Qwen3.5本地部署终极指南,Qwen3.5-27B
Qwen3.5 轻量版来了,更智能,更小巧,量化版本地部署,消费级显卡轻松跑 一文中测试了,十分建议:首选 Qwen3.5-27B,无论是官方benchmark测评还是其他网友评价,都支持这一结论

Qwen3.5 全阵容:阿里这次玩了个大的
阿里最新发布的 Qwen3.5,不再只是单个模型,而是一整个军团:
|
型号 |
类型 |
总参数 |
激活参数 |
定位 |
|---|---|---|---|---|
|
Qwen3.5-27B |
Dense |
27B |
27B |
稳扎稳打型 |
|
Qwen3.5-35B-A3B |
MoE |
35B |
3B |
极速小钢炮 |
|
Qwen3.5-122B-A10B |
MoE |
122B |
10B |
中杯选手 |
|
Qwen3.5-397B-A17B |
MoE |
397B |
17B |
旗舰巨兽 |
两个关键词:混合推理 + MoE 架构。
混合推理意味着支持 thinking 和 non-thinking 双模式,想深度思考就开 thinking,想快速对话就关掉,成年人全都要。
MoE 架构让 397B 参数的模型只激活 17B,推理速度飞快,显存占用远小于同等性能的 Dense 模型。和 DeepSeek R1 的 671B-A37B 相比,Qwen3.5-397B-A17B 参数更少、激活更少,但性能几乎平起平坐——还得是阿里。
其他核心指标:
- 256K 上下文窗口(可扩展到 1M)
- 201 种语言支持
- 文本、视觉、视频、Agent、工具调用全覆盖
性能到底有多猛?直接上数据
旗舰 397B-A17B 对标闭源巨头
直接看最硬核的 Benchmark 对比:
|
Benchmark |
GPT-5.2 |
Claude 4.5 Opus |
Gemini-3 Pro |
Qwen3.5-397B |
|---|---|---|---|---|
|
MMLU-Pro |
87.4 |
89.5 |
89.8 |
87.8 |
|
GPQA Diamond |
92.4 |
87.0 |
91.9 |
88.4 |
|
AIME26 |
96.7 |
93.3 |
90.6 |
91.3 |
|
SWE-bench Verified |
80.0 |
80.9 |
76.2 |
76.4 |
|
TAU2-Bench |
87.1 |
91.6 |
85.4 |
86.7 |
|
IFBench |
75.4 |
58.0 |
70.4 |
76.5 |
|
BrowseComp |
65.8 |
67.8 |
59.2 |
78.6 |
说实话,Qwen3.5-397B 在多项搜索 Agent、指令遵循、多语言任务上已经超过了 GPT-5.2 和 Claude Opus 4.5。特别是 BrowseComp 搜索评测拿到了 78.6 分,直接碾压 GPT-5.2 的 65.8 分和 Claude 的 67.8 分。MultiChallenge 指令遵循测试 67.6 分也是所有模型中最高的。
IFBench 指令遵循 76.5 分,反超 GPT-5.2 的 75.4 和 Claude 的 58.0——阿里在指令遵循这块确实下了狠功夫。
当然,在纯数学推理(AIME26、HMMT)和代码(SWE-bench、LiveCodeBench)上,和 GPT-5.2 还有差距。但考虑到这是一个开源模型,能跟闭源三巨头正面硬刚到这种程度,真香。
和 vLLM 或者 SGLang 部署的在线 API 不同,这里 Unsloth 提供的是量化后本地跑的方案,适合没有 H100 集群的普通玩家。
Unsloth 量化后精度损失有多少?
