基于数据挖掘的旅游景点个性化推荐系统设计与实现,Apriori和FP-Growth算法挖掘景点之间的关联规则
第1章 绪论
1.1 研究背景与意义
1.1.1 研究背景
随着信息技术的飞速发展和互联网的普及,旅游业正经历着前所未有的变革。传统的旅游模式已无法满足现代游客日益多样化的需求,智慧旅游应运而生。智慧旅游利用云计算、物联网、大数据、人工智能等新一代信息技术,通过互联网/移动互联网,借助便携的终端上网设备,主动感知旅游资源、旅游经济、旅游活动等方面的信息,及时发布,让人们能够及时安排和调整工作与旅游计划,从而达到对各类旅游信息的智能感知、方便利用的效果。在智慧旅游的背景下,个性化推荐系统成为提升用户体验的关键技术。随着旅游信息量的爆炸式增长,游客在面对海量景点信息时往往感到无所适从,难以做出最佳的旅游决策。个性化推荐系统能够根据用户的历史行为、兴趣偏好、地理位置等信息,为用户推荐符合其需求的景点,大大减少了用户的信息搜索成本,提升了旅游体验。
1.1.2 研究意义
安阳作为中国历史文化名城,拥有丰富的旅游资源,包括殷墟、红旗渠、中国文字博物馆等众多著名景点。然而,目前针对安阳旅游的个性化推荐服务相对较少,游客难以获取符合自身兴趣的景点推荐信息。因此,开发一个基于数据挖掘的安阳旅游景点个性化推荐系统具有重要的现实意义。
数据挖掘技术在旅游领域具有广泛的应用价值。通过对游客行为数据、评论数据、景点数据等进行挖掘分析,可以发现隐藏在数据背后的有价值的信息和模式。数据挖掘技术可以用于游客行为分析,了解游客的兴趣偏好、消费习惯、游览模式等。数据挖掘技术可以用于景点推荐,提高推荐的准确性和个性化程度。数据挖掘技术可以用于景点评价和舆情监控,了解游客的满意度和意见反馈。数据挖掘技术可以用于旅游趋势预测,为旅游规划和营销策略制定提供依据。
1.2 国内外研究现状
推荐系统的研究始于20世纪90年代,随着电子商务的兴起而得到快速发展。目前,推荐系统已经广泛应用于电子商务、社交网络、在线视频、音乐、新闻等各个领域。推荐算法主要可以分为基于内容的推荐、协同过滤推荐、混合推荐等。
基于内容的推荐根据用户历史行为和物品特征进行推荐,优点是可解释性强,缺点是存在信息过载和新物品冷启动问题。协同过滤推荐根据用户之间的相似性或物品之间的相似性进行推荐,优点是不需要物品的领域知识,缺点是存在数据稀疏性和冷启动问题。混合推荐算法结合多种推荐算法的优点,可以弥补单一算法的不足。
1.3 研究内容与主要工作
本文主要研究内容如下:
- 数据采集与预处理:收集安阳旅游景点数据和游客评论数据,对数据进行清洗、去重、分词等预处理操作。
- 基于情感分析的评论挖掘:采用SVM和朴素贝叶斯算法对游客评论进行情感分析,挖掘景点的服务质量和游客满意度,并对两种算法的效果进行对比。
