团结引擎小游戏平台 Burst 编译器支持 —— 提升小游戏运行性能与控制包体大小
在小游戏开发中,CPU 性能瓶颈和包体大小是开发者面临的两大核心挑战。Burst是一个基于 LLVM 的深度优化后端编译器,能够将 C# 高性能计算子集(HPC#)编译为高度优化的机器码,显著提升 CPU 密集型计算的运行帧率。同时,针对小游戏的包体敏感性,我们为 Burst 引入了独有的 Managed回退分支裁剪 功能,在保证性能的前提下有效控制 wasm 包体大小。
Burst 的 HPC# 代码不经过 IL2CPP 转换,而是直接通过 Burst 优化器生成 LLVM IR,经由 LLVM 优化器产出高效的 wasm 代码,绕过了 IL2CPP 对 .NET垃圾回收机制的模拟,并能够基于 HPC# 的严格假设执行更激进的内联、循环展开和向量化优化。值得关注的是,Burst 可以独立于 Job/ECS 使用,开发者不必依赖完整的 DOTS 框架。
Burst 编译器(com.unity.burst)现已支持团结引擎小游戏平台。其中,Burst Package 1.8.21 及以上支持小游戏平台的基本编译优化功能,Managed 回退分支裁剪功能要求 Burst Package 1.8.27 及以上(引擎版本 Tuanjie 1.9.0 及以上)。
Burst 带来的收益
丨性能收益
在小游戏场景中,诸如物理碰撞、大量实体的裁剪计算、避障算法、粒子模拟等 CPU 密集型任务往往是性能瓶颈。Burst 编译器通过 LLVM 的编译层级优化,能够显著加速这些计算过程,无需修改业务逻辑即可获得可观的帧率提升。
以下性能数据基于 oppo A5 测试机、微信小游戏平台测得,裁剪等级为 Medium。
丨Infinity 粒子系统场景
Infinity 粒子系统(团结引擎粒子系统)是大规模使用 HPC# 编写并用 Burst 编译的典型项目。其核心计算逻辑(粒子模拟、采样、裁剪等)全部采用 HPC# 实现,充分利用了 Native 容器、Unity.Mathematics 等特性,并通过 SOA 数据组织方式进一步优化计算性能。因此,Infinity 的测试场景(Main、Test200、TestSingle)能够充分验证 Burst 编译优化和包体裁剪的实际效果。该测试场景来自开源项目 Infinity Benchmark Suite,开发者可自行下载运行。
丨Main 场景
|
指标 |
Burst+裁剪 |
不开启Burst |
Burst无裁剪 |
优化效果 |
|---|---|---|---|---|
|
FPS(帧率) |
36.1 |
2.3 |
34.6 |
+1469% |
|
wasm包体(KB) |
24,223 |
24,050 |
25,646 |
-5.5% |
丨TestSingle 场景
|
指标 |
Burst+裁剪 |
不开启Burst |
Burst无裁剪 |
优化效果 |
|---|---|---|---|---|
|
FPS(帧率) |
56.9 |
1.2 |
57.7 |
+4642% |
|
wasm 包体(KB) |
23,923 |
23,783 |
25,609 |
-6.6% |
