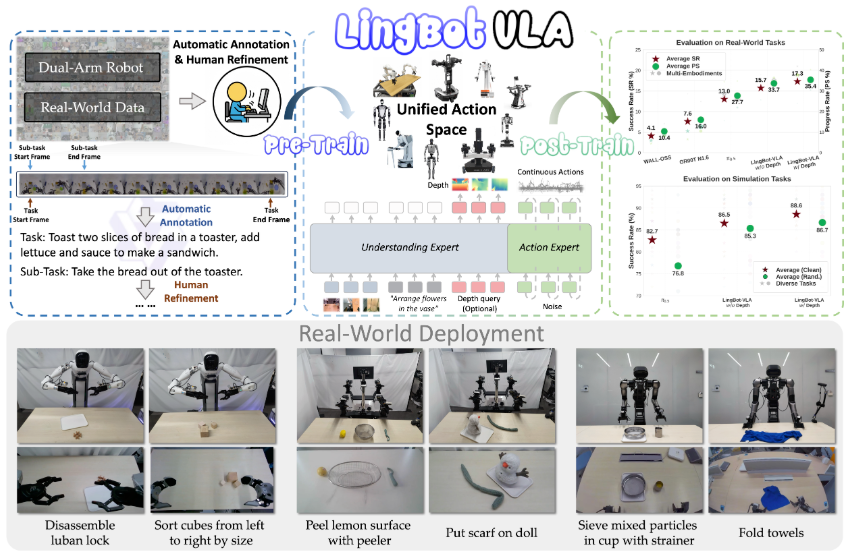
LingBot-VLA:实用的VLA基础模型 — 技术深度解析
前言:
接下来几天我会将蚂蚁集团灵波科技最新的研究成果进行一波系统的梳理,给大家分享一下lingbot-vla、lingbot-map、lingbot-va、lingbot-depth和lingbot-world,应该说是现下具身主流技术栈比较全面的,今天主要是分享一下lingbot-vla,从整个研究框架来看虽然遵循π系列的范式,还是有很多关键的创新点和启发式思考的:
- VLA Real-World Scaling Law:首次系统验证VLA模型真机性能随预训练数据量(3K→20K小时)持续增长且未饱和,可以具体看实验结果,近两年其实大家都在想办法扩充数据,期望达到llm范式中出现的scaling law,目前来看数据量还远远不够;
- MoE架构+Flow Matching:VLM Expert + Action Expert非对称设计,Flow Matching生成流畅连续动作;
- Query-based Depth Distillation:零推理开销集成LingBot-Depth空间感知,提升透明/反光物体操作,弥补现下的vla本身存在空间感知不足;
- 统一动作空间:9种双臂构型共享统一token化动作表示,实现跨平台泛化
- 20,000小时真实数据:遥操作采集+半自动标注管线,9种构型多样化覆盖
- 高效训练代码库:FSDP2+FlexAttention+torch.compile,261 samples/s,1.5~2.8×加速
- GM-100评测基准:3平台×100任务×130次试验=39,000+次真机试验
- 全面开源:代码+模型+评测数据+技术报告,推动可复现、可验证的VLA研究,关于复现这一块大家可以关注同济子豪兄的整套教程https://www.bilibili.com/video/BV1sjLx6HE5D/?spm_id_from=333.1387.upload.video_card.click&vd_source=9d0f55526b2f13215c09af8c6b1f3d34以及文档https://zihao-ai.feishu.cn/wiki/space/7589642043471924447
论文:A Pragmatic VLA Foundation Model
arXiv:[2601.18692] A Pragmatic VLA Foundation Model
代码:https://github.com/Robbyant/lingbot-vla
