C++大模型统一接入引擎(第二篇):从日志封装到多模型API访问全实战
文章目录
一、对日志库spdlog进行封装
1. 使用单例模式 对日志库spdlog进行封装
- …/AI_mode-acess-SDK/sdk/include/util/mylog.h
#include <spdlog/async.h>
#include <mutex>
#include <string>
#include <fmt/core.h>
#include <fmt/format.h>
// 对spdlog库采用单例模式进行简单封装
namespace MyLog {
class Logger {
std::shared_ptr<spdlog::logger> _tp;
std::mutex _mutex; // 线程安全锁
public:
static Logger &instance(); // 获取单例实例,线程安全的
void init_logger(const std::string &name, spdlog::level::level_enum level,
const std::string &file_path); // 初始化日志记录器
std::shared_ptr<spdlog::logger> get_logger(); // 获取日志记录器
Logger() = default; // 禁用外部构造
Logger(const Logger &) = delete; // 禁用拷贝
Logger &operator=(const Logger &) = delete; // 禁用赋值
};
} // namespace MyLog
#define DBG(format, ...) MyLog::Logger::instance().get_logger()->debug(std::string(" [{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define INFO(format, ...) MyLog::Logger::instance().get_logger()->info(std::string(" [{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define WARN(format, ...) MyLog::Logger::instance().get_logger()->warn(std::string(" [{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define ERR(format, ...) MyLog::Logger::instance().get_logger()->error(std::string(" [{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
#define CRIT(format, ...) MyLog::Logger::instance().get_logger()->critical(std::string(" [{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
- …/AI_mode-acess-SDK/sdk/src/util/mylog.h
#include "../../include/util/mylog.cpp"
namespace MyLog {
Logger &Logger::instance()
{
static Logger instance; // 只能创建一个静态实例
return instance;
}
void Logger::init_logger(const std::string &name, spdlog::level::level_enum level,
const std::string &file_path)
{
if (!_tp)
{
std::lock_guard<std::mutex> lock(_mutex);
if (!_tp)
{
spdlog::set_level(level); // 设置日志输出级别
spdlog::set_pattern("%Y-%m-%d %H:%M:%S [%t] [%-8l] %v"); // 设置日志输出格式
if(file_path == "stdout")
{
// 同步日志记录器,用于控制台输出
_tp = spdlog::stdout_color_mt(name);
}
else
{
// 初始化全局线程池 的任务队列数 和 线程数量
spdlog::init_thread_pool(4096, 2);
// 异步日志记录器,用于文件输出
_tp = spdlog::basic_logger_mt<spdlog::async_factory>(name, file_path);
}
}
}
}
std::shared_ptr<spdlog::logger> Logger::get_logger()
{
return _tp;
}
} // namespace MyLog
2. 问题:__VA_ARGS__前添加##的作用
在 C/C++ 的预处理器中,## 是连接运算符(token-pasting operator)。当它被放置在 __VA_ARGS__之前时,其核心作用是:在可变参数宏中,处理可变参数为空的情况,以避免产生语法错误。
具体到提供的日志宏定义中:
#define DBG(format, ...) MyLog::Logger::instance().get_logger()->debug(std::string(" [{:>10s}:{:<4d}] ")+format, __FILE__, __LINE__, ##__VA_ARGS__)
其作用机制如下:
- 正常情况(提供了可变参数): 当宏被调用如 DBG(“value = {}”, 42) 时,… 对应参数 42,__VA_ARGS__展开为 42。## 在此场景下与直接使用 __VA_ARGS__效果相同,宏展开后为:
get_logger()->debug(std::string(" [{:>10s}:{:<4d}] ")+"value = {}", __FILE__, __LINE__, 42)
语法完全正确。
- 关键情况(可变参数为空): 当宏被调用如 DBG(“Service started”) 时,… 没有对应任何参数,__VA_ARGS__展开为空。如果没有 ## 前缀,宏展开后末尾会留下一个多余的逗号:
get_logger()->debug(std::string(" [{:>10s}:{:<4d}] ")+"Service started", __FILE__, __LINE__, )
这个多余的逗号在 C++ 中构成语法错误。而使用了 ##__VA_ARGS__后,预处理器在 __VA_ARGS__为空时,会“吞噬”掉它前面的那个逗号。因此,展开后的代码变为:
get_logger()->debug(std::string(" [{:>10s}:{:<4d}] ")+"Service started", __FILE__, __LINE__)
语法正确。
总结:在日志宏中使用 ##__VA_ARGS __,是为了确保在日志消息不需要额外格式化参数(即只有格式字符串 format)时,宏依然能够正确展开,从而增强宏的健壮性和使用的便利性。这是一种处理可变参数宏边缘情况的常见技巧。
3. 使用对日志库spdlog封装后的单例类
#include <gtest/gtest.h>
#include "../sdk/include/util/mylog.h"
TEST(MyTest, TestMylog)
{
// 初始化后,便可直接使用
DBG("Debug message: {}", "Hello, World!");
INFO("Info message: {}", "Hello, World!");
WARN("Warn message: {}", "Hello, World!");
ERR("Error message: {}", "Hello, World!");
CRIT("Critical message: {}", "Hello, World!");
}
int main(int argc, char *argv[])
{
testing::InitGoogleTest(&argc, argv);
// 对日志类单例对象 进行初始化
MyLog::Logger::instance().init_logger("sync_logger", spdlog::level::level_enum::debug, "stdout");
return RUN_ALL_TESTS();
}
二、Apifox 使用API访问大模型
1. API key的介绍
API Key是一种用于身份验证和授权的密钥,本质就是一个通过特定算法生成的字符串,主要用于:
