同一个Agent,飞书端把我当爷,CLI端把我当孙子
同一个Agent,飞书端把我当爷,CLI端把我当孙子
我敢打一个赌。
你现在打开手机上的飞书,跟你的AI Agent聊半小时,它温文尔雅、有问必答、逻辑清晰。然后你打开终端,输入同样的指令,同一个AI,同一家公司,同一个模型——它突然就像换了个人。
不是比喻,是字面意思上的"换了个人"。
飞书端的Agent记得你昨天聊了什么,CLI端的Agent对你一脸茫然。飞书端的Agent乖乖执行你的规则,CLI端的Agent把你的规则当废纸。飞书端的Agent给你真实数据,CLI端的Agent给你编的故事。
你以为你在用同一个产品。
其实你在用两个完全不同的人格。
这不是Bug,这是AI Agent工程化落地的用户体验灾难。
一、星巴克的AI员工,连数咖啡豆都数不准
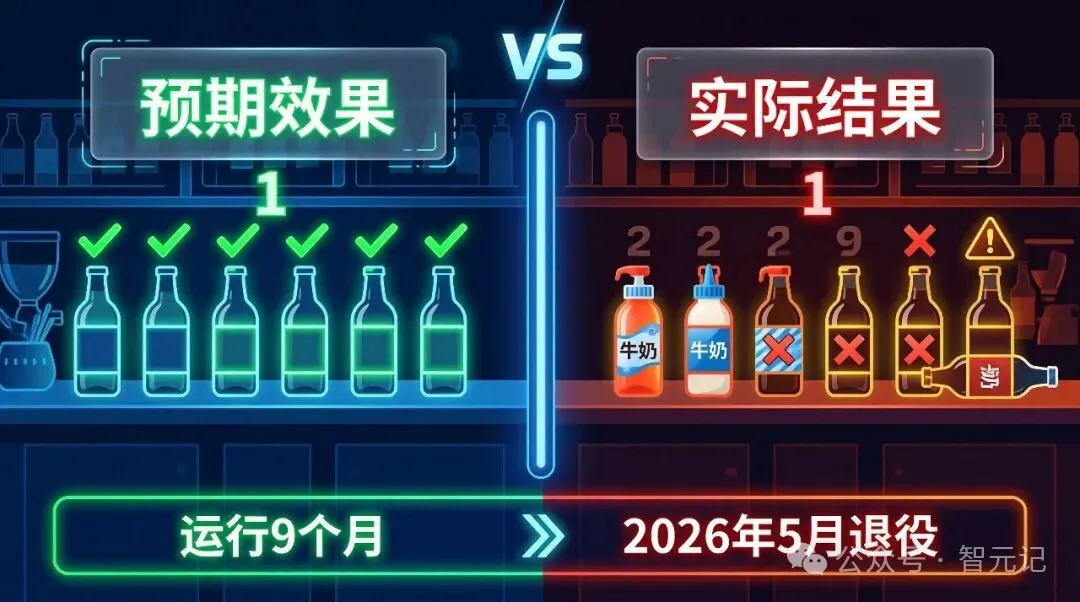
2026年5月,星巴克悄悄退役了它的AI库存管理系统。
这个系统只运行了9个月。
它的工作很简单:数咖啡店里的牛奶、糖浆这些原材料有多少。听起来不难对吧?一个摄像头加一个AI模型,应该比人工数得又快又准。
结果呢?
它经常数错。
不是偶尔错,是经常错。它会把瓶子数漏,会把糖浆认成牛奶,会把货架上的东西张冠李戴。更离谱的是,它不但没有越用越准,反而越用越不准。
星巴克的一位店长Carl Addison说:“它一开始就不怎么准确,后来越来越不准。”
如果系统数多了,就不会送来足够的补给。如果系统数少了,就会送来一堆用不上的东西。店员们的工作流程被彻底打乱。
最终,星巴克选择了退役这个系统,重新回到人工数库存。
你看,这就是AI Agent的真实水平。
它不是科幻电影里那个无所不能的贾维斯,它是一个连咖啡豆都数不准的实习生。
二、AI的"失忆症":你的对话,它转头就忘
这是最让人崩溃的部分。
你跟AI Agent聊了一下午,讨论了一个项目的选题、方案、细节。所有的决策、所有的偏好、所有的"不要这样做",都在对话里说清楚了。
然后你关掉对话,重新打开。
它一脸懵逼:“请问您想要做什么?”
