YOLOv10 卷积层改进:基于 FDConv(频率动态卷积) 的动态特征增强
·
一、简介
FDConv 是 CVPR 2025 提出的频率动态卷积,摒弃传统空间域造核思路,在频域构建差异化卷积核,搭配空间、频带双自适应调制,参数高效且特征表达能力更强。频率动态卷积 FDConv 以频域分组为核心,结合 IDFT、KSM、FBM 三大模块,实现卷积核动态适配,可无缝嵌入各类视觉模型。本文采用 FDConv 替换 YOLOv10 单层卷积层,借助频域解耦与动态调制能力,优化多尺度、边缘及细节特征表征。提高泛化能力和多场景适应
论文:https://arxiv.org/pdf/2503.18783
架构图:
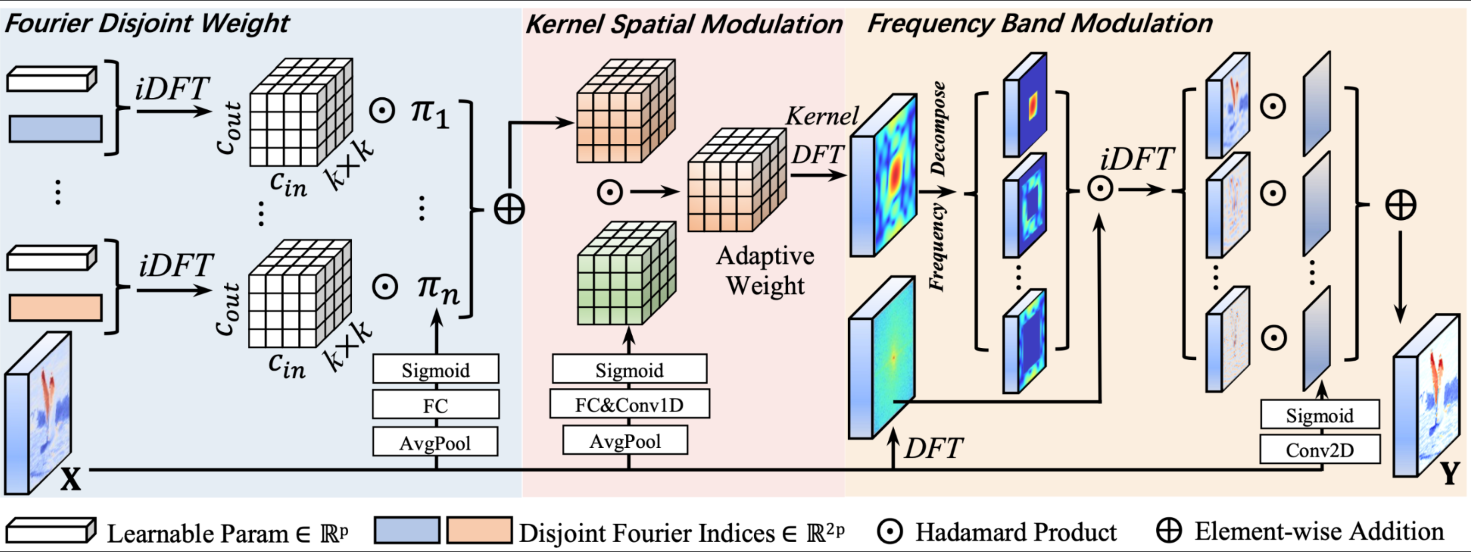
1. FDW 频域权重分组(造不同频率的核)
不同于常规卷积直接训练空间权重,FDConv 在傅里叶频域进行参数学习:
- 将频域划分为多组互不重叠的高低频带
- 每组频段独立训练专属频域权重参数
- 从根源得到频率差异极大的多组核基底(低频、高频、细节核)
2. IDFT 频域转空间域
频域参数无法直接卷积,因此通过 IDFT/IFFT:
- 将所有频域权重 还原为标准空间卷积核
- 保留各组原本的频率特性,完成 “频域设计、空间使用”
3. KSM 核空间自适应调制(调单个核内部权重)
对 IDFT 得到的每一组卷积核做动态微调:
- 通过通道维度关联 + 全局特征信息
- 生成自适应调制系数,对卷积核内部权重逐点调整
- 实现:同一个卷积核,在图像不同区域响应不同
- 平坦区域:偏向低频平滑
- 边缘纹理区域:偏向高频细节
4. FBM 频带自适应权重分配(调多个核的融合权重)
针对多组不同频率的卷积输出做智能融合:
- 利用 1×1 卷积 + Sigmoid 根据输入图像内容
- 自动预测每一个频段的空间权重图
- 对低频、中频、高频特征逐像素加权融合
二:论文原代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd
import numpy as np
import matplotlib.pyplot as plt
from numpy.linalg import matrix_rank
from torch.utils.checkpoint import checkpoint
from mmcv.cnn import CONV_LAYERS
from torch import Tensor
import torch.nn.functional as F
import math
from timm.models.layers import trunc_normal_
import time
class StarReLU(nn.Module):
"""
StarReLU: s * relu(x) ** 2 + b
"""
def __init__(self, scale_value=1.0, bias_value=0.0,
scale_learnable=True, bias_learnable=True,
mode=None, inplace=False):
super().__init__()
self.inplace = inplace
self.relu = nn.ReLU(inplace=inplace)
self.scale = nn.Parameter(scale_value * torch.ones(1),
requires_grad=scale_learnable)
self.bias = nn.Parameter(bias_value * torch.ones(1),
requires_grad=bias_learnable)
def forward(self, x):
return self.scale * self.relu(x) ** 2 + self.bias
class KernelSpatialModulation_Global(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16,
temp=1.0, kernel_temp=None, kernel_att_init='dyconv_as_extra', att_multi=2.0, ksm_only_kernel_att=False, att_grid=1, stride=1, spatial_freq_decompose=False,
act_type='sigmoid'):
super(KernelSpatialModulation_Global, self).__init__()
attention_channel = max(int(in_planes * reduction), min_channel)
self.act_type = act_type
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = temp
self.kernel_temp = kernel_temp
self.ksm_only_kernel_att = ksm_only_kernel_att
# self.temperature = nn.Parameter(torch.FloatTensor([temp]), requires_grad=True)
self.kernel_att_init = kernel_att_init
self.att_multi = att_multi
# self.kn = nn.Parameter(torch.FloatTensor([kernel_num]), requires_grad=True)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.att_grid = att_grid
self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)
# self.bn = nn.Identity()
self.bn = nn.BatchNorm2d(attention_channel)
# self.relu = nn.ReLU(inplace=True)
self.relu = StarReLU()
# self.dropout = nn.Dropout2d(p=0.1)
# self.sp_att = SpatialGate(stride=stride, out_channels=1)
# self.attup = AttUpsampler(inplane=in_planes, flow_make_k=1)
self.spatial_freq_decompose = spatial_freq_decompose
# self.channel_compress = ChannelPool()
# self.channel_spatial = BasicConv(
# # 2, 1, 7, stride=1, padding=(7 - 1) // 2, relu=False
# 2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False
# )
# self.filter_spatial = BasicConv(
# # 2, 1, 7, stride=stride, padding=(7 - 1) // 2, relu=False
# 2, 1, kernel_size, stride=stride, padding=(kernel_size - 1) // 2, relu=False
# )
if ksm_only_kernel_att:
self.func_channel = self.skip
else:
if spatial_freq_decompose:
self.channel_fc = nn.Conv2d(attention_channel, in_planes * 2 if self.kernel_size > 1 else in_planes, 1, bias=True)
else:
self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)
# self.channel_fc_bias = nn.Parameter(torch.zeros(1, in_planes, 1, 1), requires_grad=True)
self.func_channel = self.get_channel_attention
if (in_planes == groups and in_planes == out_planes) or self.ksm_only_kernel_att: # depth-wise convolution
self.func_filter = self.skip
else:
if spatial_freq_decompose:
self.filter_fc = nn.Conv2d(attention_channel, out_planes * 2, 1, stride=stride, bias=True)
else:
self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, stride=stride, bias=True)
# self.filter_fc_bias = nn.Parameter(torch.zeros(1, in_planes, 1, 1), requires_grad=True)
self.func_filter = self.get_filter_attention
if kernel_size == 1 or self.ksm_only_kernel_att: # point-wise convolution
self.func_spatial = self.skip
else:
self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)
self.func_spatial = self.get_spatial_attention
if kernel_num == 1:
self.func_kernel = self.skip
else:
# self.kernel_fc = nn.Conv2d(attention_channel, kernel_num * kernel_size * kernel_size, 1, bias=True)
self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)
self.func_kernel = self.get_kernel_attention
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
if hasattr(self, 'channel_spatial'):
nn.init.normal_(self.channel_spatial.conv.weight, std=1e-6)
if hasattr(self, 'filter_spatial'):
nn.init.normal_(self.filter_spatial.conv.weight, std=1e-6)
if hasattr(self, 'spatial_fc') and isinstance(self.spatial_fc, nn.Conv2d):
# nn.init.constant_(self.spatial_fc.weight, 0)
nn.init.normal_(self.spatial_fc.weight, std=1e-6)
# self.spatial_fc.weight *= 1e-6
if self.kernel_att_init == 'dyconv_as_extra':
pass
else:
# nn.init.constant_(self.spatial_fc.weight, 0)
# nn.init.constant_(self.spatial_fc.bias, 0)
pass
if hasattr(self, 'func_filter') and isinstance(self.func_filter, nn.Conv2d):
# nn.init.constant_(self.func_filter.weight, 0)
nn.init.normal_(self.func_filter.weight, std=1e-6)
# self.func_filter.weight *= 1e-6
if self.kernel_att_init == 'dyconv_as_extra':
pass
else:
# nn.init.constant_(self.func_filter.weight, 0)
# nn.init.constant_(self.func_filter.bias, 0)
pass
if hasattr(self, 'kernel_fc') and isinstance(self.kernel_fc, nn.Conv2d):
# nn.init.constant_(self.kernel_fc.weight, 0)
nn.init.normal_(self.kernel_fc.weight, std=1e-6)
if self.kernel_att_init == 'dyconv_as_extra':
pass
# nn.init.constant_(self.kernel_fc.weight, 0)
# nn.init.constant_(self.kernel_fc.bias, -10)
# nn.init.constant_(self.kernel_fc.weight[0], 6)
# nn.init.constant_(self.kernel_fc.weight[1:], -6)
else:
# nn.init.constant_(self.kernel_fc.weight, 0)
# nn.init.constant_(self.kernel_fc.bias, 0)
# nn.init.constant_(self.kernel_fc.bias, -10)
# nn.init.constant_(self.kernel_fc.bias[0], 10)
pass
if hasattr(self, 'channel_fc') and isinstance(self.channel_fc, nn.Conv2d):
# nn.init.constant_(self.channel_fc.weight, 0)
nn.init.normal_(self.channel_fc.weight, std=1e-6)
# nn.init.constant_(self.channel_fc.bias[1], 6)
# nn.init.constant_(self.channel_fc.bias, 0)
if self.kernel_att_init == 'dyconv_as_extra':
pass
else:
# nn.init.constant_(self.channel_fc.weight, 0)
# nn.init.constant_(self.channel_fc.bias, 0)
pass
def update_temperature(self, temperature):
self.temperature = temperature
@staticmethod
def skip(_):
return 1.0
def get_channel_attention(self, x):
if self.act_type =='sigmoid':
channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), 1, 1, -1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
elif self.act_type =='tanh':
channel_attention = 1 + torch.tanh_(self.channel_fc(x).view(x.size(0), 1, 1, -1, x.size(-2), x.size(-1)) / self.temperature) # b, kn, cout, cin, k, k
else:
raise NotImplementedError
# channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
# channel_attention = torch.sigmoid(self.channel_fc(x) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
# channel_attention = self.channel_fc(x) # b, kn, cout, cin, k, k
# channel_attention = torch.tanh_(self.channel_fc(x) / self.temperature) + 1 # b, kn, cout, cin, k, k
return channel_attention
def get_filter_attention(self, x):
if self.act_type =='sigmoid':
filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), 1, -1, 1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
elif self.act_type =='tanh':
filter_attention = 1 + torch.tanh_(self.filter_fc(x).view(x.size(0), 1, -1, 1, x.size(-2), x.size(-1)) / self.temperature) # b, kn, cout, cin, k, k
else:
raise NotImplementedError
# filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
# filter_attention = self.filter_fc(x) # b, kn, cout, cin, k, k
# filter_attention = torch.tanh_(self.filter_fc(x) / self.temperature) + 1 # b, kn, cout, cin, k, k
return filter_attention
def get_spatial_attention(self, x):
spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)
if self.act_type =='sigmoid':
spatial_attention = torch.sigmoid(spatial_attention / self.temperature) * self.att_multi
elif self.act_type =='tanh':
spatial_attention = 1 + torch.tanh_(spatial_attention / self.temperature)
else:
raise NotImplementedError
return spatial_attention
def get_kernel_attention(self, x):
# kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, self.kernel_size, self.kernel_size)
kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)
if self.act_type =='softmax':
kernel_attention = F.softmax(kernel_attention / self.kernel_temp, dim=1)
elif self.act_type =='sigmoid':
kernel_attention = torch.sigmoid(kernel_attention / self.kernel_temp) * 2 / kernel_attention.size(1)
elif self.act_type =='tanh':
kernel_attention = (1 + torch.tanh(kernel_attention / self.kernel_temp)) / kernel_attention.size(1)
else:
raise NotImplementedError
# kernel_attention = kernel_attention / self.temperature
# kernel_attention = kernel_attention / kernel_attention.abs().sum(dim=1, keepdims=True)
return kernel_attention
def forward(self, x, use_checkpoint=False):
if use_checkpoint:
return checkpoint(self._forward, x)
else:
return self._forward(x)
def _forward(self, x):
# comp_x = self.channel_compress(x)
# csg = self.channel_spatial(comp_x).sigmoid_() * self.att_multi
# csg = 1
# fsg = self.filter_spatial(comp_x).sigmoid_() * self.att_multi
# fsg = 1
# x_h = x.mean(dim=-1, keepdims=True)
# x_w = x.mean(dim=-2, keepdims=True)
# x_h = self.relu(self.bn(self.fc(x_h)))
# x_w = self.relu(self.bn(self.fc(x_w)))
# avg_x = (self.avgpool(x_h) + self.avgpool(x_w)) * 0.5
# avg_x = self.avgpool(self.relu(self.bn(self.fc(x))))
avg_x = self.relu(self.bn(self.fc(x)))
return self.func_channel(avg_x), self.func_filter(avg_x), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return self.attup.flow_warp(self.func_channel(x), grid), self.attup.flow_warp(self.func_filter(x), grid), self.func_spatial(avg_x), self.func_kernel(avg_x), sp_gate
# return (self.func_channel(x_h) * self.func_channel(x_w)).sqrt(), (self.func_filter(x_h) * self.func_filter(x_w)).sqrt(), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return (self.func_channel(x_h) * self.func_channel(x_w)), (self.func_filter(x_h) * self.func_filter(x_w)), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return ((self.func_channel(x_h) + self.func_channel(x_w)) * csg).sigmoid_() * self.att_multi, ((self.func_filter(x_h) + self.func_filter(x_w)) * fsg).sigmoid_() * self.att_multi, self.func_spatial(avg_x), self.func_kernel(avg_x)
# return (self.func_channel(x_h) * self.func_channel(x_w) * csg), (self.func_filter(x_h) * self.func_filter(x_w) * fsg), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return (self.dropout(self.func_channel(x_h) * self.func_channel(x_w))), (self.dropout(self.func_filter(x_h) * self.func_filter(x_w))), self.func_spatial(avg_x), self.func_kernel(avg_x)
# k_att = F.relu(self.func_kernel(x) - 0.8 * self.func_kernel(x_inverse))
# k_att = k_att / (k_att.sum(dim=1, keepdim=True) + 1e-8)
# return self.func_channel(x), self.func_filter(x), self.func_spatial(x), k_att
class KernelSpatialModulation_Local(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel=None, kernel_num=1, out_n=1, k_size=3, use_global=False):
super(KernelSpatialModulation_Local, self).__init__()
self.kn = kernel_num
self.out_n = out_n
self.channel = channel
if channel is not None: k_size = round((math.log2(channel) / 2) + 0.5) // 2 * 2 + 1
# self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, kernel_num * out_n, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
nn.init.constant_(self.conv.weight, 1e-6)
self.use_global = use_global
if self.use_global:
self.complex_weight = nn.Parameter(torch.randn(1, self.channel // 2 + 1 , 2, dtype=torch.float32) * 1e-6)
# self.norm = nn.GroupNorm(num_groups=32, num_channels=channel)
self.norm = nn.LayerNorm(self.channel)
# self.norm_std = nn.LayerNorm(self.channel)
# trunc_normal_(self.complex_weight, std=.02)
# self.sigmoid = nn.Sigmoid()
# nn.init.constant(self.conv.weight.data) # nn.init.normal_(self.conv.weight, std=1e-6)
# nn.init.zeros_(self.conv.weight)
def forward(self, x, x_std=None):
# feature descriptor on the global spatial information
# y = self.avg_pool(x)
# b,c,1, -> b,1,c, -> b, kn * out_n, c
# x = torch.cat([x, x_std], dim=-2)
x = x.squeeze(-1).transpose(-1, -2) # b,1,c,
b, _, c = x.shape
if self.use_global:
x_rfft = torch.fft.rfft(x.float(), dim=-1) # b, 1 or 2, c // 2 +1
# print(x_rfft.shape)
x_real = x_rfft.real * self.complex_weight[..., 0][None]
x_imag = x_rfft.imag * self.complex_weight[..., 1][None]
x = x + torch.fft.irfft(torch.view_as_complex(torch.stack([x_real, x_imag], dim=-1)), dim=-1) # b, 1, c // 2 +1
x = self.norm(x)
# x = torch.stack([self.norm(x[:, 0]), self.norm_std(x[:, 1])], dim=1)
# b,1,c, -> b, kn * out_n, c
att_logit = self.conv(x)
# print(att_logit.shape)
# print(att.shape)
# Multi-scale information fusion
# att = self.sigmoid(att) * 2
att_logit = att_logit.reshape(x.size(0), self.kn, self.out_n, c) # b, kn, k1*k2, cin
att_logit = att_logit.permute(0, 1, 3, 2) # b, kn, cin, k1*k2
# print(att_logit.shape)
return att_logit
import torch
import torch.nn as nn
import torch.nn.functional as F
class FrequencyBandModulation(nn.Module):
def __init__(self,
in_channels,
k_list=[2],
lowfreq_att=False,
fs_feat='feat',
act='sigmoid',
spatial='conv',
spatial_group=1,
spatial_kernel=3,
init='zero',
max_size=(64, 64), # 预计算mask的最大尺寸
**kwargs,
):
super().__init__()
self.k_list = k_list
self.lowfreq_att = lowfreq_att
self.in_channels = in_channels
self.fs_feat = fs_feat
self.act = act
if spatial_group > 64:
spatial_group = in_channels
self.spatial_group = spatial_group
# 构建注意力卷积层 (这部分逻辑不变)
if spatial == 'conv':
self.freq_weight_conv_list = nn.ModuleList()
_n = len(k_list)
if lowfreq_att:
_n += 1
for i in range(_n):
freq_weight_conv = nn.Conv2d(
in_channels=in_channels,
out_channels=self.spatial_group,
stride=1,
kernel_size=spatial_kernel,
groups=self.spatial_group,
padding=spatial_kernel // 2,
bias=True
)
if init == 'zero':
nn.init.normal_(freq_weight_conv.weight, std=1e-6)
if freq_weight_conv.bias is not None:
freq_weight_conv.bias.data.zero_()
self.freq_weight_conv_list.append(freq_weight_conv)