项目主页:Robbyant - Exploring the Frontiers of Embodied Intelligence | 蚂蚁灵波科技 - 探索具身智能的上限,打造物理世界的 AGI 平台
模型权重:https://huggingface.co/collections/robbyant/lingbot-vla
评测基准:https://huggingface.co/datasets/robbyant/lingbot-GM-100
团队:蚂蚁集团 · 灵波科技(Robbyant Team)
一、研究背景与动机
1.1 核心问题
视觉-语言-动作(VLA)基础模型被寄予厚望——它有望让机器人通过观察和指令学会各种复杂操作任务。然而,一个真正实用的VLA模型需要同时满足三个条件:
|
条件 |
描述 |
|
跨任务泛化 |
一个模型能完成多种不同任务,而非每个任务训练一个专用模型 |
|
跨平台泛化 |
同一个"大脑"能迁移到不同形态的机器人上 |
|
成本效率 |
适应新任务所需的数据量和GPU时间可接受 |
1.2 现有VLA方法的困境
|
痛点 |
描述 |
|
缺乏Scaling实证 |
社区缺乏关于VLA模型在真实机器人性能上如何随预训练数据规模增长的系统性研究 |
|
数据效率低 |
传统方法需要针对每个新任务大量采集数据,成本高昂 |
|
训练效率低 |
缺乏支持大规模数据高效训练的优化代码库,训练时间和计算成本高企 |
|
空间感知弱 |
纯RGB输入无法准确感知透明/反光/弱纹理物体的深度,导致抓取失败 |
1.3 LingBot-VLA的定位
LingBot-VLA的核心理念是**"Pragmatic"(实用)**——不做炫技的实验室Demo,而是确保模型能在真实部署场景中可用、用得起、可迁移。
二、模型架构
2.1 整体架构:VLM + Action Expert
LingBot-VLA采用VLM骨干 + 基于扩散的动作头的经典VLA架构:
┌─────────────────────────────────────────────┐
│ VLM Backbone │
│ (Qwen2.5-VL-3B / PaliGemma 等) │
│ │
│ ┌───────────┐ ┌──────────────────┐ │
│ │ 视觉编码器 │ │ 语言编码器 │ │
│ │ (ViT) │ │ (LLM Decoder) │ │
│ └─────┬─────┘ └────────┬─────────┘ │
│ │ │ │
│ └───────┬───────────┘ │
│ │ Shared Self-Attention │
