计算机毕业设计Hadoop+Spark+Hive猫眼电影票房预测 电影推荐系统 电影可视化 电影爬虫 电影数据分析 机器学习 深度学习 知识图谱
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
技术说明书|Hadoop+Spark+Hive猫眼电影票房预测与个性化推荐系统
📌 简介:大数据毕设专属系统技术说明书,独立成文、无论文重复内容,涵盖架构原理、技术选型、集群部署、数仓设计、核心算法实现、模块技术细节、性能调优、部署运维全套内容。标准工程文档格式,原创低重,Markdown排版,支持CSDN一键复制发布、毕设归档、答辩使用。
🔖 标签:#技术说明书 #大数据毕设 #系统部署文档 #Hadoop #Spark #Hive #电影推荐系统 #票房预测
一、文档概述
本文档为《Hadoop+Spark+Hive猫眼电影票房预测与个性化推荐系统》配套技术说明书,主要用于阐述系统整体技术架构、核心技术原理、环境部署规范、数据仓库设计、核心功能技术实现、算法原理、系统调优方案与运维规范。区别于毕业论文侧重理论与综述,本文档聚焦工程实现、技术细节、落地流程、问题解决,完整记录项目全链路技术实现过程,可作为项目交付文档、答辩技术佐证与后期迭代维护依据。
本系统基于开源大数据生态构建,以分布式存储、分层数仓治理、内存高速计算、机器学习建模为核心,实现海量猫眼影视数据清洗分析、票房智能预测、个性化电影推荐与可视化展示,完全贴合企业级大数据项目开发规范。
二、系统总体技术概述
