一文读懂Bernini视频生成和视频编辑模型
写在前面

欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师/开发工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
AIGC时代的 《三年面试五年模拟》AI算法工程师/开发工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写AI Agent(AI智能体)的深入浅出全维度解析文章: 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
AIGC算法岗/开发岗面试面经交流社群(涵盖AI Agent、AIGC图像创作、AI视频、LLM大模型、AI多模态、数字人、传统深度学习、具身智能等AIGC面试干货资源)欢迎大家加入:https://t.zsxq.com/33pJ0
大家好,我是Rocky。
核心导读
如果只把 Bernini 看成一个“视频生成和视频编辑模型”,很容易低估这篇论文。它真正重要的地方,不是又把 V2V、RV2V、S2V、T2V 做进一个系统,而是提出了一个更本质的分工:让多模态大模型负责理解和规划,让扩散模型负责渲染和保真。
Rocky认为,这篇工作的价值在于它把过去视频生成模型里经常混在一起的三件事拆开了:用户意图理解、目标视觉语义规划、像素/潜空间渲染。拆开之后,系统才有机会继承 MLLM 的推理与多参考理解能力,也保留 DiT 视频扩散模型在真实感、时序一致性和高分辨率生成上的优势。
这不是一个小技巧,而是视频生成进入中场阶段后的典型路线:单纯堆扩散模型参数已经不够了,真正有复利的是把“理解能力”变成可被生成模型消费的中间表示。Bernini 选择的接口不是自然语言、不是离散视觉 token,也不是简单的 MLLM hidden states,而是 MLLM 自身的 ViT embedding space。换句话说,它不是让大模型“说出”应该生成什么,而是让大模型直接在视觉语义空间里“规划”目标。
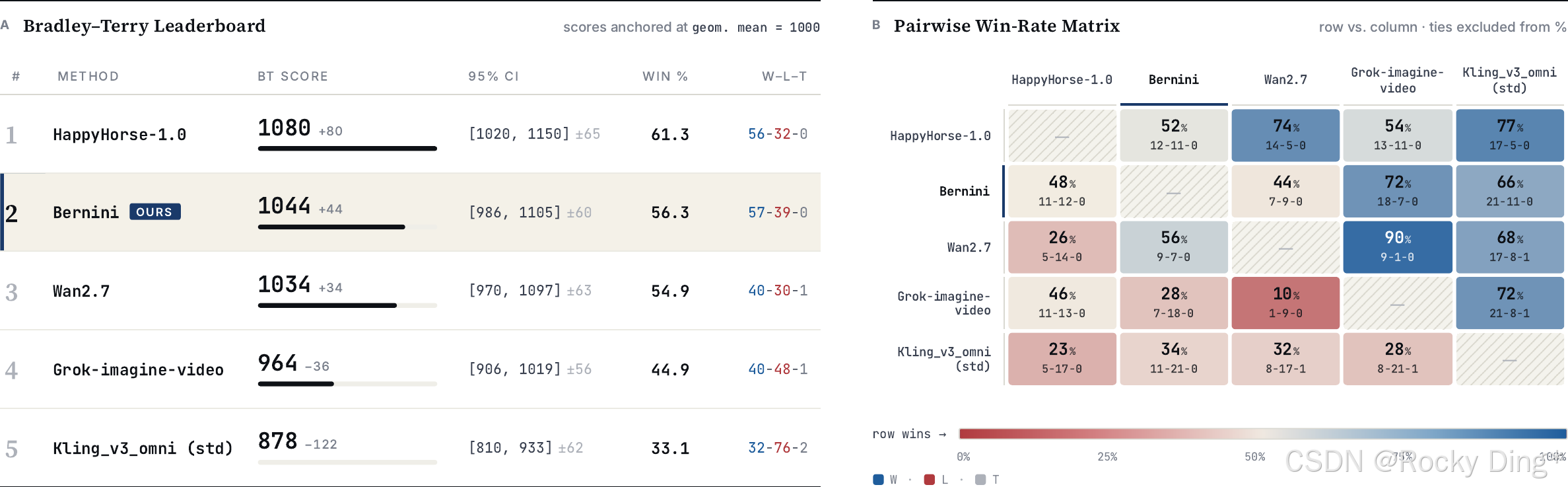
图 1 是论文开篇的编辑排行榜。它的作用不是证明 Bernini 在所有维度都无敌,而是先给出一个很明确的应用目标:开放式视频编辑里,用户真正关心的不是单帧好看,而是指令是否执行、非编辑区域是否稳定、视频是否像原本就该那样发生变化。这个目标会贯穿整篇论文。

图 2 展示了 Bernini 希望统一的任务范围:文本到视频、主体到视频、视频到视频编辑、参考引导的视频编辑。这里的关键不是“多任务”本身,而是这些任务背后的条件结构不同:有的只有文本,有的有参考图,有的有源视频,有的还要同时保持源视频和参考对象的一致性。一个真正统一的视频系统,必须先解决这些条件如何进入同一个推理与生成流程。
问题背景:作者到底想解决什么
过去几年,多模态大模型和扩散模型分别走出了两条成熟路线。MLLM 擅长读长指令、理解多图关系、做视觉语义推理;扩散模型擅长把条件渲染成高质量图像或视频。但这两类模型的能力长期没有被优雅地接起来。
如果只用文本连接二者,MLLM 的视觉理解会被压缩成语言描述,很多空间关系、身份一致性、局部编辑意图会在转述中损失。如果直接把 MLLM hidden states 喂给扩散模型,接口虽然宽,但并不保证这些状态天然对齐到视觉生成所需的语义空间。如果从头训练一个统一模型,又会带来巨大的数据、算力和灾难性遗忘风险。
Bernini 的问题意识很清楚:能不能让 MLLM 继续做它最擅长的语义理解,同时让视频扩散模型继续做它最擅长的高质量渲染,中间只用一个稳定、连续、可训练的视觉语义接口连接?
这个问题在视频编辑里尤其尖锐。视频编辑不是“重新生成一个视频”,而是在保留源视频身份、背景、运动和非编辑区域的前提下,局部执行复杂指令。用户说“把人物手里的杯子换成麦克风”,模型不仅要知道杯子在哪里、麦克风长什么样,还要知道手部交互、遮挡、背景、动作节奏不能乱。这类任务的本质不是纯图像质量,而是理解、规划、约束和渲染之间的协同。
核心思路:用一句主线串起来
Bernini 的主线可以压缩成一句话:
MLLM planner 在 ViT embedding space 里预测目标视频的语义表示,DiT renderer 再根据这个语义计划、文本条件和源视频 VAE 特征,在 VAE latent space 里渲染最终视频。
这句话里有三个关键判断。
第一,语义计划不必是高分辨率像素。论文认为,高层内容可以由紧凑的 semantic tokens 表达,细节保真则交给 VAE 特征和扩散渲染器。这个拆分很重要,因为它避免让 MLLM 直接承担像素生成,也避免让 DiT 独自理解复杂指令。
第二,语义接口选择 ViT embedding space。MLLM 本来就是通过视觉编码器理解图像和视频的,ViT embedding 是它内部已经熟悉的视觉语义坐标系。让 planner 预测这个空间里的目标表示,比让它输出语言描述或离散 token 更接近“理解转生成”的本质。