│ ▼ │
│ ┌─────────────────────────────┐ │
│ │ 统一多模态表征空间 │ │
│ │ (RGB + Language + Depth) │ │
│ └──────────────┬──────────────┘ │
│ │ │
│ ┌────────┴────────┐ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────────┐ │
│ │VLM Expert│ │Action Expert │ │
│ │(视觉+语言)│ │(动作扩散头) │ │
│ └──────────┘ └──────────────┘ │
│ │
└─────────────────────────────────────────────┘VLM和Action Expert通过共享自注意力机制交互,实现逐层的跨模态融合。
设计原理:共享注意力让两个专家可以逐层交流信息,VLM提供语义理解("这是什么"、"该怎么做"),Action Expert提供动作执行("手该怎么动"),两者的对齐在每一层都得以实现,而非仅在最终输出层。
2.2 Mixture-of-Experts (MoE) 设计
LingBot-VLA的VLM骨干支持MoE变体:
|
Expert |
职责 |
特点 |
|
VLM Expert |
处理视觉和语言信息 |
高容量,参数量大 |
|
Action Expert |
规划和执行动作 |
轻量级,推理成本低 |
设计原理:视觉理解需要高容量的表征能力("看清"场景中的物体、材质、空间关系),而动作输出是低维的连续向量(6-7自由度的关节角度或末端位姿)。非对称设计避免用大模型做小任务,提升推理效率。
2.3 动作头:Flow Matching扩散
动作生成采用Flow Matching技术,将动作预测建模为从噪声到目标动作的连续流:
其中 是高斯噪声,
是学习的向量场,
是最终动作。
设计原理:相比高斯混合或离散化动作空间,Flow Matching能生成连续流畅的动作序列,让机器人的每一个动作自然过渡到下一个——而非僵硬的阶跃式运动。Diffusion-based动作头已证明在对称性、多模态分布建模方面优于回归头。
2.4 统一动作空间
不同机器人的自由度、关节构型、动作表示各不相同。LingBot-VLA提出了一套统一动作空间处理方案:
- 将所有机器人构型的动作映射到统一的归一化空间
- 训练时,不同构型的数据共享统一的token化表示
- 推理时,通过构型特定的解码器将统一动作转换回具体执行指令
