世界模型与世界动作模型(WAM):从基础模拟器到具身动作
2026年5月来自华为金鑫博士的论文“World Models and World Action Models (WAM): From Foundation Simulators to Embodied Action”。
世界模型(World Models)——即一种使智体能够模拟未来状态、预测后果并规划行动的内部预测表征——已成为具身人工智能(Embodied AI)领域的一个基础性范式。该领域源自基于模型的强化学习,随着大规模生成模型的横空出世,它经历了彻底的变革,从而打破了过去被动式视频预测与交互式物理仿真之间泾渭分明的界限。与此同时,视觉-语言-动作(VLA)模型构建了一个强有力的框架,实现了将高层级语言意图落地为低层级运动控制。这两条主线——即预测性世界仿真与基于动作的多模态推理——的自然融合,催生“具身世界动作模型”(WAMs);这代表一个全新的前沿领域,在其中,智体通过“想象未来”的方式来学习如何采取行动。然而,随着机器人学、自动驾驶及交互式仿真等领域相关方法的井喷式增长,当前的研究格局呈现出碎片化的态势,尚缺乏系统性的统一整合。
本综述对现代世界模型生态系统进行全面且结构化的梳理,涵盖200余篇关键文献,并将其归纳于一个统一的分类体系之中。系统地涵盖六大支柱领域:(i) 基础世界模型(Foundation World Models),包括通用型交互式仿真器(如 Genie、Cosmos、Sora)以及针对特定游戏的仿真环境(如 Oasis、Matrix-Game);(ii) 视觉-语言-动作(VLA)模型,涵盖基础架构(如 RT-2、π₀、OpenVLA)、专用于自动驾驶的 VLA 模型,以及具身操作策略;(iii) 具身世界动作模型(WAMs),通过零样本策略、可控仿真平台以及基于世界模型的强化学习,实现了视频生成与动作预测的统一;(iv) 