基于 RAG 完整项目实践 —— 智能客服
这篇文章将从头到尾展示如何通过 RAG 技术 + Chat Model 来实现智能客服(或者其他能力的AI),一步一步拆解每一个核心的实现技术。
完成项目代码开源在 Gitee
一 )需求分析
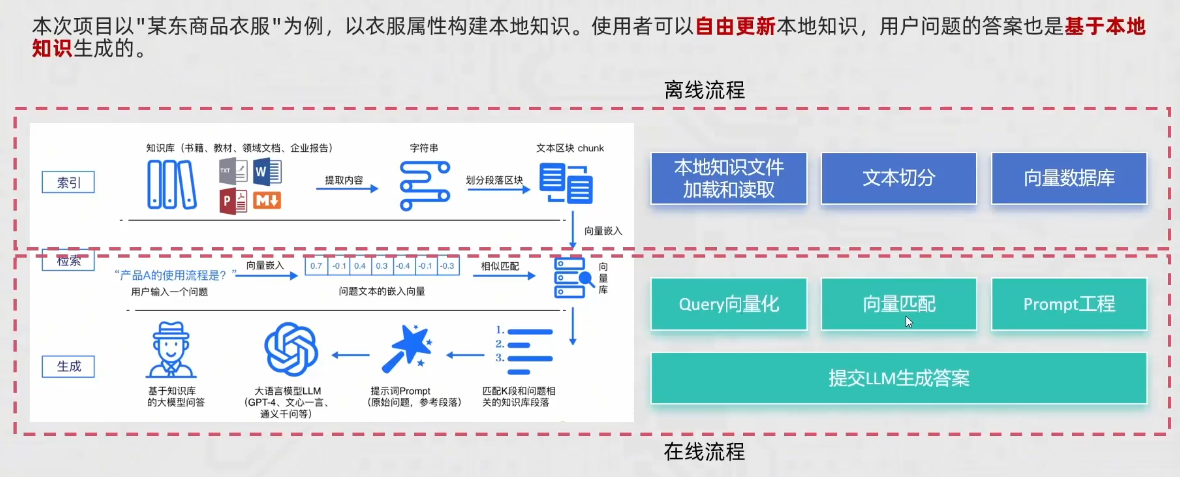
这次的项目就以某商品的衣服智能客服为例进行构建,该项目分为两大部分,在线流程和离线流程部分。离线流程需要实现相对应本地数据库的构建,即构建向量数据库;在线部分实现的是人和AI之间的交互,AI需要根据用户提问在本地知识库中检索相关文档进行回答用户问题。离线部分的本地数据库需要能够自由更新,在线部分的AI需要基于本地知识生成答案。
二 )离线流程
这里需要实现本地数据库的存储,不和以往的数据库类似,这里采用向量数据库存储,好处就是当句子都被向量化之后,语义之间的比配(检索)就只需要计算两个向量之间的余弦相似度就可以完成匹配,这样在后期抽取用户相应知识的时候就比较方便了。
2.1 余弦余弦相似度
向量化的核心是把句子变成一串数字(向量),数字代表语义,意思越像,数字越接近。例如:
-
忘记密码怎么办?→
[0.98, 0.02, 0.05] -
我密码忘了怎么弄?→
[0.97, 0.03, 0.04] -
如何重置密码?→
[0.96, 0.04, 0.03] -
怎么下单购买?→
[0.05, 0.99, 0.02]
意思一样,所转化为的向量(数字)几乎一样,但是意思不同,向量(数字)几乎完全不同。计算公式如下
![]()
![]()
结果范围是 [-1, 1] 。1:完全一样;0:完全无关;-1:完全相反。
向量数据库存储客服知识库,其核心优势就在于将自然语言转换为数值化向量,通过计算向量间的余弦相似度实现语义级的检索。相较于传统数据库依赖关键词精确匹配的方式,向量数据库能够理解用户问句的真实意图,能够大幅提升智能客服问答的准确率与用户体验。
2.2 数据向量化
在上面我们知道了当文本被向量化后,可以很好通过语义进行抽取相关资料,但是文本如何被向量化呢?向量化的时候又怎么保证相同语义的数据被向量化后 “靠的近” 呢?