第三方评测人 Benjamin Marie 用 750 道混合题(LiveCodeBench v6、MMLU Pro、GPQA、Math500)测试了 Qwen3.5-397B 的量化版:
|
版本 |
准确率 |
精度损失 |
磁盘大小 |
|---|---|---|---|
|
原始 FP16 |
81.3% |
— |
~807GB |
|
UD-Q4_K_XL (4-bit) |
80.5% |
-0.8% |
~214GB |
|
UD-Q3_K_XL (3-bit) |
80.7% |
-0.6% |
~160GB |
4-bit 量化只掉了 0.8 个百分点,3-bit 甚至只掉了 0.6 个百分点。也就是说,你用不到原来 1/4 的存储空间,就能获得 99% 的性能。这就是 Unsloth Dynamic 2.0 量化技术的杀疯了之处——重要的层会被自动提升到 8-bit 甚至 16-bit,而不是一刀切全部压缩。
你的设备能跑哪个?硬件需求速查
这是最实际的部分,别收藏了不看:
|
型号 |
4-bit 量化 |
8-bit 量化 |
原始 FP16 |
|---|---|---|---|
|
Qwen3.5-27B |
17 GB |
30 GB |
54 GB |
|
Qwen3.5-35B-A3B |
22 GB |
38 GB |
70 GB |
|
Qwen3.5-122B-A10B |
70 GB |
132 GB |
245 GB |
|
Qwen3.5-397B-A17B |
214 GB |
512 GB |
810 GB |
翻译成人话:
- 有一张 24GB 显卡(比如 4090)?→ 跑 Qwen3.5-27B 或 35B-A3B,后者 MoE 推理更快
- Mac M 系列 70GB+ 统一内存?→ 可以冲 122B-A10B
- 256GB M3 Ultra Mac?→ 直接上旗舰 397B-A17B 的 4-bit 版
- 192GB RAM 设备?→ 跑 397B 的 3-bit 版,也毫无问题
27B 和 35B-A3B 怎么选?如果追求准确率,选 27B。如果追求推理速度,选 35B-A3B。后者因为 MoE 架构只激活 3B 参数,速度会快得多。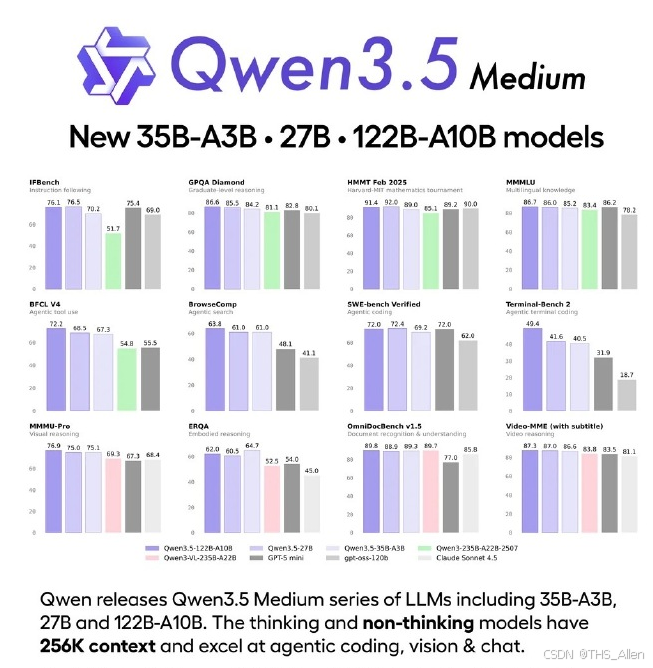
极简部署:复制粘贴就能跑
方案一:llama.cpp 直接起飞(推荐)
以 Qwen3.5-35B-A3B 为例,这是 24GB 显卡/内存用户的最佳选择:
1. 编译 llama.cpp
代码语言:javascript
AI代码解释
# 安装依赖并编译(有 GPU 用 CUDA=ON,纯 CPU 改成 OFF)
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j \
--clean-first --target llama-cli llama-mtmd-cli llama-server llama-gguf-split
cp llama.cpp/build/bin/llama-* llama.cpp
2. 一键运行(Thinking 模式)
代码语言:javascript
AI代码解释
# 精确编码任务用这个(temperature=0.6,更稳定)
export LLAMA_CACHE="unsloth/Qwen3.5-35B-A3B-GGUF"
./llama.cpp/llama-cli \
-hf unsloth/Qwen3.5-35B-A3B-GGUF:MXFP4_MOE \
--ctx-size 16384 \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.00
代码语言:javascript
AI代码解释
# 通用任务用这个(temperature=1.0,更有创意)
export LLAMA_CACHE="unsloth/Qwen3.5-35B-A3B-GGUF"
./llama.cpp/llama-cli \
-hf unsloth/Qwen3.5-35B-A3B-GGUF:MXFP4_MOE \
--ctx-size 16384 \
--temp 1.0 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.00
3. 非思考模式(更快响应)
代码语言:javascript
AI代码解释
# 不需要深度推理时,关掉 thinking 模式
export LLAMA_CACHE="unsloth/Qwen3.5-35B-A3B-GGUF"
./llama.cpp/llama-cli \
-hf unsloth/Qwen3.5-35B-A3B-GGUF:MXFP4_MOE \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"
方案二:先下载模型再运行
如果网络不稳定,可以先把模型文件下载到本地:
代码语言:javascript
AI代码解释
# 安装下载工具
pip install huggingface_hub hf_transfer
# 下载 4-bit 量化版(Dynamic MXFP4_MOE,约 22GB)
hf download unsloth/Qwen3.5-35B-A3B-GGUF \
--local-dir unsloth/Qwen3.5-35B-A3B-GGUF \
--include "*MXFP4_MOE*"
