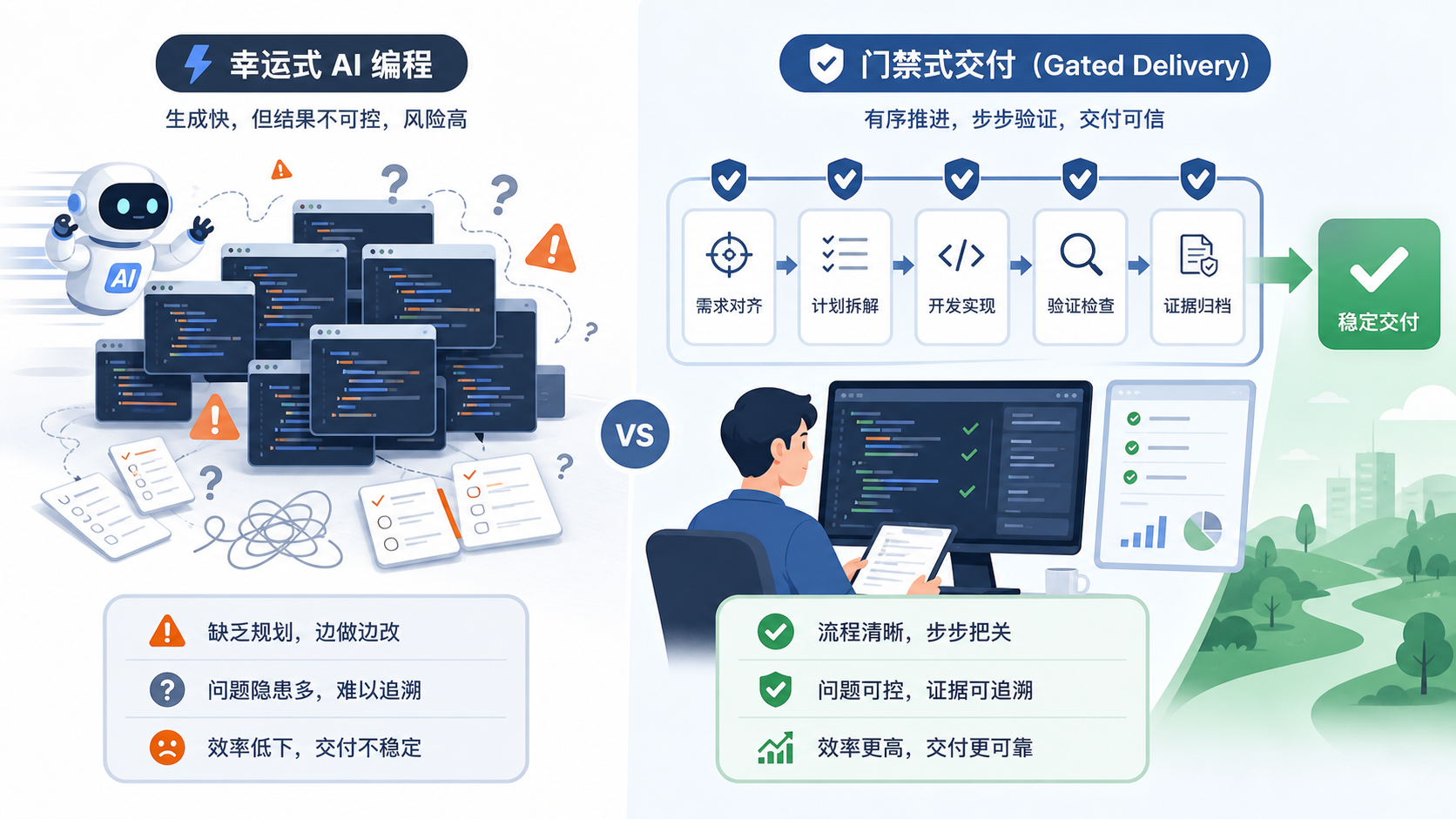
AI 越会写代码,越不能让它直接写到 commit
AI 编程最容易给人一种错觉:
只要模型够强、prompt 够长、上下文塞得够多,交付就会变稳定。
但我越来越觉得,真正的问题不在这里。
很多翻车现场,模型并不是不会写代码。
它写得很快,解释得也很完整,甚至每一段 diff 单独看都还挺合理。
可最后结果还是不对。
需求没对齐。
边界没确认。
bug 没定位根因。
测试没跑。
commit 前没人检查。
它像一个精力旺盛、响应极快、随时准备开工的队友。你只要给一点方向,它就会立刻往前冲。
而工程交付最怕的,恰恰是“还没搞清楚,就已经开始冲”。