自动驾驶世界模型,涵盖视频生成、闭环仿真、规划策略,以及几何占据/鸟瞰图(BEV)表征技术;(v) 效率与评估,涵盖计算加速技术以及用于衡量物理真实性的基准测试协议;(vi) 数据集与生态系统,包括支撑整个领域发展的大规模机器人学习语料库及行业技术报告。
通过上述编排,清晰地勾勒出该领域从被动式像素预测器向主动、具备推理能力且基于动作仿真器演进的轨迹。当前面临的关键开放性挑战,包括物理一致性、跨具身场景的泛化能力、安全性验证,以及“仿真-到-现实”(Sim-to-Real)的评估鸿沟。指出通向认知型世界模型、自主数据采集以及标准化开放生态系统等未来的发展方向。
如图 1 所示世界模型与世界动作模型的分类体系。这一统一的图景涵盖六大主要类别:基础世界模型、视觉-语言-动作模型、具身世界动作模型、自动驾驶世界模型、效率与评估,以及数据集与生态系统。虚线箭头指示基础世界模型(Foundation WMs)与视觉-语言-动作模型(VLAs)向世界动作模型(WAMs)的融合趋势,而后面两个则提供了相应的支撑基础设施。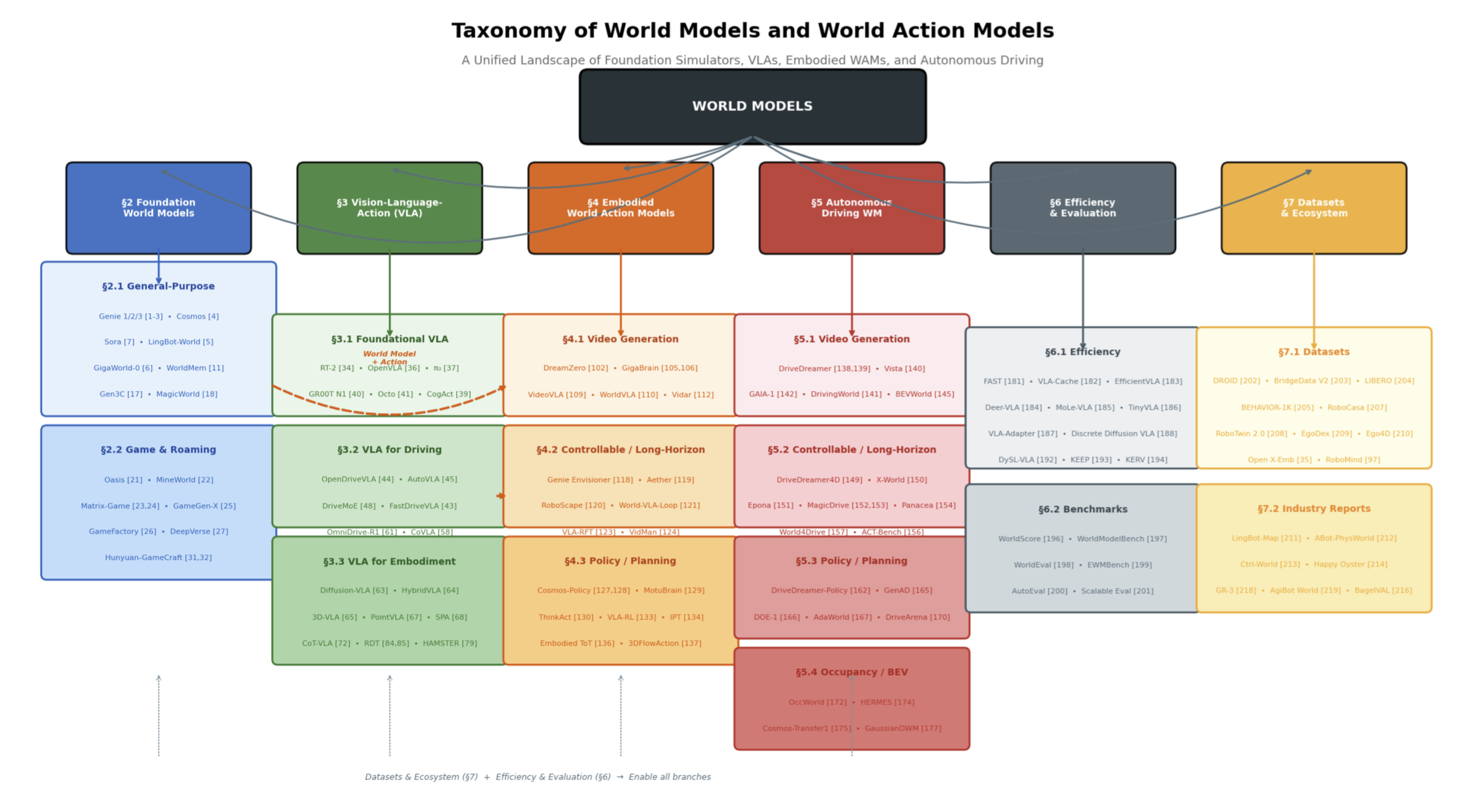
基础世界模型代表生成式仿真的前沿领域,旨在从大规模视频数据中学习通用的环境动力学,从而使智体能够通过输入动作来查询模型,并接收到连贯且具有长时序跨度的未来观测结果。与旨在学习紧凑隐空间动力学以服务于控制任务的经典“基于模型的强化学习”(Model-based RL)不同,现代基础世界模型优先强调规模、通用性和交互性:它们基于多样化的互联网级视频数据进行训练,并期望能够响应开放式的动作输入,对任意场景、物体及物理交互进行仿真。
基础世界模型划分为两个相互补充的分支:通用交互式仿真器——旨在实现对物理世界的广泛覆盖;以及游戏与漫游环境——专注于开放式的三维游戏世界。