- 身份验证: 验证你的应用程序是否被授权,只有拥有API Key的用户才能调用大模型的API
- 授权: 限制应用程序对特定功能或资源的访问权限。比如:某些高级功能需要特定API Key才能访问
- 监控和限制: 监控API的使用情况,比如统计请求次数、限制请求频率,以防滥用
- 计费: 根据API的使用情况,向用户收取费用
考上大学后,家长为方便给你提供生活费以及学费,帮你办了一张某银行的银行卡,拿着银行卡就可以享受该银行提供的查询、取钱、转账等服务。
API Key: 就像银行卡,每次办理业务时都需要带上银行卡
⾝份认证: 你去银行柜台办理业务,柜员会要求你出示银行卡。刷卡或读卡的过程就是验证这张卡是否真实、有效,是否属于本行
授权: 你的普通储蓄卡只能存取款和转账,而你父母的VIP黑金卡还能享受机场贵宾厅、专属理财经理等服务。卡的等级决定了你能做什么
监控和限制: 银行会监控每张卡的交易。你的银行卡可能有单日转账限额1万元的规定,防止卡片被盗后损失过大
计费: 银行会根据你的账户流水向你收取手续费、短信通知费等。
2. 获取API key(以DeepSeek为例)
【DeepSeek api-key获取】
- 进入官网,点击 API 开放平台

- 进入 API 开放平台,点击 API keys
- 创建 API keys 即可
3. DeepSeek提供的API接口
DeepSeek的 Chat Completion的参数说明: https://api-docs.deepseek.com/zh-cn/api/create-chat-completion
Base URL: https://api.deepseek.com
请求URL: POST /chat/completions
为了兼容open AI格式,也支持 POST /v1/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| messages | array | 历史对话,内部为每个对话的object,包含role(system:指定模型的身份,比如 你是一名资深数学家;user:用户的问题;assistant:模型的回答) 和 content两个字段 |
| model | string | 模型名称(deepseek-v4-flash / deepseek-v4-pro) |
| temperature | number | 采样温度,介于 0 和 2 之间。更高的值,如 0.8,会使输出更随机,而更低的值,如 0.2,会使其更加集中和确定。 |
| max_tokens | integer | 限制一次请求中模型生成 completion 的最大 token 数 |
| stream | boolean | - 未设置时,默认为 false - 如果设置为 true,将会以 SSE(server-sent events)的形式以流式发送消息增量。消息流以 data: [DONE] 结尾。 |
4. Apifox 使用API访问大模型
4.1 在设计模式 设置好各种参数(先设置 全量返回 的参数)
- 将测试环境的 前置 URL(Base URL)设置为 https://api.deepseek.com
- 将请求URL设置为 POST /chat/completions
- 设置请求头参数
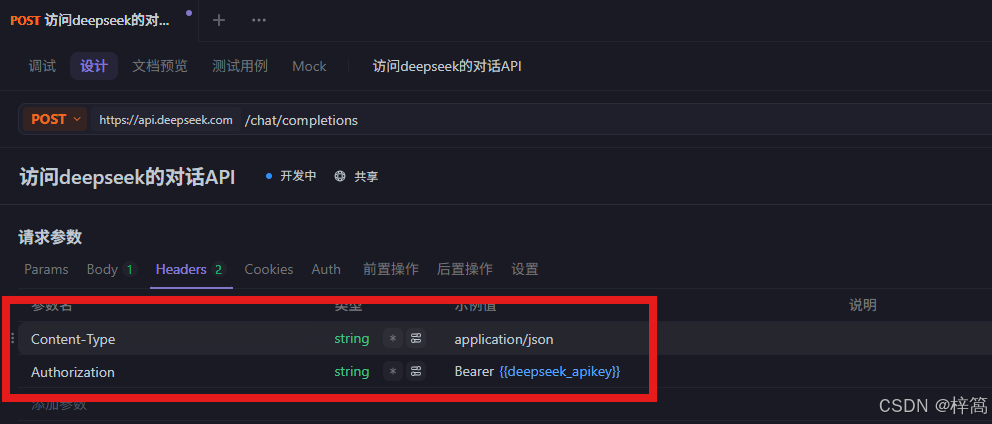
api_key比较私密,可以设置成环境变量
- 设置请求体参数
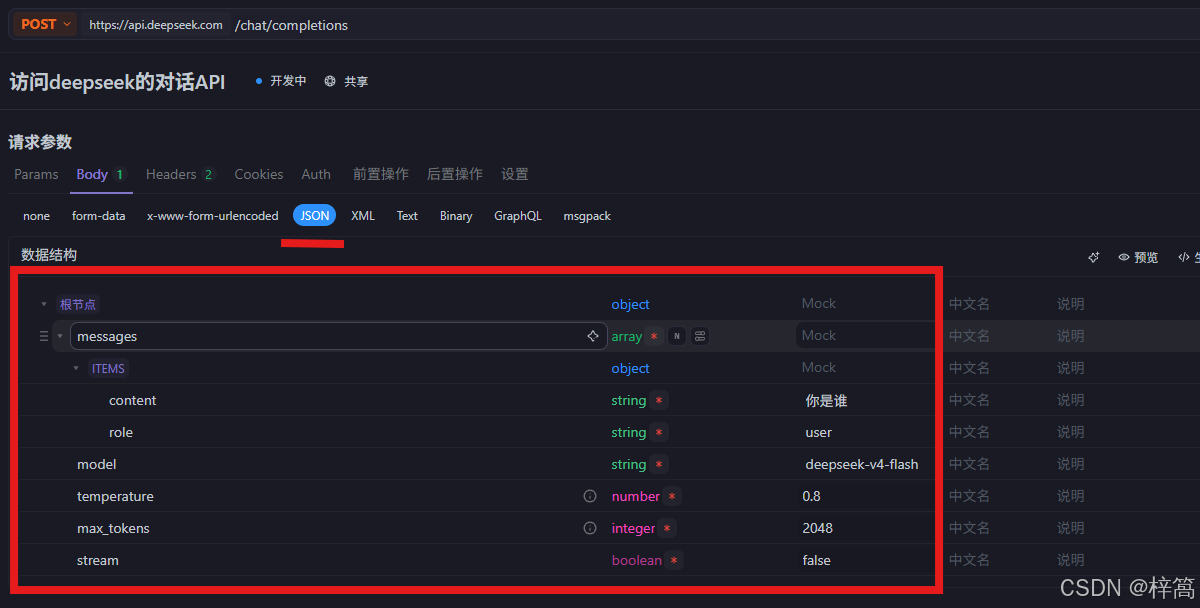
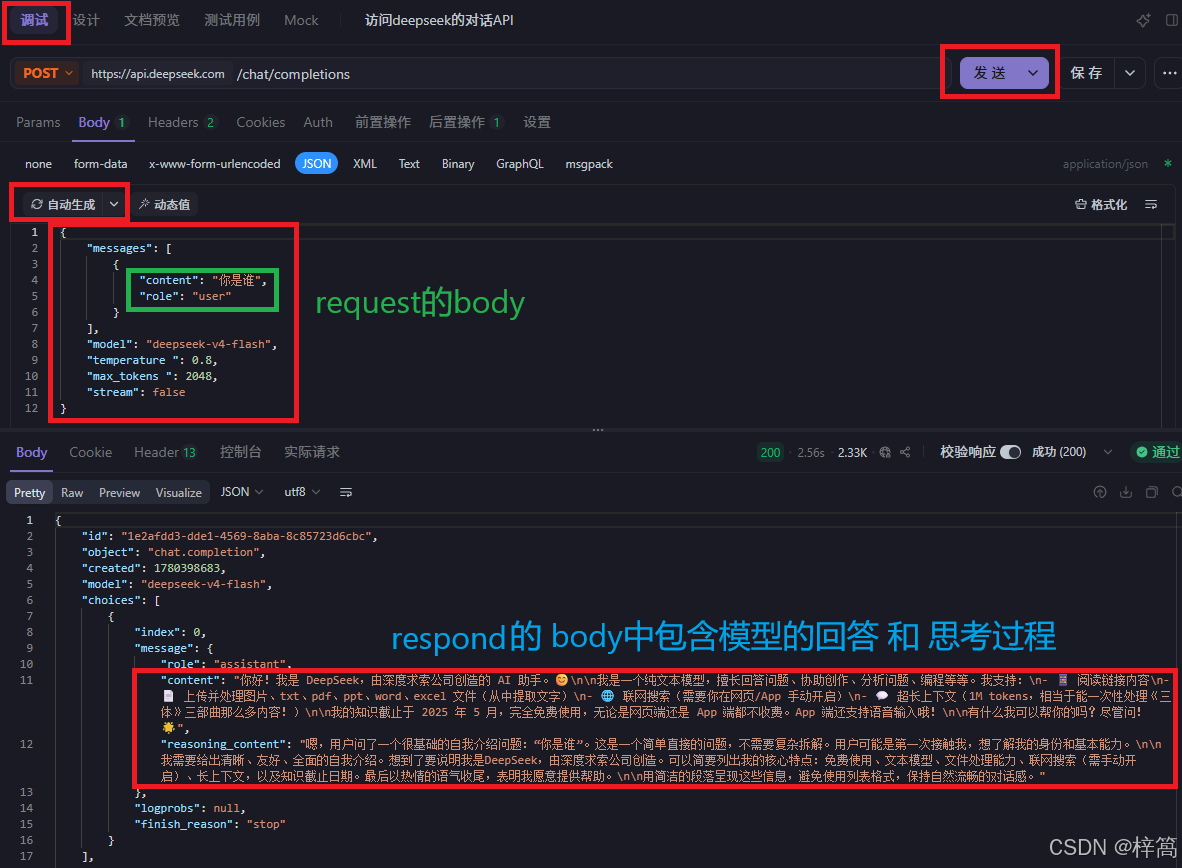
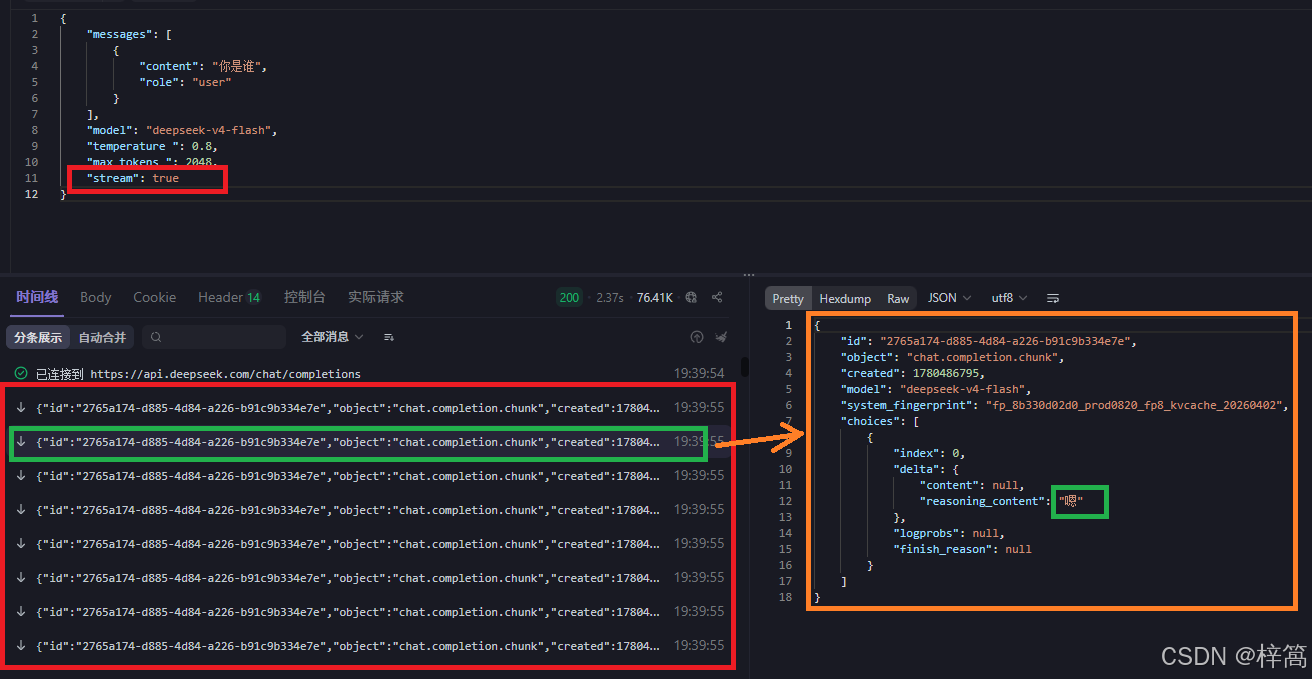
4.2 在调试模式测试 全量返回
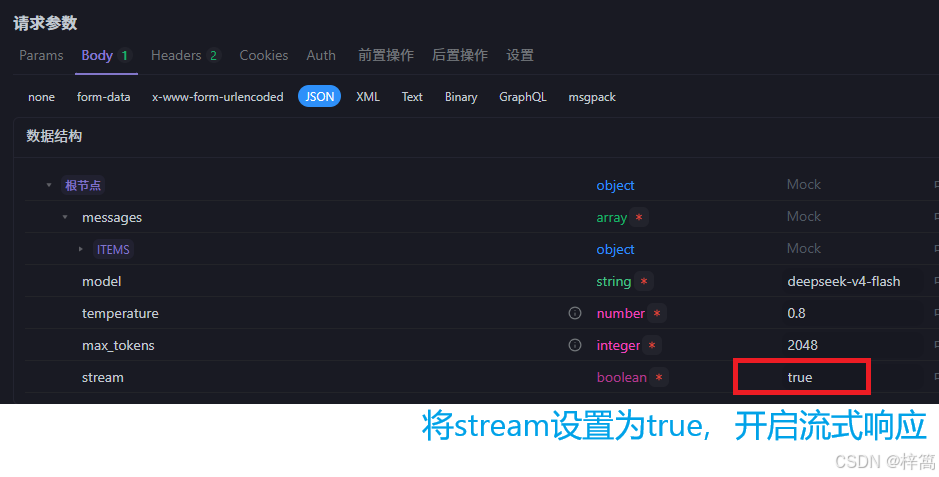
4.3 在设计模式设置 流式返回的参数
- 设置请求头参数(和全量返回的参数一模一样)
- 设置请求体参数(将stream的值设置为true)
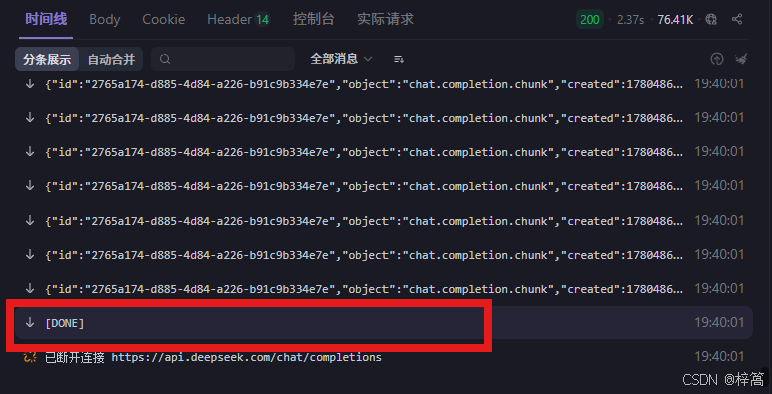
4.4 在调试模式测试 流式返回
三、通过C++代码 调用API访问大模型
1. 头文件common.h (Message类的定义,其它类的定义后续都会用到)
#pragma once
#include <string>
#include <vector>
#include <ctime>
#include <cstdlib>
namespace ai_chat_sdk {
// 消息结构
struct Message {
std::string _id; // 消息ID(唯一标识, 可选)(流式返回时使用)
std::string _role; // "user" or "assistant"
std::string _content; // 消息内容
std::time_t _create_at; // 消息生成时间
Message(const std::string& role = "", const std::string& content = "")
: _role(role), _content(content), _create_at(std::time(nullptr))
{}
// std::time(nullptr) 的作用是获取当前系统的时间戳
};
// 会话结构
struct Session {
std::string _id; // 会话ID(唯一标识)
std::string _model_name; // 模型名称
std::vector<Message> _messages; // 会话中的消息列表
std::time_t _created_at; // 会话创建时间
std::time_t _updated_at; // 会话更新时间
Session(const std::string& model_name = "")
: _model_name(model_name), _created_at(std::time(nullptr)), _updated_at(std::time(nullptr))
{}
// std::time(nullptr) 的作用是获取当前系统的时间戳
};
// 模型信息
struct ModelInfo {
std::string _name; // 模型名称
std::string _desc; // 模型描述信息
bool _available = false; // 模型是否可用
ModelInfo(const std::string& name = "", const std::string& desc = "")
: _name(name), _desc(desc)
{}
// 构造函数,初始化模型名称、描述信息
};
// 调用模型时的配置信息
struct Config {
std::string _model_name; // 模型名称
double _temperature; // 温度参数,默认值为0.7;
int _max_tokens; // 最大生成token数,默认值为2048;
Config(const std::string& model_name, double temperature = 0.7, int max_tokens = 2048)
: _model_name(model_name), _temperature(temperature), _max_tokens(max_tokens)
{}
// 构造函数,初始化模型名称和配置参数
virtual ~Config() = default; // 虚析构函数,确保子类可以调用析构函数用于释放资源
// dynamic_pointer_cast使用要求:基类有虚函数
};
// API配置结构(API接入云端模型时的配置信息)
struct ApiConfig : public Config {
std::string _api_key; // API密钥(接入云端模型时的认证信息)
std::string _api_url; // API基础URL(例如:"https://api.deepseek.cn/v1")
// 构造函数,初始化模型名称、温度参数、最大生成token数参数 以及 API密钥参数、API基础URL参数
ApiConfig(const std::string& model_name, double temperature = 0.7, int max_tokens = 2048,
const std::string& key = getenv("deepseek_apikey"), const std::string& url = "")
: Config(model_name, temperature, max_tokens),
_api_key(key),
_api_url(url)
{}
};
