矩阵分解与latent space
基于阅读:INSIDER: Interpretable sparse matrix decomposition for RNA expression data analysis,Kai ZhaoID1, Sen Huang2, Cuichan Lin3, Pak Chung ShamID4,5,6, Hon-Cheong So3,7,8*, Zhixiang LinID1*” “PLOS Genetics” 2024-03-14的一些思考。
latent space
源自IBM的讲解:What Is Latent Space? | IBM
feature space vs. latent space
feature space ,特征空间:特征空间的每个维度对应原始数据的特征。描述不是数据本身,是能够表示特定数据点集合的有意义的特征值范围。
比如,图像数据中,特征空间的每个维度对应数据中的特定形状、纹理、颜色模式。
latent space,潜在空间:潜在空间的每个维度对应原始数据的一个潜在变量。是决定数据分布方式的潜在特征。
比如,一座桥可以测量过往车辆的重量,但是桥上没有摄像头识别车辆类型。通识中,我们认为车辆类型会显著影响重量。车辆重量是一个可观测变量observable variable,车辆类型是latent variable。我们可以分析车辆重量这个observable variable来推测车辆类型这个latent variable。
因此在该论文里,observable variable是可观测的rnaseq数据,而latent variable应该是那些donors、tissues、phenotypes。
latent space and dimensionality reduction
比如图像数据,n*n的图像可以表示为一个n*n维的向量,每个维度代表一个元素,取值为0-1。如果是RGB彩色的,则需变成3n*n维的向量。但图像大部分是空白背景,因此可以将图像(其向量)降维到仅包含实际信息的维度。
降维后的实际信息的维度,构成了latent space。
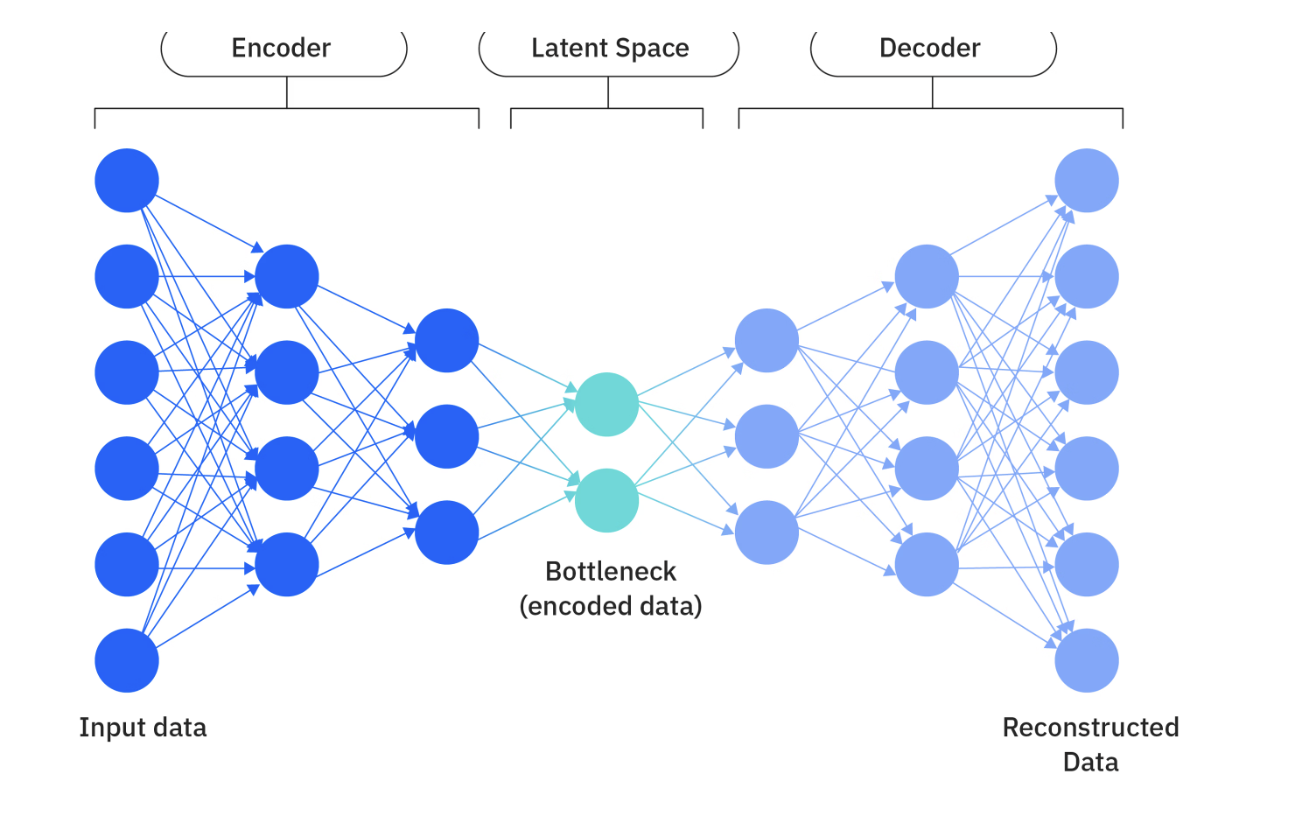
Autoencoders自编码器
自编码器是一个神经网络架构,专门为降低维度和将数据压缩到潜在空间而设计的。
其目标为通过降维压缩来输入数据,再从压缩后的表示中精确重构原始输入。编码器的每一层都比前一层的节点数量减少,每一层会降维压缩传递到下一层,。解码器会使用潜在向量来重构原始输入。
训练目标函数是最小化重构损失,即解码器重构结果与原始输入的差异程度。因此自编码器可以学习输入数据潜在空间的有效映射。
例子:一块假表将其拆解,并尝试重建其内部的齿轮和机械结构(潜在空间)就可以识别出与真品不符的元素。
自编码器相对于其他降维算法(如线性判别分析或主成分分析 (PCA))的优势是:可以对不同变量之间的非线性关系进行建模。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)