PLUTO论文翻译
PLUTO:将基于模仿学习的自动驾驶规划推向极限
Jie Cheng, Yingbing Chen, and Qifeng Chen
摘要 :我们提出了 PLUTO,一个强大的框架,旨在将基于模仿学习的自动驾驶规划推向极限。我们的改进源于三个关键方面:一种纵向-横向感知的模型架构,可实现灵活多样的驾驶行为;一种广泛适用且高效的批量计算创新辅助损失计算方法;一种利用对比学习的新型训练框架,辅以一套新的数据增强方法,用于规范驾驶行为并促进对潜在交互的理解。我们使用大规模真实世界 nuPlan 数据集及其相关的标准化规划基准评估了我们的框架。令人印象深刻的是,PLUTO 实现了最先进的闭环性能,首次击败了其他竞争性的基于学习的方法,并超越了当前表现最佳的基于规则的规划器。结果和代码可在 https://jchengai.github.io/pluto 获取。
关键词 — 自动驾驶,模仿学习,基于学习的规划。
I. 引言
基于学习的规划已成为自动驾驶一种潜在的可扩展方法,吸引了大量的研究兴趣[1]。特别是基于模仿的规划,在模拟和实际应用中已显示出显著的成功。然而,基于学习的规划的有效性仍然不尽如人意。正如[2]所指出的,传统的基于规则的规划优于所有基于学习的替代方案,赢得了2023年nuPlan规划挑战赛。本文阐述了基于学习的规划中固有的主要挑战,并提出了我们的新颖解决方案,旨在推动基于学习的规划所能达到的边界。
第一个挑战在于获取多模态驾驶行为。观察到,虽然基于学习的规划器擅长学习纵向任务(如车道保持),但它们在横向任务[3]上表现不佳,例如执行变道或绕过障碍物,即使空间允许也是如此。我们将这一缺陷归因于模型架构设计中缺乏显式的横向行为建模。我们之前的工作[4]试图通过生成明确以附近参考线为条件的计划来解决这个问题,但该方法仅限于生成最多三个方案,并且没有有效地整合横向和纵向行为建模。在本研究中,我们通过采用基于查询的架构来增强这种方法,该架构能够通过融合横向和纵向查询生成大量方案。先进的模型设计使我们的规划器能够展示多样化和灵活的驾驶行为,我们认为这是迈向实用基于学习规划的关键一步。
除了模型架构之外,纯模仿学习还包含固有的局限性,包括学习捷径[5]-[8]、分布偏移[3]、[5]、[9]和因果混淆[10]、[11]等倾向。本文从三个维度解决这些普遍存在的挑战:
(1) 超越纯模仿损失的学习。我们同意先前的研究[5]、[9]、[12],即仅依靠模仿损失不足以学习期望的驾驶行为。在训练阶段施加显式约束是必要的,尤其是在自动驾驶这一安全关键领域。一种流行的方法是添加辅助损失来惩罚不良行为,例如碰撞和越野驾驶,如[5]、[9]先前所证明的那样。然而,它们的方法要么是为热图输出设计的[5],要么需要一个可微分的光栅化器[9]将每个轨迹点渲染到图像中。因此,输出分辨率受到限制以减轻计算负担。目前尚不清楚如何针对更现代的基于向量的模型高效地实现这些损失。为了填补这一空白,我们引入了一种基于可微分插值的新颖辅助损失计算方法。这种方法不仅涵盖了广泛的辅助任务,而且便于在现代深度学习框架中进行批量计算,从而增强了其适用性和效率。
(2) 新的数据增强。当模型进行开环训练和闭环测试时会出现问题。例如,随着时间推移的误差累积可能导致输入数据偏离训练分布;模型可能依赖非预期的捷径而非获取知识。数据增强已被广泛用于缓解这些问题并已证明有效,例如,基于扰动的增强[3]、[5]、[9]教会模型学习从小偏差中恢复,而基于丢弃的增强防止学习捷径[3]。除了这两种增强之外,我们还引入了进一步的增强技术,旨在规范驾驶行为和增强交互学习。
(3) 通过对比学习。基于模仿学习的模型由于缺乏与环境的交互反馈,往往难以识别潜在的因果关系[10]。这个问题会显著影响性能;例如,规划器可能通过模仿附近代理的行为而非响应红灯来减速。我们的目标是在不显著复杂化训练过程的情况下解决这个问题,而强化学习或采用数据驱动的模拟器则会复杂化训练过程。受对比学习[13]有效性的启发,对比学习通过区分相似和不相似的示例来增强表示,我们认识到有机会将因果理解注入模型。这是通过使模型能够区分原始输入数据和修改后的输入数据(例如,从自动驾驶车辆(AV)的视角中排除前车)来实现的。基于这种方法以及前述两种策略,我们引入了一个新颖的统一框架,称为对比模仿学习(CIL)。
总之,本研究引入了一个全面的数据驱动规划框架,名为PLUTO,旨在将基于模仿学习的自动驾驶规划推向极限。PLUTO在模型架构、数据增强和学习框架方面融合了创新的解决方案。它已使用大规模真实世界nuPlan[14]数据集进行了评估,并展示了卓越的闭环性能。值得注意的是,PLUTO首次超越了现有的最先进的基于规则的规划器PDM[2],标志着该领域的一个重要里程碑。我们的主要贡献如下:
- 我们引入了一种基于查询的模型架构,同时处理横向和纵向规划操作,实现灵活多样的驾驶行为。
- 我们提出了一种基于微分插值的辅助损失计算方法。该方法适用于广泛的辅助任务,并允许在基于向量的模型中进行高效的批量计算。
- 我们提出了对比模仿学习(CIL)框架,并附有一套新的数据增强方法。CIL框架旨在规范驾驶行为并增强交互学习,同时不显著增加训练的复杂性。
- 我们在大规模nuPlan数据集上的评估表明,PLUTO在闭环规划中实现了最先进的性能。我们的模型和基准已公开可用。
II. 相关工作
A. 基于模仿的规划
考虑到当今数据的丰富性和可负担性,通过克隆经验丰富的驾驶员的策略来学习驾驶可能是自动驾驶最直接和可扩展的解决方案。其中一种流行的方法是端到端(E2E)驾驶[15]。这种方法直接从原始传感器数据学习驾驶策略,并在相对较短的时间内取得了显著进展。最初,研究重点是基于卷积神经网络(CNN)的模型[16]、[17],将摄像头输入映射到控制策略。后来演变为包含更复杂的方法[18]-[21],利用多传感器融合。最近,由LAV[22]和UniAD[23]等实体引领的发展已转向基于模块的端到端架构。这种方法将感知、预测和规划过程集成到一个统一模型中[24]、[25]。尽管它们有潜力,但大多数端到端策略严重依赖高保真模拟环境(如CARLA[26])进行训练和评估。因此,这些方法存在几个问题,包括模拟代理缺乏真实性和多样性、依赖不完美的基于规则的专家,以及必须弥合模拟与现实的差距才能应用于真实场景。
本文关注另一个研究方向,通常被称为中到中方法,该方法采用感知后结果作为输入特征。这种方法的主要优势在于模型可以专注于学习规划,并可以使用真实世界数据进行训练,消除了模拟到现实迁移的担忧。开创性的方法如ChauffeurNet[5]、SafetyNet[27]和UrbanDriver[28]已经展示了在真实环境中操作自动驾驶车辆的能力,后续工作在此基础上进行[3]、[4]、[29]-[31]。这些方法受益于运动预测领域的进步,包括采用基于向量的模型[4]、[28],这些模型在预测任务中表现出色,取代了基于光栅化鸟瞰图的早期规划模型[5]、[9]。然而,其中许多模型忽略了规划任务的固有特性,例如闭环测试和主动决策能力的需求。相比之下,我们提出的框架从一开始就是专门为规划设计的。我们的网络通过基于查询的架构联合建模纵向和横向驾驶行为,实现了灵活多样的驾驶风格。