注:Infinity 场景中不开启 Burst 时帧率极低,是因为粒子系统在帧率不足时会触发多步模拟(Multi-Step)机制——即在一帧内执行多次物理模拟以追赶落后的时间步,进一步加重 CPU 负担,导致帧率持续恶化。开启 Burst 后帧率回归正常水平,多步模拟不再触发,性能得以充分发挥。因此,Infinity 场景的 FPS 提升幅度包含了多步模拟机制消除后的叠加效果。
第三方插件场景(Asset Store 插件及算法测试)
丨Congi 场景
|
指标 |
Burst+裁剪 |
不开启Burst |
Burst无裁剪 |
优化效果 |
|---|---|---|---|---|
|
FPS(帧率) |
20 |
8.1 |
20.2 |
+147% |
|
wasm 包体(KB) |
18,896 |
18,694 |
18,972 |
-0.4% |
丨Duck 场景(软光栅化)
|
指标 |
Burst+裁剪 |
不开启Burst |
Burst无裁剪 |
优化效果 |
|---|---|---|---|---|
|
FPS(帧率) |
34.1 |
14.6 |
33.8 |
+134% |
|
wasm 包体(KB) |
18,355 |
18,301 |
18,433 |
-0.4% |
丨Noise 场景(噪声算法)
|
指标 |
Burst+裁剪 |
不开启Burst |
Burst无裁剪 |
优化效果 |
|---|---|---|---|---|
|
FPS(帧率) |
3.9 |
2.2 |
3.9 |
+77% |
|
wasm 包体(KB) |
18,154 |
18,132 |
18,202 |
-0.3% |
包体收益
Burst 编译器的激进内联优化在提升性能的同时,可能会导致 wasm 包体膨胀。为此,团结引擎小游戏平台针对 Burst 引入了 Managed 回退分支裁剪功能。开启裁剪后,在帧率无明显降低的前提下,wasm 包体大小得到有效控制:
- 开启 Burst + 包体裁剪后,包体相比不裁剪可减少 0.3% 至 6.6%,帧率几乎不变
- 开启 Burst 后的包体与不开启 Burst 的包体大小相当,引入 Burst 不会导致包体明显增大
包体裁剪功能
通过引入 Managed 回退分支裁剪功能,Burst 在小游戏平台上实现了提升帧率的同时包体不会明显膨胀。下面介绍其原理和使用方式。
丨为什么需要裁剪
Burst 编译器在处理标记了 [BurstCompile] 的 HPC# 函数和 Job 函数时,除了生成经过 Burst 优化器深度优化的 Native Code(最终编译为 wasm)之外,还会保留一份内容与原函数完全相同的 Managed 回退函数。这份 Managed 回退函数并非由 Burst 编译,而是会经过 IL2CPP 编译出现在最终的 wasm 包体中。
Managed 回退分支的设计初衷是:当 Burst 运行时未启用时,系统可以经由 Managed 回退函数回到 C# 原始实现。但在小游戏平台上,Burst 始终以 AOT 方式编译,不存在回退场景,因此经过 IL2CPP 编进包体的 Managed 回退函数成为纯粹的冗余代码,会导致 wasm 包体膨胀。
丨裁剪实现原理
包体裁剪的核心思路是:在 IL2CPP 编译链路中裁剪掉 Managed 回退函数,这样 Managed 回退函数就不会出现在最终的 wasm 包体中。