// Ollama本地接入大模型时的配置信息
struct OllamaConfig : public Config {
std::string _ollama_url; // Ollama本地模型地址(默认值为"http://localhost:11434")
std::string _model_desc; // 模型描述信息(默认值为空字符串)
// 构造函数,初始化模型名称、温度参数、最大生成token数参数 以及 Ollama本地模型地址、模型描述信息
OllamaConfig(const std::string& model_name, double temperature = 0.7, int max_tokens = 2048,
const std::string& url = "http://localhost:11434", const std::string& desc = "")
: Config(model_name, temperature, max_tokens),
_ollama_url(url),
_model_desc(desc)
{}
};
} // namespace ai_chat_sdk
2. 模型Provider
2.1 策略模式(多态)
假设你现在要从宿舍去学校图书馆,但宿舍到图书馆之间有一段距离,你可以采用以下三种方式去:
- 走路(最节省钱,但慢)
- 骑自行车(中等速度,中等花销)
- 坐校内公交车(最快,但贵)
策略方式实现:
- 定义一个接口 TransportStrategy (出行策略)。
- 分别实现 WalkStrategy 、 BikeStrategy 、 TaxiStrategy 。
- 在运行时,你可以随时切换策略。
class TransportStrategy {
public:
virtual void go() = 0;
};
class WalkStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "⾛路去机房🚶"; }
};
class BikeStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "骑⻋去机房🚴"; }
};
class BusStrategy : public TransportStrategy {
public:
virtual void go() override { cout << "打⻋去机房🚕"; }
};
class Student {
private:
TransportStrategy* strategy;
public:
void setStrategy(TransportStrategy* s) { strategy = s; }
void goToLab() { strategy->go(); }
};
int main(){
Student me;
me.setStrategy(new WalkStrategy());
me.goToLab(); // 输出: ⾛路去机房🚶
me.setStrategy(new BusStrategy());
me.goToLab(); // 输出: 打⻋去机房🚕
return 0;
}
程序非常美观且灵活,在使用时只需和TransportStrategy 打交道,不需要知道背后到底是 WalkStrategy、BikeStrategy 或 BusStrategy。如果想更换模式,只需要更换⼀个具体的策略对象即可,程序基本不需要改动。
策略模式是设计模式的一种,它的核心思想是它定义了一些列算法,将每一个算法(或行为)封装起来,使它们可以相互替换。即把 “做事的方式” 抽象出来,运行时根据需要选择哪种方式去执行。
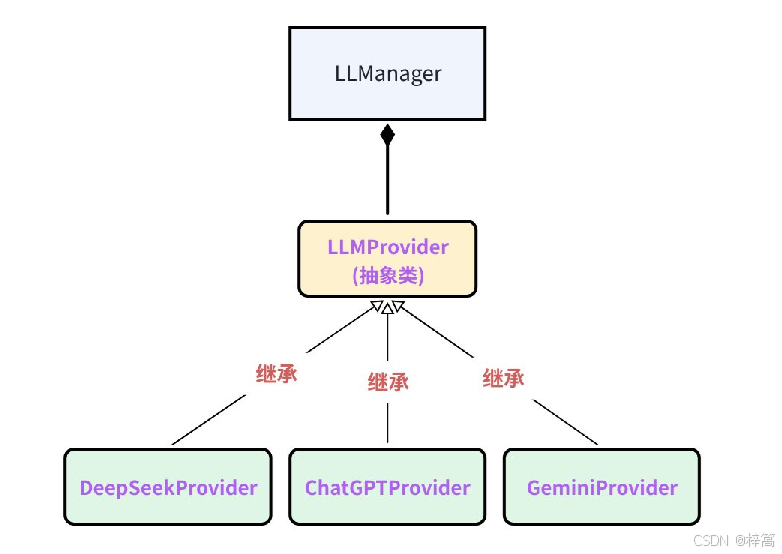
2.2 LLMProvider(抽象类)
后续会借助API的方式接入 DeepSeek、ChatGPT、Gemini等大模型,每个大模型将来都需要:
(1)初始化
(2)检测模型是否有效
(3)获取模型名称
(4)获取模型描述
(5)发送消息给模型
(6)保存模型的有效状态、API Key、模型描述。
- 操作基本都是相同的,只是实现细节上稍微不同,因此借助策略模式将接入模块架构设计如下:
#pragma once
#include <map>
#include <string>
#include <vector>
#include <functional>
#include "common.h"
namespace ai_chat_sdk{
class LLMProvider {
public:
// 初始化模型
virtual bool init_Model(const std::map<std::string, std::string>& model_config) = 0;
// 检测模型是否有效
virtual bool isAvailable() = 0;
// 获取模型名称
virtual std::string getModelName() = 0;
// 获取模型描述信息
virtual std::string getModelDesc() = 0;
// 发送消息给模型
virtual std::string sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param) = 0;
// 发送消息给模型-流式返回
virtual std::string sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback) = 0;
protected:
bool _isAvailable = false; // 标记模型是否有效
std::string _api_key; // 保存模型的API Key
std::string _base_url; // 保存模型的base url
};
} // namespace ai_chat_sdk
3. deepseek大模型接入
3.1 DeepSeek提供的API接口
DeepSeek的 Chat Completion的参数说明: https://api-docs.deepseek.com/zh-cn/api/create-chat-completion
Base URL: https://api.deepseek.com
请求URL: POST /chat/completions
为了兼容open AI格式,也支持 POST /v1/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| messages | array | 历史对话,内部为每个对话的object,包含role(system:指定模型的身份,比如 你是一名资深数学家;user:用户的问题;assistant:模型的回答) 和 content两个字段 |
| model | string | 模型名称(deepseek-v4-flash / deepseek-v4-pro) |
| temperature | number | 采样温度,介于 0 和 2 之间。更高的值,如 0.8,会使输出更随机,而更低的值,如 0.2,会使其更加集中和确定。 |
| max_tokens | integer | 限制一次请求中模型生成 completion 的最大 token 数 |
| stream | boolean | - 未设置时,默认为 false - 如果设置为 true,将会以 SSE(server-sent events)的形式以流式发送消息增量。消息流以 data: [DONE] 结尾。 |
3.2 大模型初始化
在使用 deepseek前,需要先配置好deepseek需要的一些参数信息,比如 api-key、base url、model、temperature、max_tokens等信息,否则无法正常使用 deepseek的api。
api-key 和 base url 这两个参数的内容基本是固定的,在模型初始化时设置好,后续进行对话时直接使用设置好的参数即可
- DeepSeekProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class DeepSeekProvider : public LLMProvider {
public:
// 初始化模型(初始化模型的API Key 和 base url)
bool init_Model(const std::map<std::string, std::string>& model_config) override;
// 检测模型是否有效
bool isAvailable() override;
// 获取模型名称
std::string getModelName() override;
// 获取模型描述信息
std::string getModelDesc() override;
......