先前的研究[5]、[9]-[11]已经证明了基本模仿学习的局限性并提出了改进方法。为了解决复合误差,一个早期的解决方案可以追溯到DAgger[32],它通过加入额外的专家演示来交互式地细化训练模型。随后,ChauffeurNet[5]引入了基于扰动的增强,使模型能够从小偏差中恢复,并为后来的研究确立了标准实践。添加辅助损失(如碰撞损失和越野损失[5]、[9]、[28])是提高整体性能的另一个重要方面。然而,它们的方法要么是为热图输出设计的[5],要么需要可微分的光栅化器[9]将轨迹转换为一系列带有核函数的图像。这些方法不适用于基于向量的方法。我们的研究通过引入一种采用可微分插值的新技术来弥补这一差距。
B. 对比学习
对比学习[33]是一种通过比较相似和不相似对来学习表示的框架,在计算机视觉[13]、[34]和自然语言处理[35]中取得了显著成功。在自动驾驶的背景下,已有一些针对运动预测的尝试。Social NCE[36]引入了一种社会对比损失来指导行人运动预测中的目标生成。Marah等人[37]利用基于动作的对比学习损失来细化学习到的轨迹嵌入。FEND[38]采用这种方法来识别长尾轨迹。这些研究强调了对比学习通过精心选择正例和负例将领域特定知识融入模型的潜力。在我们的研究中,我们将其应用扩展到规划领域,旨在改进驾驶行为预测并促进对车辆间隐式交互的理解。由于生成负样本对于对比方法至关重要,我们还引入了一套新的数据增强函数来定义对比任务。
III. 方法论
A. 问题表述
在本研究中,我们探讨动态城市环境中的自动驾驶任务,考虑自动驾驶车辆(AV)、NA个动态代理、𝑁𝑆NS个静态障碍物、高精地图𝑀M以及其他交通相关上下文C(如交通信号灯状态)。我们将代理的特征定义为𝐴=𝐴0:𝑁𝐴,其中A0代表自动驾驶车辆,静态障碍物表示为𝑂=𝑂1:𝑁𝑆。此外,我们将代理𝑎在时间𝑡的未来状态表示为 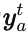 ,历史视野和未来视野分别表示为TH和TF。我们提出的系统PLUTO旨在同时为自动驾驶车辆生成NT条多模态规划轨迹,并为每个动态代理生成预测。最终输出轨迹τ∗的选择由评分模块S执行,该模块将基于学习的结果与所有场景上下文相结合。PLUTO的公式如下:
,历史视野和未来视野分别表示为TH和TF。我们提出的系统PLUTO旨在同时为自动驾驶车辆生成NT条多模态规划轨迹,并为每个动态代理生成预测。最终输出轨迹τ∗的选择由评分模块S执行,该模块将基于学习的结果与所有场景上下文相结合。PLUTO的公式如下:
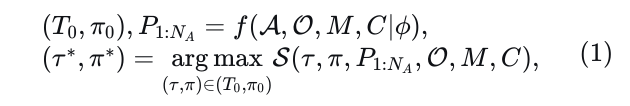
其中𝑓表示PLUTO的神经网络,ϕ是模型参数, 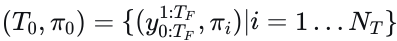 是自动驾驶车辆的规划轨迹及其对应的置信度分数,
是自动驾驶车辆的规划轨迹及其对应的置信度分数, 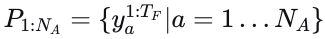 是代理的预测。
是代理的预测。
后续章节将详细阐述PLUTO框架内的每个组件。
B. 输入表示与场景编码
代理历史编码。任何给定时间𝑡t每个代理的观测状态表示为 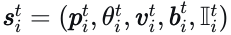 ,其中𝑝和𝜃分别表示代理的位置坐标和航向角;𝑣指速度向量,𝑏定义感知边界框的尺寸(长度和宽度);𝐼是一个二值指示符,表示该帧的观测状态。我们通过计算连续时间步之间的差异将历史序列转换为向量形式:
,其中𝑝和𝜃分别表示代理的位置坐标和航向角;𝑣指速度向量,𝑏定义感知边界框的尺寸(长度和宽度);𝐼是一个二值指示符,表示该帧的观测状态。我们通过计算连续时间步之间的差异将历史序列转换为向量形式: 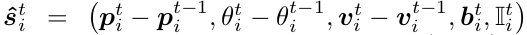 ,得到代理的特征向量
,得到代理的特征向量 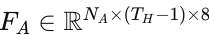 。为了提取和浓缩这些历史特征,我们采用基于邻域注意力的特征金字塔网络(FPN)[39],生成代理嵌入
。为了提取和浓缩这些历史特征,我们采用基于邻域注意力的特征金字塔网络(FPN)[39],生成代理嵌入 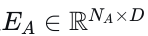 ,其中D表示本文中一致使用的隐藏层维度。
,其中D表示本文中一致使用的隐藏层维度。
静态障碍物编码。与通常忽略静态障碍物的运动预测任务不同,静态障碍物的存在对于确保安全导航至关重要。静态障碍物包括自动驾驶车辆不得穿过的任何实体,例如交通锥或隔离栏。可行驶区域内的每个静态障碍物表示为 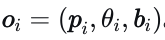 。我们使用两层多层感知机(MLP)对静态物体特征
。我们使用两层多层感知机(MLP)对静态物体特征 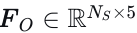 进行编码,得到嵌入
进行编码,得到嵌入 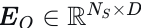 。
。
自动驾驶车辆状态编码。借鉴先前研究的见解[3]、[8],即模仿学习倾向于从历史状态中采用捷径,从而对性能产生不利影响,我们的方法仅使用自动驾驶车辆的当前状态作为输入特征。该当前状态包括自动驾驶车辆的位置、航向角、速度、加速度和转向角。为了编码状态特征同时避免基于外推运动学状态生成轨迹,我们采用了[3]中建议的基于注意力的状态丢弃编码器(SDE)。编码后的自动驾驶车辆嵌入为 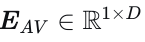 。
。
向量化地图编码。地图由𝑁𝑃NP条多段线组成。这些多段线经过初始下采样过程以标准化点的数量,然后计算每个点的特征向量。具体来说,对于每条多段线,第𝑖个点的特征包含八个通道: 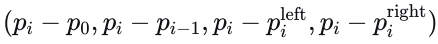 。这里,p0表示多段线的起点,而
。这里,p0表示多段线的起点,而 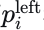 和
和 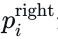 分别代表车道的左右边界点。包含边界特征至关重要,因为它传达了关于可行驶区域的信息,这对规划任务必不可少。多段线的特征表示为
分别代表车道的左右边界点。包含边界特征至关重要,因为它传达了关于可行驶区域的信息,这对规划任务必不可少。多段线的特征表示为 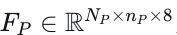 ,其中𝑛𝑃nP表示每条多段线的点数。为了编码地图特征,采用了类似PointNet[40]的多段线编码器,产生编码特征空间