设计原理:跨平台泛化的关键障碍是动作空间不一致。统一动作空间让模型可以在同一语义空间学习"操作意图",再由构型特定的后处理映射到具体关节角度。这就像学开车——油门刹车转向的"意图"是通用的,但不同车型的踏板力度不同。
2.5 深度信息集成:Query-based Depth Distillation
- 这是LingBot-VLA的关键创新之一。为了利用LingBot-Depth的空间感知能力而又不显著增加推理开销,团队采用了基于查询向量的深度蒸馏方法;
- 引入与三视角操作图像对应的可学习queries;
- 这些queries经VLM处理后,与LingBot-Depth输出的depth embeddings进行对齐;
对齐通过对比损失实现:
其中 是可学习query的输出,
是LingBot-Depth在同一空间位置的深度embedding,
是温度参数。
设计原理:
- 不直接将深度图作为额外输入通道(会改变VLM架构、增加推理延迟)
- 而是通过蒸馏让VLM内部的特征表征"学会"深度信息
- 训练时需要LingBot-Depth,推理时仅使用对齐后的queries,无额外推理成本
- 保留了VLM原始架构的兼容性和效率
2.6 模型变体
|
变体 |
VLM骨干 |
深度信息 |
特点 |
|
LingBot-VLA-4B |
Qwen2.5-VL-3B |
无 |
基础版,轻量高效 |
|
LingBot-VLA-4B-Depth |
Qwen2.5-VL-3B |
有(Query蒸馏) |
增强空间感知,支持透明/反光物体操作 |
三、数据处理
3.1 数据规模与来源

|
指标 |
数据量 |
|
预训练总数据 |
~20,000小时真实操作数据 |
|
机器人构型 |
9种主流双臂机器人 |
|
评测任务 |
3平台 × 100任务 × 130次试验 = 39,000+次试验 |
9种双臂机器人构型包括:
- AgileX Cobot Magic
- Galaxea R1Pro / R1Lite
- AgiBot G1
- 其他主流构型
数据集地址:
|
数据集 |
地址 |
|
GM-100评测基准 |
|
|
LingBot-VLA模型权重 |
|
|
LingBot-VLA (ModelScope) |
3.2 数据采集方式
采用**遥操作(Teleoperation)**方式采集:由真人远程控制机器人完成各种任务。
设计原理:遥操作确保了数据的真实性和有效性。相比模拟数据,真实遥操作数据不存在sim-to-real gap;相比自主采集,遥操作保证动作的合理性和多样性。
3.3 数据标注管线
采用半自动标注方式,兼顾效率和质量:
原始视频 → 人工标注者按原子动作切分 → 大模型标注任务描述和子任务分解 → 人工微调- 原子动作切分:人工标注者将长视频按原子动作(如"伸手"、"抓取"、"旋转")进行时间边界标注
- 任务描述生成:使用qwenvl多模态大语言模型自动生成每段视频对应的任务描述
- 子任务分解:qwenvl多模态大语言模型将复合任务分解为子任务序列
- 人工微调:人工审核和修正自动标注结果
设计原理:纯人工标注20,000小时数据成本不可接受,纯自动标注质量不够。半自动方案让大模型承担重复性工作(初始标注),人工聚焦于质量保证(审核修正)。
3.4 真机Scaling Law验证
这是LingBot-VLA最重要的实验发现之一:
|
预训练数据量 |
下游任务性能趋势 |
|
3,000小时 |
基线 |
|
6,000小时 |
显著提升 |
|
13,000小时 |
持续提升 |
|
18,000小时 |
持续提升 |
|
20,000小时 |
仍在提升,未见饱和 |
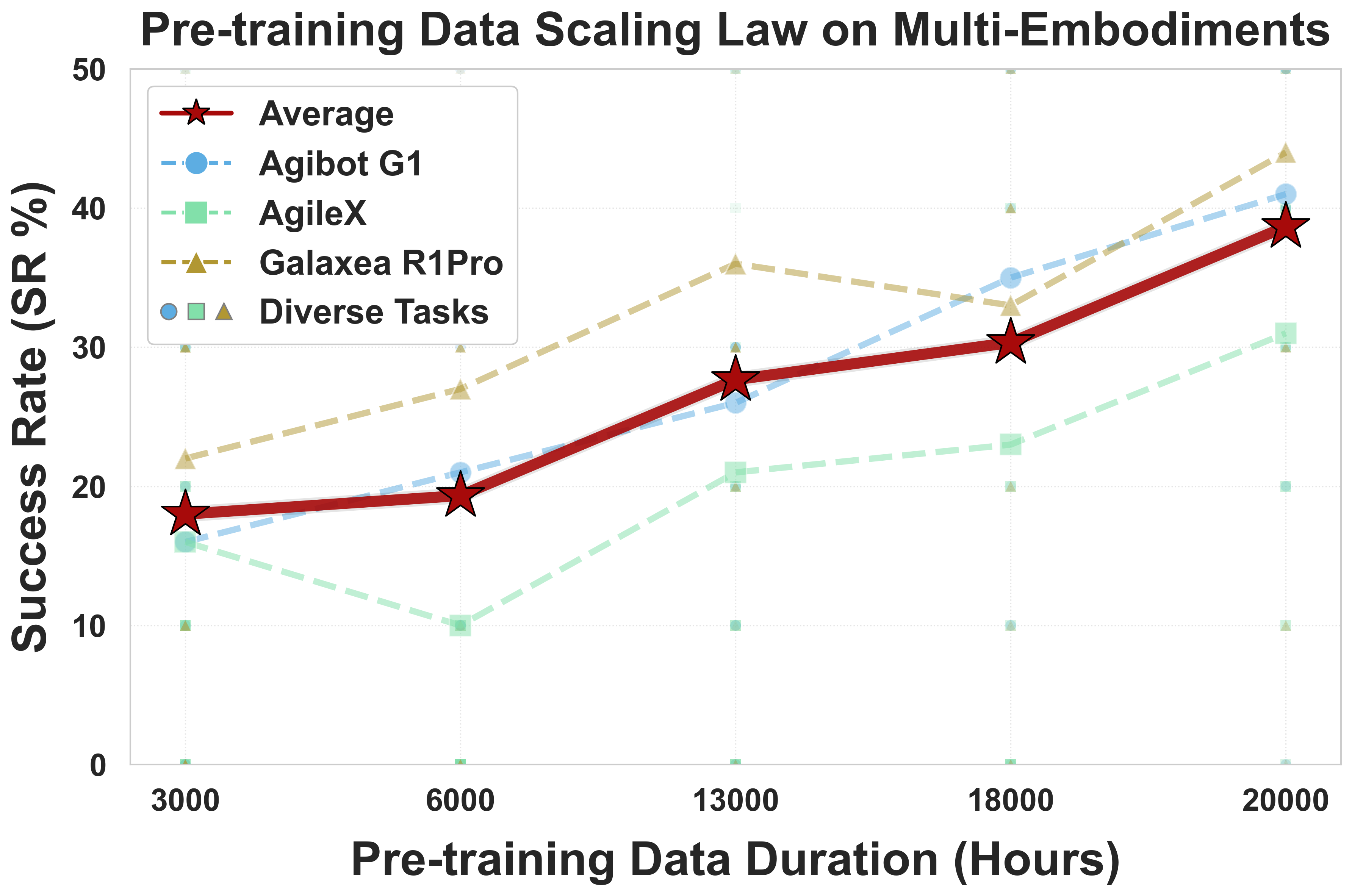
关键发现:VLA模型的真机性能随预训练数据量增长呈现持续且显著的提升,且在20,000小时时仍未观察到饱和迹象。
设计原理:这是首次在VLA领域系统验证的real-world scaling law。它证明了一个重要的实践结论——继续增加高质量训练数据仍然能带来性能增益,为未来VLA的大规模数据挖掘提供了实证支撑。
3.5 三视角输入
LingBot-VLA采用三视角操作图像作为视觉输入:
- 左臂视角
- 右臂视角
- 全局/腕部视角
设计原理:双臂操作需要同时感知两个手臂的工作空间和它们之间的空间关系。三视角输入提供全面的空间覆盖,消除单视角的遮挡盲区。
四、训练方案
4.1 预训练阶段
目标:在大规模多构型数据上学习通用的视觉-语言-动作对应关系。
|
参数/策略 |
设置 |
|
VLM骨干 |
Qwen2.5-VL-3B-Instruct |
|
动作头 |
Flow Matching Diffusion Head |
|
动作空间 |
统一归一化动作空间 |
|
数据 |
~20,000小时,9种双臂构型 |
|
输入 |
三视角RGB图像 + 语言指令 + 深度(depth变体) |
4.2 后训练(Post-Training)
目标:将预训练的通用能力高效迁移到具体下游任务。
|
参数 |
设置 |
|
每任务数据量 |
130条演示轨迹 |
|
微调方式 |
参数高效微调 |
|
评测任务数 |
3平台 × 100任务 |