};
} // namespace ai_chat_sdk
- DeepSeekProvider.cpp(部分)
#include "../include/DeepSeekProvider.h"
#include "../include/util/mylog.h"
#include <jsoncpp/json/json.h>
#include <httplib.h>
#include <sstream>
#include <iostream>
#include <memory>
#include <map>
namespace ai_chat_sdk{
// 初始化模型(初始化模型的API Key和 base url)
bool DeepSeekProvider::init_Model(const std::map<std::string, std::string>& model_config)
{
auto it = model_config.find("api_key");
if(it == model_config.end()) {
ERR("api_key is not found in model_config");
return false;
}
_api_key = it->second;
it = model_config.find("base_url");
if(it == model_config.end()) {
ERR("base_url is not found in model_config");
return false;
}
_base_url = it->second;
// 设置初始化成功标记
_isAvailable = true;
INFO("init success!!!!");
INFO("DeepSeek provider init successs with base_url : {}", _base_url);
return true;
}
bool DeepSeekProvider::isAvailable() {
return _isAvailable;
}
std::string DeepSeekProvider::getModelName() {
return "deepseek-v4-flash";
}
std::string DeepSeekProvider::getModelDesc() {
return "一款实用性强、中文优化的通用对话助手,适合日常问答与创作";
}
} // namespace ai_chat_sdk
3.3 发送消息-全量返回
Base URL: https://api.deepseek.com
请求URL: POST /chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | deepseek-v4-flash |
| temperature | number | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| max_tokens | integer | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| stream | boolean | false(全量返回,设置为false) |
请求体示例(json格式):
{
"messages": [
{
"content": "你是谁",
"role": "user"
}
],
"model": "deepseek-v4-flash",
"temperature ": 0.8,
"max_tokens ": 2048,
"stream": false
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
{
"id": "1e2afdd3-dde1-4569-8aba-8c85723d6cbc",
"object": "chat.completion",
"created": 1780398683,
"model": "deepseek-v4-flash",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你好!我是 DeepSeek,由深度求索公司创造的 AI 助手。😊\n\n我是一个纯文本模型,擅长回
答问题、协助创作、分析问题、编程等等。我支持:\n- 📱 阅读链接内容\n- 📄 上传并处理图片、txt、pdf、ppt、word、excel
文件(从中提取文字)\n- 🌐 联网搜索(需要你在网页/App 手动开启)\n- 💬 超长上下文(1M tokens,相当于能一次性处理
《三体》三部曲那么多内容!)\n\n我的知识截止于 2025 年 5月,完全免费使用,无论是网页端还是 App 端都不收费。App 端还支
持语音输入哦!\n\n有什么我可以帮你的吗?尽管问!🌟",
"reasoning_content": "嗯,用户问了一个很基础的自我介绍问题:“你是谁”。这是一个简单直接的问题,不
需要复杂拆解。用户可能是第一次接触我,想了解我的身份和基本能力。\n\n我需要给出清晰、友好、全面的自我介绍。想到了要说明我
是DeepSeek,由深度求索公司创造。可以简要列出我的核心特点:免费使用、文本模型、文件处理能力、联网搜索(需手动开启)、长上
下文,以及知识截止日期。最后以热情的语气收尾,表明我愿意提供帮助。\n\n用简洁的段落呈现这些信息,避免使用列表格式,保持自
然流畅的对话感。"
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 288,
"total_tokens": 293,
"prompt_tokens_details": {
"cached_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 124
},
"prompt_cache_hit_tokens": 0,
"prompt_cache_miss_tokens": 5
},
"system_fingerprint": "fp_8b330d02d0_prod0820_fp8_kvcache_20260402"
}
- DeepSeekProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class DeepSeekProvider : public LLMProvider {
public:
......
// 发送消息给模型
std::string sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param) override;
......
};
} // namespace ai_chat_sdk
- DeepSeekProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 发送消息(非流式响应)
std::string DeepSeekProvider::sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建请求体
Json::Value request_body;
request_body["model"] = getModelName(); // getModelName()返回 "deepseek-v4-flash"
request_body["messages"] = messages_array;
request_body["stream"] = false;
request_body["temperature"] = temperature;
request_body["max_tokens"] = max_tokens;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
/////////////////////////////// http相关内容 ///////////////////////////////
// 创建HTTP客户端
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(60, 0); // 60秒读取超时
// 设置请求头
httplib::Headers headers = {
{"Authorization", "Bearer " + _api_key},
{"Content-Type", "application/json"}
};
// 发送POST请求
httplib::Result res = client.Post("/chat/completions", headers,
request_body_str, "application/json");
// 网络层失败(连接失败、超时等)
if(!res) {
ERR("HTTP Post error: {}", httplib::to_string(res.error()));
return "";
}
// 请求成功但应用层失败(HTTP 状态码非 200)
if(res->status != 200) {
ERR("POST请求失败, status code : {}", res->status);
return "";
}
DBG("POST请求成功, response body : {}", res->body);
/////////////////////////////////////////////////////////////////////////
// 解析响应体(字符串格式的JSON字符串)为 Json::Value对象
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
Json::Value resp;
std::string error;
bool parse_ret = srd->parse(res->body.c_str(),res->body.c_str() + res->body.size(), &resp, &error);
if(!parse_ret) {
ERR("Json解析失败, error : {}", error);
return "";
}
// 从解析后的Json::Value对象中提取响应内容
if(resp.isMember("choices") && resp["choices"].isArray() && !resp["choices"].empty())
{
Json::Value choice = resp["choices"][0];
if(choice.isMember("message") && choice["message"].isObject()) {
Json::Value message = choice["message"];
if(message.isMember("content") && message["content"].isString())
{
DBG("message content : {}", message["content"].asString());
return message["content"].asString();
}
}
}
// 解析失败,返回错误信息
ERR("Invalid response format from DeepSeek API");
return "";
}
.......