如图 2 所示:其中核心技术包括长时程一致性、交互控制、实时推理和物理合理性;该类方法的演化轨迹是:被动视频预测、动作为条件的生成、交互仿真、记忆增强的长时程和开源生态。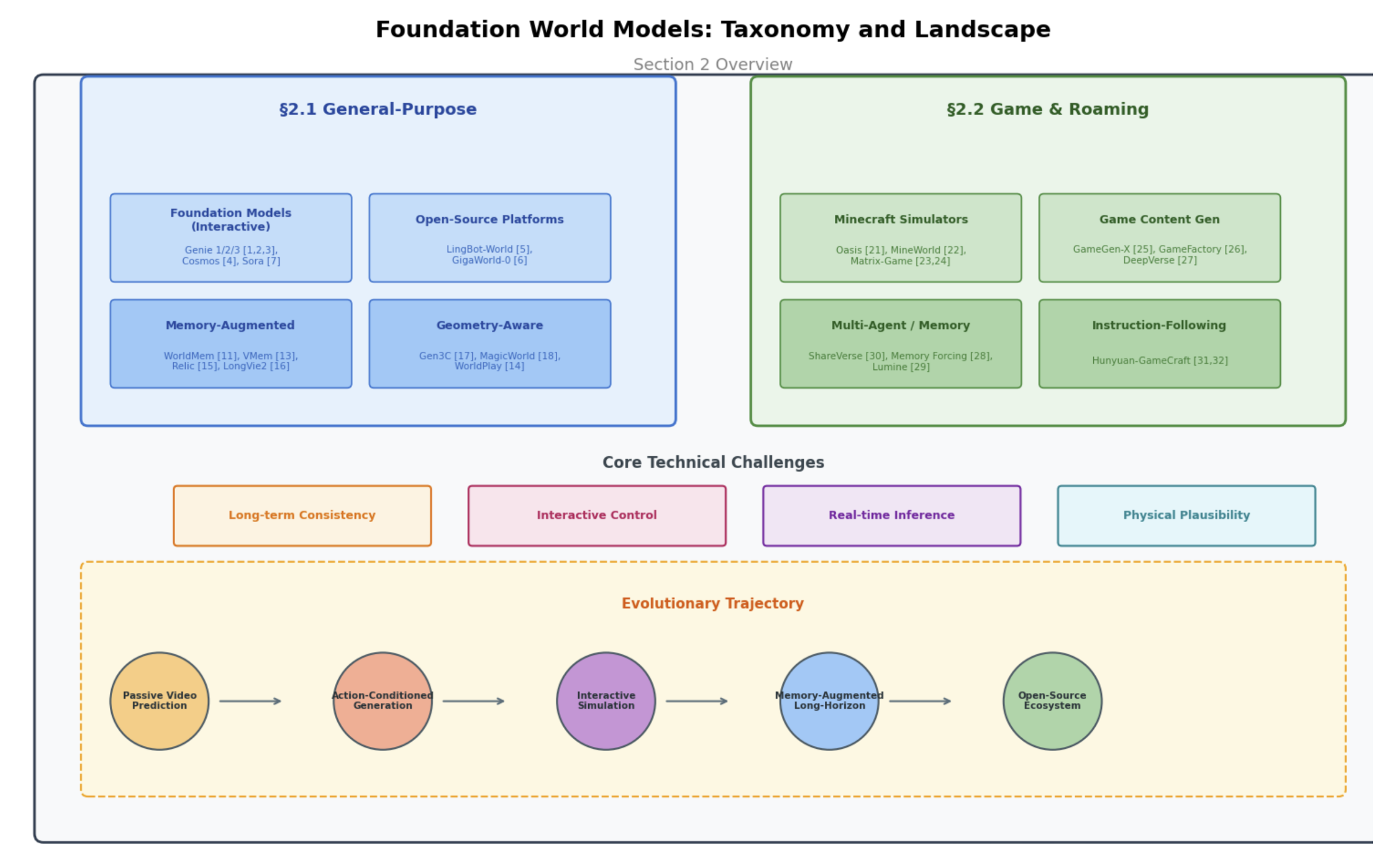
尽管基础世界模型侧重于预测未来的观测结果,但“视觉-语言-动作”(VLA)模型所解决的,却是另一项互补的挑战:将以自然语言表达的高层级人类意图,具象化并转化为低层级的物理控制信号。通过将视觉感知、语言推理和运动动作整合于单一的端到端架构之中,VLA 模型成为在现实世界中运作的具身智体(embodied agents)的核心策略支柱。如图 3 所示VLA 领域划分为三个主要分支进行梳理:基础VLA、自动驾驶VLA和具身VLA,关键技术包括动作token化、跨莫泰对齐、规模化和泛化、推理和CoT、以及实时效率,演化轨迹如专用BC策略、VLM协同微调、通才VLA、流匹配/扩散模型的动作、3D觉察和推理VLA、以及开源生态。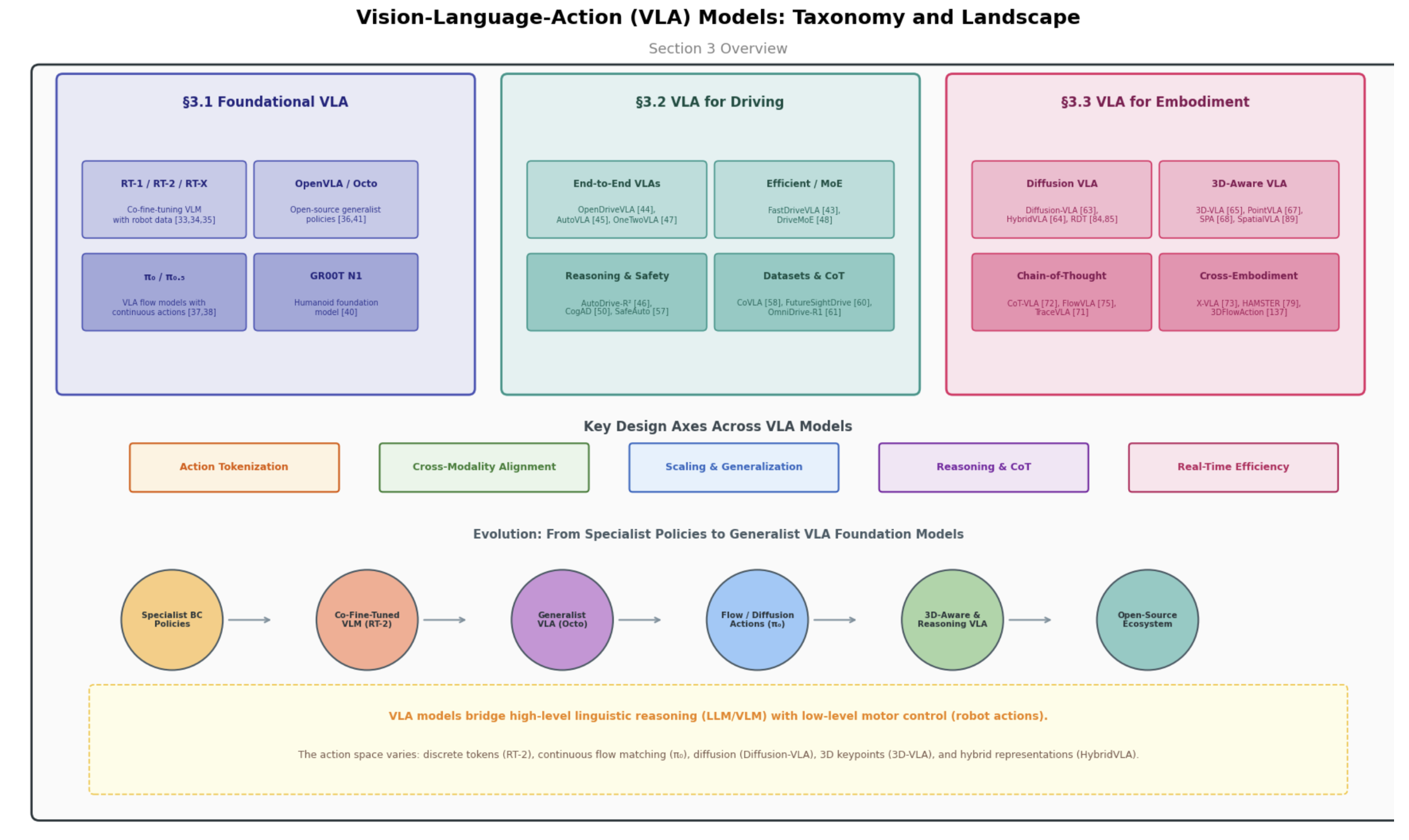