# freq_weight_conv = nn.Conv2d(
# in_channels=in_channels,
# out_channels=self.spatial_group * _n,
# stride=1,
# kernel_size=spatial_kernel,
# groups=self.spatial_group,
# padding=spatial_kernel // 2,
# bias=True
# )
# if init == 'zero':
# nn.init.normal_(freq_weight_conv.weight, std=1e-6)
# if freq_weight_conv.bias is not None:
# freq_weight_conv.bias.data.zero_()
else:
raise NotImplementedError
# 【优化核心】预计算并缓存不同频率的mask
self.register_buffer('cached_masks', self._precompute_masks(max_size, k_list), persistent=False)
def _precompute_masks(self, max_size, k_list):
"""
在初始化时预先计算一组最大尺寸的掩码。
"""
max_h, max_w = max_size
_, freq_indices = get_fft2freq(d1=max_h, d2=max_w, use_rfft=True)
# print(freq_indices.shape)
# print(freq_indices)
freq_indices = freq_indices.abs().max(dim=-1, keepdims=False)[0] # (max_h, max_w//2 + 1)
# print(freq_indices)
# freq_list = [0, *[0.5 / freq for freq in k_list], 0.5]
masks = []
for freq in k_list:
# 创建一个布尔掩码
mask = freq_indices < 0.5 / freq + 1e-8
# print(freq)
# print(mask)
masks.append(mask)
# 将列表堆叠成一个张量 (num_masks, max_h, max_w//2 + 1)
# 增加一个维度以方便广播
return torch.stack(masks, dim=0).unsqueeze(1) # (num_masks, 1, max_h, max_w//2 + 1)
def sp_act(self, freq_weight):
if self.act == 'sigmoid':
return freq_weight.sigmoid() * 2
elif self.act == 'tanh':
return 1 + freq_weight.tanh()
elif self.act == 'softmax':
return freq_weight.softmax(dim=1) * freq_weight.shape[1]
else:
raise NotImplementedError
def forward(self, x, att_feat=None):
if att_feat is None:
att_feat = x
x_list = []
x = x.to(torch.float32)
pre_x = x.clone()
b, _, h, w = x.shape
# x_fft = torch.fft.rfft2(x, norm='ortho').contiguous()
x_fft = torch.fft.rfft2(x, norm='ortho')
# 【优化核心】获取并调整缓存的mask大小
# 将缓存的mask插值到当前特征图的频域尺寸
# 注意频域尺寸是 (h, w//2 + 1)
freq_h, freq_w = h, w // 2 + 1
# 将mask从 (num_masks, 1, max_h, max_w//2+1) 转为 (num_masks, 1, h, w//2+1)
# 使用 nearest 插值,因为它对于0/1掩码来说既快速又准确
current_masks = F.interpolate(self.cached_masks.float(), size=(freq_h, freq_w), mode='nearest')
for idx, freq in enumerate(self.k_list):
# 直接从缓存中获取mask
mask = current_masks[idx]
# 应用掩码并进行逆傅里叶变换
# `s=(h,w)` 确保 irfft2 的输出尺寸与原始 `x` 匹配
low_part = torch.fft.irfft2(x_fft * mask, s=(h, w), norm='ortho')
high_part = pre_x - low_part
pre_x = low_part
# 注意力计算部分不变
freq_weight = self.freq_weight_conv_list[idx](att_feat)
freq_weight = self.sp_act(freq_weight)
# 将注意力权重和高频部分相乘
# 重塑形状以进行广播
tmp = freq_weight.reshape(b, self.spatial_group, -1, h, w) * \
high_part.reshape(b, self.spatial_group, -1, h, w)
x_list.append(tmp.reshape(b, -1, h, w))
# 处理低频部分
if self.lowfreq_att:
freq_weight = self.freq_weight_conv_list[len(self.k_list)](att_feat)
freq_weight = self.sp_act(freq_weight)
tmp = freq_weight.reshape(b, self.spatial_group, -1, h, w) * \
pre_x.reshape(b, self.spatial_group, -1, h, w)
x_list.append(tmp.reshape(b, -1, h, w))
else:
x_list.append(pre_x)
return sum(x_list)
def get_fft2freq(d1, d2, use_rfft=False):
# Frequency components for rows and columns
freq_h = torch.fft.fftfreq(d1) # Frequency for the rows (d1)
if use_rfft:
freq_w = torch.fft.rfftfreq(d2) # Frequency for the columns (d2)
else:
freq_w = torch.fft.fftfreq(d2)
# Meshgrid to create a 2D grid of frequency coordinates
freq_hw = torch.stack(torch.meshgrid(freq_h, freq_w), dim=-1)
# print(freq_hw)
# print(freq_hw.shape)
# Calculate the distance from the origin (0, 0) in the frequency space
dist = torch.norm(freq_hw, dim=-1)
# print(dist.shape)
# Sort the distances and get the indices
sorted_dist, indices = torch.sort(dist.view(-1)) # Flatten the distance tensor for sorting
# print(sorted_dist.shape)
# Get the corresponding coordinates for the sorted distances
if use_rfft:
d2 = d2 // 2 + 1
# print(d2)
sorted_coords = torch.stack([indices // d2, indices % d2], dim=-1) # Convert flat indices to 2D coords
# print(sorted_coords.shape)
# # Print sorted distances and corresponding coordinates
# for i in range(sorted_dist.shape[0]):
# print(f"Distance: {sorted_dist[i]:.4f}, Coordinates: ({sorted_coords[i, 0]}, {sorted_coords[i, 1]})")
if False:
# Plot the distance matrix as a grayscale image
plt.imshow(dist.cpu().numpy(), cmap='gray', origin='lower')
plt.colorbar()
plt.title('Frequency Domain Distance')
plt.show()
return sorted_coords.permute(1, 0), freq_hw
@CONV_LAYERS.register_module() # for mmdet, mmseg
class FDConv(nn.Conv2d):
def __init__(self,
*args,
reduction=0.0625,
kernel_num=4,
use_fdconv_if_c_gt=16, #if channel greater or equal to 16, e.g., 64, 128, 256, 512
use_fdconv_if_k_in=[1, 3], #if kernel_size in the list
use_fdconv_if_stride_in=[1], #if stride in the list
use_fbm_if_k_in=[3], #if kernel_size in the list
use_fbm_for_stride=False,
kernel_temp=1.0,
temp=None,
att_multi=2.0,
param_ratio=1,
param_reduction=1.0,
ksm_only_kernel_att=False,
att_grid=1,
use_ksm_local=True,
ksm_local_act='sigmoid',
ksm_global_act='sigmoid',
spatial_freq_decompose=False,
convert_param=True,
linear_mode=False,
fbm_cfg={
'k_list':[2, 4, 8],
'lowfreq_att':False,
'fs_feat':'feat',
'act':'sigmoid',
'spatial':'conv',
'spatial_group':1,
'spatial_kernel':3,
'init':'zero',
'global_selection':False,
},
**kwargs,
):
super().__init__(*args, **kwargs)
self.use_fdconv_if_c_gt = use_fdconv_if_c_gt
self.use_fdconv_if_k_in = use_fdconv_if_k_in
self.use_fdconv_if_stride_in = use_fdconv_if_stride_in
self.kernel_num = kernel_num
self.param_ratio = param_ratio
self.param_reduction = param_reduction
self.use_ksm_local = use_ksm_local
self.att_multi = att_multi
self.spatial_freq_decompose = spatial_freq_decompose
self.use_fbm_if_k_in = use_fbm_if_k_in
self.ksm_local_act = ksm_local_act
self.ksm_global_act = ksm_global_act
assert self.ksm_local_act in ['sigmoid', 'tanh']
assert self.ksm_global_act in ['softmax', 'sigmoid', 'tanh']
### Kernel num & Kernel temp setting
if self.kernel_num is None:
self.kernel_num = self.out_channels // 2
kernel_temp = math.sqrt(self.kernel_num * self.param_ratio)
if temp is None:
temp = kernel_temp
if min(self.in_channels, self.out_channels) <= self.use_fdconv_if_c_gt \
or self.kernel_size[0] not in self.use_fdconv_if_k_in:
return
print('*** kernel_num:', self.kernel_num)
self.alpha = min(self.out_channels, self.in_channels) // 2 * self.kernel_num * self.param_ratio / param_reduction
self.KSM_Global = KernelSpatialModulation_Global(self.in_channels, self.out_channels, self.kernel_size[0], groups=self.groups,
temp=temp,
kernel_temp=kernel_temp,
reduction=reduction, kernel_num=self.kernel_num * self.param_ratio,
kernel_att_init=None, att_multi=att_multi, ksm_only_kernel_att=ksm_only_kernel_att,
act_type=self.ksm_global_act,
att_grid=att_grid, stride=self.stride, spatial_freq_decompose=spatial_freq_decompose)
# print(use_fbm_for_stride, self.stride[0] > 1)
if self.kernel_size[0] in use_fbm_if_k_in or (use_fbm_for_stride and self.stride[0] > 1):
self.FBM = FrequencyBandModulation(self.in_channels, **fbm_cfg)
# self.channel_comp = ChannelPool(reduction=16)
if self.use_ksm_local:
self.KSM_Local = KernelSpatialModulation_Local(channel=self.in_channels, kernel_num=1, out_n=int(self.out_channels * self.kernel_size[0] * self.kernel_size[1]) )
self.linear_mode = linear_mode
self.convert2dftweight(convert_param)
def convert2dftweight(self, convert_param):
d1, d2, k1, k2 = self.out_channels, self.in_channels, self.kernel_size[0], self.kernel_size[1]