第三,planner 和 renderer 可以分开训练,只做轻量联合训练。这样既保护 MLLM 的理解能力,也保护 DiT 的生成能力。对大模型工程来说,这一点非常现实:不是每个团队都能从零训练一个全模态统一大模型,但很多团队可以围绕已有 MLLM 和视频 DiT 构建接口层。
方法展开:沿着论文原始逻辑拆解
1. 架构:把理解、规划和渲染拆成两个模型、三个职责
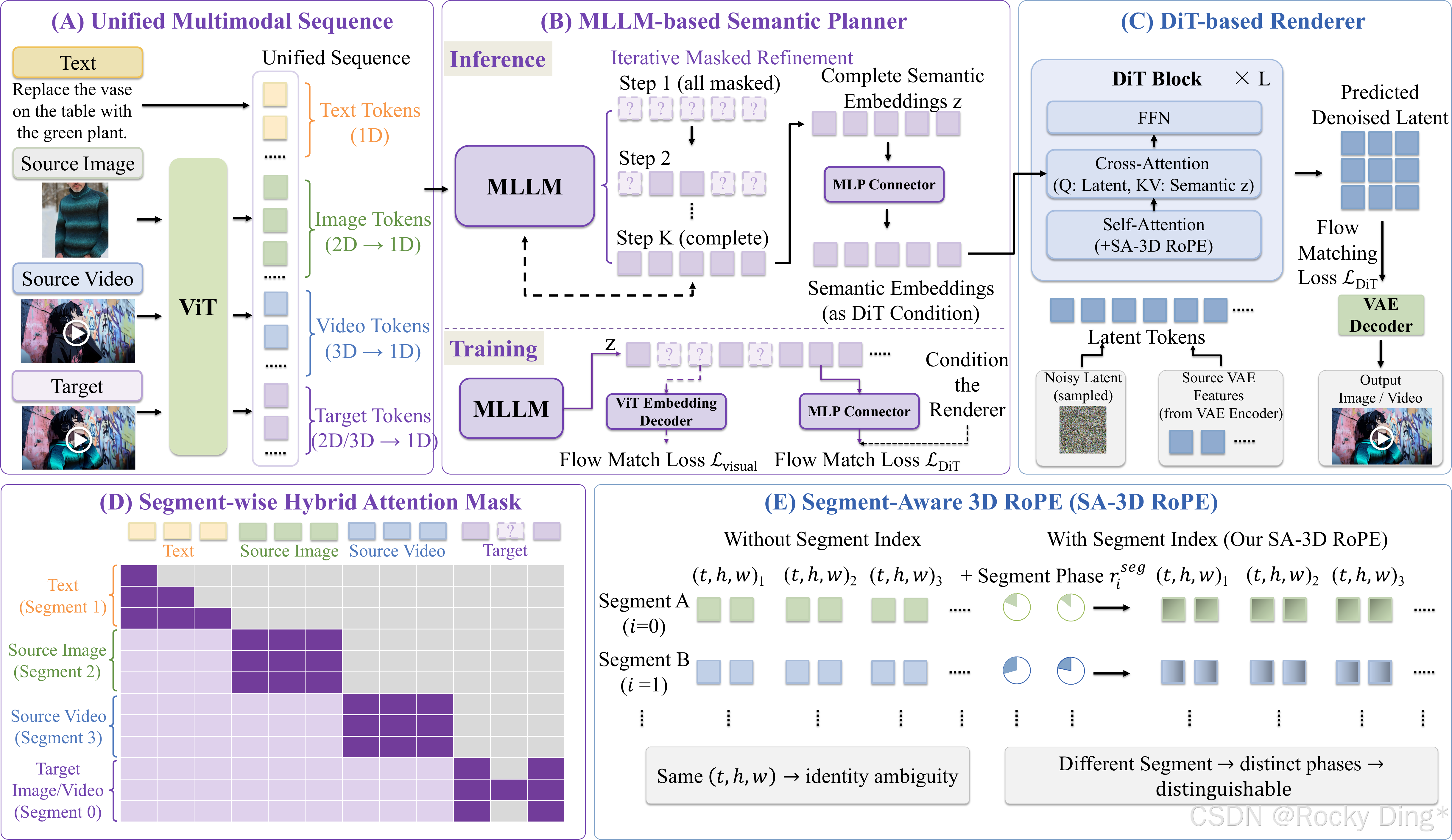
图 3 是整篇论文最重要的图。它展示了 Bernini 的五个模块逻辑:统一输入序列、MLLM planner、DiT renderer、混合注意力 mask、Segment-Aware 3D RoPE。
从输入看,Bernini 把文本、源视觉条件和目标视觉 token 序列化到一个统一 1D 序列里。不同任务只是输入条件不同:T2V 可能只有文本,S2V 有参考主体图,V2V 有源视频,RV2V 同时有源视频和参考图。统一序列的好处是任务不用各自设计一套结构,但坏处是不同 visual segments 会共享相同的时空坐标,这也是后面 SA-3D RoPE 要解决的问题。
MLLM planner 的形式化表达是:
z = M L L M ( t , v 1 s r c , v 2 s r c , … , v N s r c , v t g t ) \mathbf{z}=\mathrm{MLLM}(\mathbf{t},\mathbf{v}^{\mathrm{src}}_1,\mathbf{v}^{\mathrm{src}}_2,\dots,\mathbf{v}^{\mathrm{src}}_N,\mathbf{v}^{\mathrm{tgt}}) z=MLLM(t,v1src,v2src,…,vNsrc,vtgt)
其中 t \mathbf{t} t 是文本 embedding, v i s r c \mathbf{v}^{\mathrm{src}}_i visrc 是第 i i i 个源视觉输入的 ViT embedding, v t g t \mathbf{v}^{\mathrm{tgt}} vtgt 是目标输出的视觉 embedding。训练时目标 token 被随机 mask,模型学习从上下文推断被遮住的目标语义;推理时目标 token 一开始全是 mask,再逐步补全。
这里很像 MaskGIT/MAR 一类 masked generative modeling 思路,但 Bernini 的重点不是离散视觉 token,而是连续 ViT embedding。Rocky认为这个选择更贴近 MLLM 的优势:MLLM 不是在像素里思考,也不是在 VAE latent 里思考,它的视觉理解天然发生在视觉编码器的语义空间里。
DiT renderer 则负责把这个语义计划变成视频。它在 VAE latent space 中做 flow matching denoising,并通过 cross-attention 接收 planner 输出的语义条件。对于编辑任务,源视频 VAE 特征会额外注入,用来保留低层细节和源视频一致性。
训练目标由三个部分组成:
L = λ t e x t L n t p + λ v i s u a l L v i s u a l + λ d i t L d i t \mathcal{L}= \lambda_{\mathrm{text}}\mathcal{L}_{\mathrm{ntp}} +\lambda_{\mathrm{visual}}\mathcal{L}_{\mathrm{visual}} +\lambda_{\mathrm{dit}}\mathcal{L}_{\mathrm{dit}} L=λtextLntp+λvisualLvisual+λditLdit
L n t p \mathcal{L}_{\mathrm{ntp}} Lntp 用来保护 MLLM 的语言/多模态理解能力, L v i s u a l \mathcal{L}_{\mathrm{visual}} Lvisual 用来训练 ViT embedding decoder, L d i t \mathcal{L}_{\mathrm{dit}} Ldit 用来训练 DiT 渲染器。这个组合体现了 Bernini 的工程克制:不是把所有能力压进一个损失里,而是让每个模块保住自己的能力边界。
2. SA-3D RoPE:多参考输入里,坐标相同不代表角色相同
标准 3D RoPE 会编码视频 token 的时间、高度和宽度位置。但在 Bernini 的统一序列中,不同视觉段可能有相同的 ( t , h , w ) (t,h,w) (t,h,w) 坐标:源视频第 1 帧的某个 patch、参考图的某个 patch、目标视频的某个 patch,位置可能一样,语义角色却完全不同。
如果模型无法区分这些 segment,参考图里的背景、颜色、纹理就可能泄漏到目标视频不该变化的区域。论文提出 Segment-Aware 3D RoPE,把 segment index 也编码进旋转位置中:
r ~ t , h , w , i = r t , h , w ⊙ r i s e g \tilde{\mathbf{r}}_{t,h,w,i}=\mathbf{r}_{t,h,w}\odot\mathbf{r}^{\mathrm{seg}}_i r~t,h,w,i=rt,h,w⊙riseg
