VoxCPM技术报告
VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning
VoxCPM 团队
项目地址:https://github.com/OpenBMB/VoxCPM/
模型权重:https://huggingface.co/openbmb/VoxCPM-0.5B
在线演示 Demo:https://huggingface.co/spaces/openbmb/VoxCPM-Demo
音频样例页:https://openbmb.github.io/VoxCPM-demopage/
摘要
语音合成生成模型长期存在一组核心矛盾:离散 Token 方案能保障生成稳定性,但会损失语音表现力;连续信号方案可保留完整声学细节,却会因任务耦合引发误差累积。行业主流为此采用依赖预训练语音 Tokenizer 的多阶段流水线架构,但这类架构会造成语义 - 声学特征割裂,难以实现整体化、高表现力的语音生成。
本文提出分层语义 - 声学建模结合半离散残差表征的方案,解决了上述痛点,并推出全新无 Tokenizer TTS 模型——VoxCPM。本框架引入可微量化瓶颈,让模型模块形成天然分工:Text-Semantic Language Model (TSLM) 负责生成语义 - 韵律规划内容,Residual Acoustic Model (RALM) 还原细粒度声学细节。这套分层语义 - 声学表征会引导局部扩散解码器生成高保真语音隐变量。
核心优势在于:整套架构基于简单的扩散损失实现端到端训练,彻底摆脱对外部语音 Tokenizer 的依赖。模型基于总计 180 万小时的双语语料完成训练,0.5B 参数量的 VoxCPM 在开源零样本 TTS任务中取得当前最优性能,证明本方案可同时实现高表现力与高稳定性的语音合成。此外,VoxCPM 具备文本理解能力,能够结合上下文推理并生成匹配的韵律与风格,输出语音流畅自然、具备强上下文感知能力。为助力社区研究与开发,VoxCPM 基于 Apache 2.0 协议完全开源。
1 引言
现代文本转语音(TTS)的研发目标,早已从单纯保障语音可懂度,升级为合成高度拟人化音频 —— 精准传递细腻情绪、说话人身份与文本上下文语义。这一方向是情感虚拟助手、沉浸式数字虚拟形象等应用的核心基础,但其背后存在关键技术难题:如何同时还原细粒度声学特征(决定语音质感)与长距离语义结构(决定语音可懂度与自然韵律)。
受大语言模型(LLM)启发,当前主流路线将 TTS 定义为基于预训练神经音频编解码器(如 EnCodec)输出离散 Token 的序列建模任务。通过自回归 / 非自回归方式从文本、音素预测离散 Token,该方案具备优秀的可扩展性与上下文学习能力。但离散量化存在固有的量化上限:音频压缩会不可逆丢失大量细粒度声学细节。
为弥补音质损失,当前顶尖 TTS 系统普遍采用多阶段混合流水线:先由 LLM 生成离散 Token,再将其作为条件送入独立的扩散解码器做细节优化。该方案虽提升保真度,却造成严重的语义 - 声学割裂:LLM 运行在抽象离散空间,无法感知声学特征;扩散模型仅做局部优化,缺失高层语义信息。模块割裂不仅无法实现端到端优化,也限制了整体化、高表现力、上下文感知型语音合成的效果。
另一类路线直接对连续语音表征建模,以此规避量化损失。早期模型如 Tacotron 2、近期的 MELLE 均以自回归方式生成梅尔频谱图。但采用标准回归损失训练连续预测目标,容易导致输出语音过度平滑、风格多样性不足。后续研究将回归任务替换为去噪任务,对连续表征分布建模,衍生出非自回归、自回归两大分支。其中自回归方案在还原自然韵律、丰富表达风格上表现更优,有效提升了连续表征的细节与多样性。
但纯连续自回归模型仍存在本质缺陷:高层语义 - 韵律规划、底层声学渲染两大任务被耦合在同一个学习目标中。模型需要在单一连续空间内完成两类逻辑完全不同的任务,二者所需的归纳偏置也截然不同。任务耦合会极大限制单一 LLM 的建模能力:模型既要充当全局规划器,又要承担局部渲染工作,架构上无天然职能划分。我们认为,任务耦合是模型稳定性不足的核心原因—— 模型学习重心会偏向拟合底层声学纹理,进而破坏高层语义连贯性,最终引发长序列生成中典型的误差累积问题。
针对以上问题,本文提出一套无 Tokenizer、端到端统一框架,借助半离散残差表征实现分层语义 - 声学建模,破解表现力与稳定性的矛盾,并推出全新 TTS 模型 VoxCPM。本文核心思路:想要实现整体化、高表现力的语音合成,需要在架构上显式区分语义 - 韵律规划与声学渲染,同时保证整套系统可端到端训练。
本方案的核心创新是引入可微有限标量量化(FSQ)瓶颈,让模型模块自然分工:
-
Text-Semantic Language Model (TSLM) 生成语义 - 韵律规划内容,量化操作保障输出稳定性,模块专注学习语言学特征;
-
Residual Acoustic Language Model (RALM) 还原量化丢失的细粒度声学细节,专攻声学特征优化。
这套分层设计让各模块各司其职,且全程保持可微性。TSLM 与 RALM 的输出共同引导局部扩散解码器,生成高保真语音隐变量。最重要的是:整套分层模型基于统一的扩散损失端到端训练,在不依赖外部 Tokenizer 的前提下,将语音规划与声学渲染无缝融合。
本研究基于 180 万小时大规模双语语音语料训练,0.5B 参数量的 VoxCPM 在开源零样本 TTS任务中取得当前最优性能,充分证明本方案可兼顾高表现力与高稳定性。本文主要贡献如下:
-
提出端到端分层架构,通过内置半离散瓶颈破解语音合成中表现力 - 稳定性的权衡问题。该机制在统一框架内隐性解决连续模型的任务耦合,天然划分语义 - 韵律规划与细粒度声学建模两大职能。
-
结合残差学习与量化瓶颈,实现模块化分工 + 整体化建模。区别于模块割裂的多阶段流水线,本方案在不拆分架构的前提下完成功能划分,简化训练流程,彻底消除对外部语音 Tokenizer 的依赖。
