计算机毕业设计之基于LSTM的空气质量预测的算法的研究
摘要
本研究旨在探索基于长短期记忆网络的空气质量预测算法,以提供更为精准和高效的空气质量预测服务。通过系统性的数据预处理、模型构建、训练和验证,成功开发了一个针对未来七天空气质量指数的预测模型。该模型利用LSTM的强大时序数据处理能力,有效捕捉了空气质量变化中的复杂规律和趋势。
在研究过程中,首先对大量历史空气质量数据进行了严格的清洗、归一化和序列化处理,确保了数据的质量和一致性。随后,设计了合理的LSTM网络结构,并通过多次实验和参数调整,优化了模型性能。模型在训练集上表现出良好的学习能力和收敛速度,在测试集上实现了较高的预测精度,验证了其有效性和可靠性。本研究不仅为空气质量预测领域提供了新的技术手段,也为城市环境管理和公众健康保障提供了科学依据,具有广阔的应用前景和推广价值。
本研究的实施分为五个主要步骤:数据采集、数据预处理、数据分析和数据可视化、管理系统。首先,进行了数据采集工作。从公开渠道收集了大量与空气质量相关的数据,包括质量等级统计、AQI指数统计、天津空气质量、PM2.5统计、PM10统计和质量成分统计等。为了确保数据的全面性和准确性,还对这些数据进行了合并和处理,将其整合为一个统一的CSV文件格式。
接下来是数据预处理阶段。由于原始数据可能存在缺失值和不一致的地方,需要对其进行清洗和整理。使用了Pandas库来读取CSV文件,并对数据进行筛选、填充缺失值以及去除重复项等操作。经过这一系列的处理,系统的数据集变得更加干净和有序。
然后进入数据分析环节。利用Spark框架对预处理后的数据进行深度挖掘和分析,Pandas来数据分析,sklearn机器学习搭建模型与预测。通过编写自定义脚本,对不同地区的空气质量情况进行了比较,分析了城市、地区等因素对空气质量的影响,并得出了相应的结论和建议。
最后是数据可视化部分。将分析得到的结果转化为图表形式,以便于理解和传播。使用了Vue.js框架来创建交互式的网页界面,用户可以通过点击不同的按钮来查看各种统计信息和趋势图。此外,还制作了柱状图、折线图和饼状图来展示某些特定的数据分布情况。管理系统则实现了个人中心,空气质量信息管理,空气质量预测管理等功能模块
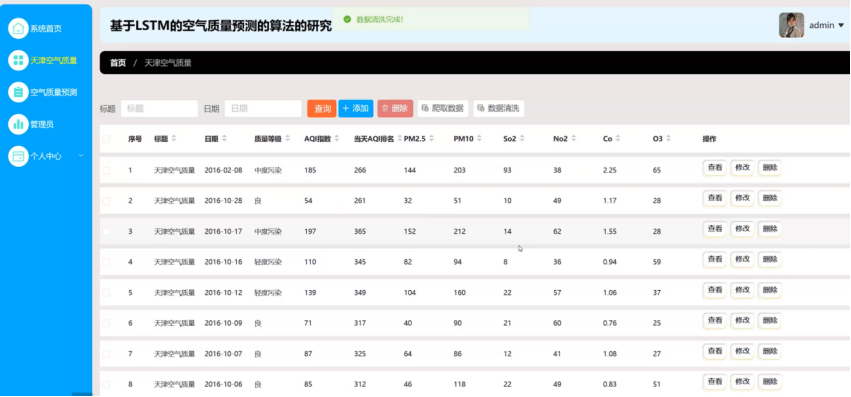
管理员在空气质量指数信息管理模块中,通过数据爬虫技术自动抓取空气质量信息,并进行数据清洗以保障信息准确性。模块允许管理员查看空气质量指数信息详情、修改信息、删除记录以及查询。系统提供了友好的操作界面,管理员可轻松编辑信息,而爬虫和数据清洗功能则后台自动运行,确保数据的实时更新和高质量,从而有效支持管理员的日常信息管理工作。
数据爬取采用Python的爬虫框架,Scrapy结合HTTP请求库如Requests,从网站等目标源获取数据。爬取过程中,通过设置合理的爬取频率和遵守robots.txt规则,确保数据获取的合法性和效率。获取原始数据后,进入数据清洗阶段,利用Python的Pandas库对数据进行预处理,包括去除空值、异常值,格式统一,以及处理重复数据。此外,通过正则表达式对文本数据进行清洗,提取有用信息。数据清洗还涉及数据类型转换、缺失值填充等操作,确保数据的质量和一致性。最终,清洗后的数据存储于数据库,为后续的数据分析和业务应用提供准确、可靠的数据基础

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)