从YOLO到U-Net:视觉识别两大核心模型,如何撑起安防、医疗的智能防线?
卷积神经网络 在视觉领域有着极为广泛的应用,它与经典神经网络同属最基础的概念和核心元素,但需明确的是,任何想要实现优异表现的模型,都绝非依靠单个神经网络就能达成,即便是大模型,也不会单纯依赖经典神经网络,而是会在经典神经网络的基础上,套上Transformer框架、编码器解码器以及QKV自注意力机制,借助这些框架充分释放经典神经网络的效能.
在视觉识别领域,卷积神经网络同样遵循这一逻辑,在其之上叠加框架后,便衍生出了Yolo、UNet等成熟模型。相较于大模型领域应用层的丰富多元,涵盖私有知识库、工作流、提示词等诸多方向,视觉领域的应用层则相对单薄,当我们切入不同场景时,往往需要在模型层深耕,甚至结合模型层与工具协同发力,开展针对性的模型训练。
截至目前,视觉领域的核心聚焦于模型层,当模型层通过大量技术打磨具备核心功能后,便能与APP、小程序、Web网页实现无缝链接,最终转化为可落地的产品。由于当前视觉领域尚未出现通用模型,各类应用均需依托模型层按既定的五个步骤推进,这也决定了视觉产品的功能本质上等同于模型能力,产品形态不过是在模型能力之上叠加前端页面,实现便捷的页面操作。
而卷积神经网络所支撑的图像分类、目标检测、图像分割技术,也深度赋能安防、工业检测、医疗图像、自动驾驶等众多行业,成为这些领域视觉技术落地的核心支撑。
常用的模型:
- 图像分类:ResNet、EfficientNet
- 目标检测:YOLO
- 图像分割:UNet
卷积神经网络 与 图像分类模型
卷积神经网络的核心:从特征提取到分类输出
卷积神经网络之所以能高效完成图像分类,核心在于其层层递进的特征提取机制,每一步都精准服务于最终的分类目标。
首先是卷积核,它堪称微观特征提取器,能够精准捕捉图像中的边缘、纹理等基础细节;
接着,卷积层会调用n个不同的卷积核,对整张图片进行全方位扫描,全面挖掘图像中的多元特征;扫描后生成的特征图,每一个数值都对应着图像某一小区域的特征属性,将图像的细节特征转化为可量化的数据;
而池化层则进一步优化特征提取效率,它通过缩小特征图尺寸,扩大感受野,让模型更易捕捉图像的结构特征,为后续分类筑牢基础。
