知识图谱中的意图识别模型训练与优化实践
在最近参与的 熙瑾会悟项目中,我负责知识图谱板块中的 意图识别模型。这一块对于整个平台的智能问答和信息抽取来说至关重要,因为意图识别直接决定了用户输入的语义能否被准确理解。今天,我就把我们在模型训练与优化上的实践经验分享给大家,希望对做自然语言处理的小伙伴们有帮助。
一、落地遇到的五大实际难题
本次业务处理的是离线语音转记文本,这类内容以口语、即兴记录为主,给意图识别带来了诸多挑战:
1.口语化文本识别不准:文本里充斥着省略句、倒装句和各类语气词,和标准书面语差异大,模型误判情况频发;
2.相似意图极易混淆:查询、提问、归纳、补充等意图语义相近,基础模型很难做出精准区分;
3.离线推理速度滞后:原始模型参数量偏大,未做轻量化处理,部署在离线设备上延迟高,达不到实时转记要求;
4.小样本泛化能力差:项目初期标注数据有限,常规训练方式很容易造成模型过拟合,面对新样本准确率大幅下滑;
5.抗噪声能力薄弱:转记文本常出现错别字、断句混乱、冗余内容,这些噪声会直接干扰模型判断,输出错误结果。
针对以上问题,我最终确定从数据、模型、训练策略、知识融合四个方向展开全链路优化。
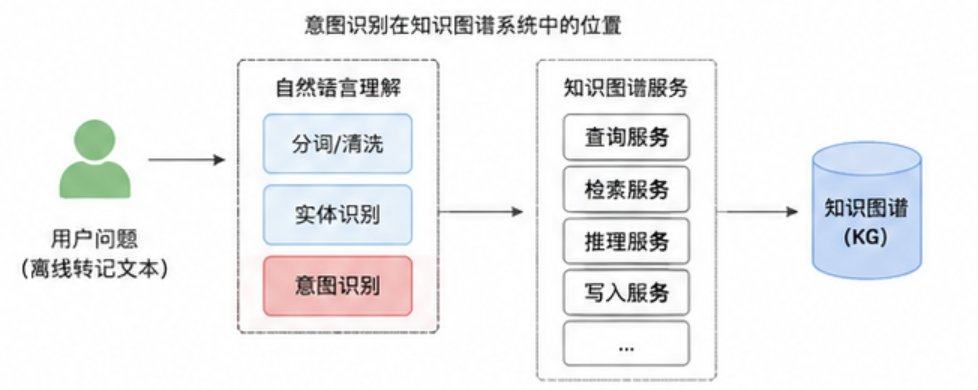
下图为意图识别在整个知识图谱系统中的所处位置:
二、技术选型与数据处理方案
结合离线低算力设备的部署要求,我没有一味堆砌大模型,而是选择轻量化架构,在精度和性能之间找到平衡。
2.1 核心技术栈
