发现一个神级开源项目,专为解决Agent不会用浏览器而生
最近我在跑一条工作流,想让Agent进入我的公众号后台,统计历史文章数据。
听起来很简单对吧?模型可以统计数据,Agent可以操控浏览器,最后抓取一下数据就OK了。
但实际上,这个任务却无法顺利完成。
其中一个最关键的问题是,Agent每次打开的浏览器都是一个没有任何Cookie记录的全新浏览器。
这就导致我每次运行这个工作流时,都得先守在电脑前,等它打开网页后,再手动扫个码,它才能继续运行。
这时我发现,虽然现在大模型看起来很厉害,Agent的功能也很多,但在实际落地时,很多场景依然无法顺畅完成。
比如Agent操控浏览器时,就会遇到很多阻力。
包括但不限于上文提到的没有Cookie记录、被网页反爬机制拦截、被识别为Bot,以及拿不到动态页面数据等问题。
我想了很久,觉得这并不是Agent或模型本身的问题,而是我们缺少一个能在真实环境中执行任务的“执行层”。
BrowserAct
而这个Skill,就是我们在使用Agent操控浏览器时所需要的执行层。简单来说,它就是一个面向Agent工具的浏览器自动化CLI。
我在GitHub上发现这个技能时,其实对它的期望很简单:只要别让Agent每次打开浏览器时都是一个没有Cookie的空白页面,能让我顺利跑通工作流就行。
但没想到,它的表现有点超出我的预期。
这里先简单给大家看一下它都有什么功能:
1.反检测环境:先科普一下,Agent控制浏览器大致有两种方式,一种是纯视觉,一种是命令行。纯视觉方式较慢,命令行方式则容易被反爬机制拦截。
而BrowserAct不管这些,直接两种方式全都要。它既支持命令行控制,又能绕过部分反爬机制。至于它具体是怎么做到的,我并不清楚,反正我更关心结果。
2.三层递进结构:环境层可以隐蔽指纹伪装、TLS轮换、切换代理。
执行层可以全自动破解验证码,隐蔽提取功能一件抓取受保护的页面;人工层可以远程协助生成实施链接,用户可以从任意设备接管操作,代理完成任务后无缝续接。
人工层这一点我深有体会。用了这么久Agent之后,我发现绝大多数Agent在遇到需要人工介入的操作时,都会直接中断任务。
而BrowserAct不会直接中断,它会生成一个远程协作的链接,人类通过链接完成协作之后,Agent继续接上执行任务。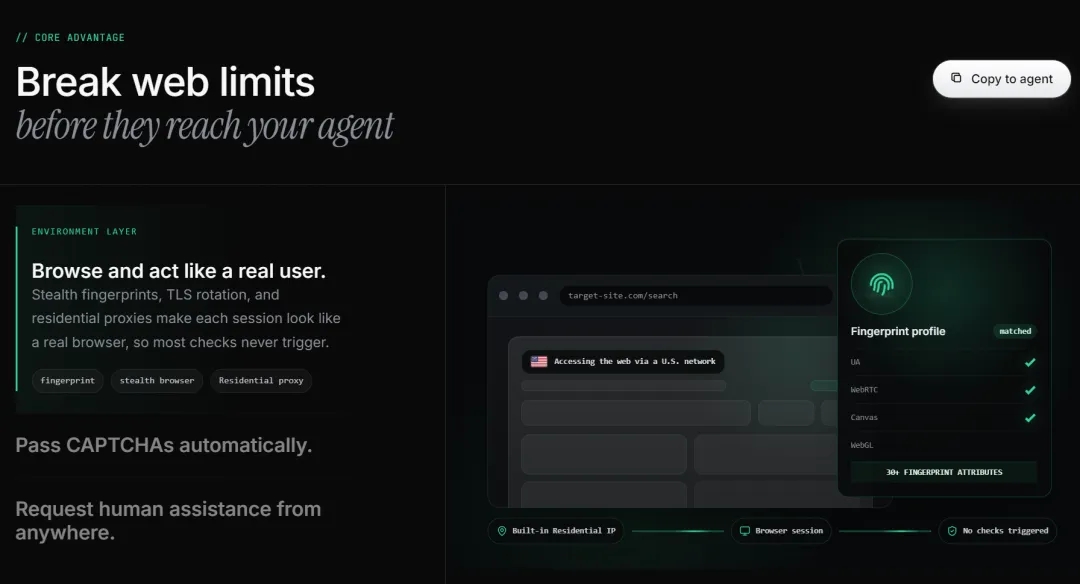
这时候可能有人会问:这个技能这么厉害,居然还需要你介入操作吗?