如图 4所示:VLA 模型中的动作表征范式。(a) 离散token化(RT-2)将动作视为词汇tokens;(b) 连续流匹配(π0)通过速度场生成平滑的动作片段;© 扩散解码(Diffusion-VLA, RDT)在 LLM 推理的条件下对动作轨迹进行去噪。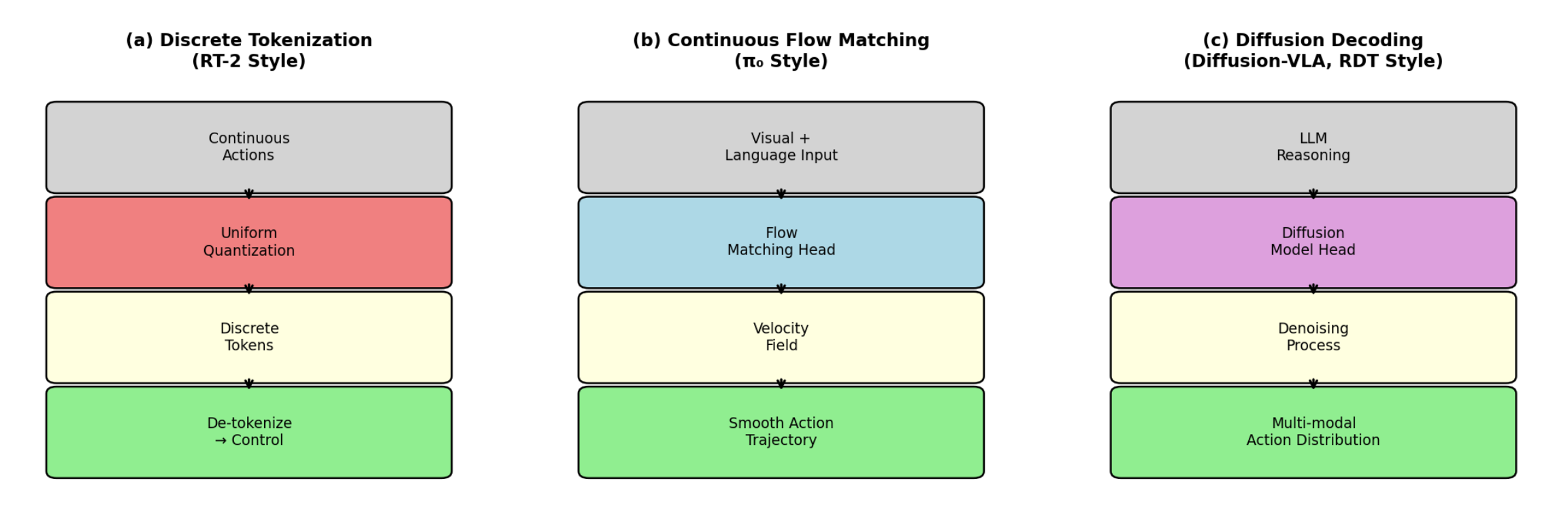
基础世界模型预测未来的景象;视觉-语言-动作模型决定应执行何种动作。具身世界动作模型(WAMs)代表这两种范式的自然融合:这类架构在一个统一的生成框架内,既能模拟未来状态,又能生成可执行的动作。WAMs 不再将世界模拟与策略执行视为相互独立的流水线,而是学会去构想动作可能产生的后果并直接输出控制信号;或者,它们充当可微分的模拟器,使策略能够在其中进行训练与优化,从而避免昂贵的现实世界交互成本。 