强化学习(Reinforcement Learning, RL)的分类与深度解析
目录
蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)
时序差分(Temporal Difference, TD)学习
强化学习是机器学习的重要分支之一,它以“智能体与环境交互试错”为核心思想,通过最大化长期累积奖励来学习最优决策,在机器人控制、游戏AI、资源调度等领域展现出强大的应用潜力。
✅1.强化学习基础理论框架
强化学习的核心是马尔可夫决策过程(Markov Decision Process, MDP),这是描述智能体与环境交互的数学模型,定义了强化学习问题的基本要素。
1.1 MDP核心组成
状态空间S:环境所有可能状态的集合,任意时刻智能体处于状态st∈S。
动作空间A:智能体可执行的所有动作的集合,在状态st下执行动作at∈A。
状态转移概率P(st+1∣st,at):描述在状态st执行动作at后,环境转移到状态st+1的概率,满足马尔可夫性:下一个状态仅由当前状态和动作决定,与历史无关。
奖励函数R(st,at,st+1):智能体执行动作后,环境反馈的即时标量奖励,衡量动作的优劣。折扣因子γ∈[0,1]:对未来奖励的折扣系数,决定智能体对“短期奖励”和“长期奖励”的重视程度,γ越接近1,越重视未来收益。
1.2 最大化期望累积奖励
强化学习的目标是找到一个最优策略π(a∣s)(状态到动作的映射),使得从初始状态出发,智能体获得的期望累积奖励最大化。定义从状态st出发的回报(Return):

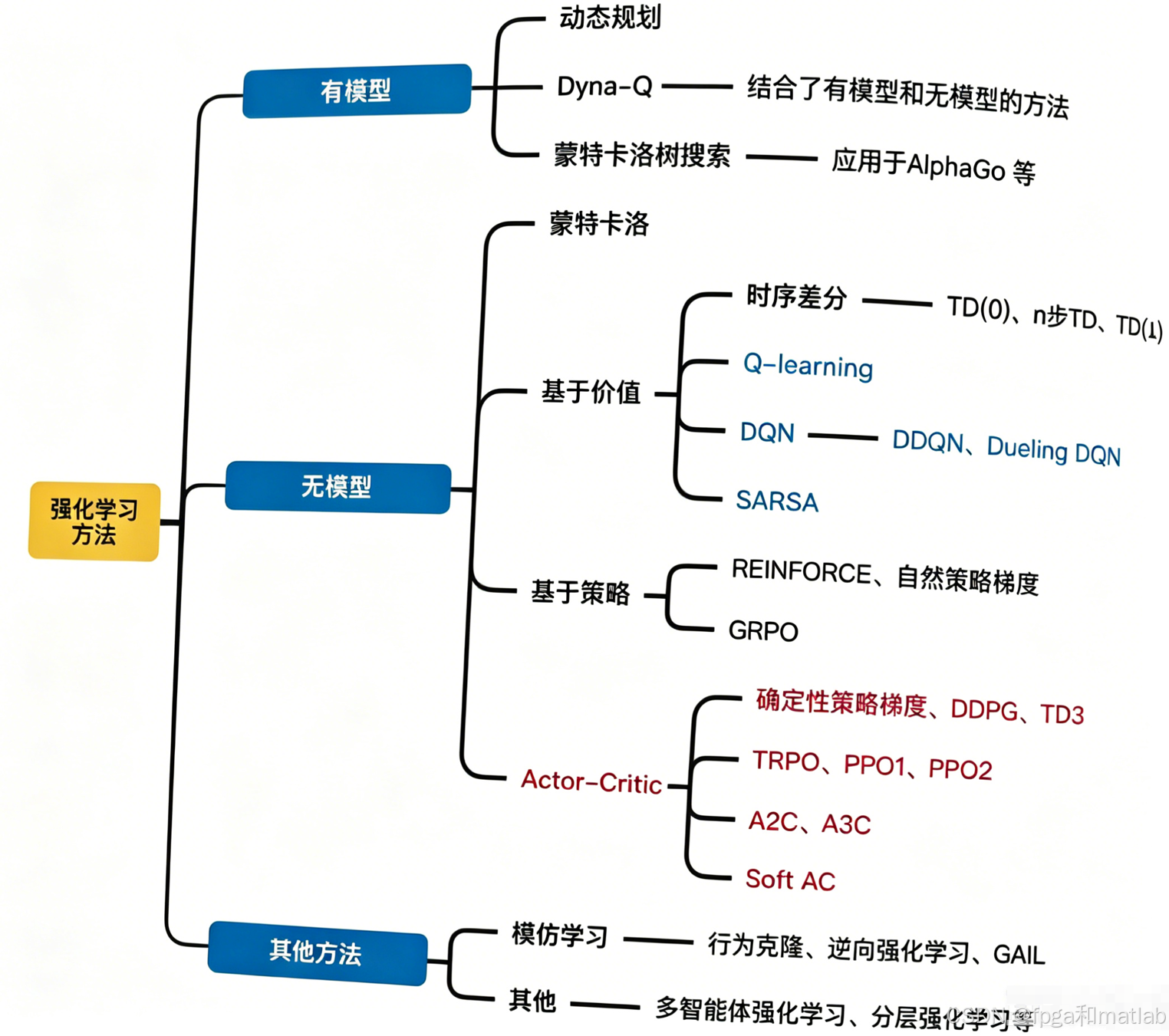
✨2. 强化学习的分类体系
强化学习分类包括基于价值(Value-Based)、基于策略(Policy-Based)、Actor-Critic(AC)。
2.1 基于价值(Value-Based)
不直接学习策略,而是通过估计状态价值函数V(s)或动作价值函数Q(s,a),再通过价值函数推导最优策略。

2.2 基于策略(Policy-Based)
直接参数化策略πθ(a∣s),通过优化策略参数θ最大化期望回报,核心是策略梯度(Policy Gradient)方法。

2.3 Actor-Critic(AC)
结合了基于价值和基于策略的优势:
Actor(演员):基于策略梯度更新策略参数,负责选择动作;
Critic(评论家):估计价值函数(如V(s)或Q(s,a)),为Actor提供策略更新的“基线”,降低策略梯度的方差。
核心更新逻辑:用优势函数A(st,at)=Q(st,at)−V(st)代替原始回报Gt,既保留策略梯度的无偏性,又大幅降低方差。策略梯度变为:
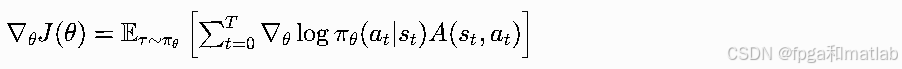
🚀3.有模型强化学习和无模型强化学习
3.1 有模型强化学习
动态规划(Dynamic Programming, DP)
基于已知的环境模型P(s′∣s,a)和R(s,a,s′),通过迭代求解贝尔曼方程得到最优价值函数和策略。

蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)
一种结合蒙特卡洛采样与树搜索的有模型规划算法,典型应用是AlphaGo。核心分为四步:

Dyna-Q算法
结合有模型规划和无模型学习的混合算法,核心流程:

3.2 无模型强化学习
蒙特卡洛(Monte Carlo, MC)方法
不依赖环境模型,直接用完整轨迹的平均回报估计价值函数,核心更新公式:
![]()
其中Gt是状态s在轨迹中的实际回报,α为学习率。MC方法是同策略算法,只能处理回合制任务,需要完整轨迹才能更新。
时序差分(Temporal Difference, TD)学习
结合了MC的无模型特点和DP的自举(Bootstrapping)思想,用下一步的价值估计更新当前价值,无需等待轨迹结束。

Q-learning(异策略TD算法)
直接估计动作价值函数Q(s,a),目标策略为贪心策略,行为策略为探索性策略(如ϵ-贪心),更新公式:
![]()
Q-learning是异策略算法,可重复利用旧数据,保证收敛到最优动作价值函数。
在python中,其程序调用方法如下:
import numpy as np
import gym
# 初始化环境
env = gym.make("CliffWalking-v0")
n_states = env.observation_space.n
n_actions = env.action_space.n
# 超参数
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.1 # 探索率
episodes = 500 # 训练回合数
# 初始化Q表
Q = np.zeros((n_states, n_actions))
# ε-贪心策略
def epsilon_greedy(state):
if np.random.uniform(0, 1) < epsilon:
return np.random.choice(n_actions)
else:
return np.argmax(Q[state, :])
# 训练
for ep in range(episodes):
state, _ = env.reset()
done = False
total_reward = 0
while not done:
action = epsilon_greedy(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