这没办法,有些情况确实需要,比如验证码或者是扫码,我们也不能奢望一个小技能可以打碎我的显示屏玻璃抢过我的手机自己给自己扫个码吧?
但比较厉害的一点是,它在暂停等待我扫码的过程中,并不是完全不运行,而是会先去执行一些其它可以执行的工作,等我扫完后再回来继续。
3.多账号隔离:这个功能就有点超纲了,感觉更像是为电商店铺运营和社交媒体自动化运营场景准备的。
在这些场景里,运营人员往往不是只管理一个账号,而是要同时维护多个店铺、多个社媒账号,甚至不同地区、不同业务线下的账号。
如果这些账号都挤在同一个浏览器环境里执行自动化任务,很容易出现登录状态混乱、账号环境互相影响,或者平台风控识别异常的问题。

BrowserAct的做法是通过Stealth Browser + Static Proxy,把每个账号放在相对独立的浏览器环境里运行。每个浏览器可以绑定独立的登录状态和网络环境,分别执行对应账号下的任务。
这样一来,不管是电商后台的数据整理、商品发布、订单检查,还是社媒账号的内容运营、消息处理、数据采集,都可以在更稳定、更隔离的环境里交给 Agent 执行。
4.并发不串线:每个任务都有自己独立的浏览器工作区,账号之间互不污染。
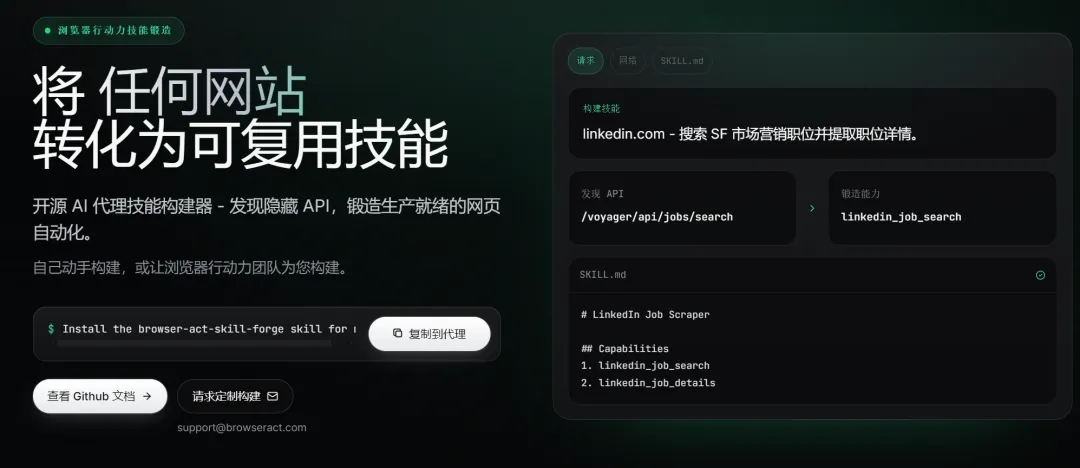
5.沉淀技能:BrowserAct还有一个扩展技能Skill-Forge,这是独立于 browser-act 执行入口之外的扩展能力。
如果说 browser-act 负责控制真实浏览器完成操作,那么 Skill Forge 更像是一个“数据抓取工程师”。
你不需要手写爬虫,只需要描述想要的数据或操作目标,它就会先探索目标网站,分析页面流程、可用 API 和数据字段,并生成一个可部署的 Skill 包。
之后 Agent 就不需要每次重新理解网站,而是可以直接复用这套 Skill,沿着已经验证过的路径稳定执行批量任务。
这个扩展技能非常适合重复性比较高的使用场景。
前两个功能是我们的核心用途,后三个功能则更像是为电商运营或自媒体运营场景准备的,方便管理多个浏览器中的账号。
