LLM —— 基础知识(Bert&GPT&T5)浅析
目录
1.自编码模型 (AutoEncoder model,AE) 代表 => Bert模型
2.自回归模型 (Autoregressive model,AR) 代表 =>. GPT
3.序列到序列(Sequence to Sequence Model) 代表 => T5模型
2. GGUF / GGML(本地 CPU/GPU 推理, llama.cpp 生态)
一、语言模型发展史
1.基于规则和统计的语言模型
链式法则
P(S)=P(W1,W2,....,Wn)=P(W1)∗P(W2|W1)∗....∗P(Wn|W1,W2,....,Wn−1)
N-gram语言模型特点:
优点:
① 原理简单,好理解,可解释性强,
②参数可以从语料库统计得到,训练简单。
缺点:
① 上下文长度限制
② 数据稀疏性,如语料库中美出现过,词频为0,导致概率为0
③ 泛化能力差,无法了解词语之间的语义相似性。如“喜欢”和“热爱”是近义词
2.神经网络语言模型
RNN、LSTM、GRU等
优点:
① 通过词向量,模型可以泛化到未训练见过的词语组合
② 捕捉语义相似度,语义相近的词,在向量空间中的位置更近使得模型具备更好的泛化能力。
缺点:
① 上下文长度固定
② 计算复杂度高,输出层的softmax计算量打,与词表大小成正比。
③ 长距离依赖问题,还面临梯度消失和爆炸,难以有效捕捉长距离依赖。
3.基于transformer的预训练模型
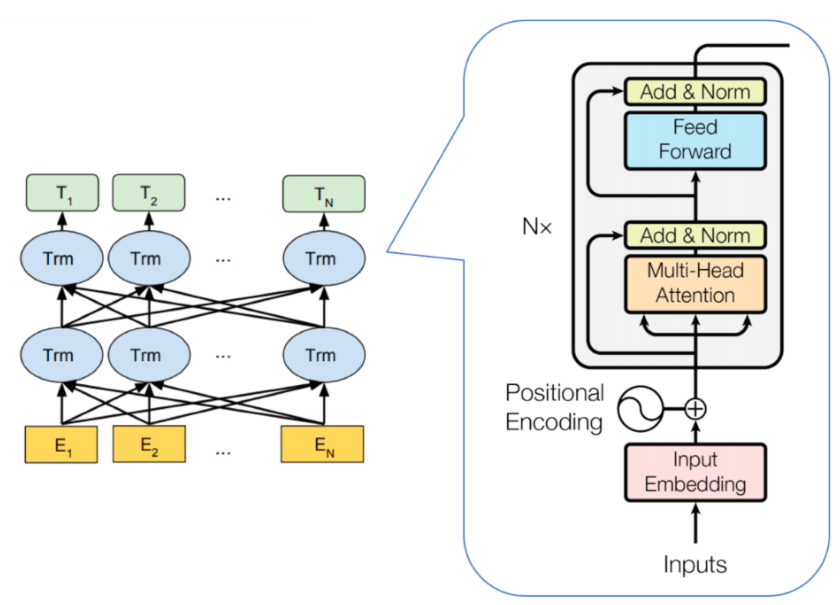
transformer、自注意机制(多头自、掩码多头自)、多头交叉注意力,解决了长距离依赖,并且可以完美解决长距离依赖问题,batch_size,并行计算,大大提升训练速度。
原理篇:NLP - Transformer原理解析-CSDN博客
基于transformer的预训练模型Bert、GPT、T5等。通过大量通用文本数据学习大量的语言,并将这些知识运用到下游任务中。
预训练语言模型的使用方式:
- 预训练:预训练指建立基本的模型,先在一些比较基础的数据集、语料库上进行训练,然后按照具体任务训练,学习数据的普遍特征。
- 微调:微调指在具体的下游任务中使用预训练好的模型进行迁移学习,以获取更好的泛化效果。
预训练语言模型的特点:
- 优点:更强大的泛化能力,丰富的语义表示,可以有效防止过拟合。
- 缺点:计算资源需求大,可解释性差等。
4.大语音模型(LLM)
LLM 具有大规模参数(十亿=1B 或 更大级别)深度学习模型。
LLM三大主流框架
① Encoder - Only 架构
-
代表模型:BERT, RoBERTa, DeBERTa
-
特点:能够同时“看到”整个输入句子的上下文(双向理解),极其擅长 深度理解 。
-
适用任务:文本分类、情感分析、命名实体识别等需要对文本进行全面理解的任务。
② Encoder - Decoder 架构
-
代表模型:T5, BART, Flan-T5
-
特点:保留了原始 Transformer 的完整结构,适用于将一个文本序列转换为另一个文本序列的 序列到序列 任务。