如图 5 所示WAMs 划分为三个分支:基于视频生成的 WAM 、可控仿真平台以及策略/规划框架,充分展现世界模型与 VLA 策略之间的融合趋势,其演化从世界模型(预测)、VLA策略(动作)、WAM训练(想象展开)、谨慎规划和WAM中的规模化RL。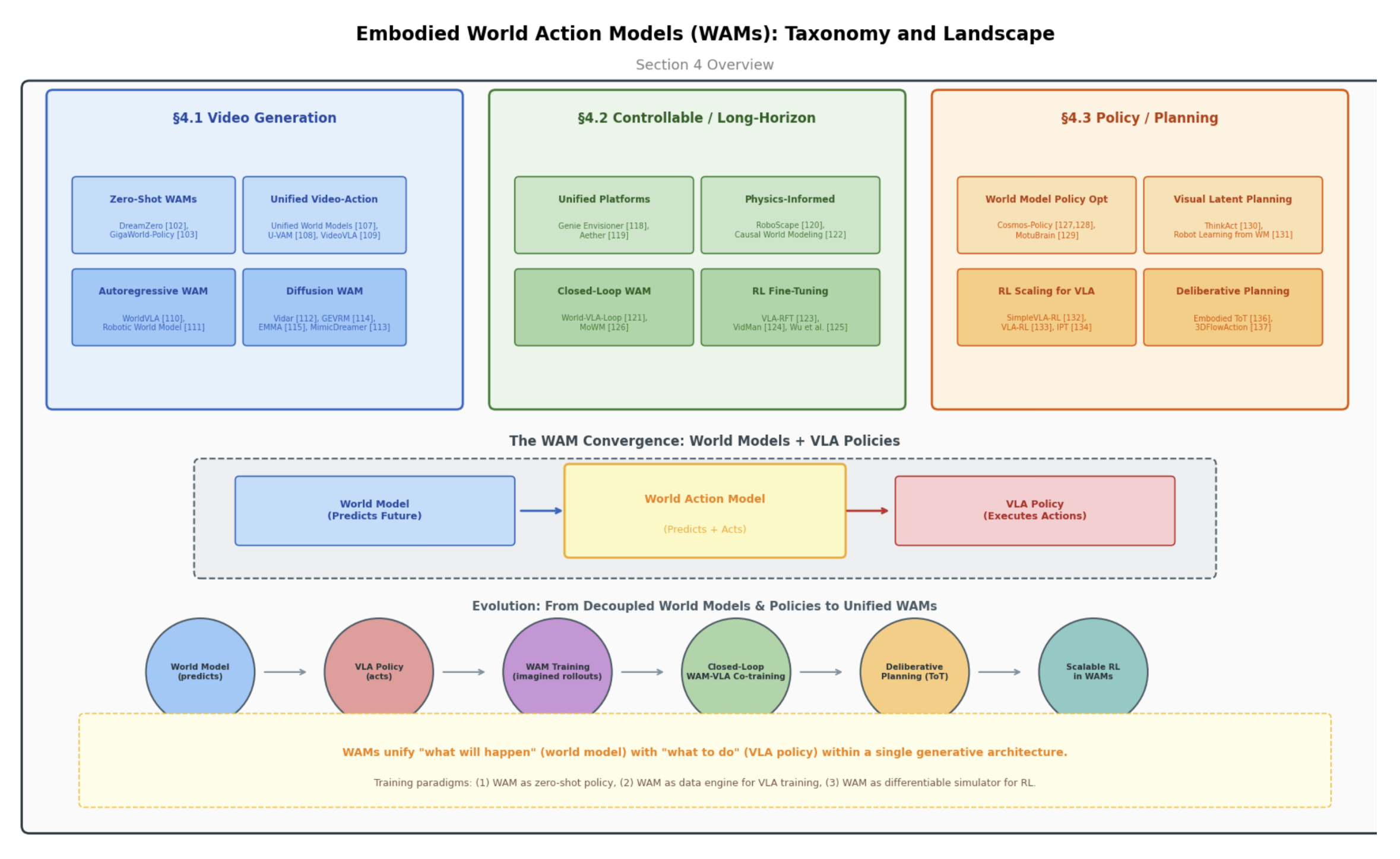
如图 6 所示:具身世界动作模型的训练范式。(a) WAM 作为零样本策略:模型直接预测动作,无需进行显式的策略训练。(b) WAM 作为数据引擎:合成的想象轨迹用于扩充稀缺的真实世界数据,以辅助 VLA模型的训练。© WAM 作为可微分模拟器:策略梯度通过世界模型进行反向传播,从而实现对控制策略的优化。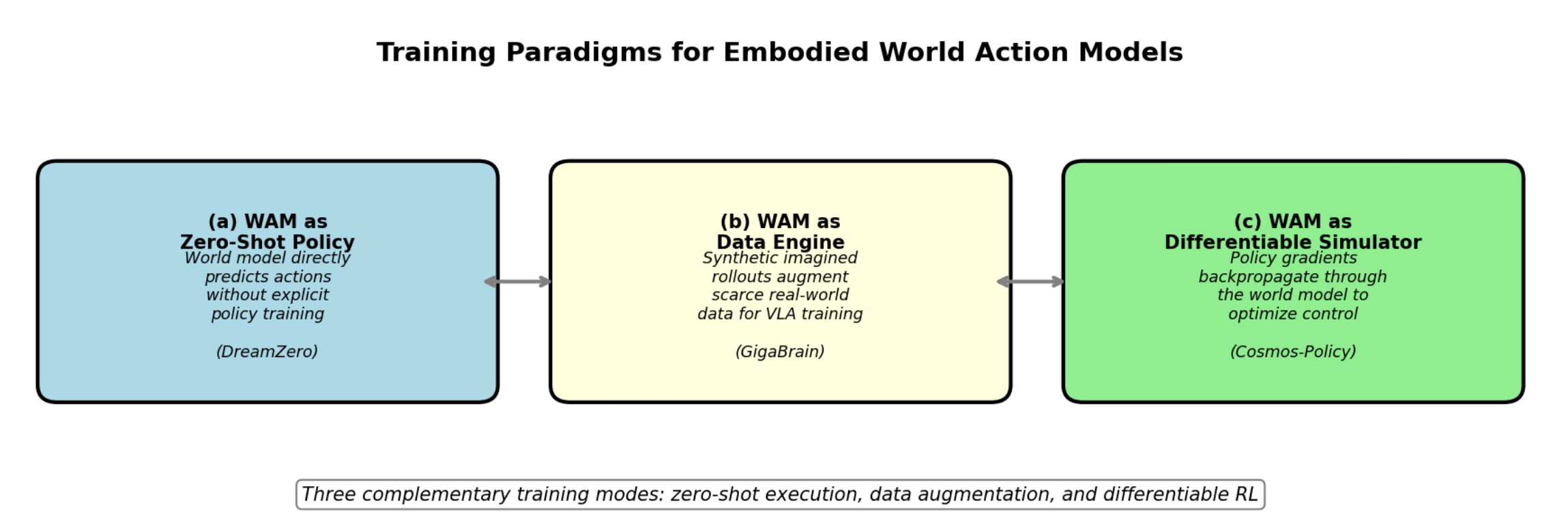