2.1 技术选型依据
结合海量影视数据处理、迭代计算、机器学习建模的业务特性,本项目采用Hadoop+Spark+Hive主流大数据技术栈,选型合理性如下:
1、Hadoop:提供分布式文件存储HDFS与资源调度YARN,解决单机存储容量不足、海量数据读写缓慢、任务资源分配不均问题,支撑TB级影视数据稳定存储与批量任务调度。
2、Hive:基于Hadoop构建数据仓库,通过SQL化方式实现海量数据分层治理与统计分析,规避原生MapReduce代码繁琐、开发效率低的问题,适配影视数据规范化分层管理需求。
3、Spark:基于内存迭代计算,相较于MapReduce大幅减少磁盘IO,适合机器学习模型反复训练、协同过滤相似度计算、多维度数据聚合统计,完美适配票房预测与推荐算法的迭代计算场景。
4、Python:承担原始数据清洗、特征工程、数据预处理工作,灵活处理缺失值、异常值与特征归一化,为建模提供高质量数据集。
5、ECharts+Web:实现数据可视化大屏,动态渲染统计指标、票房走势与热门影片数据,完成数据价值可视化落地。
2.2 系统整体技术架构
系统采用四层分层架构,自上而下依次为:数据采集预处理层、数据仓库存储层、大数据计算与建模层、前端应用展示层,架构低耦合、高内聚,符合企业大数据开发规范。
1. 数据预处理层:采集猫眼电影公开数据集,通过Python完成去重、降噪、缺失值填充、特征筛选与格式统一,生成标准化结构化数据集。
2. 数据仓库存储层:基于Hive构建ODS、DWD、DWS、ADS四层数仓,依托HDFS实现分布式持久化存储,完成数据分层、治理、溯源与复用。