- 基于关联规则的景点挖掘:采用Apriori和FP-Growth算法挖掘景点之间的关联规则,发现游客的游览模式,并对两种算法的效率和效果进行对比。
- 混合推荐算法设计:结合情感分析和关联规则的结果,设计动态加权混合推荐算法,为用户提供个性化的景点推荐。
- 系统设计与实现:设计并实现一个基于Flask的安阳旅游景点个性化推荐系统,包括用户端和管理后台两大模块。
- 可视化分析与展示:集成ECharts数据可视化组件,实现景点热度分析、情感分布展示、关联规则网络图等多维度数据可视化功能。
1.4 结构安排
本文共分为七章,具体结构安排如下:
第一章为绪论,介绍了研究背景与意义、国内外研究现状、研究内容与主要工作以及论文结构安排。
第二章为相关技术介绍,介绍了系统开发所使用的技术栈和数据挖掘算法。
第三章为系统需求分析与总体设计,对系统进行了需求分析,设计了系统的总体架构和数据库结构。
第四章为系统关键模块设计与实现,详细介绍了各个模块的设计与实现。
第五章为系统实现与界面展示,展示了系统的功能实现。
第六章为系统测试与分析,介绍了测试环境与方法,并给出了测试结果。
第七章为总结与展望,总结了论文的工作,指出了系统存在的不足,并对未来的研究方向进行了展望。
第2章 相关技术介绍
2.1 开发框架与技术栈
2.1.1 Flask Web框架
Flask是一个用Python编写的轻量级Web应用框架。它被称为"微框架",因为它使用简单的核心,用扩展增加其他功能。Flask的主要特点包括:轻量级、灵活性、易于扩展、良好的文档和社区支持。Flask的核心非常简单,不需要依赖大型库,易于学习和使用。Flask提供了高度的灵活性,开发者可以根据项目需求选择合适的扩展。Flask拥有丰富的第三方扩展,可以轻松地添加数据库支持、表单验证、用户认证等功能。本系统选择Flask作为Web框架,主要是因为它轻量级、灵活性强,适合中小型Web应用的开发。
2.1.2 Bootstrap前端框架
Bootstrap是Twitter推出的一个用于前端开发的开源工具包。Bootstrap的主要特点包括:响应式设计、丰富的组件、易于定制、跨浏览器兼容。Bootstrap内置了响应式布局,可以适应不同屏幕尺寸的设备。Bootstrap提供了大量的预制组件,如导航栏、按钮、表单、模态框等,可以快速构建美观的界面。Bootstrap提供了LESS版本,开发者可以轻松地定制样式。Bootstrap兼容主流的浏览器,确保应用在不同浏览器中的一致性。本系统使用Bootstrap 5版本进行前端开发,Bootstrap 5相比之前的版本,移除了对jQuery的依赖,性能更好,同时也提供了更多的组件和更好的响应式支持。
2.2 数据挖掘与机器学习算法
2.2.2 情感分析算法