自动驾驶是“世界模型”(World Models)应用领域中要求最为严苛、且对安全性要求极高的领域之一。相较于通用仿真器或具身操作环境,自动驾驶世界模型必须能够处理高速动态场景、严格的几何约束、多智体交互,以及法规层面的安全要求。如图 7 所示自动驾驶世界模型划分为四个主要分支:视频生成、可控仿真、规划策略以及占据/BEV(鸟瞰视图)表征,其中尤为突出闭环自动驾驶管线; 闭环的自动驾驶包括多视图传感器、感知和BEV、世界模型(预测未来)、规划(轨迹)、控制(转向/加速)和闭环反馈;进化趋势如:模块化感知-规划、端到端驾驶网络、生成视频WM、4D场景表征、世界动作模策略和闭环虚拟-到-真实迁移;自动驾驶模型必须满足安全约束、集合一致性、物理合理性和长时程稳定性。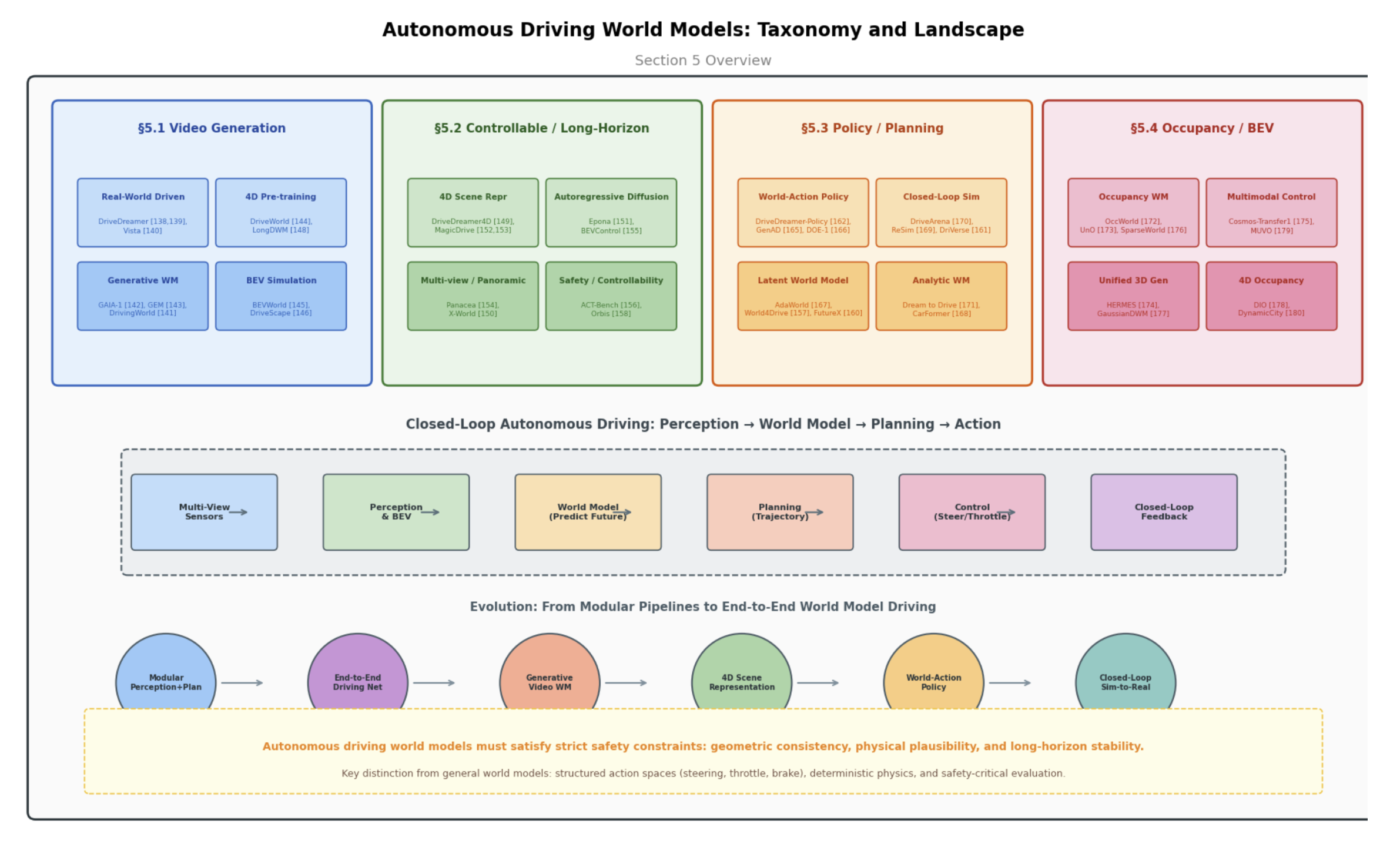

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献143条内容
已为社区贡献143条内容

所有评论(0)