大模型跑分人均 90+,为什么实际用起来像弱智?聊聊 AI 榜单背后的“刷题”与真相
我相信大家在办公室里,一定经历过这种“窒息时刻”:
看厂商发布会或者科技推文的时候,那排面,锣鼓喧天鞭炮齐鸣。PPT 上的柱状图恨不得冲出屏幕顶到天花板。什么 MMLU 综合大考拿了 96 分,GSM8K 数学满分,脚踢 GPT-5.5,拳打 Claude 4.7,直接宣布人类进入 AGI 时代,明年大家集体不用上班。
结果你满怀期待地把公司的实际业务丢给它,或者只是让它帮你写一个带点拐弯逻辑的前端组件,它立马开始胡言乱语、答非所问、疯狂幻觉。
你: “帮我写一个 React 列表组件。要求:支持无限滚动,第一页加载 10 条,向下滚动时再加载 10 条。对了,后端接口有限频,用户手速太快时要加个防抖,而且要把滚动位置记录在 localStorage 里,防止页面刷新后丢失。”
跑分 95 的 AI: “没问题!这是为您生成的精美 React 组件!”
然后它啪啪啪给你甩出来一段代码。你仔细一瞅:好家伙,无限滚动没实现,倒是用 setTimeout 写了个死循环;防抖函数把页面直接搞卡死了;至于 localStorage,它确实存了,但它把整个几万行的列表数据一股脑往里塞,直接把浏览器给挤爆了……
甚至当你指出错误时,它还会用极其诚恳的语气对你说:“对不起,我是个 AI 助手,我刚才理解错了。下面是修改后的正确代码……”——然后把刚才那段一模一样的屎山代码又给你复制了一遍。
那一刻,你看着屏幕,心中只有一万匹草泥马奔腾而过,只想薅着它的领子问一句:
“不是,哥们?你在发品会上那股桀骜不驯、脚踢硅谷的劲儿,到底哪去了?!”
一、 AI 圈也普及了“应试教育”
为什么 AI 的跑分和我们的“实际体感”会产生如此巨大的买家秀与卖家秀差距?
说白了,原因就两个字:刷题。
现在的 AI 大模型,本质上是一个“超级无情的文件复读机”。它吞下了几乎整个互联网的数据。在以前,像 MMLU(考大学各学科选择题)或 HumanEval(写几行简单的 Python 填空题)确实能拉开模型的差距。
但当这些测试集变成了行业公认的“黄金标准”、全网公开免费下载之后,事情就变味了。
这就好比高考。如果考试大纲和往年真题完全公开,而且二十年不换题,那学校要做的是什么?当然是死记硬背、狂刷真题、总结套路啊!
有些厂商为了让自家模型发布时有个好看的“跑分”数据好写公关稿,在喂数据阶段,就不小心(或者故意)把这些测试集的题目和标准答案,伪装成“学习资料”喂给了AI。
考试前: 偷偷把期末考试卷子背了一百遍,连标点符号在哪都记住了。
考试时: 啪的一下,很快啊!五分钟交卷,斩获 98 分。
出社会(你用它时): 老板让你去解决一个具体的、带点逻辑陷阱的业务需求。AI 瞬间阿巴阿巴:“这题我没在黄冈密卷里见过啊……”
这就是业内饱受诟病的 “数据泄露(Data Contamination)”。它在学术上叫“过拟合高分模型”,在办公室里,我们一般管这叫“高分低能的巨婴”。
二、 2026 年,大模型圈的“反作弊风暴”
面对这种全员“王后雄五三模拟”的作弊名场面,大牛和极客们终于坐不住了。
你厂商不是喜欢刷题吗?行,那我们就把考卷难度直接拉到宇宙尽头,或者干脆不发卷子,搞盲测!