-
适用任务:机器翻译、文本摘要、问答等。
③ Decoder - Only 架构
-
代表模型:GPT 系列, PaLM, LLaMA, ChatGPT
-
特点:自回归(Auto-regressive)模型,根据前面的文本预测下一个词,极其擅长 内容生成 。
-
适用任务:文章写作、聊天对话、代码生成等需要创意和流畅表达的任务。
二、LLM 三大 (大模型架构)浅析
1.自编码模型 (AutoEncoder model,AE) 代表 => Bert模型
谷歌2018年10月提出的一种预训练模型
Bert架构,采用transformer Encoder block进行连接,典型双向编码模型。
这也是为什么上一篇 NLP模型优化与蒸馏,用BiLSTM
BiLSTM:双向视角对齐 BERT,上下文建模完整,小幅增加开销换来精度与泛化大幅提升,是该蒸馏组合的最优学生模型。
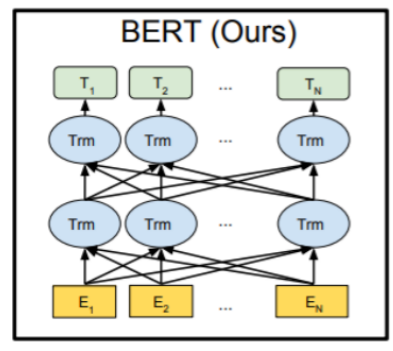
黄色:Embedding模块
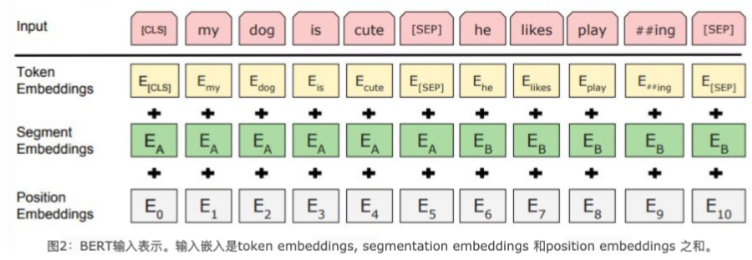
- Token Embeddings 是词嵌入张量, 第一个单词是CLS标志, 可以用于之后的分类任务。
- Segment Embeddings 是句子分段嵌入张量, 是为了服务后续的两个句子为输入的预训练任务。
- Position Embeddings 是位置编码张量, 此处注意和传统的Transformer不同, 不是三角函数计算的固定位置编码, 而是通过可学习参数矩阵,
max_len=512、hidden_size=768【512, 768】,随机初始化
整个Embedding模块的输出张量就是这3个张量的直接加和结果。
蓝色:Transformer模块(只有用编码部分)
纯Encoder的架构能有效地学习语言知识,设计了“掩码语言模型(MLM)”和“下一句预测(NSP)”这两个巧妙的预训练任务
用 MLM + NSP 联合损失,把 BERT 的 Transformer 权重、词嵌入、位置嵌入、段嵌入全部训练好,得到一个 “懂语言” 的通用模型。
绿色:预微调模块
在面对特定任务时,只需要对预微调层进行微调,就可以利用Transformer强大的注意力机制来模拟很多下游任务(句子关系判断、分类、问答(QA)、单句贴标签(NER) 等), 并得到SOTA的结果。
Bert模型参数
| 参数 | 取值 |
|---|---|
| transformer 层数 | 12 |
| 特征维度 | 768 |
| transformer head 数 | 12 |
| 总参数量 | 1.15 亿 |
更适合用于语言嵌入表达, 语言理解方面的任务, 不适合用于生成式的任务
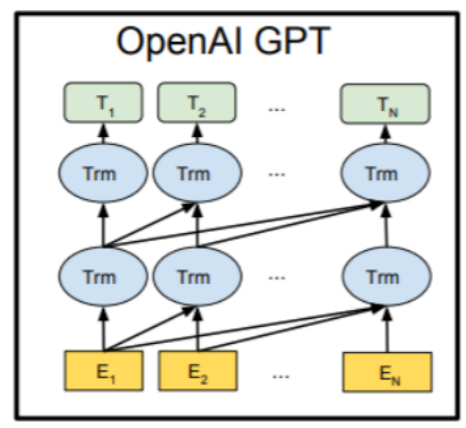
2.自回归模型 (Autoregressive model,AR) 代表 =>. GPT模型
2018年6月,OpenAI公司提出,生成式预训练模型
