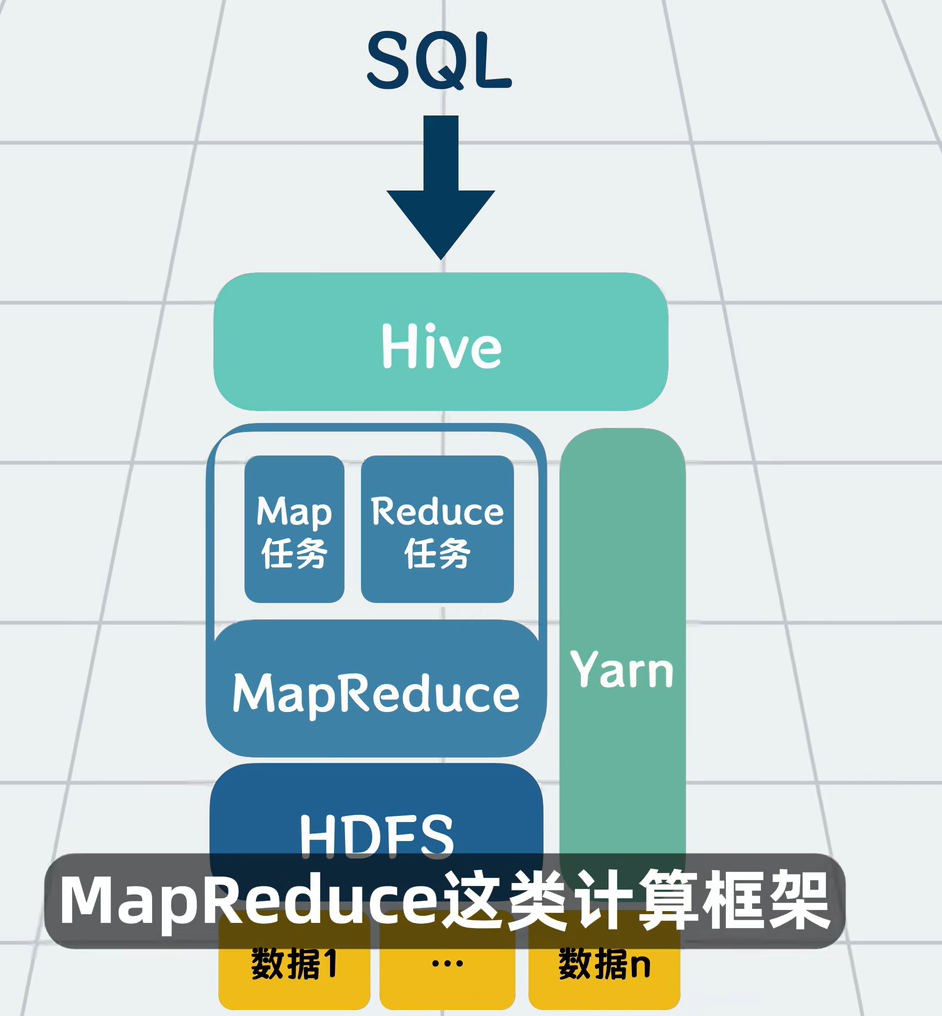
Hive 的作用:让你写 SQL 查询 HDFS 上的数据。
SELECT product_id, SUM(sales) FROM orders GROUP BY product_id;
Hive 会把这个 SQL 翻译成 MapReduce 或 Spark 作业,自动运行,然后把结果返回给你。
比喻:
Hive 就是“翻译官”:你说中文(SQL),它翻译成机器能懂的 MapReduce/Spark 语言。
重要特点
- Hive 适合离线批处理(几分钟甚至几小时跑完)。
- 它不适合实时查询(不像 MySQL 那样秒级响应)。
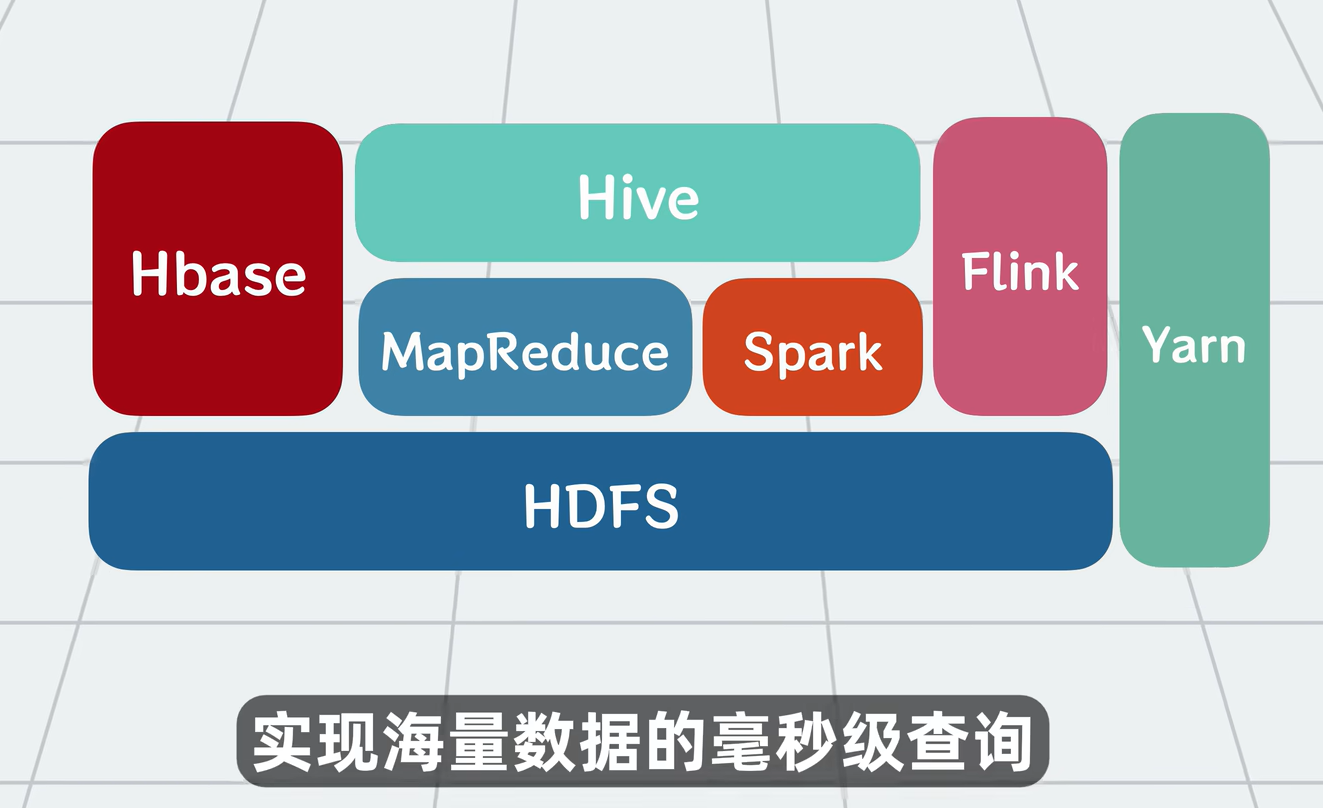
7. HBase:大数据的实时数据库
HDFS 是文件系统,只能顺序读写,不支持“查询某一行数据”这种随机访问。
假如你想从 10 亿条记录里快速找到用户 ID = 8888888 的那条,HDFS 需要扫描整个文件,太慢。
HBase 是一个分布式、面向列的 NoSQL 数据库,运行在 HDFS 之上:
- 支持按 rowkey 快速随机读写(毫秒级)。
- 支持海量数据(PB 级)。
- 不支持复杂 SQL,只支持简单的
get、put、scan。
比喻:
HDFS 像一个巨大的仓库,你只能整箱搬进搬出(顺序读写)。
HBase 在这个仓库里建了一套自动化立体货架,你输入货架号,机器臂马上帮你取出那一个小盒子(随机读写)。
HBase 适合什么场景?
- 用户画像存储(根据 userId 秒查标签)。
- 时序数据(物联网设备每秒钟上报的数据)。
- 需要实时读写、但不需要复杂查询的大数据场景。
8. 一张图总结它们的关系
┌─────────────────────────────────────────┐
│ 离线批处理 │
│ ┌─────────┐ ┌──────────────┐ │
│ │ Hive │─SQL──▶ │ MapReduce │ │
│ │ (翻译) │ │ 或 Spark │ │
│ └─────────┘ └──────────────┘ │
└─────────────────────────────────────────┘
│
▼
┌─────────────────┐
│ HDFS (分布式存储) │
└─────────────────┘
▲
┌─────────────────┼─────────────────────┐