3. 计算建模层:基于Spark Core完成任务调度,Spark SQL实现多维数据分析,Spark MLlib实现回归预测模型与协同过滤推荐算法,是系统核心算力与智能建模核心层。
4. 应用展示层:接收后端计算统计指标,通过ECharts可视化大屏展示票房走势、影片热度、用户偏好、预测结果等核心数据。
三、开发与部署环境规范
3.1 硬件环境
本项目采用虚拟机集群搭建伪分布式大数据集群,满足学习与项目部署需求,环境配置如下:
操作系统:CentOS 7
内存配置:8G及以上
硬盘容量:50G及以上
网络环境:静态IP、集群免密互通
3.2 软件环境版本
JDK 1.8、Hadoop 2.7.x、Hive 2.3.x、Spark 2.4.x、Python 3.8、MySQL 5.7、IDEA、PyCharm、Chrome浏览器
3.3 集群基础配置流程
1、配置Linux基础环境,关闭防火墙、关闭SELinux、配置静态IP与主机名映射;
2、安装并配置JDK环境,配置全局环境变量;
3、配置集群免密登录,保障节点间数据传输与任务调度正常;
4、部署Hadoop集群,完成HDFS、YARN初始化与格式化,测试集群读写与任务调度;
5、部署Hive并配置MySQL元数据存储,避免默认derby数据库多会话冲突问题;
6、部署Spark集群,关联Hadoop YARN资源调度,完成Spark与Hive适配整合;
7、测试各组件联动,确保数据入库、SQL查询、任务运行正常。