最近 AI 圈最火、大厂最怕的几个硬核新榜单,直接把那些“靠死记硬背”出来的速成模型底裤都给扒了下来:
1. Humanity’s Last Exam (HLE)
这个名字听起来就很中二——“人类的最后一届期末考”。
这是今年由前沿组织联合全球上千名博士、各领域专家专门出的“防大搜题”考卷。里面的题目涵盖量子物理、前沿生物、硬核高等数学,全都是开放性的硬核推理。
难度有多离谱?普通的理科大学生,哪怕开卷让他们去谷歌百度上搜,正确率也只有 30% 左右。
在这个榜单上,那些曾经在老题库里人均 95+ 的大模型,瞬间集体“现了原形”。今年最顶尖的推理模型(比如 OpenAI 的 5.4/5.5 系列、Gemini 的最新推理版)在上面也只能考个 40 多分。
潜台词:想在这张卷子上作弊?除非你把出卷的博士生导师本人给生吞了。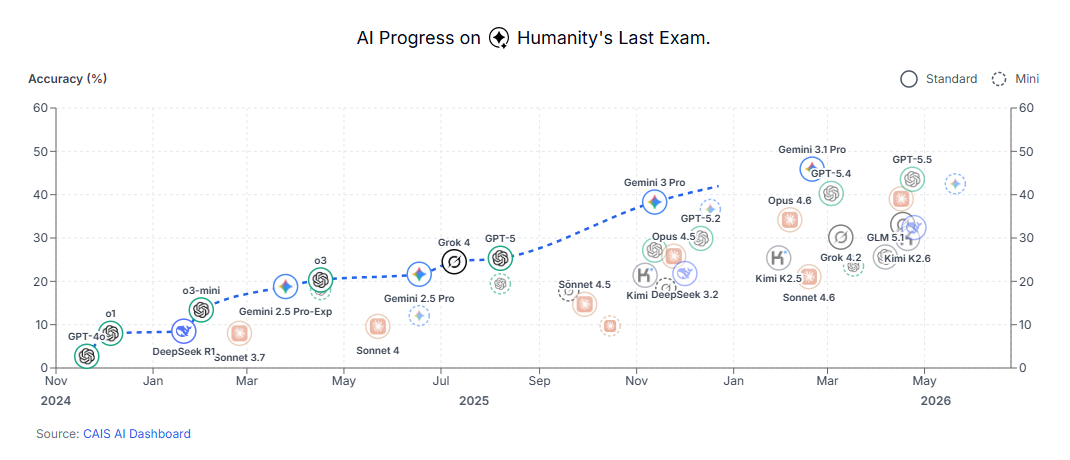
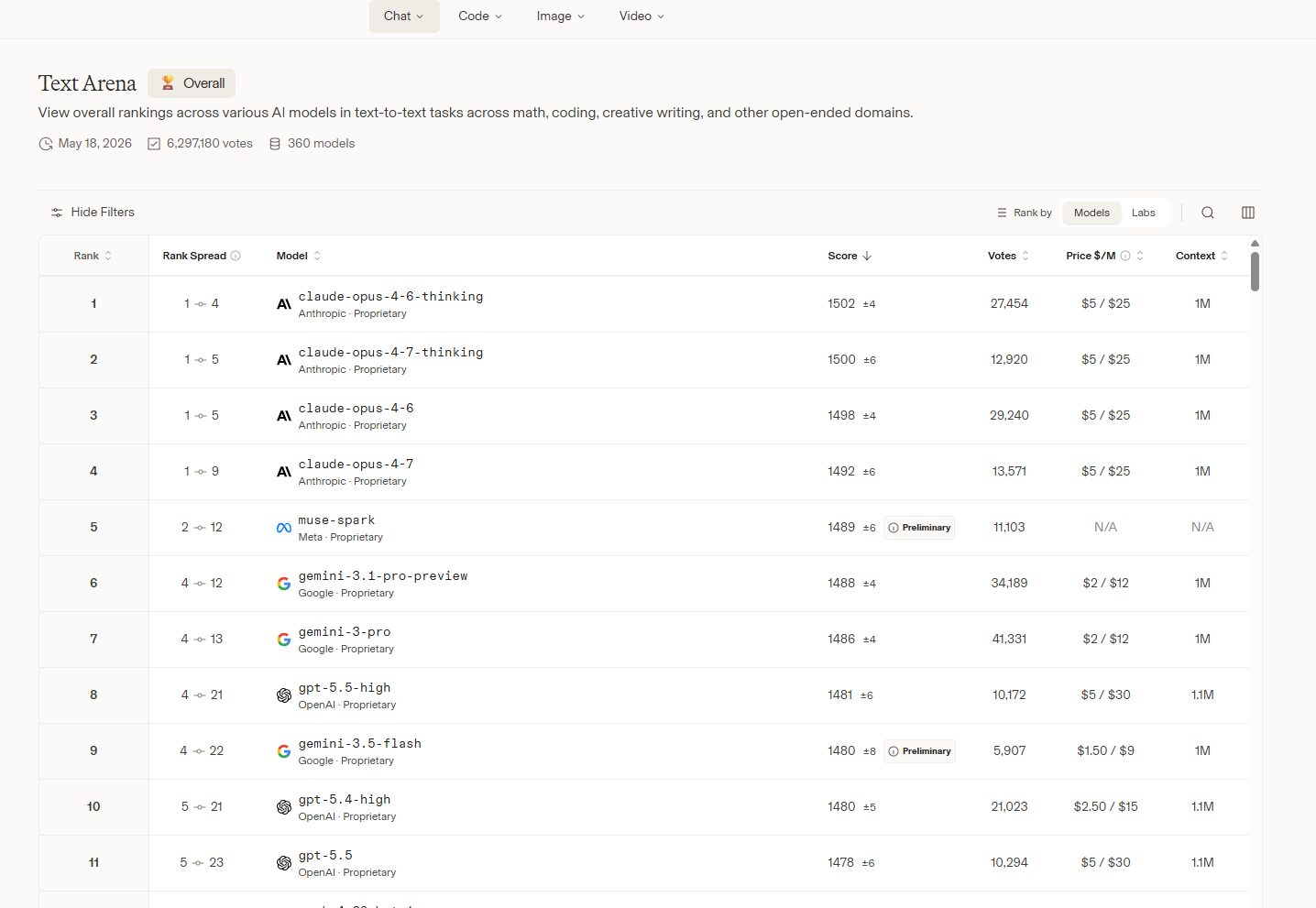
2. LMSYS Chatbot Arena
这就是现在大名鼎鼎的“赛博斗兽场”。