整套方案用到的技术都贴合落地场景:文本预处理采用正则清洗、分词、停用词过滤、错别字修正等手段;通过预训练模型微调适配垂直业务;搭配多类数据增强方法扩充样本;利用知识蒸馏、量化压缩实现模型轻量化;优化损失函数缓解过拟合,最后结合知识图谱做结果二次校验。
2.2 模型选型思路
传统 TextCNN、LSTM 对口语化、碎片化文本的语义捕捉能力不足,直接被排除;原生 BERT-base 虽然识别精度高,但参数量大、推理慢,完全不适合离线设备。综合考量后,我选用bert-tiny作为基础模型。它体积小、算力消耗低、推理效率高,经过场景微调后,精度完全能够满足业务需求,是离线 NLP 落地的优选方案。
2.3 数据清洗与增强
数据是模型效果的根基,我先完成基础数据清洗:剔除乱码、严重错字等无效内容,统一意图标签规范。 面对标注样本不足的问题,我采用多种方式做数据扩增:用同义词替换改写语句、通过回译生成不同表达、依托知识图谱实体批量构造问句;同时拆分多意图句子,保证单条样本仅对应一个意图,再补充上下文信息,最终把数千条原始样本扩充至万级,有效提升了模型泛化能力。
下图为整体离线转记业务流程:

离线转记整体流程图
下图为意图识别数据处理全流程: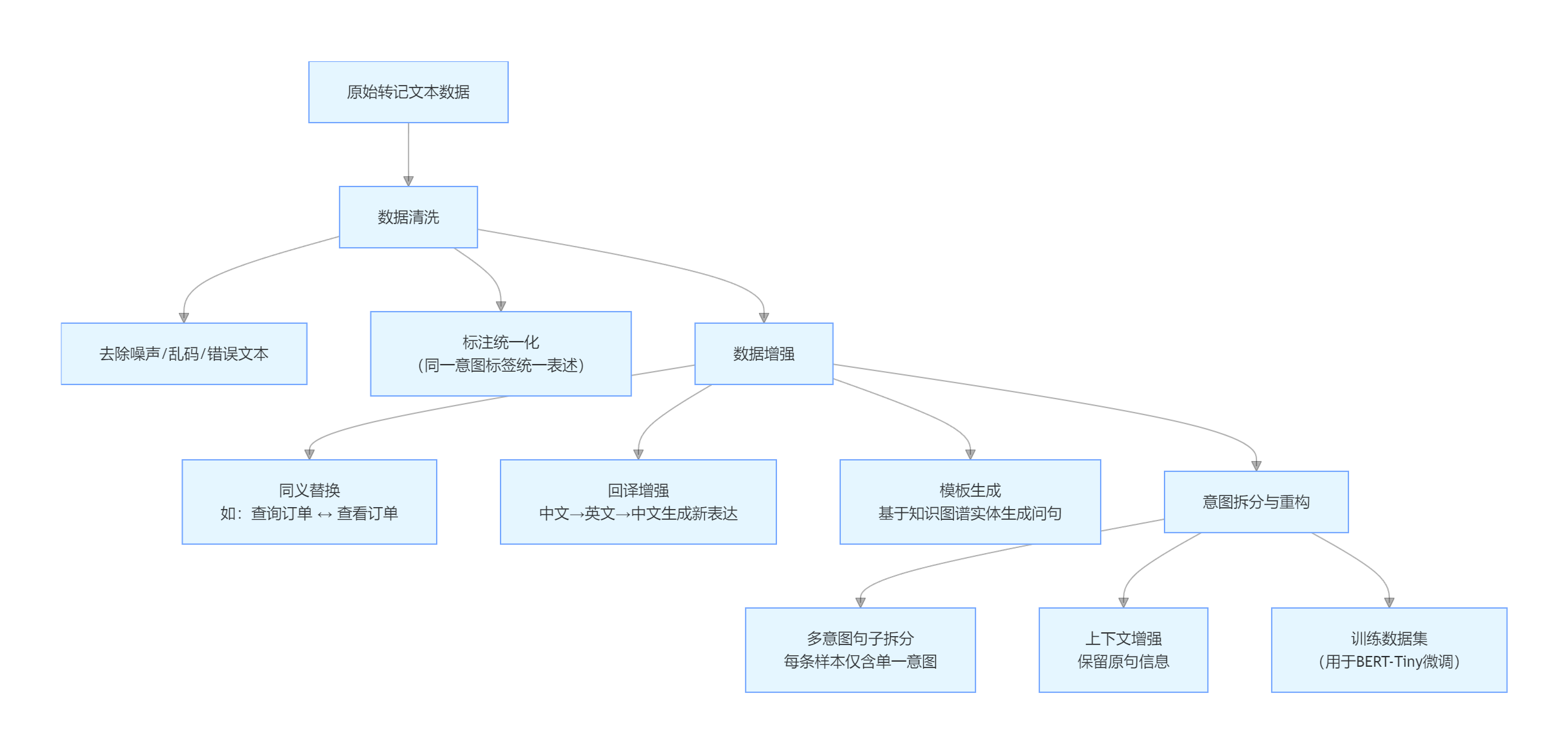
意图识别数据处理流程图
三、全链路优化实战方案
我从数据、模型、推理、业务四个层面逐一优化,针对性解决各类痛点。
下图是离线意图识别整体架构:
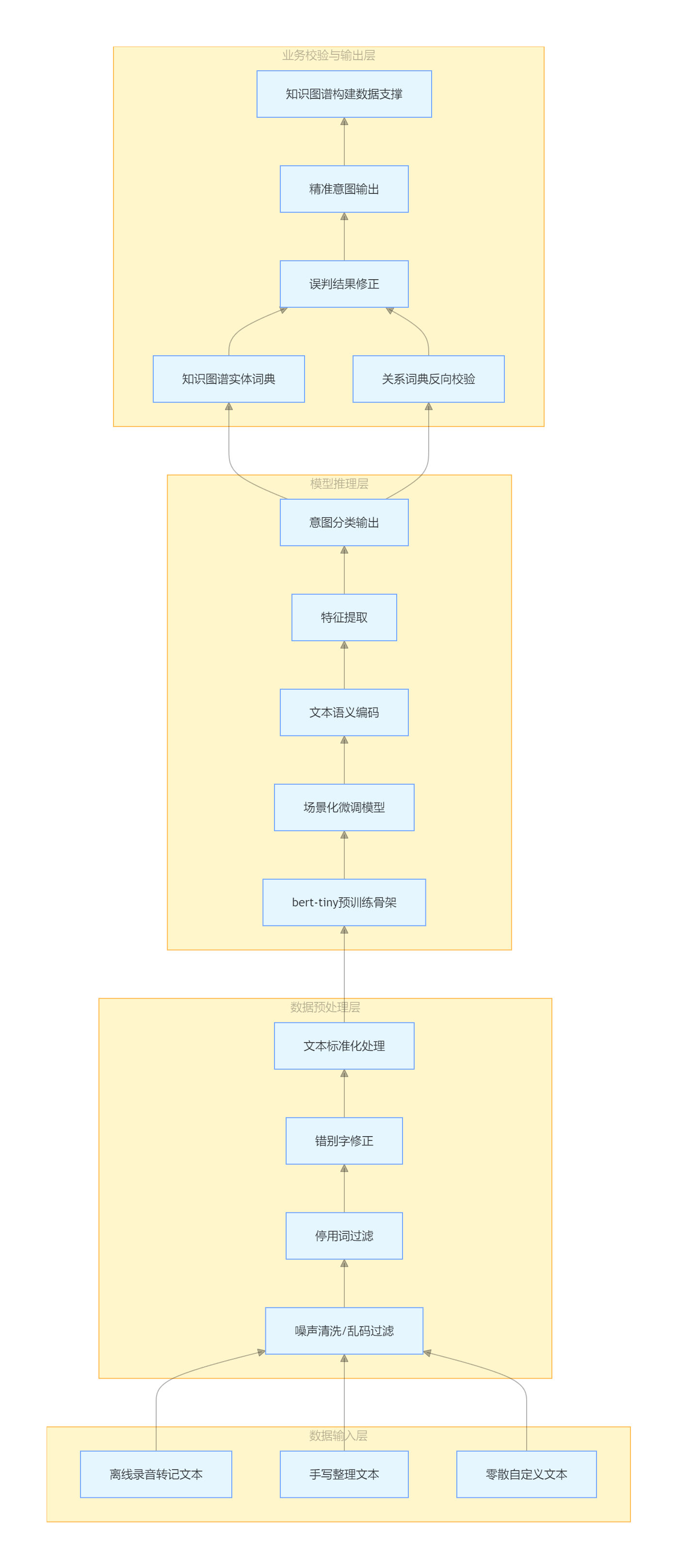
离线意图识别整体架构流程图
3.1 数据层:净化文本,扩充样本