关键技术点就在Embedding模型 ,在这里不详细介绍Embedding模型具体的原理,只是较为形象的讲解一下其主要实现的效果。
我们可以把词向量模型(Embedding 模型)理解成一个翻译机:
输入Embedding 模型:一句话
Embedding 模型输出:一串固定长度的数字(比如 384 维、768 维、1024 维)
这个过程叫文本嵌入(Text Embedding);具体步骤如下:
“忘记密码怎么办”
→ 1 分词:忘记 / 密码 / 怎么办
→ 2 每个词得到向量
→ 3 整句合成一个向量:
[0.12, 0.55, 0.89, 0.21, ...] (共384个数字)所以数据向量化这个过程我们通过 Embedding 模型来实现,那 Embedding 模型又是如何被训练的呢?
因为Embedding 模型训练的时候,就强制让 “意思相近” 的文本向量靠近。该模型的训练目标就是“相似的句子,向量距离近;不相似的句子,距离远”。
训练时用这种数据:
相似句对:
- 忘记密码怎么办
- 密码忘了怎么找回→ 向量拉近
不相似句对:
- 忘记密码怎么办
- 怎么下单支付→ 向量推开
模型通过大量数据学习,自动把语义信息编码到数字里。
具体的 Embedding 模型选择也有很多种,不同的 Embedding 模型有不同的输出维度,输出维度越高的模型其语义考察的会更加丰富,更加准确。
Embedding 模型的使用:
import os
from pathlib import Path
import requests
from sentence_transformers import SentenceTransformer
mirror_endpoint = "https://hf-mirror.com"
model_name = "BAAI/bge-small-zh-v1.5"
model_dir = Path(".hf-local-models") / "BAAI__bge-small-zh-v1.5"
required_files = [
"1_Pooling/config.json",
"config.json",
"config_sentence_transformers.json",
"model.safetensors",
"modules.json",
"sentence_bert_config.json",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt",
]
model_dir.mkdir(parents=True, exist_ok=True)
for relative_path in required_files:
local_path = model_dir / relative_path
if local_path.exists() and local_path.stat().st_size > 0:
continue
local_path.parent.mkdir(parents=True, exist_ok=True)
url = f"{mirror_endpoint}/{model_name}/resolve/main/{relative_path}"
print(f"downloading: {relative_path}")
with requests.get(url, stream=True, timeout=(30, 300)) as response:
response.raise_for_status()
with open(local_path, "wb") as file:
for chunk in response.iter_content(chunk_size=1024 * 1024):
if chunk:
file.write(chunk)
# 加载本地模型
model = SentenceTransformer(str(model_dir))
text = "我遇到了404的错误怎么办"
embedding = model.encode(text)
print(embedding)
print(f"导入成功!向量维度:{len(embedding)}") # 输出 512 即正常这里通过 huggingface 的镜像网站下载 BAAI/bge-small-zh-v1.5 这个词嵌入模型,这个模型是北京智源研究院(BAAI)推出的轻量级、高性能中文文本嵌入(Embedding)模型,专为中文语义检索、RAG、智能客服等场景设计,是目前中文小模型里 “速度与精度” 平衡最好的选择之一。
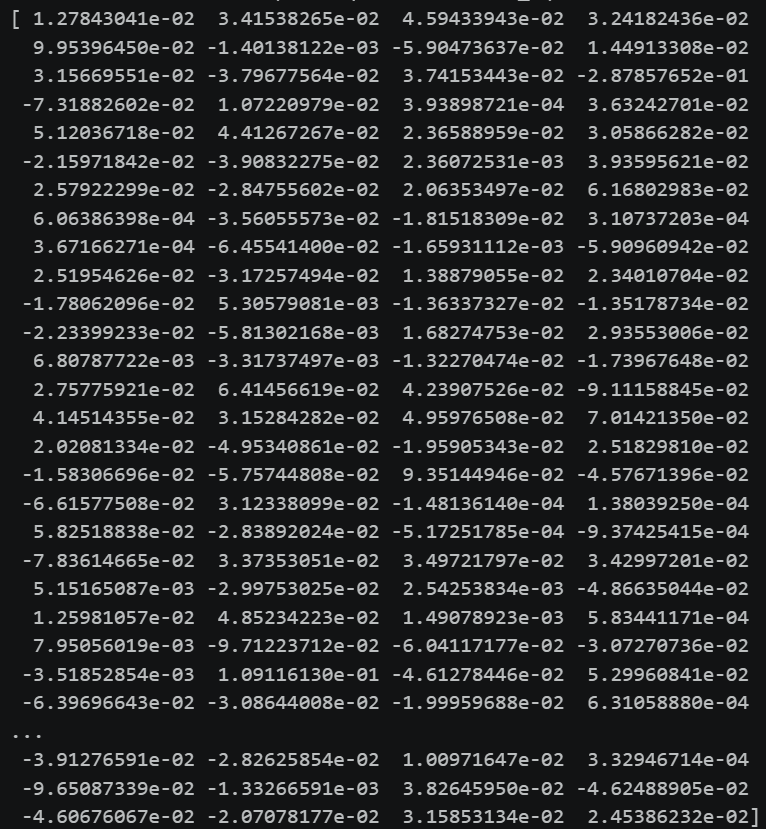
最后 text = "我遇到了404的错误怎么办" 就被向量化为了上述的 512 维的向量。
2.3 向量数据库
本地数据通过 Embedding 模型可以将对应文本转化为对应的向量,那转化的向量如何存储?这里使用Chroma向量数据库。 Chroma 是一款轻量级、开源、AI 原生的向量数据库,主打极简开发、开箱即用,非常适合 RAG、语义搜索、AI Agent 记忆等场景。下面介绍其使用方法:
2.3.1 向量数据库(创建/连接)
# 初始化向量数据库(创建/连接)
vector_store = Chroma(
collection_name="collection1", # 类似裕数据库的表名
embedding_function=SentenceTransformerEmbeddings(model), # 向量化的模型
persist_directory="./chroma_db", # 数据存储路径
)2.3.2 向向量数据库中添加数据