所以后来我做了一件事:不再把 AI 编程当成一次完整的对话,而是把它拆成 11 道关卡。
不是为了让流程变复杂。
而是为了让每一次交付,都不用靠运气。
一、为什么 AI 编程需要“关卡”
人类开发者在真实项目里工作,从来不是只靠“写代码”。
写代码之前,要理解需求。
理解需求之前,要确认用户到底想解决什么问题。
方案复杂时,要先比较取舍。
修 bug 时,要先复现,再定位根因。
写完以后,要验证。
提交之前,要 review。
这些动作太普通了,普通到我们经常忘记它们的存在。
但 AI 不会天然继承团队里的工程习惯。
你让它“帮我做一下”,它默认会直接开始做。
你让它“修一下 bug”,它默认会直接给补丁。
你让它“提交一下”,它可能会把没有验证的改动包装成一个看起来很专业的 commit message。
这不是恶意。
这是它的默认工作方式:响应、补全、生成。
可软件交付不是生成文本。
软件交付是一条证据链。
从意图,到范围,到方案,到实现,到验证,到 review,到提交,每一环断了,最后都可能变成线上风险。
所以关卡的意义,不是拦住 AI。
关卡真正拦住的,是我们的侥幸。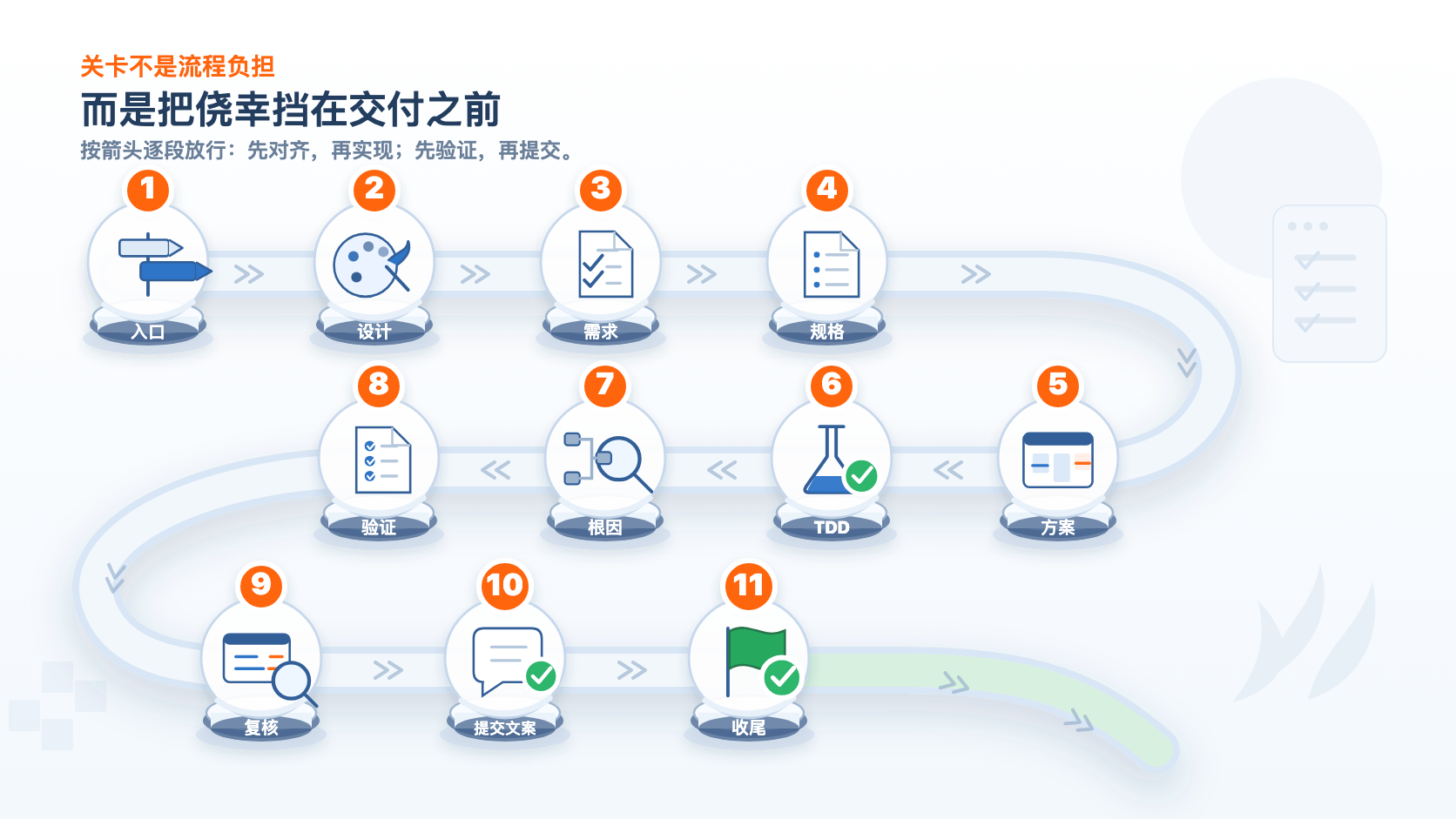
二、11 道关卡,每一道只解决一个失控点
我把这套流程做成了 dev-skills(仓库:Jason-chen-coder/dev-skills)。
它不是一个“大而全的万能 agent”,而是 11 个分工明确的 skill。
每个 skill 只管一道关。