设计原理:得益于预训练的强大先验,后训练只需极少数据(130条/任务)即可适配新任务。实验证明LingBot-VLA在更少数据下即可超越π₀.₅,且性能优势随数据量增加持续扩大。
4.3 深度蒸馏训练
深度信息通过以下方式集成到训练中:
其中 包含语言建模损失和动作预测损失,
是query-depth对齐损失。
设计原理:深度蒸馏损失作为辅助目标,不影响主任务的梯度方向,仅通过对比学习将空间信息"注入"VLM的内部表征。推理时不需要LingBot-Depth模型,零额外推理开销。
4.4 高效训练代码库
LingBot-VLA构建了一套高度优化的训练基础设施:
|
优化技术 |
实现 |
加速效果 |
|
FSDP2 |
改进版全分片数据并行,为Action Expert构建专门分片组 |
降低通信开销 |
|
FlexAttention |
处理多模态融合中的稀疏注意力计算 |
减少无效计算 |
|
torch.compile |
算子融合,减少内核启动开销 |
最大化内存带宽利用率 |
|
混合精度训练 |
FP16/BF16 |
降低显存占用和计算量 |
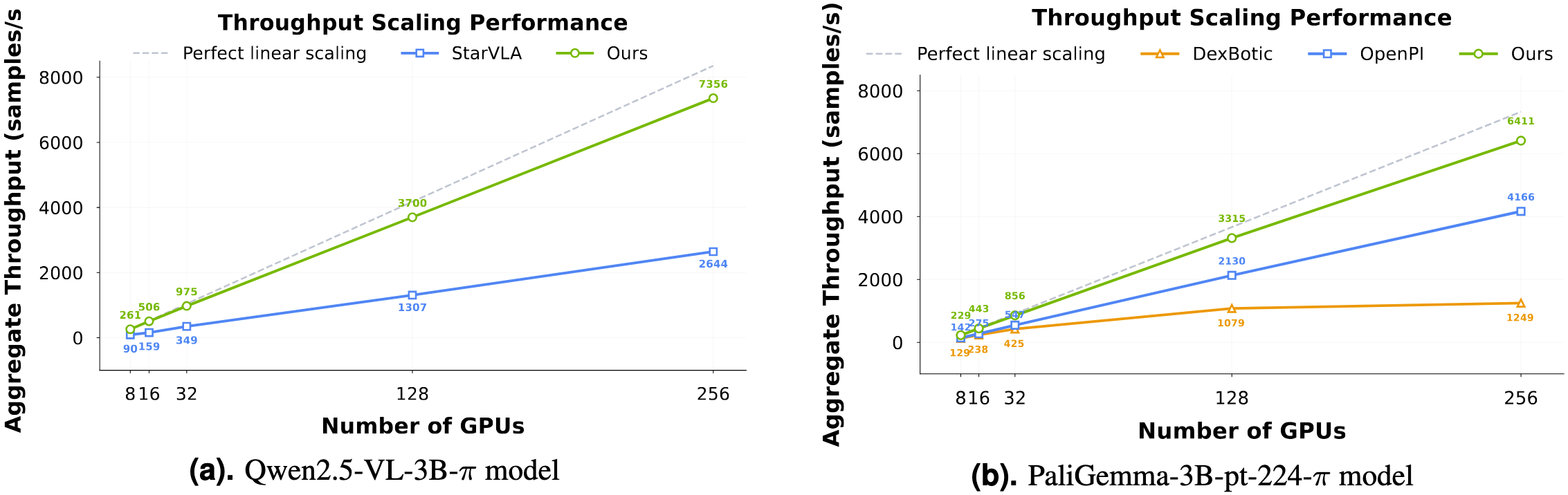
训练吞吐量:8-GPU配置下261 samples/second,比StarVLA、OpenPI等主流框架快1.5~2.8倍。
设计原理:
- FSDP2专门分片组:Action Expert参数量远小于VLM,如果使用同一分片策略会导致通信效率低下。为Action Expert构建专门分片组,减少参数分片带来的通信负担。
- FlexAttention:多模态融合中,不同token的注意力模式不同(语言token关注所有token,视觉token可能只关注局部),稀疏注意力计算可跳过不必要的attention计算。
五、评测基准:GM-100
GM-100由100个任务组成,每个任务大约有100条训练轨迹和30条测试轨迹,总计13000条操作轨迹,规模已经不小。不过,相比单纯追求规模的数据集,真正让GM-100与其他测评集打出差异化的,是其任务多样性和评估系统性。
GM-100的主要作者与项目牵头人、上海交通大学李永露老师,其实验室践行的理念是“以数据为中心的具身智能”。
整体的任务类型、丰富度等都具备很高的价值,项目主页在这里大家可以访问看看:GM-100 Benchmark | The Great March 100
5.1 基准设计
LingBot-VLA与上海交大共同打造了GM-100评测基准:
|
维度 |
设置 |
|
机器人平台 |
3种(AgileX、Agibot G1、Galaxea R1Pro) |
|
任务数 |
