给 RNN 装上“会增长的记忆”:解读 Google 的 Memory Caching
这篇论文来自 Ali Behrouz 团队,是他们 Titans / Atlas / Miras / Nested Learning 这条测试时记忆(test-time memorization)研究线上的最新一篇。它想回答一个老问题:为什么效率更高的递归模型,在长上下文和召回任务上始终打不过 Transformer? 答案被归结为一个结构性瓶颈——RNN 只有一块固定大小的记忆,被迫不断遗忘。而本文给出的解法朴素得出奇:别让旧记忆消失,把它们存档下来。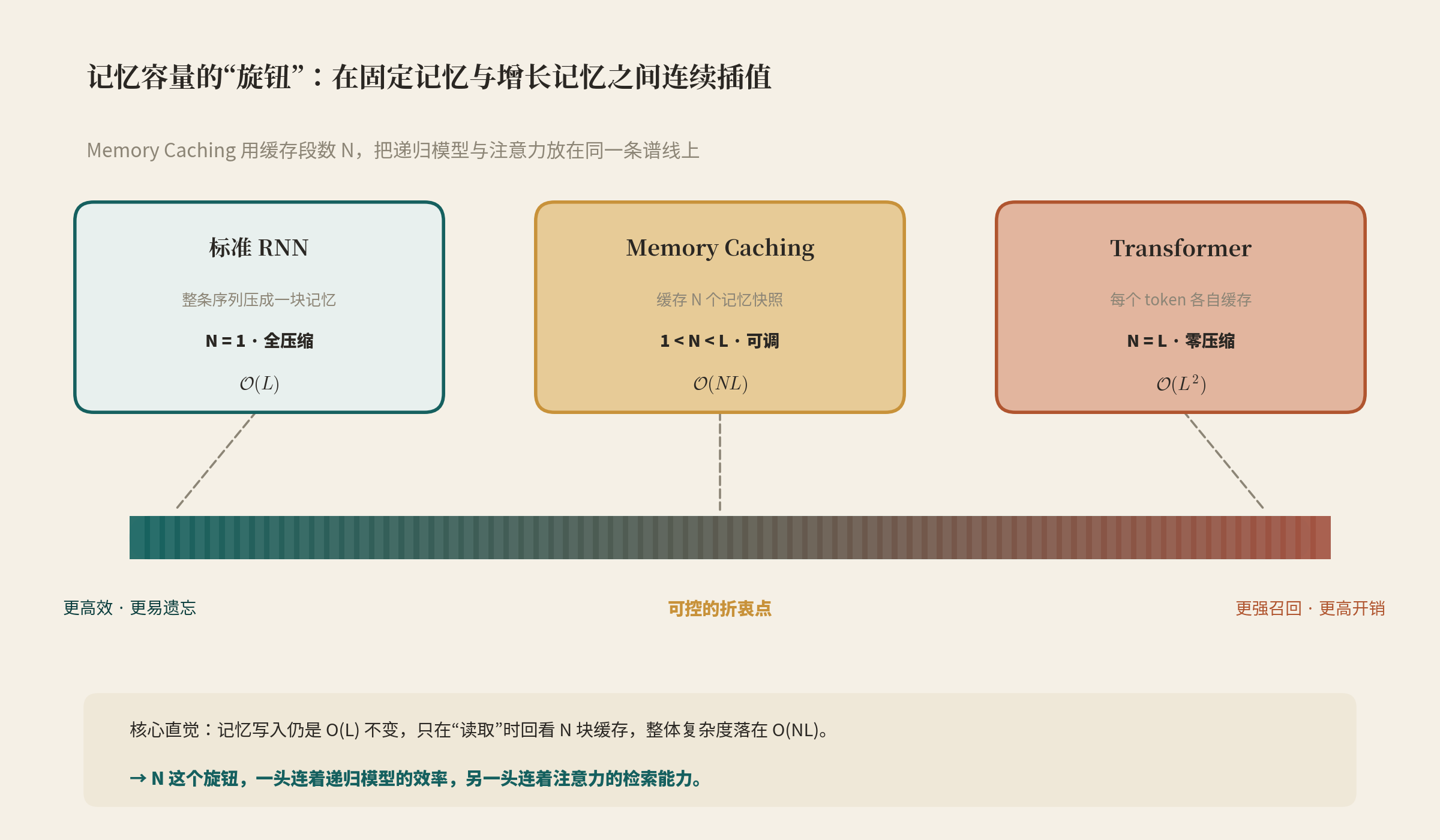
一、问题背景:固定记忆 vs 增长记忆
要理解这篇论文,先要看清两类模型在"记忆"上的根本差异。
1.1 注意力 = 增长的关联记忆
标准注意力(Vaswani et al., 2017)对每个查询 qiq_iqi,要遍历全部历史 token:
yi=1Zi∑t=1iexp (qi⊤kt) vt y_i = \frac{1}{Z_i}\sum_{t=1}^{i}\exp\!\big(q_i^\top k_t\big)\,v_t yi=Zi1t=1∑iexp(qi⊤kt)vt
它本质上是一个容量随上下文增长的关联记忆——每个 token 都被原样缓存(即 KV-cache),因此检索时能直接访问序列任意位置。这正是它召回能力强的来源,但代价是 O(L2)\mathcal{O}(L^2)O(L2) 的计算和推理时不断膨胀的显存。
1.2 线性注意力 / RNN = 固定的压缩记忆
线性注意力(Katharopoulos et al., 2020)把 exp(⋅)\exp(\cdot)exp(⋅) 换成可分解核 ϕ(⋅)\phi(\cdot)ϕ(⋅),于是注意力退化成一个固定大小的记忆矩阵的递归更新:
Mt=Mt−1+vt ϕ(kt)⊤,yi=1ZiMi ϕ(qi) \mathcal{M}_t = \mathcal{M}_{t-1} + v_t\,\phi(k_t)^\top,\qquad y_i = \frac{1}{Z_i}\mathcal{M}_i\,\phi(q_i) Mt=Mt−1+vtϕ(kt)⊤,yi=Zi1Miϕ(qi)
记忆只有一块、大小不变。序列一长,这块记忆就"溢出"——被迫遗忘旧信息。这是 RetNet、RWKV、DeltaNet、Titans 这一大类模型在 recall 密集任务上吃亏的共同根源。