① InMemoryVectorStore 实现
loader = CSVLoader(file_path="./data/rag.csv", encoding="utf-8")
documents = loader.load()
vector_store = InMemoryVectorStore(
embedding=SentenceTransformerEmbeddings(model),
)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=0,
separators=["\n\n", "\n", " ", ""],
length_function=len,
)
split_texts = text_splitter.split_documents(documents)
vector_store.add_documents(
documents=split_texts,
)
上述实现方式是存储在内存中,程序结束后,存储的向量就会自动的被清楚。主要实现流程:向量数据库的创建 vector_store ;本地化的文本数据进行分段 text_splitter.split_documents ;最后通过 vector_store.add_documents 将分段后的文本数据加入 vector_store,在加入的时候,由于add_documents 是 Iterator 的,所以会一段一段的将分段后的文本数据(类型是 document )转化为向量并存储到vector_store 中。
每一个被分段的文本数据如下所示:
Document ( metadata = { 'source' : ' ./data/rag.csv ', ' row ' : 0 }, page_content = ' user_query : 如何安装Python的pandas库?' )
② 本地持久化存储
# 1 定义向量数据库
vector_store = Chroma(
collection_name = "collection1", # 集合名称,类似数据库中的表名
embedding_function = SentenceTransformerEmbeddings(model), # 嵌入模型
persist_directory = "./chroma_db", # 持久化数据库路径
)
# 2 分段
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=0,
separators=["\n\n", "\n", " ", ""],
length_function=len,
)
chunks= text_splitter.split_documents(text) # 这里的text是本地文本数据
# 3 加入向量数据库
metadata = {
"source": file_name,
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"operator": operator_name
}
vector_store.add_texts(
chunks,
metadatas = [metadata for _ in range(len(chunks))]
)本地持久化存储使用 Chroma 来创建,较比 InMemoryVectorStore 方式,需要多提供 collection_name ( 类似于表名 ) 和 persist_directory ( 持久化存储的路径 )。
2.4 本地数据上传去重
防止本地数据重复上传至向量数据库,所以再加入向量数据库前,我们需要判断一下等待加入数据的数据是否已经存在于向量数据库中,通过 MD5技术来实现。
MD5 是一种哈希算法,作用只有一个,把任意长度的文本 / 文件转换成一串固定长度(32 位)的唯一字符串。特点:
- 输入一模一样 → 输出 MD5 一定一模一样
- 输入差一个字 / 一个符号 → MD5 完全不同
- 32 位字符串,例如:
d41d8cd98f00b204e9800998ecf8427e
一句话来说MD5 = 数据的唯一身份证号。这样的话,我们再将本地文本存储到向量数据库的时候,应该记录下来对应的MD5,同时新文件上传的时候,同样计算其对应的MD5,并查看MD5是否存在于专门记录MD5值的文件中,如存在,则表示该文件已经被上传,如不存在,则表示该文件没有被上传。
def get_string_md5(input_string:str, encoding='utf-8'):
"""
获取字符串的md5值
:param input_string: 输入字符串
:return: md5值
"""
str_bytes = input_string.encode(encoding = encoding) # 将字符串转换为字节
md5_obj = hashlib.md5() # 得到md5对象
md5_obj.update(str_bytes) # 更新md5对象
md5_hex = md5_obj.hexdigest() # 得到md5的十六进制值
return md5_hex # 返回md5的十六进制值通过上述代码即可获得对应字符串的MD5值。
2.5 开发本地知识库文件上传界面
import time
import streamlit as st
from konwledage_base import KnowledgeBaseService
st.title("📊Dataset Upload Module")
st.markdown("---")