GPT架构,采用transformer Decoder block,但是没有用到其中的 Multi-Head Attention (交叉注意力)这个子层。
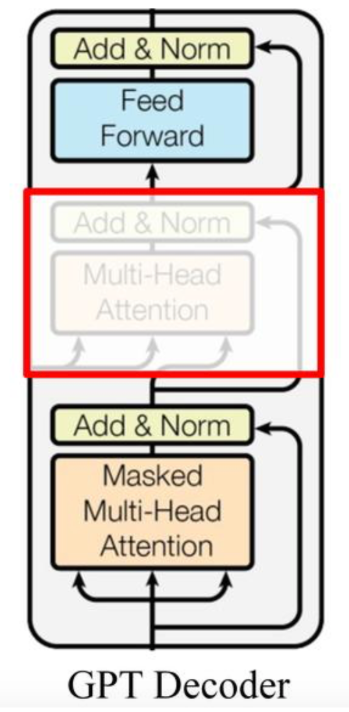
| 参数 | 取值 |
|---|---|
| transformer 层数 | 12 |
| 特征维度 | 768 |
| transformer head 数 | 12 |
| 总参数量 | 1.17 亿 |
优点
- 在有监督学习的12个任务中, GPT在9个任务上的表现超过了state-of-the-art的模型
- 利用Transformer做特征抽取, 能够捕捉到更长的记忆信息, 且较传统的 RNN 更易于并行化
缺点
- GPT 最大的问题就是传统的语言模型是单向的
- 针对不同的任务, 需要不同的数据集进行模型微调, 相对比较麻烦
总结:
AR模型使用注意力机制,预测下一个token,因此自然适用于文本生成,只能用于前向或者后向建模,不能同时使用双向的上下文信息,不能完全捕捉token的内在联系。
3.序列到序列(Sequence to Sequence Model) 代表 => T5模型
同时使用编码器和解码器,Encoder-decoder模型通常用于需要内容理解和生成的任务,比如机器翻译。
T5 是谷歌 2020年7月提出,相关论文为“Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”。 该模型的目的为构建任务统一框架:将所有NLP任务都视为文本转换任务。
T5 模型架构
核心改动
- 归一化逻辑:
- ① 编码器层 左(transformer) —— 右 (T5)


- ② 解码器层 左(transformer) —— 右 (T5)


- 位置编码:外部正弦绝对编码 → 注意力内部可学习相对位置偏置(分桶)

- 激活函数:GELU → ReLU
- 嵌入层:词表全共享、删除 Segment Embedding
- 预训练目标:逐词预测 → 连续片段掩码还原
- 任务范式:多任务多头 → 统一文本转文本 + 任务前缀
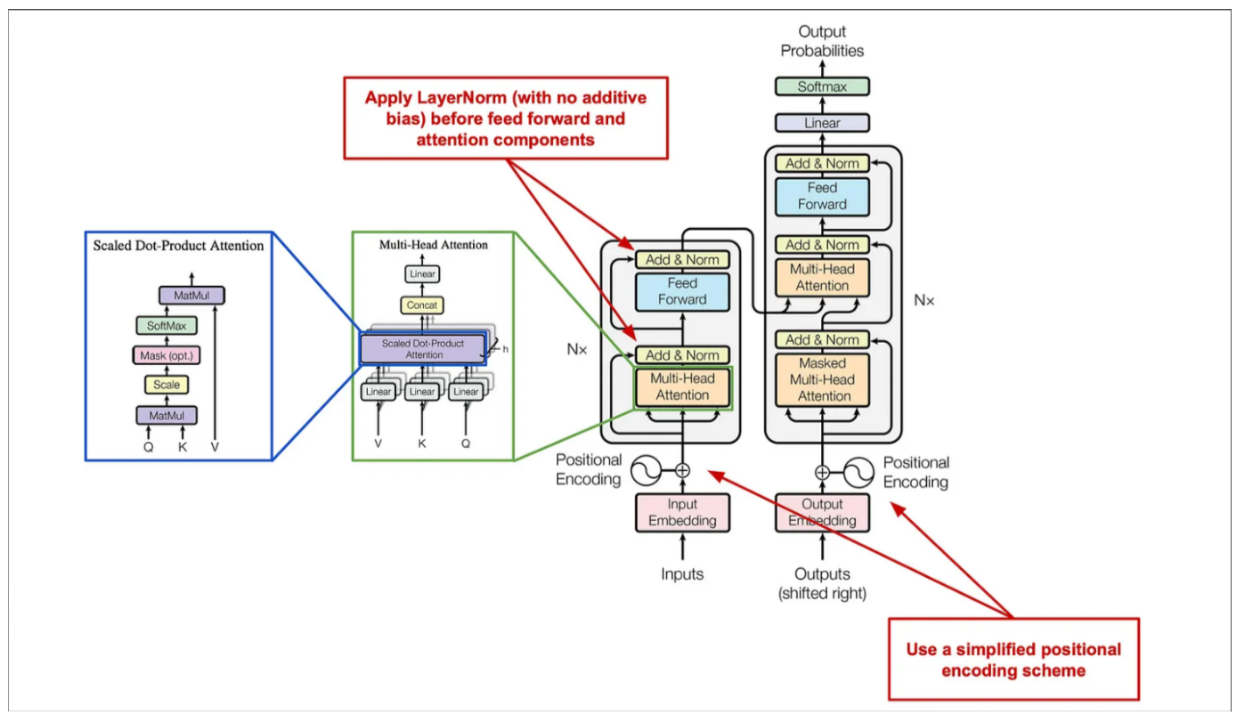
T5 = 标准 Transformer Encoder–Decoder + 相对位置偏置 + RMSNorm+Pre-Norm + 跨度掩码预训练 + 统一文本到文本范式,在保持经典架构的同时,把训练稳定性、长文本能力、任务统一性都拉满了。
T5 模型参数
| 参数 | 取值 |
|---|---|
| transformer 层数 | 24 |
| 特征维度 | 768 |
| transformer head 数 | 12 |
| 总参数量 | 2.2 亿 |
T5 模型优缺点
优点:
T5模型可以处理多种NLP任务,并且可以通过微调来适应不同的应用场景,具有良好的可扩展性;相比其他语言生成模型(如GPT-2、GPT-3等),T5模型的参数数量相对较少,训练速度更快,且可以在相对较小的数据集上进行训练。
缺点:
由于T5模型使用了大量的Transformer结构,在训练时需要大量的计算资源和时间; 模型的可解释性不足。