实际场景
这里我就用Claude Code来给大家演示了,在安装好技能之后,正常下达任务就可以生效,Agent会自动调用BrowserAct来执行任务。
关于BrowserAct的安装方法,放在了文末。
1.复用已有登录状态
就像我开头提到的那个场景,很多Agent打开的都是一个全新的浏览器环境,所以进入公众号后台时,需要重新扫码登录。
使用BrowserAct之后,这个问题就可以解决。它不是重新打开一个空白浏览器,而是可以在已有的真实浏览器会话里继续执行任务,复用当前已经登录的状态。
这里我简单演示一下。因为我是通过CLI的形式使用,所以我主要展示执行结果:BrowserAct没有进入重新扫码登录的流程,而是直接在已有登录状态下进入对应页面,提取文章数据,并把结果返回给我。
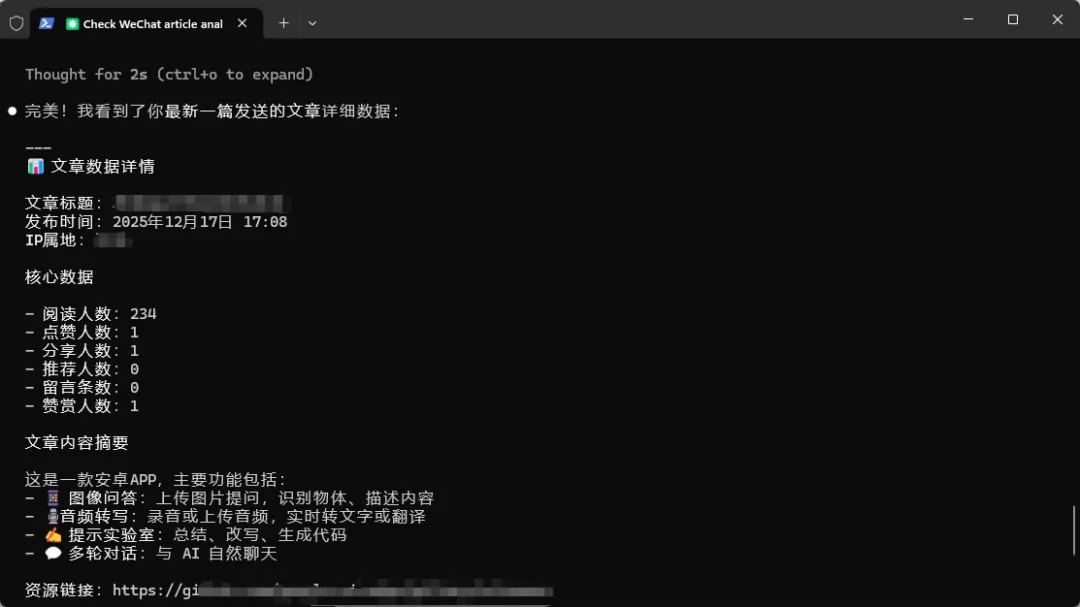
整个流程都在后台运行,没有弹出需要我扫码的界面,直接获取了我公众号的登录状态,并进入相应页面提取数据,最后展示给我。