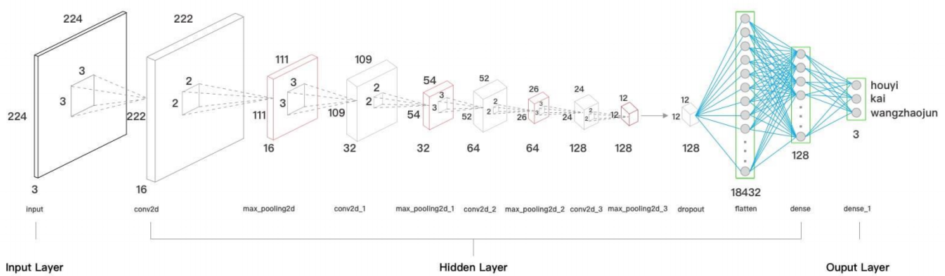
图像分类本身是视觉任务中最基础的一类,只需判断图片中是否存在人、猫、狗、车等目标,无需额外标注具体位置。
卷积神经网络无需搭建复杂框架,仅靠卷积层与池化层的层层堆叠,就能从原始图片中提取出特征图,这张特征图本质上就是原始图片的浓缩表征。随后,通过linear层对提取的特征进行识别,就能精准输出图片中包含的目标类别,整个过程高效直接。
它提取的特征聚焦于图像中特征鲜明的区域,将这些区域转化为数学向量,再经过分类任务处理,即可输出不同目标的概率,恰好匹配图像分类任务对特征提取的核心需求。
若想系统掌握卷积神经网络(CNN)的原理,推荐阅读文章:单模态视觉识别模型:从应用到原理的初步解析。
ResNet:图像分类的利器,却受限于任务边界
随着对图像分类精度的要求不断提升,网络层数需要持续增加,ResNet残差学习框架应运而生。若想深入了解ResNet,可查阅文章:浅谈多模态领域的Transformer。
ResNet之所以能在图像分类领域表现突出,核心原因有三:
其一, 它天生擅长提取特征,能精准捕捉图像的核心信息;
其二, 图像分类任务本身门槛较低,只需优质特征就能完成分类;
其三, 它聚焦于特征突出的区域,让核心特征得到充分关注。
ResNet的核心创新是残差链接,这一设计打破了深度神经网络的训练瓶颈,让网络层数可以持续加深,真正让深度神经网络从理论走向现实。
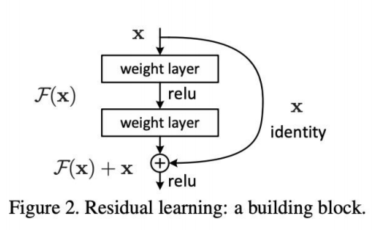
网络层数越深,提取的特征就越具深度,足以区分猫和狗这类外形相近的物种——二者虽同属小型毛茸茸动物,但细微差异能被深层特征精准捕捉。
不过,ResNet的局限性也十分明显,它仅能胜任图像分类这类简单任务。
一方面,图像分类的训练数据构造简单,只需将图片与对应标签配对即可;
另一方面,ResNet未叠加复杂框架,缺乏应对高阶任务的能力,这也决定了它只能聚焦于简单任务场景。
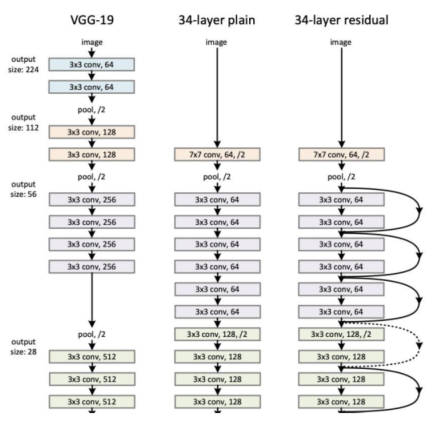