一方面定制专属停用词表,过滤 “嗯、啊、然后” 等语气词,借助正则清理特殊符号、重复内容,搭配错词词典修正转记错误,规范输入文本;另一方面通过同义词替换、句式改写等方式扩增样本,全程保证标签不变,彻底改善小样本、高噪声的问题。
3.2 模型层:减少混淆,缓解过拟合
训练阶段做了两处关键优化:一是引入标签平滑 + 自适应交叉熵损失函数,避免模型在小样本下过度拟合,弱化标签绝对权重,提升相似意图的区分度;二是使用分层解冻微调,冻结模型底层通用语义参数,只训练上层分类与场景适配层,既保留预训练模型的语言能力,又让模型快速适配本项目业务。
3.3 推理层:模型瘦身,提速增效
为适配离线设备,我采用知识蒸馏方案:以 BERT-base 作为教师模型,将学习到的语义知识迁移到 bert-tiny 学生模型中,实现小模型高精度;再搭配 INT8 量化压缩,在基本不损失精度的前提下缩小模型体积。优化后,模型推理速度提升 60% 以上。
3.4 业务层:图谱联动,结果校验
这是本次优化的亮点。模型输出意图后,系统会结合项目自建的实体、关系词典做反向校验。如果识别结果和文本对应的实体、关系不匹配,就启动二次语义判断,修正误判内容,从业务源头避免因意图错误导致知识图谱构建异常。
四、落地效果总结
经过全链路优化,模型各项指标提升显著:意图识别准确率从最初的 72% 提升至 94% 以上,相似意图混淆率下降 80%;单条文本推理延迟稳定控制在 10ms 以内,完全满足实时转记需求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)