-
依托 180 万小时大规模双语语音数据训练,0.5B 参数量 VoxCPM 刷新开源零样本 TTS 最优性能;在消费级 NVIDIA RTX 4090 显卡上,模型实时因子(RTF)低至 0.17,具备极强工程落地价值。
-
设计完备的消融实验,验证半离散残差表征是实现高稳定、高表现力、上下文感知合成的核心组件;同时开源全部代码与模型,助力社区后续研究。
2 相关工作
2.1 基于离散 Token 的 TTS
离散 Token 是现代 TTS 的主流技术路线,该路线借鉴 LLM 思路,借助 EnCodec、DAC 等神经音频编解码器,通过 \\ 残差矢量量化(RVQ)\\ 将语音转为离散表征。AudioLM、VALL-E 率先将音频生成、TTS 定义为离散声学 Token 的自回归序列预测任务。
后续衍生出多项优化工作:SoundStorm 引入非自回归生成提升效率;Spear-TTS 聚焦弱监督场景下的多语言能力;VoiceCraft、XTTS 依托上下文学习强化零样本 TTS 效果。
近期研究主要围绕可扩展性、可控性、零样本泛化能力展开:CosyVoice 引入监督语义 Token 优化零样本性能;迭代版本 CosyVoice 2/3 结合文本 LLM 初始化、流式合成与大规模训练数据,实现接近真人的音质、低延迟与复杂真实场景适配;IndexTTS、IndexTTS 2 在自回归 Token 生成中实现精准时长、情绪控制,适配高表现力、高时序要求的业务;SparkTTS 采用单路解耦语音 Token 设计提升建模效率;FireRedTTS 及迭代版本 FireRedTTS-2 构建工业级语音生成框架,支持长文本多人对话;Openaudio-s1 采用双路自回归架构 + 在线 RLHF,提升语音表现力与指令跟随能力;Higgs Audio v2 设计统一音频 Tokenizer,可同时提取语义与声学特征,并基于千万小时级音频预训练,打造强力音频基础模型。
尽管迭代众多,但离散量化带来的音质损失始终无法根除,声学保真度存在上限,因此行业陆续出现各类混合架构作为补充。
2.2 基于连续表征的 TTS
为规避离散模型的量化损失,连续表征路线直接对梅尔频谱、语音隐变量等特征建模。早期 Tacotron 2 搭建「文本→梅尔频谱」编码器 - 解码器经典架构;FastSpeech 引入显式时长建模,提升文本 - 音频对齐稳定性。受 VALL-E 启发,MELLE 直接基于文本条件自回归生成连续梅尔频谱帧,并结合变分推断优化采样机制。
近期研究大量融合扩散技术,提升连续表征的细节丰富度与风格多样性:NaturalSpeech 2、VoiceBox 等非自回归模型直接在连续表征上执行扩散运算;F5-TTS 采用流匹配技术提升合成效率。自回归类方案在韵律还原、风格多样性上更具优势,同时支持流式合成,代表性工作包括:ARDIT 采用自回归扩散 Transformer 做 TTS,通过参数共享统一语义连贯性与声学自然度;DiTAR 引入分块设计,用因果 LM 保障块间稳定性,双向局部扩散 Transformer 完成块内细节优化;VibeVoice 基于逐 Token 扩散实现长文本多人语音合成。
此外,CLEAR、FELLE 聚焦隐变量自回归建模,采用由粗到细的分层 Token 设计;MELA-TTS、KALL-E 结合 Transformer - 扩散联合架构与分布预测,同步提升效率与合成质量。
连续表征路线虽持续优化,但任务耦合的短板始终存在:高层语义规划与底层声学渲染相互纠缠,无显式任务划分时,长序列生成极易出现稳定性问题。
2.3 TTS 中的分层与残差建模
分层 + 残差建模的核心思路:将 TTS 拆解为多层子任务,平衡稳定性与表现力。HierSpeech++ 结合变分推断实现语义 - 声学映射;HALL-E 依托分层神经编解码器 + LLM,支持分钟级长语音合成;MARS6 构建高鲁棒性分层 Token 编码器 - 解码器 Transformer;DiffStyleTTS 将扩散用于分层韵律建模;HAM-TTS 引入分层声学建模 + 数据增强,优化零样本 TTS;QTTS 基于残差量化编码设计分层并行架构。歌声合成领域的 LeVo 同样采用分层框架,用两个仅解码器 Transformer 对歌声声部分层建模,提升生成质量。
上述工作弥补了传统方案的部分缺陷,但仍有不足:部分分层设计缺少规范化量化瓶颈;依赖 Tokenizer 的模型存在量化损失;多阶段拆分架构无法端到端优化。本文方案区别于现有研究:在统一框架内完整融合显式残差设计与半离散瓶颈,不依赖外部组件即可实现特征解耦。
3 方法论
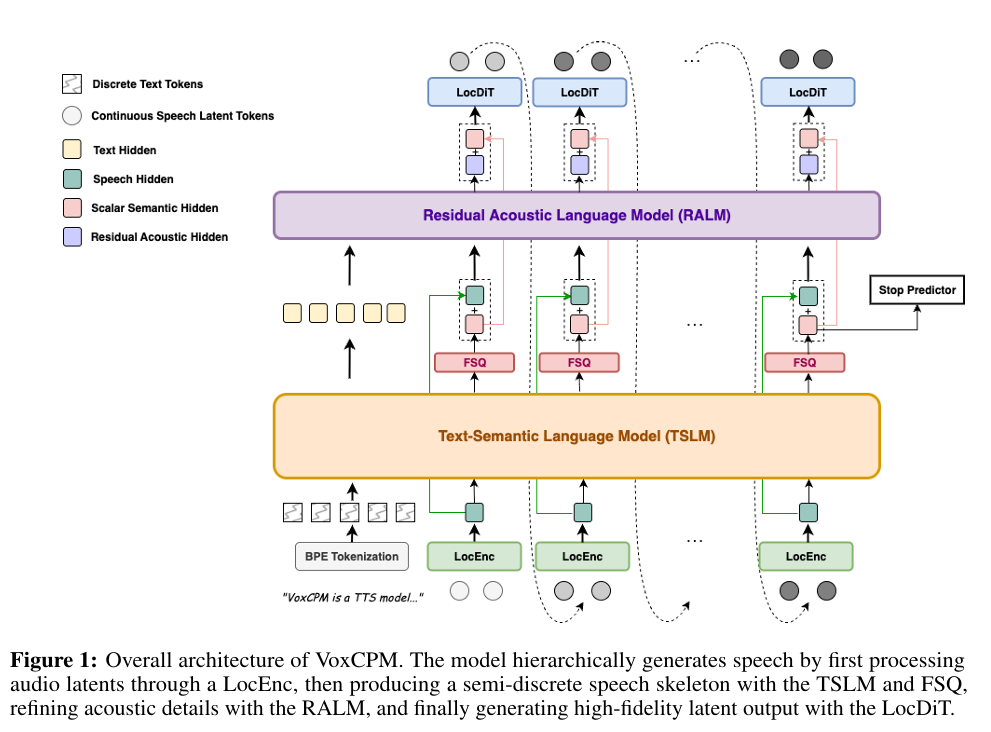
模型按分层逻辑完成语音生成:先通过 LocEnc 处理音频隐变量,再由 TSLM + FSQ 生成半离散语音骨架,随后 RALM 补充声学细节,最终由 LocDiT 生成高保真隐变量输出。
3.1 核心设计动机
语音合成长期面临表现力与稳定性的固有矛盾:基于语音 Tokenizer 的离散量化方案,自回归生成稳定,但量化会不可逆丢失细粒度声学细节;纯连续表征可完整保留音质,却因任务耦合导致长序列误差持续累积,严重影响语音可懂度。
除此之外,现有直接使用 FSQ、矢量量化(VQ)构建离散码本用于语言建模的方案,存在可扩展性缺陷:为承载更丰富声学特征而提升维度时,码本规模会指数级膨胀,形成体量庞大、特征稀疏的词表,导致 LLM 难以精准预测。
本文认为:有效的解决方案需要从架构层面拆分任务—— 将稳定的语义 - 韵律内容建模、细粒度声学细节建模相互分离,同时保证全程可微以支持端到端训练。核心思路:引入可微量化瓶颈,借助标量量化天然拆分特征:一部分为类离散特征骨架(保障内容稳定),另一部分为连续残差特征(还原声学表现力)。