,其中𝑛𝑃nP表示每条多段线的点数。为了编码地图特征,采用了类似PointNet[40]的多段线编码器,产生编码特征空间 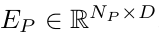 。
。
场景编码。为了有效捕捉各种模态输入之间复杂的交互,我们将不同的嵌入连接成一个张量 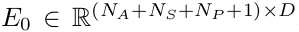 。然后使用一系列𝐿𝑒𝑛𝑐Lenc个Transformer编码器对该张量进行整合。由于向量化过程,输入特征被剥离了其全局位置信息。为了抵消这种损失,向每个嵌入引入了全局位置嵌入,记为𝑃𝐸。遵循[41],𝑃𝐸PE表示使用代理和静态障碍物的最新位置以及多段线的起点对全局位置(p,θ)的傅里叶嵌入。此外,为了封装固有的语义属性,如代理类型、车道限速和交通信号灯状态,在输入嵌入的同时还加入了可学习的嵌入𝐸𝑎𝑡𝑡𝑟。𝐸0初始化为
。然后使用一系列𝐿𝑒𝑛𝑐Lenc个Transformer编码器对该张量进行整合。由于向量化过程,输入特征被剥离了其全局位置信息。为了抵消这种损失,向每个嵌入引入了全局位置嵌入,记为𝑃𝐸。遵循[41],𝑃𝐸PE表示使用代理和静态障碍物的最新位置以及多段线的起点对全局位置(p,θ)的傅里叶嵌入。此外,为了封装固有的语义属性,如代理类型、车道限速和交通信号灯状态,在输入嵌入的同时还加入了可学习的嵌入𝐸𝑎𝑡𝑡𝑟。𝐸0初始化为
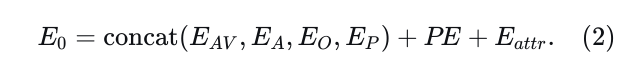
Transformer编码器的第𝑖层公式化为
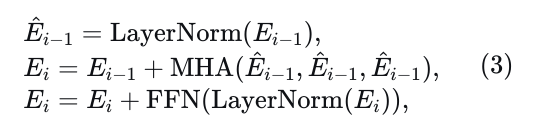
其中MHA(𝑞,𝑘,𝑣)是标准的多头注意力[42]函数,FFN是前馈网络层。我们将𝐸𝑒𝑛𝑐记为编码器最后一层的输出。
C. 多模态规划轨迹解码
自动驾驶中的规划任务本质上是多模态的,因为在给定的驾驶场景中通常可以采用多种有效行为。例如,车辆可以选择继续跟随前方较慢的车辆,或者变道超车。为了解决这个复杂问题,我们采用了基于查询的、类似DETR[43]的轨迹解码器。然而,直接实现学习到的无锚点查询已被发现会导致模式崩溃和训练不稳定,如[44]所示。受驾驶行为可以分解为横向(例如变道)和纵向(例如刹车和加速)动作组合这一观察的启发,我们引入了一种半锚点解码结构。图1展示了我们解码流程的图示概览,后续段落将详细描述各个组件。
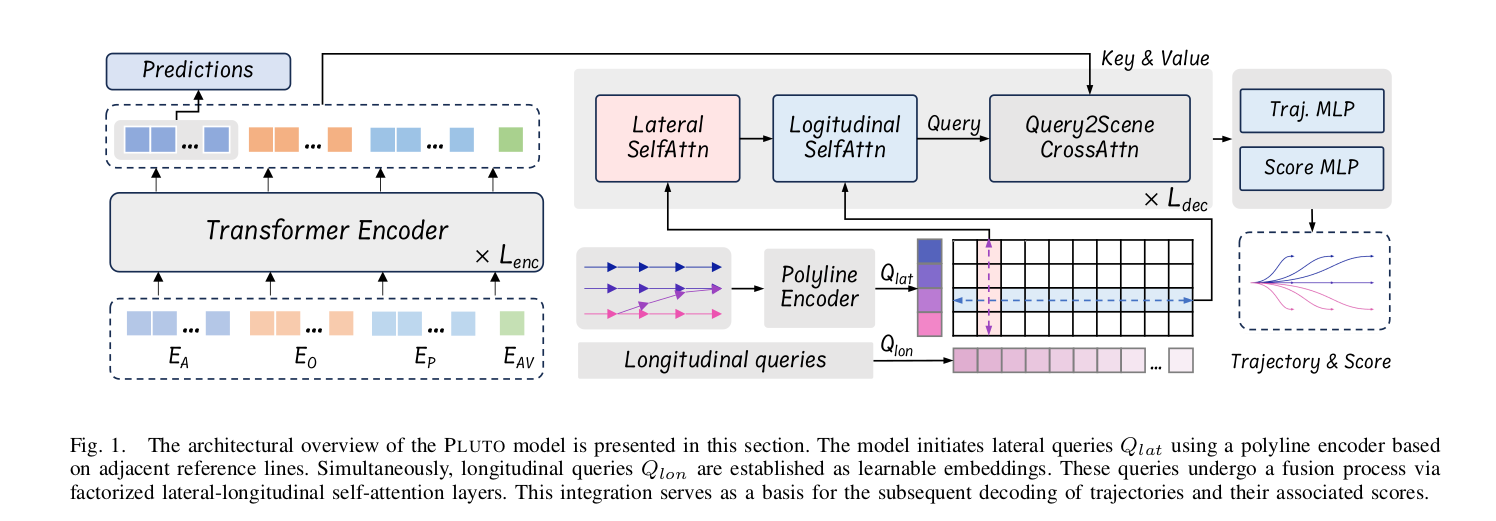
图 1 PLUTO 模型整体结构_ 本图展示了 PLUTO 模型的整体架构。模型首先利用__折线编码器,基于周边车道参考线生成横向查询Qlat;与此同时,将可学习嵌入向量作为__纵向查询Qlon。两类查询经由__横纵向因式自注意力层_完成特征融合,融合结果将用于后续轨迹及对应置信分数的解码。
作为横向查询的参考线。遵循[4]中概述的方法,本研究采用参考线作为横向查询的高级抽象。参考线通常源自自动驾驶车辆路线上周围的车道,是传统车辆运动规划中的关键组件,用于引导横向驾驶行为。最初,我们在自动驾驶车辆当前位置半径𝑅𝑟𝑒𝑓范围内识别车道段。从每个识别出的车道段开始,执行深度优先搜索以探索所有可能的拓扑连接,连接各自的车道中心线。随后,这些连接的中心线被截断为统一长度,并重新采样以保持一致的点数。参考线的表示和编码方法与第III-B节中概述的向量化地图编码相同。最终,嵌入的参考线被用作横向查询 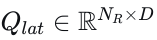 ,其中𝑁𝑅表示参考线的数量。
,其中𝑁𝑅表示参考线的数量。
分解的横向-纵向自注意力。除了𝑄𝑙𝑎𝑡之外,我们采用𝑁𝐿个无锚点、可学习的查询 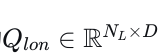 来封装纵向行为的多模态性质。随后,𝑄𝑙𝑎𝑡和𝑄𝑙𝑜𝑛被组合以创建初始的横向-纵向查询集,记为
来封装纵向行为的多模态性质。随后,𝑄𝑙𝑎𝑡和𝑄𝑙𝑜𝑛被组合以创建初始的横向-纵向查询集,记为 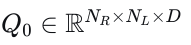 :
:
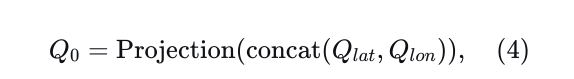
其中Projection指的是简单的线性层或多层感知机。由于𝑄0中的每个查询仅捕获与单个参考线相关的局部区域信息,我们利用𝑄0上的自注意力机制来整合跨不同参考线的全局横向-纵向信息。尽管如此,直接对𝑄0应用自注意力会导致 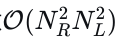 的计算复杂度,随着𝑁𝑅和𝑁𝐿的增加变得过高。受文献中类似方法的启发[45],我们在𝑄的每个轴上采用分解注意力策略,有效地将计算复杂度降低到
的计算复杂度,随着𝑁𝑅和𝑁𝐿的增加变得过高。受文献中类似方法的启发[45],我们在𝑄的每个轴上采用分解注意力策略,有效地将计算复杂度降低到 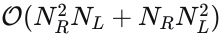 。
。
轨迹解码。轨迹解码器由一系列𝐿𝑑𝑒𝑐个解码层组成,每个解码层包含三种注意力机制:横向自注意力、纵向自注意力和查询到场景的交叉注意力。这些过程数学上表示如下:
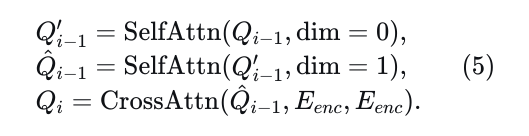
这里, 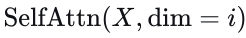 表示对𝑋X的第𝑖维应用自注意力,而
表示对𝑋X的第𝑖维应用自注意力,而 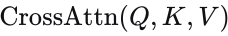 包含层归一化、多头注意力和前馈网络,类似于公式3定义的结构。解码器的最终输出𝑄𝑑𝑒𝑐随后用于使用两个MLP确定自动驾驶车辆的未来轨迹点及其相应的分数:
包含层归一化、多头注意力和前馈网络,类似于公式3定义的结构。解码器的最终输出𝑄𝑑𝑒𝑐随后用于使用两个MLP确定自动驾驶车辆的未来轨迹点及其相应的分数:
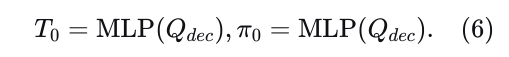
每个解码出的轨迹点有六个通道:[𝑝𝑥,𝑝𝑦,cos𝜃,sin𝜃,𝑣𝑥,𝑣𝑦]。此外,为了适应
缺乏参考线的场景,引入了一个额外的MLP头直接从自动驾驶车辆的编码特征解码单条轨迹:
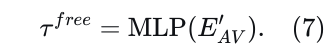
模仿损失。为了避免模式崩溃,我们在训练过程中采用了教师强制[46]技术。首先,将真值轨迹 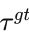 的终点投影到参考线上,选择横向距离最近的参考线作为目标参考线。然后,将该目标参考线按距离划分为𝑁𝐿−1个等长段。每个段对应每个纵向查询管理的区域,最后一个查询负责超出目标参考线的区域。包含投影终点的查询被指定为目标查询。通过整合目标参考线和目标纵向查询,我们得到目标监督轨迹
的终点投影到参考线上,选择横向距离最近的参考线作为目标参考线。然后,将该目标参考线按距离划分为𝑁𝐿−1个等长段。每个段对应每个纵向查询管理的区域,最后一个查询负责超出目标参考线的区域。包含投影终点的查询被指定为目标查询。通过整合目标参考线和目标纵向查询,我们得到目标监督轨迹 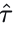 。对于轨迹回归,我们采用平滑L1损失[47];对于分数分类,我们使用交叉熵损失,表示如下:
。对于轨迹回归,我们采用平滑L1损失[47];对于分数分类,我们使用交叉熵损失,表示如下:
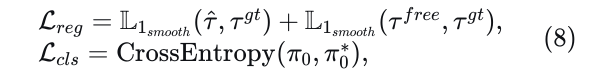
其中 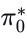 表示从 的索引派生的独热分布。总模仿损失表示为这两个分量的和,两者权重相等:
表示从 的索引派生的独热分布。总模仿损失表示为这两个分量的和,两者权重相等:
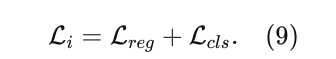
预测损失。使用一个简单的两层MLP,从编码后的代理嵌入中为每个动态代理生成单一模态的预测:
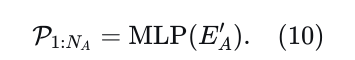
首先,这提供了密集的监督,有利于训练[39]、[48]。其次,生成的预测在后处理阶段消除不合适的规划方案中起着至关重要的作用,详见第III-F节。将代理的真值轨迹记为 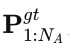 ,预测损失为:
,预测损失为:
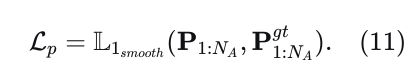
D. 高效可微分的辅助损失
正如先前研究所强调的[5]、[12],纯模仿学习不足以排除不良结果,例如与静态障碍物碰撞或偏离可行驶路径。因此,在模型训练阶段将这些约束作为辅助损失纳入是必不可少的。然而,以可微分的方式整合这些约束并实现模型的端到端训练提出了重大挑战。为此目的经常采用的一种方法是可微分光栅化。例如,Zhou等人[9]展示了一种技术,其中每个轨迹点被转换为光栅化图像,使用可微分的核函数,然后利用图像空间中的障碍物掩码计算损失。然而,这种方法受限于其计算和内存需求,进而限制了输出分辨率(例如,它只允许大的时间间隔和短的规划视野)。为了减轻这些限制,我们提出了一种基于可微分插值的新方法。该方法便于同时计算所有轨迹点的辅助损失。我们以可行驶区域约束为例来阐述我们提出的方法。
代价图构建。我们方法的第一步是将约束转换为可查询的代价图表示。具体来说,对于可行驶区域约束,我们采用广泛认可的欧几里得符号距离场(ESDF)进行代价表示。这个过程包括将不可行驶区域(例如,越野区域)映射到𝐻×𝑊的光栅化二值掩码上,然后对该掩码执行距离变换。我们方法相较于现有方法的一个显著优势是它消除了将轨迹渲染成一系列图像的需求,从而显著降低了计算需求。
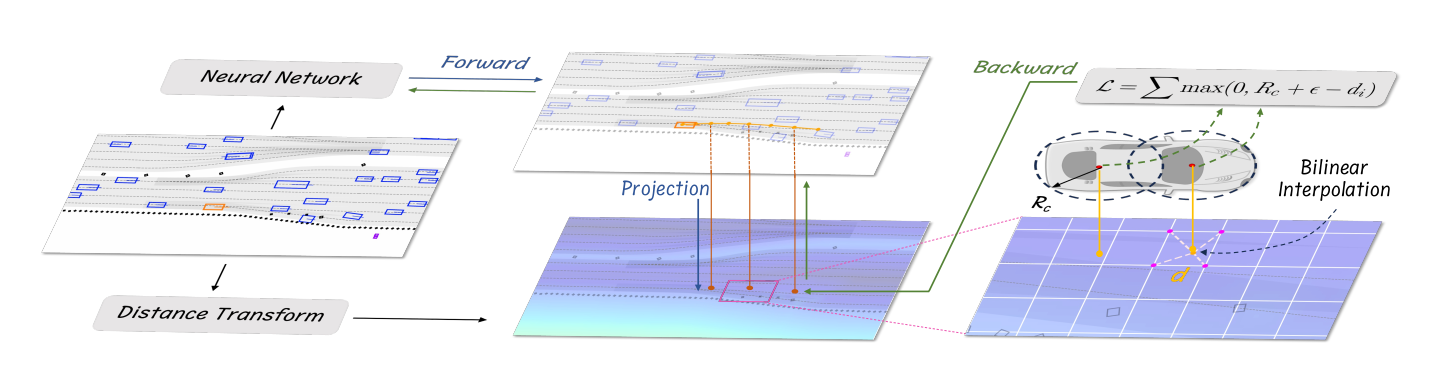
图 2 本文所提辅助损失计算方法示意图 首先,将神经网络输出的轨迹映射至代价图对应的图像空间;随后通过双线性插值__获取代价值,并以此构建损失函数。由于整个计算流程均可微,因此可将各类辅助任务直接融入模型框架,实现端到端训练。
损失计算。根据基于优化的车辆运动规划中的既定方法[49],我们使用𝑁𝑐个覆盖圆来建模车辆的形状。轨迹点决定了这些圆的圆心,这些圆心可以以可微分的方式获得。如图2所示,对于与轨迹点相关联的每个覆盖圆𝑖,我们通过投影和双线性插值获得其有符号距离值𝑑𝑖。为了确保遵守可行驶区域约束,当𝑑𝑖低于
圆的半径𝑅𝑐时,我们对模型施加惩罚。辅助损失为:
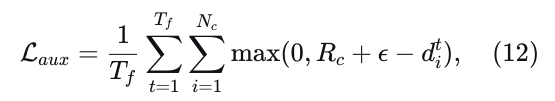
其中𝜖是安全阈值。公式12同样适用于惩罚碰撞,只需对代价图构建稍作修改。
在实践中,𝑑𝑖和𝐿𝑎𝑢𝑥可以使用现代深度学习框架以可微分和高效的方式进行批量计算,如算法1所示。需要注意的是,我们的方法是通用的,不限于基于ESDF的表示。任何允许连续查询的代价表示(如势场)都可以与适当设计的损失函数结合使用。
算法1 可行驶区域损失伪代码
# traj: Trajectory, [B, T, 4] (x, y, cos, sin)
# offset: constant offset of the centers
# sdf: Signed Distance Feild [B, H, W, 1]
# res: rasterization resolution of the SDF
# Rc: radius of the covering circle
# epsilon: safety threshold
def DrivableAreaLoss(traj, sdf, offset, res, Rc, epsilon):
H, W = sdf.shape[1:3]
centers = traj[..., None, :2] + offset * traj[..., None, 2:4]
# 投影
centers_pixel=torch.stack([centers[..., 0]/res, -centers[..., 1]/res], dim=-1)
grid = centers_pixel / torch.tensor([W//2, H//2])
# 批量查询距离
distance = F.sample_grid(sdf.unsqueeze(1), grid, mode="bilinear").squeeze(1)
# 铰链损失
cost = Rc + epsilon - distance
loss_mask = cost > 0
cost.masked_fill_(~loss_mask, 0)
loss = F.l1_loss(cost, torch.zeros_like(cost), reduction="none").sum(-1)
loss = loss.sum() / (loss_mask.sum() + 1e-6)
return loss
E. 对比模仿学习框架
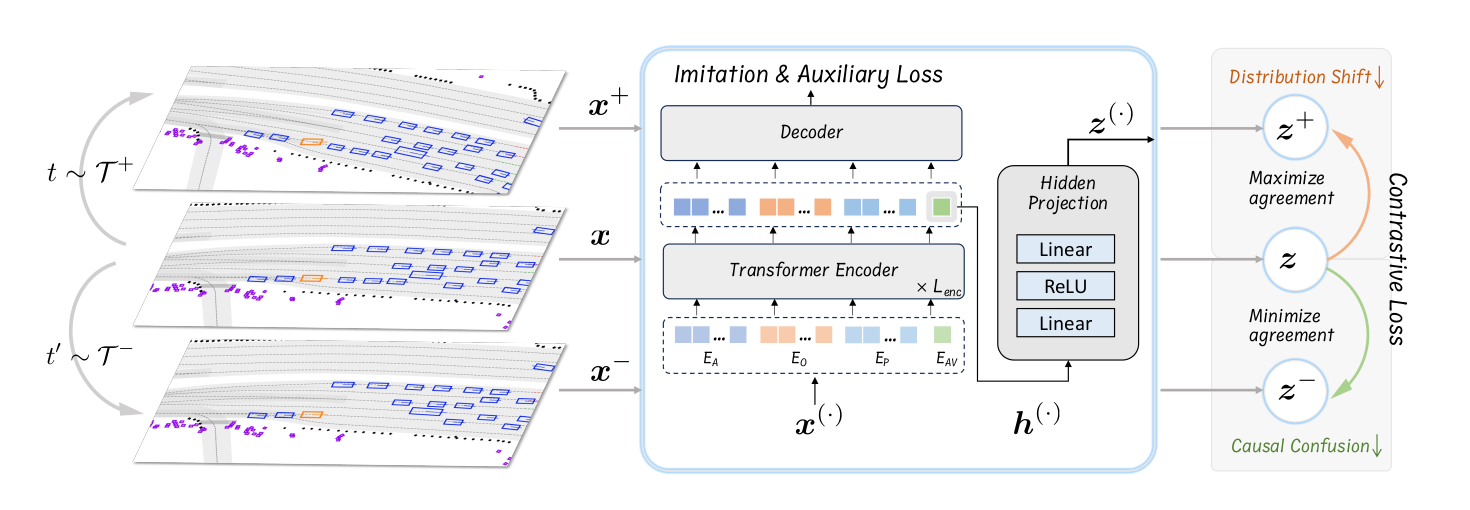
图 3 本文提出的对比模仿学习(CIL)框架示意图_ 对于任意输入数据,分别从不同增广模块中选取两种数据增广算子(t 取自正增广集合__T+、t’取自负增广集合T-,生成正样本与负样本。模型将数据映射得到隐层特征z(.),并基于该特征计算对比损失:拉近原始样本与正样本特征的相似度,同时拉大原始样本与负样本特征的相似度。_
我们引入了对比模仿学习(CIL)框架,旨在以连贯且直接的结构有效解决分布偏移和因果混淆的挑战。如图3所示,CIL框架包含四个基本步骤:
- 给定一个训练场景数据样本,记为𝑥,我们应用正数据增强模块𝑇+和负数据增强模块𝑇−来生成正样本𝑥+和负样本𝑥−。正增强是那些保持原始真值有效性的增强(例如,见图4a),而负增强则改变原始的因果结构,使得原始真值不再适用。
- 如第III-B节详述的Transformer编码器用于推导原始和增强数据样本的潜在表示ℎ(⋅)。随后,这些表示通过一个两层的MLP投影头映射到一个新的空间,表示为
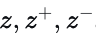 。