这里 r t , h , w \mathbf{r}_{t,h,w} rt,h,w 是标准时空 RoPE, r i s e g \mathbf{r}^{\mathrm{seg}}_i riseg 是 segment index 对应的旋转频率, ⊙ \odot ⊙ 表示复数逐元素乘法。它不是简单加一个 segment embedding,而是在相位层面给不同视觉段一个全局调制。
Rocky认为,这个细节非常有工程含义。多参考视频编辑不是“把更多图塞进上下文”就完了,关键是模型要知道哪个 token 是源视频、哪个是参考对象、哪个是目标输出。接口越统一,角色区分越重要。
3. 数据:Bernini 的能力不是凭空从架构里长出来的
很多生成论文会把架构讲得很漂亮,但真正决定模型上限的往往是数据。Bernini 在数据部分花了大量篇幅,核心是为统一视频生成和编辑构建多任务训练语料。
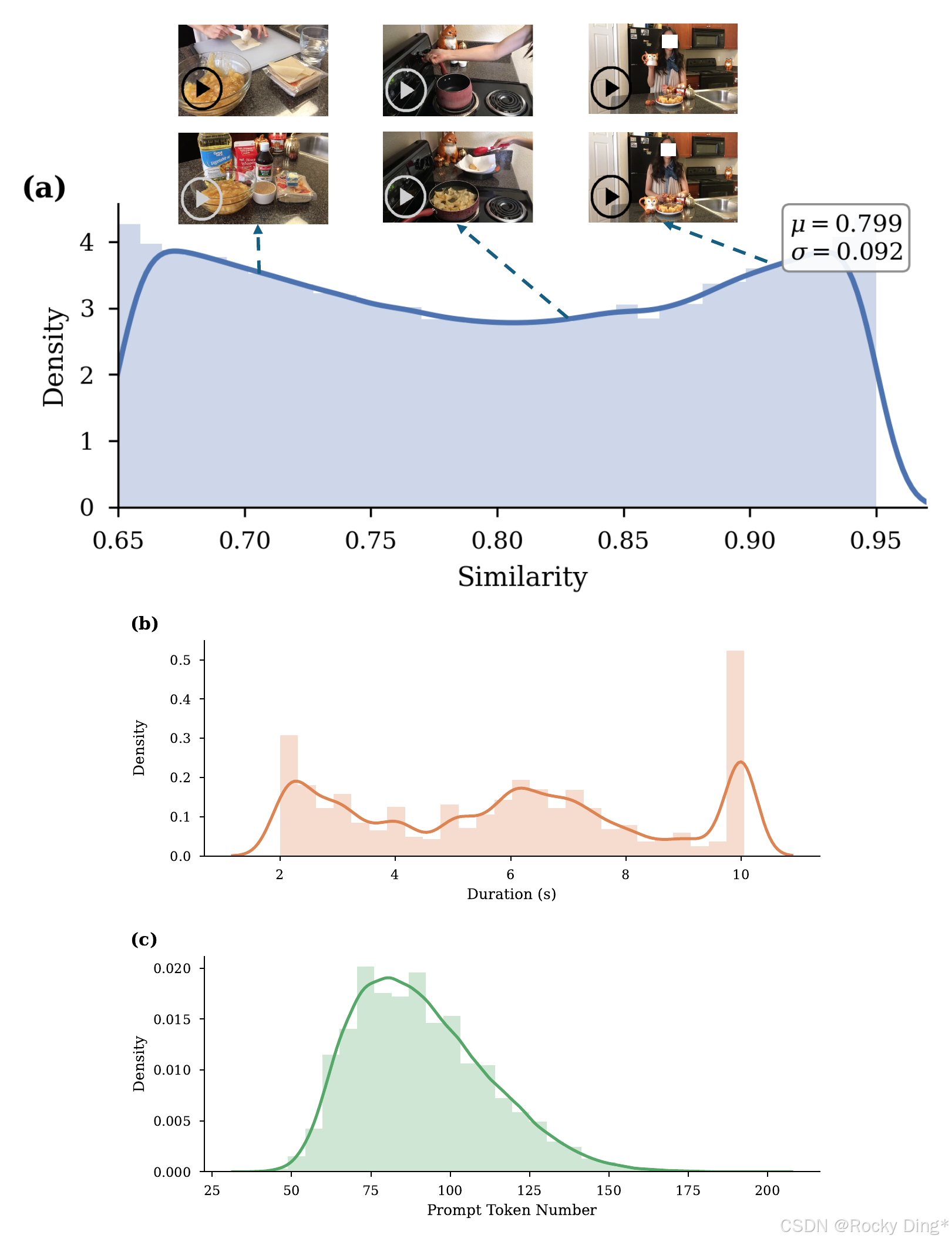
图 4 展示了视频对数据的相似度、时长和 prompt token 分布。论文构建了约 2000 万 video pairs,来源于通用 T2V 语料,通过 X-CLIP 相似度筛选、内容采样和粗到细指令生成得到。相似度区间控制在 0.65 到 0.95,避免一边是近重复、一边是语义不相关。

图 5 展示了 video pair 和密集 prompt 的样例。注意 prompt 的结构不是简单一句话,而是先描述相机运动,再描述前景和背景变化。这意味着数据不是只教模型“改什么”,还在教模型“变化如何发生”。对视频编辑来说,这一点比图像编辑更重要,因为视频变化必须沿时间展开。

图 6 对应 image-pair data。论文从教程视频中抽取近 3000 万 image pairs,用 CLIP 相似度、运动过滤、模糊检测和 MLLM prompt 生成构造图像编辑监督。这个设计的背后逻辑是:高质量视频编辑数据难以规模化,但图像编辑数据更成熟,可以作为视频编辑能力的迁移来源。
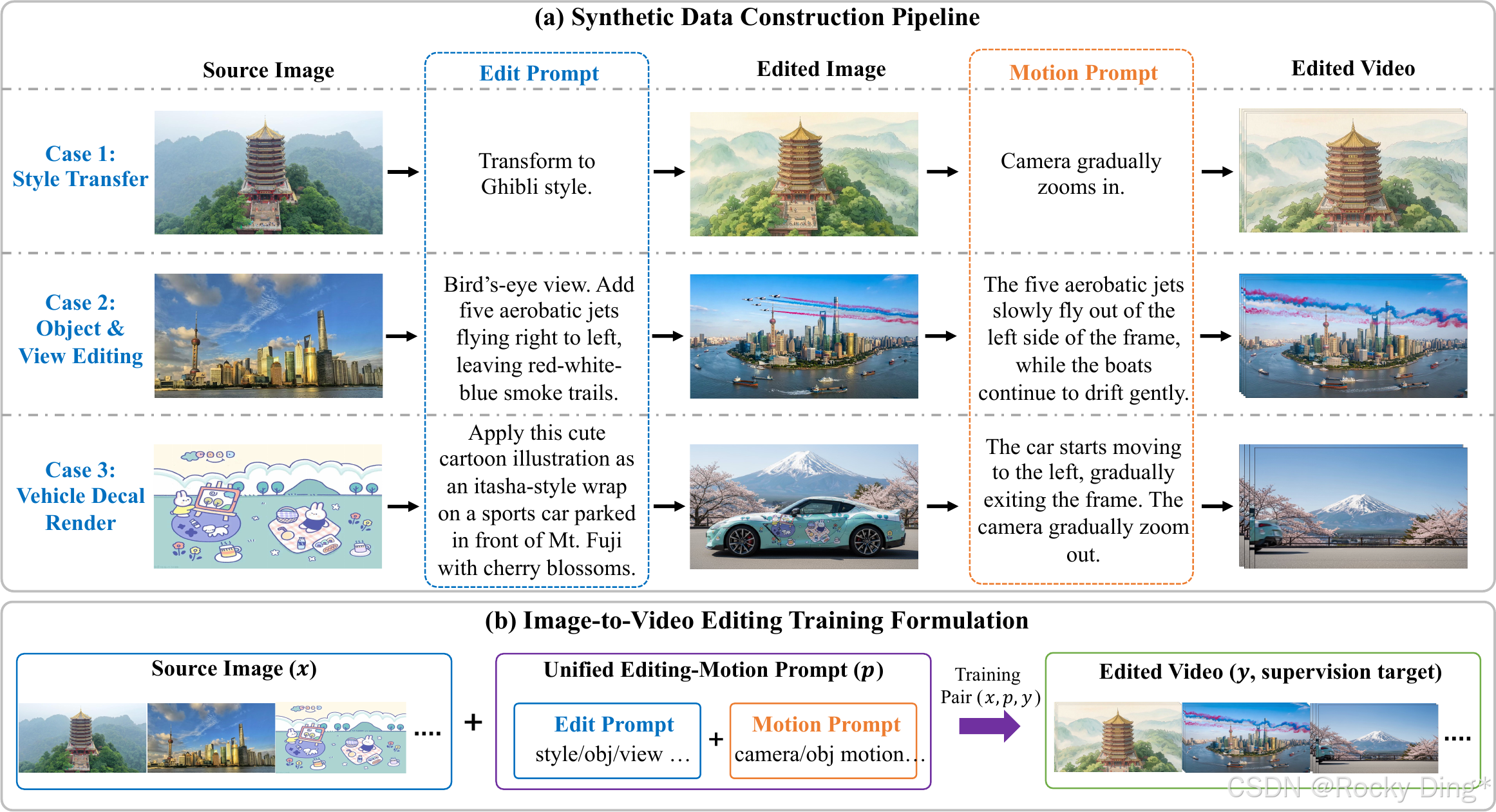
图 7 展示 image editing 和 image-to-video editing data。Bernini 不是只训练 V2V,而是把 I2I 的编辑能力先转换成 I2V,再进一步帮助 V2V。这个链路体现了一个很现实的判断:当目标数据稀缺时,先在更容易规模化的任务上学习可迁移的编辑语义,再把它转入视频时序生成。

图 8 是 propagation-based editing data。论文先用已有工具生成初始 addition/removal/replacement 数据,再训练一个基础传播模型,把第一帧高质量编辑传播到目标视频。它要解决的是视频编辑里的一个硬问题:单帧能改好,不代表整段视频能稳定改好。

图 9 展示 motion-aware editing data。这里的本质是“编辑会改变因果后果”。比如替换手中物体后,人的动作也应该合理变化;添加一个人后,互动姿态也应该自然。论文用 I2V 分支提供动作适配,用 V2V 分支保持源运动一致,通过加权 guidance 融合两者。
其核心形式可以写成:
ϵ ^ = α ⋅ ϵ I 2 V b r a n c h + β ⋅ ϵ V 2 V b r a n c h , α + β = 1 \hat{\epsilon}=\alpha\cdot\epsilon_{\mathrm{I2V\ branch}}+\beta\cdot\epsilon_{\mathrm{V2V\ branch}},\quad \alpha+\beta=1 ϵ^=α⋅ϵI2V branch+β⋅ϵV2V branch,α+β=1
论文原式更细,把 text-dropped、image-dropped、video-dropped 条件都拆开。这种拆法说明 Bernini 团队并不把 motion-aware data 当成普通合成数据,而是在构造“动作适配”和“源运动保留”之间的可控平衡。

图 10 是 motion-transfer data。参考视频比参考图多了时间信息,尤其适合人物动作迁移。论文通过 DWPose 从真实视频抽取姿态,再用 Bernini 的 pose-to-video 能力构造 reference video、reference image、target video 三元组。
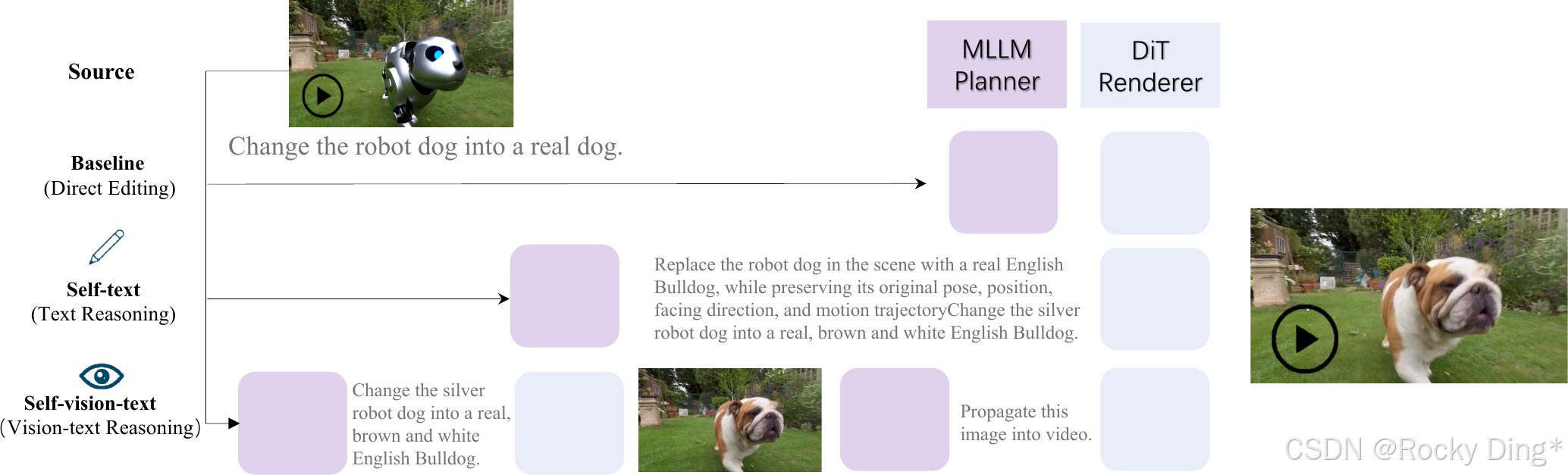
图 11 展示 reasoning-augmented video data。论文把 CoT 引入视频编辑,分成 self-text reasoning 和 self-vision-text reasoning。前者把用户指令改写成更结构化的中间指令,后者先生成视觉中间状态,再进行视频级传播。Rocky认为,后者更接近视频编辑的真实流程:复杂编辑往往不是语言一步到位,而是先形成一个“应该变成什么样”的视觉中间计划。
关键训练表格可以压缩成下面几类。