total_reward += reward
# Q-Learning 更新公式
Q[state, action] = Q[state, action] + alpha * (
reward + gamma * np.max(Q[next_state, :]) - Q[state, action]
)
state = next_state
if (ep + 1) % 100 == 0:
print(f"Episode {ep+1}, Total Reward: {total_reward}")
# 测试
state, _ = env.reset()
done = False
while not done:
action = np.argmax(Q[state, :])
next_state, _, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state = next_state
env.render()
env.close()SARSA(同策略TD算法)
与Q-learning类似,但目标策略与行为策略一致,更新时使用下一个实际执行的动作at+1,而非贪心动作:
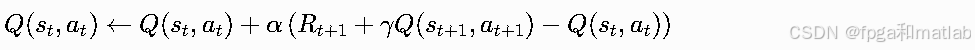
在python中,其程序调用方法如下:
import numpy as np
import gym
env = gym.make("CliffWalking-v0")
n_states = env.observation_space.n
n_actions = env.action_space.n
alpha = 0.1
gamma = 0.9
epsilon = 0.1
episodes = 500
Q = np.zeros((n_states, n_actions))
def epsilon_greedy(state):
if np.random.uniform() < epsilon:
return np.random.choice(n_actions)
return np.argmax(Q[state])
for ep in range(episodes):
state, _ = env.reset()
action = epsilon_greedy(state)
done = False
total_reward = 0
while not done:
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
total_reward += reward
next_action = epsilon_greedy(next_state)
# SARSA 更新公式
Q[state, action] = Q[state, action] + alpha * (
reward + gamma * Q[next_state, next_action] - Q[state, action]
)
state, action = next_state, next_action
if (ep + 1) % 100 == 0:
print(f"Episode {ep+1}, Reward: {total_reward}")
env.close()DQN(深度Q网络)
用神经网络Qθ(s,a)近似动作价值函数,解决高维状态空间问题,核心改进包括:

在python中,其程序调用方法如下:
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from collections import deque
import random
# 设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 超参数
BATCH_SIZE = 64
LR = 1e-3
GAMMA = 0.95
MEMORY_CAPACITY = 2000
EPSILON = 0.1
TARGET_UPDATE = 10
env = gym.make("CartPole-v1")
n_state = env.observation_space.shape[0]
n_action = env.action_space.n
# 神经网络
class Net(nn.Module):
def __init__(self, n_state, n_action):
super(Net, self).__init__()
self.fc1 = nn.Linear(n_state, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, n_action)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# DQN 主体
class DQN:
def __init__(self):
self.eval_net = Net(n_state, n_action).to(device)
self.target_net = Net(n_state, n_action).to(device)
self.optimizer = optim.Adam(self.eval_net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
self.memory = deque(maxlen=MEMORY_CAPACITY)
self.learn_step = 0
# 存储经验
def store_transition(self, s, a, r, s_):
