《AI生图与生视频:从入门到商业实战》
大家好,这里是JZ_AIhub,致力于决定收集全网的AI知识
本次《AI生图与生视频:从入门到商业实战》中1.1人工智能生成图像与视频的核心技术演进历程
由于工作量太大无法全部上传,所以需要完整版请私信我
要理解2026年AI生成技术百花齐放的繁荣景象,我们必须回溯其技术演进的核心脉络。这条脉络并非线性发展,而是由多个关键思想的提出、碰撞与融合所驱动。其历史可追溯至对创造力本身的早期计算探索,例如上世纪70年代Harold Cohen开发的AARON程序,这被视为AI艺术的先驱,它依据预定义的规则系统进行绘画,展现了将艺术表达编码为算法的初步尝试,但真正的革命始于深度学习时代的到来。
2014年,Ian Goodfellow等人提出生成对抗网络(GAN),这无疑是生成技术从模糊走向清晰的里程碑。GAN的核心架构由生成器与判别器两个神经网络组成,它们在零和博弈的框架下相互对抗:生成器试图伪造出足以欺骗判别器的样本,而判别器则努力分辨真伪。这种对抗机制逼迫生成器不断提升伪造能力,最终创造出足以以假乱真的图像。GAN迅速催生了大量衍生模型,如DCGAN、StyleGAN等,首次在特定领域生成了令人惊叹的逼真人脸和场景。然而,GAN的训练过程极不稳定,需要精心平衡生成器与判别器的训练节奏,且容易出现“模式崩溃”问题——即生成器只学会生成少数几种样本,多样性严重不足。
几乎在同一时期,变分自编码器(VAE)由Kingma和Welling于2014年提出,它从概率编码的角度切入生成问题。VAE通过学习数据的潜在概率分布,将每张图像映射到潜在空间中的一个连续区域而非孤立点,从而构建了一个平滑、可插值的潜在空间。这一特性使得VAE的生成过程更具连续性与可解释性,用户可以在潜在空间中平滑漫步,观测图像的逐步变化。但代价是生成的图像往往较为模糊,缺乏GAN那样的精细纹理细节。
2015年,自回归模型如PixelRNN和PixelCNN将生成任务重新定义为逐像素的序列预测问题,像语言模型预测下一个词那样逐个预测下一个像素值。这类模型的生成质量稳定可控,但由于必须按像素顺序串行生成,计算成本极高且速度缓慢。
至此,生成模型领域形成了两大流派:
一是追求高保真度的GAN路线
二是追求多样性与稳定性的VAE及自回归模型路线,两者各有优劣,难以兼得。
一个颠覆性的变革源于2015年反向扩散思想的引入,但当时并未引起足够重视。
直到2020年,Jonathan Ho等人发表《去噪扩散概率模型》,才首次以严谨的实验证明扩散模型能够在图像生成质量上超越当时最先进的GAN。
扩散模型的核心机制精妙地分为两个过程:
前向过程逐步向数据添加高斯噪声,直到原始图像被完全破坏为纯噪声;
而学习到的反向过程则从纯噪声出发,一步步预测并去除噪声,最终还原出清晰的图像。
这种逐步细化的生成方式天然避免了GAN对抗训练的种种不稳定问题,且每次生成都从完全不同的随机噪声出发,从根本上保证了高多样性。扩散模型的成功标志着生成技术范式的重大转移。
此后,技术演进在两条并行且相互交织的轨道上加速推进。