| 表格 | 论文中的作用 | 关键事实 |
|---|---|---|
| Table 1 训练数据统计 | 说明 Stage II/III 使用的生成和编辑数据混合 | 覆盖 T2I、T2V、I2I、I2V、V2V、IV2V,其中 propagation-based editing、motion-aware editing、person/general R2V/RV2V 是关键自建数据 |
| Table 2 训练阶段 | 说明三阶段训练课程 | Stage I 训练 MLLM planner,Stage II 训练 DiT renderer,Stage III 轻量联合训练 All |
| Table 3 mask ratio | 说明 planner 如何减少目标泄漏 | 从 T2I 到 V2V/IV2V, α \alpha α 增大、 β \beta β 减小,mask ratio 更偏向高遮挡 |
| Table 4 noise scheduler | 说明不同任务的扩散时间步采样 | 图像相关任务用 logit-normal,视频相关任务用 mode 函数;I2V/V2V/IV2V shift 为 5.0 |
| Table 5 inference guidance | 说明推理时不同条件的权重 | T2V 用 60 steps,S2V/V2V/RV2V 用 40 steps;RV2V 的 image guidance 为 3.0,强调参考图一致性 |
4. 训练与推理:先分开变强,再轻量对齐
Bernini 的训练分三阶段。
Stage I 训练 MLLM planner 和 ViT embedding decoder。目标是让 MLLM 从一个理解模型,变成能预测目标视觉语义的 planner。训练分辨率是 256P、2 fps,同时混合生成、编辑、理解数据,以免 planner 在学习生成语义时丢掉语言和视觉理解能力。
Stage II 训练 DiT renderer。这里用 Wan2.2-A14B 作为渲染基础,训练目标是让 renderer 在文本、源 VAE 特征和编辑数据上获得强渲染能力。论文还提到 pair data 的采样比例会线性衰减,因为 pair data 对泛化有帮助,但过多也可能削弱指令跟随和非编辑区域一致性。
Stage III 才做联合训练。这里不是从头把两个系统拧成一个黑箱,而是用轻量联合训练对齐 planner 的语义预测和 renderer 的视觉渲染。这个阶段引入高质量生成/编辑数据、理解数据和后期的 CoT 数据,使系统在不破坏原有能力的情况下形成“语义到视觉”的接口。
推理时,planner 先用 25 个 iterative planning steps 从全 mask 目标 token 逐步预测 ViT embedding;每一步内部的 embedding decoder 用 5 个 denoising steps 做 refinement。随后 renderer 执行最终视频扩散:T2V 用 60 步,S2V/V2V/RV2V 用 40 步。
renderer 的 guidance 也被拆成多个增量项:
ϵ ^ = ϵ ∅ , ∅ , ∅ , ∅ + ω v i d Δ v i d + ω i m g Δ i m g + ω t x t Δ t x t + ω t g t Δ t g t \hat{\epsilon}= \epsilon_{\varnothing,\varnothing,\varnothing,\varnothing} +\omega_{\mathrm{vid}}\Delta_{\mathrm{vid}} +\omega_{\mathrm{img}}\Delta_{\mathrm{img}} +\omega_{\mathrm{txt}}\Delta_{\mathrm{txt}} +\omega_{\mathrm{tgt}}\Delta_{\mathrm{tgt}} ϵ^=ϵ∅,∅,∅,∅+ωvidΔvid+ωimgΔimg+ωtxtΔtxt+ωtgtΔtgt
这说明 Bernini 推理时并不是把所有条件简单 concat,而是显式控制源视频、参考图、文本和目标语义 embedding 对最终 denoising 的贡献。对产品落地来说,这类条件可控性很重要,因为不同应用对“改得明显”和“保留原视频”之间的偏好不同。
5. 基础设施:视频长序列不是论文细节,而是系统门槛
Bernini 还有一节 Infrastructure,很多读者可能会跳过,但 Rocky认为这部分非常值得看。视频编辑模型的难点不仅在模型结构,还在长上下文、多模态、多任务、长序列训练的系统工程。
论文提到,通过 FSDP 配置优化、预分配 buffer 直接 index-scattering、activation offloading、FlashAttention-4、FlexAttention、异步 QKV 通信、Ulysses sequence parallelism、sequence packing、token-bucket batching、greedy bin-packing dataloader 等手段,把每 GPU 显存从 72GB 降到 40GB,训练序列长度从 100K 提升到 440K tokens,吞吐提升约 4.5 倍。