self.memory.append((s, a, r, s_))
# 选择动作
def choose_action(self, s):
s = torch.FloatTensor(s).unsqueeze(0).to(device)
if np.random.random() < EPSILON:
return random.randint(0, n_action-1)
else:
with torch.no_grad():
q = self.eval_net(s)
return torch.argmax(q).item()
# 网络学习
def learn(self):
# 目标网络更新
if self.learn_step % TARGET_UPDATE == 0:
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step += 1
# 采样批次
batch = random.sample(self.memory, BATCH_SIZE)
s = torch.FloatTensor([t[0] for t in batch]).to(device)
a = torch.LongTensor([t[1] for t in batch]).unsqueeze(1).to(device)
r = torch.FloatTensor([t[2] for t in batch]).unsqueeze(1).to(device)
s_ = torch.FloatTensor([t[3] for t in batch]).to(device)
# 计算Q值
q_eval = self.eval_net(s).gather(1, a)
q_next = self.target_net(s_).detach()
q_target = r + GAMMA * q_next.max(1, keepdim=True)[0]
# 反向传播
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 主训练
dqn = DQN()
episodes = 300
for ep in range(episodes):
state, _ = env.reset()
total_reward = 0
done = False
while not done:
action = dqn.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
total_reward += reward
# 塑形奖励
x, x_dot, theta, theta_dot = next_state
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r = r1 + r2
dqn.store_transition(state, action, r, next_state)
if len(dqn.memory) > BATCH_SIZE:
dqn.learn()
state = next_state
if (ep + 1) % 20 == 0:
print(f"Episode {ep+1}, Reward: {total_reward:.1f}")
env.close()REINFORCE(蒙特卡洛策略梯度)
最基础的策略梯度算法,用完整轨迹的回报Gt作为权重更新策略参数,更新公式:
![]()
算法方差较大,需要大量轨迹样本。
在python中,其程序调用方法如下:
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
env = gym.make("CartPole-v1")
n_state = env.observation_space.shape[0]
n_action = env.action_space.n
LR = 1e-3
GAMMA = 0.98
EPISODES = 300
# 策略网络
class PolicyNet(nn.Module):
def __init__(self, s_dim, a_dim):
super().__init__()
self.fc1 = nn.Linear(s_dim, 64)
self.fc2 = nn.Linear(64, a_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.softmax(self.fc2(x), dim=-1)
class REINFORCE:
def __init__(self):
self.policy_net = PolicyNet(n_state, n_action).to(device)
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=LR)
def choose_action(self, state):
state = torch.FloatTensor(state).to(device)
prob = self.policy_net(state)
action = torch.distributions.Categorical(prob).sample()
return action.item(), prob[action]
def learn(self, trajectory):
states, actions, rewards = zip(*trajectory)
# 计算折扣回报
G = 0
discounted_rewards = []