一条轨道是多模态大模型的崛起,2021年,OpenAI发布DALL·E,首次将大规模Transformer架构与文本到图像生成任务结合,证明了从海量图文对中学习跨模态关联的巨大潜力——模型不仅能生成图像,还能理解“鳄梨形状的扶手椅”这类高度抽象的文本描述。
另一条轨道是扩散模型的持续进化,2022年,两股力量全面合流,迎来了AI图像生成的爆发之年。
OpenAI的DALL·E 2、Google的Imagen以及Stability AI的开源模型Stable Diffusion相继问世。其中,Stable Diffusion的贡献尤为关键,它创造性地提出在感知压缩后的潜在空间而非高维像素空间进行扩散过程。这一改进极大地降低了计算需求和显存占用,使得高质量的AI生图能够在消费级GPU上运行,彻底打破了技术壁垒,开启了图像生成的民主化时代。
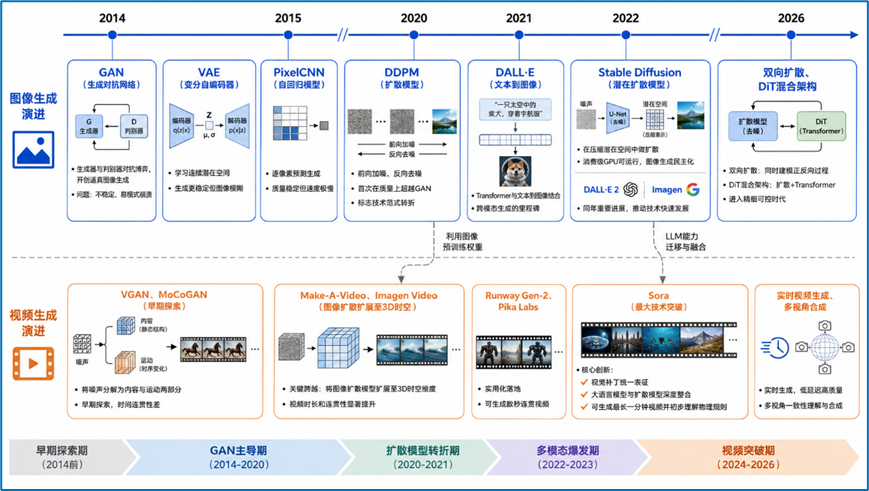
视频生成的演进轨迹与图像生成高度相似,但面临着更为严峻的时空一致性挑战。
早期视频生成工作多基于GAN架构,2016至2018年间出现的VGAN、MoCoGAN等模型尝试将噪声向量分解为内容部分和运动部分,分别进行独立的生成与控制。
但这些方法在时序连贯性和长视频生成上始终捉襟见肘,生成的视频往往只有几帧,且容易出现物体闪烁和突变。扩散模型的兴起为视频生成带来了质变。
从2022年的Make-A-Video、Imagen Video开始,研究者们探索将2D图像扩散模型扩展至3D时空维度,或在预训练的强大图像生成模型中插入时间注意力层,巧妙地利用图像模型已经习得的视觉先验来约束视频帧间的连贯性。
2023年,Runway的Gen-2和Pika Labs等工具的快速迭代,标志着AI视频从实验室研究正式迈向实用化,能够生成数秒内保持连贯、风格多样的视频片段。
2024年初,OpenAI发布的Sora模型带来了又一次认知冲击。Sora首次展示了大语言模型与扩散模型深度整合后的惊人潜力——通过将视频压缩为时空视觉补丁(Visual Patches)的统一表征方式,模型能够理解和生成长达一分钟的视频,其中包含复杂的相机运动、多主体交互以及对物理世界运行规则(如重力、遮挡、光影)的初步理解。
Sora的意义不仅在于生视频,更在于它展现了AI从像素生成走向世界模型构建的初步可能性。截至2026年,技术演进已进入实时生成、精确可控和高一致性时代。
混合架构开始出现,例如结合扩散模型与自回归模型优势的DiT架构;双向扩散模型如Stable Diffusion 3进一步提升了文本理解精度;3D生成、多视角合成、音频-视频联合生成等方向持续突破。从历史脉络中可以清晰地看到一条主线:生成技术的核心从早期的符号规则系统,到追求更高保真度的对抗式框架,再到大一统的扩散生成范式,而贯穿始终的驱动力是寻找更稳定、更可控、计算更高效的生成原理,并将其与语言理解、物理世界建模深度结合,不断逼近从无到有创造真实世界影像的终极目标。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)