freq_indices, _ = get_fft2freq(d1 * k1, d2 * k2, use_rfft=True) # 2, d1 * k1 * (d2 * k2 // 2 + 1)
# freq_indices = freq_indices.reshape(2, self.kernel_num, -1)
weight = self.weight.permute(0, 2, 1, 3).reshape(d1 * k1, d2 * k2)
weight_rfft = torch.fft.rfft2(weight, dim=(0, 1)) # d1 * k1, d2 * k2 // 2 + 1
if self.param_reduction < 1:
# freq_indices = freq_indices[:, torch.randperm(freq_indices.size(1), generator=torch.Generator().manual_seed(freq_indices.size(1)))] # 2, indices
# freq_indices = freq_indices[:, :int(freq_indices.size(1) * self.param_reduction)] # 2, indices
num_to_keep = int(freq_indices.size(1) * self.param_reduction)
freq_indices = freq_indices[:, :num_to_keep] # 保留前 k 个最低频的索引
weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)
weight_rfft = weight_rfft[freq_indices[0, :], freq_indices[1, :]]
weight_rfft = weight_rfft.reshape(-1, 2)[None, ].repeat(self.param_ratio, 1, 1) / (min(self.out_channels, self.in_channels) // 2)
else:
weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)[None, ].repeat(self.param_ratio, 1, 1, 1) / (min(self.out_channels, self.in_channels) // 2) #param_ratio, d1, d2, k*k, 2
if convert_param:
self.dft_weight = nn.Parameter(weight_rfft, requires_grad=True)
del self.weight
else:
if self.linear_mode:
assert self.kernel_size[0] == 1 and self.kernel_size[1] == 1
self.weight = torch.nn.Parameter(self.weight.squeeze(), requires_grad=True)
indices = []
for i in range(self.param_ratio):
indices.append(freq_indices.reshape(2, self.kernel_num, -1)) # paramratio, 2, kernel_num, d1 * k1 * (d2 * k2 // 2 + 1) // kernel_num
self.register_buffer('indices', torch.stack(indices, dim=0), persistent=False)
def get_FDW(self, ):
d1, d2, k1, k2 = self.out_channels, self.in_channels, self.kernel_size[0], self.kernel_size[1]
weight = self.weight.reshape(d1, d2, k1, k2).permute(0, 2, 1, 3).reshape(d1 * k1, d2 * k2)
weight_rfft = torch.fft.rfft2(weight, dim=(0, 1)).contiguous() # d1 * k1, d2 * k2 // 2 + 1
weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)[None, ].repeat(self.param_ratio, 1, 1, 1) / (min(self.out_channels, self.in_channels) // 2) #param_ratio, d1, d2, k*k, 2
return weight_rfft
def forward(self, x):
if min(self.in_channels, self.out_channels) <= self.use_fdconv_if_c_gt or self.kernel_size[0] not in self.use_fdconv_if_k_in:
return super().forward(x)
global_x = F.adaptive_avg_pool2d(x, 1)
channel_attention, filter_attention, spatial_attention, kernel_attention = self.KSM_Global(global_x)
if self.use_ksm_local:
# global_x_std = torch.std(x, dim=(-1, -2), keepdim=True)
hr_att_logit = self.KSM_Local(global_x) # b, kn, cin, cout * ratio, k1*k2,
hr_att_logit = hr_att_logit.reshape(x.size(0), 1, self.in_channels, self.out_channels, self.kernel_size[0], self.kernel_size[1])
# hr_att_logit = hr_att_logit + self.hr_cin_bias[None, None, :, None, None, None] + self.hr_cout_bias[None, None, None, :, None, None] + self.hr_spatial_bias[None, None, None, None, :, :]
hr_att_logit = hr_att_logit.permute(0, 1, 3, 2, 4, 5)
if self.ksm_local_act == 'sigmoid':
hr_att = hr_att_logit.sigmoid() * self.att_multi
elif self.ksm_local_act == 'tanh':
hr_att = 1 + hr_att_logit.tanh()
else:
raise NotImplementedError
else:
hr_att = 1
b = x.size(0)
batch_size, in_planes, height, width = x.size()
DFT_map = torch.zeros((b, self.out_channels * self.kernel_size[0], self.in_channels * self.kernel_size[1] // 2 + 1, 2), device=x.device)
kernel_attention = kernel_attention.reshape(b, self.param_ratio, self.kernel_num, -1)
if hasattr(self, 'dft_weight'):
dft_weight = self.dft_weight
else:
dft_weight = self.get_FDW()
# print('get_FDW')
# _t0 = time.perf_counter()
for i in range(self.param_ratio):
# print(i)
# print(DFT_map.device)
indices = self.indices[i]
if self.param_reduction < 1:
w = dft_weight[i].reshape(self.kernel_num, -1, 2)[None]
DFT_map[:, indices[0, :, :], indices[1, :, :]] += torch.stack([w[..., 0] * kernel_attention[:, i], w[..., 1] * kernel_attention[:, i]], dim=-1)
else:
w = dft_weight[i][indices[0, :, :], indices[1, :, :]][None] * self.alpha # 1, kernel_num, -1, 2
# print(w.shape)
DFT_map[:, indices[0, :, :], indices[1, :, :]] += torch.stack([w[..., 0] * kernel_attention[:, i], w[..., 1] * kernel_attention[:, i]], dim=-1)
pass
# print(time.perf_counter() - _t0)
adaptive_weights = torch.fft.irfft2(torch.view_as_complex(DFT_map), dim=(1, 2)).reshape(batch_size, 1, self.out_channels, self.kernel_size[0], self.in_channels, self.kernel_size[1])
adaptive_weights = adaptive_weights.permute(0, 1, 2, 4, 3, 5)
# print(spatial_attention, channel_attention, filter_attention)
if hasattr(self, 'FBM'):
x = self.FBM(x)
# x = self.FBM(x, self.channel_comp(x))
if self.out_channels * self.in_channels * self.kernel_size[0] * self.kernel_size[1] < (in_planes + self.out_channels) * height * width:
# print(channel_attention.shape, filter_attention.shape, hr_att.shape)
aggregate_weight = spatial_attention * channel_attention * filter_attention * adaptive_weights * hr_att
# aggregate_weight = spatial_attention * channel_attention * adaptive_weights * hr_att
aggregate_weight = torch.sum(aggregate_weight, dim=1)
# print(aggregate_weight.abs().max())
aggregate_weight = aggregate_weight.view(
[-1, self.in_channels // self.groups, self.kernel_size[0], self.kernel_size[1]])
x = x.reshape(1, -1, height, width)
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
if isinstance(filter_attention, float):
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1))
else:
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1)) # * filter_attention.reshape(b, -1, 1, 1)
else:
aggregate_weight = spatial_attention * adaptive_weights * hr_att
aggregate_weight = torch.sum(aggregate_weight, dim=1)
if not isinstance(channel_attention, float):
x = x * channel_attention.view(b, -1, 1, 1)
aggregate_weight = aggregate_weight.view(
[-1, self.in_channels // self.groups, self.kernel_size[0], self.kernel_size[1]])
x = x.reshape(1, -1, height, width)
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
# if isinstance(filter_attention, torch.FloatTensor):
if isinstance(filter_attention, float):
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1))
else:
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1)) * filter_attention.view(b, -1, 1, 1)
if self.bias is not None:
output = output + self.bias.view(1, -1, 1, 1)
return output
def profile_module(
self, input: Tensor, *args, **kwargs
):
# TODO: to edit it
b_sz, c, h, w = input.shape
seq_len = h * w
# FFT iFFT
p_ff, m_ff = 0, 5 * b_sz * seq_len * int(math.log(seq_len)) * c
# others
# params = macs = sum([p.numel() for p in self.parameters()])
params = macs = self.hidden_size * self.hidden_size_factor * self.hidden_size * 2 * 2 // self.num_blocks
# // 2 min n become half after fft
macs = macs * b_sz * seq_len
# return input, params, macs
return input, params, macs + m_ff
if __name__ == '__main__':
x = torch.rand(4, 128, 64, 64) * 1
# m = ODPEConv2d(in_channels=128, out_channels=128, kernel_num=8, kernel_size=3, padding=1, mirror_weight=False, weight_residual=False, use_rfft=True)
# m = ODPEAdaptConv2d(in_channels=128, out_channels=64, kernel_num=8, kernel_size=3, padding=1, mirror_weight=False, weight_residual=False, use_rfft=True, bias=True, param_ratio=4, omni_only_kernel_att=False, use_hr_att=False, att_grid=1, stride=2, spatial_freq_decompose=False)
m = FDConv(in_channels=128, out_channels=64, kernel_num=8, kernel_size=3, padding=1, bias=True)