for r in reversed(rewards):
G = r + GAMMA * G
discounted_rewards.append(G)
discounted_rewards = torch.FloatTensor(list(reversed(discounted_rewards))).to(device)
discounted_rewards = (discounted_rewards - discounted_rewards.mean()) / (discounted_rewards.std() + 1e-6)
# 策略梯度更新
loss = 0
for s, a, g in zip(states, actions, discounted_rewards):
s = torch.FloatTensor(s).to(device)
prob = self.policy_net(s)
log_prob = torch.log(prob[a])
loss += -log_prob * g
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 训练
agent = REINFORCE()
for ep in range(EPISODES):
state, _ = env.reset()
trajectory = []
total_r = 0
done = False
while not done:
action, _ = agent.choose_action(state)
next_state, r, terminated, truncated, _ = env.step(action)
done = terminated or truncated
trajectory.append((state, action, r))
total_r += r
state = next_state
agent.learn(trajectory)
if (ep+1) % 20 == 0:
print(f"Episode {ep+1}, Reward: {total_r}")
env.close()自然策略梯度
引入Fisher信息矩阵F修正梯度方向,使更新更稳定,自然梯度为:

3.3 Actor-Critic系列算法
A2C
同步版的AC算法,用优势函数A(st,at)=Q(st,at)−V(st)作为权重更新Actor,Critic估计状态价值函数Vϕ(s),更新公式:
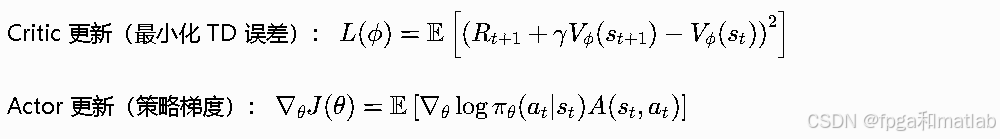
在python中,其程序调用方法如下:
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
env = gym.make("CartPole-v1")
n_state = env.observation_space.shape[0]
n_action = env.action_space.n
LR_A = 1e-3
LR_C = 1e-3
GAMMA = 0.98
EPISODES = 300
# 策略网络(Actor) + 价值网络(Critic)
class Actor(nn.Module):
def __init__(self, s_dim, a_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(s_dim, 64),
nn.ReLU(),
nn.Linear(64, a_dim)
)
def forward(self, x):
return torch.softmax(self.fc(x), dim=-1)
class Critic(nn.Module):
def __init__(self, s_dim):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(s_dim, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
def forward(self, x):
return self.fc(x)
class A2C:
def __init__(self):
self.actor = Actor(n_state, n_action).to(device)
self.critic = Critic(n_state).to(device)
self.opt_a = optim.Adam(self.actor.parameters(), lr=LR_A)
self.opt_c = optim.Adam(self.critic.parameters(), lr=LR_C)
def choose_action(self, s):
s = torch.FloatTensor(s).to(device)
prob = self.actor(s)
dist = torch.distributions.Categorical(prob)
a = dist.sample()
return a.item(), dist.log_prob(a)
def learn(self, s, a, r, s_):
s = torch.FloatTensor(s).to(device)
s_ = torch.FloatTensor(s_).to(device)
r = torch.tensor([r], dtype=torch.float32).to(device)
v_s = self.critic(s)
v_s_ = self.critic(s_).detach()