与传统多阶段 TTS(将量化仅作为离散预测目标)不同,本方案仅把量化作为正则化手段,约束隐状态空间。该设计既规避词表爆炸问题,又能发挥离散表征的稳定性优势。
3.2 模型整体架构
VoxCPM 采用分层自回归架构,以输入文本 Token 序列 T = t 1 , . . . , t N T={t_{1}, ..., t_{N}} T=t1,...,tN 为条件,生成连续语音隐变量序列 Z = z 1 , . . . , z M Z={z_{1}, ..., z_{M}} Z=z1,...,zM;单个隐变量 z i ∈ R P × D z_{i} \in \mathbb{R}^{P ×D} zi∈RP×D 代表包含 P P P 帧、 D D D 维 VAE 隐向量的语音块。整体生成概率公式:
p ( Z ∣ T ) = ∏ i = 1 M p ( z i ∣ T , Z < i ) p(Z | T)=\prod_{i=1}^{M} p\left(z_{i} | T, Z_{<i}\right) p(Z∣T)=∏i=1Mp(zi∣T,Z<i)
模型核心创新为分层条件机制与残差表征学习,整体由四大模块构成:局部音频编码器(LocEnc)、Text-Semantic Language Model (TSLM)、Residual Acoustic Language Model (RALM)、Local Diffusion Transformer Decoder (LocDiT);TSLM 输出额外接入停止预测器,用于判定生成序列的终止位置。
单块语音生成逻辑:
z i ∼ L o c D i T ( h i f i n a l ) , h i f i n a l = F S Q ( T S L M ( T , E < i ) ) ⏟ 稳定特征骨架 + R A L M ( ⋅ ) ⏟ 残差声学细节 z_{i} \sim LocDiT(h_{i}^{final }), \quad h_{i}^{final }=\underbrace{FSQ\left(TSLM\left(T, E_{<i}\right)\right)}_{稳定特征骨架 }+\underbrace{RALM(\cdot)}_{残差声学细节 } zi∼LocDiT(hifinal),hifinal=稳定特征骨架
FSQ(TSLM(T,E<i))+残差声学细节
RALM(⋅)
式中 E < i = L o c E n c ( Z < i ) E_{<i}=LocEnc(Z_{<i}) E<i=LocEnc(Z<i) 代表历史音频上下文:轻量级 LocEnc 将 VAE 隐变量块压缩为紧凑声学嵌入。分层主干输出融合特征 h i f i n a l h_{i}^{final } hifinal,同时包含 TSLM+FSQ 的语义内容与 RALM 的声学细节;LocDiT 基于该特征,通过去噪扩散流程生成当前语音隐变量块 z i z_{i} zi。
整套模型支持端到端训练,梯度可流经所有模块(FSQ 依靠直通估计器实现反向传播),保证各模块协同优化,共同服务于语音合成任务。
3.3 分层语义 - 声学建模
本分层建模旨在从特征层面隐性拆分两大任务:语义 - 韵律规划、细粒度声学合成,通过结构化表征学习,解决稳定性与表现力的核心矛盾。
3.3.1 Text-Semantic Language Model (TSLM)
TSLM 是分层架构核心,负责挖掘高层语言结构,生成贴合上下文的韵律模式。区别于传统 TTS 依赖音素的设计,本模型以预训练文本大模型 MiniCPM-4 为主干,可直接从原始文本挖掘深层上下文,预测更自然的韵律。
针对中文场景,采用字符级分词 + 中文 BPE Tokenizer,缓解 TTS 任务词表稀疏问题。TSLM 同时接收文本 Token 与历史音频上下文,学习生成随语句动态变化的语义内容与韵律结构,输出连续语义 - 韵律表征(同时包含说话内容与对应韵律规则),并送入后续量化模块。
3.3.2 基于 FSQ 的半离散表征学习
有限标量量化(FSQ)是本方案核心组件,它将 TSLM 输出的连续隐向量映射到结构化格点空间,生成半离散表征。FSQ 对向量每一维执行确定性标量量化,公式如下:
h i , j F S Q = Δ ⋅ c l i p ( r o u n d ( h i , j T S L M Δ ) , − L , L ) h_{i, j}^{FSQ}=\Delta \cdot clip\left(round\left(\frac{h_{i, j}^{TSLM}}{\Delta}\right),-L, L\right) hi,jFSQ=Δ⋅clip(round(Δhi,jTSLM),−L,L)
其中 Δ \Delta Δ 为量化步长, L L L 为截断范围,round 函数将数值映射为离散等级;反向传播阶段,FSQ 依靠直通估计器保持全程可微。
FSQ 起到瓶颈约束作用,原理近似残差矢量量化(RVQ)第一层,用于提取粗粒度语义 - 韵律骨架(语音内容、语调模式等)。本文将该类表征定义为半离散表征:相比标准 FSQ,本方案采用更高特征维度,保证特征承载能力充足。
与 RVQ(第一层作为预测目标、后续层补细节)不同,本文的 FSQ 瓶颈是连续数据流内部的可微归纳偏置。它引导模型优先学习稳定的高层语义 - 韵律特征,明确瓶颈需保留的核心信息,降低 TSLM 建模压力,让模型聚焦语音主干特征,缓解误差累积。
3.3.3 残差声学建模
量化会丢失部分细粒度声学信息,为此引入 Residual Acoustic Language Model (RALM)。该模块专门还原传统离散量化丢失的细腻语音特征:说话人声纹、频谱精细结构、微韵律变化等。RALM 计算逻辑:
h i r e s i d u a l = R A L M ( H t e x t T S L M , H < i F S Q ⊕ E < i ) h_{i}^{residual }=RALM\left(H_{text }^{TSLM}, H_{<i}^{FSQ} \oplus E_{<i}\right) hiresidual=RALM(HtextTSLM,H<iFSQ⊕E<i)