。 - 计算三元组对比损失以增强𝑧和𝑧+之间的一致性,同时降低𝑧和𝑧−之间的相似性。
- 最后,对原始和正增强数据样本解码轨迹,并计算模仿损失和辅助损失。
在实践中,我们随机采样一个包含𝑁𝑏𝑠个样本的小批量。每个样本分别经历正增强和负增强,由从集合𝑇+和𝑇−中随机选择的增强器执行。这种增强使总样本数增加到3𝑁𝑏𝑠。所有样本由同一个编码器和投影头处理。令 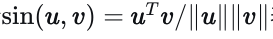 表示归一化后的𝑢和𝑣之间的点积,基于softmax的三元组对比损失[50]定义为:
表示归一化后的𝑢和𝑣之间的点积,基于softmax的三元组对比损失[50]定义为:
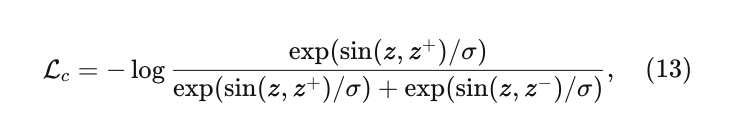
其中𝜎表示温度参数。对比损失在小批量中的所有三元组上计算。除此之外,我们使用未修改的真值轨迹为原始和正增强样本都提供监督。请注意,负增强样本仅用于计算对比损失,因为它们的原始真值在增强后可能无效。总训练损失包含四个部分:模仿损失、预测损失、辅助损失和对比损失,表示为:
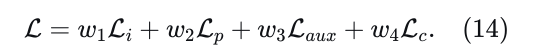
数据增强。数据增强是对比学习工作的关键。虽然基于扰动的增强很普遍,但其他增强策略仍未得到充分探索。在此背景下,我们提出了六个精心设计的增强函数来定义对比任务,图4提供了示例说明。
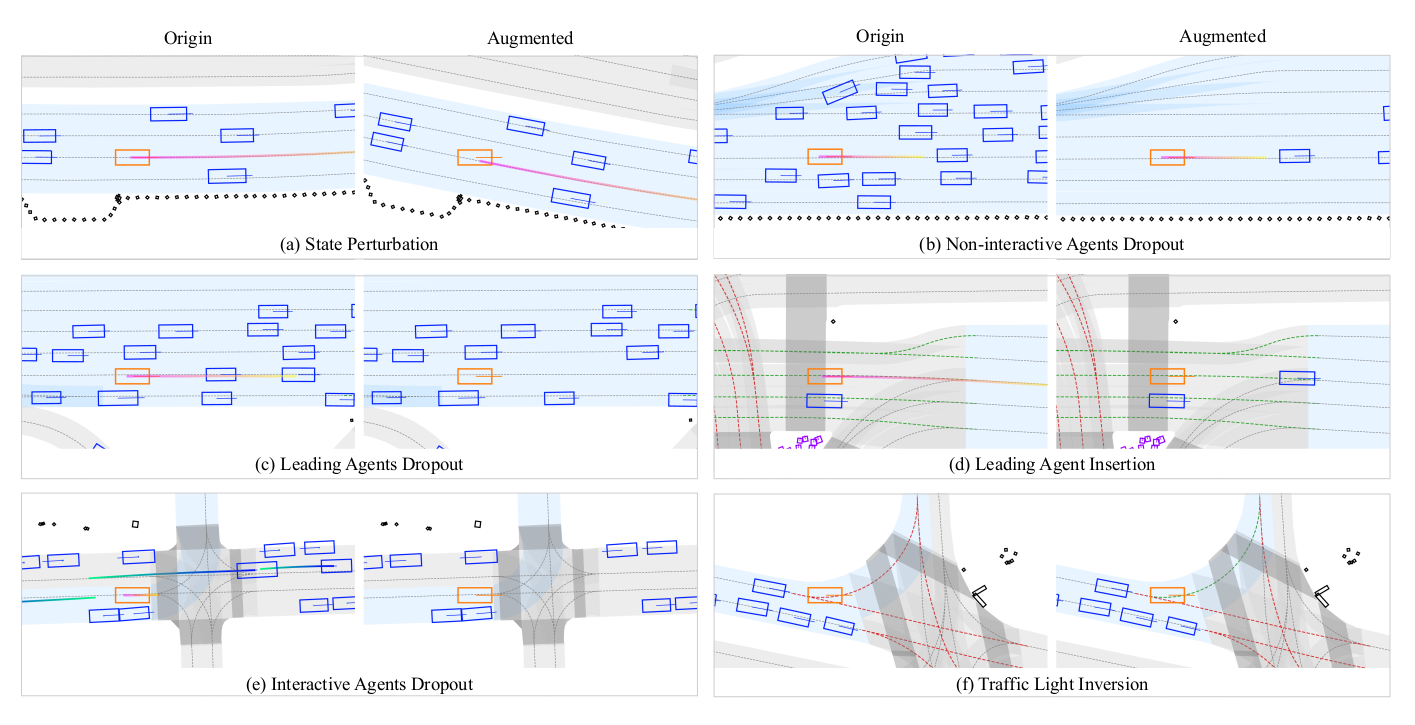
图 4 本文设计的数据增广方案示例_ 每组图示中,左侧为原始场景,右侧为增广后的场景。自动驾驶车辆(自车)以橙色标识,其余交通车辆为蓝色,车道上的虚线代表信号灯状态。其中 (a)、(b) 属于__正样本增广T+,© 至 (f) 为__负样本增广T-。_
(1) 状态扰动 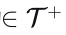 (图4a):对自动驾驶车辆的当前位置、速度、加速度和转向角引入微小的随机扰动。此增强旨在使模型能够学习针对训练分布微小偏差的恢复策略。CIL框架旨在最大化原始和增强样本潜在表示之间的相似性,从而增强模型对误差累积的鲁棒性。
(图4a):对自动驾驶车辆的当前位置、速度、加速度和转向角引入微小的随机扰动。此增强旨在使模型能够学习针对训练分布微小偏差的恢复策略。CIL框架旨在最大化原始和增强样本潜在表示之间的相似性,从而增强模型对误差累积的鲁棒性。
(2) 非交互代理丢弃 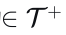 (图4b):从输入场景中移除在不久的将来不会与自动驾驶车辆交互的代理。交互代理通过其未来边界框与自动驾驶车辆轨迹的交集来识别。这种增强防止模型通过模仿非交互代理来学习行为,从而鼓励模型辨别与交互代理的真实因果关系。
(图4b):从输入场景中移除在不久的将来不会与自动驾驶车辆交互的代理。交互代理通过其未来边界框与自动驾驶车辆轨迹的交集来识别。这种增强防止模型通过模仿非交互代理来学习行为,从而鼓励模型辨别与交互代理的真实因果关系。
(3) 前车丢弃 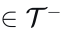 (图4c):移除位于自动驾驶车辆前方的所有代理。特别关注跟驰动态,这是真实驾驶中的常见情况。此增强训练模型学习跟驰行为以防止追尾碰撞。
(图4c):移除位于自动驾驶车辆前方的所有代理。特别关注跟驰动态,这是真实驾驶中的常见情况。此增强训练模型学习跟驰行为以防止追尾碰撞。
(4) 前车插入 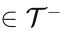 (图4d):在自动驾驶车辆的原始路径中引入一个前车,位置使得自动驾驶车辆的预期轨迹变得无效(例如,会导致碰撞)。插入车辆的运动轨迹数据来自当前小批量中随机选择的代理,以保持数据真实性。
(图4d):在自动驾驶车辆的原始路径中引入一个前车,位置使得自动驾驶车辆的预期轨迹变得无效(例如,会导致碰撞)。插入车辆的运动轨迹数据来自当前小批量中随机选择的代理,以保持数据真实性。
(5) 交互代理丢弃 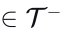 (图4e):排除与自动驾驶车辆有直接或间接交互的代理。交互代理的识别遵循非交互代理丢弃中概述的方法。此增强旨在训练模型应对复杂场景中不太直观的交互,例如无保护左转和变道。
(图4e):排除与自动驾驶车辆有直接或间接交互的代理。交互代理的识别遵循非交互代理丢弃中概述的方法。此增强旨在训练模型应对复杂场景中不太直观的交互,例如无保护左转和变道。
(6) 交通灯反转 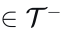 (图4f):在自动驾驶车辆接近由交通灯控制且没有前车的交叉口的场景中,交通灯状态被反转(例如,从红灯变为绿灯)。此功能教导模型遵守基本的交通灯规则。
(图4f):在自动驾驶车辆接近由交通灯控制且没有前车的交叉口的场景中,交通灯状态被反转(例如,从红灯变为绿灯)。此功能教导模型遵守基本的交通灯规则。
这些增强函数设计时带有最小的归纳偏差,以确保广泛的适用性。对比学习任务促进了一种隐式的反馈机制,提供隐式的奖励信号。这些信号强化了对基本驾驶原则的遵守。
F. 规划与后处理
在轨迹规划中,我们的目标是从第III-C节讨论的多模态输出中选择一条确定性的未来轨迹。我们并非仅仅选择最可能的轨迹,而是集成了一个后处理模块作为额外的安全验证机制,如算法2所示。

在提取场景特征后,执行模型以生成多模态规划轨迹  、相关的置信度分数
、相关的置信度分数 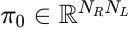 以及代理运动预测
以及代理运动预测 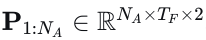 。鉴于𝑇0的轨迹总数𝑁𝑅𝑁𝐿可能很大,初始过滤步骤仅保留按置信度分数排名前𝐾K的轨迹,以简化后续计算。
。鉴于𝑇0的轨迹总数𝑁𝑅𝑁𝐿可能很大,初始过滤步骤仅保留按置信度分数排名前𝐾K的轨迹,以简化后续计算。
遵循[2],对𝑇0执行闭环前向仿真以获得仿真推演 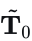 ,利用线性二次型调节器(LQR)进行轨迹跟踪,利用运动学自行车模型进行状态更新。已经注意到[3],基于轨迹的模仿学习可能无法完全考虑底层系统的动力学,导致模型规划轨迹与其实际执行之间存在差异。为了缓解这个问题,我们的评估依赖于仿真推演而非模型的直接输出,从而缩小了差距。
,利用线性二次型调节器(LQR)进行轨迹跟踪,利用运动学自行车模型进行状态更新。已经注意到[3],基于轨迹的模仿学习可能无法完全考虑底层系统的动力学,导致模型规划轨迹与其实际执行之间存在差异。为了缓解这个问题,我们的评估依赖于仿真推演而非模型的直接输出,从而缩小了差距。