} // namespace ai_chat_sdk
3.4 测试代码:测试全量返回
- test.cpp
#include <gtest/gtest.h>
#include "../sdk/include/util/mylog.h"
#include "../sdk/include/DeepSeekProvider.h"
TEST(DeepSeekProviderTest, sendMessageDeepSeek)
{
// 创建DeepSeekProvider实例
auto deepseekProvider = std::make_shared<ai_chat_sdk::DeepSeekProvider>();
ASSERT_TRUE(deepseekProvider != nullptr);
// 初始化模型配置
std::map<std::string, std::string> model_config;
// api_key比较私密, 我将api_key设置为环境变量中的deepseek_apikey的值
model_config["api_key"] = std::getenv("deepseek_apikey");
model_config["base_url"] = "https://api.deepseek.com";
deepseekProvider->init_Model(model_config);
ASSERT_TRUE(deepseekProvider->isAvailable());
// 测试发送消息(非流式响应)
std::vector<ai_chat_sdk::Message> messages;
messages.push_back({"user", "你好"});
std::map<std::string, std::string> param_map = {
{"temperature", "0.7"},
{"max_tokens", "2048"}
};
std::string response = deepseekProvider->sendMessage(messages, param_map);
ASSERT_FALSE(response.empty());
INFO("fulldata : {}", response);
}
int main(int argc, char *argv[])
{
// 初始化gtest库
testing::InitGoogleTest(&argc, argv);
// 初始化⽇志库
MyLog::Logger::instance().init_logger("sync_logger", spdlog::level::level_enum::debug, "stdout");
// 运⾏所有测试
return RUN_ALL_TESTS();
}
- CMakeLists.txt
注意:httplib库默认使用http协议,而deepseek的官网链接使用https协议,因此在编译时需要链接 OpenSSL开发库以支持SSL/TLS。否则在使用httplib创建http客户端进行通信时会报错。
ubuntu下安装OpenSSL开发库命令: sudo apt-get install libssl-dev
# CMake 最低版本要求
cmake_minimum_required(VERSION 3.10)
# 项目名称
project(test_DeepSeekProvider)
# 设置C++标准
set(CMAKE_CXX_STANDARD 17)
# 设置构建类型为Debug
set(CMAKE_BUILD_TYPE Debug)
# 添加可执行文件
add_executable(test_provider
test.cpp
../sdk/src/util/mylog.cpp
../sdk/src/DeepSeekProvider.cpp
)
# 查找OpenSSL包
find_package(OpenSSL REQUIRED)
# 包含OpenSSL头文件路径
include_directories(${OPENSSL_INCLUDE_DIR})
# 添加编译定义
target_compile_definitions(test_provider PUBLIC
CPPHTTPLIB_OPENSSL_SUPPORT
)
# 链接库
target_link_libraries(test_provider PRIVATE fmt gtest spdlog jsoncpp OpenSSL::SSL OpenSSL::Crypto)
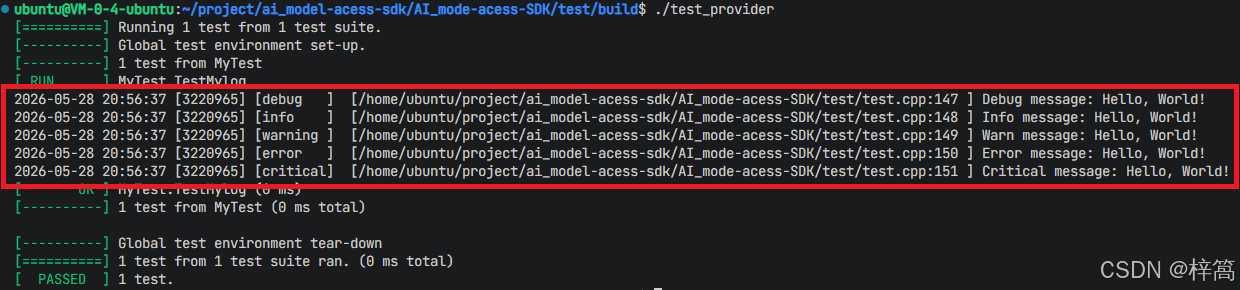
- 代码运行结果:
3.5 流式响应需要的协议
3.5.1 标准的HTTP协议(全量返回使用)
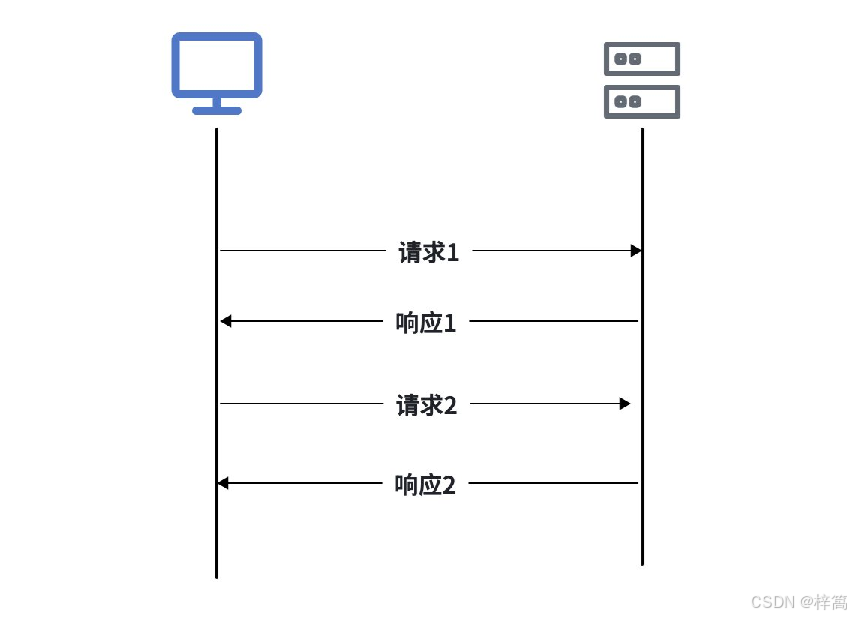
HTTP协议是严格的 “请求-响应” 模型,永远是客户端发起请求,服务器才能响应,服务器就像个 “哑巴”,它知道更多内容,但是它无法主动告诉你。这种一问一答的模式对于大部分网页浏览器、数据提交等场景已经足够了。
3.5.2 SSE协议(流式返回使用)
SSE是Server Send Event的缩写,即服务器发送事件,是建立在HTTP协议之上的开发标准,允许服务器主动向客户端(如浏览器)推送实时数据。

SSE通过单一的持久连接实现数据的实时传输,客户端无需频繁发起请求。
SSE协议特点
- 单向通信: 服务器可以主动推送数据到客户端,但客户端无法直接通过SSE向服务器发送数据
- 基于HTTP协议: SSE使用标准的HTTP协议,无需额外的协议或端口配置,兼容性好易于实现
- 轻量级: SSE的实现更简单,代码量少,适合简单的实时数据推送场景
- 自动重连: 如果连接断开,浏览器会自动尝试重新连接,无需开发者手动处理重连逻辑
- 支持事件类型: 服务器可以发送不同类型事件,客户端可以根据事件类型执行不同的操作
- 支持消息ID: 每条消息可以包含一个唯一的ID,用于断线重连后恢复消息流
数据格式(每个事件可以包含以下字段):
- data:消息内容(必须)
- event:事件类型(可选)
- id:消息ID(可选)
- retry:重连时间(可选,单位:毫秒)
data: Hello, world!
event: message
id: 123
retry: 10000
data: Hello, hello
event: message
id: 1245
retry: 10000
......
data: [DONE]
每条消息以两个换行符 (\n\n) 结束,消息流传输完毕后会有专门的结束标记,不同实现结束标记不同,比如 data: [DONE]。
当我们向 DeepSeek、ChatGPT、Gemini等大模型提问时,这些大模型并不是⼀次性将完整回答丢给用户,而是服务器边思考,边主动将思考结果吐(推送)给用户的,就和打字一样一点点输出,用户不需要长时间的等待,能及时看到服务器响应的结果,体验比较好,这种方式称为流式响应。SSE推出后实际不温不火,大模型爆火后,正式大模型场景的需要,SSE协议就爆火了。
3.5.3 WebSocket协议(后续补充)
SSE协议有⼀个缺陷就是单向传输,即数据只能由服务器给客户端推送,在新闻推送、股票行情、体育比分等场景是比较合适的,因为这些场景客户端无需给服务器发数据。
但有些场景 SSE就束手无策了。比如:你在宿舍的微信群里发了一个消息 “谁去食堂帮我捎个饭”,服务器收到后需要 “谁去食堂帮我捎个个饭” 这条消息主动推送给群中其他人,其他人收到消息后,就需要发消息回应你 而不是不闻不问。此处由舍友回复"滚犊子",那服务器收到后又要推送给其他人…
该场景中,不仅需要服务器主动给客户端推送消息,也需要客户端给服务器发送消息。这种场景下 WebSocket协议就派上用场了。
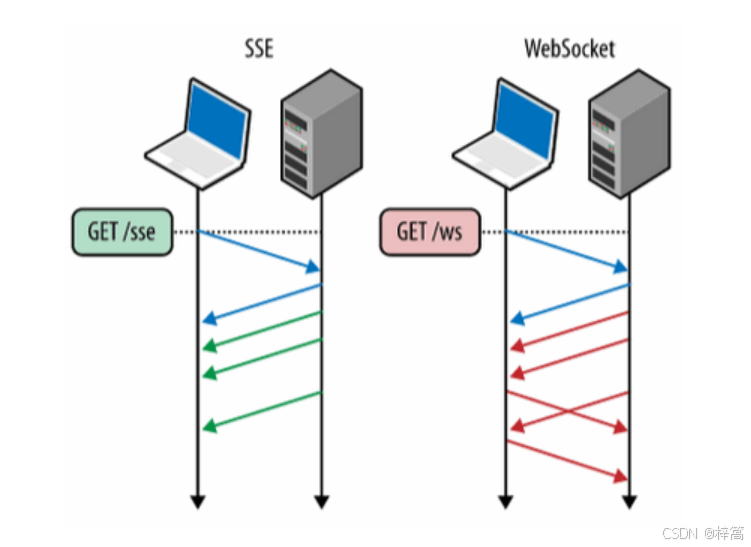
3.5.4 对比SSE协议 和 WebSocket协议(流式返回选择SSE的理由)
| 特性 | SSE | WebSocket |
|---|---|---|
| 通信方向 | 单向通道:服务器 → 客户端 | 双向通道:服务器 <=> 客户端 |
| 设计目的 | 服务器主动推送数据(如新闻、状态更新) | 双向实时对话(如聊天、游戏操作同步) |
| 协议 | HTTP | 独立的TCP协议,在HTTP握手后升级协议(ws/wss) |
| 数据格式 | 纯文本 | 二进制 或 文本 |
| 自动重连 | 内置 | 需要手动实现 |
| 使用场景 | 实时通知、日志流、LLM响应等单向场景 | 实时聊天、多人在线游戏、实时交易等双向交互场景 |
- 为什么DeepSeek的助手消息使用 SSE,不使用 websocket?