RALM 输入包含三部分:文本对应的 TSLM 隐状态、历史语音的 FSQ 半离散表征、历史声学嵌入 E < i E_{<i} E<i。
借助残差学习,模型形成清晰分工:TSLM+FSQ 支路保障内容稳定与韵律连贯,RALM 支路提升声学表现力、还原说话人特征。最终融合特征: h i f i n a l = h i F S Q + h i r e s i d u a l h_{i}^{final }=h_{i}^{FSQ}+h_{i}^{residual } hifinal=hiFSQ+hiresidual,同时整合语义稳定性与声学表现力,为后续扩散模块提供完备条件。
3.3.4 Local Diffusion Transformer Decoder (LocDiT)
Local Diffusion Transformer (LocDiT) 是高保真合成模块,以前置分层网络输出的融合特征 h i f i n a l h_{i}^{final } hifinal 为条件,生成连续语音隐变量块。
模块借鉴 DiTAR 设计,采用双向 Transformer,让单个语音块内实现全感受野建模。为提升生成连贯性,将前一语音块 z i − 1 z_{i-1} zi−1 作为额外条件输入,把任务转化为补全生成(而非独立分块生成),经实验验证可显著提升音质。推理阶段会按固定概率掩码 LocDiT 中的 LM 引导信息,实现无分类器引导(CFG)。
3.4 训练目标
整套模型基于流匹配损失端到端训练,直接优化语音隐变量生成质量。流匹配条件公式训练稳定性强、采样效率高,因此作为主损失:
L F M = E t , z i 0 , ϵ [ ∣ v θ ( z i t , t , h i f i n a l , z i − 1 ) − d d t ( α t z i 0 + σ t ϵ ) ∣ 2 ] \mathcal{L}_{FM}=\mathbb{E} t, z_{i}^{0}, \epsilon\left[\left|v_{\theta}\left(z_{i}^{t}, t, h_{i}^{final }, z_{i-1}\right)-\frac{d}{d t}\left(\alpha_{t} z_{i}^{0}+\sigma_{t} \epsilon\right)\right|^{2}\right] LFM=Et,zi0,ϵ[
vθ(zit,t,hifinal,zi−1)−dtd(αtzi0+σtϵ)
2]
式中 z i t = α t z i 0 + σ t ϵ z_{i}^{t}=\alpha_{t} z_{i}^{0}+\sigma_{t} \epsilon zit=αtzi0+σtϵ 为 t t t 时刻加噪隐变量, ϵ ∼ N ( 0 , I ) \epsilon \sim N(0, I) ϵ∼N(0,I) 为高斯噪声, v θ v_{\theta} vθ 是 LocDiT 预测的速度场。
同时引入二分类损失,训练停止预测器识别语音序列终止位置:
L S t o p = E i ∼ s e q u e n c e [ B C E ( s θ ( h i F S Q ) , 1 [ t o k e n i 为序列最后一位 ] ) ] \mathcal{L}_{Stop }=\mathbb{E}_{i \sim sequence }\left[BCE\left(s_{\theta}\left(h_{i}^{FSQ}\right), \mathbb{1}[ token i 为序列最后一位 ]\right)\right] LStop=Ei∼sequence[BCE(sθ(hiFSQ),1[tokeni为序列最后一位])]
其中 s θ s_{\theta} sθ 为停止概率投影层,BCE 代表二分类交叉熵损失。
最终总损失为两项损失加权和: L = L F M + λ L S t o p L=L_{FM}+\lambda L_{Stop } L=LFM+λLStop。梯度反向传播至整个自回归分层网络(FSQ 依靠直通估计器回传梯度)。在统一损失约束下,各模块协同学习,分别胜任语义规划、特征稳定、声学优化等职能。
3.5 因果音频 VAE
为支持低延迟流式合成,本文采用因果变分自编码器(因果 Audio VAE),将原始音频映射至计算效率更高的隐空间。Audio VAE 采用联合损失训练:梅尔频谱域重建损失、多周期 + 多尺度判别器对抗损失、极小权重 KL 散度正则项。
相比原始波形,隐空间表征大幅降低计算量,同时保留听觉感知质量。因果结构保证编码、解码均可流式执行,适配低延迟实时业务。
Audio VAE 输出连续语音 Token 帧率为 25Hz;架构参考 DAC,编码器、解码器均由堆叠 \\ 因果卷积网络(Causal CNN)\\ 实现。针对 16kHz 单声道音频,编码器通过步长 [2, 5, 8, 8] 的跨步卷积实现 640 倍下采样,将原始音频压缩为 25Hz 隐表征;解码器对隐表征上采样还原波形。
Audio VAE 训练损失包含对抗(GAN)损失、梅尔频谱损失、KL 散度损失,其中 KL 散度损失权重设为 5 × 10 − 5 5 \times 10^{-5} 5×10−5。
4 实验与结果
4.1 实验设置
数据集
-
大规模双语语料:内部自建数据集,总时长 180 万小时,以中英双语语音为主。音频来源覆盖有声书、播客、访谈、广播剧等场景;通过转录文本随机音素替换等数据增广,支持发音纠错等进阶功能。所有音频统一重采样至 16kHz 单声道,依次经过声源分离、语音活动检测(VAD)、自动语音识别(ASR),完成文本 - 音频对齐。
-
Emilia 数据集:公开数据集,总时长 9.5 万小时,包含中英双语语音,主要用于模型对比与消融实验。