第 1 关:入口关
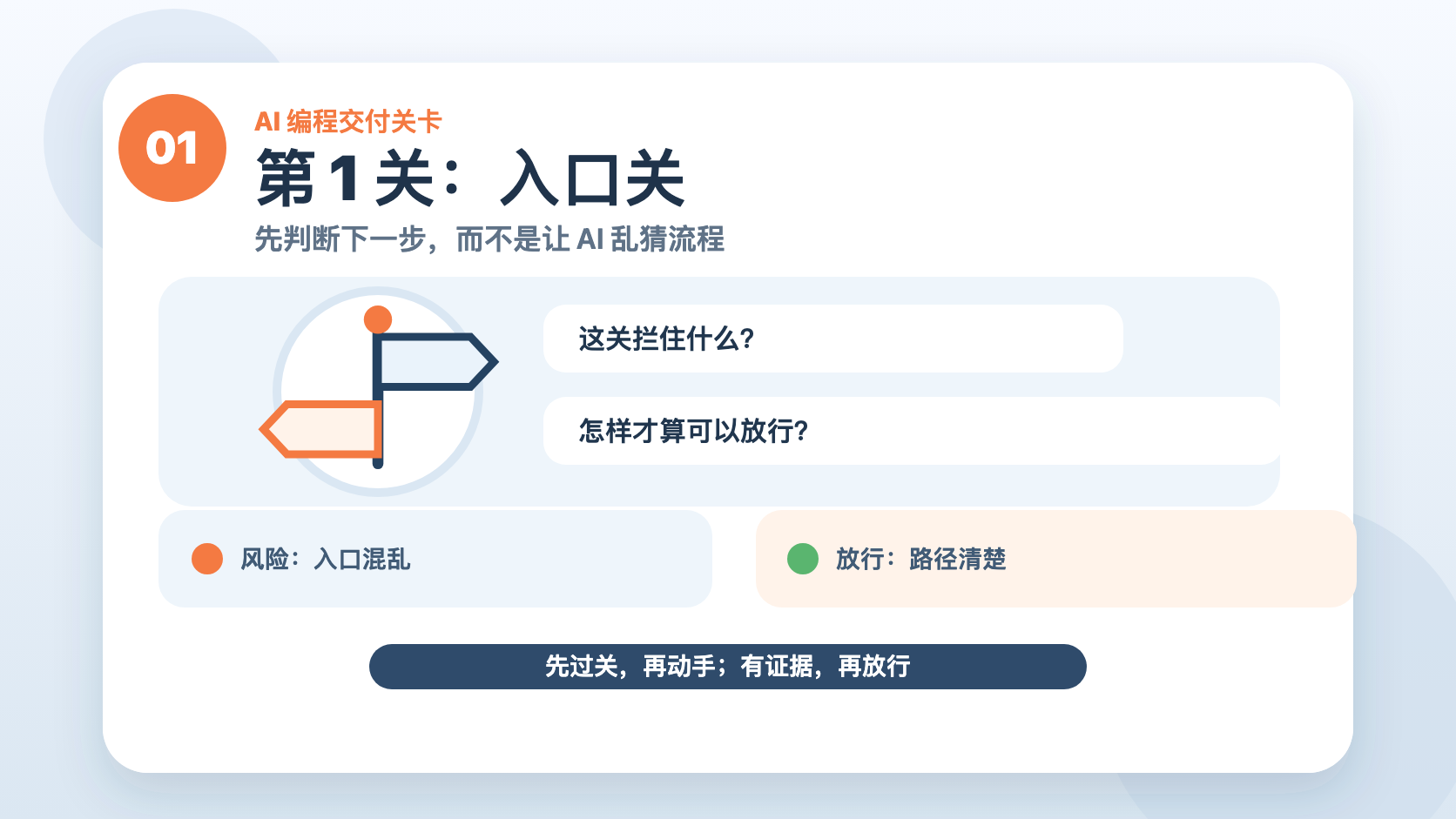
有时候最难的不是写代码,而是不知道下一步该做什么。
这时不应该让 AI 乱猜。
dev-auto 的作用很简单:看当前状态,推荐下一步。
它不会替你偷偷执行后面的流程,也不会自动调起一堆工具。
它只回答一个问题:
现在该往哪走?
这道关解决的是“入口混乱”。
很多流程失控,不是因为后面做错了,而是从第一步就进错了门。
第 2 关:设计上下文关
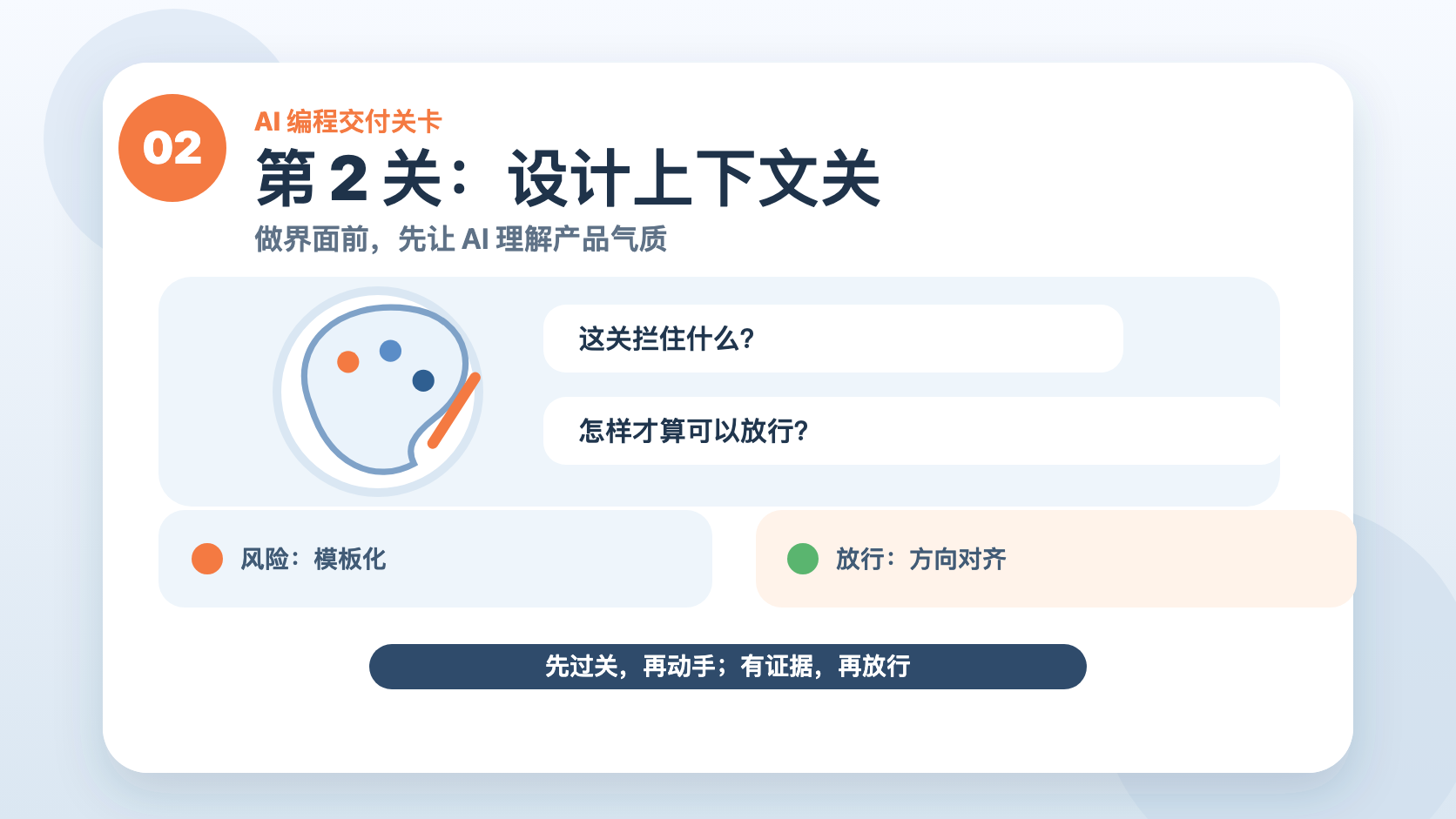
做 UI、landing page、产品界面时,AI 最容易犯一个毛病:
它不是不会设计。
它是太容易把所有界面都设计成同一种“AI 味”。
大卡片、渐变背景、空洞 hero、看起来很热闹但不贴产品。
dev-design-context 做的是一件前置工作:先沉淀项目的设计上下文。
这个产品应该安静还是张扬?
信息密度应该高还是低?
交互是给第一次访问的人,还是给每天重复使用的人?
设计不是美化。
设计是产品判断。
没有上下文,AI 只会套模板。
第 3 关:需求拷问关
大部分 AI 代码问题,根源都在需求没说清。
“加一个导出功能。”
“优化一下列表。”
“这里体验不好,改一下。”
这些话对人来说已经很模糊,对 AI 来说更危险。因为它不会停在模糊里,它会把模糊补成答案。
dev-grill-docs 的职责,是在写代码前拷问需求。
目标是什么?
范围是什么?
不做什么?