这部分给人的启发是:视频生成/编辑进入工程化阶段后,算法 paper 和系统 paper 的边界会越来越模糊。一个方案能不能落地,不只取决于损失函数漂不漂亮,还取决于是否能稳定训练、是否能处理长视频 token、是否能在多 GPU 上保持吞吐。
实验与证据:结果能支撑到什么程度
1. Bernini-Bench:论文先定义了自己认为重要的编辑能力
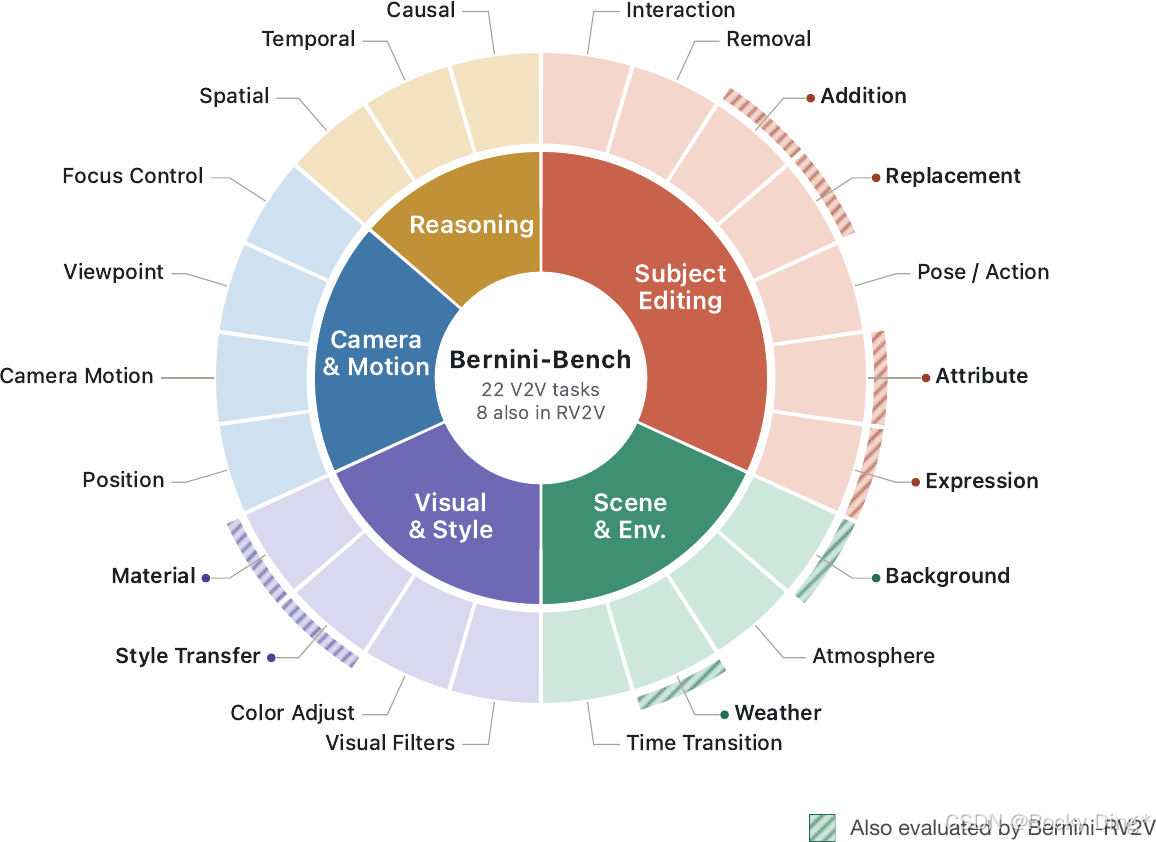
图 12 展示 Bernini-Bench。论文认为现有视频编辑 benchmark 主要覆盖 V2V,对 reference-image-guided video editing 覆盖不足,任务类型也不够细。因此作者构建了 300 个测试案例,覆盖 22 个编辑类别,分为 Subject Editing、Scene & Environment、Visual & Style、Camera & Motion、Reasoning 五个维度,其中 8 类也评估 RV2V。
评价维度包括 Instruction Following、Video Consistency、Reference Image Consistency、Generation Quality 和 Overall Score。这里有一个重要限制:论文也承认当前 MLLM 对小尺度失真、自然度瑕疵的判断不够可靠,所以 Generation Quality 的自动评分只能作为参考。它同时使用 MLLM scoring 和 human SBS evaluation。
2. 视频编辑:最强证据是“编辑一致性”
| Benchmark | Bernini 的主要结果 | 论文可支撑的结论 |
|---|---|---|
| Bernini-V2V | OS 3.49,高于 Wan2.7 的 3.30 | 在自建 V2V benchmark 上整体更强 |
| Bernini-RV2V | OS 3.50,略低于 Wan2.7 的 3.58,但 VC 3.51 最高 | 参考引导编辑中,Bernini 的视频一致性优势更明显 |
| OpenVE-Bench | Overall 4.04,高于 VINO 的 3.18 | 在公开开放视频编辑 benchmark 上大幅领先 |
| EditVerse | Editing Quality 8.02,高于 EditVerse baseline 的 7.65 | 编辑质量和文本对齐表现强 |
| FiVE | Acc 78.16,高于 Omni 的 72.41 | 在 VQA 式编辑准确性指标上强 |
这组结果说明 Bernini 的强项主要不是单纯画质,而是编辑的可控性和一致性。尤其在 Bernini-Bench 上,它对 Wan2.7 的优势集中在 Video Consistency。这与架构设计是对齐的:planner 提供语义计划,源 VAE 特征保留低层细节,SA-3D RoPE 减少多参考泄漏。
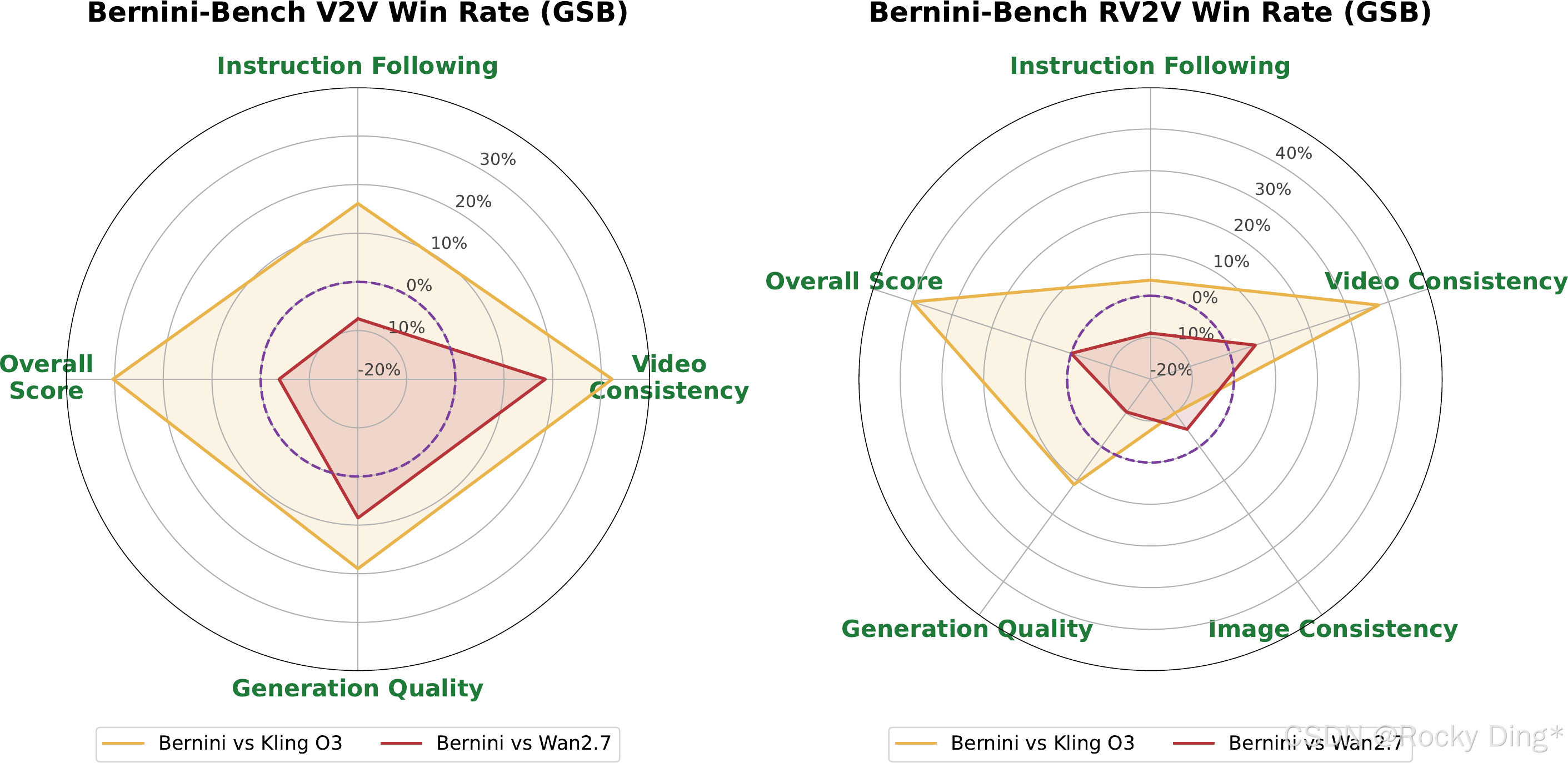
图 13 是 human SBS evaluation 的胜率图。相比自动评分,人评更能反映实际编辑结果。论文给出的证据是:Bernini 相比 Kling O3 在多数维度更强,相比 Wan2.7 具备竞争力,尤其在 Video Consistency 上优势显著。

图 14 展示定性案例。论文强调几类现象:其他模型可能改变背景、引入额外物体、丢失人物身份或参考图一致性;Bernini 则更能同时完成编辑和保持非编辑区域。定性图不能单独证明 SOTA,但它能解释为什么表格里的 VC 指标有意义。
3. 推理增强:CoT 的价值不是“更会写 prompt”,而是把编辑计划显式化
| 变体 | OS | IF | VC | GQ |
|---|---|---|---|---|
| Baseline | 3.12 | 3.36 | 3.18 | 3.37 |
| + Qwen2.5-VL Prompt Enhancer | 3.20 | 3.43 | 3.21 | 3.39 |
| + Self-text | 3.33 | 3.55 | 3.31 | 3.44 |
| + GPT-5.4 Prompt Enhancer | 3.49 | 3.66 | 3.51 | 3.49 |
| + GPT-5.4 PE + Self-visual-text | 3.52 | 3.65 | 3.54 | 3.49 |
表格说明了一个很有意思的现象:普通 prompt enhancer 有帮助,但 self-text reasoning 更强;更强的外部 prompt enhancer 继续提高性能;在此基础上加入 self-visual-text reasoning,整体分数和一致性进一步提升。

图 15 展示不同推理模式的定性比较。真正值得关注的是 self-vision-text reasoning 引入了视觉中间状态。语言 CoT 可以把指令讲清楚,但视频编辑的很多难点不是语言关系,而是空间和时间变化本身。视觉中间状态相当于让模型先“看见计划”,再把计划传播到视频里。