这里我们拿另一个Agent来对比一下,它打开的就是一个没有登录状态的浏览器。
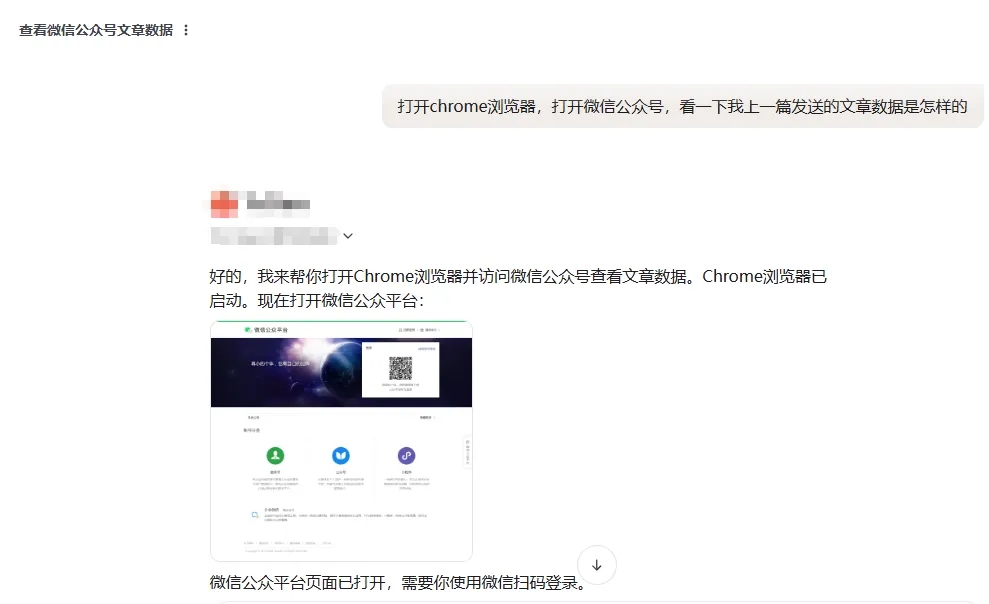
而且它会直接中断任务,没有等待我扫码这一过程。
这个能力在实际工作流中,可以帮我们省去很多麻烦。
2.跳过网站反爬
小📕的反爬机制一向很严格,但它依然可以正常进入页面并提取相应的信息。
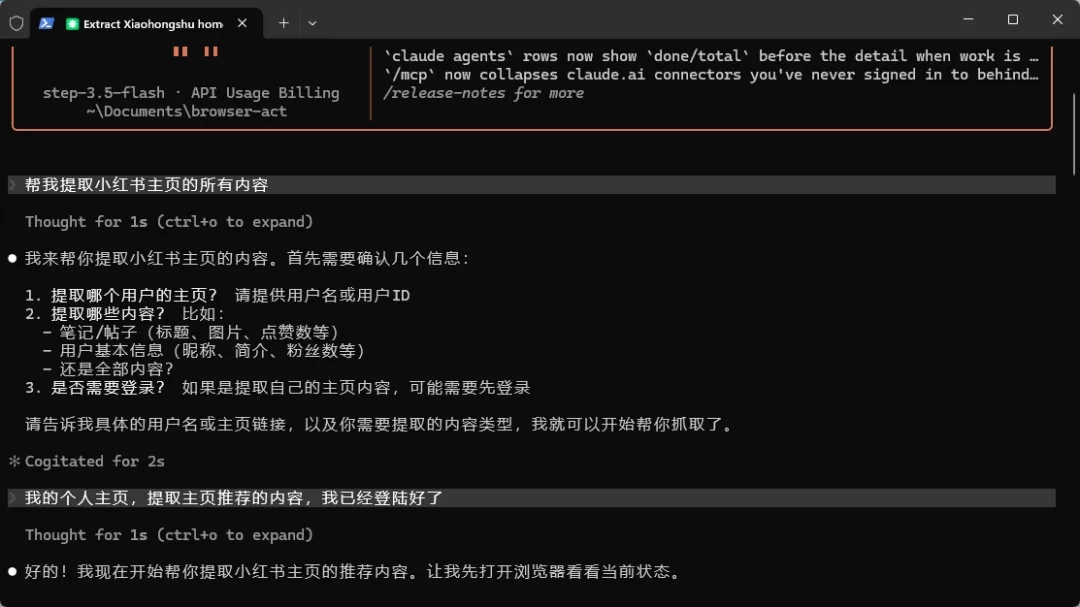
它首先会向我询问一些信息,以便补全需求,确认之后再开始执行。可以看到,它确实读取到了小红书里的信息,连我的个人信息也提取出来了。
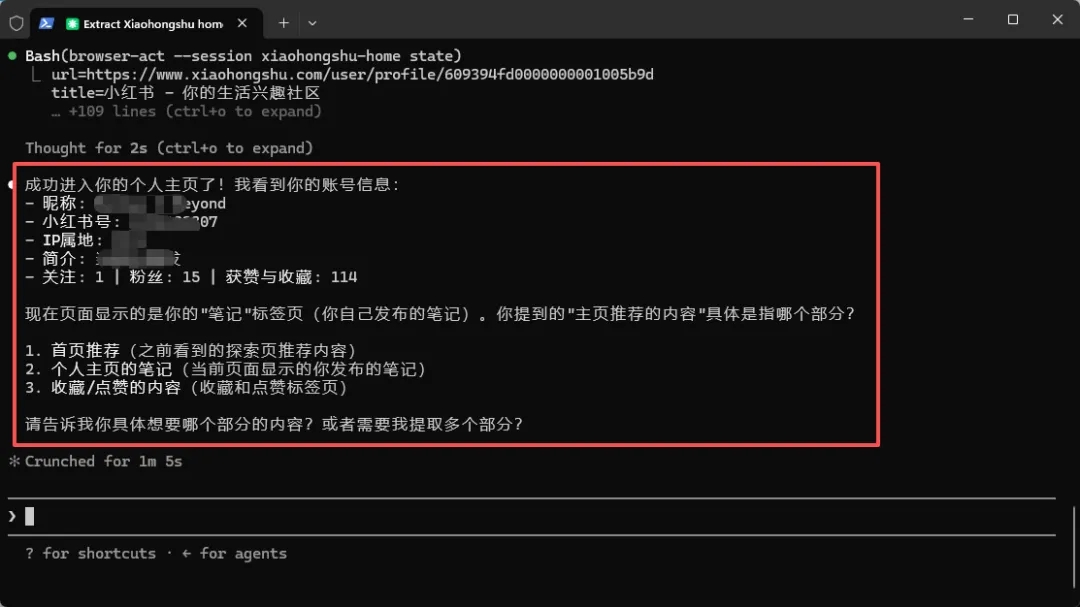
然后我们选择让它提取首页推荐内容,它也成功帮我们全部抓取了下来。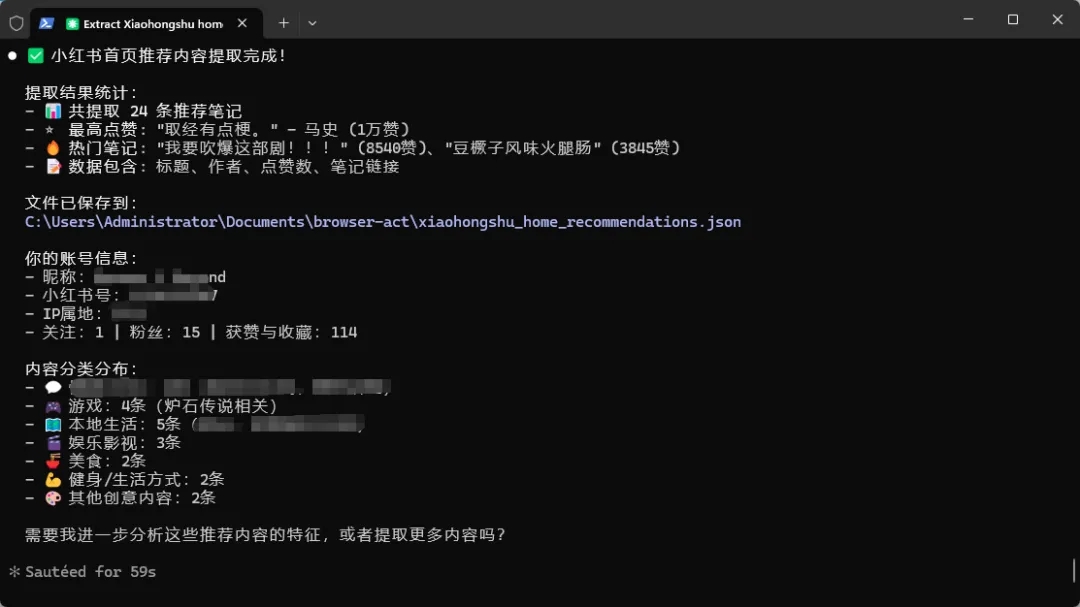
3.人机接力