td_target = r + GAMMA * v_s_
td_error = td_target - v_s
# 更新Critic
loss_c = td_error.pow(2)
self.opt_c.zero_grad()
loss_c.backward()
self.opt_c.step()
# 更新Actor
_, log_prob = self.choose_action(s.cpu().numpy())
loss_a = -log_prob * td_error.detach()
self.opt_a.zero_grad()
loss_a.backward()
self.opt_a.step()
agent = A2C()
for ep in range(EPISODES):
state, _ = env.reset()
total_r = 0
done = False
while not done:
action, _ = agent.choose_action(state)
next_state, r, terminated, truncated, _ = env.step(action)
done = terminated or truncated
total_r += r
agent.learn(state, action, r, next_state)
state = next_state
if (ep+1) % 20 == 0:
print(f"Episode {ep+1}, Reward: {total_r}")
env.close()A3C
多线程异步训练的AC算法,多个Worker线程与环境交互,独立计算梯度后异步更新全局网络参数,提升训练效率,无需经验回放。
DDPG
异策略AC算法,结合DQN与确定性策略梯度,适用于连续动作空间:

在python中,其程序调用方法如下:
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from collections import deque
import random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
env = gym.make("Pendulum-v1")
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.shape[0]
a_bound = env.action_space.high[0]
# 超参
LR_A = 1e-4
LR_C = 1e-3
GAMMA = 0.99
TAU = 0.005
MEMORY_CAP = 10000
BATCH = 128
# 网络
class Actor(nn.Module):
def __init__(self, s_dim, a_dim, a_bound):
super().__init__()
self.fc1 = nn.Linear(s_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, a_dim)
self.a_bound = a_bound
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return torch.tanh(self.fc3(x)) * self.a_bound
class Critic(nn.Module):
def __init__(self, s_dim, a_dim):
super().__init__()
self.fc1 = nn.Linear(s_dim + a_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 1)
def forward(self, s, a):
x = torch.cat([s, a], dim=1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
class DDPG:
def __init__(self):
self.actor = Actor(s_dim, a_dim, a_bound).to(device)
self.actor_target = Actor(s_dim, a_dim, a_bound).to(device)
self.critic = Critic(s_dim, a_dim).to(device)
self.critic_target = Critic(s_dim, a_dim).to(device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.critic_target.load_state_dict(self.critic.state_dict())
self.opt_a = optim.Adam(self.actor.parameters(), lr=LR_A)
self.opt_c = optim.Adam(self.critic.parameters(), lr=LR_C)
self.memory = deque(maxlen=MEMORY_CAP)
def choose_action(self, s):
s = torch.FloatTensor(s).unsqueeze(0).to(device)
with torch.no_grad():
a = self.actor(s).cpu().numpy()[0]
a += np.random.normal(0, 0.1, a_dim)
