wandb:机器学习实验追踪的标准方案
wandb:机器学习实验追踪的标准方案
wandb 在 GitHub 上已经拿到 11,100 Star 了。
Weights & Biases 简称 wandb,做的事是机器学习实验追踪和可视化。从数据集到生产模型,整个流程的指标、超参数、输出都能记下来,在 web 面板上对比查看。
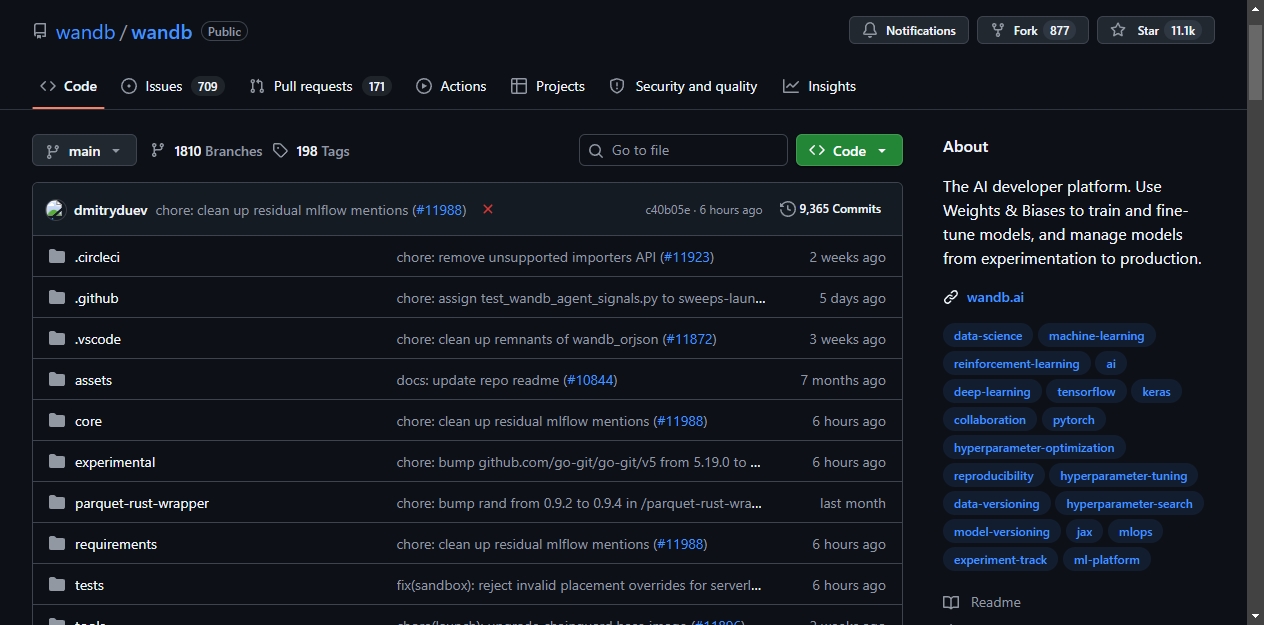
1、这玩意是干嘛的
训练模型时,loss、accuracy、学习率这些数据散落在各个脚本里,想对比两次实验得手动翻日志。wandb 把这些东西串成一条线:每次训练启动就是一个 run,指标自动上传,超参数自动归档,artifact 版本也能管。
它不只记数字。模型权重、数据集版本、环境配置,全都可追踪。团队里谁改了什么、哪次实验效果最好,打开面板一目了然。
2、为什么用它
做深度学习实验的人都有过这种经历:跑了一组参数,隔两天忘了当初设了什么,结果复现不出来。或者团队里每个人都在本地跑实验,数据存在各自电脑里,汇总起来一团乱。
wandb 解决的就是这个问题。所有实验数据集中到一处,自动带时间戳和配置快照。你可以把某次 run 标记为 baseline,其他人直接对比自己的实验和 baseline 的差异。
另一个实用功能是 artifact 管理。训练好的模型、预处理过的数据集,都可以作为 artifact 版本化保存,后续实验直接引用,不用到处传文件。
3、安装与使用
安装:
pip install wandb
注册账号并创建 API key,然后用命令行登录:
wandb login
在代码里创建一个 run:
import wandb
project = "my-awesome-project"
config = {"epochs": 1337, "lr": 3e-4}
with wandb.init(project=project, config=config) as run:
# 训练代码
run.log({"accuracy": 0.9, "loss": 0.1})
wandb.init() 初始化一个 run,run.log() 上传指标。with 语法会在代码块结束时自动标记 run 完成,如果抛出异常则标记为 failed。
面板上可以看到每次 run 的 accuracy 和 loss 随训练步数的变化,run 列表会自动生成名字。
4、框架集成
wandb 和 PyTorch、TensorFlow、Keras、Hugging Face、Lightning 等主流框架都有集成。不需要大幅改动现有代码,加几行就能接入。
做 LLM 应用的人也可以看看 Weave,这是 wandb 推出的新工具集,专门用来跟踪、调试、评估和监控 LLM 应用。
5、部署方式
wandb 提供三种托管方案:
- Multi-tenant Cloud:wandb 官方托管,在 GCP 北美区域运行,注册即用。
- Dedicated Cloud:单租户实例,部署在 wandb 的 AWS、GCP 或 Azure 账户中,网络、计算和存储与其他实例隔离。
- Self-Managed:部署在你自己的 AWS、GCP、Azure 账户或本地基础设施上。
企业有数据合规要求时,后两种方案更合适。
6、适合谁用
- 需要追踪大量实验、对比不同超参数效果的 ML 研究者
- 团队协作训练模型、需要共享实验记录和 artifact 的工程师
- 搭建 LLM 应用、需要跟踪和评估流水线的人(wandb 的 Weave 工具专门面向这个场景)
wandb 用的是 MIT 协议,可商用。
师
- 搭建 LLM 应用、需要跟踪和评估流水线的人(wandb 的 Weave 工具专门面向这个场景)
wandb 用的是 MIT 协议,可商用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)