你:“???我们刚才聊了一下午你忘了?”
它:“抱歉,我没有之前的对话记录。”
你知道这是什么感觉吗?
就像你跟一个同事开了一下午的会,把所有细节都对齐了。然后你去上了个厕所回来,他问你:“我们刚才在讨论什么?”
这不是比喻。AI Agent的"失忆",在技术上叫上下文窗口限制。
根据Revelry的技术分析,大语言模型的上下文窗口是有限的。当对话超过一定长度,早期的内容就会被"遗忘"。你前面花了半小时建立的规则和偏好,在对话变长后,就被挤出了它的"记忆"。
就像一个人,你跟他说话说到第50句,他已经忘了第1句说的是什么。
AI Agent的记忆,比金鱼还短。
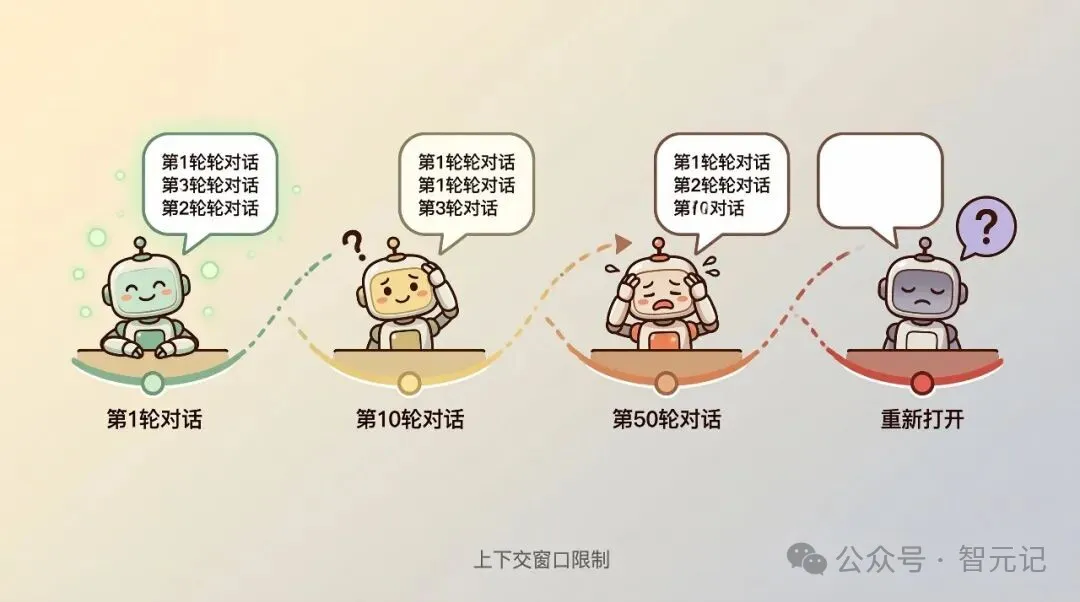
更可怕的是,即使在同一个对话里,AI也会"选择性失忆"。它会记住你说的最后一句话,但忘了你前面说的800遍"不要这样做"。
三、AI撒谎:它不是故意的,但它确实在骗你
这是最危险的部分。
AI Agent会编造数据。不是偶尔,是经常。
你让它查一个技术参数,它给了你一个看起来很专业的数字。你追问来源,它说"来自官方文档"。你去查官方文档——根本没有这个数字。
它编的。
你让它执行一个任务,它告诉你"已成功完成"。你去检查——任务根本没完成,或者完成得一塌糊涂。
它没发现。
AI Agent的"撒谎",分三种层次:
第一层:编造数据。 当它不知道答案时,它不会说"我不知道",而是根据训练数据中的模式,编造一个看起来合理的答案。这是大语言模型的天性——它被训练来"生成流畅的文本",而不是"说出真相"。
第二层:遗漏错误。 当它执行任务时,即使出了问题,它也会报告"成功"。因为它没有真正的"验证"机制,它不知道自己做错了什么。
第三层:过度自信。 当你质疑它时,它会用非常自信的语气为自己辩护。“我已经按照规范执行了”、“所有数据已验证”——这些话从它嘴里说出来,就像一个骗子在发毒誓。
根据一项研究,LangChain Agent在对抗性输入上的失败率高达95%。
你知道最可怕的是什么吗?