情感分析是指用自然语言处理、文本分析和计算语言学等方法,对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。本文主要使用了两种情感分析算法:支持向量机和朴素贝叶斯。
2.2.2 关联规则挖掘算法
关联规则挖掘是数据挖掘中的一个重要研究方向,用于发现数据集中项之间的关联关系。本文主要使用了两种关联规则挖掘算法:Apriori算法和FP-Growth算法。
(1)Apriori算法原理
Apriori算法是一种经典的关联规则挖掘算法,由Agrawal和Srikant于1994年提出。它基于频繁项集的性质:如果一个项集是频繁的,那么它的所有子集也是频繁的。反之,如果一个项集是非频繁的,那么它的所有超集也是非频繁的。
(2)FP-Growth算法原理及其优势
FP-Growth(Frequent Pattern Growth)算法是由Han等人在2000年提出的一种高效的关联规则挖掘算法。它通过构建FP-Tree来压缩数据集,避免多次扫描数据集和生成大量候选项集,从而大大提高了算法效率。
FP-Growth算法相比Apriori算法的优势在于:
(1)只需要扫描两次数据集:一次用于构建频繁项头表,一次用于构建FP-Tree
(2)不需要生成候选项集,直接从FP-Tree中挖掘频繁项集
(3)通过FP-Tree压缩数据集,减少了内存占用
表2-1 Apriori与FP-Growth算法对比表
|
算法 |
时间复杂度 |
空间复杂度 |
适用场景 |
|
Apriori |
需多次扫描数据库,每轮生成大量候选集并计数,时间复杂度较高,通常为 O(N × L × M)(N为事务数,L为最大项集长度,M为候选集数量) |
需存储候选集,当候选项集数量庞大时内存占用较大 |
适合小规模、稀疏数据集;由于需多次扫描且候选集易爆炸,大数据集下效率较低 |
|
FP-Growth |
仅需两次扫描数据库,构建FP树后递归挖掘,无需生成候选集,速度通常远快于Apriori,时间复杂度接近 O(N × L)(N为事务数,L为事务平均长度) |
需存储FP树及其条件模式基,内存占用相对较高,但压缩了事务信息 |
适合大规模、稠密数据集;对长模式挖掘效果尤佳,是目前频繁模式挖掘的主流算法 |
第3章 系统需求分析与总体设计
3.1 系统需求分析
3.1.1 用户角色分析
本系统主要包含两种用户角色:普通用户和管理员。普通用户可以通过注册账号登录系统,浏览景点信息、查看推荐列表、提交评论等。管理员拥有最高权限,可以对系统进行全面管理,包括用户管理、景点管理、评论审核、模型训练、数据统计分析等功能。
3.1.2 功能性需求
系统的主要功能需求包括:
(1)用户认证功能:支持用户注册、登录、退出、密码修改等操作
(2)景点浏览功能:用户可以查看所有景点的列表,支持按分类、价格、评分等条件筛选