1.3 测试时记忆视角
作者所在团队提出过一个统一框架:把序列模型的更新规则看作一个前向过程中动态进行的"在线学习/记忆"。最简形式下,记忆模块 M(⋅)\mathcal{M}(\cdot)M(⋅) 在学习键值映射,每步求解一个带保留项的内部目标(attentional bias):
Mt+1=argminM L(M(kt);vt)+Ret(M;Mt) \mathcal{M}_{t+1} = \arg\min_{\mathcal{M}}\; \mathcal{L}\big(\mathcal{M}(k_t);v_t\big) + \mathcal{R}_{e_t}(\mathcal{M};\mathcal{M}_t) Mt+1=argMminL(M(kt);vt)+Ret(M;Mt)
这个视角是本文的关键支点:既然递归更新是一个优化过程,那么记忆的中间状态就是这个优化过程的检查点(checkpoint)。Memory Caching 做的事,本质上就是把这些检查点存下来。
二、Memory Caching 框架
2.1 核心机制:分段、缓存、聚合
做法分三步,直觉非常清晰:
- 分段:把序列切成 NNN 个段 S(1),…,S(N)S^{(1)},\dots,S^{(N)}S(1),…,S(N);
- 压缩:每段用记忆模块按原本的递归规则压缩,压缩完把该段的最后状态 ML(s)(s)\mathcal{M}^{(s)}_{L^{(s)}}ML(s)(s) 缓存下来;
- 聚合检索:当前 token 的输出,不再只用当前记忆,而是把在线记忆 + 所有历史缓存记忆一起喂给查询。
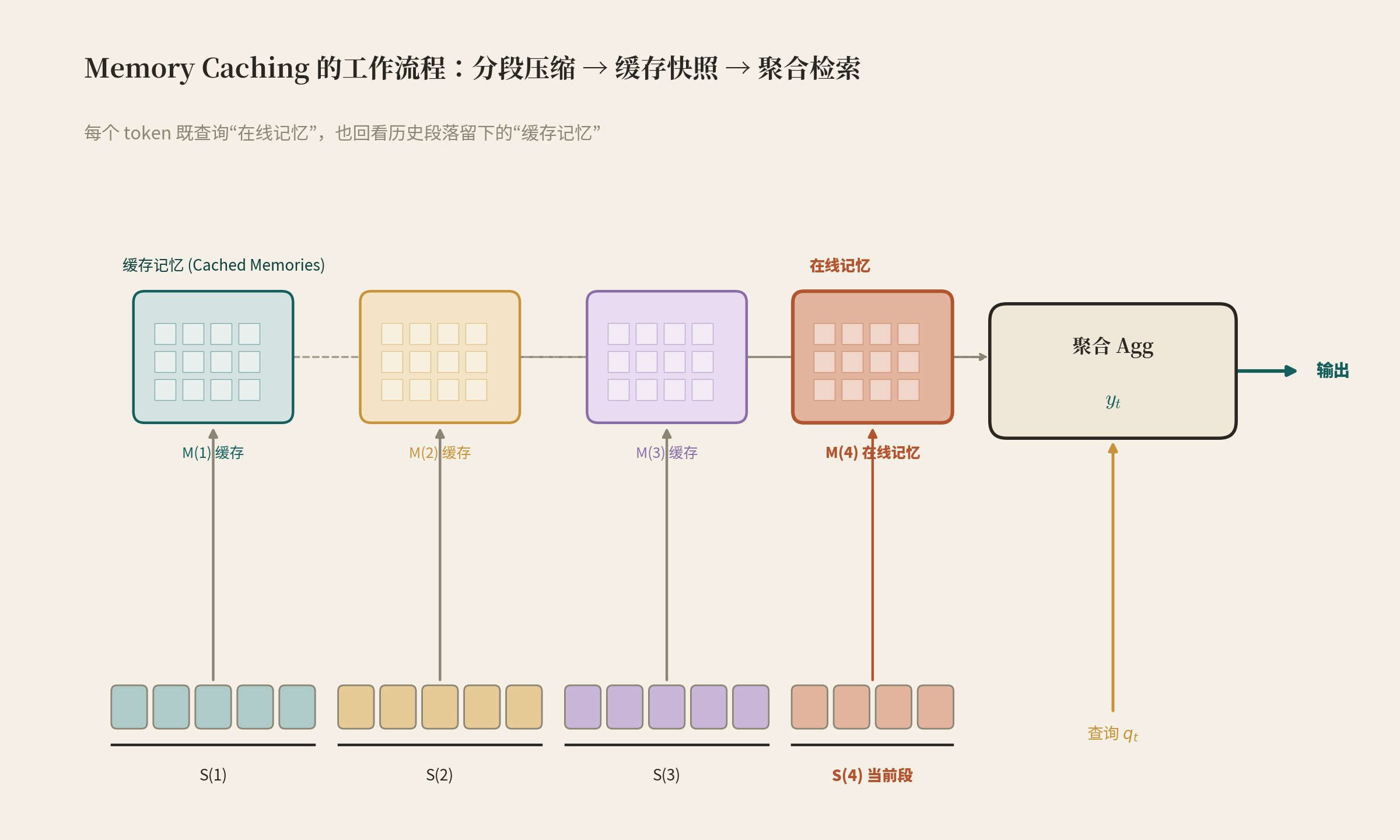
标准 RNN 的输出是 yt=Mt(qt)y_t = \mathcal{M}_t(q_t)yt=Mt(qt);而 MC 给出一个聚合函数 Agg(⋅)\mathrm{Agg}(\cdot)Agg(⋅):
yt=Agg({ML(1)(1)(⋅),…,ML(s−1)(s−1)(⋅)}; Mt(s)(⋅); qt) y_t = \mathrm{Agg}\Big(\{\mathcal{M}^{(1)}_{L^{(1)}}(\cdot),\dots,\mathcal{M}^{(s-1)}_{L^{(s-1)}}(\cdot)\};\ \mathcal{M}^{(s)}_t(\cdot);\ q_t\Big) yt=Agg({ML(1)(1)(⋅),…,ML(s−1)(s−1)(⋅)}; Mt(s)(⋅); qt)