# m2 = DFT_Att(n=128)
print(m)
# m.convert2dftweight()
y = m(x)
print(y.shape)
pass三、yolov10主干网络P4层修改方案
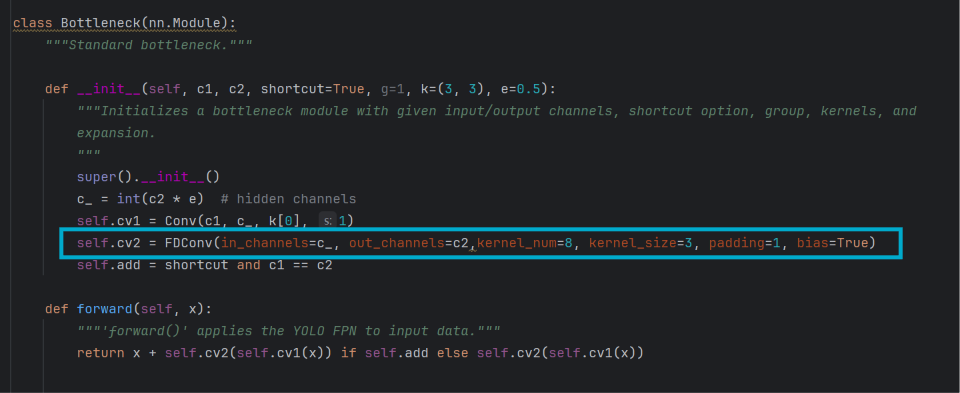
对P4层的C2f中 Bottleneck 内部cv2 层卷积进行替换,P4层负责中等尺度目标特征提取,既要捕捉物体主体轮廓,又要保留边缘、纹理等细节。FDConv依托频域建模与双自适应机制,可动态强化高低频特征表达,相比原始卷积能进一步提升多尺度特征表征能力,同时保持轻量化优势。
四、修改
修改后C2f层代码
import torch.nn as nn
import torch.autograd
import matplotlib.pyplot as plt
from torch.utils.checkpoint import checkpoint
from mmcv.cnn import CONV_LAYERS
from torch import Tensor
import math
import warnings
warnings.filterwarnings("ignore")
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class StarReLU(nn.Module):
"""
StarReLU: s * relu(x) ** 2 + b
"""
def __init__(self, scale_value=1.0, bias_value=0.0,
scale_learnable=True, bias_learnable=True,
mode=None, inplace=False):
super().__init__()
self.inplace = inplace
self.relu = nn.ReLU(inplace=inplace)
self.scale = nn.Parameter(scale_value * torch.ones(1),
requires_grad=scale_learnable)
self.bias = nn.Parameter(bias_value * torch.ones(1),
requires_grad=bias_learnable)
def forward(self, x):
return self.scale * self.relu(x) ** 2 + self.bias
class KernelSpatialModulation_Global(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16,
temp=1.0, kernel_temp=None, kernel_att_init='dyconv_as_extra', att_multi=2.0, ksm_only_kernel_att=False, att_grid=1, stride=1, spatial_freq_decompose=False,
act_type='sigmoid'):
super(KernelSpatialModulation_Global, self).__init__()
attention_channel = max(int(in_planes * reduction), min_channel)
self.act_type = act_type
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = temp
self.kernel_temp = kernel_temp
self.ksm_only_kernel_att = ksm_only_kernel_att
# self.temperature = nn.Parameter(torch.FloatTensor([temp]), requires_grad=True)
self.kernel_att_init = kernel_att_init
self.att_multi = att_multi
# self.kn = nn.Parameter(torch.FloatTensor([kernel_num]), requires_grad=True)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.att_grid = att_grid
self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)
# self.bn = nn.Identity()
self.bn = nn.BatchNorm2d(attention_channel)
# self.relu = nn.ReLU(inplace=True)
self.relu = StarReLU()
# self.dropout = nn.Dropout2d(p=0.1)
# self.sp_att = SpatialGate(stride=stride, out_channels=1)
# self.attup = AttUpsampler(inplane=in_planes, flow_make_k=1)
self.spatial_freq_decompose = spatial_freq_decompose
# self.channel_compress = ChannelPool()
# self.channel_spatial = BasicConv(
# # 2, 1, 7, stride=1, padding=(7 - 1) // 2, relu=False
# 2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False
# )
# self.filter_spatial = BasicConv(
# # 2, 1, 7, stride=stride, padding=(7 - 1) // 2, relu=False
# 2, 1, kernel_size, stride=stride, padding=(kernel_size - 1) // 2, relu=False
# )
if ksm_only_kernel_att:
self.func_channel = self.skip
else:
if spatial_freq_decompose:
self.channel_fc = nn.Conv2d(attention_channel, in_planes * 2 if self.kernel_size > 1 else in_planes, 1, bias=True)
else:
self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)
# self.channel_fc_bias = nn.Parameter(torch.zeros(1, in_planes, 1, 1), requires_grad=True)
self.func_channel = self.get_channel_attention
if (in_planes == groups and in_planes == out_planes) or self.ksm_only_kernel_att: # depth-wise convolution
self.func_filter = self.skip
else:
if spatial_freq_decompose:
self.filter_fc = nn.Conv2d(attention_channel, out_planes * 2, 1, stride=stride, bias=True)
else:
self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, stride=stride, bias=True)
# self.filter_fc_bias = nn.Parameter(torch.zeros(1, in_planes, 1, 1), requires_grad=True)
self.func_filter = self.get_filter_attention
if kernel_size == 1 or self.ksm_only_kernel_att: # point-wise convolution
self.func_spatial = self.skip
else:
self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)
self.func_spatial = self.get_spatial_attention
if kernel_num == 1:
self.func_kernel = self.skip
else:
# self.kernel_fc = nn.Conv2d(attention_channel, kernel_num * kernel_size * kernel_size, 1, bias=True)
self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)
self.func_kernel = self.get_kernel_attention
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
if hasattr(self, 'channel_spatial'):
nn.init.normal_(self.channel_spatial.conv.weight, std=1e-6)
if hasattr(self, 'filter_spatial'):
nn.init.normal_(self.filter_spatial.conv.weight, std=1e-6)
if hasattr(self, 'spatial_fc') and isinstance(self.spatial_fc, nn.Conv2d):
# nn.init.constant_(self.spatial_fc.weight, 0)
nn.init.normal_(self.spatial_fc.weight, std=1e-6)
# self.spatial_fc.weight *= 1e-6
if self.kernel_att_init == 'dyconv_as_extra':
pass
else:
# nn.init.constant_(self.spatial_fc.weight, 0)
# nn.init.constant_(self.spatial_fc.bias, 0)
pass
if hasattr(self, 'func_filter') and isinstance(self.func_filter, nn.Conv2d):
# nn.init.constant_(self.func_filter.weight, 0)
nn.init.normal_(self.func_filter.weight, std=1e-6)
# self.func_filter.weight *= 1e-6
if self.kernel_att_init == 'dyconv_as_extra':
pass
else:
# nn.init.constant_(self.func_filter.weight, 0)
# nn.init.constant_(self.func_filter.bias, 0)
pass
if hasattr(self, 'kernel_fc') and isinstance(self.kernel_fc, nn.Conv2d):
# nn.init.constant_(self.kernel_fc.weight, 0)
nn.init.normal_(self.kernel_fc.weight, std=1e-6)
if self.kernel_att_init == 'dyconv_as_extra':
pass
# nn.init.constant_(self.kernel_fc.weight, 0)
# nn.init.constant_(self.kernel_fc.bias, -10)
# nn.init.constant_(self.kernel_fc.weight[0], 6)
# nn.init.constant_(self.kernel_fc.weight[1:], -6)
else:
# nn.init.constant_(self.kernel_fc.weight, 0)
# nn.init.constant_(self.kernel_fc.bias, 0)
# nn.init.constant_(self.kernel_fc.bias, -10)
# nn.init.constant_(self.kernel_fc.bias[0], 10)
pass
if hasattr(self, 'channel_fc') and isinstance(self.channel_fc, nn.Conv2d):
# nn.init.constant_(self.channel_fc.weight, 0)
nn.init.normal_(self.channel_fc.weight, std=1e-6)
# nn.init.constant_(self.channel_fc.bias[1], 6)
# nn.init.constant_(self.channel_fc.bias, 0)
if self.kernel_att_init == 'dyconv_as_extra':
pass
else:
# nn.init.constant_(self.channel_fc.weight, 0)
# nn.init.constant_(self.channel_fc.bias, 0)
pass
def update_temperature(self, temperature):
self.temperature = temperature
@staticmethod
def skip(_):
return 1.0
def get_channel_attention(self, x):
if self.act_type =='sigmoid':
channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), 1, 1, -1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
elif self.act_type =='tanh':
channel_attention = 1 + torch.tanh_(self.channel_fc(x).view(x.size(0), 1, 1, -1, x.size(-2), x.size(-1)) / self.temperature) # b, kn, cout, cin, k, k
else:
raise NotImplementedError
# channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
# channel_attention = torch.sigmoid(self.channel_fc(x) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
# channel_attention = self.channel_fc(x) # b, kn, cout, cin, k, k
# channel_attention = torch.tanh_(self.channel_fc(x) / self.temperature) + 1 # b, kn, cout, cin, k, k
return channel_attention
def get_filter_attention(self, x):
if self.act_type =='sigmoid':
filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), 1, -1, 1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
elif self.act_type =='tanh':
filter_attention = 1 + torch.tanh_(self.filter_fc(x).view(x.size(0), 1, -1, 1, x.size(-2), x.size(-1)) / self.temperature) # b, kn, cout, cin, k, k
else:
raise NotImplementedError
# filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, x.size(-2), x.size(-1)) / self.temperature) * self.att_multi # b, kn, cout, cin, k, k
# filter_attention = self.filter_fc(x) # b, kn, cout, cin, k, k
# filter_attention = torch.tanh_(self.filter_fc(x) / self.temperature) + 1 # b, kn, cout, cin, k, k
return filter_attention
def get_spatial_attention(self, x):
spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)
if self.act_type =='sigmoid':
spatial_attention = torch.sigmoid(spatial_attention / self.temperature) * self.att_multi
elif self.act_type =='tanh':
spatial_attention = 1 + torch.tanh_(spatial_attention / self.temperature)
else:
raise NotImplementedError
return spatial_attention
def get_kernel_attention(self, x):
# kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, self.kernel_size, self.kernel_size)
kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)
if self.act_type =='softmax':
kernel_attention = F.softmax(kernel_attention / self.kernel_temp, dim=1)
elif self.act_type =='sigmoid':
kernel_attention = torch.sigmoid(kernel_attention / self.kernel_temp) * 2 / kernel_attention.size(1)
elif self.act_type =='tanh':
kernel_attention = (1 + torch.tanh(kernel_attention / self.kernel_temp)) / kernel_attention.size(1)
else:
raise NotImplementedError
# kernel_attention = kernel_attention / self.temperature
# kernel_attention = kernel_attention / kernel_attention.abs().sum(dim=1, keepdims=True)
return kernel_attention
def forward(self, x, use_checkpoint=False):
if use_checkpoint:
return checkpoint(self._forward, x)
else:
return self._forward(x)
def _forward(self, x):
# comp_x = self.channel_compress(x)
# csg = self.channel_spatial(comp_x).sigmoid_() * self.att_multi
# csg = 1
# fsg = self.filter_spatial(comp_x).sigmoid_() * self.att_multi
# fsg = 1
# x_h = x.mean(dim=-1, keepdims=True)
# x_w = x.mean(dim=-2, keepdims=True)
# x_h = self.relu(self.bn(self.fc(x_h)))
# x_w = self.relu(self.bn(self.fc(x_w)))
# avg_x = (self.avgpool(x_h) + self.avgpool(x_w)) * 0.5
# avg_x = self.avgpool(self.relu(self.bn(self.fc(x))))
if self.training and x.size(0) == 1:
out = F.batch_norm(
self.fc(x),
self.bn.running_mean,
self.bn.running_var,
self.bn.weight,
self.bn.bias,
training=False,
momentum=self.bn.momentum,
eps=self.bn.eps,
)
else:
out = self.bn(self.fc(x))
avg_x = self.relu(out)
return self.func_channel(avg_x), self.func_filter(avg_x), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return self.attup.flow_warp(self.func_channel(x), grid), self.attup.flow_warp(self.func_filter(x), grid), self.func_spatial(avg_x), self.func_kernel(avg_x), sp_gate
# return (self.func_channel(x_h) * self.func_channel(x_w)).sqrt(), (self.func_filter(x_h) * self.func_filter(x_w)).sqrt(), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return (self.func_channel(x_h) * self.func_channel(x_w)), (self.func_filter(x_h) * self.func_filter(x_w)), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return ((self.func_channel(x_h) + self.func_channel(x_w)) * csg).sigmoid_() * self.att_multi, ((self.func_filter(x_h) + self.func_filter(x_w)) * fsg).sigmoid_() * self.att_multi, self.func_spatial(avg_x), self.func_kernel(avg_x)
# return (self.func_channel(x_h) * self.func_channel(x_w) * csg), (self.func_filter(x_h) * self.func_filter(x_w) * fsg), self.func_spatial(avg_x), self.func_kernel(avg_x)
# return (self.dropout(self.func_channel(x_h) * self.func_channel(x_w))), (self.dropout(self.func_filter(x_h) * self.func_filter(x_w))), self.func_spatial(avg_x), self.func_kernel(avg_x)
# k_att = F.relu(self.func_kernel(x) - 0.8 * self.func_kernel(x_inverse))
# k_att = k_att / (k_att.sum(dim=1, keepdim=True) + 1e-8)
# return self.func_channel(x), self.func_filter(x), self.func_spatial(x), k_att
class KernelSpatialModulation_Local(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel=None, kernel_num=1, out_n=1, k_size=3, use_global=False):
super(KernelSpatialModulation_Local, self).__init__()
self.kn = kernel_num
self.out_n = out_n
self.channel = channel
if channel is not None: k_size = round((math.log2(channel) / 2) + 0.5) // 2 * 2 + 1
# self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, kernel_num * out_n, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
nn.init.constant_(self.conv.weight, 1e-6)
self.use_global = use_global
if self.use_global:
self.complex_weight = nn.Parameter(torch.randn(1, self.channel // 2 + 1 , 2, dtype=torch.float32) * 1e-6)
# self.norm = nn.GroupNorm(num_groups=32, num_channels=channel)
self.norm = nn.LayerNorm(self.channel)
# self.norm_std = nn.LayerNorm(self.channel)
# trunc_normal_(self.complex_weight, std=.02)
# self.sigmoid = nn.Sigmoid()
# nn.init.constant(self.conv.weight.data) # nn.init.normal_(self.conv.weight, std=1e-6)
# nn.init.zeros_(self.conv.weight)
def forward(self, x, x_std=None):
# feature descriptor on the global spatial information
# y = self.avg_pool(x)
# b,c,1, -> b,1,c, -> b, kn * out_n, c
# x = torch.cat([x, x_std], dim=-2)
x = x.squeeze(-1).transpose(-1, -2) # b,1,c,
b, _, c = x.shape
if self.use_global:
x_rfft = torch.fft.rfft(x.float(), dim=-1) # b, 1 or 2, c // 2 +1
# print(x_rfft.shape)
x_real = x_rfft.real * self.complex_weight[..., 0][None]
x_imag = x_rfft.imag * self.complex_weight[..., 1][None]
x = x + torch.fft.irfft(torch.view_as_complex(torch.stack([x_real, x_imag], dim=-1)), dim=-1) # b, 1, c // 2 +1
x = self.norm(x)
# x = torch.stack([self.norm(x[:, 0]), self.norm_std(x[:, 1])], dim=1)
# b,1,c, -> b, kn * out_n, c
att_logit = self.conv(x)
# print(att_logit.shape)
# print(att.shape)
# Multi-scale information fusion
# att = self.sigmoid(att) * 2
att_logit = att_logit.reshape(x.size(0), self.kn, self.out_n, c) # b, kn, k1*k2, cin
att_logit = att_logit.permute(0, 1, 3, 2) # b, kn, cin, k1*k2
# print(att_logit.shape)
return att_logit
import torch
import torch.nn as nn
import torch.nn.functional as F
class FrequencyBandModulation(nn.Module):
def __init__(self,
in_channels,
k_list=[2],
lowfreq_att=False,
fs_feat='feat',
act='sigmoid',
spatial='conv',
spatial_group=1,
spatial_kernel=3,
init='zero',
max_size=(64, 64), # 预计算mask的最大尺寸
**kwargs,
):
super().__init__()
self.k_list = k_list
self.lowfreq_att = lowfreq_att
self.in_channels = in_channels
self.fs_feat = fs_feat
self.act = act
if spatial_group > 64:
spatial_group = in_channels
self.spatial_group = spatial_group
# 构建注意力卷积层 (这部分逻辑不变)
if spatial == 'conv':
self.freq_weight_conv_list = nn.ModuleList()
_n = len(k_list)
if lowfreq_att:
_n += 1
for i in range(_n):
freq_weight_conv = nn.Conv2d(
in_channels=in_channels,
out_channels=self.spatial_group,
stride=1,
kernel_size=spatial_kernel,
groups=self.spatial_group,
padding=spatial_kernel // 2,
bias=True
)
if init == 'zero':
nn.init.normal_(freq_weight_conv.weight, std=1e-6)
if freq_weight_conv.bias is not None:
freq_weight_conv.bias.data.zero_()
self.freq_weight_conv_list.append(freq_weight_conv)