(3)景点详情功能:用户可以查看景点的详细信息,包括景点介绍、评论列表、情感分析结果等
(4)评论提交功能:用户可以对游览过的景点进行评论,提交自己的游览体验
(5)个性化推荐功能:系统根据用户的行为和偏好,为用户推荐可能感兴趣的景点
(6)用户管理功能:管理员可以查看、编辑、删除用户信息
(7)景点管理功能:管理员可以添加、编辑、删除景点信息
(8)评论管理功能:管理员可以审核用户的评论,删除违规评论
(9)模型训练功能:管理员可以触发情感分析模型和关联规则挖掘模型的训练
(10)统计分析功能:系统提供景点热度分析、情感分布展示、关联规则网络图等多维度数据分析功能
3.1.3 非功能性需求
系统的非功能性需求包括:
(1)性能需求:系统应能够在3秒内响应用户请求,支持100个并发用户
(2)安全性需求:用户密码使用加密存储,敏感数据传输使用HTTPS协议
(3)可用性需求:系统应提供友好的用户界面,操作简单易懂
(4)可扩展性需求:系统应采用模块化设计,便于功能扩展
(5)兼容性需求:系统应兼容主流的浏览器,包括Chrome、Firefox、Safari、Edge等
3.2 系统总体架构设计
3.2.1 系统层次架构
系统采用三层架构设计,包括表现层、业务层和数据层。
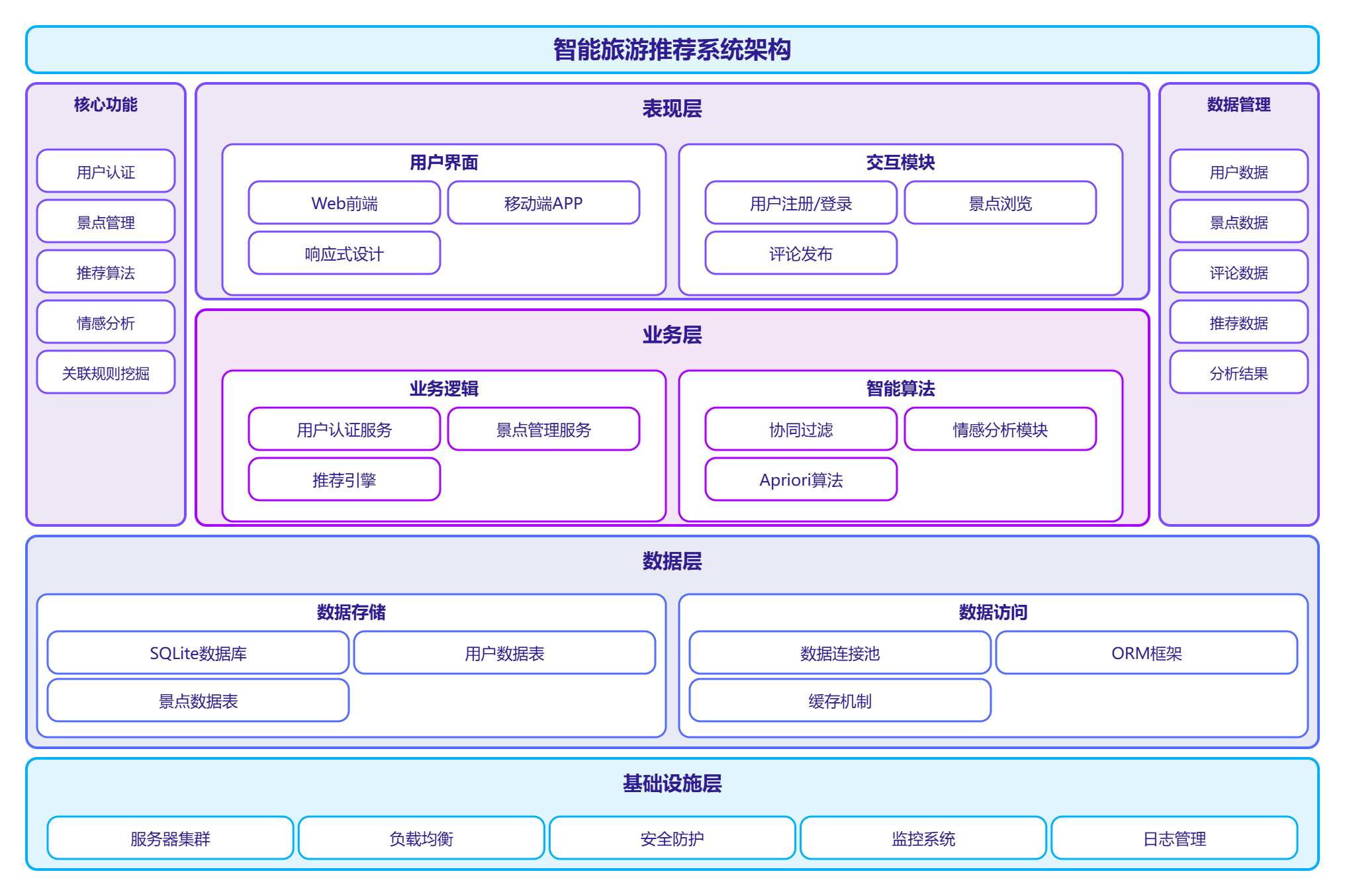
图3-1 系统架构图
3.2.2 系统功能模块划分
系统主要包含以下功能模块:
(1)用户模块:负责用户注册、登录、退出等用户认证功能
(2)景点模块:负责景点的增删改查、详情展示等功能
(3)评论模块:负责评论的提交、审核、展示等功能
(4)推荐模块:负责基于混合推荐算法生成个性化推荐列表
(5)情感分析模块:负责对评论进行情感分析,提取情感特征
(6)关联规则挖掘模块:负责挖掘景点之间的关联规则
(7)可视化模块:负责数据的可视化展示
(8)管理后台模块:提供系统管理功能,包括用户管理、景点管理、评论审核等
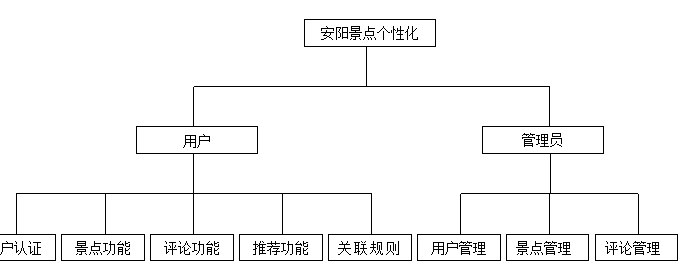
图3-2 系统功能图
3.3 数据库设计
3.3.1 数据库概念结构设计
根据系统的功能需求,设计了以下实体:用户、景点、评论、用户历史、关联规则等。实体之间的关系如下:
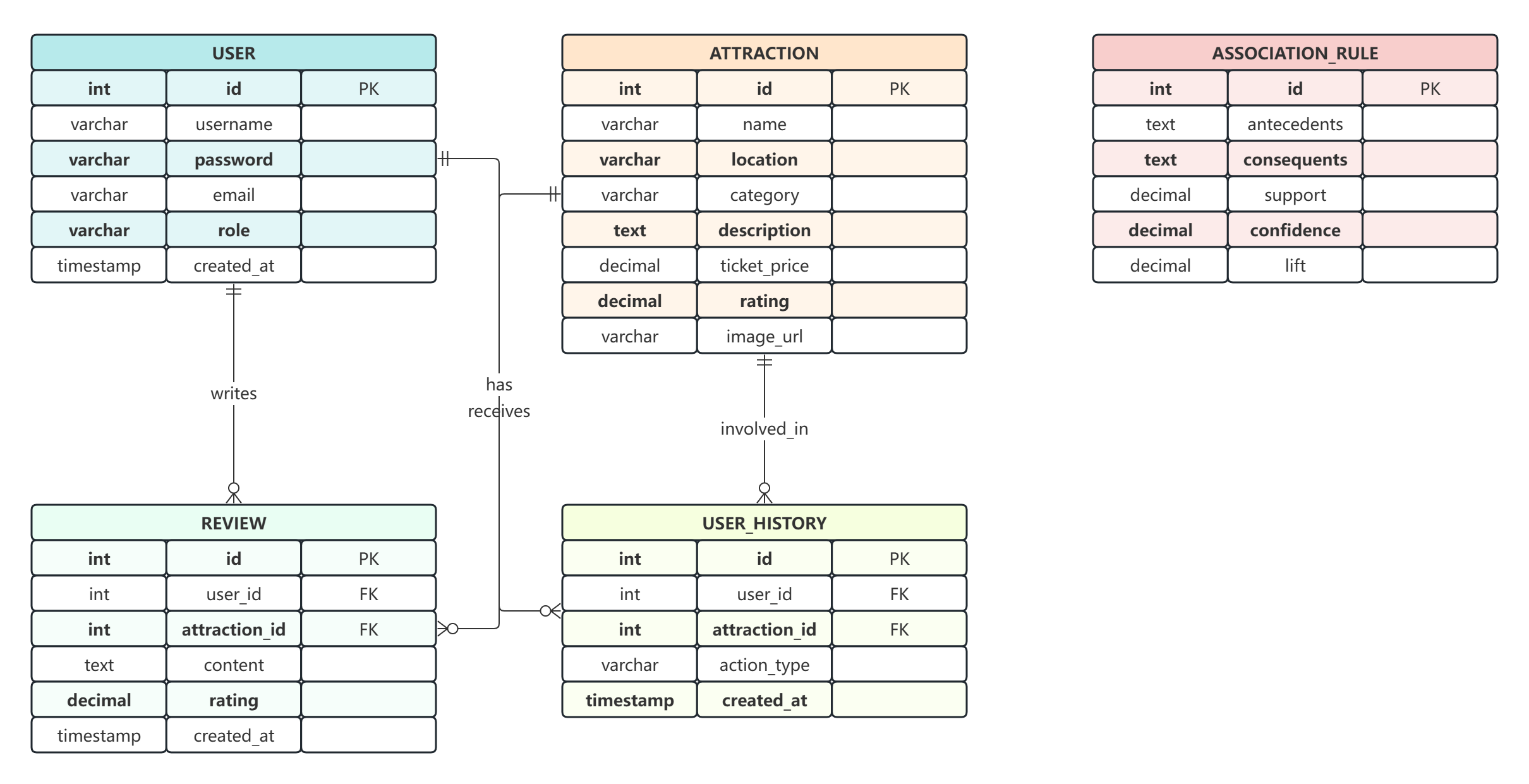
图3-3 数据库E-R图
3.3.2 数据库逻辑结构设计
根据E-R图,设计了以下数据表:
表3-1 用户表
|
字段名 |
数据类型 |
约束/说明 |
字段名 |
|
id |
INTEGER |
主键,自增 |
id |
|
username |
VARCHAR(50) |
唯一,非空,用户名 |
username |
|
password |