4. 视频生成和主体到视频:统一框架没有明显牺牲基础生成能力
在 VBench 上,Bernini 的 Total score 为 84.64,接近其基础 renderer Wan2.2-A14B 的 84.79。这一点很重要,因为统一编辑能力很容易损害原本 T2V 的基础生成质量。论文的证据表明 Bernini 扩展到编辑和参考生成后,仍基本保留 Wan2.2 的 T2V 能力。
在 OpenS2V-Eval 上,Bernini Total 为 62.94,高于 Kling O3 的 59.19 和 RefAlign-14B 的 60.42。最突出的是 FaceSim 78.20,远高于 Kling O3 的 57.20。这说明多参考主体一致性是 Bernini 的明显强项,也与它的 segment-aware 输入建模和参考条件 guidance 相关。
5. 消融:论文最有力的因果证据
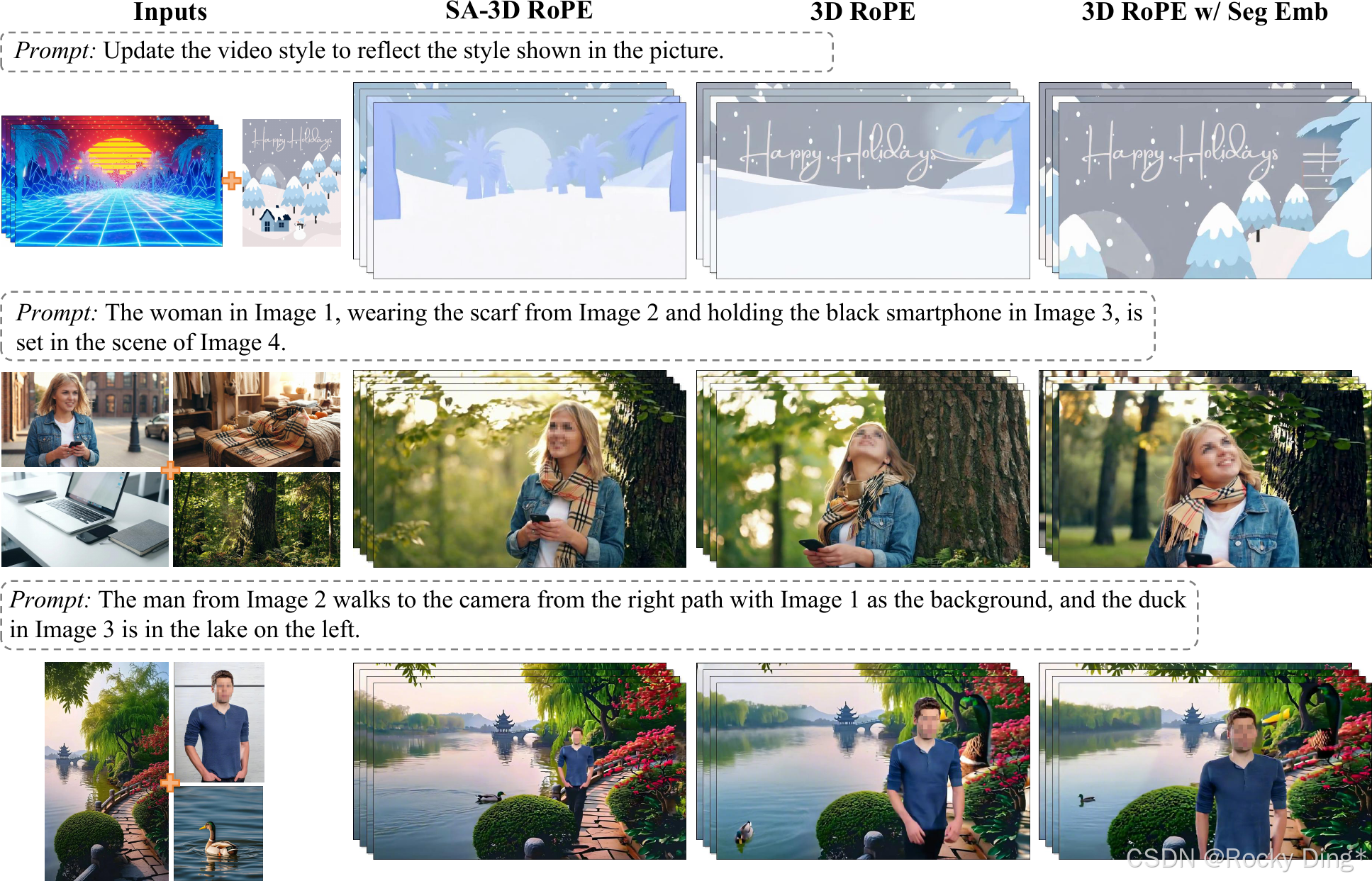
图 16 对比 SA-3D RoPE、标准 3D RoPE 和加 segment embedding 的 3D RoPE。结论是:简单 segment embedding 有提升,但仍会出现参考泄漏,例如背景或不该迁移的对象细节被带入目标。SA-3D RoPE 通过 segment-conditioned phase modulation 更好地区分不同视觉段。

图 17 消融 ViT semantic interface 和 MLLM planner。去掉 ViT 语义接口后,模型在对象替换、风格迁移等任务上指令跟随变弱;进一步去掉 MLLM,结果更明显退化。这是对核心主张的关键支持:Bernini 的性能不是只来自 Wan2.2 renderer,而是来自 planner、ViT semantic interface 和 renderer 的组合。
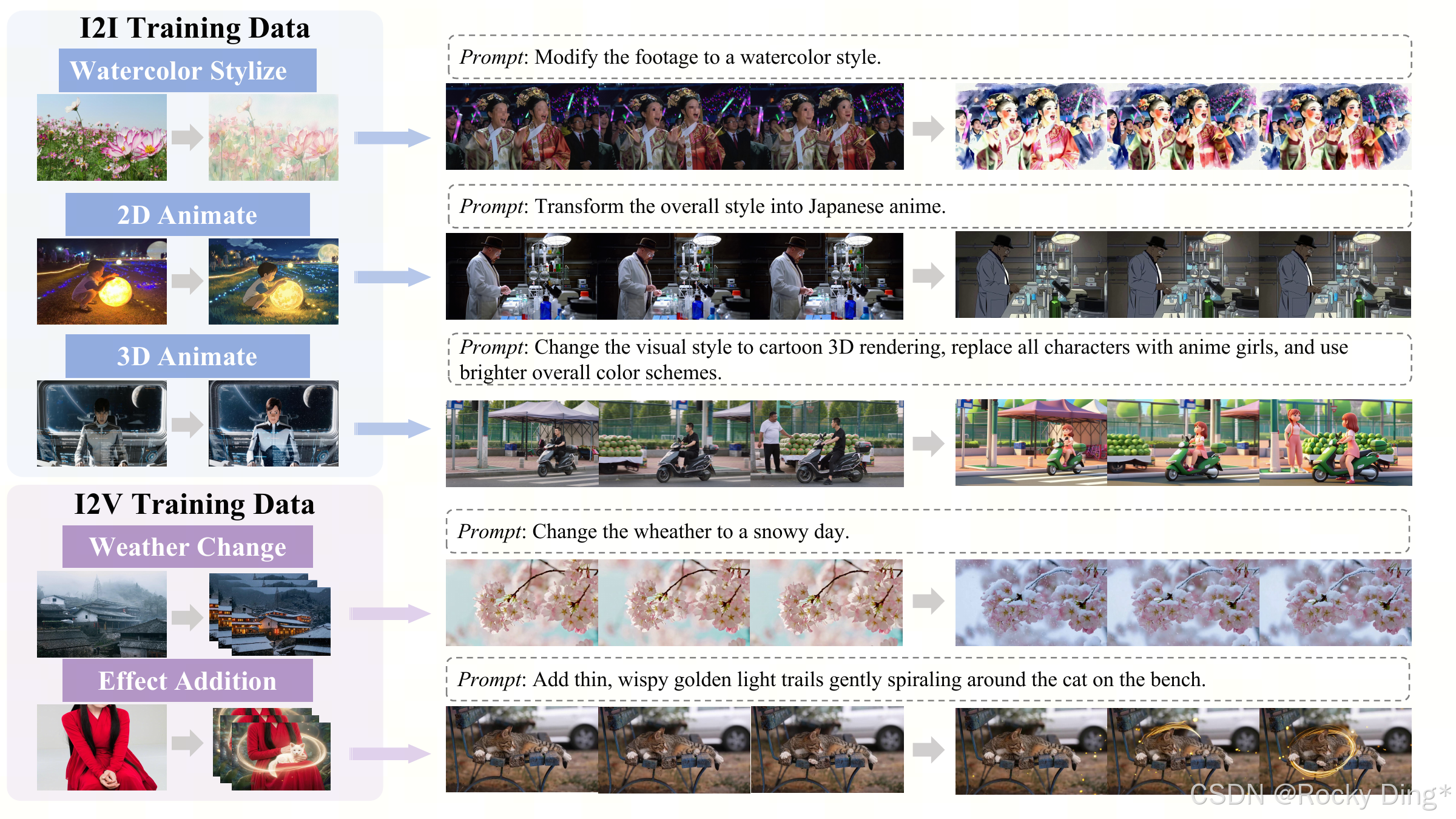
图 18 说明 I2I 和 I2V 训练数据能帮助视频编辑泛化。它展示水彩、动画、天气、特效等多样编辑。这里的证据更偏定性,但背后的方法论很重要:用成熟图像编辑数据迁移到视频编辑,是目前高质量视频编辑数据稀缺时的务实路径。
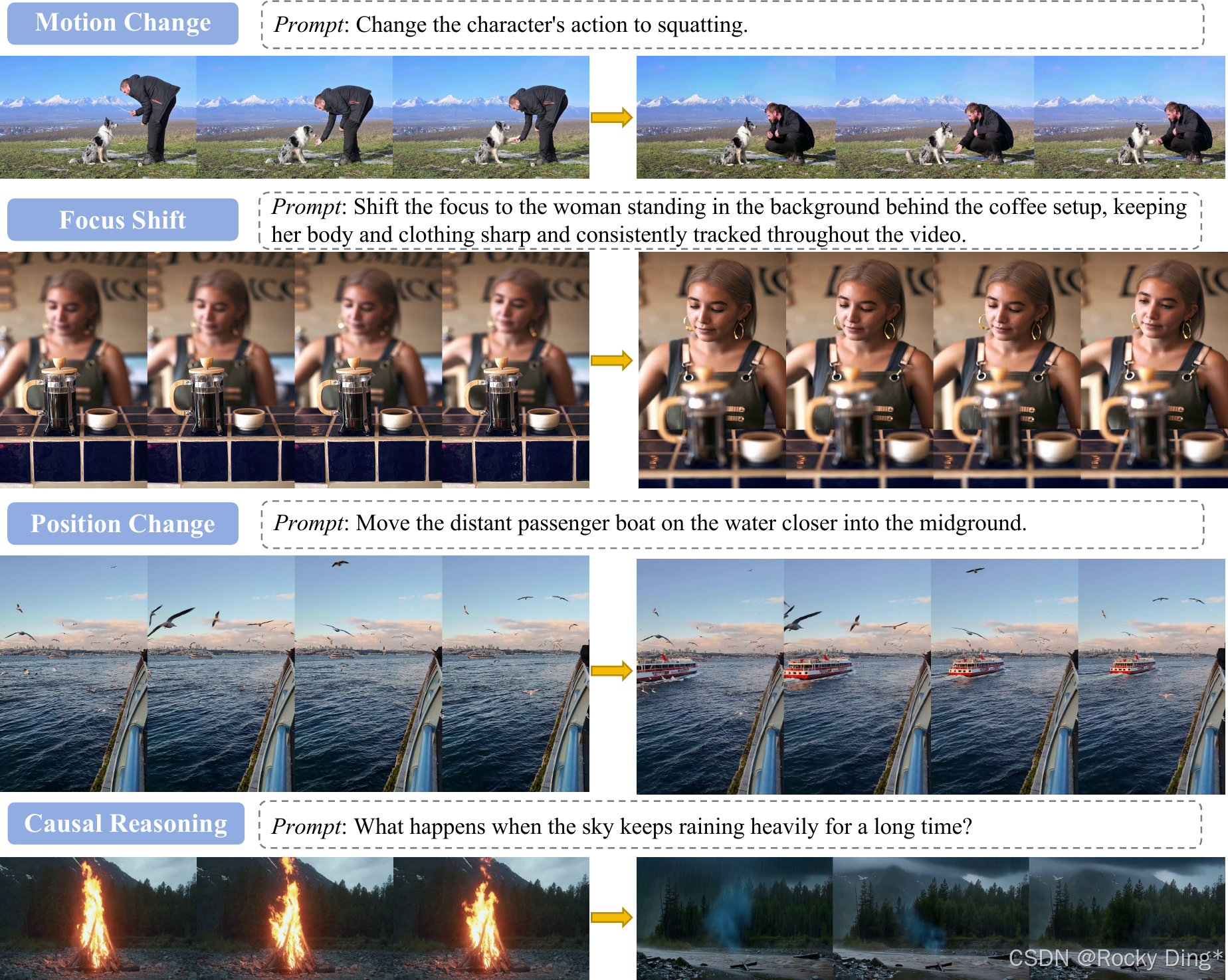
图 19 展示多样指令泛化,包括运动变化、焦点变化、位置变化和因果推理。论文举了“长时间大雨导致火被熄灭”这类案例,强调模型不是只拟合标准编辑模板,而能把指令背后的因果关系转化为视觉变化。
6. 附录定性:更多案例说明稳定性,但也不应被当作唯一证据

图 20 给出更多 V2V 定性比较。它展示 Bernini 在改变动作、添加/替换对象、保持背景方面的优势。定性图的意义在于帮助读者理解模型错误类型,而不是替代表格评价。

图 21 展示 RV2V 定性比较。参考引导编辑最怕两类失败:参考对象不像,或者源视频被破坏。Bernini 的优势集中在两者之间的平衡。

图 22 展示更多泛化样例。它支持论文关于多样编辑指令的主张,但仍然需要注意:泛化案例是展示性证据,真正的可复现结论仍要回到 benchmark 设计、评价协议和消融实验。
这篇工作的边界与可复现性
Bernini 的贡献很清楚,但边界也必须讲清楚。
第一,它不是完全开源可复现的“训练配方”。论文公开了架构、数据构造思路、训练阶段、关键超参和评测,但大量数据是 in-house,大量模型组件也依赖强基础模型。读者可以复现思想和部分结构,很难完整复现同等规模结果。
第二,它仍依赖强外部模型。论文实现中使用 Qwen2.5-VL-7B 作为 MLLM planner,Wan2.2-A14B 作为 DiT renderer,并且默认会用额外 MLLM 重写用户指令。结论里作者也承认,在复杂编辑场景下仍依赖强 LLM rewriter,说明系统原生推理能力还没有完全替代外部 prompt enhancement。
第三,评估体系仍有不确定性。视频编辑没有像图像分类那样简单的客观指标。Bernini-Bench 的自动评分依赖 MLLM,论文自己也指出 MLLM 对细微视觉失真判断不可靠。人评能补足一部分,但人评成本高、主观性强,benchmark 覆盖范围也会影响结论。
第四,画质不一定全面领先。论文明确提到,在 subject-to-video generation 中,Bernini 的一致性很强,但视觉质量仍落后于更强闭源系统如 Wan2.7。换句话说,Bernini 更像是把理解能力接入编辑和参考生成的系统方案,而不是单纯追求最强画质的 renderer。
第五,系统复杂度较高。MLLM planner、ViT embedding decoder、DiT renderer、多条件 guidance、SA-3D RoPE、CoT 数据、三阶段训练、长序列并行优化,这些组合形成了很强能力,也形成了很高工程门槛。对一般团队来说,直接复刻不现实,更现实的是抽取其中的接口思想。
如果继续研究/落地,应该关注什么