2.2 为什么是 O(NL)\mathcal{O}(NL)O(NL)
这里有个值得敲黑板的点:记忆的写入(更新)完全没改,仍是 O(L)\mathcal{O}(L)O(L);多出来的成本只在读取——每个 token 要对 NNN 块缓存各做一次前向,于是每 token 检索成本 O(N)\mathcal{O}(N)O(N),整体落在 O(NL)\mathcal{O}(NL)O(NL),其中 1≤N≤L1\le N\le L1≤N≤L。这正是它能"几乎免费地"嫁接到任意 RNN 上的原因。两个端点也很自然:
- N=1N=1N=1:不缓存任何状态 → 退化成普通递归模型 O(L)\mathcal{O}(L)O(L);
- N=LN=LN=L:每个 token 自成一段、全部缓存 → 逼近注意力的"直接访问" O(L2)\mathcal{O}(L^2)O(L2)。
三、四种聚合策略
聚合函数 Agg(⋅)\mathrm{Agg}(\cdot)Agg(⋅) 怎么设计,是本文的主要技术贡献。论文给了四种,从最朴素到最精巧:
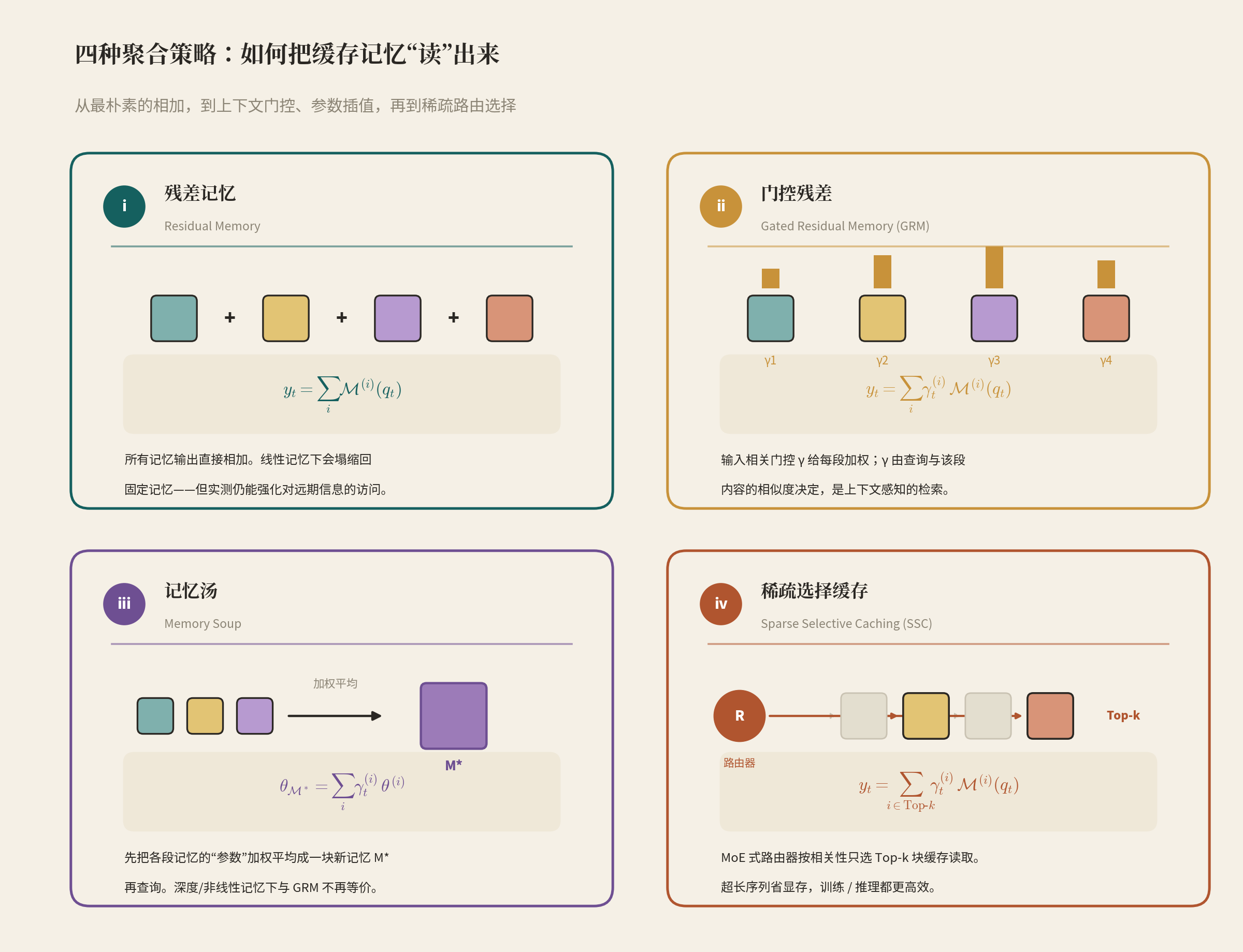
3.1 残差记忆(Residual Memory)
最简单——把在线记忆和所有缓存记忆的输出直接相加,相当于在记忆状态间加残差连接:
yt=Mt(s)(qt)⏟在线记忆+∑i=1s−1ML(i)(i)(qt)⏟缓存记忆 y_t = \underbrace{\mathcal{M}^{(s)}_t(q_t)}_{\text{在线记忆}} + \underbrace{\sum_{i=1}^{s-1}\mathcal{M}^{(i)}_{L^{(i)}}(q_t)}_{\text{缓存记忆}} yt=在线记忆 Mt(s)(qt)+缓存记忆 i=1∑s−1ML(i)(i)(qt)
这里有个微妙之处:如果记忆是线性的(矩阵),这些缓存可以提前求和,公式会塌缩回一块固定记忆,理论上等于没改。但实验上它仍然有效——作者解释这是因为它充当了一个"保留算子(retention operator)",强化了对远期信息的访问。
3.2 门控残差记忆(GRM)