# freq_weight_conv = nn.Conv2d(
# in_channels=in_channels,
# out_channels=self.spatial_group * _n,
# stride=1,
# kernel_size=spatial_kernel,
# groups=self.spatial_group,
# padding=spatial_kernel // 2,
# bias=True
# )
# if init == 'zero':
# nn.init.normal_(freq_weight_conv.weight, std=1e-6)
# if freq_weight_conv.bias is not None:
# freq_weight_conv.bias.data.zero_()
else:
raise NotImplementedError
# 【优化核心】预计算并缓存不同频率的mask
self.register_buffer('cached_masks', self._precompute_masks(max_size, k_list), persistent=False)
def _precompute_masks(self, max_size, k_list):
"""
在初始化时预先计算一组最大尺寸的掩码。
"""
max_h, max_w = max_size
_, freq_indices = get_fft2freq(d1=max_h, d2=max_w, use_rfft=True)
# print(freq_indices.shape)
# print(freq_indices)
freq_indices = freq_indices.abs().max(dim=-1, keepdims=False)[0] # (max_h, max_w//2 + 1)
# print(freq_indices)
# freq_list = [0, *[0.5 / freq for freq in k_list], 0.5]
masks = []
for freq in k_list:
# 创建一个布尔掩码
mask = freq_indices < 0.5 / freq + 1e-8
# print(freq)
# print(mask)
masks.append(mask)
# 将列表堆叠成一个张量 (num_masks, max_h, max_w//2 + 1)
# 增加一个维度以方便广播
return torch.stack(masks, dim=0).unsqueeze(1) # (num_masks, 1, max_h, max_w//2 + 1)
def sp_act(self, freq_weight):
if self.act == 'sigmoid':
return freq_weight.sigmoid() * 2
elif self.act == 'tanh':
return 1 + freq_weight.tanh()
elif self.act == 'softmax':
return freq_weight.softmax(dim=1) * freq_weight.shape[1]
else:
raise NotImplementedError
def forward(self, x, att_feat=None):
if att_feat is None:
att_feat = x
x_list = []
x = x.to(torch.float32)
pre_x = x.clone()
b, _, h, w = x.shape
# x_fft = torch.fft.rfft2(x, norm='ortho').contiguous()
x_fft = torch.fft.rfft2(x, norm='ortho')
# 【优化核心】获取并调整缓存的mask大小
# 将缓存的mask插值到当前特征图的频域尺寸
# 注意频域尺寸是 (h, w//2 + 1)
freq_h, freq_w = h, w // 2 + 1
# 将mask从 (num_masks, 1, max_h, max_w//2+1) 转为 (num_masks, 1, h, w//2+1)
# 使用 nearest 插值,因为它对于0/1掩码来说既快速又准确
current_masks = F.interpolate(self.cached_masks.float(), size=(freq_h, freq_w), mode='nearest')
for idx, freq in enumerate(self.k_list):
# 直接从缓存中获取mask
mask = current_masks[idx]
# 应用掩码并进行逆傅里叶变换
# `s=(h,w)` 确保 irfft2 的输出尺寸与原始 `x` 匹配
low_part = torch.fft.irfft2(x_fft * mask, s=(h, w), norm='ortho')
high_part = pre_x - low_part
pre_x = low_part
# 注意力计算部分不变
freq_weight = self.freq_weight_conv_list[idx](att_feat)
freq_weight = self.sp_act(freq_weight)
# 将注意力权重和高频部分相乘
# 重塑形状以进行广播
tmp = freq_weight.reshape(b, self.spatial_group, -1, h, w) * \
high_part.reshape(b, self.spatial_group, -1, h, w)
x_list.append(tmp.reshape(b, -1, h, w))
# 处理低频部分
if self.lowfreq_att:
freq_weight = self.freq_weight_conv_list[len(self.k_list)](att_feat)
freq_weight = self.sp_act(freq_weight)
tmp = freq_weight.reshape(b, self.spatial_group, -1, h, w) * \
pre_x.reshape(b, self.spatial_group, -1, h, w)
x_list.append(tmp.reshape(b, -1, h, w))
else:
x_list.append(pre_x)
return sum(x_list)
def get_fft2freq(d1, d2, use_rfft=False):
# Frequency components for rows and columns
freq_h = torch.fft.fftfreq(d1) # Frequency for the rows (d1)
if use_rfft:
freq_w = torch.fft.rfftfreq(d2) # Frequency for the columns (d2)
else:
freq_w = torch.fft.fftfreq(d2)
# Meshgrid to create a 2D grid of frequency coordinates
freq_hw = torch.stack(torch.meshgrid(freq_h, freq_w), dim=-1)
# print(freq_hw)
# print(freq_hw.shape)
# Calculate the distance from the origin (0, 0) in the frequency space
dist = torch.norm(freq_hw, dim=-1)
# print(dist.shape)
# Sort the distances and get the indices
sorted_dist, indices = torch.sort(dist.view(-1)) # Flatten the distance tensor for sorting
# print(sorted_dist.shape)
# Get the corresponding coordinates for the sorted distances
if use_rfft:
d2 = d2 // 2 + 1
# print(d2)
sorted_coords = torch.stack([indices // d2, indices % d2], dim=-1) # Convert flat indices to 2D coords
# print(sorted_coords.shape)
# # Print sorted distances and corresponding coordinates
# for i in range(sorted_dist.shape[0]):
# print(f"Distance: {sorted_dist[i]:.4f}, Coordinates: ({sorted_coords[i, 0]}, {sorted_coords[i, 1]})")
if False:
# Plot the distance matrix as a grayscale image
plt.imshow(dist.cpu().numpy(), cmap='gray', origin='lower')
plt.colorbar()
plt.title('Frequency Domain Distance')
plt.show()
return sorted_coords.permute(1, 0), freq_hw
@CONV_LAYERS.register_module() # for mmdet, mmseg
class FDConv(nn.Conv2d):
def __init__(self,
*args,
reduction=0.0625,
kernel_num=4,
use_fdconv_if_c_gt=16, #if channel greater or equal to 16, e.g., 64, 128, 256, 512
use_fdconv_if_k_in=[1, 3], #if kernel_size in the list
use_fdconv_if_stride_in=[1], #if stride in the list
use_fbm_if_k_in=[3], #if kernel_size in the list
use_fbm_for_stride=False,
kernel_temp=1.0,
temp=None,
att_multi=2.0,
param_ratio=1,
param_reduction=1.0,
ksm_only_kernel_att=False,
att_grid=1,
use_ksm_local=True,
ksm_local_act='sigmoid',
ksm_global_act='sigmoid',
spatial_freq_decompose=False,
convert_param=True,
linear_mode=False,
fbm_cfg={
'k_list':[2, 4, 8],
'lowfreq_att':False,
'fs_feat':'feat',
'act':'sigmoid',
'spatial':'conv',
'spatial_group':1,
'spatial_kernel':3,
'init':'zero',
'global_selection':False,
},
**kwargs,
):
super().__init__(*args, **kwargs)
self.use_fdconv_if_c_gt = use_fdconv_if_c_gt
self.use_fdconv_if_k_in = use_fdconv_if_k_in
self.use_fdconv_if_stride_in = use_fdconv_if_stride_in
self.kernel_num = kernel_num
self.param_ratio = param_ratio
self.param_reduction = param_reduction
self.use_ksm_local = use_ksm_local
self.att_multi = att_multi
self.spatial_freq_decompose = spatial_freq_decompose
self.use_fbm_if_k_in = use_fbm_if_k_in
self.ksm_local_act = ksm_local_act
self.ksm_global_act = ksm_global_act
assert self.ksm_local_act in ['sigmoid', 'tanh']
assert self.ksm_global_act in ['softmax', 'sigmoid', 'tanh']
### Kernel num & Kernel temp setting
if self.kernel_num is None:
self.kernel_num = self.out_channels // 2
kernel_temp = math.sqrt(self.kernel_num * self.param_ratio)
if temp is None:
temp = kernel_temp
if min(self.in_channels, self.out_channels) <= self.use_fdconv_if_c_gt \
or self.kernel_size[0] not in self.use_fdconv_if_k_in:
return
# print('*** kernel_num:', self.kernel_num)
self.alpha = min(self.out_channels, self.in_channels) // 2 * self.kernel_num * self.param_ratio / param_reduction
self.KSM_Global = KernelSpatialModulation_Global(self.in_channels, self.out_channels, self.kernel_size[0], groups=self.groups,
temp=temp,
kernel_temp=kernel_temp,
reduction=reduction, kernel_num=self.kernel_num * self.param_ratio,
kernel_att_init=None, att_multi=att_multi, ksm_only_kernel_att=ksm_only_kernel_att,
act_type=self.ksm_global_act,
att_grid=att_grid, stride=self.stride, spatial_freq_decompose=spatial_freq_decompose)
# print(use_fbm_for_stride, self.stride[0] > 1)
if self.kernel_size[0] in use_fbm_if_k_in or (use_fbm_for_stride and self.stride[0] > 1):
self.FBM = FrequencyBandModulation(self.in_channels, **fbm_cfg)
# self.channel_comp = ChannelPool(reduction=16)
if self.use_ksm_local:
self.KSM_Local = KernelSpatialModulation_Local(channel=self.in_channels, kernel_num=1, out_n=int(self.out_channels * self.kernel_size[0] * self.kernel_size[1]) )
self.linear_mode = linear_mode
self.convert2dftweight(convert_param)
def convert2dftweight(self, convert_param):
d1, d2, k1, k2 = self.out_channels, self.in_channels, self.kernel_size[0], self.kernel_size[1]
freq_indices, _ = get_fft2freq(d1 * k1, d2 * k2, use_rfft=True) # 2, d1 * k1 * (d2 * k2 // 2 + 1)