在视觉模型的研发中,第一步必须明确核心任务——是零件检测、图片分类,还是医疗图像分割。任务定义清晰后,模型的输入输出也随之确定,后续只需匹配对应的训练数据即可。
这也凸显出图像分类任务的本质: 它是视觉模型中最基础的任务,无需复杂架构支撑。
而想要打造真正的大模型,仅靠经典神经网络远远不够,必须叠加编码器解码器、自注意力机制,依托Transformer等核心架构,才能突破能力边界,承接更高阶的任务挑战。
YOLO模型 - 目标检测
YOLO的定位:聚焦目标检测,主打速度突破
YOLO全称“You Only Look Once”,核心聚焦目标检测领域,在安防、无人驾驶等场景应用极为广泛。它的诞生,正是为了对传统目标检测方法进行优化,而优化的核心重点,便是速度——在保证模型精度不大幅降低的前提下,大幅提升检测速度,以满足实时性要求极高的任务需求。
基于卷积神经网络,为解决更高阶、更复杂的目标检测任务,YOLO衍生出专属的复杂模型框架,成为目标检测领域的标杆性模型,完美适配对实时响应有强依赖的行业场景。
YOLO的实战价值:精准匹配安防与无人驾驶核心诉求
在安防场景中,YOLO的应用逻辑十分清晰:以工业园区为例,系统可精准判断特定区域是否出现车辆、人员,一旦出现违规目标便触发报警;甚至可叠加额外前提,比如识别人员是否佩戴黄色安全帽,未佩戴则判定违规并报警,这类精准的异常检测能力,是安防体系的核心支撑。
在无人驾驶领域,实时检测行人、车辆、障碍物等目标,同样是保障行驶安全的关键。这类对实时性、准确性要求极高的任务,正是YOLO的核心适用场景,其也成为安防、无人驾驶领域最主流的目标检测模型架构。
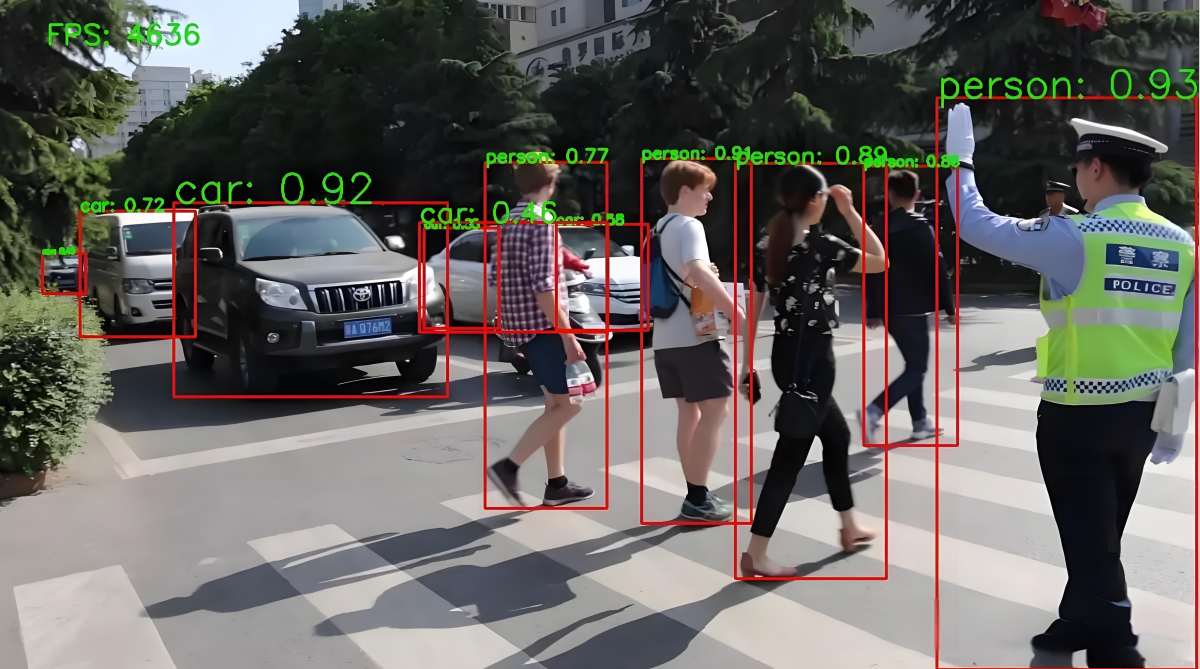
YOLO的诞生逻辑:打破传统两阶段瓶颈,实现实时检测
在YOLO问世前,目标检测采用两阶段模式:
第一阶段, 通过算法从图像或视频中锁定可疑目标区域;
第二阶段, 对可疑区域进行截图,再借助图像分类模型识别区域内的物体。
这种模式的弊端显著——流程繁琐、运行速度慢,无法满足自动驾驶等对实时性要求极高的场景。
YOLO的核心突破,在于将两阶段流程简化为“单次查看”:
输入一张图像,模型一次性完成目标的定位与识别,大幅压缩处理时间。