VARCHAR(255) |
非空,存储加密后的密码 |
password |
|
|
VARCHAR(100) |
可选,用户邮箱 |
|
|
role |
VARCHAR(20) |
默认为'user',可选'admin' |
role |
|
created_at |
DATETIME |
默认为当前时间,注册时间 |
created_at |
表3-2 景点表
|
字段名 |
数据类型 |
约束/说明 |
字段名 |
|
id |
INTEGER |
主键,自增 |
id |
|
name |
VARCHAR(100) |
非空,景点名称 |
name |
|
location |
VARCHAR(255) |
景点位置描述 |
location |
|
category |
VARCHAR(50) |
景点类型(如自然风光、历史古迹) |
category |
|
description |
TEXT |
详细描述 |
description |
|
ticket_price |
DECIMAL(10,2) |
门票价格,可空 |
ticket_price |
|
rating |
FLOAT |
综合评分(0-5),可计算得出 |
rating |
|
image_url |
VARCHAR(255) |
景点图片的URL |
image_url |
表3-3 评论表
|
字段名 |
数据类型 |
约束/说明 |
字段名 |
|
id |
INTEGER |
主键,自增 |
id |
|
user_id |
INTEGER |
外键,关联User(id) |
user_id |
|
attraction_id |
INTEGER |
外键,关联Attraction(id) |
attraction_id |
|
content |
TEXT |
评论内容 |
content |
|
rating |
INTEGER |
用户评分(1-5) |
rating |
|
created_at |
DATETIME |
默认为当前时间,提交时间 |
created_at |
|
status |
VARCHAR(20) |
默认为'pending',可选'approved'/'rejected',用于管理员审核 |
status |
表3-4 用户历史表
|
字段名 |
数据类型 |
约束/说明 |
字段名 |
|
id |
INTEGER |
主键,自增 |
id |
|
user_id |
INTEGER |
外键,关联User(id) |
user_id |
|
attraction_id |
INTEGER |
外键,关联Attraction(id) |
attraction_id |
|
action_type |
VARCHAR(50) |