术语怎么定义?
验收标准是什么?
这道关不是为了问难用户,而是为了把聊天里的意图变成可以追踪的契约。
需求不清楚时,最贵的不是多问一句。
最贵的是少问一句,然后写错一整个功能。
第 4 关:规格兼容关

很多团队已经习惯说“先 spec 一下”。
所以 dev-spec 保留为兼容入口。
它本质上仍然走 dev-grill-docs 的 spec-only 路径:把需求整理成清晰的意图文档,而不是让关键约定散落在聊天记录里。
这道关解决的是“旧习惯和新流程的衔接”。
一个好的工作流,不应该要求所有人先背一套新语言。
它应该允许你用熟悉的说法进入正确的流程。
第 5 关:方案关

不是所有功能都需要正式方案。
但复杂功能、高风险改动、多模块协作,一定不能直接开写。
dev-plan 负责把已经对齐的 spec 变成实施方案。
有哪些可选方案?
为什么选这个?
风险在哪里?
哪些边界不能碰?
怎么验证?
方案关最重要的作用,是让 AI 在动手前先暴露取舍。
因为工程里最危险的决定,往往不是代码里的某一行,而是“它默认替你选了一个方案”。
第 6 关:行为锁定关

新功能和小改动最怕什么?
最怕看起来改好了,其实行为没被锁住。
dev-tdd 的价值不是仪式感。
它的价值是让 AI 在写实现前,先把目标行为变成测试。
先红,再绿。
先证明这个行为以前不存在或会失败,再证明现在成立。
这道关把“我觉得好了”变成“测试证明好了”。
没有行为锁定,AI 写得越快,漂移得也越快。
第 7 关:根因关

修 bug 时,AI 特别容易只修症状。
页面白屏,就加空判断。
请求失败,就包 try-catch。
数据错乱,就塞默认值。
这些补丁有时能让报错消失,但不一定能让问题解决。
dev-fix 的核心原则是:没有 root cause,就没有 fix。
先复现。
再列假设。
再沿着调用链、状态流、数据流往回追。
最后用回归测试证明问题真的被抓住。
这道关解决的是“猜补丁”。
如果你不知道火从哪里烧起来,只是把报警器关掉,那不叫修复。
第 8 关:验证关

AI 最喜欢说的一句话,是“已完成”。
但工程里,“完成”不是一句话。
完成必须有证据。
dev-verify 做的事很朴素:在声称 ready、fixed、done 之前,拿出新鲜验证。
跑了什么命令?
覆盖了哪些路径?
哪些需求已经验证?
哪些风险还没有覆盖?
这道关把“语气上的完成”变成“证据上的完成”。
速度不是交付。
证据才是交付。
第 9 关:提交前 review 关

AI 写完代码后,最容易出现一种尴尬:
功能可能是对的,但 diff 不干净。
顺手改了无关文件。
引入了临时变量。
绕开了团队约定。
测试覆盖不够。
commit 前没有人看,这些东西就会一起进仓库。
dev-code-review 不是夸改动好不好,而是专门找风险。
需求是否落实?
有没有无关改动?
有没有坏测试?
有没有死代码?
有没有和 spec 或 plan 冲突?
这道关解决的是“生成完就提交”的冲动。
AI 可以写代码,但不应该自己给自己放行。
第 10 关:提交信息关

commit message 不是包装。
它是后来的人理解这次变更的入口。
dev-commit-writer 只在你明确跳过 review、只要 message 时使用。
它的定位很克制:不评审代码质量,只根据当前 diff 写出合适的提交信息。
这道关提醒我一件事:
每个工具都应该有边界。
该 review 的时候不要只写 message。
该写 message 的时候,也不要假装自己已经 review 过。
边界清楚,流程才不会互相污染。
第 11 关:收尾关
很多人以为交付结束在 commit。
其实不是。
分支怎么处理?