st.subheader("Intelligent customer service, exemplified by apparel product support")
st.caption("Cai Cien")
st.caption("CSDN blog: https://blog.csdn.net/2401_84080967?type=blog")
st.markdown("---")
with st.container():
uploader_file = st.file_uploader(
"👇Please upload a txt file:",
type=["txt"],
accept_multiple_files=False,
)
user_name = st.text_input("👇Please input your name:")
btn = st.button("Upload Data")
if "service" not in st.session_state:
st.session_state["service"] = KnowledgeBaseService()
if btn:
if user_name is None or user_name.strip() == "" or uploader_file is None:
st.warning("Please add name and upload a txt file")
else:
file_details = {
"filename": uploader_file.name,
"filetype": uploader_file.type,
"filesize": uploader_file.size / 1024
}
st.write(file_details)
text = uploader_file.getvalue().decode("utf-8")
with st.spinner("UPLOADING..."):
time.sleep(2)
result = st.session_state["service"].upload_by_str(text, file_details["filename"], user_name)
st.write(result)
这里使用 streamlit 便捷开发,streamlit适合数据科学家、AI 工程师快速做原型、仪表盘、模型 Demo、内部小工具(几天内搞定)。不适合通用网站、高并发服务、复杂前端、生产级大型应用。
三 )在线流程
在线流程中 AI 需要基于用户提问和本地知识生成答案,所以在线流程中的核心技术就是 RAG 技术,当接受到用户问题后,首先要进行语义理解,在本地向量数据库中查找相对应的知识并抽取知识,将抽取到的知识和用户提问构建成对应的提示词输入给 AI 进行回答。
3.1 RAG 技术的实现
RAG 技术的实现也就是要根据用户提问去本地数据库抽取对应的知识,其实这一步很简单,如下:
from langchain_chroma import Chroma
from sentence_transformers import SentenceTransformer
import config_data as config
from konwledage_base import SentenceTransformerEmbeddings
class VectorStoreService:
def __init__(self):
self.model_dir = config.embedding_model_dir
self.model = SentenceTransformer(self.model_dir)
self.embeddings = SentenceTransformerEmbeddings(self.model)
self.vector_store = Chroma(
collection_name=config.collection_name,
embedding_function=self.embeddings,
persist_directory=config.persist_directory
)
def get_retriever(self):
similarity_threshold = config.similarity_threshold
retriever = self.vector_store.as_retriever(search_kwargs={"k": similarity_threshold}) # 向量库转换成检索器
return retriever
# test
if __name__ == "__main__":
service = VectorStoreService()
retriever = service.get_retriever()
results = retriever.invoke("实施流程中怎么定义学生模型的结构参数空间与部署约束")
print(results)在 VectorStoreService 中定义 get_retriever 函数,用于得到对应向量数据库的检索器 retriever ;向量数据库对象 vector_store 有一个 as_retriever 来定义其对应的检索器 retriever。当创建 VectorStoreService 对象的时候,其通过 service.get_retriever() 就得到了对应向量数据库的检索器,这时候调用 invoke 方法即可完成对应的检索。输出如下所示:
这样 RAG 技术就已经实现了,可以成功的根据用户提问在向量数据库中抽取出对应的资料。
3.2 构建 RAG 后的提示词模板