100项(每平台) |
|
每任务后训练数据 |
130条轨迹 |
|
总试验次数 |
39,000+ |
100项任务覆盖:
- 简单抓取放置
- 多步骤组装
- 精细操作(插入、拧转)
- 可变形物体操作(折叠衣物)
- 透明/反光物体操作
- 长序列任务(10+步骤)
5.2 评测指标
|
指标 |
含义 |
|
SR(Success Rate) |
任务完成成功率 |
|
PS(Progress Rate) |
任务进度率,衡量部分完成的程度 |
5.3 真机评测结果
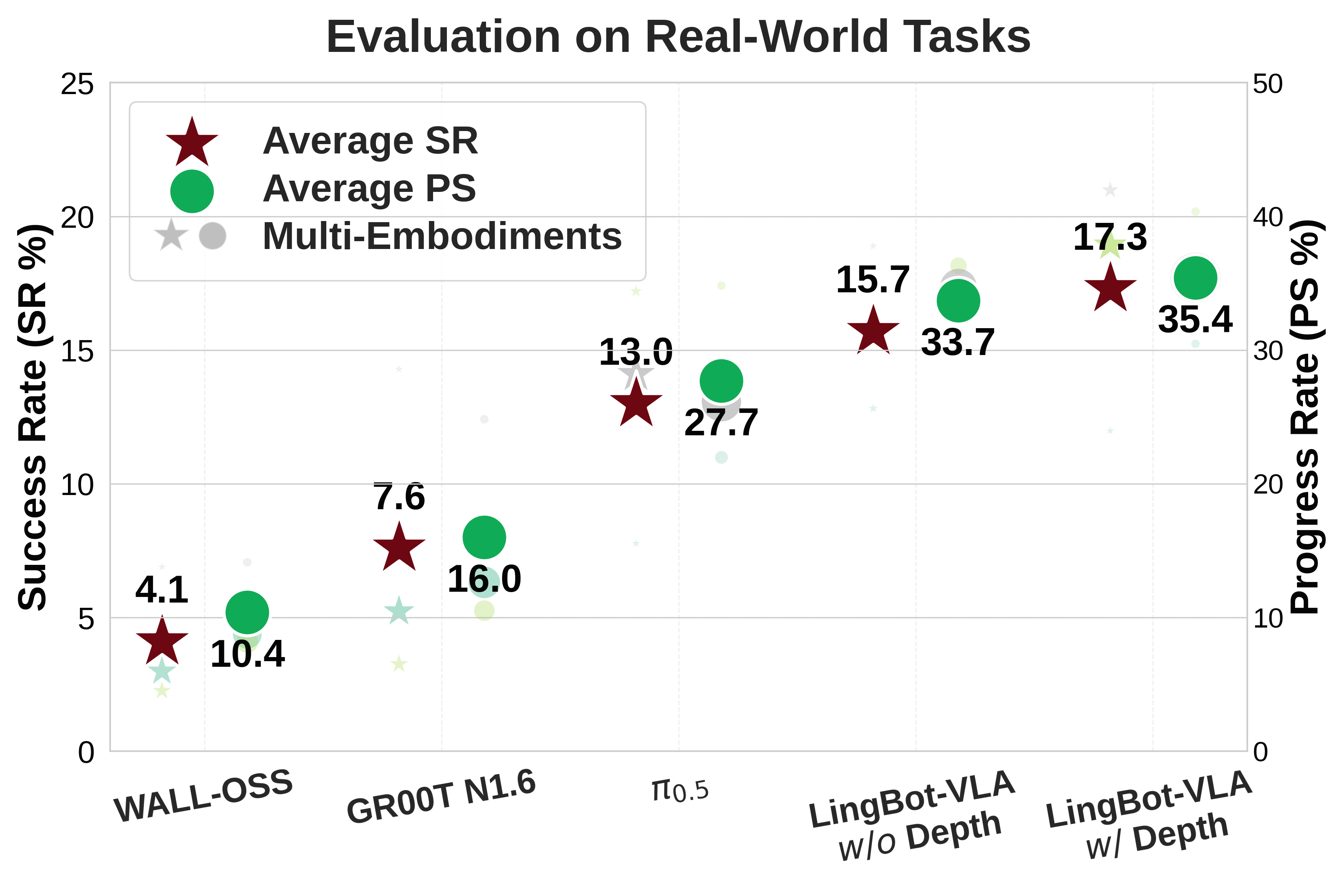
|
平台 |
π₀.₅ SR |
Ours w/o depth SR |
Ours w/ depth SR |
|
Agibot G1 |
7.77% |
12.82% |
11.98% |
|
AgileX |
17.20% |
15.50% |
18.93% |
|
Galaxea R1Pro |
14.10% |
18.89% |
20.98% |
|
平均 |
13.02% |
15.74% |
17.30% |
关键发现:
- LingBot-VLA(无深度)平均SR 15.74% vs π₀.₅ 13.02%,提升21%
- 加入深度信息后平均SR 17.30%,提升33%
- 深度信息在透明/反光物体操作上提升尤为显著
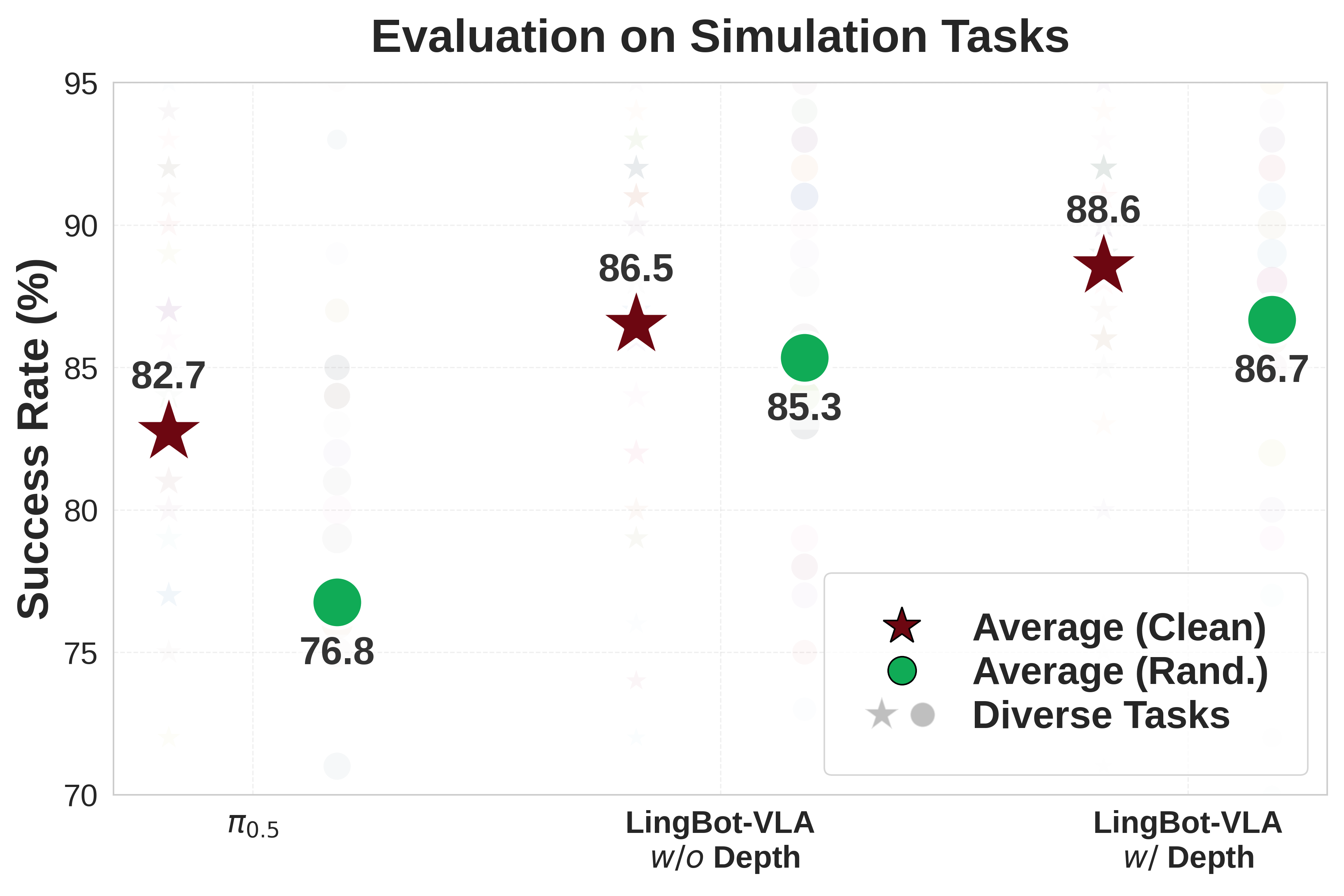
5.4 仿真评测结果(RoboTwin 2.0)
|
场景 |
π₀.₅ |
Ours w/o depth |
Ours w/ depth |
|
Clean Scenes |
82.74% |
86.50% |
88.56% |
|
Randomized Scenes |
76.76% |
85.34% |
86.68% |
在随机化场景(光照、杂物、高度扰动)下,LingBot-VLA比π₀.₅提升9.92%。
5.5 机器人操作能力展示
|
场景 |
描述 |
|
透明物体交互 |
玻璃花瓶"插花"——深度信息帮助感知透明物体 |
|
复杂精细操作 |
清洁餐具+摆放到指定位置——多步骤连续操作 |
|
可变形物体 |
折叠衣物——预判布料形变 |
六、VLA Scaling Law实证
这是LingBot-VLA论文最重要的科学贡献之一——首次在VLA领域系统验证real-world scaling law:
|
预训练数据 |
性能趋势 |
|
3K → 6K小时 |
显著跳跃 |
|
6K → 13K小时 |
持续提升 |
|
13K → 18K小时 |
持续提升 |