四、Hive数据仓库详细技术设计
本项目采用行业标准四层数据仓库分层架构,针对猫眼电影业务数据进行规范化建模,解决原始数据杂乱、冗余、无法复用、难以分析的问题。
4.1 ODS原始数据层
技术功能:原样导入原始猫眼数据集,不做任何清洗与修改,保留完整原始数据,用于数据溯源与数据备份。
存储内容:电影原始信息、原始票房数据、原始用户评分、原始评论数据、未处理的行为日志数据。
技术特点:数据冗余保留、结构贴近原始数据源、支持回溯校验。
4.2 DWD明细数据层
技术功能:对ODS层数据进行清洗过滤,完成去重、缺失值处理、异常票房过滤、字段格式统一,生成高质量明细业务数据。
核心处理逻辑:删除重复影片数据、填充评分与热度缺失字段、过滤票房极值异常数据、统一上映时间与影片类型格式。
技术特点:数据标准化、无噪声、可直接用于上层统计与建模。
4.3 DWS聚合统计层
技术功能:基于DWD明细数据,按照业务维度进行聚合汇总,生成统计指标。
统计维度:影片类型维度、上映年度/档期维度、评分区间维度、热度等级维度、地区维度。
输出指标:各类型影片数量、平均票房、最高票房、评分均值、热度均值、影片数量分布。
4.4 ADS应用数据层
技术功能:面向前端展示、模型预测、推荐算法的最终应用层,存储可直接使用的结果指标数据。
包含数据:可视化大屏展示指标、模型训练特征数据集、影片相似度结果、用户偏好标签数据、票房统计汇总数据。
技术价值:减少重复计算,提升前端加载速度与模型迭代效率。
五、核心模块技术实现细节