self.prompt_template = ChatPromptTemplate.from_messages([
{"role": "system", "content": "以我提供的参考资料为主,简洁和专业的回答用户问题,不要编造信息。参考资料:{reference}"},
{"role": "system", "content": "并且提供用户的对话历史记录,如下所示:"},
MessagesPlaceholder(variable_name="history"),
{"role": "user", "content": "用户提问:{question}"},
])reference 将被补全通过 RAG 得到的资料,MessagesPlaceholder(variable_name="history"), 将被补全用户的历史聊天记录,question 将被补全用户提问;当这三个参数都被补全的话,提示词就被构建好了,就可以喂给 AI 模型进行回复了。
3.3 构建完整服务链
class RAGService:
def __init__(self):
self.vector_store_service = VectorStoreService()
self.prompt_template = ChatPromptTemplate.from_messages([
{"role": "system", "content": "以我提供的参考资料为主,简洁和专业的回答用户问题,不要编造信息。参考资料:{reference}"},
{"role": "system", "content": "并且提供用户的对话历史记录,如下所示:"},
MessagesPlaceholder(variable_name="history"),
{"role": "user", "content": "用户提问:{question}"},
])
self.chat_model = ChatModelService().chat
self.chain = self._get_chain()
def _get_chain(self):
retriever = self.vector_store_service.get_retriever()
def format_document(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档内容:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
chain = (
{
"history": itemgetter("history"),
"question": itemgetter("question"),
"reference": itemgetter("question") | retriever | format_document,
} | self.prompt_template | self.chat_model | StrOutputParser()
)
conversation_chain = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="question",
history_messages_key="history",
)
return conversation_chain
if __name__ == "__main__":
session_config = {
"configurable": {
"session_id": "user_001"
}
}
print(type(RAGService().chain))
result = RAGService().chain.invoke({"question": "什么是RAG?"}, config=session_config)
print(result)
当 RAGService().chain.invoke({"question": "什么是RAG?"}, config=session_config) 的时候,由于对普通链进行了加强 RunnableWithMessageHistory ,使得链条具有记忆功能,同时当链条加强为带有记忆功能后,其 invoke 用户问题的时候需要传入的是字典,而非单个 str 。conversation_chain 首先得到列表 ({"question": "什么是RAG?","history": [ HumanMessage(),AIMessage() ]"},然后传到基础链;
{
"history": [HumanMessage(), AIMessage()......]
"question": '什么是RAG?'
"reference": '什么是RAG?' | retriever | format_document,
} | self.prompt_template | self.chat_model | StrOutputParser()reference 中入链的是 retriever ,通过构建的检索器在相关的数据库中检索资料,将检索到的资料通过format_document整理格式,reference 得到的是 Document 对象。当以下
{
"history": [HumanMessage(), AIMessage()]
"question": '什么是RAG?'
"reference": '什么是RAG?' | retriever | format_document,
}被填充完成后,就可以被送入 prompt_template 得到完整提示词模板,最后送入模型。
invoke的时候填入的是config,那如何通过config自动得到history?