模型架构配置
VoxCPM 基于 Megatron 框架实现,本次发布为 0.5B 参数量版本,详细配置见下表:
表 1 VoxCPM-0.5B 模型架构配置
| 模块 | 配置参数 |
|---|---|
| LocEnc | 4 层,隐层维度 1024,前馈网络维度 4096 |
| TSLM | 24 层(MiniCPM-4-0.5B 预训练权重初始化),隐层维度 1024,前馈网络维度 4096 |
| FSQ | 256 维,9 个量化等级 |
| RALM | 6 层,隐层维度 1024,前馈网络维度 4096 |
| LocDiT | 4 层,隐层维度 1024,前馈网络维度 4096 |
| 停止预测器 | 3 层 MLP,隐层维度 1024,输出维度 2 |
| 语音块帧率 | TSLM & RALM 运行在 12.5Hz Token 帧率 |
| Audio VAE | 16kHz 波形 → 25Hz 隐表征,下采样步长 [2,5,8,8] |
训练细节
共训练两个版本模型用于对比:
-
VoxCPM:基于 180 万小时双语语料,40 张 NVIDIA H100,迭代 50 万步;
-
VoxCPM-Emilia:基于 Emilia 公开数据集,24 张 NVIDIA H100,迭代 20 万步。
所有模型采用 AdamW 优化器,峰值学习率 1 × 10 − 4 1 \times 10^{-4} 1×10−4,使用 \\ 预热 - 稳态 - 衰减(WSD)\\ 学习率调度(对收敛至关重要)。衰减阶段学习率降至极低,同时翻倍批次大小,可显著提升零样本音色相似度。
消融实验统一使用 8 张 H100、固定学习率 1 × 10 − 4 1 \times 10^{-4} 1×10−4、迭代 20 万步,保证对比条件一致。LocDiT 推理时以 0.1 概率掩码 LM 引导信息,启用 CFG。
表 2 VoxCPM 系列模型训练配置
| 模型 | 训练阶段 | 学习率 | 单批次 Token 数 | 迭代步数 | 硬件 |
|---|---|---|---|---|---|
| VoxCPM | 稳态 | 1 × 10 − 4 1 \times 10^{-4} 1×10−4 | 4096 | 400K | 40 × H100 |
| VoxCPM | 衰减 | 1 × 10 − 4 → 5 × 10 − 6 1 \times 10^{-4} \to 5 \times 10^{-6} 1×10−4→5×10−6 | 8192 | 100K | 40 × H100 |
| VoxCPM-Emilia | 稳态 | 1 × 10 − 4 1 \times 10^{-4} 1×10−4 | 4096 | 150K | 24 × H100 |
| VoxCPM-Emilia | 衰减 | 1 × 10 − 4 → 5 × 10 − 6 1 \times 10^{-4} \to 5 \times 10^{-6} 1×10−4→5×10−6 | 8192 | 50K | 24 × H100 |
| VoxCPM-ablation | 稳态 | 1 × 10 − 4 1 \times 10^{-4} 1×10−4 | 4096 | 200K | 8 × H100 |
评估指标与评测基准
本文结合客观指标与主观评测开展综合评估:
-
客观指标:采用词错误率 (WER)、\\ 字符错误率 (CER)\\ 衡量语音可懂度;使用说话人嵌入余弦相似度 (SIM) 评估音色克隆效果;通过 DNSMOS 综合评价语音整体质量。
-
主观评测:邀请 20 名母语使用者按照 5 分制打分,完成 \\ 自然度平均分 (N-MOS)与音色相似度平均分 (S-MOS)\\ 两项主观评分。
评测基于两大高难度基准数据集开展:
-
SEED-TTS-EVAL2:覆盖中英双语通用 TTS 场景,包含复杂句式构成的困难测试集,重点考核语音可懂度与音色相似度;
-
CV3-EVAL3:衍生自 CosyVoice 3 评测竞赛,侧重考核真实场景下的语音表现力与音色克隆能力。
基线模型
本文选取当前业界主流开源顶尖 TTS 模型作为对比基线,包括 CosyVoice 系列、MaskGCT、F5-TTS、SparkTTS、FireRedTTS 系列、IndexTTS 2、HiggsAudio v2 等。所有基线模型均使用官方代码与默认参数,实验数据引用其原始论文公开结果。
4.2 核心结果:与前沿 TTS 模型对比
SEED-TTS-EVAL 基准结果
如表 3 所示,VoxCPM 在该基准上取得开源模型中的最优性能。其英文 WER 低至 1.85%,中文 CER 低至 0.93%,超越 IndexTTS 2、CosyVoice 2 等主流竞品;同时保持优秀的音色相似度,英文 SIM 为 72.9%,中文 SIM 为 77.2%。
实验结果证明:本文提出的半离散瓶颈结合分层语义 - 声学建模架构,有效平衡了语音可懂度与表现力,既解决了纯连续模型易不稳定的问题,又弥补了离散模型丢失声学细节的缺陷。
基于公开小数据集训练的 VoxCPM-Emilia 同样取得不俗成绩(英文 WER 2.34%、中文 CER 1.11%),体现出该架构优异的数据利用率与鲁棒性 —— 即便训练数据规模有限,FSQ 瓶颈依旧能稳定语义 - 声学表征的学习过程。
另外,DiTAR 基于音素建模的方案虽然稳定性略优,但 VoxCPM 依托预训练大语言模型 + BPE Token 设计,拥有更强的文本理解能力,且无需依赖外部音素转换工具。消融实验也进一步证实,分层残差声学建模能够从根本上规避纯连续 Token 建模的固有缺陷。
表 3 SEED-TTS-EVAL 基准实验结果
(指标说明:WER/CER 越低代表可懂度越好;SIM 越高代表音色克隆效果越好;✓ 代表开源)
| 模型 | 参数量 | 开源 | 英文 | 中文 | 困难集 | |||