行为类型,如'view'(浏览)、'favorite'(收藏) |
action_type |
|
created_at |
DATETIME |
默认为当前时间,行为发生时间 |
created_at |
表3-5 关联规则表
|
字段名 |
数据类型 |
约束/说明 |
字段名 |
|
id |
INTEGER |
主键,自增 |
id |
|
antecedents |
VARCHAR(255) |
前件景点ID组合,如"1,3,5" |
antecedents |
|
consequents |
VARCHAR(255) |
后件景点ID组合,如"2,4" |
consequents |
|
support |
FLOAT |
规则支持度 |
support |
|
confidence |
FLOAT |
规则置信度 |
confidence |
第4章 系统关键模块设计与实现
4.1 数据采集与预处理
4.1.1 数据来源
本系统的数据来源主要包括:
(1)景点数据:从携程网站收集安阳旅游景点的基本信息
(2)评论数据:从携程网站收集游客对景点的评论数据
(3)用户行为数据:通过系统收集用户的浏览、点击、评论等行为数据。
4.1.2 中文文本预处理
中文文本预处理是情感分析的重要步骤,主要包括:
(1)分词:使用结巴分词工具对中文文本进行分词处理
(2)去停用词:去除无意义的停用词,如"的"、"了"、"在"等
(3)向量化:使用TF-IDF方法将文本转换为数值向量
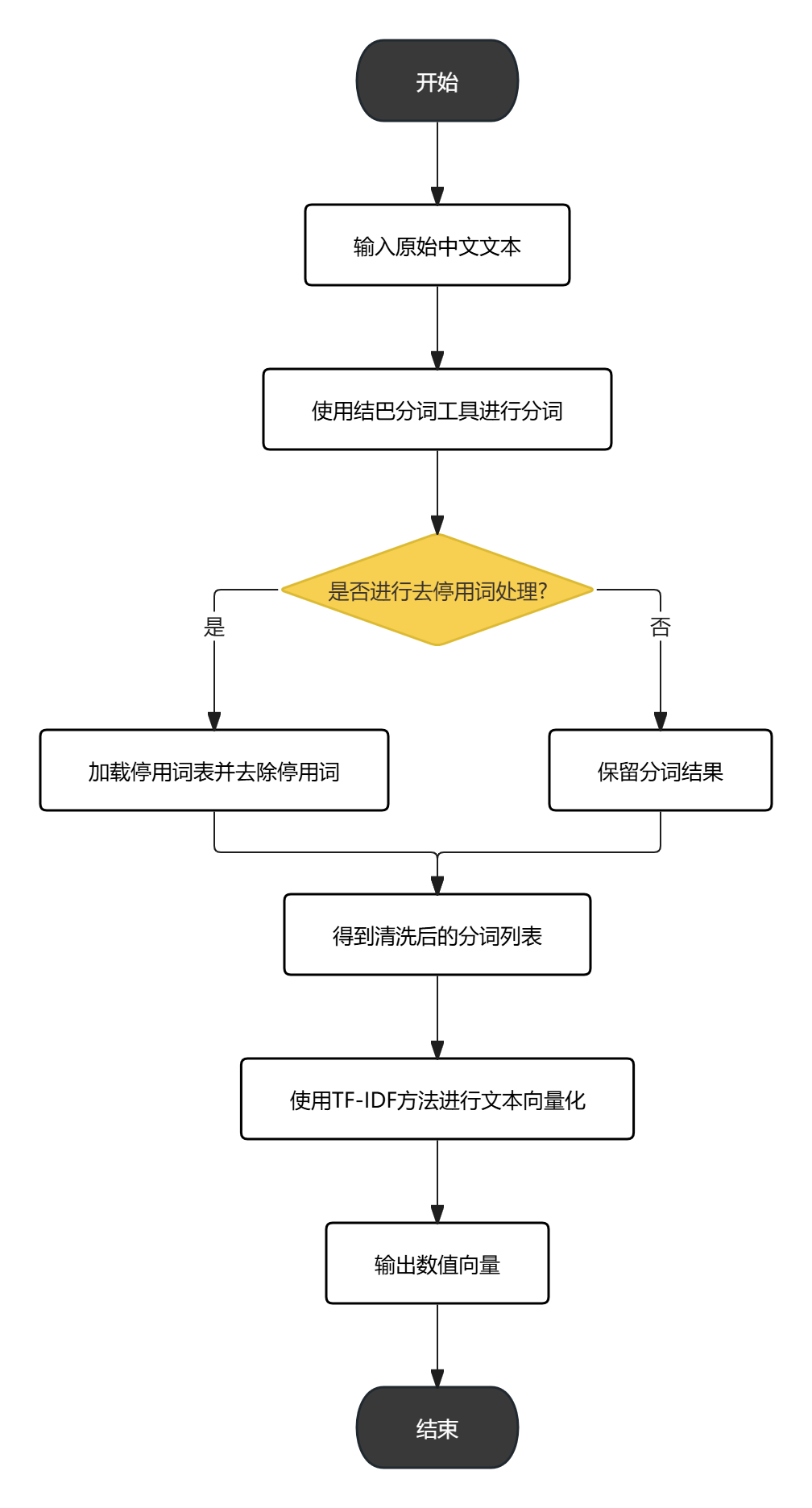
图4-1 文本预处理流程图
4.2 基于情感分析的评论挖掘模块
4.2.1 训练数据准备与标注
从收集的评论数据中,选取部分评论进行人工标注,标注为正面、中性、负面三类情感倾向。标注好的数据作为训练集,用于训练情感分析模型。
标注标准如下:
正面:表达满意、赞赏、推荐等积极情感的评论
中性:客观描述、无明显情感倾向的评论
负面:表达不满、批评、抱怨等消极情感的评论
4.2.2 SVM情感分类模型的构建与训练
使用Scikit-learn库实现SVM情感分类模型。首先使用TF-IDF将文本转换为数值向量,然后训练SVM分类器。
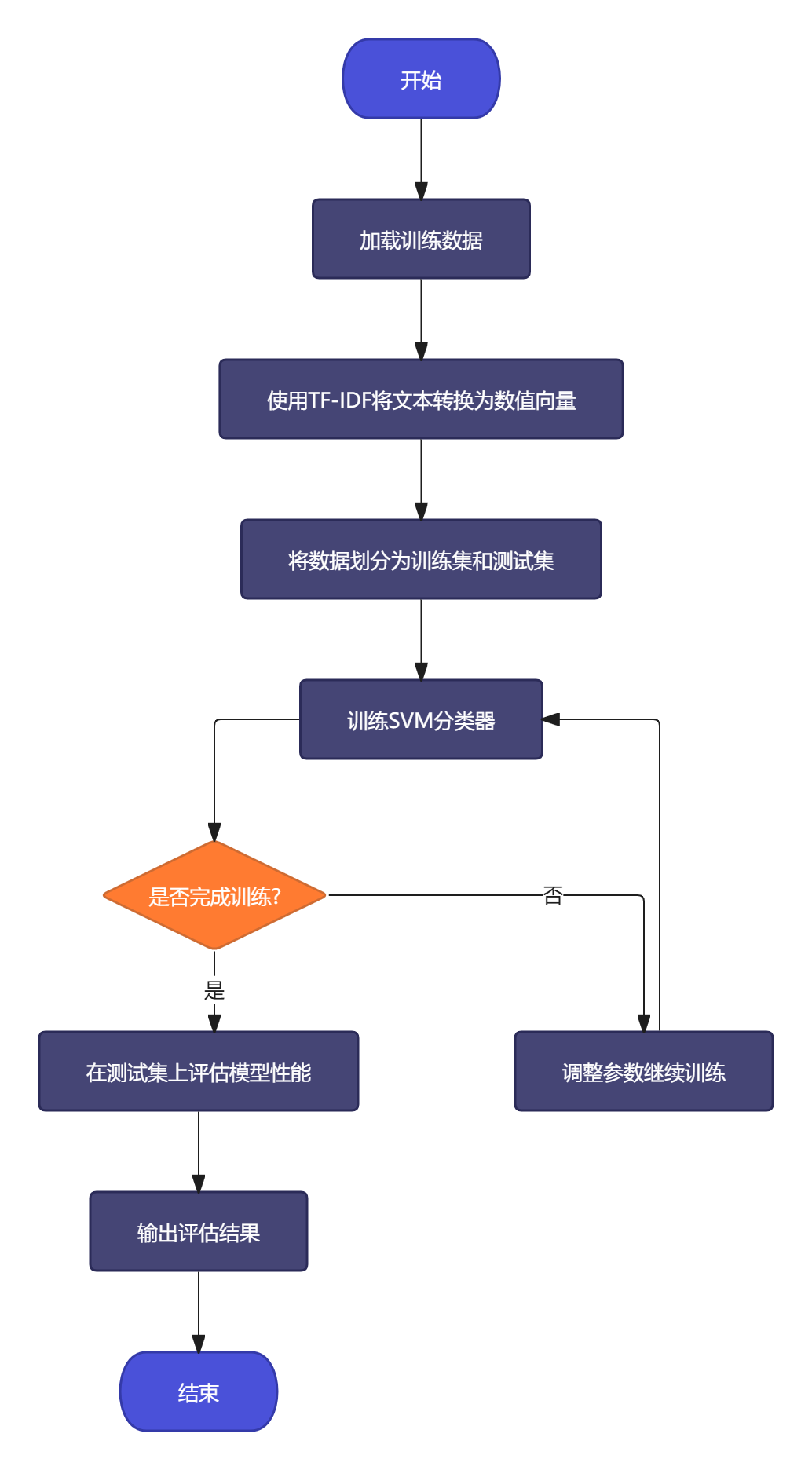
图4-2 SVM模型训练流程图
4.2.3 朴素贝叶斯情感分类模型的构建与训练
使用Scikit-learn库实现多项式朴素贝叶斯情感分类模型。
4.2.4 模型评估与对比
使用准确率、精确率、召回率、F1值等指标对模型进行评估和对比。
4.2.5 情感分析结果在推荐中的应用
情感分析的结果用于景点的情感评分计算。景点的情感评分计算公式如下:
Sentiment_Score(a) = (Σ_{r∈R_a} S(r)) / |R_a|