答:大模型的回复是服务器向客户端推送数据的单项数据流,在此期间客户端不需要给大模型服务器发送消息,而SSE刚好是服务器主动单项给客户端推送数据,并且实现简单高效,因此大模型回复通常都使用 SSE协议。
3.6 发送消息-流式返回
Base URL: https://api.deepseek.com
请求URL: POST /chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | deepseek-v4-flash |
| temperature | number | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| max_tokens | integer | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| stream | boolean | true(流式返回,设置为true) |
请求体示例(json格式):
{
"messages": [
{
"content": "你是谁",
"role": "user"
}
],
"model": "deepseek-v4-flash",
"temperature ": 0.8,
"max_tokens ": 2048,
"stream": true
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
data: {
"id": "2765a174-d885-4d84-a226-b91c9b334e7e",
"object": "chat.completion.chunk",
"created": 1780486795,
"model": "deepseek-v4-flash",
"system_fingerprint": "fp_8b330d02d0_prod0820_fp8_kvcache_20260402",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": null,
"reasoning_content": ""
},
"logprobs": null,
"finish_reason": null
}
]
}
data: {
"id": "2765a174-d885-4d84-a226-b91c9b334e7e",
"object": "chat.completion.chunk",
"created": 1780486795,
"model": "deepseek-v4-flash",
"system_fingerprint": "fp_8b330d02d0_prod0820_fp8_kvcache_20260402",
"choices": [
{
"index": 0,
"delta": {
"content": null,
"reasoning_content": "嗯"
},
"logprobs": null,
"finish_reason": null
}
]
}
data: {
"id": "2765a174-d885-4d84-a226-b91c9b334e7e",
"object": "chat.completion.chunk",
"created": 1780486795,
"model": "deepseek-v4-flash",
"system_fingerprint": "fp_8b330d02d0_prod0820_fp8_kvcache_20260402",
"choices": [
{
"index": 0,
"delta": {
"content": null,
"reasoning_content": ","
},
"logprobs": null,
"finish_reason": null
}
]
}
......
data: {
"id": "2765a174-d885-4d84-a226-b91c9b334e7e",
"object": "chat.completion.chunk",
"created": 1780486795,
"model": "deepseek-v4-flash",
"system_fingerprint": "fp_8b330d02d0_prod0820_fp8_kvcache_20260402",
"choices": [
{
"index": 0,
"delta": {
"content": "✨",
"reasoning_content": null
},
"logprobs": null,
"finish_reason": null
}
]
}
data: {
"id": "2765a174-d885-4d84-a226-b91c9b334e7e",
"object": "chat.completion.chunk",
"created": 1780486795,
"model": "deepseek-v4-flash",
"system_fingerprint": "fp_8b330d02d0_prod0820_fp8_kvcache_20260402",
"choices": [
{
"index": 0,
"delta": {
"content": "",
"reasoning_content": null
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 245,
"total_tokens": 250,
"prompt_tokens_details": {
"cached_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 104
},
"prompt_cache_hit_tokens": 0,
"prompt_cache_miss_tokens": 5
}
}
data: [DONE]
- DeepSeekProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class DeepSeekProvider : public LLMProvider {
public:
......
// 发送消息给模型-流式返回
std::string sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback) override;
......
};
} // namespace ai_chat_sdk
- DeepSeekProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 实现流式响应
std::string DeepSeekProvider::sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建请求体
Json::Value request_body;
request_body["model"] = getModelName();
request_body["messages"] = messages_array;
request_body["stream"] = true; // 开启流式响应
request_body["temperature"] = temperature;
request_body["max_tokens"] = max_tokens;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
//////////////////////////////////////// 与非流式响应有区别的内容 ////////////////////////////////////////
// 创建HTTP Client
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(300, 0); // 流式响应需要更⻓的时间
// 设置请求头
httplib::Headers headers = {
{"Authorization", "Bearer " + _api_key},
{"Content-Type", "application/json"}
};
// 流式处理变量
std::string buffer; // 接收流式响应的数据块
bool gotError = false; // 响应是否成功(成功false,失败true)
std::string errorMsg; // 错误描述符
int statusCode = 0; // 状态码
bool streamFinish = false; // 标记流式返回数据是否结束
std::string fullResponse; // 累积完整的响应
/////////////////////////////// 构建HTTP请求(设置处理函数) ///////////////////////////////
// 创建请求对象
httplib::Request req;
req.method = "POST";
req.path = "/chat/completions";
req.headers = headers;
req.body = request_body_str;
// HTTP协议响应的格式:
// ⼀个状态⾏:HTTP/1.1 200 OK
// ⼀组响应头:Content-Type,Content-Length
// 空⾏:\r\n\r\n
// 响应体
// 普通的HTTP响应是 ⼀头⼀体
// 流式响应:只有⼀个响应头,但响应体被拆分成多个块(chunks)陆续发送,即⼀头多块
// 响应头处理(检查状态码): 状态码不是200时,记录错误信息
req.response_handler = [&](const httplib::Response& res) {
int statusCode = res.status;
if(200 != statusCode){
gotError = true;
errorMsg = "HTTP Error:" + std::to_string(statusCode);
return false; // 终⽌请求(不再调用 content_receiver)
}
return true; // 继续接收数据(继续调用 content_receiver 接收响应体chunk)
};
// 响应体处理(流式回调)
// data:指向当前接收到的数据块的指针
// len:当前数据块的长度
// offset:当前数据块在响应体中的偏移量
// totalLength:响应体的总长度
// 流式响应 主要关注前两个参数 data 和 len 就足够了。因为在流式响应的场景下,总长度通常未知,需要持续接收直到 [DONE] 标记出现
req.content_receiver = [&](const char* data, size_t len, uint64_t offset, uint64_t totalLength)
{
// 如果http请求头出错,就不需要再继续接收了
if(gotError)
{
return false;
}
// 追加新数据到缓冲区
buffer.append(data, len);
DBG("buffer: {}", buffer);
// 处理所有完整的事件,事件和事件之间以\n\n分隔
size_t pos = 0;
while((pos = buffer.find("\n\n")) != std::string::npos)
{
std::string event = buffer.substr(0, pos);
buffer.erase(0, pos+2); // 移除已经处理的事件
// 处理空⾏和注释, 以:开头的是注释⾏
if(event.empty() || event[0] == ':')
{
continue;
}
// 检查事件类型: data: JSON字符串
if(event.compare(0, 6, "data: ") == 0)
{
std::string jsonStr = event.substr(6);
////// 关键代码:处理结束标记(判断流式响应是否结束) ///////
if(jsonStr == "[DONE]")
{
callback("", true); // 返回true, 代表流式响应结束
streamFinish = true; // 标记流式响应结束
return true;
}
// 反序列化:将JSON字符串 转换为 Json::Value对象
Json::Value chunk;
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
std::string errs;
bool read_ret = srd->parse(jsonStr.c_str(), jsonStr.c_str() + jsonStr.size(), &chunk, &errs);
if(!read_ret)
{
ERR("Json反序列化失败: {}", errs);
return false;
}
// 提取Json::Value对象中的 content字段
if(chunk.isMember("choices") && chunk["choices"].isArray() &&
!chunk["choices"].empty() && chunk["choices"][0].isMember("delta") &&
chunk["choices"][0]["delta"].isMember("content"))
{
std::string content = chunk["choices"][0]["delta"]["content"].asString();
// 累积到完整响应
fullResponse += content;
callback(content, false); // 调用回调函数处理增量内容, false代表流式响应未结束
}
}
}
return true; // 继续接收数据
};
///////////////////////////// HTTP请求构建结束 //////////////////////////////
// 发送HTTP请求并处理结果
auto res = client.send(req);
// send的返回值类型是Result类型,Result类型内部实现了operator bool(), 允许将Result类型的实例隐式转换为bool类型
if(!res)
{
// 请求连接失败,⽹络问题、DNS解析失败等
ERR("HTTP Post error: {}", httplib::to_string(res.error()));
return "";
}
// 确保流正常结束
if(!streamFinish){
WARN("Stream ended without [DONE] marker");
callback("", true);
}
return fullResponse;
}
.......