|---|---|---|---|---|---|---|---|---|
| WER | SIM | CER | SIM | CER | SIM | |||
| MegaTTS3 | 0.5B | 2.79 | 77.1 | 1.52 | 79.0 | — | — | |
| DiTAR | 0.6B | 1.69 | 73.5 | 1.02 | 75.3 | — | — | |
| CosyVoice3 | 1.5B | 2.02 | 71.8 | 1.12 | 78.0 | 5.83 | 75.8 | |
| CosyVoice3 | 0.5B | 2.22 | 72.0 | 1.16 | 78.1 | 6.08 | 75.8 | |
| Seed-TTS | — | 2.25 | 76.2 | 1.12 | 79.6 | 7.59 | 77.6 | |
| MiniMax-Speech | — | 1.65 | 69.2 | 0.83 | 78.3 | — | — | |
| MaskGCT | 0.3B | 2.00 | 67.0 | 1.53 | 76.0 | 8.67 | 71.3 | |
| F5-TTS | — | 2.62 | 71.7 | 2.27 | 77.4 | — | — | |
| CosyVoice | 0.3B | 4.29 | 60.9 | 3.63 | 72.3 | 11.75 | 70.9 | |
| CosyVoice2 | 0.5B | ✓ | 3.09 | 57.3 | 1.38 | 75.7 | 6.83 | 72.4 |
| SparkTTS | 0.5B | ✓ | 3.14 | 65.9 | 1.54 | 66.0 | — | — |
| Qwen2.5-Omni | 0.5B | 3.82 | 46.0 | 1.51 | 73.6 | 17.45 | 62.1 | |
| FireRedTTS-2 | 0.5B | 2.72 | 63.2 | 1.14 | 75.2 | 23.37 | 74.7 | |
| OpenAudio-s1-mini | 7B | 1.94 | 55.0 | 1.70 | 68.5 | 7.97 | 64.3 | |
| FireRedTTS | 1.5B | 1.95 | 66.5 | 1.18 | 63.5 | — | — | |
| IndexTTS 2 | 1.5B | ✓ | 1.03 | 76.5 | 1.16 | 74.4 | 7.12 | 74.4 |
| VibeVoice | 3B | 3.04 | 68.9 | 1.16 | 74.0 | — | — | |
| HiggsAudio-v2 | — | 2.44 | 67.7 | 1.50 | 55.07 | — | — | |
| VoxCPM-Emilia | 0.5B | ✓ | 2.34 | 68.1 | 1.11 | 74.0 | 12.46 | 69.8 |
| VoxCPM | 0.5B | ✓ | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 |
CV3-EVAL 基准结果
CV3-EVAL 侧重考核真实场景下的表现力与鲁棒性,实验结果如表 4 所示。VoxCPM 中文 CER 为 3.40%、英文 WER 为 4.04%;在难度最高的 CV3-Hard-EN 测试集上,英文 WER 仅 7.89%,性能超越闭源模型 CosyVoice 3。
该结果充分证明模型应对复杂真实输入的能力,这一优势得益于架构设计:TSLM+FSQ 完成语义与韵律的整体规划,再由 RALM 补足细粒度声学特征,二者结合大幅提升复杂场景下的合成效果。
*表 4 CV3-EVAL 基准实验结果( 代表闭源模型)\
| 模型 | CV3-EVAL | CV3-Hard-ZH | CV3-Hard-EN | |||||
|---|---|---|---|---|---|---|---|---|
| ZH-CER | EN-WER | CER | SIM | DNSMOS | WER | SIM | DNSMOS | |
| F5-TTS | 5.47 | 8.90 | — | — | — | — | — | — |
| SparkTTS | 5.15 | 11.0 | — | — | — | — | — | — |
| GPT-Sovits | 7.34 | 12.5 | — | — | — | — | — | — |
| CosyVoice2 | 4.08 | 6.32 | 12.58 | 72.6 | 3.81 | 11.96 | 66.7 | 3.95 |
| OpenAudio-s1-mini | 4.00 | 5.54 | 18.1 | 58.2 | 3.77 | 12.4 | 55.7 | 3.89 |
| IndexTTS2 | 3.58 | 4.45 | 12.8 | 74.6 | 3.65 | 8.78 | 74.5 | 3.80 |
| HiggsAudio-v2 | 9.54 | 7.89 | 41.0 | 60.2 | 3.39 | 10.3 | 61.8 | 3.68 |
| CosyVoice3-0.5B* | 3.89 | 5.24 | 14.15 | 78.6 | 3.75 | 9.04 | 75.9 | 3.92 |
| CosyVoice3-1.5B* | 3.91 | 4.99 | 9.77 | 78.5 | 3.79 | 10.55 | 76.1 | 3.95 |
| VoxCPM-Emilia | 4.47 | 5.23 | 22.2 | 62.6 | 3.47 | 10.00 | 62.6 | 3.68 |
| VoxCPM | 3.40 | 4.04 | 12.9 | 66.1 | 3.59 | 7.89 | 64.3 | 3.74 |