其核心目标是在维持精度的前提下,实现速度的跨越式提升,确保模型每秒可处理足够多的帧数——视频每秒通常为24-30帧,YOLO需达到每秒10帧以上的处理能力,才能满足实时目标检测的需求,这正是YOLO诞生的核心驱动力。
YOLO的核心方法:从任务定义到模型输出的全流程拆解
视觉识别领域长期缺乏通用大模型,因此打造AI产品的第一步,便是精准定义任务场景与识别目标,这直接决定了后续的模型设计与数据准备。以目标检测为例,需明确场景下需识别的物体种类,并用红色框精准定位目标。
在工业检测、智能驾驶等场景中,还需明确摄像头与待检测物体的距离、物体在图像中的占比等关键参数,参数定义越精准,模型准确率越高。
YOLO的核心工作逻辑极具特色,与普通卷积神经网络截然不同:它会将输入图像划分为7×7的网格,锁定目标物体的中心点所在网格,再通过卷积核定位目标,输出包含中心点坐标、框的宽高、置信度,以及物体类别概率的核心数据。
其核心公式为S×S×(B×5+C):其中S为网格数(7),B为每个网格的检测机会(通常为2),5代表中心点坐标、框的宽高与置信度,C为物体类别概率向量。以识别20种物体为例,一张图像经YOLO处理后,会输出7×7×(2×5+20)=1470个数据,最终仅保留置信度达标的有效目标信息。
核心公式 5 是中心坐标点(X,Y)、框住的矩形宽高(W,H)、自信度Z;
第一个网格来说,第一个网格内自信度是0,所以x * y * w * h * 0 = 0,B是2,所以它给出2个机会,这2个机会自信度都是0,所以第一个方格的输出就是0,它是没意义的。
以下图来说,当前图片里面会有46个是没意义的,只有3个中心点是有意义的。
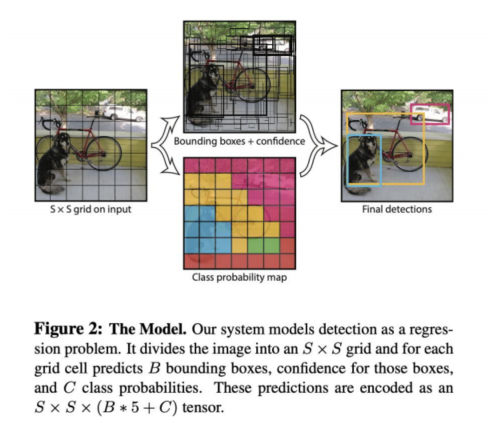
智能驾驶的案例
比如这有一辆车,车头有个摄像头,如果斑马线上有个小孩,那么车离小孩就有个估算值,因为摄像头是由固定的分辨率,也决定了这张图是怎么样的分辨率,假设车离小孩有3米远,当前分辨率是2000 * 3000像素,那么模型可以算出,这个小孩在图片内是多大,这就叫场景的设定,也可以反推过来,这个小孩在图片是100 * 200,那么这个小孩离车子是有3米远。