针对上面的塌缩问题,引入输入相关的门控 γt(i)∈[0,1]\gamma^{(i)}_t\in[0,1]γt(i)∈[0,1] 给每段加权:
yt=γt(s) Mt(s)(qt)+∑i=1s−1γt(i) ML(i)(i)(qt) y_t = \gamma^{(s)}_t\,\mathcal{M}^{(s)}_t(q_t) + \sum_{i=1}^{s-1}\gamma^{(i)}_t\,\mathcal{M}^{(i)}_{L^{(i)}}(q_t) yt=γt(s)Mt(s)(qt)+i=1∑s−1γt(i)ML(i)(i)(qt)
精妙的是门控的定义方式。如果只让 γ\gammaγ 是输入的线性投影,它就退化成"按位置过滤"——只看段的位置、不看段的内容。作者改用一个连接参数 ut=xtWuu_t = x_t W_uut=xtWu,去和该段内容的均值池化表示做相似度:
γt(i)=⟨ut, MeanPooling(S(i))⟩,再过 softmax \gamma^{(i)}_t = \big\langle u_t,\ \mathrm{MeanPooling}(S^{(i)})\big\rangle,\quad \text{再过 softmax} γt(i)=⟨ut, MeanPooling(S(i))⟩,再过 softmax
这样门控就成了上下文感知的检索:当前 token 该多看哪一段,取决于它和那一段内容的相似度。因为 γ\gammaγ 逐 token、依赖输入,所以即使线性记忆也不会塌缩。
3.3 记忆汤(Memory Soup)
灵感来自 model soup(权重平均)。前面是"先各自检索、再加权输出",记忆汤反过来——先把各段缓存记忆的参数加权平均成一块全新的、数据相关的记忆 Mt∗\mathcal{M}^*_tMt∗,再用查询去读:
θMt∗={∑i=1sγt(i)W1(i), …, ∑i=1sγt(i)Wc(i)},yt=Mt∗(qt) \theta_{\mathcal{M}^*_t} = \Big\{\sum_{i=1}^{s}\gamma^{(i)}_t W^{(i)}_1,\ \dots,\ \sum_{i=1}^{s}\gamma^{(i)}_t W^{(i)}_c\Big\},\qquad y_t = \mathcal{M}^*_t(q_t) θMt∗={i=1∑sγt(i)W1(i), …, i=1∑sγt(i)Wc(i)},yt=Mt∗(qt)