三、大模型分类
| 类别 | 核心能力 | 架构 | 典型场景 | 代表模型 |
|---|---|---|---|---|
| 生成式模型 | 基于上文生成新文本 | 仅解码器 | 对话、写作、代码生成 | GPT、LLaMA、PaLM |
| 嵌入理解模型 | 文本转为语义向量 | 双塔编码器 | 语义搜索、聚类、推荐 | BERT、RoBERTa、BGE |
| 判别分类模型 | 文本打标签 / 评分 | 单编码器 | 情感分析、意图识别 | BERT、ERNIE、ALBERT |
| 重排模型 | 深度打分、优化排序 | 交叉编码器 | 搜索排序、RAG 精排 | bge-reranker、Cohere Rerank |
| 序列转换模型 | 文本序列互转 | 编码器 + 解码器 | 翻译、摘要、问答 | T5、BART、Flan-T5 |
四、大模型精度类型
1. 浮点型(原生高精度)
-
FP32(单精度):标准全精度,精度最高、占用大,训练常用,推理极少用。
-
FP16 / Half:半精度,主流推理默认,速度、显存平衡,绝大多数模型默认精度。
-
BF16:脑浮点,范围同 FP32、精度略降,训练首选,部分推理框架支持。
2. 低精度量化(推理省显存、加速)
-
INT8:8 位整型,主流量化方案,精度损失小,通用落地首选。
-
INT4:4 位整型,极致省显存,端侧 / 本地部署最常用,轻微精度损耗。
-
INT2:2 位,压缩率最高,精度下降明显,仅极限压缩场景用。
-
FP8:新式 8 位浮点,兼顾速度与精度,新一代硬件 / 模型逐步普及。
五、大模型主流存储 / 模型格式
1. PyTorch 生态
-
.pt / .pth:PyTorch 原生权重文件,训练 / 原生部署用。
-
.bin:Hugging Face 标准权重,主流开源模型默认格式。
2. GGUF / GGML(本地 CPU/GPU 推理, llama.cpp 生态)
-
GGUF:当前本地部署首选,替代旧版 GGML,支持全精度 + 各类量化(F16/Q8_0/Q4_K_M 等),兼容性最强。
3. TensorFlow / 跨框架
-
.ckpt:旧版 TensorFlow/PyTorch 通用检查点。
-
.safetensors:安全权重格式,防恶意代码,Hugging Face 主推,逐步替代
.bin。 -
ONNX:跨框架通用格式,用于部署、推理引擎转换。
4. 专用部署格式
-
.ggla / .guff:llama.cpp 衍生格式。
-
TensorRT / TRT:英伟达 GPU 专用优化格式,极致推理加速。
-
CoreML:苹果端侧部署格式。
快速总结(日常使用)
-
训练:优先 BF16 / FP32,格式
.bin/.safetensors -
云端推理:FP16 / INT8,格式
.bin/safetensors/ONNX -
个人本地部署:INT4(Q4_K_M),格式 GGUF

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)