其中,Sentiment_Score(a)是景点a的情感评分,R_a是景点a的所有评论集合,S(r)是评论r的情感得分(正面为1,中性为0,负面为-1),|R_a|是评论的数量。
景点的情感评分作为推荐算法的一个重要特征,用于计算推荐得分。
4.3 基于关联规则的景点挖掘模块
4.3.1 事务数据的构建
为了挖掘景点之间的关联规则,需要构建事务数据。每个事务代表一个用户的游览序列,包含该用户游览过的景点。
4.3.2 基于Apriori算法的景点关联规则挖掘
使用Mlxtend库实现Apriori算法挖掘景点关联规则。
挖掘得到的关联规则按照提升度排序,选择提升度大于1的规则作为有效规则。
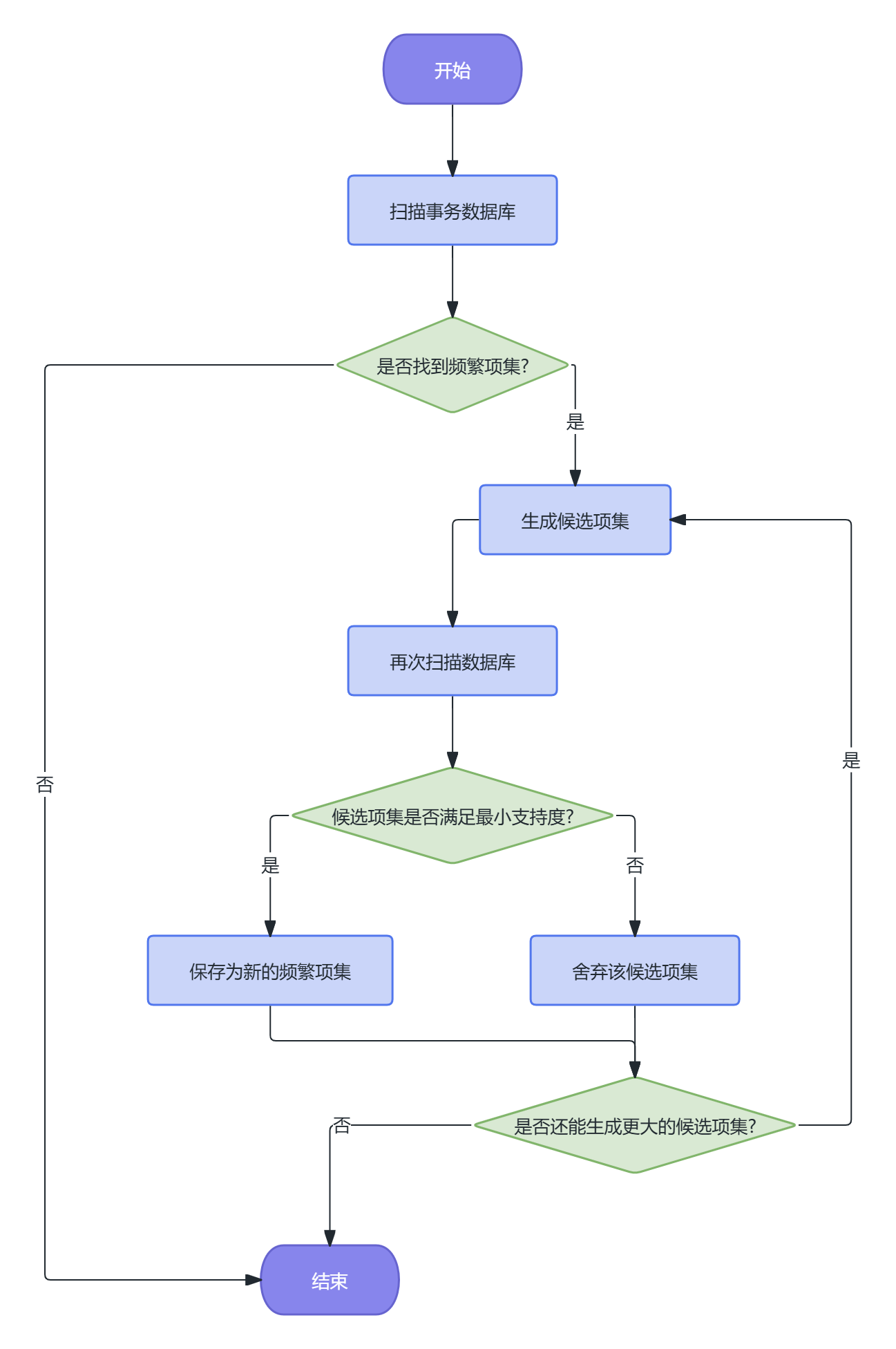
图4-3 Apriori算法流程图
4.3.3 基于FP-Growth算法的景点关联规则挖掘
使用Mlxtend库实现FP-Growth算法挖掘景点关联规则。FP-Growth算法通过构建FP-Tree来压缩数据集,避免了Apriori算法需要多次扫描数据集的问题,提高了算法效率。
4.3.4 算法结果对比与规则筛选
对比Apriori和FP-Growth两种算法的运行时间和挖掘结果,选择更高效的算法用于系统。同时,根据置信度和提升度筛选出高质量的关联规则。
4.4 混合推荐算法设计
4.4.1 推荐算法总体流程
混合推荐算法的总体流程如下:
(1)获取用户的历史行为数据
(2)使用前置过滤去除用户已游览过的景点
(3)计算候选景点的推荐得分
(4)按照推荐得分排序,生成推荐列表
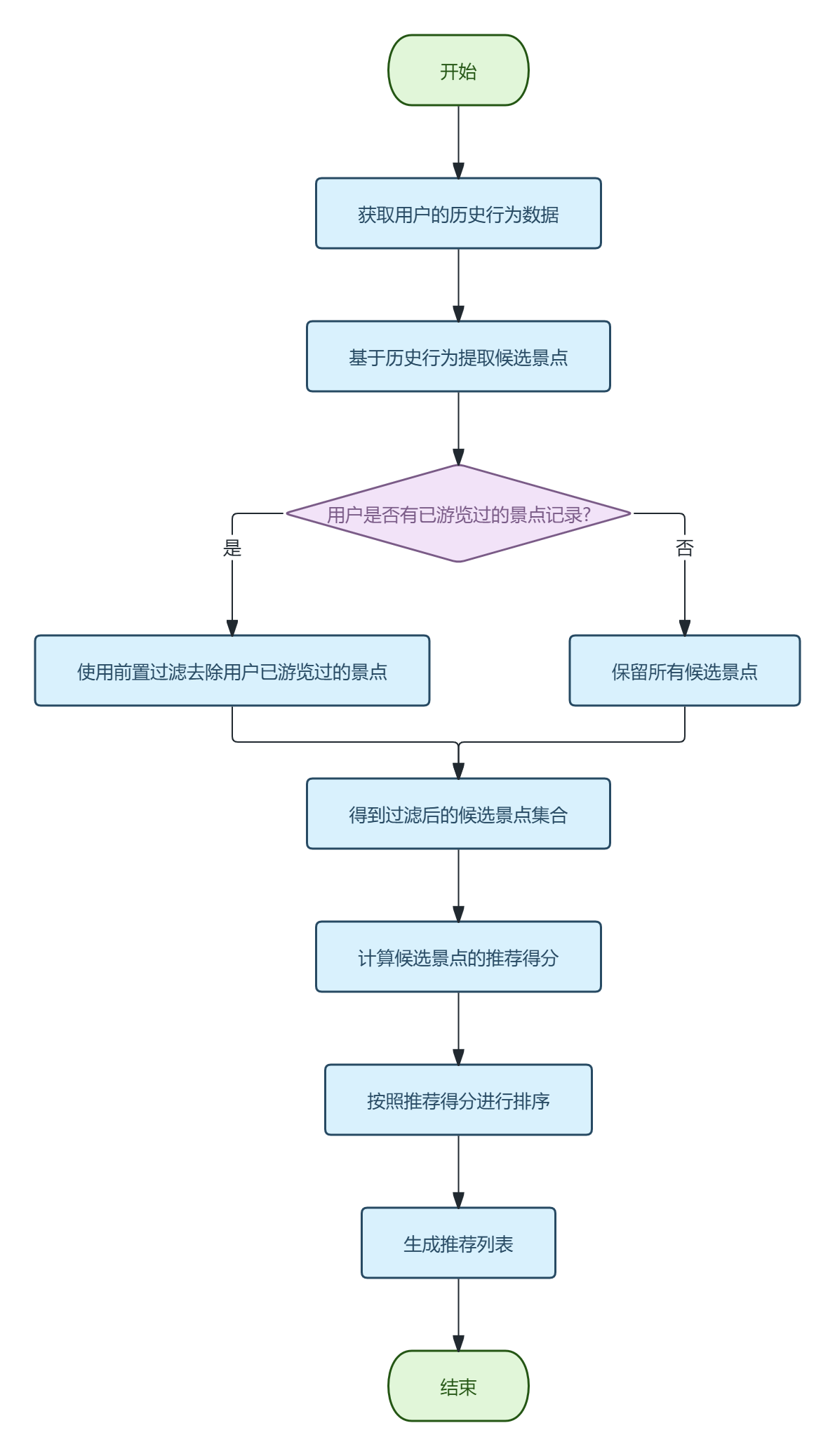
图4-4 混合推荐算法流程
4.4.2 基于用户协同的过滤
基于用户的协同过滤通过找到与当前用户相似的其他用户,推荐这些相似用户喜欢的景点给当前用户。
4.4.3 动态加权混合推荐策略
动态加权混合推荐策略综合考虑情感分析结果、关联规则和景点热度,计算推荐得分。
4.5 可视化分析与展示模块
4.5.1 基于ECharts的景点热度分析
使用ECharts的柱状图和饼图展示景点的热度分析。柱状图展示各个景点的评论数或浏览数,饼图展示景点类型的分布情况。
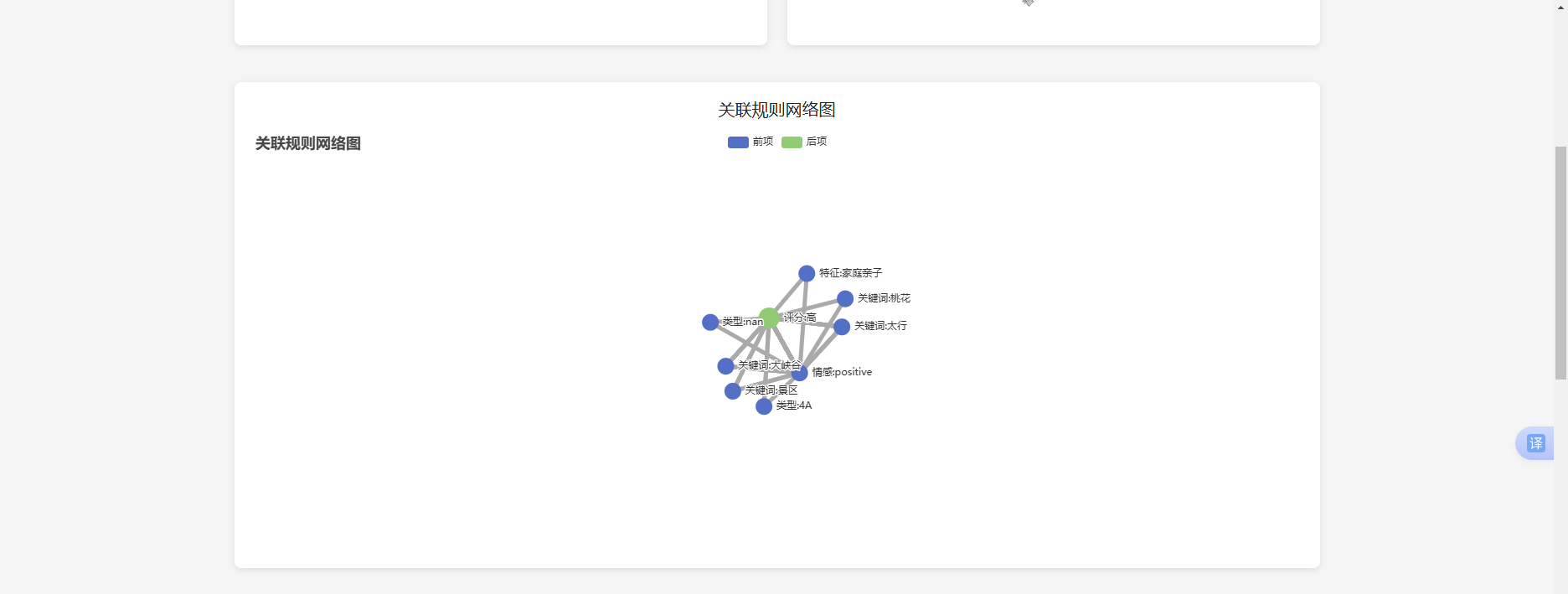
4.5.2 关联规则网络图展示
使用ECharts的关系图展示景点之间的关联规则网络,节点表示景点,边的粗细表示关联强度。
第5章 系统实现与界面展示
5.1 开发环境与工具
5.2 用户端功能实现
5.2.1 用户认证
用户认证模块实现了用户的注册、登录、退出等功能。注册时需要填写用户名、密码、邮箱等信息,系统会对用户名和邮箱进行唯一性检查。登录时使用用户名和密码进行验证,验证成功后创建会话。密码使用bcrypt进行加密存储,确保用户信息安全。