具体实现上,团结引擎在编译流程中新增了 Managed 回退分支裁剪步骤,检测到 Managed 回退函数时将其函数体替换为抛异常的代码。经过这样处理后的代码作为 IL2CPP 的输入,IL2CPP 生成的 wasm 中便不再包含这些冗余的 Managed 回退函数实现,从而有效降低了包体大小。由于小游戏运行时 Burst 始终启用,优化后的 Native Code 会优先执行,替换后的异常代码永远不会被触发,不影响实际运行。
丨使用方式
1. 在 Player Settings 中,将 "Managed Stripping Level" 设为 "Medium" 或以上
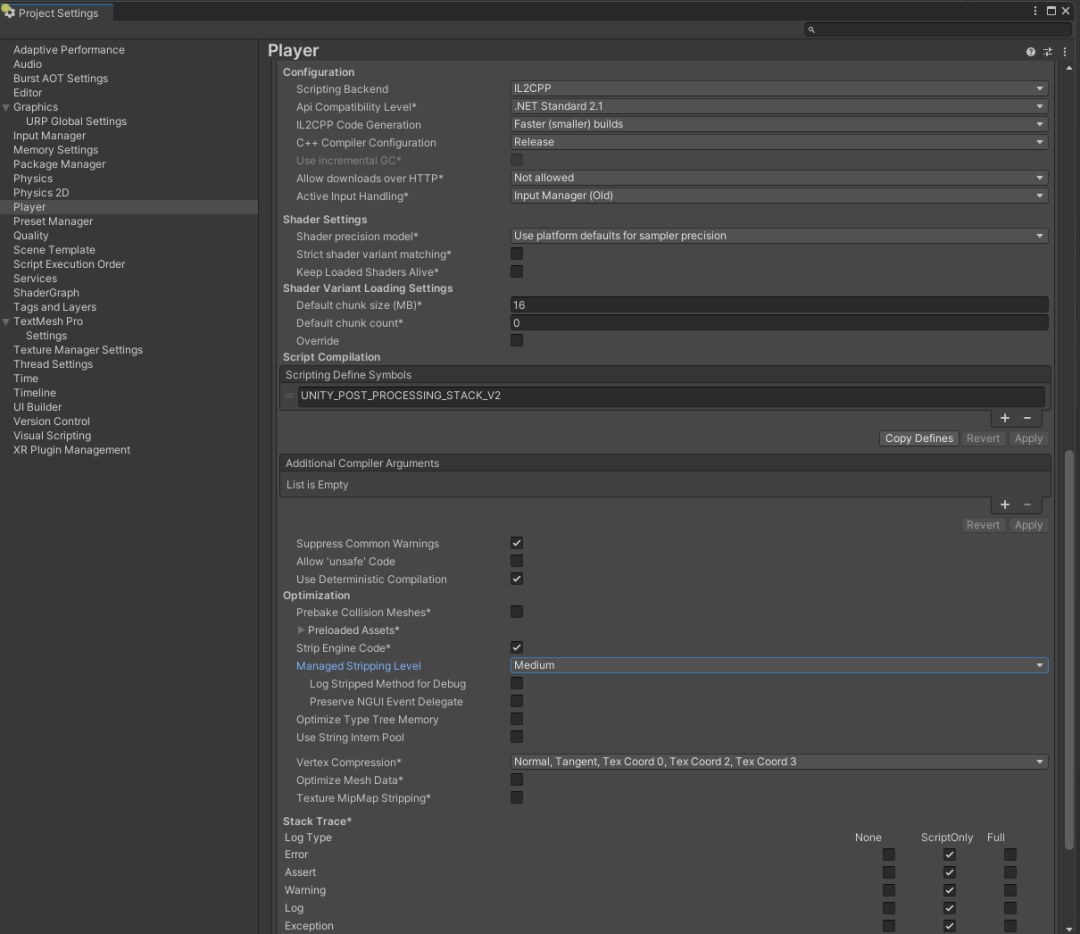
2. 在 Burst AOT Settings 中,勾选 "Enable Burst Compilation"
3. 在 Burst AOT Settings 中,勾选 "Strip Burst Managed Method"(该选项仅在 Enable Burst Compilation 开启时可见)
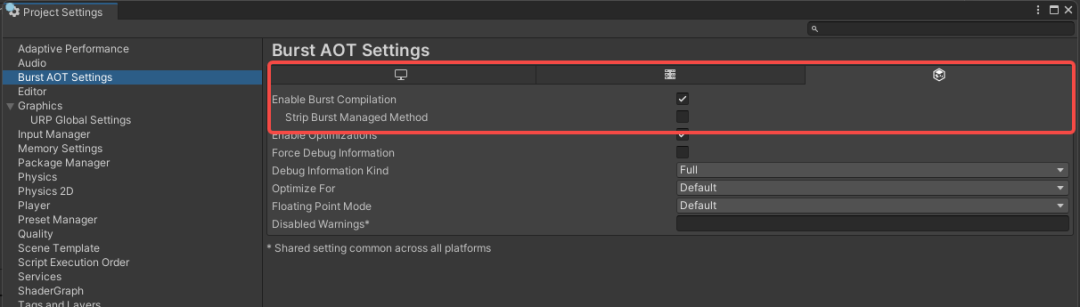
注:当 "Managed Stripping Level" 为 "Medium" 及以上,且同时勾选了 "Strip Burst Managed Method" 时,裁剪编译流程才会生效。
丨验证裁剪效果
打包完成后,可在打包输出目录下找到 webgl/Build/webgl.wasm 文件,对比开启和不开启 "Strip Burst Managed Method" 时该文件的大小差异,即可确认裁剪效果。以含 Infinity 粒子系统的项目为例,开启裁剪后 wasm 包体可减少约 1,918 KB(约 6%)。裁剪比例与 HPC# 代码在整个项目代码中的占比呈正相关——项目中使用 HPC# 编写的代码越多,裁剪效果越明显。
Burst 如何使用
丨快速使用
开发者可以通过以下方式在项目中使用 Burst。
1. 确认使用方式
Burst 支持两种使用方式,开发者可根据项目场景选择:
- Job.Run 方式:适合已有 Job 系统的项目。在小游戏单线程环境下,只需将 Job.Schedule 改为 Job.Run 即可执行
[BurstCompile]public struct MyJob : IJobFor{public NativeArray<float> data;public void Execute(int index){data[index] = data[index] * 2.0f;}}// 在小游戏平台上使用 Run 执行var job = new MyJob { data = dataArray };job.Run(dataArray.Length);
- 静态函数调用方式:适合将计算逻辑封装为独立函数的场景。将计算逻辑封装在静态函数中,加上
[BurstCompile]public struct ComputeLibrary{[BurstCompile]public static void ProcessData(ref NativeArray<float> data, int count){for (int i = 0; i < count; i++){data[i] = math.sqrt(data[i]);}}}