return np.clip(a, -a_bound, a_bound)
def store(self, s, a, r, s_):
self.memory.append((s, a, r, s_))
def soft_update(self):
for t, e in zip(self.actor_target.parameters(), self.actor.parameters()):
t.data.copy_(TAU * e.data + (1-TAU) * t.data)
for t, e in zip(self.critic_target.parameters(), self.critic.parameters()):
t.data.copy_(TAU * e.data + (1-TAU) * t.data)
def learn(self):
batch = random.sample(self.memory, BATCH)
s, a, r, s_ = zip(*batch)
s = torch.FloatTensor(s).to(device)
a = torch.FloatTensor(a).to(device)
r = torch.FloatTensor(r).unsqueeze(1).to(device)
s_ = torch.FloatTensor(s_).to(device)
# 更新Critic
a_ = self.actor_target(s_)
q_target = r + GAMMA * self.critic_target(s_, a_)
q_eval = self.critic(s, a)
loss_c = nn.MSELoss()(q_eval, q_target.detach())
self.opt_c.zero_grad()
loss_c.backward()
self.opt_c.step()
# 更新Actor
a_pred = self.actor(s)
loss_a = -torch.mean(self.critic(s, a_pred))
self.opt_a.zero_grad()
loss_a.backward()
self.opt_a.step()
self.soft_update()
ddpg = DDPG()
episodes = 300
for ep in range(episodes):
state, _ = env.reset()
total_r = 0
done = False
while not done:
action = ddpg.choose_action(state)
next_s, rew, terminated, truncated, _ = env.step(action)
done = terminated or truncated
total_r += rew
ddpg.store(state, action, rew, next_s)
if len(ddpg.memory) > BATCH:
ddpg.learn()
state = next_s
if ep % 20 == 0:
print(f"Episode {ep}, Reward: {total_r:.1f}")
env.close()TD3
DDPG的改进版,核心优化:
双Critic网络:用两个Critic估计Q1和Q2,取较小值作为目标,缓解过估计;
延迟更新Actor:每隔固定步数更新一次Actor,避免Critic误差累积;
目标策略平滑:在目标动作中加入噪声,提升策略的鲁棒性。
PPO
当前工业界最常用的同策略AC算法,核心是限制策略更新的幅度,避免一次更新过大导致策略崩溃。

PPO平衡了策略梯度的简单性和TRPO(信任区域策略优化)的稳定性,实现简单且性能优异,广泛应用于游戏AI、机器人控制等场景。
在python中,其程序调用方法如下:
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.distributions import Categorical
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
env = gym.make("CartPole-v1")
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.n
# 超参
LR = 3e-4
GAMMA = 0.99
LAMBDA = 0.95
CLIP_EPS = 0.2
EPOCHS = 10
BATCH = 64
UPDATE_STEP = 200
class ActorCritic(nn.Module):
def __init__(self, s_dim, a_dim):
super().__init__()
self.shared = nn.Sequential(
nn.Linear(s_dim, 64), nn.Tanh(),
nn.Linear(64, 64), nn.Tanh()
)
self.actor = nn.Linear(64, a_dim)
self.critic = nn.Linear(64, 1)
def get_action(self, s):
s = self.shared(s)
prob = torch.softmax(self.actor(s), dim=-1)
dist = Categorical(prob)
a = dist.sample()
logp = dist.log_prob(a)
v = self.critic(s)