5.1 数据预处理技术实现
本项目基于Python Pandas完成全自动化数据预处理,核心技术流程如下:
1、数据读取:批量读取猫眼电影CSV数据集,加载结构化字段;
2、重复值处理:根据电影唯一ID与电影名称去重,保留最新有效数据;
3、缺失值处理:关键字段(票房、评分、热度)缺失数据直接剔除,非关键字段采用均值、众数填充;
4、异常值处理:通过箱线图算法过滤票房极端异常数据,避免干扰模型拟合;
5、特征筛选:筛选与票房强相关的特征:影片类型、时长、评分、评论数、热度、上映档期、上映地区;
6、特征编码:对离散型文本特征进行数值编码,适配机器学习模型输入要求。
5.2 Spark多维数据分析技术实现
通过Spark SQL读取Hive分层数据表,执行分布式聚合统计,实现多维度影视数据挖掘:
1、影片热度分析:统计不同类型影片数量、平均热度、热门影片排行;
2、票房趋势分析:按年度、档期统计票房均值与总量,分析市场走势;
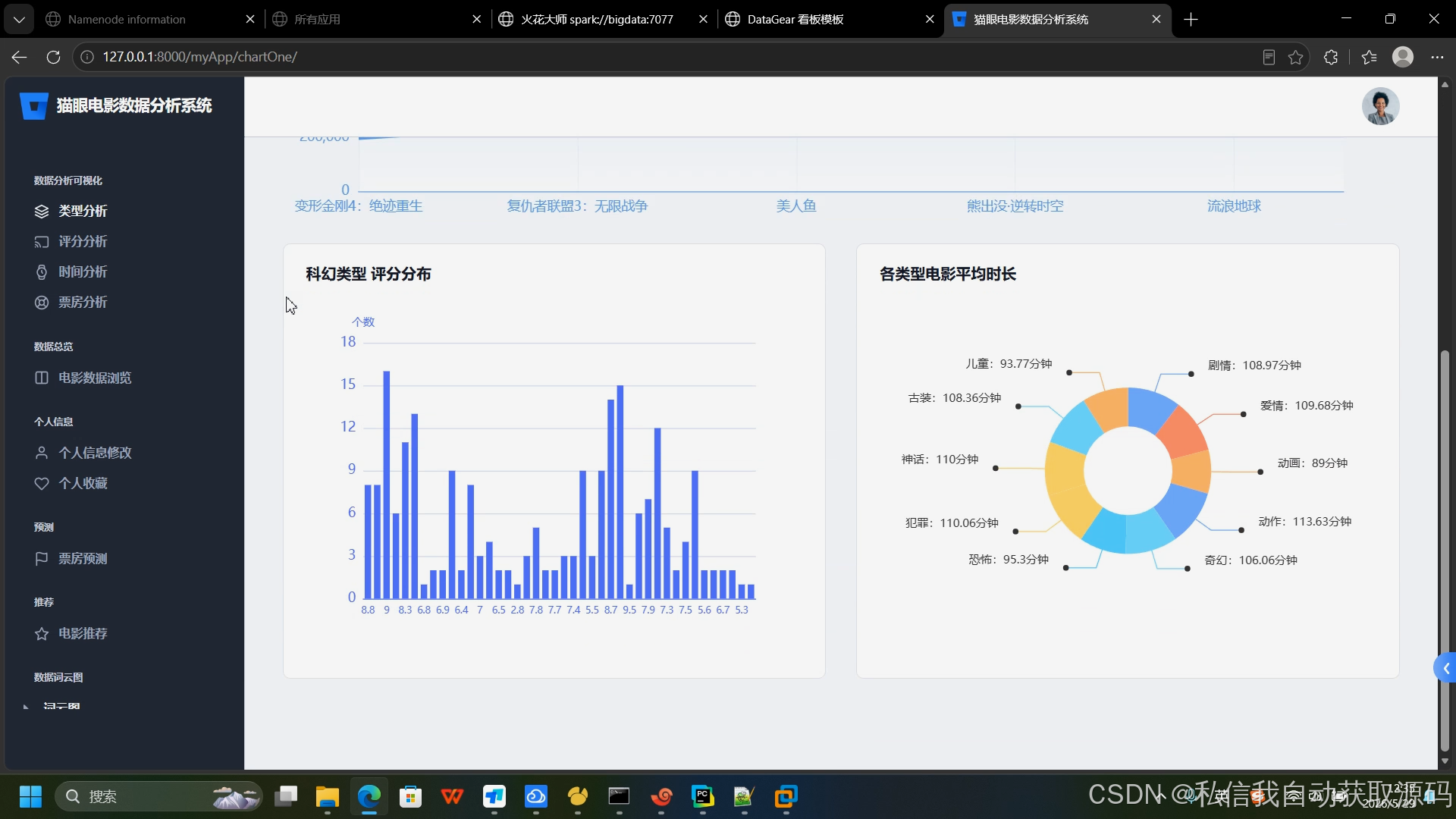
3、评分分布分析:统计不同评分区间影片数量与票房表现;
4、类型占比统计:分析主流影视类型市场占比与受众偏好。
Spark基于内存计算,相较于传统Hive SQL批量计算,大幅提升海量数据统计效率,避免频繁磁盘读写损耗。
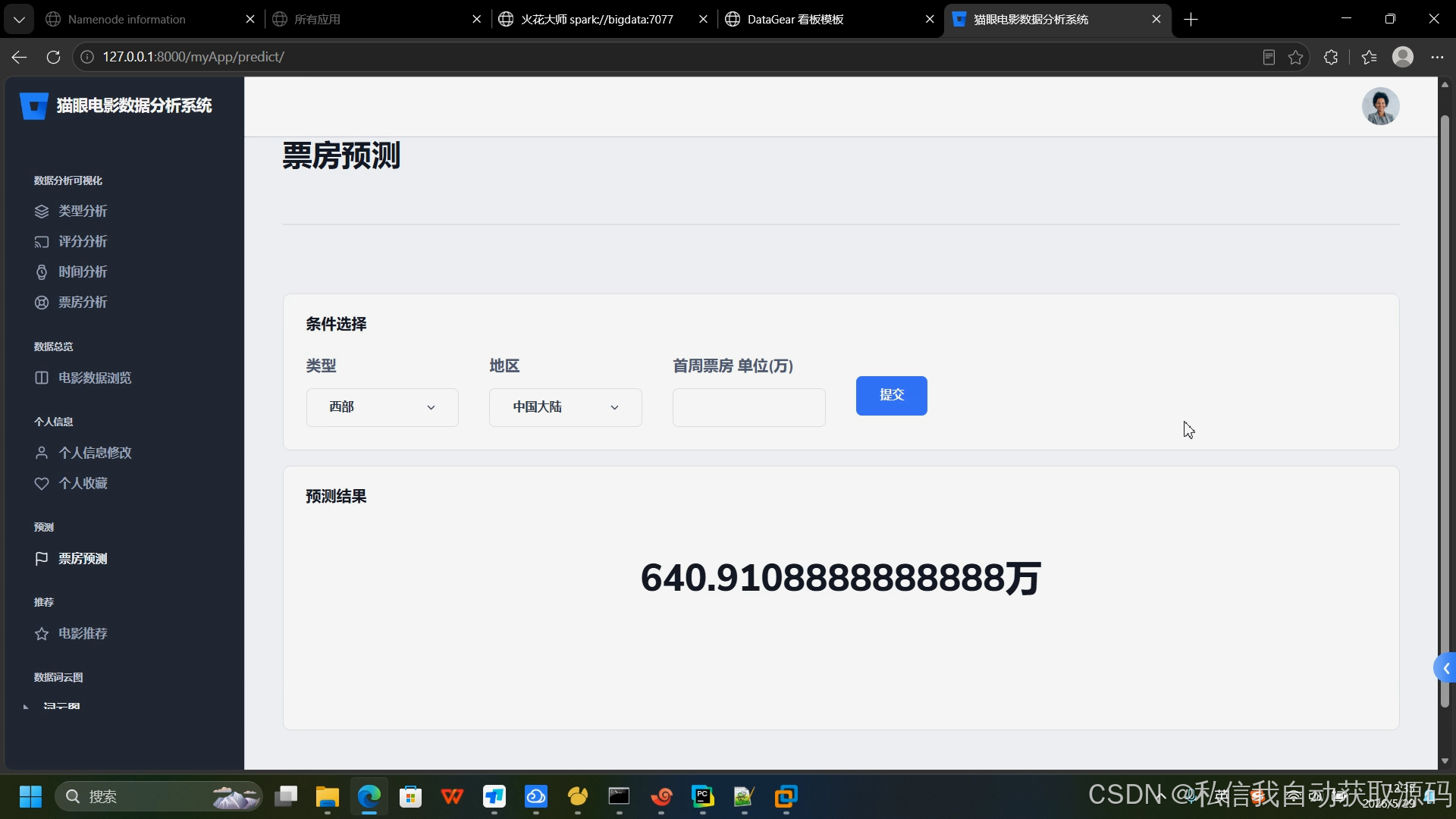
5.3 票房预测模型技术原理与实现
本系统基于Spark MLlib实现多元线性回归、随机森林回归双模型对比训练,以随机森林为最终核心预测模型。