注意:函数外围的 class/struct 也需要加上 [BurstCompile] 标签。Burst 会先查找类型上的标签,再去编译内部标记的函数。
2. 确认 Build 设置
打包时需确认以下设置:
1. Burst AOT Settings 中勾选 "Enable Burst Compilation"
2. 如需包体裁剪,勾选 "Strip Burst Managed Method",并将 "Managed Stripping Level" 设为 "Medium" 或以上
最佳实践
业务逻辑与算法分离:Burst 更适合计算密集的算法,而非多态/继承较多的业务逻辑。建议将核心计算逻辑改写为 HPC# 并用 Burst 编译,封装成独立接口供上层业务逻辑调用。
HPC# 替换步骤:在完成业务逻辑与算法的分离后,将算法部分的 C# 代码转换为 HPC# 的通用步骤如下:
1. 替换托管内存为非托管内存:class → struct
2. 替换容器类型:
Array → NativeArray,
List → NativeList,
Dictionary → NativeHashMap
3. 提炼计算过程为 static 方法:在方法和所属类型上标注 [BurstCompile]
4. 替换数学库:System.Math → Unity.Mathematics
其他注意事项:
- 使用 in/ref 传递 struct:HPC# 主要使用 struct,Native 容器中的 struct 元素必须以 in 或 ref 方式传递,否则会导致 BC1064 编译错误
- 手动内存管理:Native 容器使用完毕后需要显式调用 Dispose 释放内存
总结
团结引擎小游戏平台 Burst 编译器支持为开发者带来了两大核心价值:
1. 显著的性能提升:测试表明,开启 Burst 后,第三方插件和算法场景的帧率可获得 77% 至 147% 的提升;Infinity 粒子系统等大规模使用 HPC# 的项目,性能收益更为显著。效果因代码中计算密集程度而异,计算越密集提升越明显
2. 可控的包体大小:通过独有的 Managed 回退分支裁剪技术,开启 Burst + 裁剪后,wasm 包体相比不裁剪可减少 0.3% 至 6.6%,同时帧率几乎不受影响。裁剪比例与 HPC# 代码在整个项目代码中的占比呈正相关——项目中使用 HPC# 编写的代码越多,裁剪效果越明显。且引入 Burst 后的包体与不开启 Burst 的包体大小相当,不会给小游戏带来额外的包体压力
Burst 作为 DOTS 技术栈中独立的一环,可以脱离 Job/ECS 单独使用。开发者只需将计算密集的算法逻辑改写为 HPC#,加上 [BurstCompile] 标签,即可在小游戏平台上享受 LLVM 带来的深度编译优化。展望未来,随着 AI 辅助开发逐渐成为趋势,我们计划将 HPC# + Burst 的最佳实践蒸馏为可复用的开发 Skill,帮助开发者更便捷地将业务中的计算密集模块改写为 HPC# 并应用 Burst 编译优化,降低使用门槛,让更多小游戏项目享受到高性能计算带来的体验提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)