到目前为止,视觉识别模型,还没有所谓的大模型,在过去很多年,大家都在运行很多非常小的模型,这样的小模型它只能作非常单一的任务,在过去20年,在无数个领域里面,一直用的都是小模型,只有最近2、3年,才出现大模型。网上有很多媒体在吹捧未来AI的模型是小模型,我个人觉得这是很有误的。
YOLO的训练闭环:从数据标注到误差优化的落地路径
YOLO的落地需要一套严谨的全流程闭环,核心包含四大关键步骤:
- 场景与输入输出定义:需由产品经理、算法工程师与研发工程师协同敲定,明确场景参数、模型输入输出逻辑,这直接决定了后续数据标注的方向,以YOLO为例,其输入为一张图像,输出为包含目标位置与类别的核心数据。
- 训练数据标注:在零件检测、智能驾驶、安防等场景中,需通过标准平台对图像中的物体进行框选与分类,并精准计算中心点,形成高质量训练数据。
- 总误差定义与训练:YOLO依托卷积神经网络提取特征,模型初始参数随机初始化,核心通过计算总误差开展训练。将标注数据与模型输出对比,累积误差,再反向调整卷积核参数,让模型逐步收敛。
- 模型迭代与验收:训练过程中,算法工程师需基于经验排查误差来源,在误差分析与数据标注间循环调整,优化模型后开展验收,确保模型性能达标。
损失函数是总误差的核心载体,它由中心点坐标误差、宽高误差、置信度误差、类别概率误差五部分构成。算法工程师可通过调整超参数,灵活调配各部分误差在总误差中的占比——比如当中心点识别精准但宽高偏差大时,可降低中心点误差权重、提升宽高误差权重,通过反复训练优化模型效果。

这里做一个简单的科普,
∑是累加的意思,从0开始;S=7,就是从0开始到49,简单来说就是49组数据的累加;B是多少次机会,本次是2次机会,合起来就是49组数据,给你2次机会,就是98个误差要累积;obj全称是object目标的意思,98个误差里面有目标的话,obj就是1,没有目标,obj就是0 ,obj跟后面的计算是相乘的关系,如果是0,后面计算就不需要管了,就是0,只有obj是1,后面的计算才有意义。
后面的计算是在计算误差,第一层误差是49组数据内,给2次计算,总共98次计算,有意义是数据才算1,可以进行计算,没有意义的数据直接是0,没有任何意义,直接抹除就行。