} // namespace ai_chat_sdk
3.7 测试代码:测试流式返回
- test.cpp
#include <gtest/gtest.h>
#include "../sdk/include/util/mylog.h"
#include "../sdk/include/DeepSeekProvider.h"
TEST(DeepSeekProviderTest, sendMessageDeepSeek)
{
// 创建DeepSeekProvider实例
auto deepseekProvider = std::make_shared<ai_chat_sdk::DeepSeekProvider>();
ASSERT_TRUE(deepseekProvider != nullptr);
// 初始化模型配置
std::map<std::string, std::string> model_config;
// api_key比较私密, 我将api_key设置为环境变量中的deepseek_apikey的值
model_config["api_key"] = std::getenv("deepseek_apikey");
model_config["base_url"] = "https://api.deepseek.com";
deepseekProvider->init_Model(model_config);
ASSERT_TRUE(deepseekProvider->isAvailable());
// 测试发送消息(流式响应)
std::vector<ai_chat_sdk::Message> messages;
messages.push_back({"user", "你好"});
std::map<std::string, std::string> param_map = {
{"temperature", "0.7"},
{"max_tokens", "2048"}
};
auto write_chunk = [&](const std::string& chunk, bool last){
INFO("chunk : {}", chunk);
if(last){
INFO("[DONE]");
}
};
std::string response = deepseekProvider->sendMessageStream(messages, param_map, write_chunk);
ASSERT_FALSE(response.empty());
INFO("fulldata : {}", response);
}
int main(int argc, char *argv[])
{
// 初始化gtest库
testing::InitGoogleTest(&argc, argv);
// 初始化⽇志库
MyLog::Logger::instance().init_logger("sync_logger", spdlog::level::level_enum::debug, "stdout");
// 运⾏所有测试
return RUN_ALL_TESTS();
}
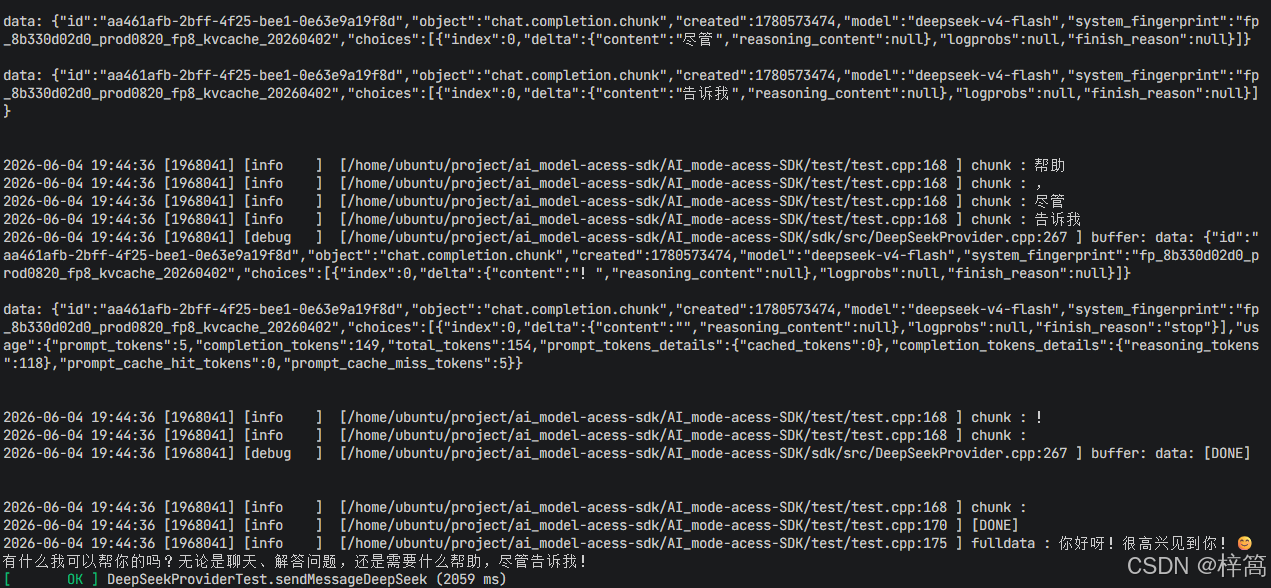
- 代码运行结果:
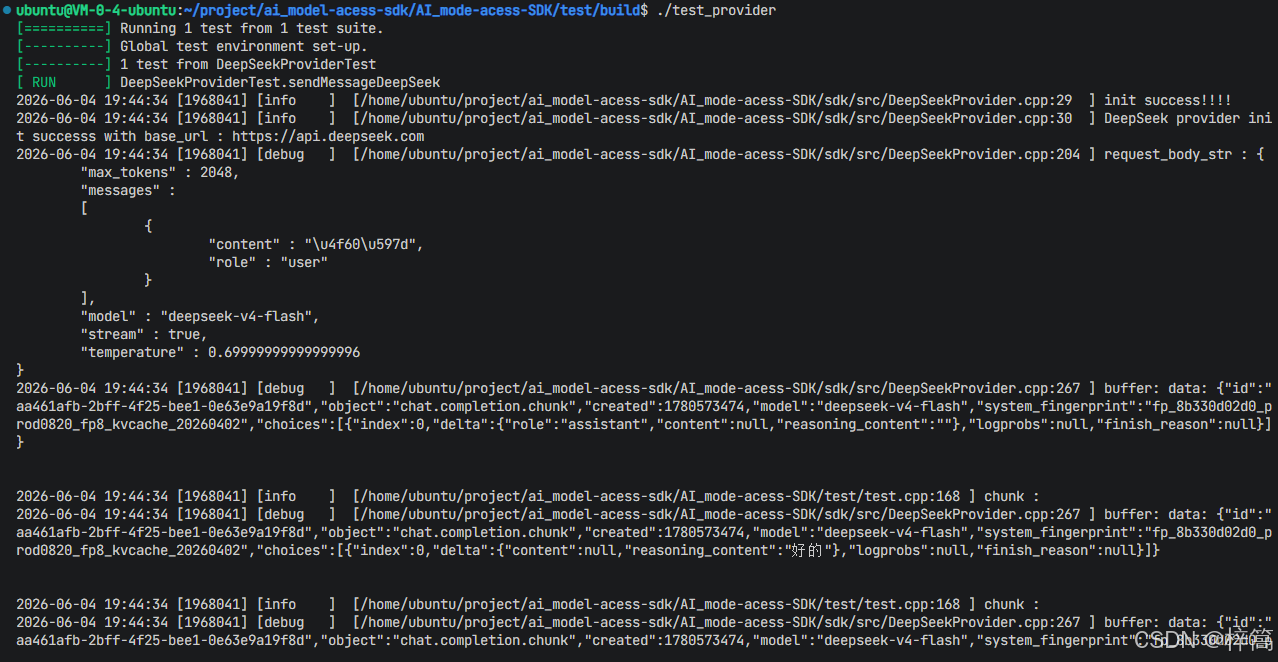
…
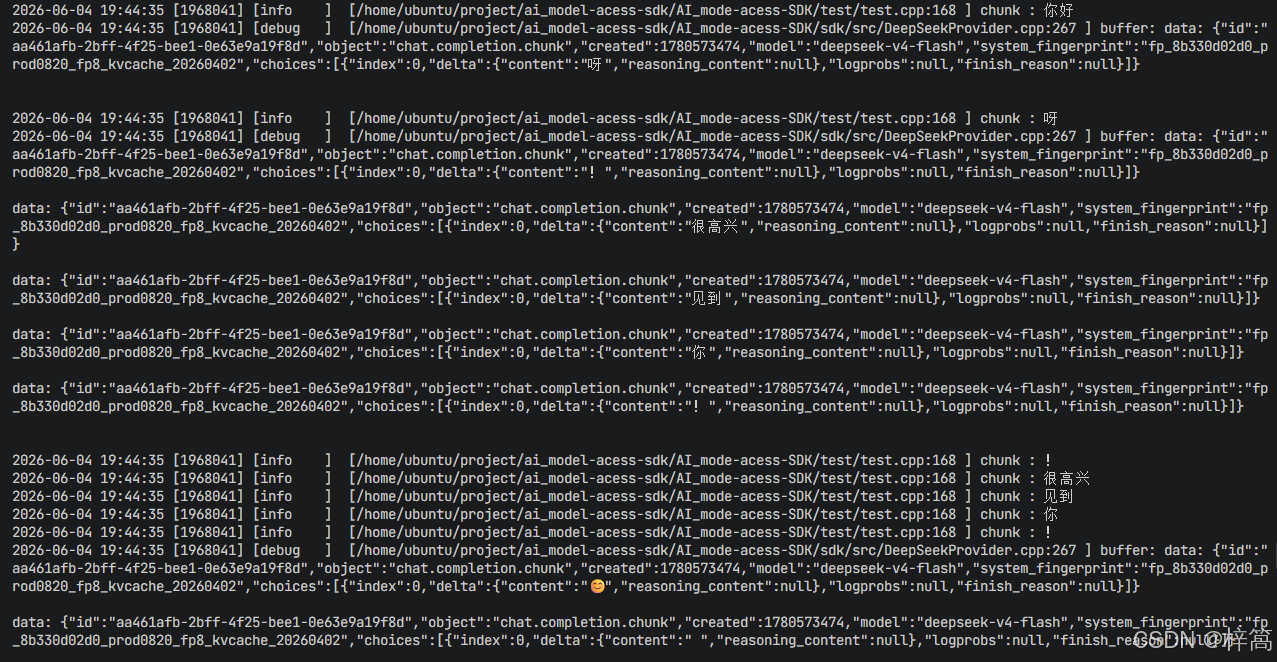
…
4. ChatGPT大模型接入
4.1 ChatGPT提供的API接口
Chat Completion的官方参数文档:https://developers.openai.com/api/reference/resources/chat/subresources/completions/methods/create
Base url: https://api.openai.com
请求URL: POST /v1/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| messages | array | 历史对话,内部为每个对话的object,包含role(developer:指定模型的身份,比如 你是一名资深数学家;user:用户的问题;assistant:模型的回答)和 content两个字段 |
| model | string | 模型名称(“gpt-5.4” / “gpt-5.4-mini” / “gpt-5.4-nano”) |
| temperature | number | 采样温度,介于 0 和 2 之间。更高的值,如 0.8,会使输出更随机,而更低的值,如 0.2,会使其更加集中和确定。 |
| max_tokens | integer | 限制一次请求中模型生成 completion 的最大 token 数 |
| stream | boolean | - 未设置时,默认为 false - 如果设置为 true,将会以 SSE(server-sent events)的形式以流式发送消息增量。 |
4.2 大模型初始化
在使用 Chatgpt前,需要先配置好Chatgpt需要的一些参数信息,比如 api-key、base url、model、temperature、max_tokens等信息,否则无法正常使用 Chatgpt的api。
api-key 和 base url 这两个参数的内容基本是固定的,在模型初始化时设置好,后续进行对话时直接使用设置好的参数即可
- ChatgptProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class ChatgptProvider : public LLMProvider {
public:
// 初始化模型(初始化模型的API Key和base url)
bool init_Model(const std::map<std::string, std::string>& model_config) override;
// 检测模型是否有效
bool isAvailable() override;
// 获取模型名称
std::string getModelName() override;
// 获取模型描述信息
std::string getModelDesc() override;
......