主观评测结果
主观 MOS 评测结果如表 5 所示,客观指标的结论得到进一步验证。
-
英文场景下:VoxCPM 的音色相似度得分全场最高,自然度也表现优异;
-
中文场景下:IndexTTS 2 在语音自然度上略有优势,但 VoxCPM 的音色相似度小幅领先。
该现象说明:VoxCPM 更擅长保障音色克隆的一致性,而 IndexTTS 2 在中文韵律自然度上表现更佳。同时,VoxCPM-Emilia 的音色相似度处于中上水平,但自然度偏低,直观体现了训练数据规模对模型效果的显著影响。
表 5 自然度与音色相似度主观评测结果
| 模型 | 中文 | 英文 | ||
|---|---|---|---|---|
| N-MOS | S-MOS | N-MOS | S-MOS | |
| MaskGCT | 3.20 ± 0.11 | 3.77 ± 0.11 | 3.84 ± 0.11 | 4.00 ± 0.10 |
| CosyVoice 2 | 3.38 ± 0.12 | 4.01 ± 0.10 | 4.14 ± 0.09 | 3.97 ± 0.10 |
| IndexTTS 2 | 4.25 ± 0.09 | 4.05 ± 0.09 | 4.03 ± 0.10 | 4.16 ± 0.09 |
| VoxCPM-Emilia | 3.79 ± 0.12 | 3.99 ± 0.11 | 3.91 ± 0.10 | 4.10 ± 0.09 |
| VoxCPM | 4.10 ± 0.10 | 4.11 ± 0.10 | 4.11 ± 0.09 | 4.18 ± 0.09 |
4.3 消融实验:半离散瓶颈的作用
本实验基于 Emilia 数据集,探究FSQ 半离散瓶颈以及不同维度设置对模型性能的影响,结果如表 6 所示。
核心结论:移除 FSQ 纯连续模型性能出现断崖式下跌,尤其在困难测试集上中文 CER 高达 24.92%。这直接印证了本文核心假设:若语义规划与声学渲染两大任务在连续空间中相互耦合,模型稳定性会彻底受损;即便采用分层架构,缺少 FSQ 带来的归纳偏置,模型也无法自主完成任务拆分,长语句生成会出现严重的误差累积。
同时实验呈现明显的参数权衡关系:
-
维度过低(如 d4):量化约束过强,表征能力不足,模型无法学习丰富的韵律特征;
-
维度过高(如 d1024):离散化约束变弱,任务耦合问题再次出现;
-
d256(256 维)为最优配置:该维度下的 FSQ 形成了理想的 “特征摘要空间”—— 既具备离散特性、稳定长距离语义规划,又保留足够信息承载韵律与说话人特征,强制模型内部形成合理的分工。
表 6 FSQ 维度消融实验(基于 Emilia 数据集,最终版本选用 256 维)
| 模型配置 | 英文 | 中文 | 中文困难集 | |||
|---|---|---|---|---|---|---|
| WER | SIM | CER | SIM | CER | SIM | |
| 启用 FSQ:d4s9 | 5.18 | 59.3 | 4.05 | 68.0 | 19.55 | 62.3 |
| 启用 FSQ:d16s9 | 3.22 | 60.4 | 1.87 | 70.5 | 14.42 | 66.2 |
| 启用 FSQ:d64s9 | 3.22 | 61.1 | 2.14 | 69.8 | 17.48 | 65.1 |
| 启用 FSQ:d128s9 | 3.43 | 62.2 | 1.67 | 70.7 | 16.76 | 65.7 |
| 启用 FSQ:d256s9 | 2.98 | 62.6 | 1.77 | 70.4 | 18.19 | 64.9 |
| 启用 FSQ:d1024s9 | 3.07 | 62.0 | 2.38 | 69.8 | 20.38 | 64.7 |
| 移除 FSQ:d1024s ∞ | 3.67 | 62.1 | 2.30 | 69.6 | 24.92 | 63.5 |
4.4 消融实验:残差声学建模的作用
本组实验验证RALM 残差声学建模这一核心架构的必要性,结果如表 7 所示。
-
移除 RALM(仅 TSLM 对接 LocDiT):无论增加 TSLM 层数至 30 层,各项指标均大幅下降,困难集性能恶化尤为明显。这证明:问题根源是任务耦合,而非模型参数量不足,显式拆分语义与声学任务是架构优化的关键。
-
RALM 移除历史声学嵌入 E < i E_{<i} E<i:性能显著下滑,说明 RALM 必须依赖历史细粒度声学信息,才能精准还原量化丢失的声学细节。
-
移除残差特征融合:仅使用 TSLM+FSQ 输出对接解码器,同样会造成效果损失。
原版完整配置取得最优结果,充分证明残差连接 + 双分支分工的有效性:TSLM 负责语义 - 韵律规划,RALM 专职声学细节优化,二者特征融合实现优势互补。
表 7 核心架构消融实验
| 模型配置 | 英文 | 中文 | 中文困难集 | |||
|---|---|---|---|---|---|---|
| WER | SIM | CER | SIM | CER | SIM | |
| 原版完整配置 | 2.98 | 62.6 | 1.77 | 70.4 | 18.19 | 64.9 |
| 移除 RALM:24 层 TSLM 直连 LocDiT | 4.34 | 61.8 | 3.05 | 69.4 | 25.00 | 63.8 |
| 移除 RALM:30 层 TSLM 直连 LocDiT | 5.35 | 62.6 | 3.46 | 69.8 | 30.40 | 63.9 |
| RALM 移除 E < i E_{<i} E<i输入 | 4.91 | 60.9 | 4.94 | 68.1 | 27.17 | 61.7 |
| 移除残差特征:仅 TSLM+FSQ 直连 LocDiT | 3.86 | 58.3 | 3.05 | 67.6 | 23.65 | 61.7 |
4.5 训练阶段对性能的影响