对线性记忆,它和 GRM 数学上等价(线性下"先平均参数"与"先各自输出再求和"一回事)。但对深度/非线性记忆(如 DLA、Titans)就分道扬镳了:它本质是给每个 token 临时插值出一个专属的非线性检索函数。
3.4 稀疏选择缓存(SSC)
前三种每个 token 都要看遍所有 NNN 块缓存,超长序列开销大。SSC 借鉴 MoE,用一个路由器按相关性分数 rt(i)=⟨ut,MeanPooling(S(i))⟩r^{(i)}_t = \langle u_t, \mathrm{MeanPooling}(S^{(i)})\ranglert(i)=⟨ut,MeanPooling(S(i))⟩ 选出 Top-kkk 块缓存(加当前在线记忆)来读:
Rt=Top-k({rt(i)}i=1s−1),yt=γt(s) Mt(s)(qt)+∑i∈Rtγt(i) ML(i)(i)(qt) \mathcal{R}_t = \mathrm{Top\text{-}}k\big(\{r^{(i)}_t\}_{i=1}^{s-1}\big),\qquad y_t = \gamma^{(s)}_t\,\mathcal{M}^{(s)}_t(q_t) + \sum_{i\in \mathcal{R}_t}\gamma^{(i)}_t\,\mathcal{M}^{(i)}_{L^{(i)}}(q_t) Rt=Top-k({rt(i)}i=1s−1),yt=γt(s)Mt(s)(qt)+i∈Rt∑γt(i)ML(i)(i)(qt)
工程上的好处很实在:段的均值池化可预计算、Top-kkk 可并行,而且只需把"被选中"的记忆加载进加速器,训练和推理的显存都能省。作者把它解读成一个"稀疏的统一记忆"——写入只激活一小块参数(无干扰地存),读取激活更大一块(自适应地取)。
四、两个理论亮点
除了工程方法,论文还有两处漂亮的理论桥接,把 RNN、混合模型、注意力统一在了一个框架下。
4.1 用 MC 重新发现"门控注意力"
把段长设为 1、记忆设成"无值的向量记忆"(每个 token 自成一段、只存自己),套上 MC 推导出来的,恰好是门控全局 softmax 注意力:
yt=(∑i=1texp(ut⊤ki)∑ℓexp(ut⊤kℓ) vi′)⊗σ(xtWQ) y_t = \Big(\sum_{i=1}^{t}\frac{\exp(u_t^\top k_i)}{\sum_\ell \exp(u_t^\top k_\ell)}\,v'_i\Big)\otimes \sigma(x_t W_Q) yt=(i=1∑t∑ℓexp(ut⊤kℓ)exp(ut⊤ki)vi′)⊗σ(xtWQ)