后面计算x坐标,y坐标,以及训练数据的x、y坐标,可以看到到底有多少偏移,偏移越多,误差越大。
第二层误差计算是用宽高做计算,比对误差,只要计算的宽高跟训练数据的宽高不一样,我就要计算误差。
第三、四层误差计算是自信度的计算,训练数据的自信度是1或0,但是模型计算出来的自信度是有小数的,比如0.87,这个时候就用训练数据的自信度与模型计算的自信度做比较,计算误差值。
这2层都跟自信度有关,是因为让模型不止要能识别出核心有用的3个中心区域,也能识别出46个无意义的区域,并且给他们误差值进行计算,也能避免让模型过拟合。第三层是与3个中心区域计算误差有关,它们的前置都是与1相乘;第四层有⋋ 这个值是0-1之间,公式内有3个超参数⋋ ,是由算法工程师人工指定的,当模型训练完后,还会进行参数测试,再次调整超参数
第五层是20种概率数字,训练数据里面20种类型概率数字与模型计算出来的20种类型概率数据的误差。
最后会去识别图片,发现中心点都很准,但是宽高参数经常不准,就要把第一层的超参数⋋调小点,第二层的超参数⋋调大点,在总误差里,第二层计算宽高误差在总占比里面会被提升,因为中心点很准了,我们可以把第一层的超参数⋋降低点。所以算法工程师可以调整这3个超参数,让它们各自在总误差里有高有底,做不同的调配,一次次训练模型
YOLO的先天局限与优化方案
卷积神经网络的固有特性,让YOLO存在先天局限:网络层级越深,特征图尺寸越小,对小物体的识别能力越弱,这在智能驾驶场景中问题尤为突出——车辆需及时识别远处的小物体,否则会引发安全风险。但在零件检测场景中,摄像头与零件的距离、角度固定,物体在图像中的占比稳定,无需识别小物体,因此这一局限不影响使用。
零件检测场景:

智能驾驶场景:
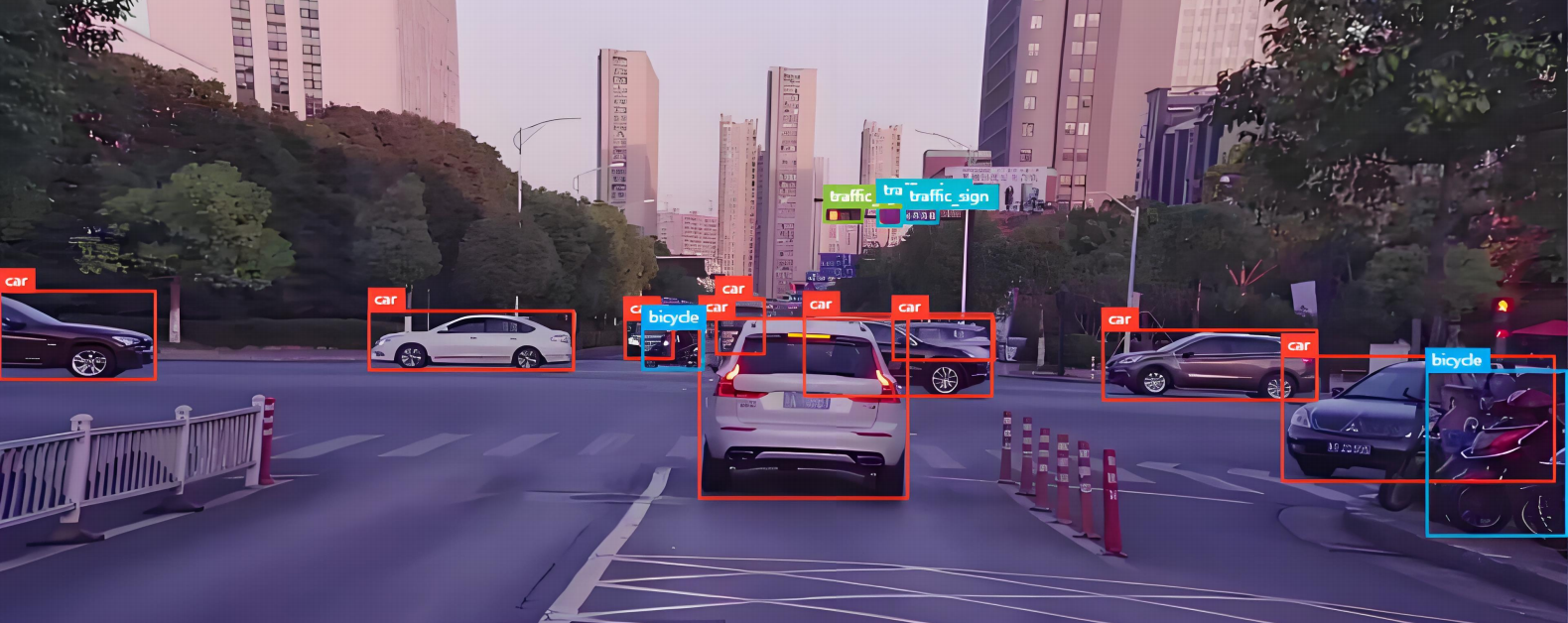
通过一次次测试,我们能发现YOLO模型里面还是在不停的做卷积核操作,池化+卷积提取特征。最后会得到一个7 * 7 * 30的数据。
训练数据里有1000条这样的7 * 7 * 30的数据,所以模型计算的结果可以与正确答案去做比较,就是误差,然后反过来可以去看每个卷积核里面的参数,是不是它们提取特征不靠谱,让模型自己去做调整参数。