是否需要 PR?
要不要 merge?
本地工作区是否干净?
有没有后续风险要记录?
dev-finish 处理的是最后一段路。
验证和 review 通过之后,再做分支收尾。
这道关解决的是“写完了但没交干净”。
一个工作流如果没有收尾,前面做得再认真,最后也可能乱在仓库状态、分支状态和交付状态上。
三、这 11 关不是线性背诵,而是按场景走路径
当然,真实工作里不需要每次把 11 个 skill 全跑一遍。
那样不是工程化,是折磨自己。
dev-skills 更像三条常用路径。
新功能或改功能,可以走:
dev-design-context(可选) -> dev-grill-docs -> dev-plan(可选) -> dev-tdd -> dev-verify -> dev-code-review -> git commit -> dev-finish
bug 或事故,可以走:
dev-fix -> dev-verify -> dev-code-review -> git commit -> dev-finish
很小的 hotfix,可以走:
dev-tdd -> dev-verify -> dev-code-review -> git commit
关键不在于每次走满。
关键在于别跳过当前场景最要命的那一关。
需求模糊,就不要跳过需求关。
方案高风险,就不要跳过方案关。
bug 没复现,就不要跳过根因关。
没有证据,就不要跳过验证关。
准备提交,就不要跳过 review 关。
这才是关卡的意义。
它不是固定流程。
它是风险路标。
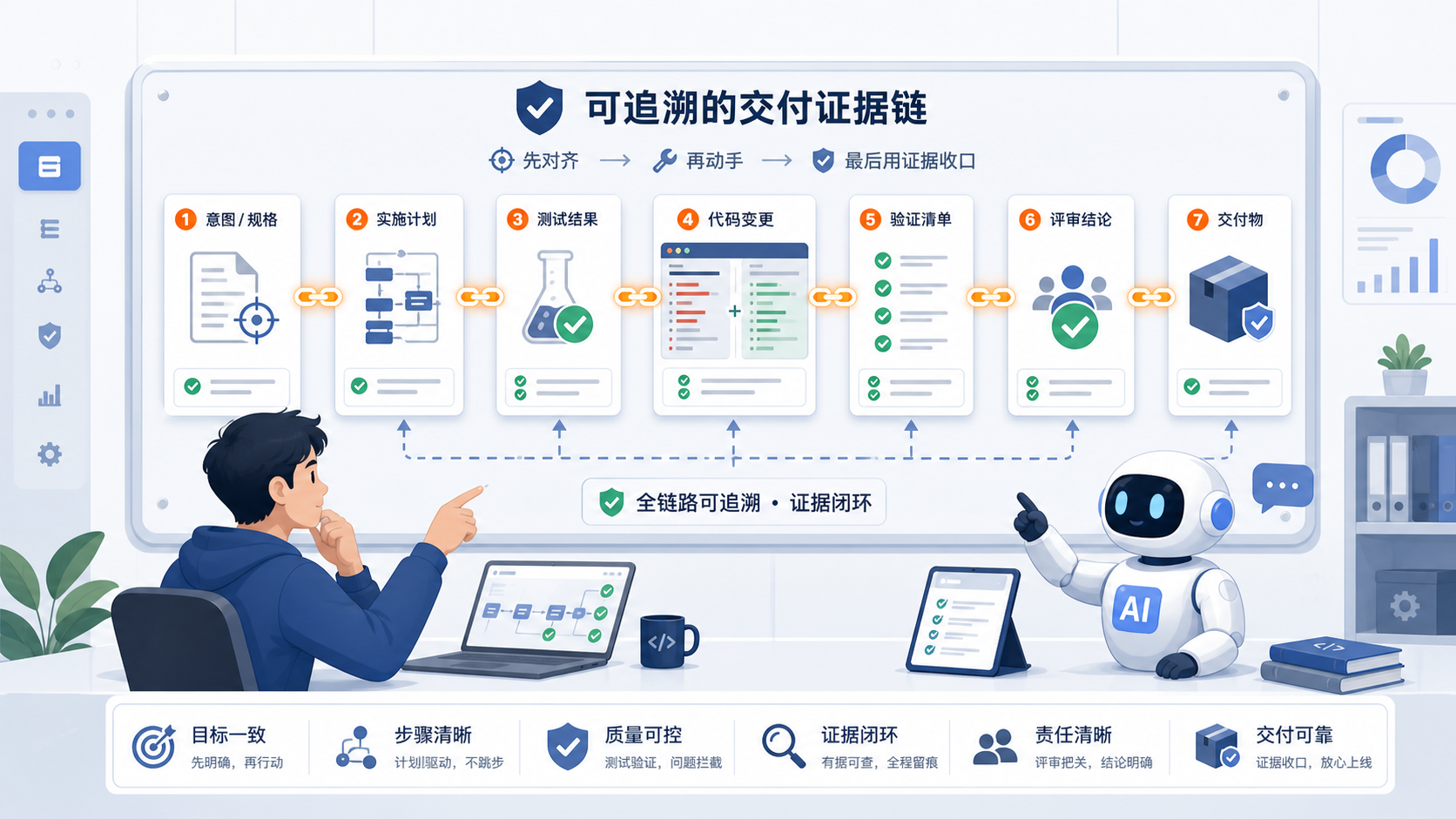
四、AI 编程真正需要的是“可追踪的契约链”
我现在越来越不喜欢把 AI 编程理解成“人给指令,AI 写代码”。
这个理解太薄了。
真实的协作更像这样:
意图要被确认。
范围要被写清。
方案要被选择。
行为要被测试。
修复要有根因。
完成要有证据。
提交要被检查。
这些东西串起来,才是一条交付链。