首先
RunnableWithMessageHistory类会自动的将config中的 session_id 传递给 get_history函数得到历史记录,需要注意的是,get_history 是我们自己实习的,函数名也可以自己任取,RunnableWithMessageHistory类只是默认将 session_id 作为参数传递给get_history函数。
3.4 历史记录存储怎么实现
conversation_chain = RunnableWithMessageHistory(
chain,
get_history, # 你的本地文件存储
input_messages_key="question",
history_messages_key="history",
)这个组件会自动做 3 件事:
- 每次 invoke 前 → 自动从文件读取 history (自动将 session_id 传入 get_history 函数)
- 把 history 塞进 prompt
- 每次 invoke 后 → 自动把新消息写入文件
LangChain 的 RunnableWithMessageHistory 是自动帮你存、自动帮你取的组件,不需要手动调用 add_message。但是 get_history 必须自己实现:
import json
import os
from typing import Sequence
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import BaseMessage, message_to_dict, messages_from_dict
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
DEFAULT_HISTORY_DIR = os.path.join(BASE_DIR, "chat_history")
def get_history(session_id: str) -> BaseChatMessageHistory:
# 每个 session_id 对应一个本地 JSON 文件
return FileChatMessageHistory(session_id=session_id, storage_path=DEFAULT_HISTORY_DIR)
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id: str, storage_path: str):
self.session_id = session_id
self.storage_path = storage_path
os.makedirs(self.storage_path, exist_ok=True)
self.file_path = os.path.join(self.storage_path, f"{self.session_id}.json")
@property
def messages(self) -> list[BaseMessage]:
try:
with open(self.file_path, "r", encoding="utf-8") as f:
messages_dict = json.load(f)
return messages_from_dict(messages_dict)
except (FileNotFoundError, json.JSONDecodeError):
return []
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
all_messages = list(self.messages)
all_messages.extend(messages)
messages_dict = [message_to_dict(msg) for msg in all_messages]
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(messages_dict, f, ensure_ascii=False, indent=2)