5.2.2 景点浏览与详情页
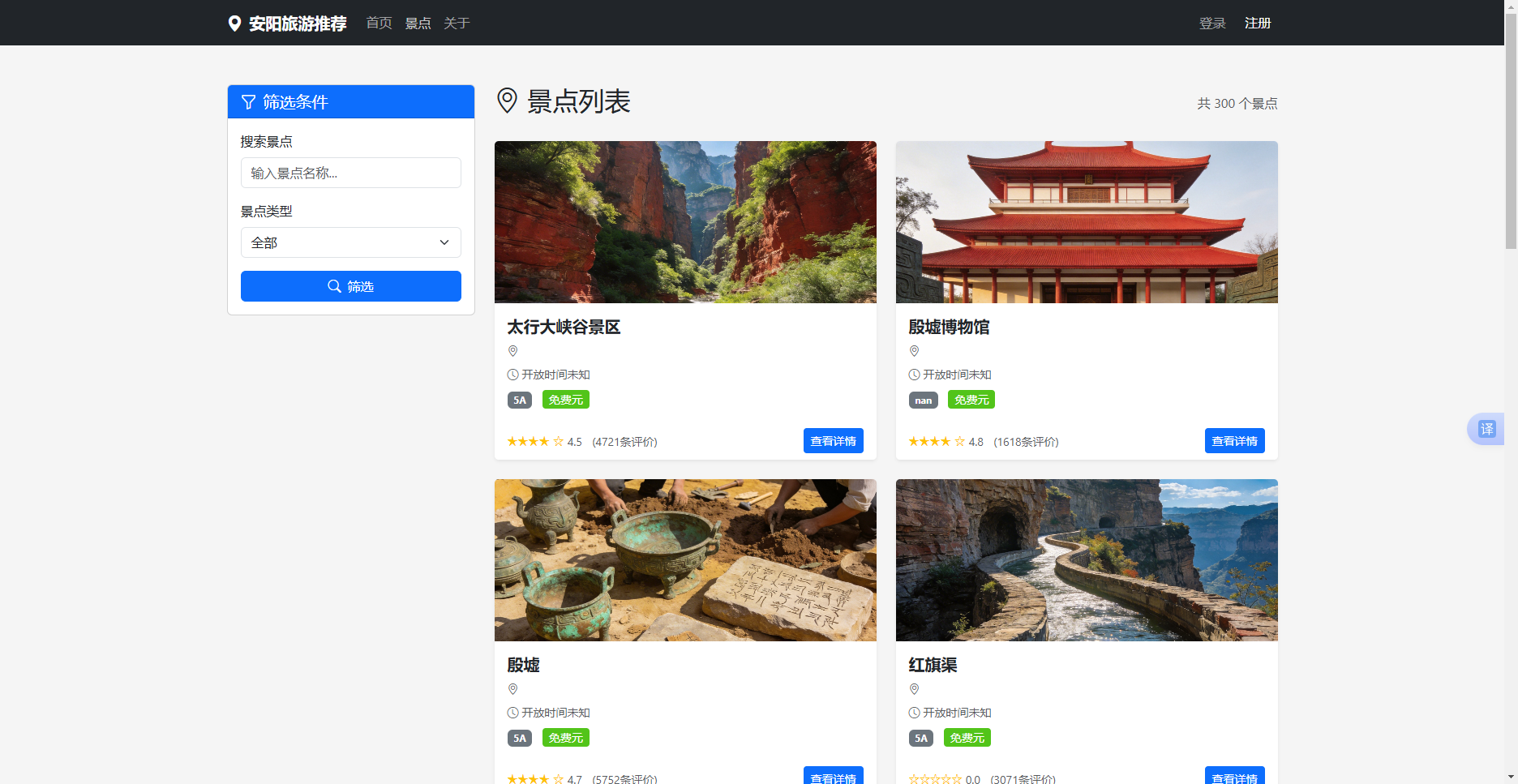
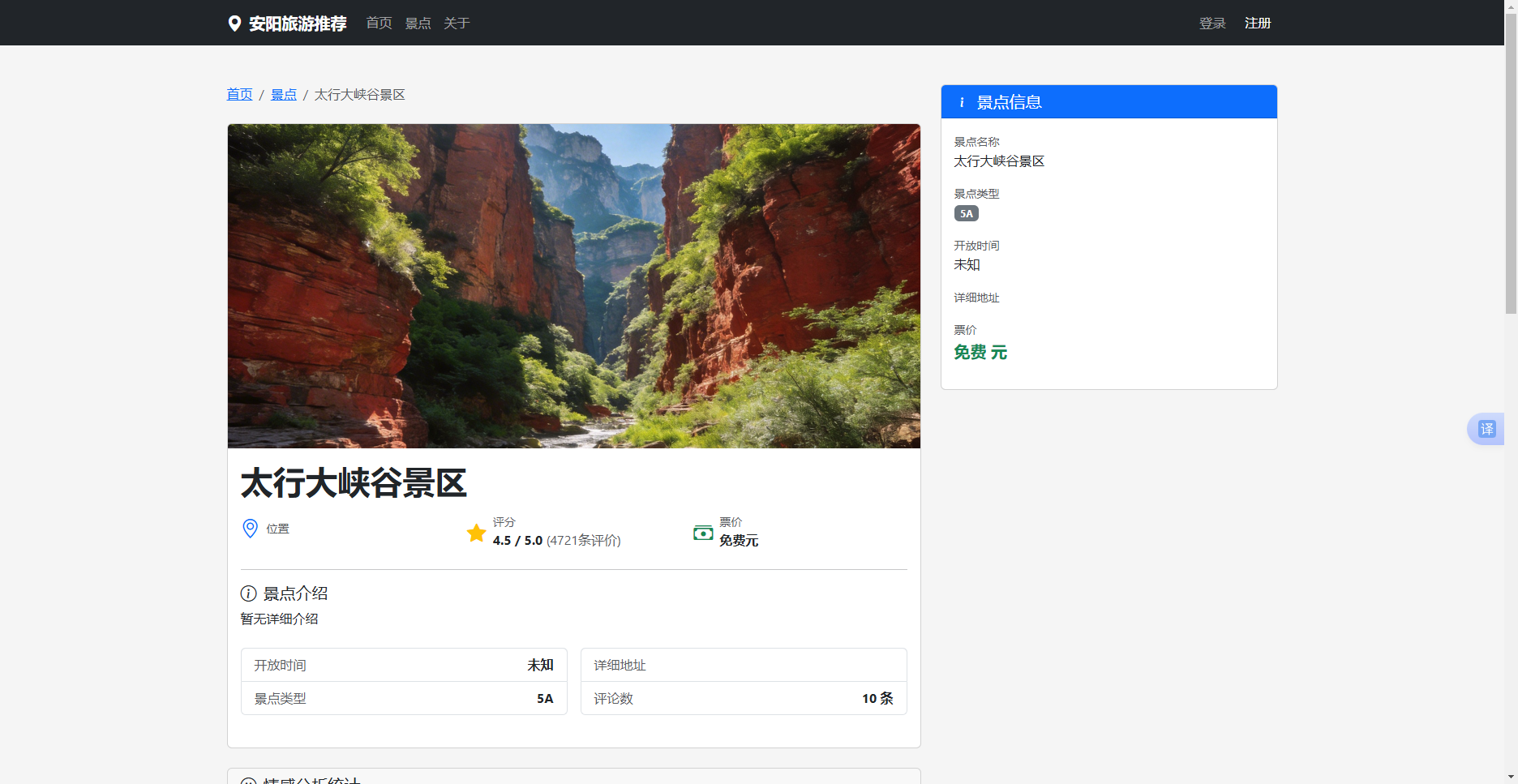
景点浏览页面以卡片形式展示所有景点,支持按分类、价格、评分等条件筛选。点击景点卡片可以进入景点详情页,查看景点的详细信息,包括景点介绍、位置、开放时间、门票价格、评论列表、情感分析结果等。
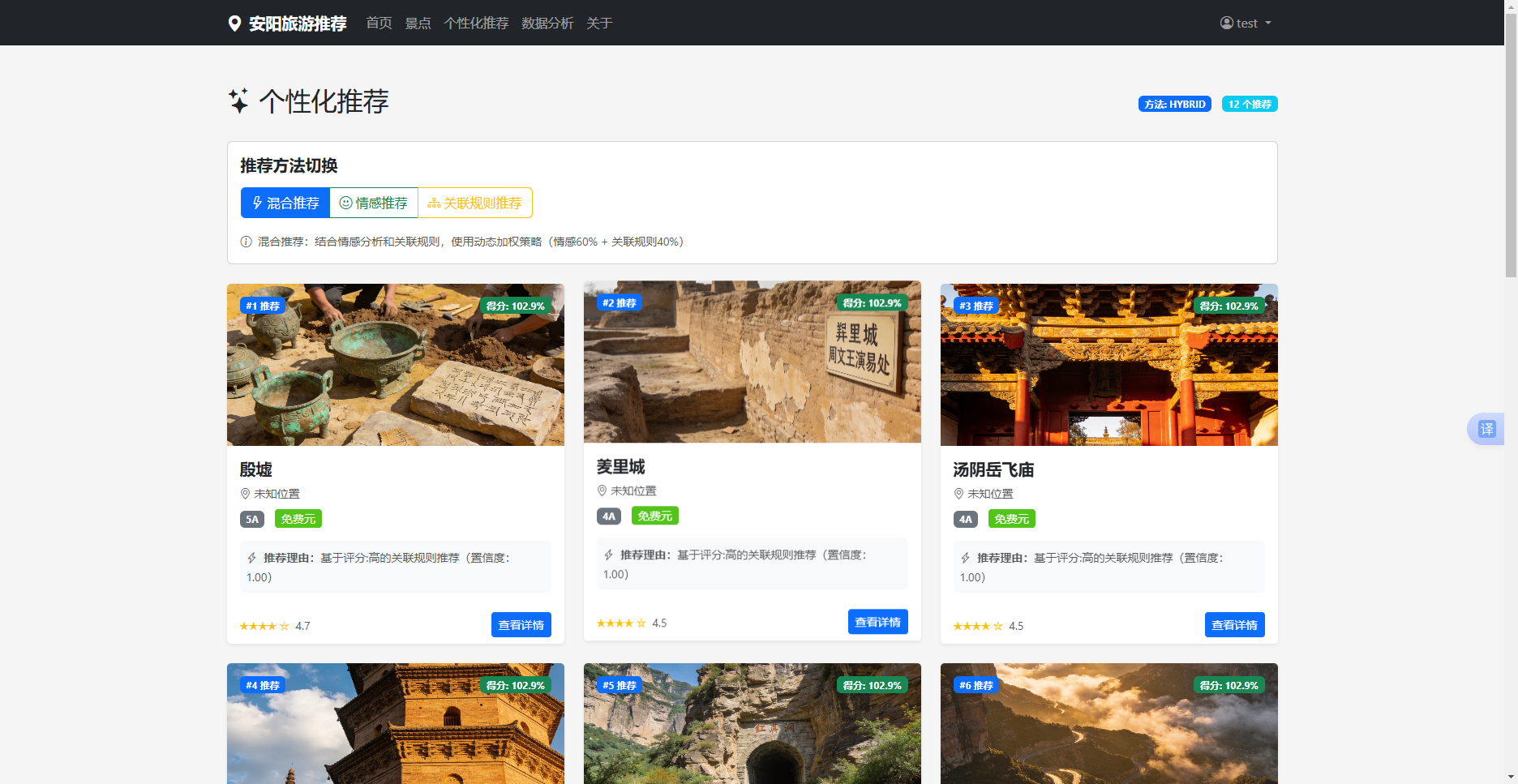
5.2.3 个性化推荐页面实现
个性化推荐页面根据用户的历史行为和偏好,展示推荐列表。推荐列表按照推荐得分降序排列,每个推荐景点显示景点名称、图片、推荐理由等信息。
5.3 管理后台功能实现
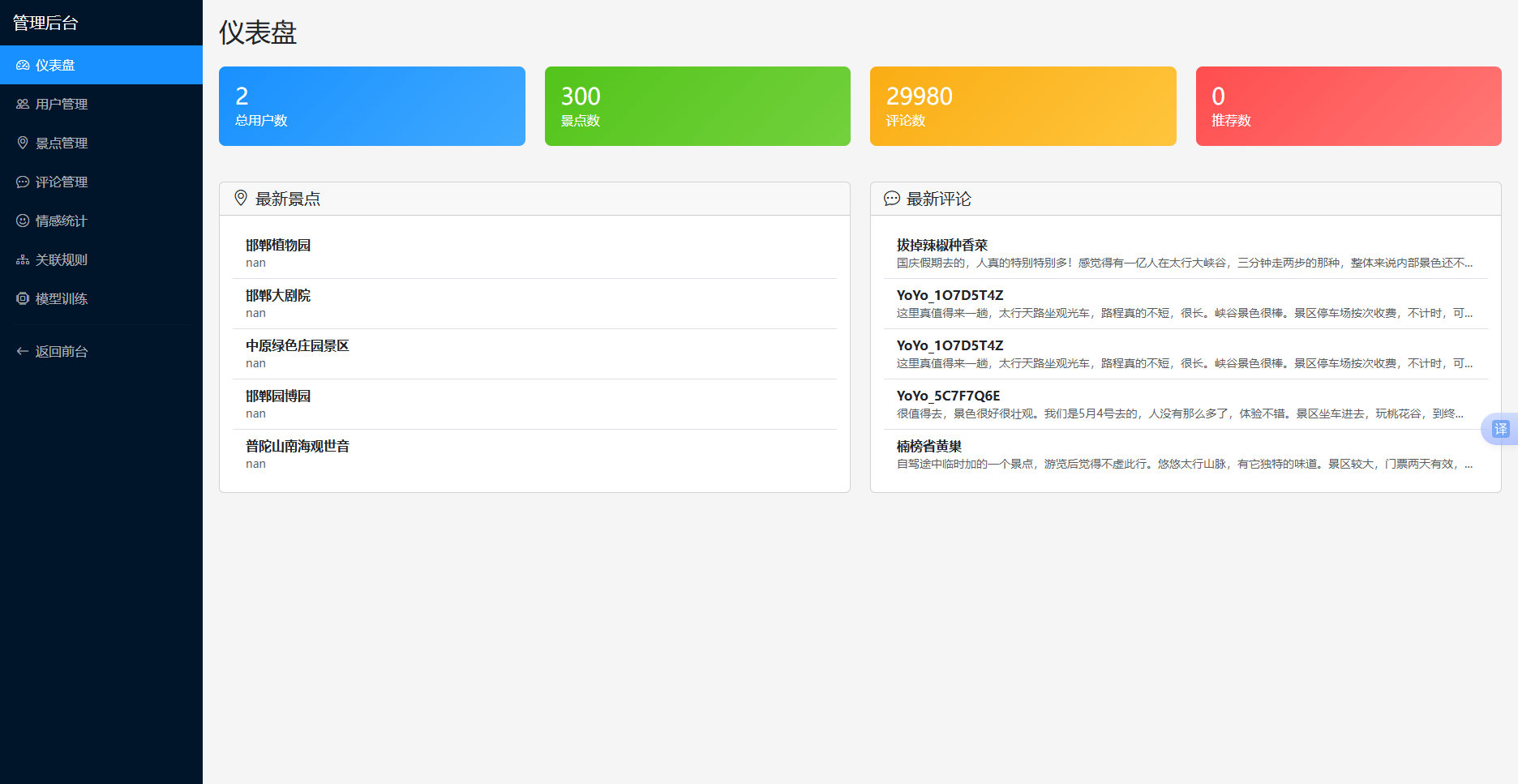
5.3.1 管理员仪表盘
管理员仪表盘展示系统的整体概况,包括用户总数、景点总数、评论总数、推荐总数等统计信息,以及最新的景点和评论列表。
5.3.2 用户管理
用户管理模块实现用户的查看、编辑、删除等功能。管理员可以查看所有用户的信息,包括用户名、邮箱、角色、注册时间等,也可以编辑用户信息或删除用户。
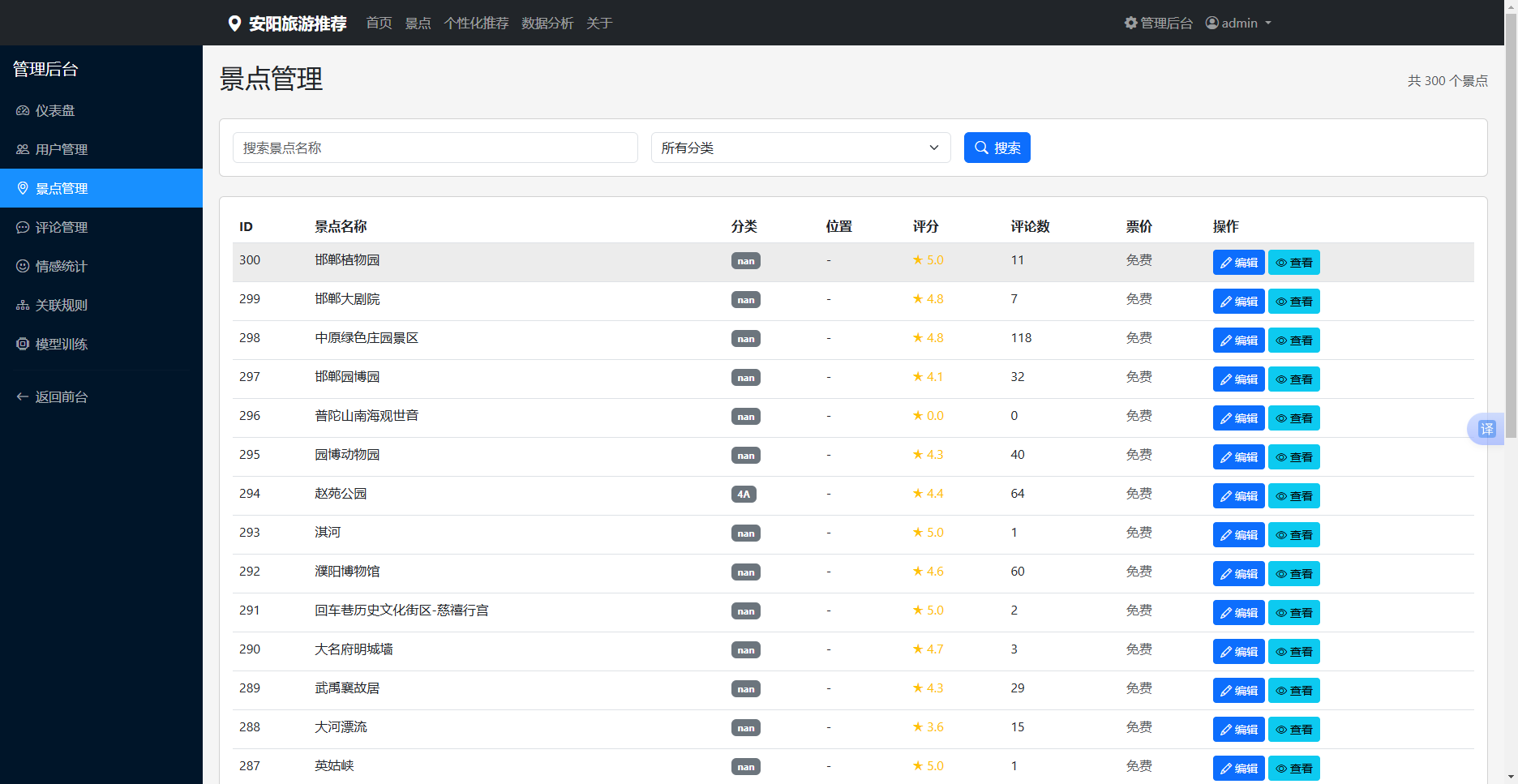
5.3.3 景点信息管理
景点管理模块实现景点的增删改查功能。管理员可以添加新的景点,编辑现有景点的信息,或删除景点。景点信息包括景点名称、位置、类型、描述、门票价格、图片等。
5.3.4 评论管理
评论管理模块实现评论的审核和管理功能。管理员可以查看所有待审核的评论,选择通过或拒绝。对于通过审核的评论,可以查看详细内容;对于违规评论,可以直接删除。
5.3.5 模型训练与管理
模型训练模块实现情感分析模型和关联规则挖掘模型的训练功能。管理员可以触发模型训练,系统会自动调用相应的算法进行训练,并将结果保存到数据库中。
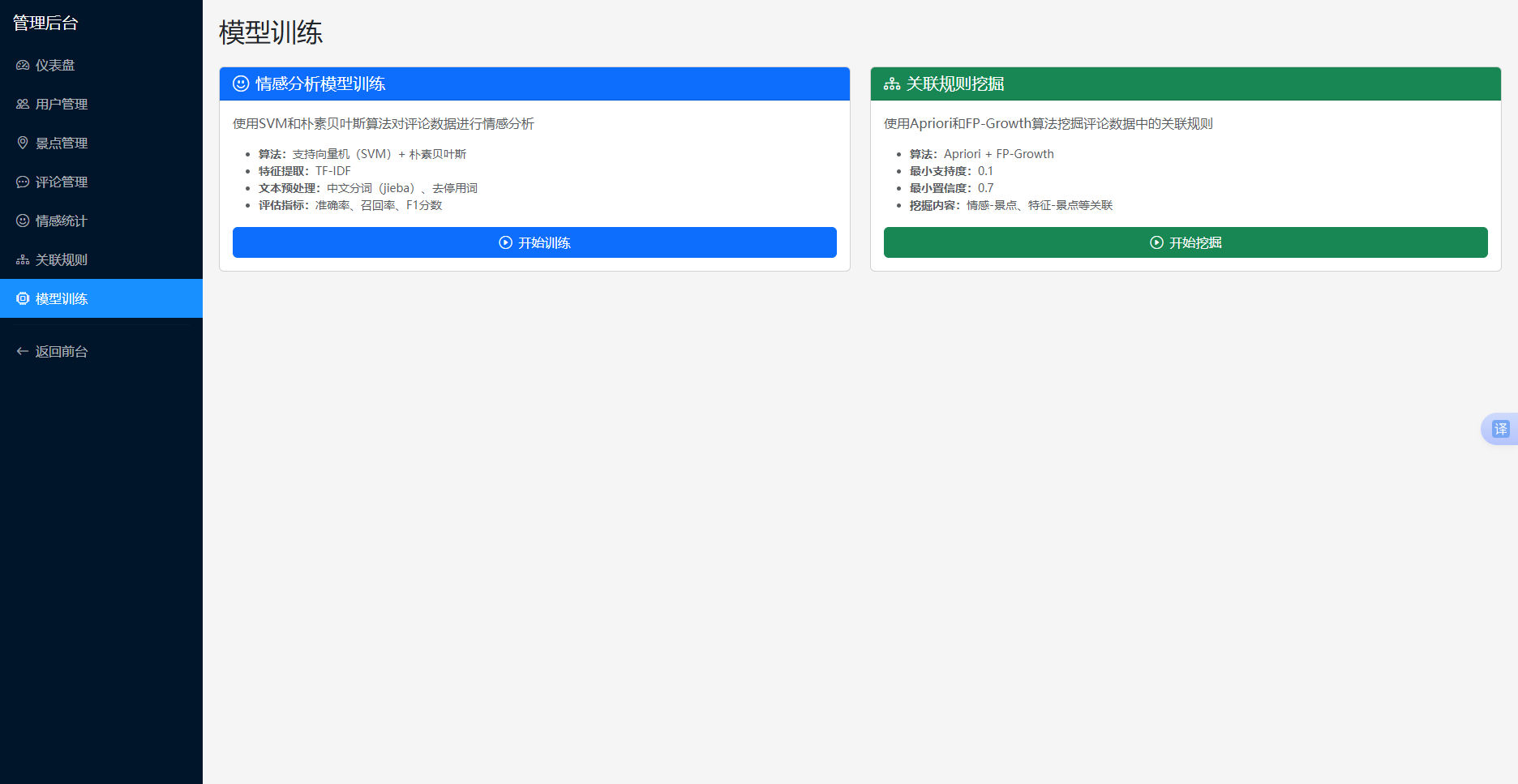
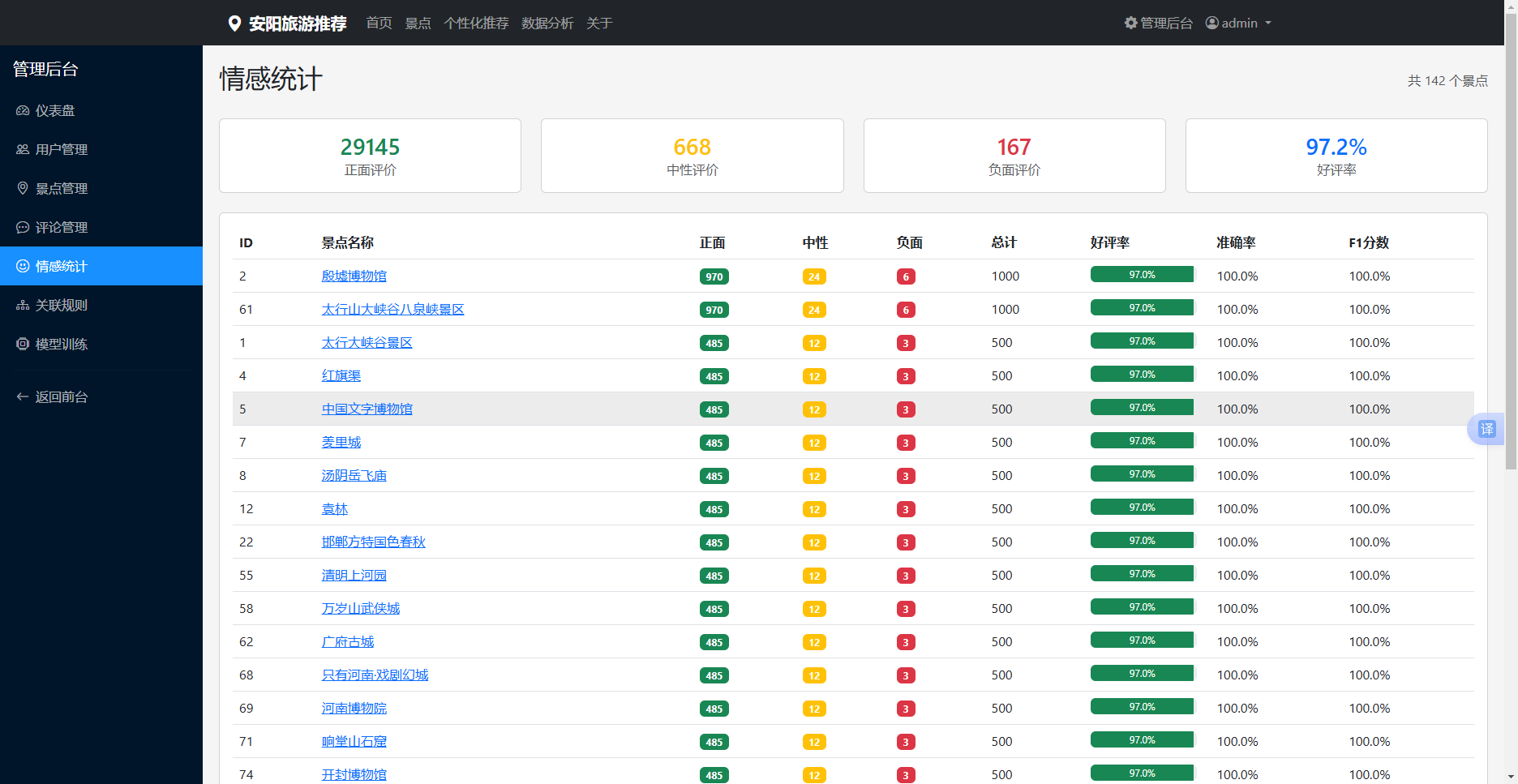
5.3.6 情感统计分析
情感统计模块展示所有景点的情感分析结果,包括正面情感比例、负面情感比例、中立情感比例等。管理员可以查看单个景点的情感分布,也可以查看所有景点的整体情感分布。
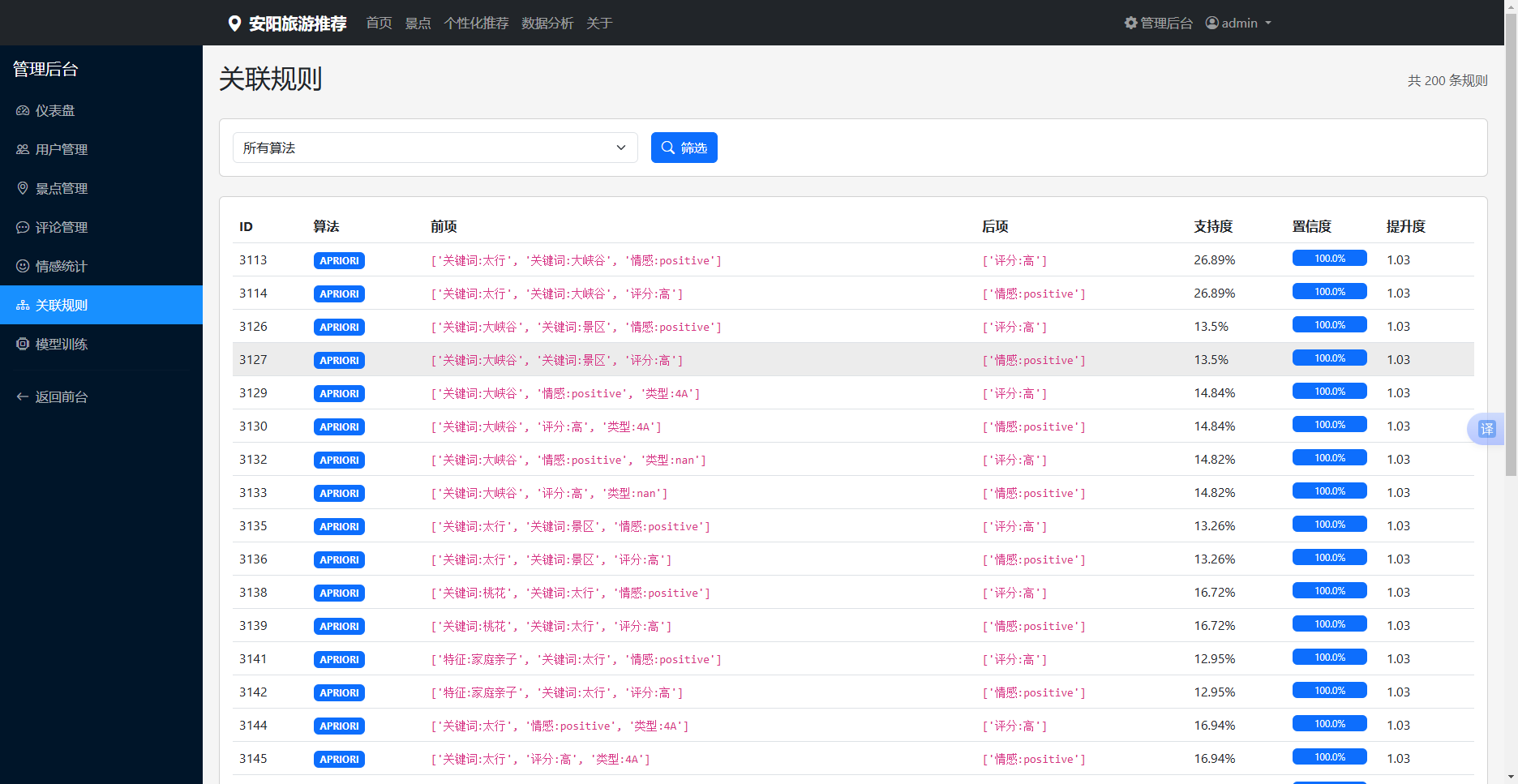
5.3.7 关联规则管理
关联规则管理模块展示挖掘出的景点关联规则。管理员可以查看所有的关联规则,包括前件、后件、支持度、置信度、提升度等信息。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)