dev-skills 里的 SDD 也是这个意思。
它不追求把 spec 变成一个沉重的状态机,也不假装代码可以完全从文档自动生成。
它要做的是更朴素的事:
让稳定 artifact 定义意图、范围、方案、测试、验证和 review 标准。
让人、主 agent、子 agent 都有同一份对齐依据。
让 AI 生成的代码,在被当成“完成”之前,先经过该经过的证据。
这听起来没有“全自动开发”那么刺激。
但它更接近真实交付。
因为真实工程里,最重要的从来不是一次生成多漂亮。
而是改动能不能被解释、被验证、被 review、被接住。
五、成熟的 AI 编程,不是让它一次做更多
很多人优化 AI 编程时,会不断追求一个方向:
让它一次做更多。
一次读更多文件。
一次写更多模块。
一次完成更多步骤。
一次从需求到 commit。
但我现在更相信另一个方向:
让它每次只做该做的事。
需求阶段,就别写实现。
方案阶段,就别偷偷改代码。
修 bug 阶段,就别绕过复现。
验证阶段,就别只给乐观总结。
review 阶段,就别当橡皮图章。
真正成熟的 AI 编程,不是把人从流程里拿掉。
而是把人的工程判断,变成 AI 每次都必须经过的关卡。
这也是我把 AI 编程拆成 11 道关卡的原因。
不是因为我喜欢流程。
而是因为我不想再靠运气交付。
运气好的时候,AI 一把就写对。
运气差的时候,它把没确认的假设、没验证的结果、没 review 的风险,一起交给你。
而工程不能靠运气。
工程要靠边界、证据和复核。
当 AI 编程也开始尊重这三件事,它才真正从“代码生成器”变成“可以协作的开发伙伴”。
最后,如果你也在用 AI 写代码,可以试着问自己一个问题:
你的流程里,哪一关最常被跳过?
是需求没问清?
是 bug 没复现?
是写完没验证?
还是 commit 前没人 review?
答案在哪里,风险就在哪里。
先把那一关补上。
你的 AI 编程体验,可能马上就会稳很多。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)