return a.item(), logp.item(), v.item()
def evaluate(self, s, a):
s = self.shared(s)
prob = torch.softmax(self.actor(s), dim=-1)
dist = Categorical(prob)
logp = dist.log_prob(a)
entropy = dist.entropy()
v = self.critic(s)
return logp, v, entropy
class PPO:
def __init__(self):
self.ac = ActorCritic(s_dim, a_dim).to(device)
self.opt = optim.Adam(self.ac.parameters(), lr=LR)
self.buffer = []
def store(self, data):
self.buffer.append(data)
def compute_gae(self, rewards, dones, values, next_v):
adv = []
gae = 0
for r, d, v in zip(reversed(rewards), reversed(dones), reversed(values)):
delta = r + GAMMA * next_v * (1-d) - v
gae = delta + GAMMA * LAMBDA * (1-d) * gae
adv.append(gae)
next_v = v
adv = list(reversed(adv))
ret = np.array(adv) + np.array(values)
return adv, ret
def update(self):
s, a, old_logp, r, d, v = zip(*self.buffer)
s = torch.tensor(s, dtype=torch.float32).to(device)
a = torch.tensor(a, dtype=torch.int64).to(device)
old_logp = torch.tensor(old_logp, dtype=torch.float32).to(device)
r = np.array(r)
d = np.array(d)
v = np.array(v)
_, last_v, _ = self.ac.evaluate(s[-1:], a[-1:])
adv, ret = self.compute_gae(r, d, v, last_v.item())
adv = torch.tensor(adv, dtype=torch.float32).to(device)
ret = torch.tensor(ret, dtype=torch.float32).to(device)
adv = (adv - adv.mean()) / (adv.std() + 1e-6)
for _ in range(EPOCHS):
logp, v_pred, ent = self.ac.evaluate(s, a)
ratio = torch.exp(logp - old_logp)
surr1 = ratio * adv
surr2 = torch.clamp(ratio, 1-CLIP_EPS, 1+CLIP_EPS) * adv
loss_clip = -torch.min(surr1, surr2).mean()
loss_v = (ret - v_pred).pow(2).mean()
loss_ent = -0.01 * ent.mean()
total_loss = loss_clip + 0.5 * loss_v + loss_ent
self.opt.zero_grad()
total_loss.backward()
self.opt.step()
self.buffer.clear()
ppo = PPO()
step_cnt = 0
ep = 0
while True:
ep += 1
state, _ = env.reset()
done = False
total_r = 0
while not done:
act, logp, val = ppo.ac.get_action(torch.FloatTensor(state).to(device))
next_s, rew, terminated, truncated, _ = env.step(act)
done = terminated or truncated
total_r += rew
ppo.store((state, act, logp, rew, done, val))
state = next_s
step_cnt += 1
if step_cnt >= UPDATE_STEP:
ppo.update()
step_cnt = 0
if ep % 20 == 0:
print(f"Episode {ep}, Reward: {total_r}")
if ep > 500:
break
env.close()Soft Actor-Critic
基于最大熵强化学习的异策略AC算法,目标是最大化期望回报的同时最大化策略的熵,提升策略的探索性和鲁棒性。

SAC使用双Critic网络缓解过估计,适用于连续动作空间的复杂控制任务,样本效率和鲁棒性优于 DDPG/PPO。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)