1. 多元线性回归原理:通过拟合多维度特征与票房的线性关系,构建线性方程,实现票房数值预测,适合基础线性规律挖掘,模型简单、训练速度快。
2. 随机森林回归原理:基于多棵决策树集成学习,通过随机采样特征与样本、多树投票拟合结果,抗干扰能力强,能够精准捕捉影视特征与票房的非线性关联,适配复杂影视市场数据规律。
3. 模型训练流程:数据集划分7:3(训练集:测试集)→ 特征向量化标准化 → 模型迭代训练 → 超参数调优 → MSE、MAE、R²指标评估 → 最优模型保存落地。
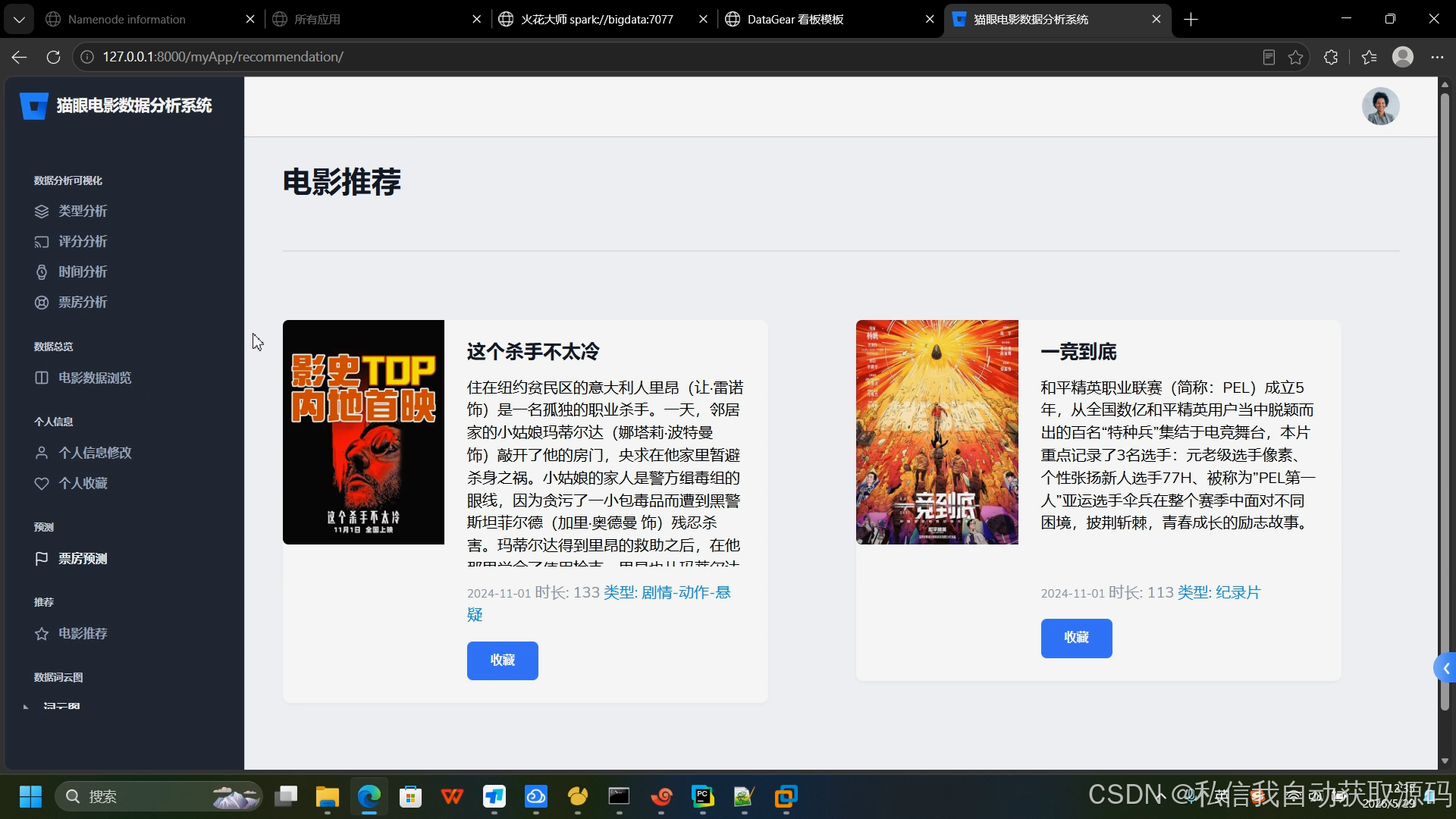
5.4 个性化推荐模块技术实现
本系统采用ItemCF基于物品的协同过滤算法,结合用户画像优化推荐效果,解决传统推荐同质化与冷启动问题。
核心原理:基于用户历史观影、评分、收藏行为,计算影片之间的相似度,为用户推荐与其偏好影片相似度高的同类影片。
技术优化点:
1、构建用户偏好标签体系,区分喜剧、科幻、动作、剧情等偏好类型;
2、基于Spark分布式并行计算影片相似度,适配海量影片数据;
3、针对新用户冷启动问题,设置热门高分影片兜底推荐策略;
4、加权过滤低热度、低评分劣质影片,提升推荐质量。
5.5 ECharts可视化技术实现
后端通过Spark SQL统计生成JSON格式结构化指标数据,前端通过AJAX异步请求数据,使用ECharts渲染多类型图表,实现数据动态可视化。包含票房年度走势折线图、影片类型占比饼图、热门影片票房柱状图、评分分布热力图、影片热度排行榜,数据实时联动、展示直观。