# 兼容单条消息写入
def add_message(self, message: BaseMessage) -> None:
self.add_messages([message])
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f, ensure_ascii=False)
3.5 用户交互界面实现
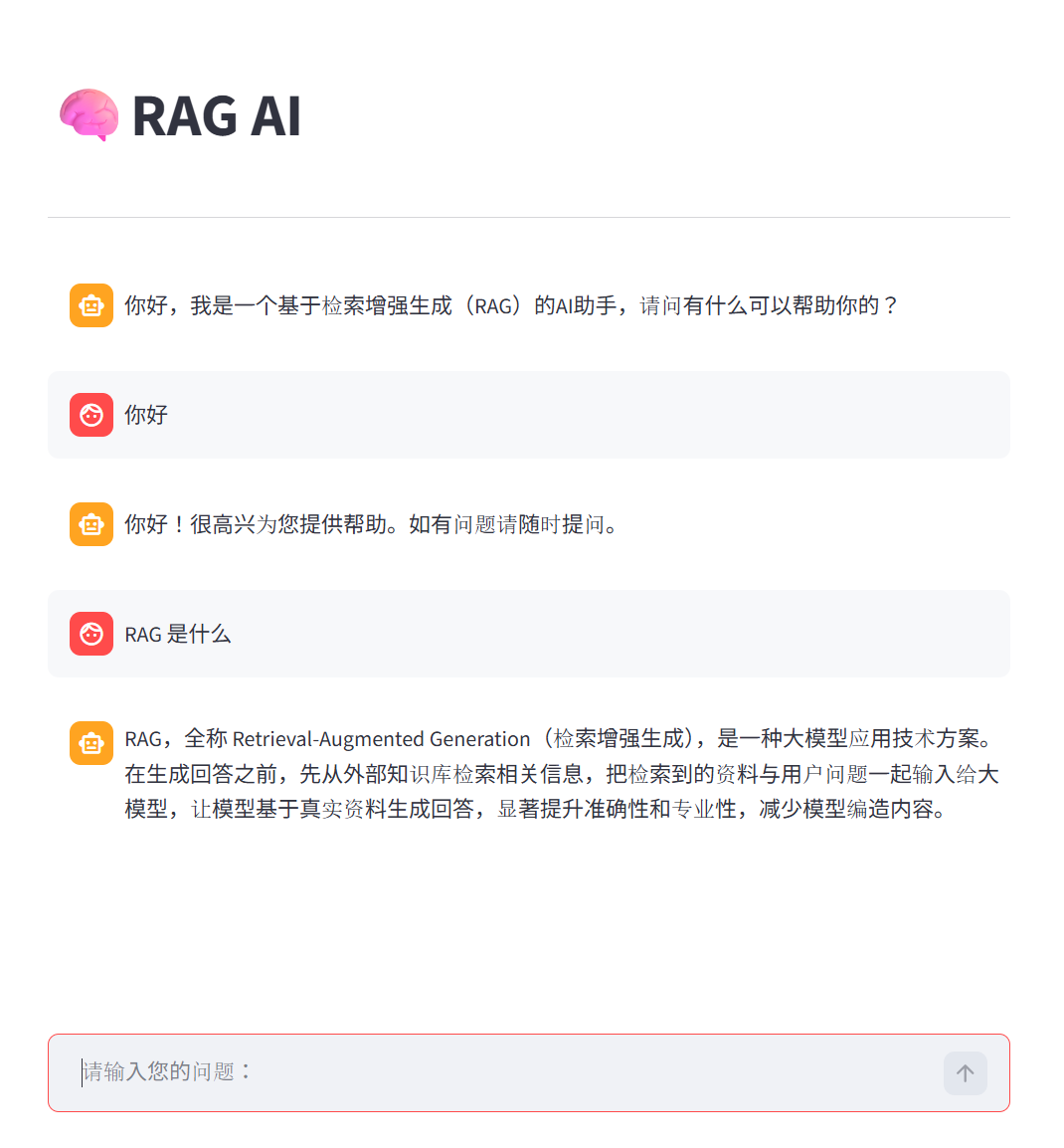
import streamlit as st
import time
from rag import RAGService
st.title("🧠RAG AI")
st.divider()
prompt = st.chat_input("请输入您的问题:")
if "rag_service" not in st.session_state:
st.session_state["rag_service"] = RAGService()
if "message" not in st.session_state:
st.session_state["message"] = [{"role": "assistant", "content": "你好,我是一个基于检索增强生成(RAG)的AI助手,请问有什么可以帮助你的?"}]
# 一启动 将历史记录写入聊天界面
for msg in st.session_state["message"]:
st.chat_message(msg["role"]).write(msg["content"])
if prompt:
cache_list = []
st.chat_message("user").write(prompt)
st.session_state["message"].append({"role": "user", "content": prompt})
with st.spinner("🧠Retrieval-Augmented Generation AI is answering..."):
time.sleep(2)
res_stream = st.session_state["rag_service"].chain.stream({"question": prompt}, config={"session_id": "user_001"})
def capture(generator, cache_list):
for item in generator:
cache_list.append(item)
yield item
st.chat_message("assistant").write_stream(capture(res_stream, cache_list))
st.session_state["message"].append({"role": "assistant", "content": "".join(cache_list)})
四 )总结
到这里,一套完整可用的 RAG 智能客服系统就全部实现完成了。从本地知识库搭建、文本向量化、文档分块、MD5 去重防止重复导入,到在线查询时的语义检索、提示词构造、大模型回答,再到对话历史本地保存和简单的交互界面,我们把 RAG 里最核心的流程都走了一遍,代码也都完整落地。
整个项目用的都是轻量开源工具,环境简单、上手快,既适合用来入门理解 RAG 工作原理,也可以直接改成自己项目里的知识库问答、智能客服等实用功能。希望这篇实战教程能帮你真正动手跑通一套 RAG 系统,让大模型不再只会 “凭空回答”,而是能基于你自己的业务数据,给出更可靠、更贴合场景的答案。
在此基础上,你还可以继续扩展:支持 PDF/Excel 等更多文件格式、更换更强的向量模型、优化流式回复效果、增加用户权限控制等,一步步把小 Demo 打磨成更成熟的 AI 应用。
本文参考链接:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)