更进一步,他们指出"压缩器 + 全局注意力"这种近来很流行的混合架构,等价于段长为 1、缓存 checkpoint 的 MC。这就给"为什么混合模型有效"提供了一个解释:注意力本质上在强制缓存过去的输入,从而扩大了递归模型的有效记忆容量。 而当查询从 qt=1q_t=\mathbf{1}qt=1 放开到 qt=xtWQq_t=x_t W_Qqt=xtWQ,MC 还能变成一种"自组装注意力"——每个查询可以自己构造送进注意力块的输入序列 {ML(i)(i)(qt)}\{\mathcal{M}^{(i)}_{L^{(i)}}(q_t)\}{ML(i)(i)(qt)},而非固定不变。
⚠️ 作者诚实地注明:这个等价只在"过度简化"的版本下成立,一旦考虑归一化和前馈层,两者的表达力会有差异。
4.2 分段就是压缩与算力的旋钮
分段方式决定了 NNN,也就决定了压缩程度与计算成本的折衷。
设每段大小为 C=L/NC=L/NC=L/N,则总成本约 O(p⋅L2/C)\mathcal{O}(p\cdot L^2/C)O(p⋅L2/C)——这是个常数更小的 Transformer。另一种是对数分段:把 LLL 写成二进制,按非零位取 2 的幂作段长(如 37=(100101)2→32,4,137=(100101)_2 \to 32,4,137=(100101)2→32,4,1),此时 N≤log2LN\le\log_2 LN≤log2L,成本压到 O(p LlogL)\mathcal{O}(p\,L\log L)O(pLlogL)。代价是对远期 token 的分辨率太低,召回能力受损。论文还把同期工作 Log-Linear Attention(Guo et al., 2025)重新表述成"GRM + 对数分段"的一个 MC 特例(记作 Log-Linear++),作为实验里的对照基线。
五、实验结果
作者在 760M(30B token)和 1.3B(100B token)两个规模上,把 MC 挂到 SWLA、DLA、Titans 三种递归架构上验证。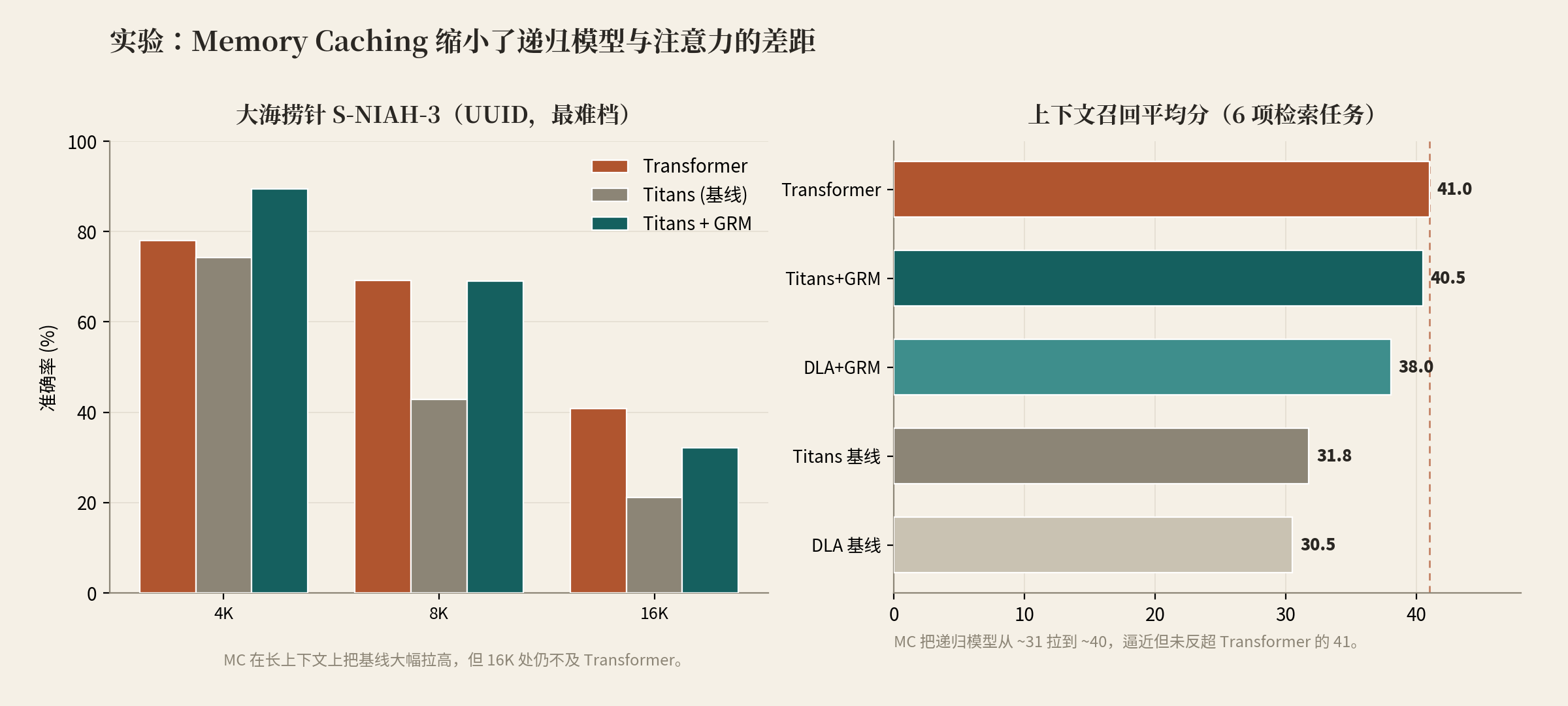
5.1 语言建模与常识推理