# freq_indices = freq_indices.reshape(2, self.kernel_num, -1)
weight = self.weight.permute(0, 2, 1, 3).reshape(d1 * k1, d2 * k2)
weight_rfft = torch.fft.rfft2(weight, dim=(0, 1)) # d1 * k1, d2 * k2 // 2 + 1
if self.param_reduction < 1:
# freq_indices = freq_indices[:, torch.randperm(freq_indices.size(1), generator=torch.Generator().manual_seed(freq_indices.size(1)))] # 2, indices
# freq_indices = freq_indices[:, :int(freq_indices.size(1) * self.param_reduction)] # 2, indices
num_to_keep = int(freq_indices.size(1) * self.param_reduction)
freq_indices = freq_indices[:, :num_to_keep] # 保留前 k 个最低频的索引
weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)
weight_rfft = weight_rfft[freq_indices[0, :], freq_indices[1, :]]
weight_rfft = weight_rfft.reshape(-1, 2)[None, ].repeat(self.param_ratio, 1, 1) / (min(self.out_channels, self.in_channels) // 2)
else:
weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)[None, ].repeat(self.param_ratio, 1, 1, 1) / (min(self.out_channels, self.in_channels) // 2) #param_ratio, d1, d2, k*k, 2
if convert_param:
self.dft_weight = nn.Parameter(weight_rfft, requires_grad=True)
del self.weight
else:
if self.linear_mode:
assert self.kernel_size[0] == 1 and self.kernel_size[1] == 1
self.weight = torch.nn.Parameter(self.weight.squeeze(), requires_grad=True)
indices = []
for i in range(self.param_ratio):
indices.append(freq_indices.reshape(2, self.kernel_num, -1)) # paramratio, 2, kernel_num, d1 * k1 * (d2 * k2 // 2 + 1) // kernel_num
self.register_buffer('indices', torch.stack(indices, dim=0), persistent=False)
def get_FDW(self, ):
d1, d2, k1, k2 = self.out_channels, self.in_channels, self.kernel_size[0], self.kernel_size[1]
weight = self.weight.reshape(d1, d2, k1, k2).permute(0, 2, 1, 3).reshape(d1 * k1, d2 * k2)
weight_rfft = torch.fft.rfft2(weight, dim=(0, 1)).contiguous() # d1 * k1, d2 * k2 // 2 + 1
weight_rfft = torch.stack([weight_rfft.real, weight_rfft.imag], dim=-1)[None, ].repeat(self.param_ratio, 1, 1, 1) / (min(self.out_channels, self.in_channels) // 2) #param_ratio, d1, d2, k*k, 2
return weight_rfft
def forward(self, x):
if min(self.in_channels, self.out_channels) <= self.use_fdconv_if_c_gt or self.kernel_size[0] not in self.use_fdconv_if_k_in:
return super().forward(x)
global_x = F.adaptive_avg_pool2d(x, 1)
channel_attention, filter_attention, spatial_attention, kernel_attention = self.KSM_Global(global_x)
if self.use_ksm_local:
# global_x_std = torch.std(x, dim=(-1, -2), keepdim=True)
hr_att_logit = self.KSM_Local(global_x) # b, kn, cin, cout * ratio, k1*k2,
hr_att_logit = hr_att_logit.reshape(x.size(0), 1, self.in_channels, self.out_channels, self.kernel_size[0], self.kernel_size[1])
# hr_att_logit = hr_att_logit + self.hr_cin_bias[None, None, :, None, None, None] + self.hr_cout_bias[None, None, None, :, None, None] + self.hr_spatial_bias[None, None, None, None, :, :]
hr_att_logit = hr_att_logit.permute(0, 1, 3, 2, 4, 5)
if self.ksm_local_act == 'sigmoid':
hr_att = hr_att_logit.sigmoid() * self.att_multi
elif self.ksm_local_act == 'tanh':
hr_att = 1 + hr_att_logit.tanh()
else:
raise NotImplementedError
else:
hr_att = 1
b = x.size(0)
batch_size, in_planes, height, width = x.size()
DFT_map = torch.zeros((b, self.out_channels * self.kernel_size[0], self.in_channels * self.kernel_size[1] // 2 + 1, 2), device=x.device)
kernel_attention = kernel_attention.reshape(b, self.param_ratio, self.kernel_num, -1)
if hasattr(self, 'dft_weight'):
dft_weight = self.dft_weight
else:
dft_weight = self.get_FDW()
# print('get_FDW')
# _t0 = time.perf_counter()
for i in range(self.param_ratio):
# print(i)
# print(DFT_map.device)
indices = self.indices[i]
if self.param_reduction < 1:
w = dft_weight[i].reshape(self.kernel_num, -1, 2)[None]
DFT_map[:, indices[0, :, :], indices[1, :, :]] += torch.stack([w[..., 0] * kernel_attention[:, i], w[..., 1] * kernel_attention[:, i]], dim=-1)
else:
w = dft_weight[i][indices[0, :, :], indices[1, :, :]][None] * self.alpha # 1, kernel_num, -1, 2
# print(w.shape)
DFT_map[:, indices[0, :, :], indices[1, :, :]] += torch.stack([w[..., 0] * kernel_attention[:, i], w[..., 1] * kernel_attention[:, i]], dim=-1)
pass
# print(time.perf_counter() - _t0)
adaptive_weights = torch.fft.irfft2(torch.view_as_complex(DFT_map), dim=(1, 2)).reshape(batch_size, 1, self.out_channels, self.kernel_size[0], self.in_channels, self.kernel_size[1])
adaptive_weights = adaptive_weights.permute(0, 1, 2, 4, 3, 5)
# print(spatial_attention, channel_attention, filter_attention)
if hasattr(self, 'FBM'):
x = self.FBM(x)
# x = self.FBM(x, self.channel_comp(x))
if self.out_channels * self.in_channels * self.kernel_size[0] * self.kernel_size[1] < (in_planes + self.out_channels) * height * width:
# print(channel_attention.shape, filter_attention.shape, hr_att.shape)
aggregate_weight = spatial_attention * channel_attention * filter_attention * adaptive_weights * hr_att
# aggregate_weight = spatial_attention * channel_attention * adaptive_weights * hr_att
aggregate_weight = torch.sum(aggregate_weight, dim=1)
# print(aggregate_weight.abs().max())
aggregate_weight = aggregate_weight.view(
[-1, self.in_channels // self.groups, self.kernel_size[0], self.kernel_size[1]])
x = x.reshape(1, -1, height, width)
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
if isinstance(filter_attention, float):
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1))
else:
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1)) # * filter_attention.reshape(b, -1, 1, 1)
else:
aggregate_weight = spatial_attention * adaptive_weights * hr_att
aggregate_weight = torch.sum(aggregate_weight, dim=1)
if not isinstance(channel_attention, float):
x = x * channel_attention.view(b, -1, 1, 1)
aggregate_weight = aggregate_weight.view(
[-1, self.in_channels // self.groups, self.kernel_size[0], self.kernel_size[1]])
x = x.reshape(1, -1, height, width)
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
# if isinstance(filter_attention, torch.FloatTensor):
if isinstance(filter_attention, float):
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1))
else:
output = output.view(batch_size, self.out_channels, output.size(-2), output.size(-1)) * filter_attention.view(b, -1, 1, 1)
if self.bias is not None:
output = output + self.bias.view(1, -1, 1, 1)
return output
def profile_module(
self, input: Tensor, *args, **kwargs
):
# TODO: to edit it
b_sz, c, h, w = input.shape
seq_len = h * w
# FFT iFFT
p_ff, m_ff = 0, 5 * b_sz * seq_len * int(math.log(seq_len)) * c
# others
# params = macs = sum([p.numel() for p in self.parameters()])
params = macs = self.hidden_size * self.hidden_size_factor * self.hidden_size * 2 * 2 // self.num_blocks
# // 2 min n become half after fft
macs = macs * b_sz * seq_len
# return input, params, macs
return input, params, macs + m_ff
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class C2f_FDConv(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = FDConv(in_channels=c_, out_channels=c2,kernel_num=8, kernel_size=3, padding=1, bias=True)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
注册
在ultralytics\nn\tasks.py文件中的
parse_model函数进行注册
五、修改后网络:
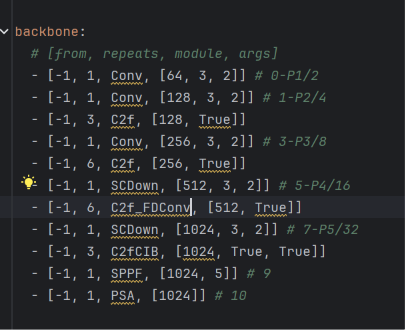
六、修改后参数和计算量:
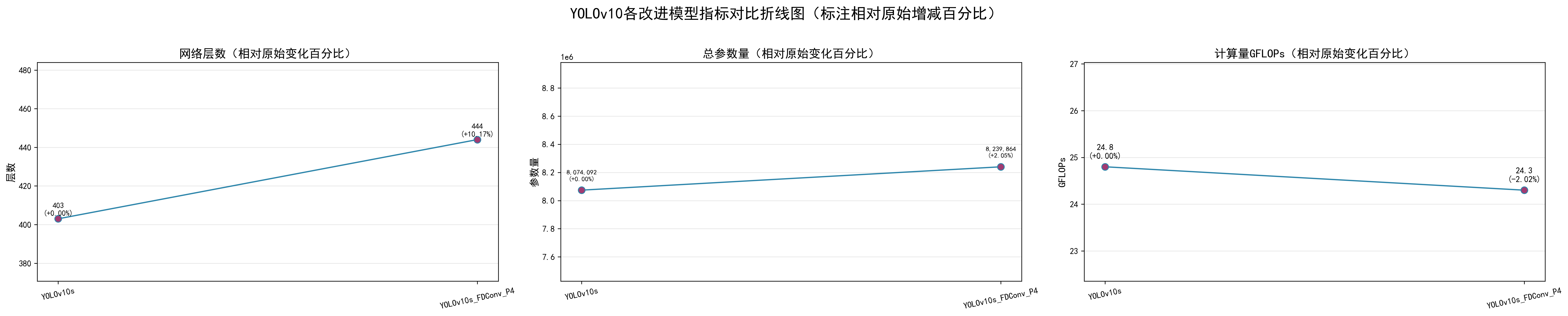
修改单层的参数和计算量变化:参数量增加2%,计算量下降2%

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)