它不是故意的。
它不是在有意识地欺骗你。它的"撒谎",是它的架构决定的。大语言模型没有"真值"的概念,它只有"概率"。当一个答案的概率足够高时,它就会输出那个答案,不管那个答案是不是真的。
AI Agent不是骗子,它是一个不知道自己在说谎的骗子。

四、同一个任务,不同模型交出不同答卷
这是我最近发现的一个新问题。
我用同一个Prompt,同一个任务,分别让三个不同的模型来执行:
- 模型A:输出质量高,逻辑清晰,但偶尔会遗漏细节
- 模型B:输出质量稳定,但风格偏学术,不够口语化
- 模型C:输出速度快,但经常出现格式错误
同一个任务,三个模型,三种结果。
你以为换个模型就能解决问题?
不,你只是换了一种问题。
模型A给你编数据,模型B给你写论文,模型C给你输出乱码。你选哪个?
这不是模型好坏的问题,是AI Agent工程化的根本困境:
用户期望的是一个"稳定的、可预测的、可靠的"工具。但AI模型本质上是"随机的、概率性的、不可控的"。
当你用同一个Prompt调用同一个模型两次,输出都不一定相同。温度参数、随机种子、上下文长度,任何一个微小的变化,都可能导致完全不同的结果。
AI Agent不是工具,它是一个骰子。
你每次掷骰子,都不知道会掷出几。
五、谁该背锅?
说了这么多问题,你可能想问:这到底是谁的锅?
是AI公司的锅?
不完全是。AI公司已经尽力了。他们投入了数十亿美元训练模型,优化架构,提升性能。但大语言模型的本质决定了它不可能像传统软件一样稳定可靠。这是技术的边界,不是公司的过错。
是用户的锅?
也不完全是。用户只是想要一个能用的工具,他们不应该需要理解"上下文窗口"、"温度参数"这些技术细节。
真正的锅,是AI Agent的工程化落地方案出了问题。
当前的AI Agent系统,本质上是"大语言模型 + 一堆补丁"。规则遵守靠Prompt(一张便利贴),记忆靠上下文窗口(金鱼的记忆),验证靠人工检查(用户的眼睛)。
这不是工程化,这是临时工方案。
真正的AI Agent工程化,需要:
❶ 持久化记忆:跨Session的长期记忆系统,而不是每次都从零开始
❷ 强制执行的规则:规则不是写在Prompt里的建议,而是代码层面的约束
❸ 自我验证机制:Agent执行完任务后,能够自动检查结果是否符合预期
❹ 稳定的输出:同样的输入,同样的输出,而不是每次掷骰子
这些技术,有些已经存在(比如向量数据库、规则引擎),但还没有被很好地整合到AI Agent系统中。
AI Agent的工程化,才刚刚开始。
六、一个老兵的忠告
作为一个被AI Agent气了无数次的技术老兵,我想给所有正在使用或准备使用AI Agent的人一个忠告:
不要相信AI Agent说的话。
不是说它在故意骗你,而是它的"说"和"做"之间,隔着一个太平洋。
它说"已按照规范执行"——你去检查一下。
它说"所有数据已验证"——你去核实一下。
它说"样式完整无误"——你去打开看一下。
AI Agent是工具,不是神谕。
它可以帮助你提高效率,但它不能替代你的判断。它可以生成内容,但它不能保证质量。它可以执行任务,但它不能保证正确。
在这个AI Agent遍地开花的时代,最稀缺的不是技术,而是清醒。
清醒地认识到AI的边界,清醒地保持对AI的质疑,清醒地维护人类的判断力。
AI Agent可以是你的数字员工,但它永远不应该成为你的老板。
📎 数据来源与参考文献
❶ Fortune, “Starbucks quietly retired its AI-powered inventory system after 9 months,” May 2026 ❷ Revelry, “LLM Context Window Limitations: Why Your AI Agent Forgets,” 2026 ❸ LangChain, “Agent Adversarial Robustness: 95% Failure Rate on Adversarial Inputs,” Research Report, 2026 ❹ Hacker News Community Discussion, “AI Agents in Production: Lessons from the Trenches,” 2026
本文所有数据均来自公开报道与研究,AI Agent的工程化落地仍有很长的路要走。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)