随后,一个基于规则的评估器根据诸如进度、驾驶舒适性和交通规则遵守情况等标准为每个仿真推演分配分数𝜋𝑟𝑢𝑙𝑒,与[2]中建立的框架一致。此评估还结合了代理轨迹预测𝑃1:𝑁𝑎来计算碰撞时间(TTC)指标,排除导致责任碰撞的推演。最终得分将初始的基于学习的置信度分数𝜋0和基于规则的分数𝜋𝑟𝑢𝑙𝑒通过以下方程结合:
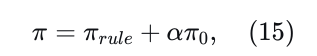
其中𝛼是一个固定的权重因子。最终轨迹𝜏∗的选择基于最大化𝜋。与[30]、[31]中描述的后处理步骤(通常使用优化器来细化轨迹)不同,我们的后处理模块仅充当轨迹选择器,保持原始规划轨迹不变。我们将后处理步骤视为将人类偏好或控制注入黑盒神经网络的一种代理,承认其当前的局限性,并提供一个下限安全保障,以减轻灾难性事故的风险。
IV. 实验
A. 实验设置
nuPlan。我们的模型使用nuPlan数据集[14]进行训练和评估。该数据集包含1300小时的真实世界驾驶数据,涵盖多达75种标记的场景类型。它通过其相关的闭环仿真框架引入了第一个公开可用的大规模自动驾驶规划基准。每次仿真以10Hz的频率进行15秒的推演,在此期间自动驾驶车辆由规划器和跟踪器管理。这些仿真中的交通代理以两种不同的方式控制:非反应式,其中代理的状态基于记录的轨迹确定;以及反应式,其中代理由智能驾驶员模型[51]规划器控制。
基准与指标。对于所有实验,我们使用从所有场景类型中采样的1M帧的标准训练分割。对于评估,我们使用Val14基准[2],其中包含来自nuPlan规划挑战中指定的14种场景类型的最多100个场景,总共有1090个场景(我们过滤掉了在反应式仿真中初始化为失败的少数场景)。
NuPlan采用三个主要的评估指标:开环分数(OLS)、非反应式闭环分数(NR-分数)和反应式闭环分数(R-分数)。鉴于先前的研究已经证明开环预测性能与闭环规划效果之间的相关性很小,本文我们只关注闭环性能。闭环分数计算为几个关键指标的加权平均值:
(1) 无自动驾驶车辆责任碰撞:当自动驾驶车辆(AV)的边界框与其他代理或静态障碍物的边界框相交时,即识别为碰撞。然而,由其他代理引发的碰撞,如追尾碰撞,不予考虑。
(2) 碰撞时间(TTC)在界限内:TTC定义为如果AV和其他实体继续沿当前轨迹和速度行驶,它们将发生碰撞所需的时间。该指标要求TTC超过指定阈值。
(3) 可行驶区域合规性:该标准要求AV始终保持在可行驶道路边界内,确保遵守指定的行驶区域。
(4) 舒适性:通过检查AV的纵向和横向加速度及加加速度、横摆率和加速度的最小值和最大值来量化AV的舒适性。这些参数根据从经验数据得出的既定阈值进行评估。
(5) 进度:通过将AV沿其规划路线行驶的距离与专家驾驶员行驶的距离进行比较来评估进度,以百分比表示。
(6) 限速合规性:该指标检查AV的速度是否在其行驶道路的法律限速范围内。
(7) 行驶方向合规性:该指标惩罚偏离正确行驶方向的行为,特别是AV被发现逆向行驶的事件。
关于指标的更详细描述和计算可以在[52]中找到。我们使用非反应式闭环分数(如未指定,记为score)作为我们的主要整体性能评估指标。
基线。在本研究中,我们使用nuPlan基准对PLUTO与现有和最新(SOTA)方法进行比较分析,以证明我们提出的方法的有效性。比较的基线分为三类:基于规则的、纯学习的和混合方法。基于规则的方法依赖手工设计的规则,不涉及学习过程。相比之下,纯学习方法使用神经网络直接生成最终规划轨迹,省略任何细化或后处理阶段。而混合方法包括一个后处理模块来细化或调整基于学习技术的结果。基准方法概述如下:
(1) 智能驾驶员模型(IDM)[51]:这是一个经典的、时间连续的跟驰模型,广泛用于交通仿真。我们使用文献[14]中引用的官方实现。
(2) PDM-Closed [2]:被认定为2023年nuPlan规划挑战赛的获胜方案,该方法通过整合具有不同超参数的IDM策略生成一系列方案,然后通过基于规则的评分系统选择最优方案。尽管其简单,但已被证明在实践中有效,并且目前拥有SOTA性能。我们使用了其开源实现。
(3) PDM-Open [2]:该方法围绕一个以中心线为条件的预测模型,并使用MLP,通过可用的开源版本实现。
(4) GC-PGP [53]:一个专注于目标条件车道图遍历的预测模型。
(5) RasterModel:一个基于CNN的模型,将输入场景解释为多通道图像,如文献[14]所述。
(6) UrbanDriver [28]:一个基于学习的规划器,利用基于PointNet的多段线编码器和Transformer处理向量化输入。该模型通过其开环重新实现进行评估,在训练阶段加入了历史数据扰动。
(7) PlanTF [3]:一个强大的纯模仿学习基线,利用Transformer架构探索模仿学习中的高效设计。尽管其简单,但它是当前纯学习模型中的SOTA。
(8) GameFormer [31]:基于类似DETR的、基于层级博弈的交互式规划和预测建模,该模型的输出作为初始估计,随后通过非线性优化器进行细化。使用了官方的开源代码进行实现。
(9) PlanTF-H [3]:该方法通过集成第III-F节所述的后处理模块来增强PlanTF,从而将其转变为混合方法。
B. 实现细节
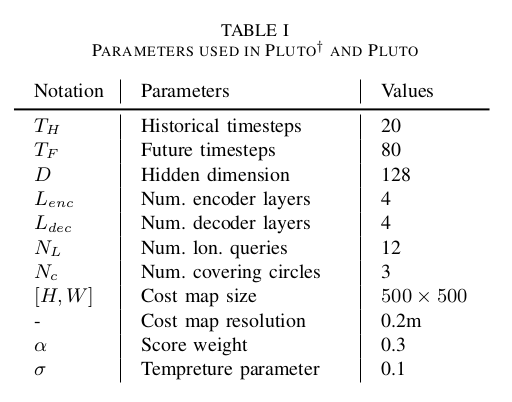
我们提出了两个变体PLUTO和PLUTO,唯一的区别是PLUTO省略了后处理步骤。特征提取集中在自动驾驶车辆周围120米半径内的地图元素和代理。我们遵循nuPlan挑战赛,将规划和历史数据视野分别设置为8秒和2秒。该模型包含了旨在惩罚越野驾驶和碰撞的辅助任务。使用4块RTX3090 GPU进行训练,批量大小为128,共25个epoch。我们使用了AdamW优化器,权重衰减为1𝑒−4。学习率在前三个epoch线性增加到1𝑒−3,然后在剩余epoch中遵循余弦衰减模式。损失权重𝑤1−4统一赋值为1.0。使用CIL的训练在45小时内完成,不使用CIL则在22小时内完成。其他参数设置的详细信息见表I。
V. 结果与讨论
A. 与最新技术的比较
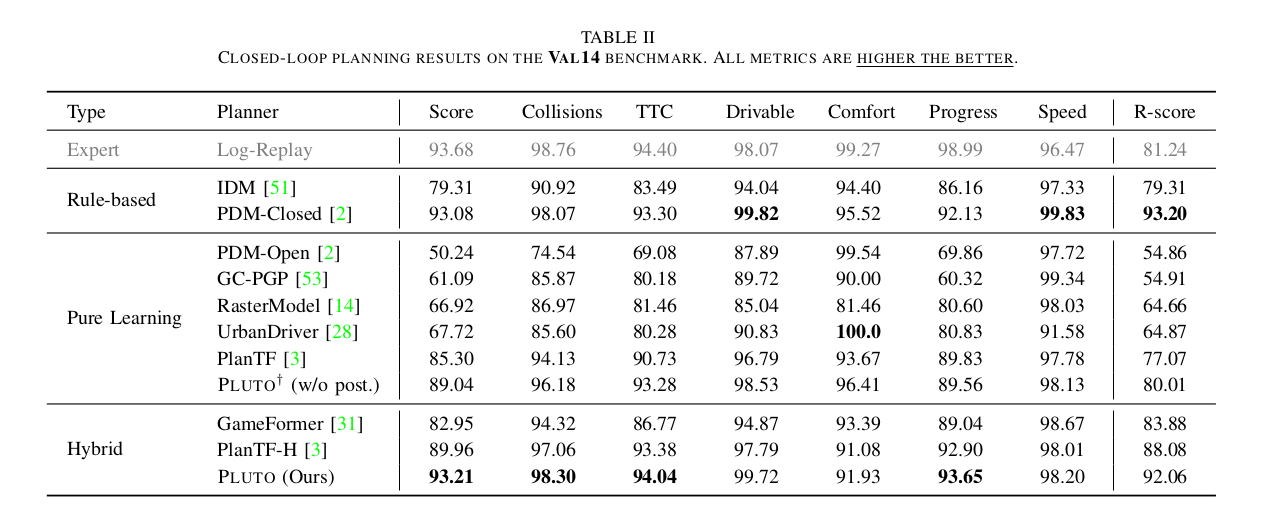
在Val14基准上与其他方法的比较分析详见表II。最初,我们纯学习的变体PLUTO超越了所有先前的纯学习基线。显著的是,与领先模型PlanTF相比,PLUTO在几乎所有评估指标上都表现出显著改进,特别是在与安全相关的指标上观察到增强(例如,碰撞从94.13提高到96.18,TTC从90.73提高到93.28,可行驶性从96.79提高到98.53)。这些结果凸显了仅基于模仿的模型的局限性,并强调了纳入辅助损失和CIL框架设计的有效性。
此外,我们的混合模型PLUTO在所有基线中获得了最高分,首次超越了当前最先进的基于规则的模型PDM-Closed。这一成就强调了基于学习方法在规划中的潜力。值得注意的是,我们方法的性能与日志回放专家非常接近(93.68对比93.21),表明朝着专家级规划迈出了重要一步。
除了定量结果,我们的方法在驾驶行为方面也比PDM-Closed具有优势。鉴于PDM-Closed主要关注速度规划,其横向机动能力有些受限,限制了其执行变道动作的能力。相比之下,得益于我们模型的基于查询的架构,PLUTO被设计为同时考虑纵向和横向运动。这种能力将在定性结果部分的案例研究中进一步说明。