│ 实时读写 │ 实时流计算 │
│ ┌────────┐ │ ┌──────────┐ │
│ │ HBase │ │ │ Flink │ │
│ └────────┘ │ └──────────┘ │
└─────────────────┴─────────────────────┘
各组件一句话总结
| 组件 | 一句话解释 |
|---|---|
| Hadoop | 大数据生态的老大哥,提供 HDFS(存储)和 MapReduce(计算)。 |
| HDFS | 把大文件拆碎、多备份存到很多电脑上,保证不丢数据。 |
| MapReduce | 分而治之的计算模型,但慢(每次写磁盘)。 |
| Spark | 用内存加速的通用计算引擎,比 MapReduce 快 10~100 倍。 |
| Flink | 真正的毫秒级实时流计算引擎,比 Spark Streaming 更实时。 |
| Hive | 让你用 SQL 查 HDFS,自动翻译成 MapReduce/Spark 作业。 |
| HBase | 在 HDFS 之上提供实时随机读写的 NoSQL 数据库。 |
9. 学习路线建议(小白友好)
- 先理解概念:搞清“分布式存储”和“分布式计算”的区别。
- 不用自己装集群:在本地装个 Docker,用
docker-compose跑一个单机版的 Hadoop + Hive 或 Spark 体验一下。 - 重点掌握 SQL:因为 Hive、Spark SQL 都离不开 SQL。
- 按场景学习:
- 要做离线报表?学 Hive + Spark。
- 要做实时大屏?学 Flink + Kafka。
- 要做海量数据快速查询?学 HBase。
不要被一堆名字吓到,你只需要记住:
HDFS 是存数据的,Spark/Flink 是算数据的,Hive 是把 SQL 转成计算的,HBase 是在 HDFS 上做快查的。
写在最后
大数据技术一直在演进,但底层的“分而治之”思想从未改变。
Hadoop 打开了大门,Spark 把速度提了上去,Flink 把实时做到了极致,而 Hive 和 HBase 让普通开发者不用写复杂代码就能用上大数据。
如果你想深入,建议从 Spark SQL 入手,因为现在很多公司已经把 Hive 迁移到 Spark 上了。
希望这篇博客能帮你建立起大数据生态的地图。有问题欢迎留言讨论~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)