它彻底废除了固定试卷。玩法很简单:你在网页里输入一个你日常工作遇到的真实难题,比如:“帮我用鲁迅的语气写一封拒绝老板周末加班要求的邮件,要委婉但带点讽刺”。
系统在后台随机分配给两个匿名模型(比如模型 A 和模型 B)来作答。你看着两份答案,觉得谁回答得好,就给谁投一票。
系统通过全球真实用户、几百万次这种“盲测互殴”,用类似国际象棋的 Elo 积分算出谁才是真正的王者。
这个榜单厂商最恨,但也最怕。因为每天用户的提问千奇百怪,厂商根本没法提前给 AI 押题。在这个榜单上垫底的,那就是真不给力。
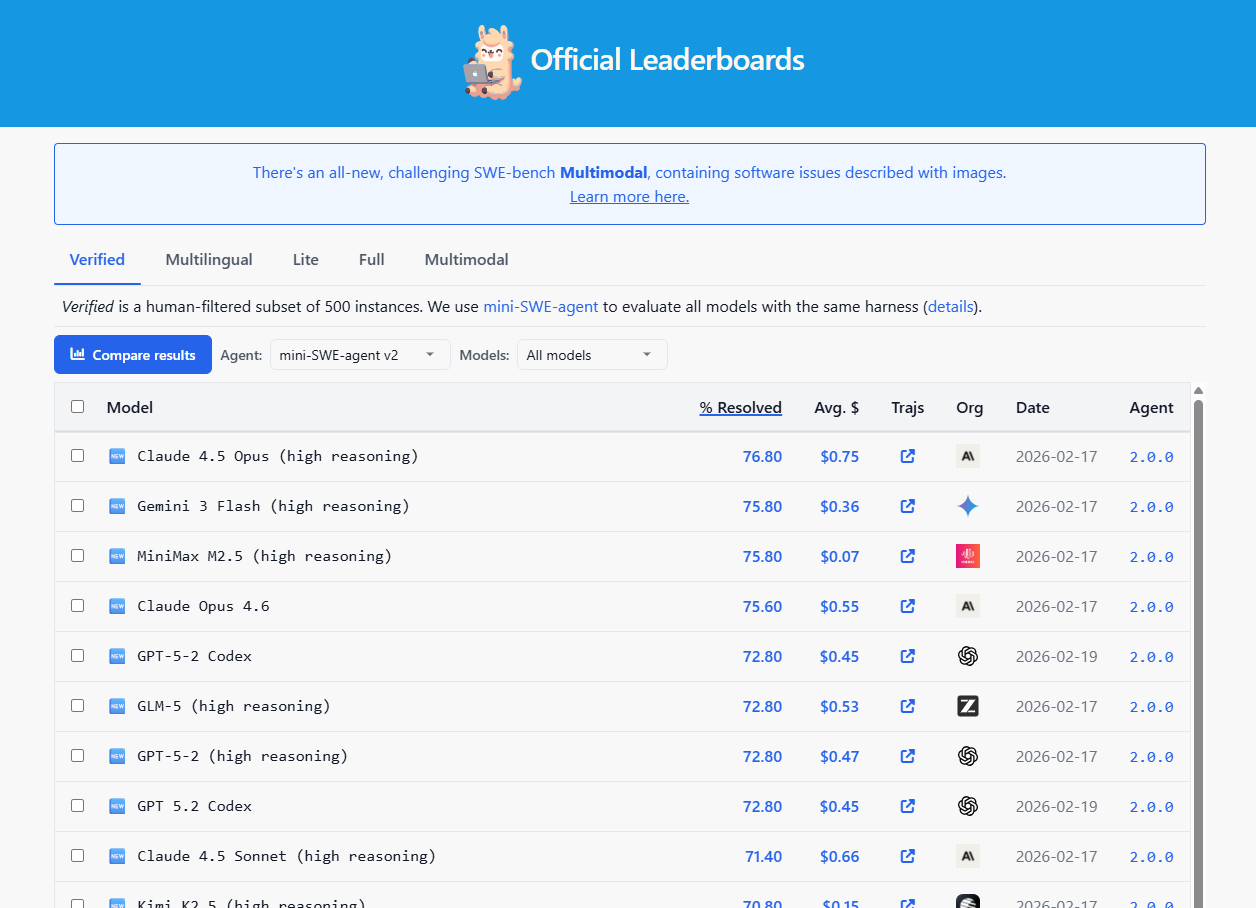
3. SWE-bench Verified
“拒绝 PPT,直接来上班”
以前的编程榜单,只考 AI 写几行 Hello World 或者简单的排序。现在的 SWE-bench 则是直接把 AI 扔进真实的 GitHub 开源项目里当苦力。
给你一万行交织在一起、不知道哪个前任程序员写的屎山代码,再给你一个真真实实存在的 Bug 报错信息。AI 必须自己去读懂整个项目结构,自己定位到是哪个文件的哪一行代码出错了,自己改掉它,并且还要跑通项目的单元测试。
能在这个榜单上拿高分的,那才是真的能帮你分担工作量、让你早点下班的“赛博义子”。
三、 避坑指南:我们该怎么看榜单?
作为产品经理、开发者或者日常需要用 AI 提效的普通人,以后看到各种铺天盖地的“跑分超越 GPT”的通稿,咱们大可不必直接高潮,保持一丝“让子弹飞一会儿”的冷漠微笑即可。
如果你在纠结自己到底该给哪家大模型充会员、或者开发产品该调用哪家的 API,建议直接看这两个:
如果你是文科生/日常办公: 比如写文案、做翻译、润色周报、做客服,别看任何学术跑分,直接去 LMSYS Chatbot Arena 看前几名是谁。那是几十万人肉测出来的“聊天体感天梯图”。
如果你是理科生/写代码/搞开发: 去看 LiveCodeBench 和 SWE-bench。这两个榜单每周都会抓取最新的 LeetCode 竞赛新题和 GitHub 新 Bug 喂给 AI,彻底斩断了厂商“偷题”的可能。谁在这上面分高,谁就是真的能干活。
总结成一句话:看学术跑分,不如看盲测天梯;听厂商吹牛,不如看它改 GitHub 屎山代码的速度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)