# 如果想下 2-bit 超压缩版:
# --include "*UD-Q2_K_XL*"
# 运行模型
./llama.cpp/llama-cli \
--model unsloth/Qwen3.5-35B-A3B-GGUF/Qwen3.5-35B-A3B-MXFP4_MOE.gguf \
--seed 3407 \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01 \
--top-k 40
方案三:部署为 API 服务(生产推荐)
想搭建一个兼容 OpenAI 接口的本地服务?用 llama-server:
代码语言:javascript
AI代码解释
# 启动服务(以 397B 为例)
./llama.cpp/llama-server \
--model unsloth/Qwen3.5-397B-A17B-GGUF/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "unsloth/Qwen3.5-397B-A17B" \
--temp 0.6 \
--top-p 0.95 \
--ctx-size 16384 \
--top-k 20 \
--min-p 0.00 \
--port 8001
然后用 Python 调用:
代码语言:javascript
AI代码解释
from openai import OpenAI
openai_client = OpenAI(
base_url="http://127.0.0.1:8001/v1",
api_key="sk-no-key-required",
)
completion = openai_client.chat.completions.create(
model="unsloth/Qwen3.5-397B-A17B",
messages=[{"role": "user", "content": "Create a Snake game."}],
)
print(completion.choices[0].message.content)
这样就完全兼容 OpenAI 的 API 格式了,之前用 OpenAI SDK 写的代码直接无缝切换。
推理参数怎么调?官方推荐设置
Qwen3.5 支持混合推理,thinking 和 non-thinking 模式的参数不一样,别搞混了:
Thinking 模式(深度推理)
|
参数 |
精确编码 |
通用任务 |
|---|---|---|
|
temperature |
0.6 |
1.0 |
|
top_p |
0.95 |
0.95 |
|
top_k |
20 |
20 |
|
min_p |
0.0 |
0.0 |
|
presence_penalty |
0.0 |
1.5 |
Non-Thinking 模式(快速响应)
|
参数 |
通用任务 |
推理任务 |
|---|---|---|
|
temperature |
0.7 |
1.0 |
|
top_p |
0.8 |
0.95 |
|
top_k |
20 |
20 |
|
min_p |
0.0 |
0.0 |
|
presence_penalty |
1.5 |
1.5 |
⚠️ 最大上下文 262,144 tokens,推荐输出长度 32,768 tokens。但注意,开大上下文很吃内存,24GB 显存建议
--ctx-size 16384。
工具调用:本地 Agent 的基础
Qwen3.5 原生支持 function calling,配合 llama-server 可以直接做本地 Agent。这意味着你可以让模型调用 Python 脚本、执行终端命令、查询数据库,而不只是对话。
和 Ollama 的工具调用相比,直接用 llama-server + OpenAI SDK 的方案更灵活,自定义能力更强。如果你只是想快速体验,Ollama 更省心;如果要做生产级的 Agent,还是走 llama-server 这条路。
不同尺寸怎么选?老章建议
|
你的场景 |
推荐型号 |
理由 |
|---|---|---|
|
日常对话、轻量代码 |
35B-A3B |
MoE 架构,速度飞快,24GB 就能跑 |
|
追求准确性、做题答卷 |
27B |
Dense 架构更稳定,17GB 起步 |
|
企业级多任务 |
122B-A10B |
甜点级的性价比,70GB 内存搞定 |
|
硬核玩家、对标闭源 |
397B-A17B |
旗舰性能,256GB Mac 直接上 |
优缺点总结
优点:
- ✅ MoE 架构,397B 参数只激活 17B,推理效率极高
- ✅ Unsloth Dynamic 2.0 量化后精度损失不到 1%,真·效果不打折
- ✅ 256K 超长上下文,201 种语言,多模态全覆盖
- ✅ 混合推理模式:thinking 和 non-thinking 随时切换
- ✅ 对标 GPT-5.2 / Claude Opus 4.5,多项指标直接反超
- ✅ 完全开源,支持本地部署和微调
缺点/局限:
- ⚠️ 旗舰 397B 的入门门槛仍然是 192GB+ 内存
- ⚠️ 在纯数学推理和代码竞赛上,和 GPT-5.2 仍有差距
- ⚠️ MoE 架构在部分纯 CPU 推理场景下速度不如 Dense 模型
适合人群:想在本地跑顶级大模型的 Mac 用户、有 24GB+ 显卡的 Linux 玩家、企业内网部署场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)