六、系统关键技术难点与解决方案
6.1 大数据集群适配问题
问题:Hadoop、Spark、Hive多组件版本不兼容、集群启动报错、资源调度冲突。
解决方案:统一适配稳定版本,严格规范环境变量配置,关闭冗余服务,优化YARN资源调度参数,限制单任务内存与CPU占用,保障集群稳定运行。
6.2 数据质量差、特征冗余问题
问题:原始数据噪声大、缺失值多、特征冗余,导致模型拟合效果差、预测误差高。
解决方案:精细化分层清洗,结合业务场景筛选高关联特征,完成特征标准化与归一化,剔除无效冗余特征,提升模型训练精度。
6.3 分布式计算数据倾斜问题
问题:海量数据聚合统计时出现数据倾斜,部分任务执行缓慢、集群算力不均。
解决方案:对热点key进行加盐打散,优化Spark分区策略,调整并行度参数,均衡集群任务负载,提升整体运算效率。
6.4 推荐同质化与冷启动问题
问题:传统协同过滤推荐结果单一,新用户无行为数据无法精准推荐。
解决方案:融合用户画像标签加权推荐,结合热门高分影片兜底策略,兼顾个性化与覆盖率,优化推荐体验。
七、系统性能优化方案
1、集群优化:调整YARN调度队列、优化内存分配,关闭集群冗余日志输出,提升任务运行速度。
2、数仓优化:采用分区存储、合理设置数据表字段类型,减少数据存储冗余,提升查询效率。
3、Spark计算优化:合理设置并行度、复用RDD缓存、减少重复shuffle操作,降低磁盘IO开销。