只要总误差大,模型就要反思下每个步骤的参数是否需要调整。
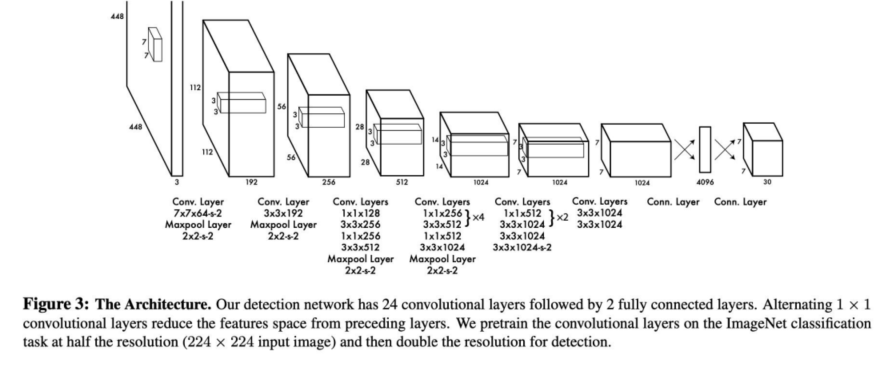
为解决小物体识别难题,YOLO引入残差块设计,每个残差块包含2个卷积层与1个池化层,借助残差学习框架,将上一层的完整信息传递至下一层,避免特征丢失。同时,YOLO开展大、中、小三种尺度的目标检测,整合不同层级的特征信息,全方位提升对不同尺寸目标的识别能力,有效弥补了模型的先天短板。
U-Net:图像分割领域的高效利器
U-Net是专为图像分割领域打造的模型,核心应用方向聚焦于医疗图像处理,凭借模型结构简单的核心优势,在高精度分割任务中占据重要地位。它精准适配医疗场景对细节的严苛要求,成为医疗图像分析的关键工具。
图像分割的核心流程:五大步骤筑牢基础
图像分割任务的落地,需严格遵循五大核心步骤,每一步都是保障分割精度的关键:
- 场景与任务定义:明确任务落地的场景,梳理场景中的限制条件,同时固定可明确的物理条件,为后续工作划定清晰边界。
- 输入输出定义:明确模型的核心逻辑,输入为单张图片,输出同样是图片,且输出图片需对每一个像素进行精准标注,明确其所属物体类别。
- 数据标注:借助AI辅助工具开展标注工作,高效完成海量像素的标注任务,为模型训练提供高质量数据基础。
- 总误差定义:搭建误差评估体系,为后续模型优化明确核心目标,确保训练方向不偏离。
- 模型训练:依托标注数据与误差定义,开展模型训练,通过不断迭代优化,让模型逐步掌握精准分割的能力。
U-Net的诞生逻辑:破解高复杂度分割难题
U-Net与YOLO的核心共性,在于二者均依托大量卷积核开展特征提取工作,但图像分割任务的复杂度远超常规检测任务,要求对每一个像素进行精准标注,这是仅能完成目标定位的YOLO无法胜任的,因此U-Net应运而生。
在自动驾驶等复杂场景中,U-Net与YOLO并非替代关系,而是协同配合,共同满足多维度的任务需求。

U-Net最核心的应用场景是医疗图像处理,其能够实现极致细致的分割工作,比如在CT图片分析中,可精准测算边缘厚度,且必须做到一个像素都不出错——因为细微的像素偏差,可能导致病情判断出现本质差异,这也凸显了U-Net在医疗场景中对精度的极致追求。