前文提到的 \\ 预热 - 稳态 - 衰减(WSD)\\ 学习率调度分为两个核心阶段,本实验对比不同阶段的模型性能,结果如表 8 所示:
-
稳态阶段:模型快速收敛,形成扎实的基础能力;
-
衰减阶段:学习率逐步降低,同时扩大批次大小,模型完成精细化调优,零样本音色相似度、复杂场景鲁棒性提升最为突出。
对比数据可见:进入衰减阶段后,中英双语错误率全面下降,音色相似度持续提升;中文困难集 CER 从 13.22% 降至 8.87%,音色相似度提升 4.4 个百分点,模型应对复杂文本的能力实现质的飞跃。
表 8 不同训练阶段的模型性能
| 训练阶段 | 英文 | 中文 | 中文困难集 | |||
|---|---|---|---|---|---|---|
| WER | SIM | CER | SIM | CER | SIM | |
| 稳态阶段 | 2.05 | 69.7 | 0.99 | 75.1 | 13.22 | 68.6 |
| 衰减阶段 | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 |
4.6 LM 引导对 LocDiT 的影响
本组实验探究无分类器引导(CFG)的缩放系数对模型的影响,CFG 用于控制 LM 分支对 LocDiT 的引导强度,实验结果呈现非单调的权衡关系:语音可懂度与音色相似度随 CFG 数值变化此消彼长。
-
CFG=1.0(关闭引导):模型几乎不受文本语义约束,错误率极高、音色相似度差;
-
CFG=2.0:综合效果最优,在不损失可懂度的前提下最大化音色相似度;
-
CFG≥3.0:引导强度过高,模型过度偏向声学特征,语音可懂度明显下降。
因此本文最终选用 CFG=2.0 作为推理默认参数。
表 9 LocDiT 的 LM 引导强度消融实验(基于 VoxCPM)
| CFG 系数 | 英文 | 中文 | 中文困难集 | |||
|---|---|---|---|---|---|---|
| WER | SIM | CER | SIM | CER | SIM | |
| 1.0(关闭 CFG) | 16.32 | 55.1 | 14.47 | 61.5 | 56.87 | 43.0 |
| 1.5 | 1.86 | 72.1 | 1.16 | 77.0 | 9.60 | 73.9 |
| 2.0 | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 |
| 3.0 | 2.16 | 71.4 | 1.12 | 74.7 | 13.22 | 65.0 |
| 5.0 | 12.78 | 60.7 | 17.23 | 59.4 | 48.46 | 39.9 |
4.7 分析与讨论
分层表征可视化分析
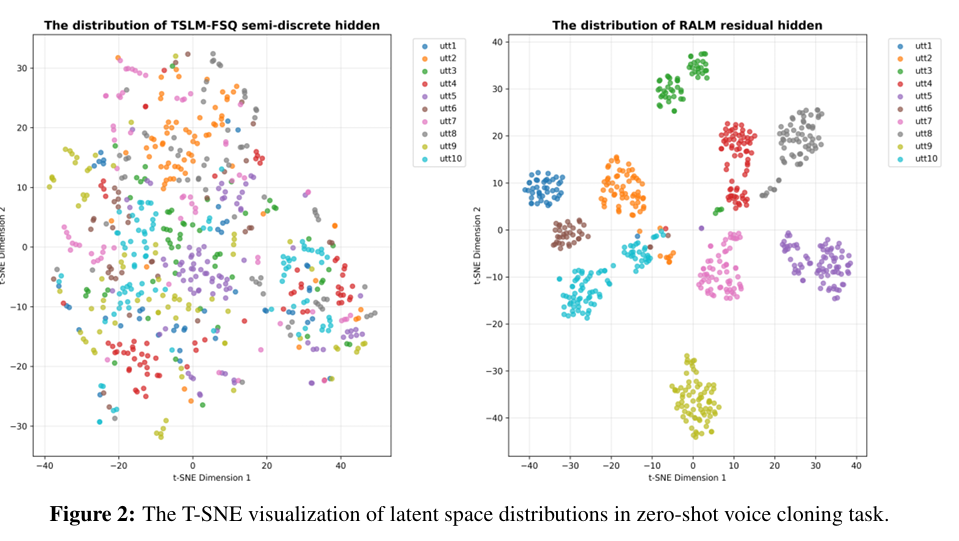
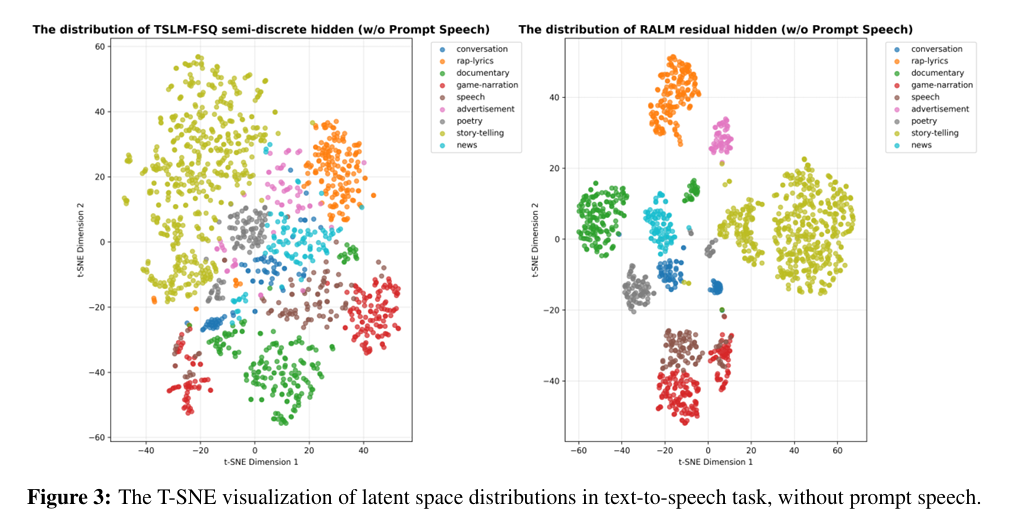
为验证 “语义 - 声学特征隐式解耦” 的核心猜想,本文采用 t-SNE 对模型内部表征做降维可视化:
-
零样本音色克隆场景(图 2):不同颜色对应不同未见过的说话人语句。TSLM+FSQ 的输出表征与文本内容、韵律结构强相关;而 RALM 输出的残差特征则呈现明显的说话人区分度,专门承载人声特质。二者分工完全符合架构设计预期。
-
纯文本转语音场景(无语音提示,图 3):输入新闻、诗歌、日常对话、说唱等不同体裁文本时,TSLM+FSQ 表征会按照文本语义体裁自动聚类,证明预训练大语言模型主干能够直接从文本中推理出匹配的韵律风格;而 RALM 输出在同一体裁内部存在丰富变化,负责为基础韵律框架补充细腻的声学细节。
上下文感知与高表现力合成能力
依托强大的文本理解能力与大规模训练数据,VoxCPM 具备优秀的上下文感知合成能力:无需额外语音提示,模型即可根据文本语义、文体风格自动生成适配的韵律、语气与表达风格。相关听觉效果可参考项目官方音频样例。
扩展性与推理效率
-
数据扩展性:对比 VoxCPM-Emilia 与完整版 VoxCPM 可见,随着训练数据规模提升,模型各项性能持续优化,证明该架构能够充分利用海量数据学习复杂语音规律,扩展性良好。
-
推理效率:0.5B 参数量的 VoxCPM 在单张消费级 NVIDIA RTX 4090 显卡上,实时因子 (RTF) 低至 0.17,推理速度远快于语音播放速度,完全满足落地部署、实时交互的工程要求。
5 结论
本文提出一款全新的无 Tokenizer TTS 模型 VoxCPM,可实现具备上下文感知能力的语音生成与高还原度音色克隆。模型通过半离散残差表征 + 分层语义 - 声学建模的统一端到端框架,彻底解决了语音合成领域长期存在的表现力与稳定性相互制衡的难题。
本方案引入可微量化瓶颈,让架构天然形成职能划分:Text-Semantic Language Model 建模高层语义与韵律结构,Residual Acoustic Model 还原细粒度声学特征。该设计不仅摆脱了对外部语音 Tokenizer 的依赖,也根治了纯连续自回归模型的误差累积问题。
大量实验证明,VoxCPM 在开源零样本 TTS 任务中达到当前顶尖水平,语音可懂度与音色克隆效果双双优异。本工作也验证了一个核心结论:基于结构化、正则化隐空间的建模思路,是实现高表现力音频生成的有效技术路线。
局限性
本研究仍存在若干待优化方向,也是未来的研究重点:
-
多语言能力有限:模型主要针对中英双语优化,对其他语种的泛化效果尚不明确;
-
语音属性可控性不足:针对精细韵律、情绪表达的手动调控能力较弱,缺少直观、精准的控制方案;
-
音频采样率受限:当前 Audio VAE 仅支持 16kHz 音频生成,无法满足 24kHz、44.1kHz 等高保真音频的应用需求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)