第一,关注“语义接口”而不是只关注模型名。Bernini 最值得迁移的不是 Qwen2.5-VL 或 Wan2.2 这两个具体选择,而是 ViT embedding space 作为 planner-renderer 接口的思想。未来更强的 MLLM 和视频 DiT 出现后,这个接口仍可能成立。
第二,关注视频编辑的数据飞轮。高质量 V2V 数据太难直接收集,Bernini 用 video pairs、image pairs、I2I、I2V、propagation、motion-aware、R2V/RV2V、CoT 数据一起构建训练分布。这说明视频编辑模型的壁垒不只是模型结构,更多在数据构造和质量筛选。
第三,关注多参考输入的 segment 建模。AI 产品里会越来越多出现“拿这张图里的鞋子、那张图里的风格、这个视频里的动作,生成一个新视频”的需求。多条件多参考会成为常态,SA-3D RoPE 这类角色区分机制会越来越重要。
第四,关注可控 guidance。Bernini 把 source video、reference image、text、target semantic embeddings 的 guidance 拆开,这为产品层调参留下空间。不同场景可以偏向保真、偏向改动、偏向参考一致性或偏向文本指令。对商业产品来说,这种可控性比单一 benchmark 分数更有价值。
第五,关注推理增强从语言走向视觉。语言 CoT 在视频编辑里有帮助,但视觉中间状态可能更关键。未来的视频 Agent 不只是写 prompt,而是能先生成计划帧、布局草图、运动草稿,再调用渲染器执行。
术语与概念速查
| 术语 | 本文中的含义 | 为什么重要 |
|---|---|---|
| MLLM planner | 基于多模态大模型的语义规划器 | 负责理解长指令、多参考输入和目标视觉语义 |
| DiT renderer | 基于 Diffusion Transformer 的渲染器 | 负责在 VAE latent space 里合成最终视频 |
| ViT embedding space | MLLM 视觉编码器使用的连续语义空间 | Bernini 用它作为理解到生成的接口 |
| Mask-based semantic planning | 训练时遮住部分目标视觉 token,推理时从全 mask 逐步补全 | 让 planner 学会从上下文推断目标语义 |
| SA-3D RoPE | 加入 segment index 的 3D rotary position encoding | 区分源视频、参考图和目标输出,减少参考泄漏 |
| VAE latent features | 视频扩散模型的低层潜空间特征 | 保留源视频细节、身份和非编辑区域一致性 |
| RV2V | Reference-guided Video-to-Video editing | 同时要求源视频一致性和参考图一致性 |
| Self-vision-text reasoning | 通过视觉中间状态增强编辑推理 | 把语言计划落到可见的视觉变化上 |
| Flow matching | 连续生成模型的一类训练目标 | Bernini 在 ViT embedding decoder 和 DiT renderer 中都使用这一范式 |
| NFE | Number of Function Evaluations | 衡量扩散/flow 采样推理步数和成本 |
拓展思考:值得继续扩展研究与思考的创新点
Bernini 这篇论文最值得继续研究的,不是某个 benchmark 分数,而是它背后的“分工式统一”思想。
第一,视频生成的下一阶段可能不是纯 unified transformer,也不是纯 diffusion scaling,而是 planner-renderer 架构。理解和渲染天然是两种能力:理解需要跨模态语义、长上下文和推理;渲染需要高分辨率、时序一致性和物理细节。把两者硬塞进一个模型当然有吸引力,但在当前算力和数据条件下,分工式系统往往更现实。
第二,ViT embedding space 可能成为多模态生成的重要中间货币。过去 AI 系统里的中间货币主要是文本,现在视觉生成越来越复杂,文本已经不足以承载所有空间、身份、材质和时序关系。连续视觉语义 embedding 可能成为未来多模态 Agent 调用生成器时的重要接口。
第三,视频编辑产品的护城河会从“能不能生成”转向“能不能稳定执行意图”。当基础视频模型越来越强,单纯画质差距会被压缩;真正长期有价值的是复杂指令理解、多参考一致性、局部可控、非编辑区域保真、工作流可调和低成本推理。
第四,数据构造会成为视频模型公司的核心资产。Bernini 里的数据 pipeline 非常重:视频对、图像对、传播式编辑、运动感知编辑、参考主体、运动迁移、推理增强。这里每一类数据都不是随便 scraped,它们都对应视频编辑里的一个能力缺口。Rocky认为,未来视频生成公司的长期差异,不只是模型结构,而是能不能持续发现这些能力缺口,并把它们变成训练数据。
最后,Bernini 给 AI Agent 领域一个很直接的启发:Agent 不应该只停留在“想清楚再调用工具”,而应该学会在任务原生的潜在空间里规划。写代码有代码空间,做设计有布局空间,做视频有视觉语义空间。真正强的 Agent,不只是会说计划,而是能把计划表达成下游执行器最容易消费的表示。