所有 MC 变体都稳定优于其基线。以 1.3B 规模为例(平均分,越高越好):
| 模型 | Wiki ppl↓ | LMB ppl↓ | 8 项下游平均↑ |
|---|---|---|---|
| Transformer++ | 17.92 | 17.73 | 53.19 |
| DLA(基线) | 16.31 | 12.29 | 53.72 |
| DLA + GRM | 16.08 | 12.10 | 55.96 |
| Titans(基线) | 15.60 | 11.41 | 56.82 |
| Titans + GRM | 15.37 | 11.29 | 58.33 |
| Titans + Memory Soup | 15.42 | 11.31 | 57.91 |
| Titans + SSC | 15.44 | 11.35 | 57.58 |
整体看:GRM 效果最好,SSC 次之;MC 对 Titans 的平均增益约 +0.8%(论文原话)。
5.2 长上下文召回(NIAH)
大海捞针任务上 MC 的优势在长上下文处最明显。以最难的 S-NIAH-3(UUID 检索)为例:
| 模型 | 4K | 8K | 16K |
|---|---|---|---|
| Transformer | 78.0 | 69.2 | 40.8 |
| Titans(基线) | 74.2 | 42.8 | 21.2 |
| Titans + GRM | 89.4 | 69.0 | 32.2 |
MC 把基线在 8K 处从 42.8 拉到 69.0,提升巨大,并全面优于 Log-Linear;但在 16K 处仍不及 Transformer。
5.3 上下文检索:缩小差距,但未反超
这是最该如实呈现的结果。6 项检索任务平均分上:Transformer 仍以 41.0 居首,MC 最好的 Titans+GRM 是 40.5——是"逼近"而非"反超"。MC 把递归模型从 ~31 拉到 ~40,确实大幅缩小了差距。此外 LongBench、MQAR 上 MC 变体也都优于各自基线。效率方面,SSC 是"两全其美"的那个:开销接近基线 RNN,长序列上远比 Transformer 高效。
六、批判性评估:几点要保留的判断
技术读者会注意到结果是否被过度包装。以下几点建议如实看待:
1. 贡献是增量而非颠覆。 语言建模上 MC 对 Titans 的平均增益约 +0.8%,体量不大;在最关键的上下文召回任务上,Transformer 仍稳居第一。论文摘要本身也诚实地写明了"close the gap"而非"超越"。
2. 这是同一团队在自家框架内的延续。 大量自引(Titans、Atlas、Miras、Nested Learning),核心叙事建立在他们自己的"关联记忆/测试时记忆"范式上。作为对照基线的 Log-Linear++,也是他们把别人的方法重新表述进自家框架后再来比较——逻辑成立,但属于对自己有利的设定。
3. 有一处实验结果可疑。 消融表(Table 5)中"Shared uuu and qqq"两行的三列指标全是 00.0 / 00.0 / 00.0。这要么是该配置导致训练彻底崩溃的真实发现,要么是 v1 预印本里尚未填入的占位符。鉴于这是 2026 年 2 月的 arXiv v1,更稳妥的态度是把它当作不确定项,而非直接转述为"共享投影会致命崩溃"的结论。
4. 效率收益强依赖分段选择。 O(NL)\mathcal{O}(NL)O(NL) 在 NNN 增大时会重新逼近 O(L2)\mathcal{O}(L^2)O(L2);而且除 SSC 外的三种变体仍需存储全部 NNN 块记忆状态,显存并非免费。真正缓解显存的只有 SSC。
5. 验证规模有限。 全部实验在学术规模(≤1.3B 参数、≤100B token)完成,能否迁移到前沿规模仍是未知数——这也是作者自己强调"作为概念验证(proof of concept)"的原因。
七、总结
Memory Caching 的核心,是把递归模型的"记忆状态"从一个被不断覆盖的单点,变成一条可以回看的检查点序列。它最有价值的地方有两层:
- 工程层面:给出一个 O(NL)\mathcal{O}(NL)O(NL) 的旋钮,让 RNN 几乎免费地获得随长度增长的有效记忆,且四种聚合策略各有取舍(GRM 性能最佳、SSC 效率最佳);
- 理论层面:把混合架构、门控注意力都纳入同一框架解释,为"为什么这些经验配方有效"提供了统一视角。
它不是 Transformer 的颠覆者,而是递归模型阵营里一次扎实的、诚实的能力补强——在长上下文召回这块短板上把差距显著缩小,同时守住了递归模型的效率优势。对关注高效长序列建模的工程师和研究者来说,这是一篇值得细读的方法论文章。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)