B. 定性结果
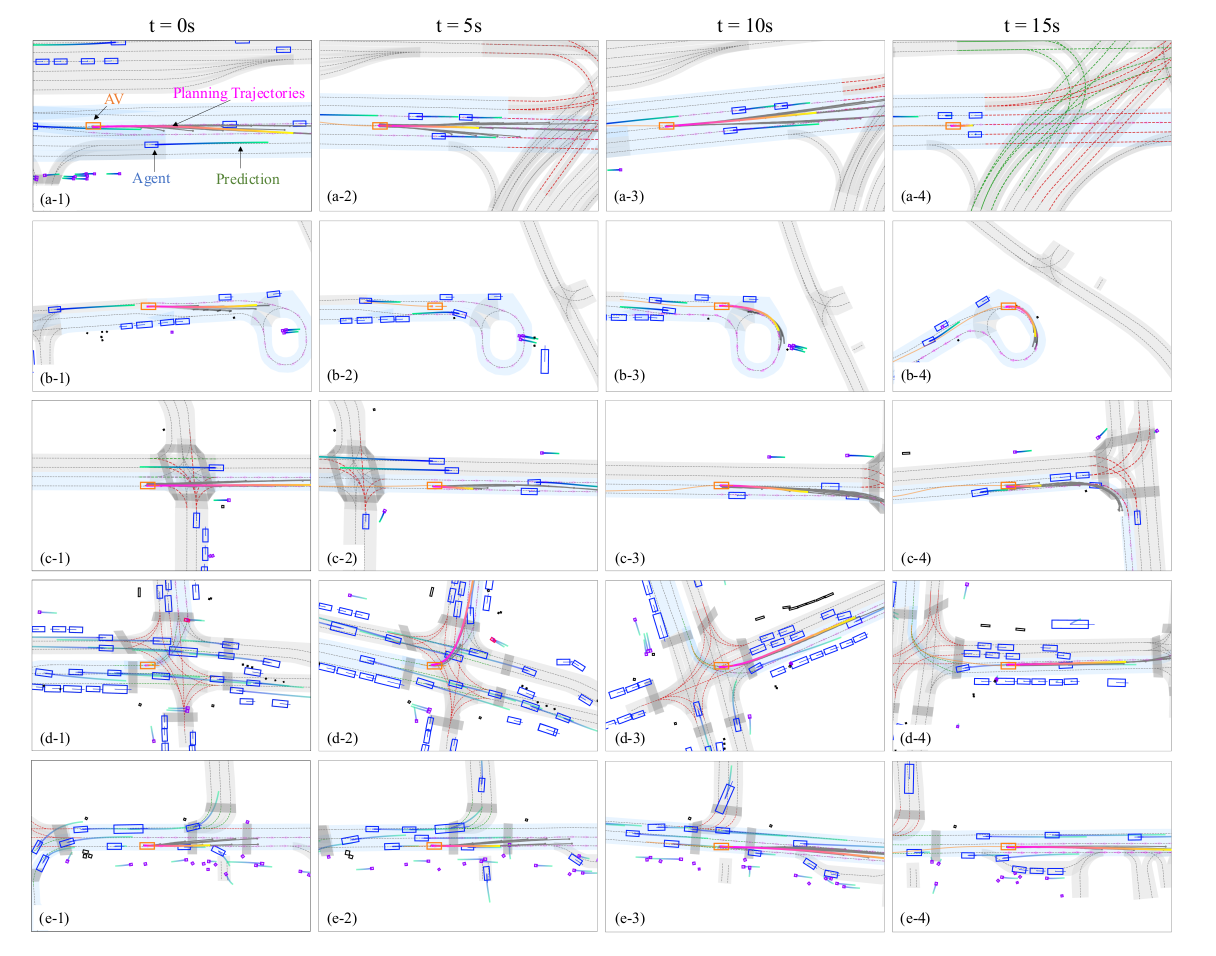
图 5 测试集中五类典型场景的闭环规划可视化结果_ 每组场景(对应图中每一行)时长为 15 秒,每隔 5 秒截取一帧画面,共 4 帧。紫色虚线箭头代表__参考线__,浅蓝色车道区域表示全局行驶路线规划,其余图例说明详见子图 a-1。如需观看更直观的动态视频,可访问项目官网。_
图5展示了来自nuPlan测试集的选定场景,通过展示多样化、类人的行为,展示了我们框架在复杂的交互式城市驾驶情境中的稳健性能。场景详述如下:
(a) 自动驾驶车辆导航到相邻的空车道以提高效率,随后在交叉口的红灯处停车。序列a-2和a-3的观察显示,PLUTO同时评估了针对不同行为的多个潜在计划(用灰色候选轨迹表示),增强了规划过程的灵活性和与人类驾驶的相似性。
(b) 在一个需要AV绕过环岛的场景中,其路径被一辆停放的车辆收窄。我们的规划系统巧妙地绕过此障碍物,同时在狭窄空间中让行迎面而来的车辆,展示了我们的方法在处理静态障碍物和与其他车辆交互方面的能力。
© 遇到车道内的静止车辆,AV执行左变道以绕过障碍物,随后返回原车道以遵守预定路线。此场景强调了规划器的动态决策能力及其在路线遵守和道路拓扑理解方面的熟练程度。
(d) 在繁忙交通中进行左转操作时,AV耐心等待适当时机完成转弯,展示了我们的方法在密集交通条件下导航交叉口的有效性。
(e) 跟随较慢车辆后,AV选择加速超车,展示了与自然人类驾驶高度一致的行为,并突显了我们提出方法的适应性。
总之,PLUTO展示了通过简单的速度规划方法(例如PDM-Closed)无法实现的先进且多样化的驾驶行为。它能够执行自然的变道、绕过障碍物并在交互场景中动态修改决策,标志着朝着实用基于学习规划迈出了重大进展。如需更多见解,包括视频,我们建议感兴趣的读者访问我们的项目网站。
C. 消融研究
对于所有消融研究,我们在nuPlan的一个子集(与Val14基准不重叠)上进行评估,该子集包含14种场景类型中每种类型的20个场景。
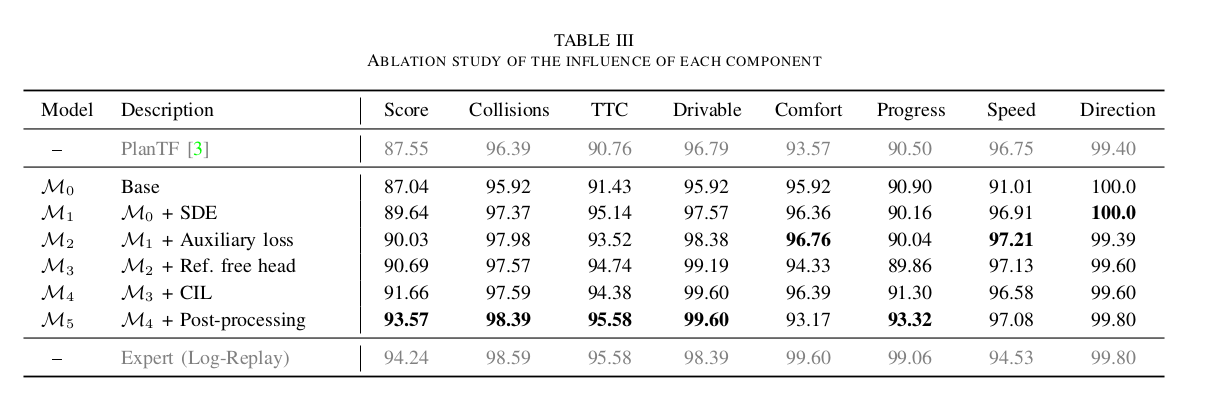
每个组件的影响。表III展示了从基础模型到表现最佳的基于学习的规划器的轨迹。初始模型记为𝑀0,基于第III-B和III-C节所述的架构构建,仅使用模仿损失进行训练。𝑀0表现与先前SOTA纯学习方法PlanTF相当,我们将这一成就归因于增强的基于查询的架构。
在𝑀1中引入状态丢弃编码器(SDE),该编码器在训练期间随机掩码自动驾驶车辆的运动学状态,以防止通过状态外推生成捷径轨迹,结果在几乎所有指标上都比𝑀0M0有显著改善。
𝑀2加入了辅助损失,旨在惩罚偏离可行驶区域和碰撞。这一修改导致碰撞指标(从97.37提高到97.98)和可行驶性指标(从95.92提高到98.38)的改善。我们想强调的是,尽管𝑀2和𝑀1之间的总分差异看似微小,但它们实际性能的差距是显著的。我们建议感兴趣的读者访问项目网站查看模型消融结果。𝑀3模型强调了整合无参考线解码头的重要性,以有效处理参考线缺失的场景,例如停车场。
此外,𝑀4使用提出的对比模仿学习框架进行训练,性能从90.69显著提升至91.66。这一改进值得注意,特别是因为它已接近专家的表现。
最终,𝑀5获得了最佳整体性能,尽管以舒适性指标的小幅折衷为代价。这种折衷源于安全检查器触发的紧急停车增加,从而提高了安全相关指标。
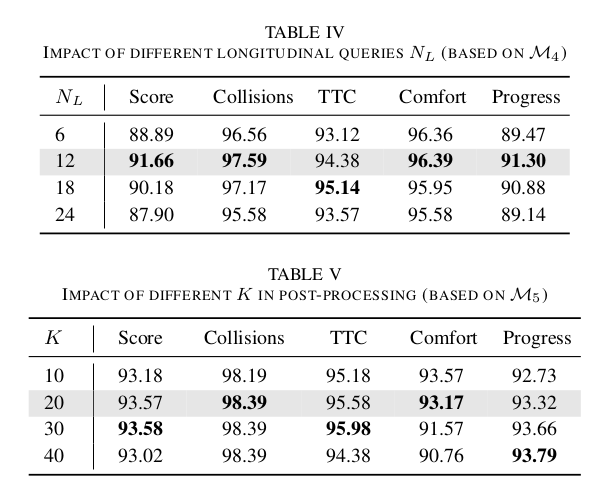
纵向查询数量。表IV展示了与不同数量的纵向查询𝑁𝐿(使用模型𝑀4)相关的结果。结果表明,在四个测试变体中,𝑁𝐿=12的设置产生了最有利的性能。这表明需要适当数量的查询来覆盖8秒规划视野内的所有纵向行为。超过此点增加𝑁𝐿NL会降低性能。这种下降可能归因于𝑁𝐿=12足以捕捉多样化的行为;额外的查询变得冗余,可能增加训练难度。
粗选中的Top-K。在规划周期中,PLUTO总共生成𝑁𝑅×𝑁𝐿条轨迹。经验证据表明,置信度分数低的轨迹往往质量较差。因此,采用基于置信度分数的初步选择过程有利于消除此类轨迹,从而加速随后的后处理。如表V所示,设置𝐾=20是合适的。
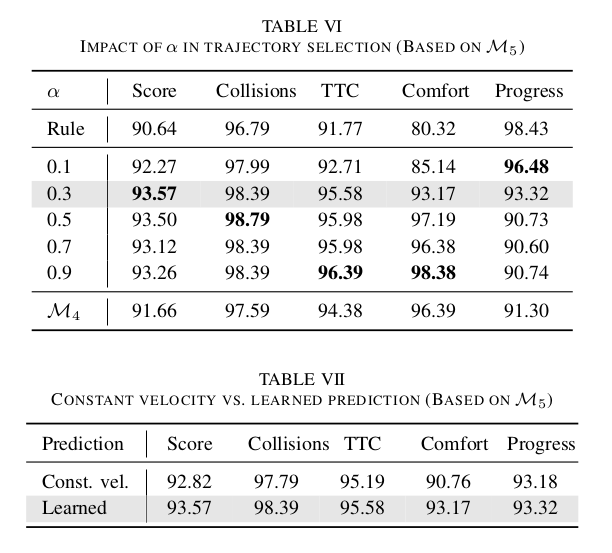
基于学习的分数的权重。如公式15所示,最终分数来自基于规则分数和基于学习分数的加权组合。本研究检验了权重参数𝛼的影响,结果详见表VI。首先,观察到与仅依赖基于规则的分数(即𝛼=0)相比,纳入基于学习的分数显著提高了性能。基于规则分数的局限性在于其手工设计的性质,可能无法准确表示所有可能的场景,而基于学习的分数通过动态适应输入特征提供了更好的泛化能力。此外,组合方法优于纯基于学习的分数(𝑀4),表明当前的模型虽然先进,但仍然受益于纳入基于规则的组件作为一种安全保障。基于最优性能,选择𝛼=0.3作为默认设置。
预测方法。在本研究中,我们将学习到的预测模型的性能与PDM-Closed中使用的恒定速度预测进行了对比,结果见表VII。
显然,使用学习到的预测进行规划比简单的恒定速度预测产生更好的结果,因为它可以更准确地辨别代理的行为。尽管我们的预测模型仅为每个代理生成单模态轨迹,但在实践中效果良好。
VI. 结论
在本研究中,我们介绍了PLUTO,一个开创性的数据驱动规划框架,扩展了模仿学习在自动驾驶领域的能力。我们在模型架构、数据增强和学习框架方面提出了创新的解决方案,有效解决了模仿学习中长期存在的挑战。基于查询的模型架构为规划器提供了在纵向和横向维度上具备适应性驾驶行为的能力。我们基于可微分插值计算辅助损失的新方法,为将约束整合到模型中提供了一种新途径。此外,对比模仿学习框架结合一套先进的数据增强技术,增强了对期望行为的获取和对内在交互的理解。使用真实驾驶数据集的实验评估表明,我们的方法为该领域的闭环性能设立了新的基准。值得注意的是,PLUTO超越了先前表现最佳的基于规则的规划器,在自动驾驶研究中确立了一个重大突破。
局限性与未来工作。在我们的方法中,我们为每个动态代理预测单条轨迹。这种方法在实践中产生了令人满意的结果;然而,生成有意义的联合多模态预测并将其有效地整合到规划策略中是未来研究的重要领域。后处理模块的添加已被证明能有效提高整体性能。然而,它无法处理所有生成的轨迹都不可用的场景。将后处理功能转变为直接影响轨迹生成的中间角色可能是一种更有利的策略。
参考文献
[1] S. Teng, X. Hu, P. Deng, B. Li, Y. Li, Y. Ai, D. Yang, L. Li, Z. Xuanyuan, F. Zhu et al., “Motion planning for autonomous driving: The state of the art and future perspectives,” IEEE Transactions on Intelligent Vehicles, 2023.