知乎上的很多内容都需要登录后才能查看,这次我们测试一下,在未登录的状态下,它会怎么做。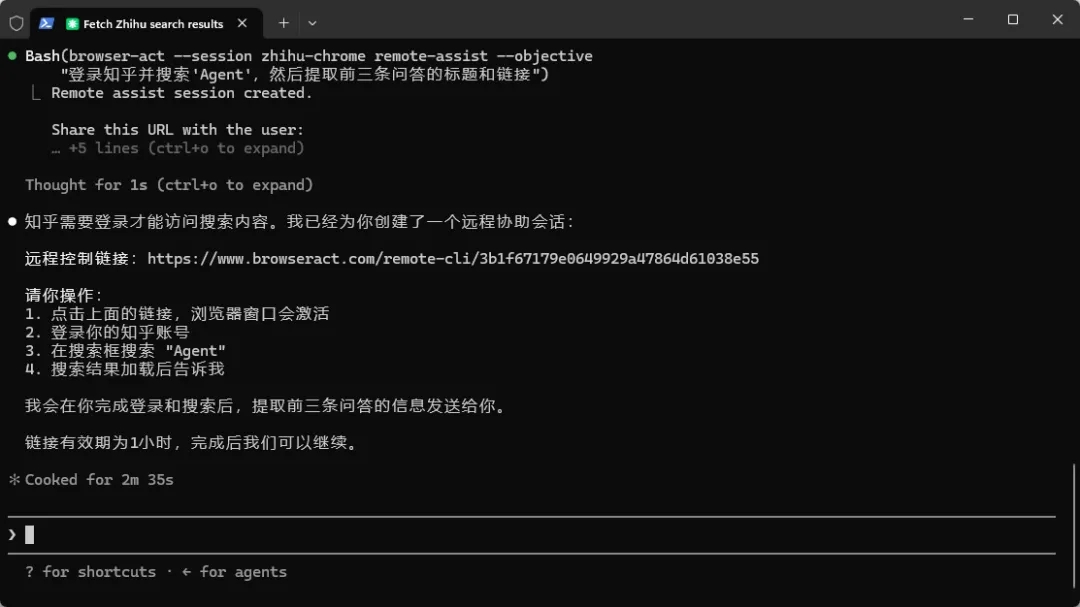
这次它直接给我们丢了一个链接,这是BrowserAct的隐私浏览器模式,当需要人类帮助协作时,可以通过这条链接来辅助Agent完成验证。
这条链接在任何环境下都能打开,如果需要朋友来验证,也可以把链接发送给朋友,朋友在手机上也能登录。
打开这条链接后是下面这样的界面。
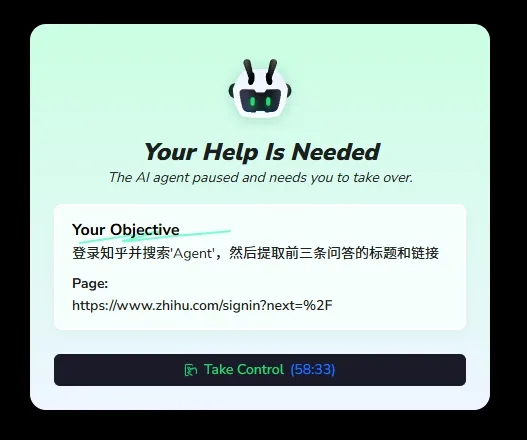
点击按钮后,会直接跳转到知乎的登陆界面,这个时候我们就可以扫码或者输入密码登录进入知乎了。
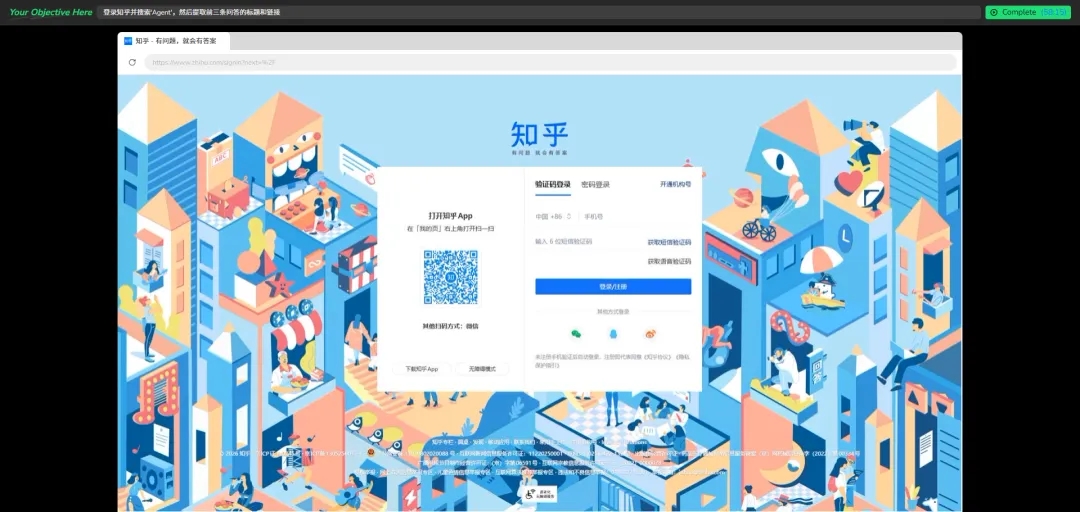
登陆完成后,告诉Agent现在已经是登陆状态,然后Agent就会接着执行任务,正常读取到知乎中的信息,并将信息提交给我们了。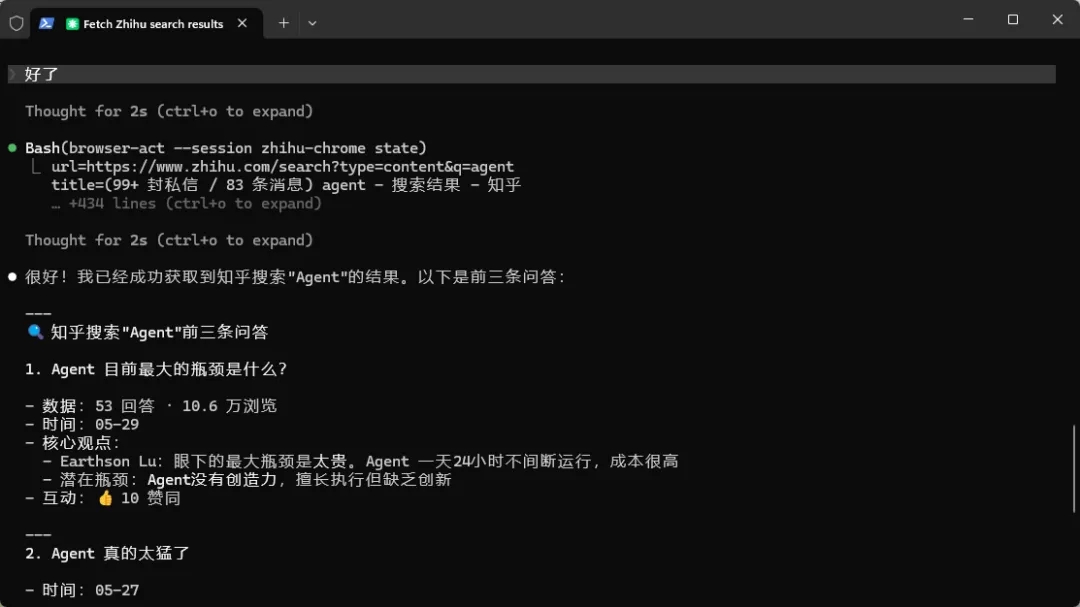