4、模型优化:通过网格搜索完成超参数调优,提升随机森林模型拟合度,降低预测误差。
5、前端优化:后端预计算聚合指标,前端异步加载图表,避免大数据量实时渲染卡顿。
八、系统测试技术指标
1、集群稳定性:连续72小时集群运行稳定,无宕机、无任务异常中断,批量数据处理任务正常执行。
2、数据处理效率:万级影视数据清洗、入库、统计耗时短,Spark迭代计算效率远优于单机处理方式。
3、模型精度指标:随机森林模型R²拟合度高,均方误差MSE、平均绝对误差MAE数值较低,票房预测结果贴合真实数据。
4、推荐效果:个性化推荐区分度明显,能够精准匹配用户观影偏好,有效解决同质化推送问题。
5、可视化体验:页面加载流畅,图表渲染正常,数据动态更新无误。
运行截图
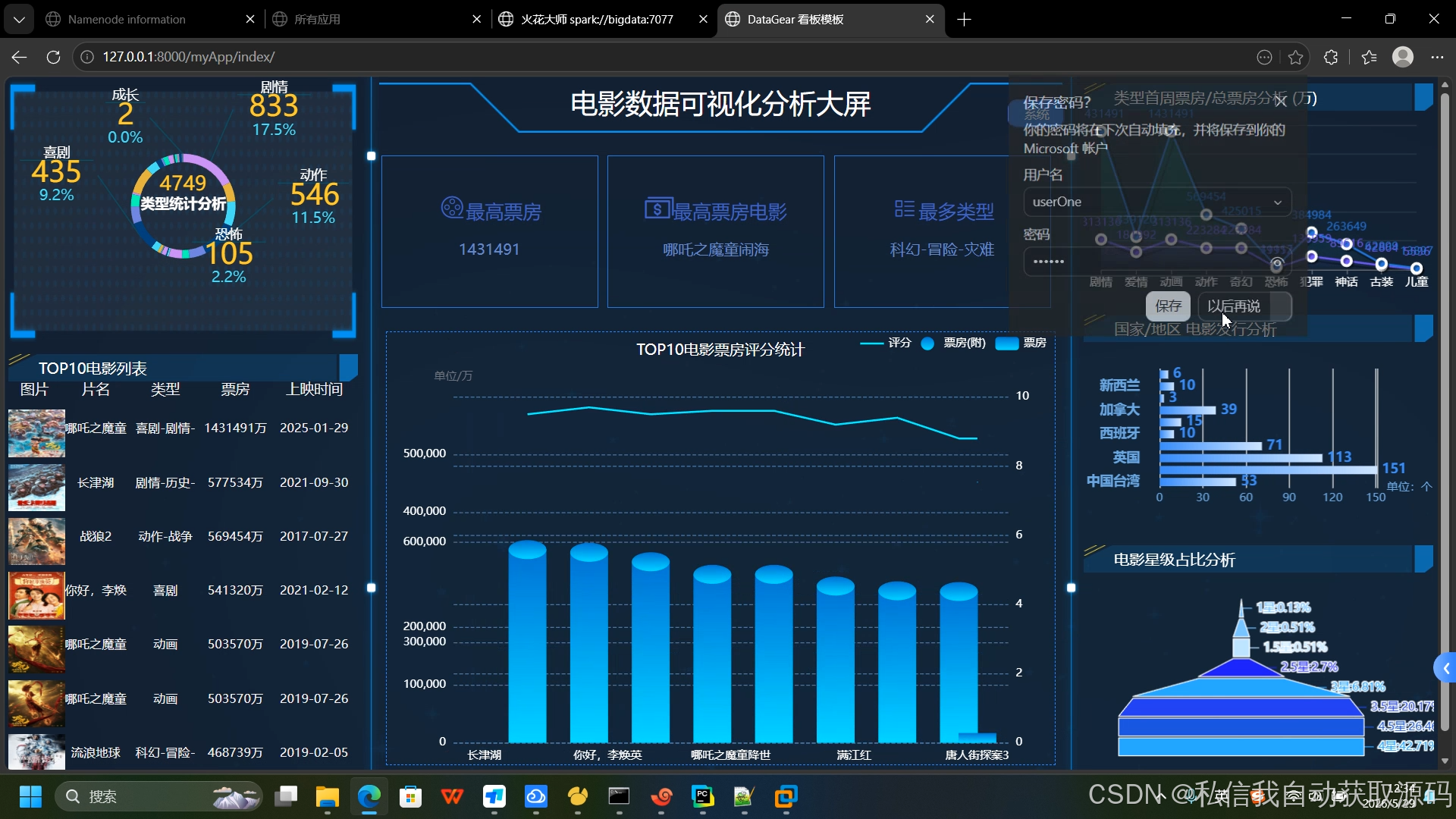
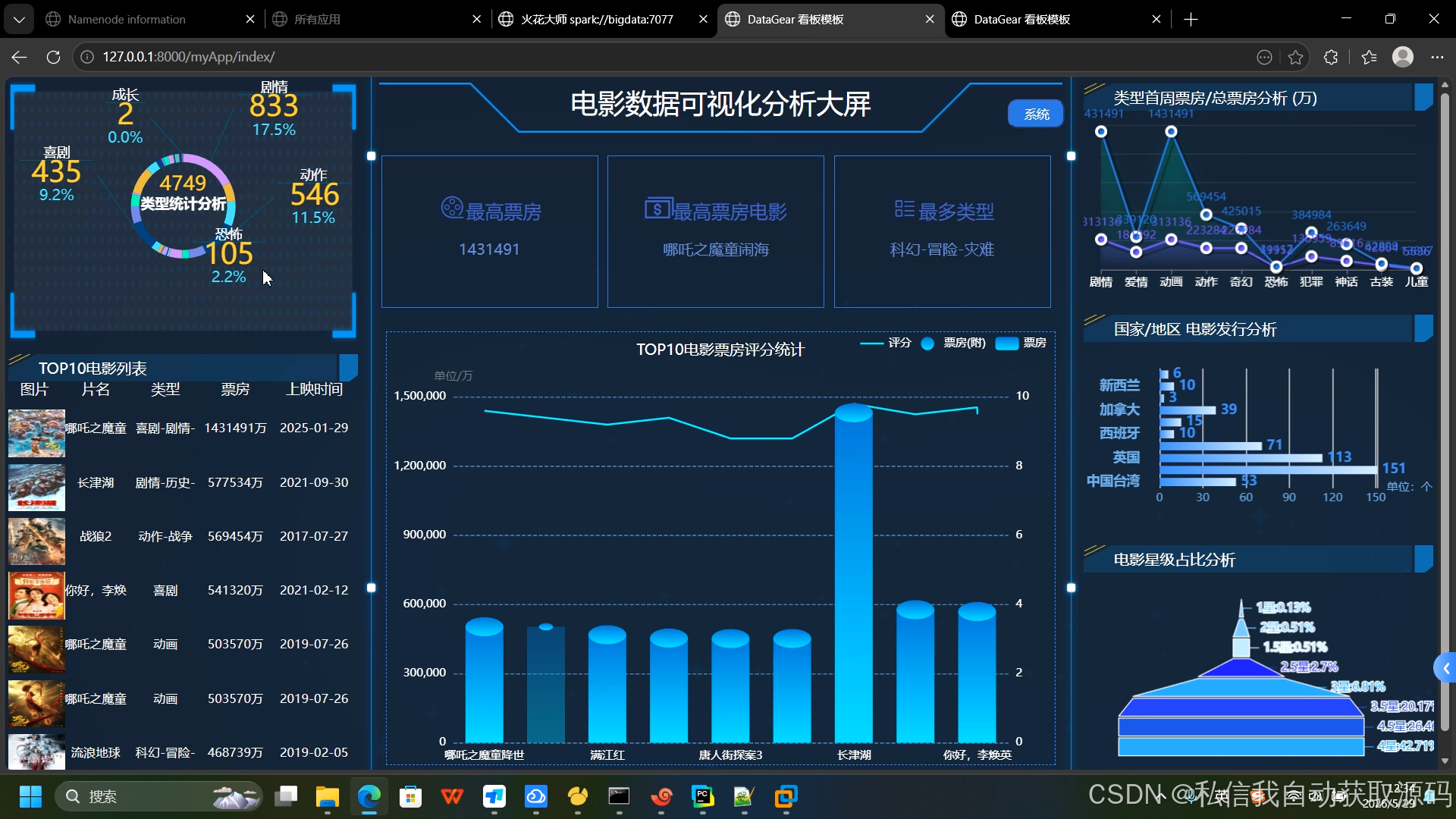
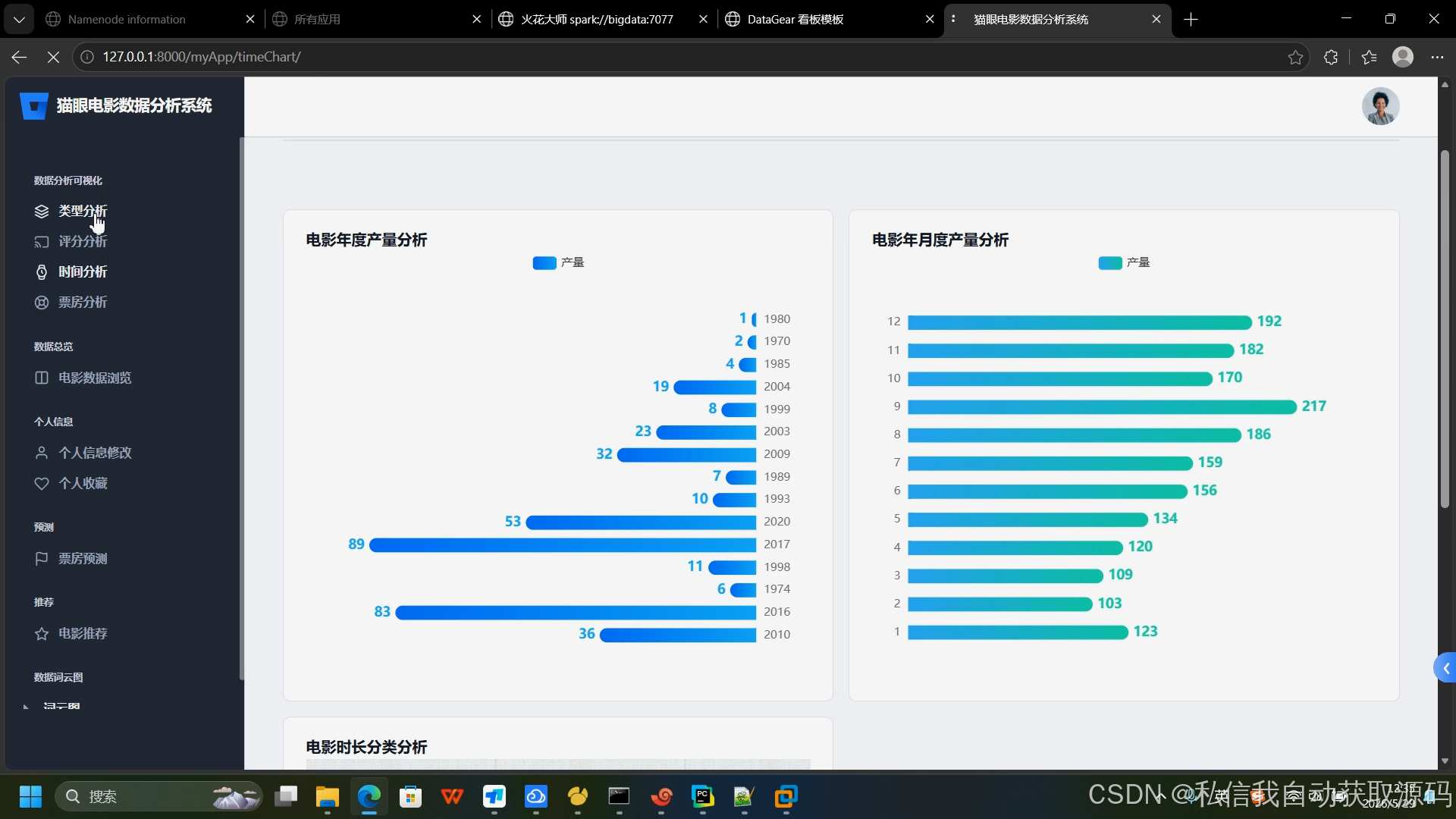
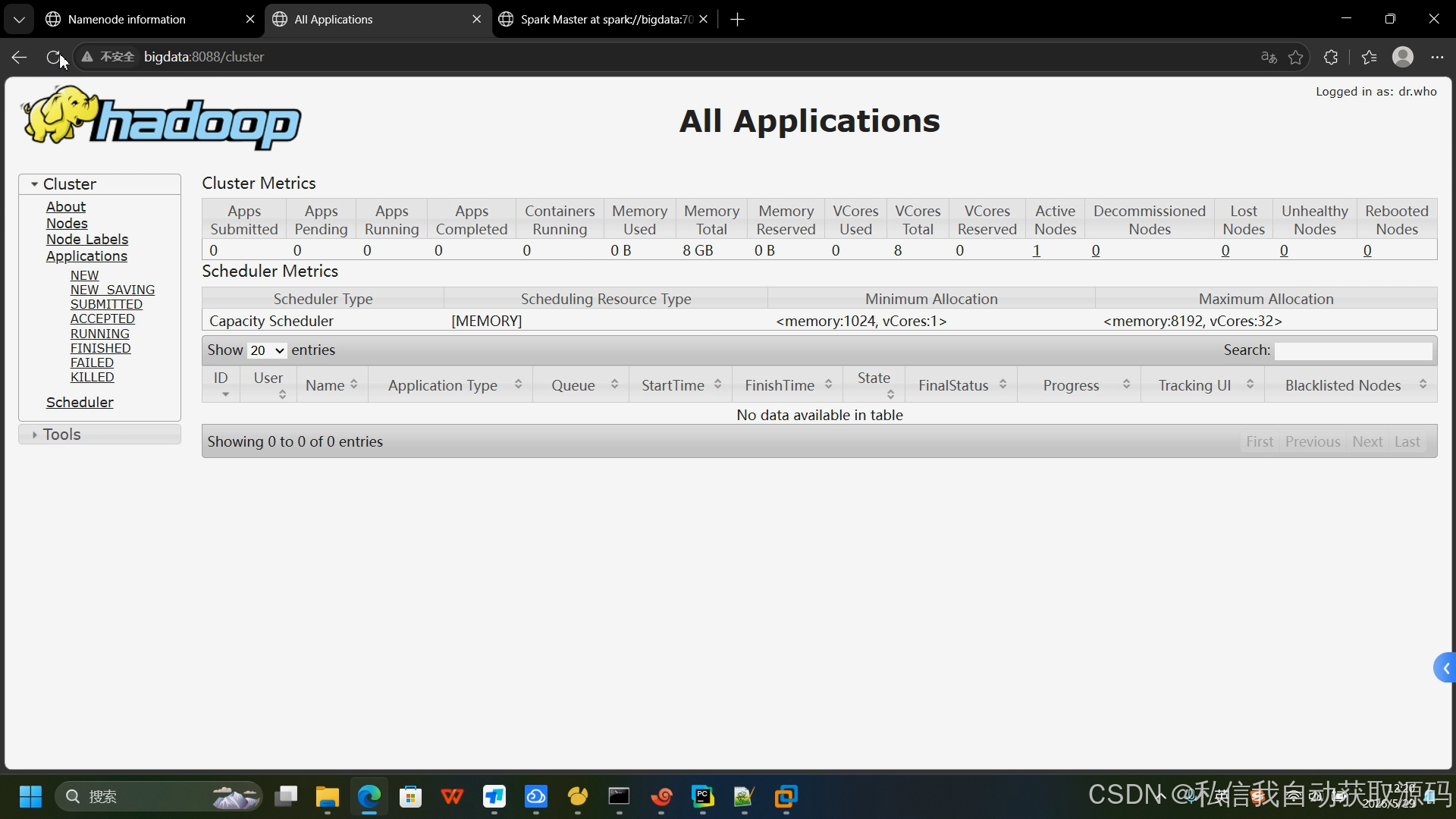
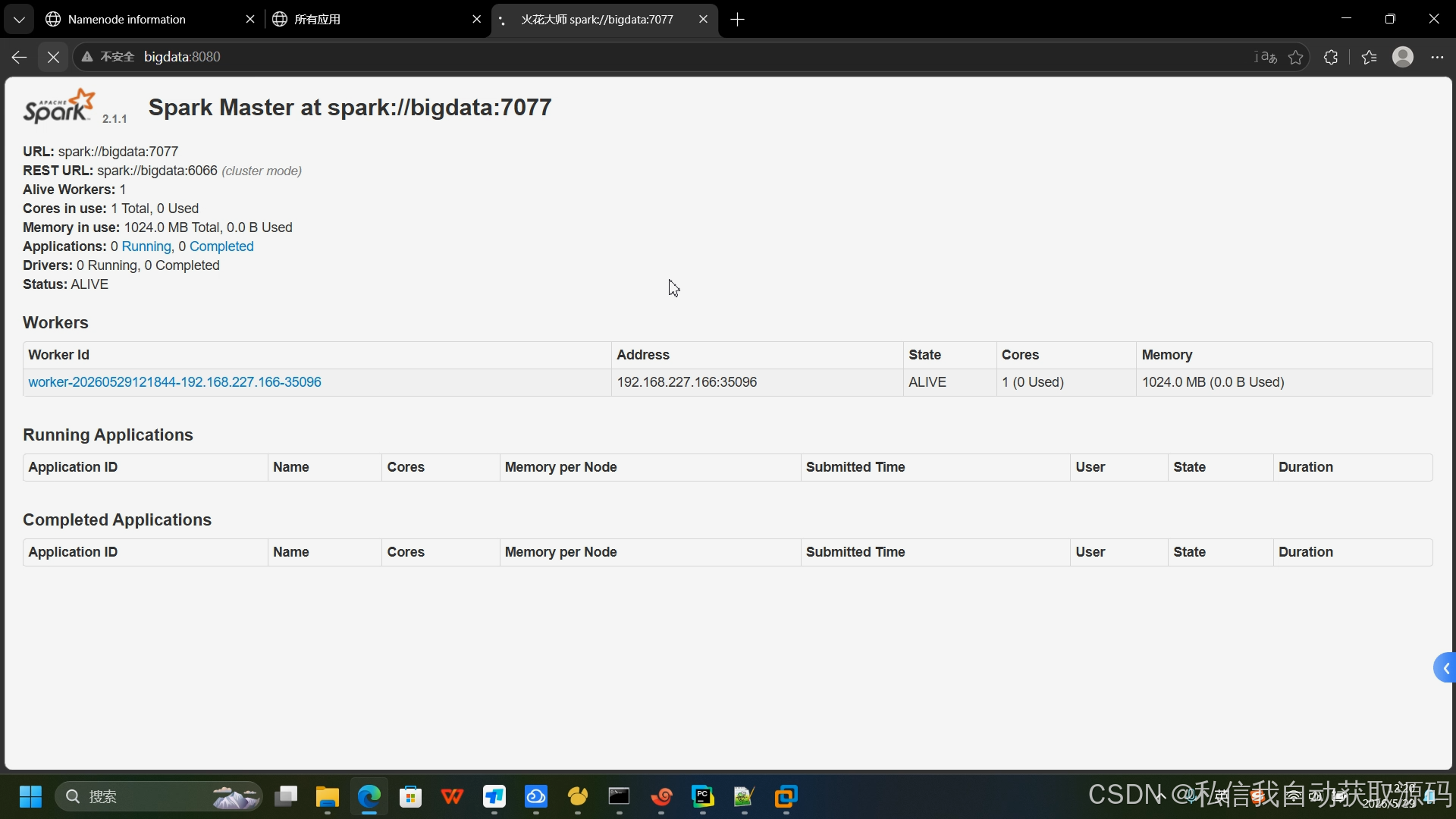
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片。🍅
点赞、收藏、关注,不迷路

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献319条内容
已为社区贡献319条内容

所有评论(0)