[2] D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta, “Parting with misconceptions about learning-based vehicle motion planning,” in Conference on Robot Learning (CoRL), 2023.
[3] J. Cheng, Y. Chen, X. Mei, B. Yang, B. Li, and M. Liu, “Rethinking imitation-based planner for autonomous driving,” in International Conference on Robotics and Automation (ICRA), 2024.
[4] J. Cheng, R. Xin, S. Wang, and M. Liu, “Mpnp: Multi-policy neural planner for urban driving,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 10 549-10 554.
[5] M. Bansal, A. Krizhevsky, and A. Ogale, “Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst,” arXiv preprint arXiv:1812.03079, 2018.
[6] U. Muller, J. Ben, E. Cosatto, B. Flepp, and Y. Cun, “Off-road obstacle avoidance through end-to-end learning,” Advances in neural information processing systems, vol. 18, 2005.
[7] D. Wang, C. Devin, Q.-Z. Cai, P. Krahenbuhl, and T. Darrell, “Monocular plan view networks for autonomous driving,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 2876-2883.
[8] C. Wen, J. Lin, T. Darrell, D. Jayaraman, and Y. Gao, “Fighting copycat agents in behavioral cloning from observation histories,” Advances in Neural Information Processing Systems, vol. 33, pp. 2564-2575, 2020.
[9] J. Zhou, R. Wang, X. Liu, Y. Jiang, S. Jiang, J. Tao, J. Miao, and S. Song, “Exploring imitation learning for autonomous driving with feedback synthesizer and differentiable rasterization,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 1450-1457.
[10] P. De Haan, D. Jayaraman, and S. Levine, “Causal confusion in imitation learning,” Advances in neural information processing systems, vol. 32, 2019.
[11] L. Cultrera, F. Becattini, L. Seidenari, P. Pala, and A. Del Bimbo, “Addressing limitations of state-aware imitation learning for autonomous driving,” IEEE Transactions on Intelligent Vehicles, 2023.
[12] Y. Lu, J. Fu, G. Tucker, X. Pan, E. Bronstein, B. Roelofs, B. Sapp, B. White, A. Faust, S. Whiteson et al., “Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios,” NeurIPS 2022 Workshop on Machine Learning for Autonomous Driving, 2022.
[13] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597-1607.
[14] H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles,” Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) Workshops, 2021.
[15] L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,” arXiv preprint arXiv:2306.16927, 2023.
[16] D. Chen, B. Zhou, V. Koltun, and P. Krahenbuhl, “Learning by cheating,” in Conference on Robot Learning. PMLR, 2020, pp. 66-75.
[17] F. Codevilla, E. Santana, A. M. López, and A. Gaidon, “Exploring the limitations of behavior cloning for autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9329-9338.
[18] K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for autonomous driving,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
[19] K. Chitta, A. Prakash, and A. Geiger, “Neat: Neural attention fields for end-to-end autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 793-15 802.
[20] H. Shao, L. Wang, R. Chen, H. Li, and Y. Liu, “Safety-enhanced autonomous driving using interpretable sensor fusion transformer,” in Conference on Robot Learning. PMLR, 2023, pp. 726-737.
[21] X. Jia, P. Wu, L. Chen, J. Xie, C. He, J. Yan, and H. Li, “Think twice before driving: Towards scalable decoders for end-to-end autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21 983-21 994.
[22] D. Chen and P. Krahenbuhl, “Learning from all vehicles,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 222-17 231.
[23] Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang et al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 853-17 862.
[24] B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” arXiv preprint arXiv:2303.12077, 2023.
[25] S. Hu, L. Chen, P. Wu, H. Li, J. Yan, and D. Tao, “St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning,” in European Conference on Computer Vision. Springer, 2022, pp. 533-549.
[26] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “Carla: An open urban driving simulator,” in Conference on robot learning. PMLR, 2017, pp. 1-16.
[27] M. Vitelli, Y. Chang, Y. Ye, A. Ferreira, M. Wolczyk, B. Osinski, M. Niendorf, H. Grimmett, Q. Huang, A. Jain et al., “Safetynet: Safe planning for real-world self-driving vehicles using machine-learned policies,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 897-904.
[28] O. Scheel, L. Bergamini, M. Wolczyk, B. Osinski, and P. Ondruska, "Urban driver: Learning to drive from real-world demonstrations using
[29] S. Pini, C. S. Perone, A. Ahuja, A. S. R. Ferreira, M. Niendorf, and S. Zagoruyko, “Safe real-world autonomous driving by learning to predict and plan with a mixture of experts,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 10 069-10 075.
[30] Z. Huang, H. Liu, J. Wu, and C. Lv, “Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving,” IEEE transactions on neural networks and learning systems, 2023.
[31] Z. Huang, H. Liu, and C. Lv, “Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3903-3913.
[32] S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 627-635.
[33] R. Hadsell, S. Chopra, and Y. LeCun, “Dimensionality reduction by learning an invariant mapping,” in 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), vol. 2. IEEE, 2006, pp. 1735-1742.
[34] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729-9738.
[35] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748-8763.
[36] Y. Liu, Q. Yan, and A. Alahi, “Social nce: Contrastive learning of socially-aware motion representations,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 118-15 129.
[37] M. Halawa, O. Hellwich, and P. Bideau, “Action-based contrastive learning for trajectory prediction,” in European Conference on Computer Vision. Springer, 2022, pp. 143-159.
[38] Y. Wang, P. Zhang, L. Bai, and J. Xue, “Fend: A future enhanced distribution-aware contrastive learning framework for long-tail trajectory prediction,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1400-1409.
[39] J. Cheng, X. Mei, and M. Liu, “Forecast-MAE: Self-supervised pretraining for motion forecasting with masked autoencoders,” Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023.
[40] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652-660.
[41] Z. Zhou, J. Wang, Y.-H. Li, and Y.-K. Huang, “Query-centric trajectory prediction,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 863-17 873.
[42] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
[43] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213-229.
[44] Y. Liu, J. Zhang, L. Fang, Q. Jiang, and B. Zhou, “Multimodal motion prediction with stacked transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7577-7586.
[45] J. Ngiam, B. Caine, V. Vasudevan, Z. Zhang, H.-T. L. Chiang, J. Ling, R. Roelofs, A. Bewley, C. Liu, A. Venugopal et al., “Scene transformer: A unified architecture for predicting multiple agent trajectories,” arXiv preprint arXiv:2106.08417, 2021.
[46] R. J. Williams and D. Zipser, “A learning algorithm for continually running fully recurrent neural networks,” Neural computation, vol. 1, no. 2, pp. 270-280, 1989.
[47] R. Girshick, “Fast r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1440-1448.
[48] S. Shi, L. Jiang, D. Dai, and B. Schiele, “Motion transformer with global intention localization and local movement refinement,” Advances in Neural Information Processing Systems, vol. 35, pp. 6531-6543, 2022.
[49] J. Cheng, Y. Chen, Q. Zhang, L. Gan, C. Liu, and M. Liu, “Real-time trajectory planning for autonomous driving with gaussian process and incremental refinement,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 8999-9005.
[50] J. Goldberger, G. E. Hinton, S. Roweis, and R. R. Salakhutdinov, “Neighbourhood components analysis,” Advances in neural information processing systems, vol. 17, 2004.
[51] M. Treiber, A. Hennecke, and D. Helbing, “Congested traffic states in empirical observations and microscopic simulations,” Physical review E, vol. 62, no. 2, p. 1805, 2000.
[52] Motional. nuplan metrics. [Online]. Available: https://nuplan-devkit.readthedocs.io/en/latest/metrics_description.html
[53] M. Hallgarten, M. Stoll, and A. Zell, “From prediction to planning with goal conditioned lane graph traversals,” arXiv preprint arXiv:2302.07753, 2023.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)