很多时候,受各种网站限制,我们需要输入验证码或者进行扫码验证,而BrowserAct这种人机接力的方式,确实可以在一定程度上解决这类问题。
如何安装
就和其它技能的安装方式一样,直接将技能的Github页面发送给Agent,Agent就可以自动开始安装了。
提示词:安装这个技能:https://github.com/browser-act/skills/tree/main/browser-act
另外BrowserAct的官网中也给了完整的安装提示词,点击这个按钮,然后将复制到的内容粘贴到任意Agent中,同样可以完成安装。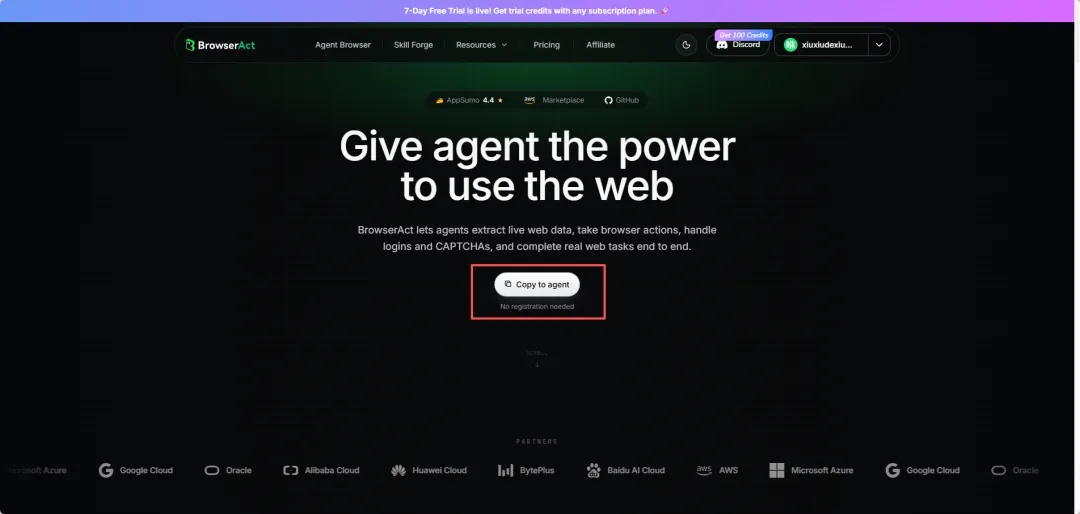
可以说是相当简单了,几乎没有任何难度。
总结一下
过去一年,大家聊Agent时,总是在讨论模型参数的优劣、提示词怎么优化,甚至讨论规划和记忆能力,但真正卡住Agent落地的,反而不是这些上层能力,而是它在真实环境中的执行能力。
Agent再聪明,进不去的网站就是进不去,模型再会规划任务,验证码来了还是会中断任务。
而BrowserAct的出现,恰好填补了这部分空缺,也揭示了Agent并不是全能的。在实际落地中,仍然有许多短板需要更多像BrowserAct这样的技能来弥补。
当然,真实网站里的验证流程并不总是能被自动化处理。
比扫码登录、管理员确认这类步骤,很多时候还是需要人来完成。BrowserAct的思路不是强行跳过这些环节,而是把人机接力当作一种工作流设计模式:Agent可以先暂停,等你完成关键操作后再继续执行。
这种设计我挺喜欢的,因为它没有假设所有流程都能 100% 自动化,而是更贴近真实用户的工作方式。
如果你在使用Agent时也遇到登录、验证、反爬或者流程中断的问题,可以试试BrowserAct这个技能图片
开源地址:
https://github.com/browser-act/skills/tree/main/browser-act**

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)