|
18K → 20K小时 |
仍在提升,未饱和 |
实践意义:
- 证明VLA模型的真机性能随数据增长有持续增益
- 为行业大规模数据挖掘提供了经济上的合理性论证
- 20,000小时远非上限,继续投入数据仍将带来回报
七、后训练效率
LingBot-VLA的后训练效率远超竞品:
|
对比维度 |
LingBot-VLA |
竞品 |
|
每任务所需数据 |
130条轨迹 |
通常数千条 |
|
训练吞吐量(8-GPU) |
261 samples/s |
93-174 samples/s |
|
相比加速比 |
基准 |
1.5~2.8× |
设计原理:后训练效率极高意味着——在实际部署中,为新的机器人平台或新任务适配模型的时间和成本大幅降低,使VLA技术从实验室走向商业落地成为可能。
八、局限性与未来方向
8.1 局限性
|
局限 |
描述 |
|
数据平台限制 |
目前主要验证于双臂机器人,单臂/移动平台尚未覆盖 |
|
长序列任务 |
超长时序任务(>1分钟连续操作)仍有进步空间 |
|
推理延迟 |
流式生成动作的延迟需进一步优化以支持高频控制 |
|
罕见场景 |
极端长尾操作(紧急制动等)数据不足 |
8.2 未来方向
- 扩展至更多机器人构型:单臂、移动操作平台、人形机器人
- 轻量化部署:模型蒸馏、量化,支持边缘设备推理
- 与LingBot家族深度协同:Depth(感知)+ VLA(决策)+ World(模拟)+ VA(行动)
- 开放具身智能数据联盟:推动行业数据共享和评测标准化
九、LingBot家族中的定位
|
模型 |
功能 |
深度信息 |
论文 |
|
LingBot-VLA |
视觉-语言-动作决策 |
✅ Query蒸馏 |
arXiv:2601.18692 |
|
LingBot-Depth |
空间感知(深度补全) |
核心能力 |
arXiv:2601.17895 |
|
LingBot-World |
可交互世界模拟器 |
- |
arXiv:2601.20540 |
|
LingBot-VA |
因果世界建模的机器人控制 |
- |
arXiv:2601.21998 |
|
LingBot-Map |
流式3D重建 |
- |
arXiv:2604.14141 |
LingBot-VLA是LingBot家族的"大脑"——整合感知(Depth)、制定决策、输出动作。2026年3月,LingBot-VLA随LingBot-Depth一同入选具身智能EAI-100"年度十大突破"。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)