这就是 Bernini 的本质:它不是让大模型替代扩散模型,也不是让扩散模型自己学会所有理解能力,而是在两者之间建立一个语义计划层。工具会迭代,模型会换代,但这种“把理解转成可渲染计划”的系统思想,大概率会留下来。
推荐阅读
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)
1. 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2025年可以说是AI Agent全面落地应用的元年,因此Rocky在持续撰写对AI Agent的全维度解析文章:深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2. 深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
和Rocky一起学习探究扩散模型的本质原理与和核心基础知识,同时不断跟进扩散模型的最新发展。Rocky在本文中对扩散模型的本质做了全面系统的梳理与讲解:深入浅出完整解析扩散模型DDPM、DDIM、SDE、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
3. 深入浅出完整解析FLUX.2、Seedream(即梦)、Z-image、GLM-Image核心基础知识
https://zhuanlan.zhihu.com/p/1975174691049189562
4. 深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
5. 深入浅出完整解析DeepSeek系列核心基础知识
6、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:深入浅出完整解析Sora、Wan2.1、AnimateDiff、CogVideoX等AI视频大模型核心基础知识
7、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
8、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
9、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:深入浅出完整解析Stable Diffusion(SD)核心基础知识
10、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:深入浅出完整解析ControlNet核心基础知识
11、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
12、深入浅出完整解析AIGC时代Transformer核心基础知识
在AIGC时代中,Transformer为AI行业带来了深刻的变革。Transformer架构正在一步一步重构所有的AI技术方向,成为AI技术架构大一统与多模态整合的关键核心基座,大有一统“AI江湖”之势。Rocky也对Transformer模型进行持续的深入浅出梳理与解析:
Transformer文章地址:深入浅出完整解析AIGC时代Transformer核心基础知识
13、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:手把手教你成为AIGC算法工程师,斩获AIGC算法offer!
14、50万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
15、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:深入浅出完整解析主流AI绘画框架(ComfyUI、Stable Diffusion WebUI、Fooocus)核心基础知识
16、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
17. AI算法工程师的《三年面试五年模拟》求职秘籍
18. AIGC产业的深度思考与分析
2023年3月21日,微软创始人比尔·盖茨在其博客文章《The Age of AI has begun》中表示,自从1980年首次看到图形用户界面(graphical user interface)以来,以OpenAI为代表的科技公司发布的AIGC模型是他所见过的最具革命性的技术进步。
Rocky也认为,AIGC及其生态,会成为AI行业重大变革的主导力量。AIGC会带来一个全新的红利期,未来随着AIGC的全面落地和深度商用,会深刻改变我们的工作、生活、学习以及交流方式,各行各业都将被重新定义,过程会非常有趣。
那么,在此基础上,我们该如何更好的审视AIGC的未来?我们该如何更好地拥抱AIGC引领的革新?Rocky准备从技术、产品、商业模式、长期主义等维度持续分享一些个人的核心思考与观点,希望能帮助各位读者对AIGC有一个全面的了解:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)