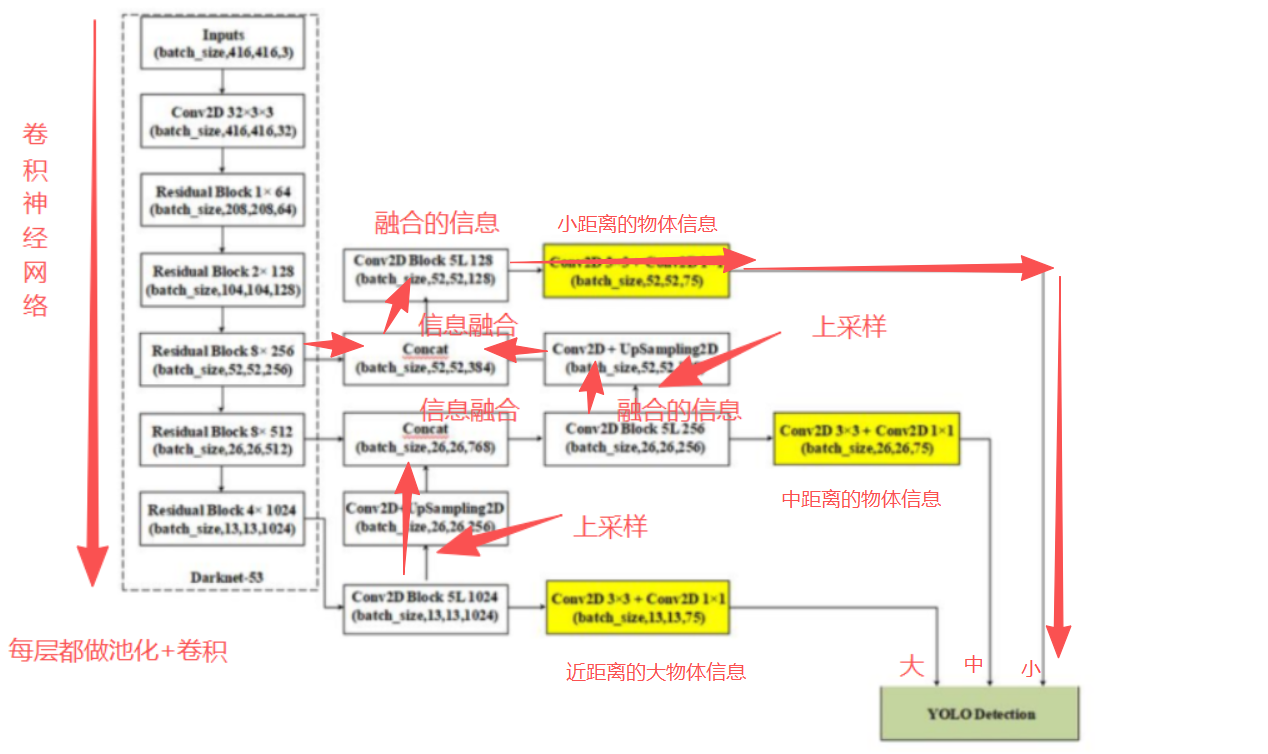
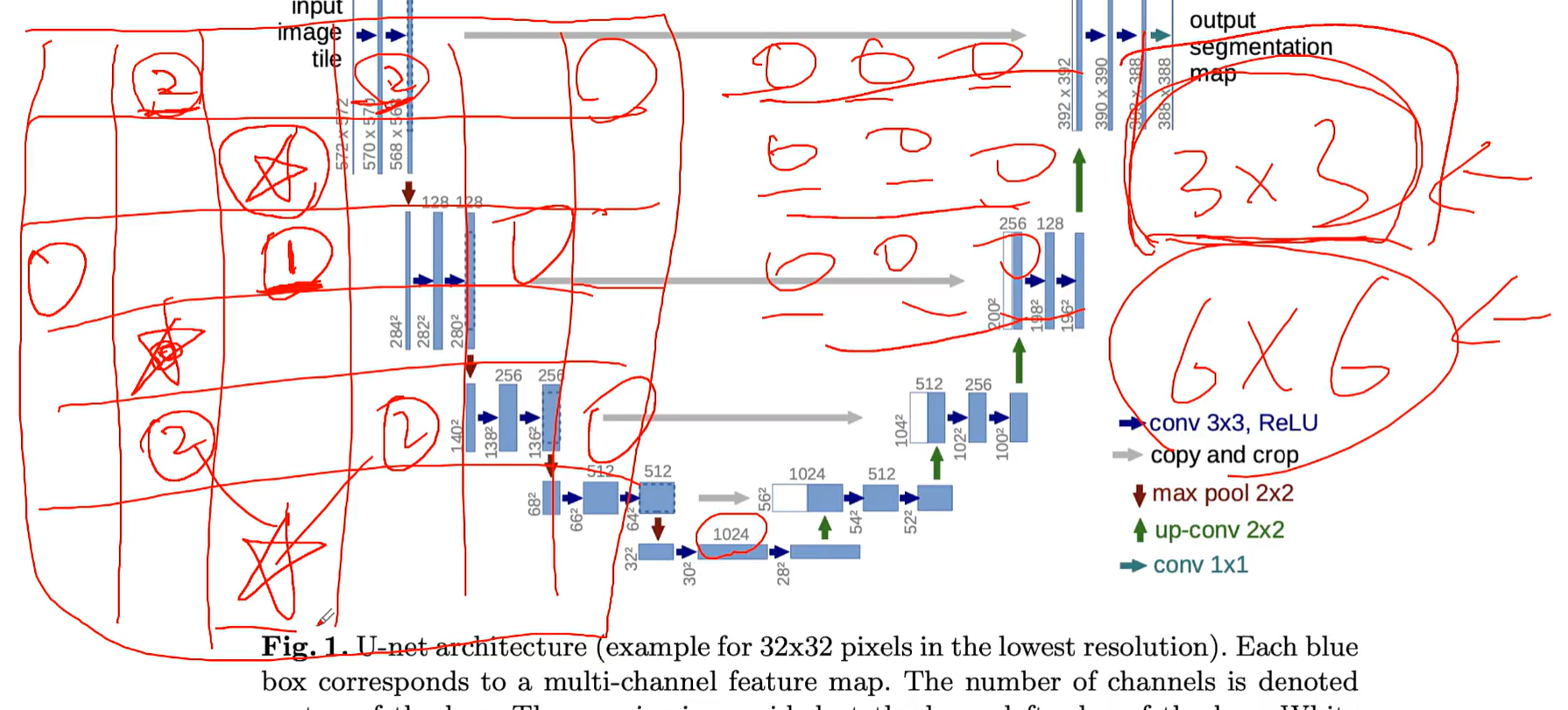
U-Net的模型架构:U型结构,特征融合的核心密码
U-Net得名于其标志性的U型架构,这一结构是模型实现高精度分割的核心支撑:
- 下采样阶段:模型持续开展特征提取,每个层级的提取都极具价值,随着层级深入,最终提取出结构、形状等核心特征。
- 上采样阶段:从最底层的特征出发,逐步开展上采样,还原与原始信息相同维度的内容。
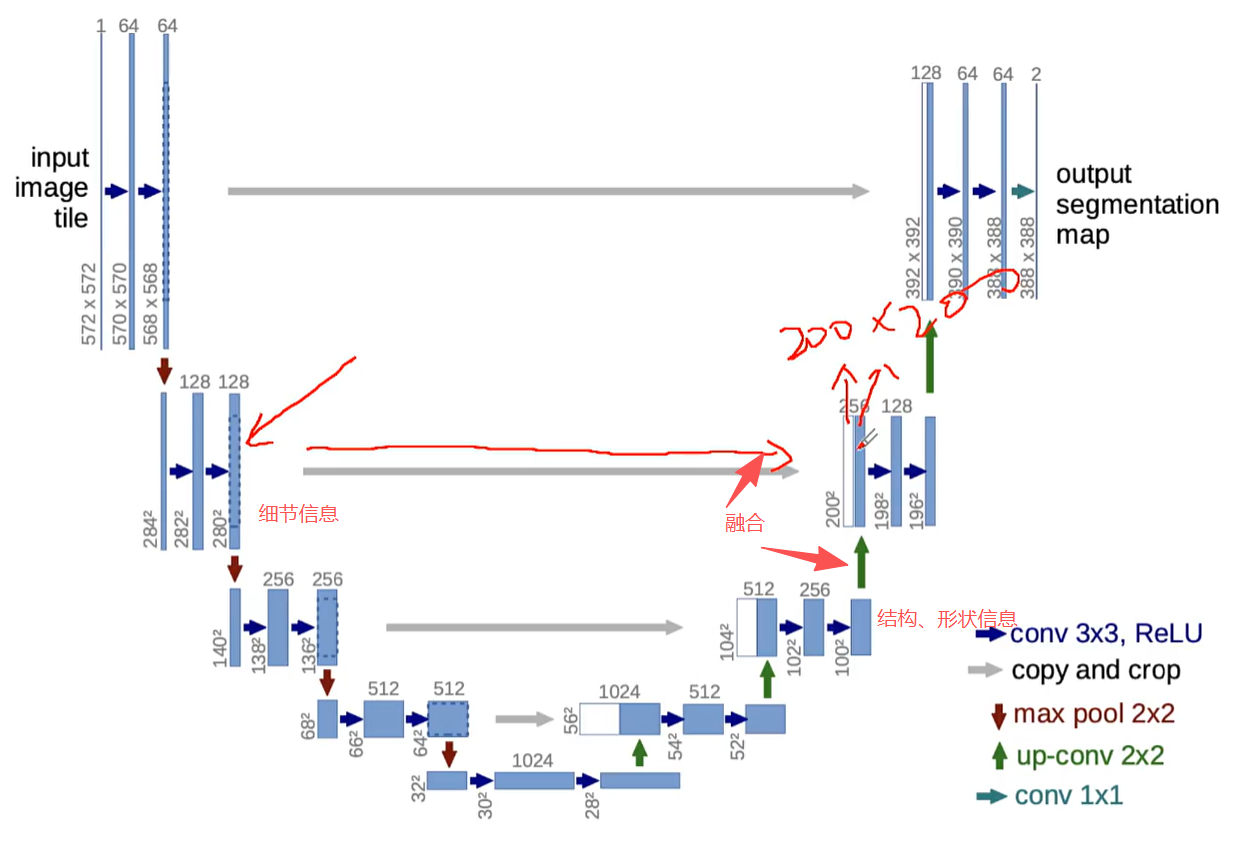
- 特征融合:在上采样的每一层级,都会将左侧下采样保留的细节、纹理信息,与右侧上采样的结构、形状信息进行融合,最大化还原特征向量信息,最终实现对图像中每一个像素的精准标注。
上采样的核心是实现维度拓展,例如将3×3的特征图拓展至6×6,而右侧每一层的特征融合操作,则是保障分割精度的关键环节。

上采样的步骤,比如从3 * 3 —> 6 * 6
右侧每层都需要做融合操作
U-Net的拓展应用与行业启示
除了医疗领域,U-Net在文生图、文生视频领域也应用广泛,展现出强大的跨领域适配能力。
大家可以看下我之前写的文章 浅谈扩散模型如何编织创意图像的魔法,聊到了文生图、视频。
其与GPT的融合逻辑也十分清晰:GPT通过96头机制输出向量数据后,经拼接形成长向量,再依托一层神经网络完成融合,输出最终的向量数据。
想详细了解GPT模型96头机制,可以看下我之前写的文章 揭秘Transformer架构设计 2(补全版),里面详细聊到了多头自注意力机制以及融合神经网络。
当前视觉模型尚未出现通用型模型,所有任务均需在模型层严格落实上述五大步骤。这也意味着,产品的核心功能直接等同于模型能力,所谓产品,本质上是在模型能力基础上叠加前端页面,实现便捷的页面操作,这一规律在U-Net的应用中同样适用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)