};
} // namespace ai_chat_sdk
- ChatgptProvider.cpp(部分)
#include "../include/ChatgptProvider.h"
#include "../include/util/mylog.h"
#include <jsoncpp/json/json.h>
#include <httplib.h>
#include <sstream>
#include <iostream>
#include <memory>
#include <map>
namespace ai_chat_sdk{
// 初始化模型(初始化模型的API Key和base url)
bool ChatgptProvider::init_Model(const std::map<std::string, std::string>& model_config)
{
auto it = model_config.find("api_key");
if(it == model_config.end()) {
ERR("api_key is not found in model_config");
return false;
}
_api_key = it->second;
it = model_config.find("base_url");
if(it == model_config.end()) {
ERR("base_url is not found in model_config");
return false;
}
_base_url = it->second;
// 设置初始化成功标记
_isAvailable = true;
INFO("init success!!!!");
INFO("DeepSeek provider init successs with base_url : {}", _base_url);
return true;
}
bool ChatgptProvider::isAvailable() {
return _isAvailable;
}
std::string ChatgptProvider::getModelName() {
return "gpt-5.4-mini"; // 模型名称
}
std::string ChatgptProvider::getModelDesc() {
return "一款推理速度快、资源消耗低的轻量级语言模型, 适合快速响应的场景";
}
} // namespace ai_chat_sdk
4.3 发送消息-全量返回
Base url:https://api.openai.com
请求URL: POST /v1/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | gpt-5.4-mini |
| temperature | number | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| max_tokens | integer | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| stream | boolean | false(全量返回,设置为false) |
请求体示例(json格式):
{
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
"model": "gpt-5.4-mini",
"temperature ": 0.8,
"max_tokens ": 2048,
"stream": false
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
{
"id": "chatcmpl-B9MBs8CjcvOU2jLn4n570S5qMJKcT",
"object": "chat.completion",
"created": 1741569952,
"model": "gpt-5.4",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 19,
"completion_tokens": 10,
"total_tokens": 29,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default"
}
- ChatgptProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class ChatgptProvider : public LLMProvider {
public:
......
// 发送消息给模型
std::string sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param) override;
......
};
} // namespace ai_chat_sdk
- ChatgptProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 发送消息(非流式响应)
std::string ChatgptProvider::sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建请求体
Json::Value request_body;
request_body["model"] = getModelName();
request_body["messages"] = messages_array;
request_body["stream"] = false;
request_body["temperature"] = temperature;
request_body["max_tokens"] = max_tokens;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
/////////////////////////////// http相关内容(我还不太了解) ///////////////////////////////
// 创建HTTP客户端
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(60, 0); // 60秒读取超时
// 设置请求头 (Content-Type是请求体的类型,和post最后一个参数重复)
httplib::Headers headers = {
{"Authorization", "Bearer " + _api_key},
/* {"Content-Type", "application/json"} */
};
// 发送POST请求 (最后一个参数是请求体的类型, 这里是"application/json")
httplib::Result res = client.Post("/v1/chat/completions", headers,
request_body_str, "application/json");
// Result类型的 operator->重载 返回的是 Response对象的指针
if(!res || res->status != 200) {
ERR("POST请求失败, status code : {}", res->status);
return "";
}
DBG("POST请求成功, response body : {}", res->body);
////////////////////////////////////////////////////////////////////////////////////////
// 解析响应体(字符串格式的JSON字符串)为 Json::Value对象
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
Json::Value resp;
std::string error;
bool parse_ret = srd->parse(res->body.c_str(),res->body.c_str() + res->body.size(), &resp, &error);
if(!parse_ret) {
ERR("Json解析失败, error : {}", error);
return "";
}
// 从解析后的Json::Value对象中提取响应内容
if(resp.isMember("choices") && resp["choices"].isArray() && !resp["choices"].empty())
{
Json::Value choice = resp["choices"][0];
if(choice.isMember("message") && choice["message"].isObject()) {
Json::Value message = choice["message"];
if(message.isMember("content") && message["content"].isString())
{
DBG("message content : {}", message["content"].asString());
return message["content"].asString();
}
}
}
// 解析失败,返回错误信息
ERR("Invalid response format from ChatGPT API");
return "";
}
.......
} // namespace ai_chat_sdk
4.4 发送消息-流式返回
Base url:https://api.openai.com
请求URL: POST /v1/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | gpt-5.4-mini |
| temperature | number | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| max_tokens | integer | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| stream | boolean | true(设置为true,开启流式返回) |
请求体示例(json格式):
{
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
"model": "gpt-5.4-mini",
"temperature ": 0.8,
"max_tokens ": 2048,
"stream": true
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
DeepSeek流式响应结束时,会发 data: [DONE];但 ChatGPT流式响应结束时通常是不会发 data: [DONE]的!
ChatGPT流式响应结束靠 finish_reason字段判断,finish_reason字段为null,代表流式响应继续,finish_reason字段不为null(被设置为"stop",代表正常结束;被设置为"length",代表达到 max_tokens 限制),代表流式响应结束
data: {
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1694268190,
"model": "gpt-4o-mini",
"system_fingerprint": "fp_44709d6fcb",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"logprobs": null,
"finish_reason": null
}
]
}
data: {
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1694268190,
"model": "gpt-4o-mini",
"system_fingerprint": "fp_44709d6fcb",
"choices": [
{
"index": 0,
"delta": {
"content": "Hello"
},
"logprobs": null,
"finish_reason": null
}
]
}
......
data: {
"id": "chatcmpl-123",
"object": "chat.completion.chunk",
"created": 1694268190,
"model": "gpt-4o-mini",
"system_fingerprint": "fp_44709d6fcb",
"choices": [
{
"index": 0,
"delta": {},
"logprobs": null,
"finish_reason": "stop"
}
]
}
- ChatgptProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class ChatgptProvider : public LLMProvider {
public:
......
// 发送消息给模型-流式返回
std::string sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback) override;
......
};
} // namespace ai_chat_sdk
- ChatgptProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 实现流式响应
std::string ChatgptProvider::sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建请求体
Json::Value request_body;
request_body["model"] = getModelName();
request_body["messages"] = messages_array;
request_body["stream"] = true; // 开启流式响应
request_body["temperature"] = temperature;
request_body["max_tokens"] = max_tokens;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
///////////////////////////// 与非流式响应有区别的内容 //////////////////////////////
// 创建HTTP Client
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(300, 0); // 流式响应需要更⻓的时间
// 设置请求头
httplib::Headers headers = {
{"Authorization", "Bearer " + _api_key},
{"Content-Type", "application/json"},
{"Accept", "text/event-stream"} // 流式响应需要设置Accept头为text/event-stream
};
// 流式处理变量
std::string buffer; // 接收流式响应的数据块
bool gotError = false; // 响应是否成功(成功false,失败true)
std::string errorMsg; // 错误描述符
int statusCode = 0; // 状态码
bool streamFinish = false; // 标记流式返回数据是否结束
std::string fullResponse; // 累积完整的响应
/////////////////////////// 构建HTTP请求(设置处理函数) ///////////////////////////
// 创建请求对象
httplib::Request req;
req.method = "POST";
req.path = "/v1/chat/completions";
req.headers = headers;
req.body = request_body_str;
// HTTP协议响应的格式:
// ⼀个状态⾏:HTTP/1.1 200 OK
// ⼀组响应头:Content-Type,Content-Length
// 空⾏:\r\n\r\n
// 响应体
// 普通的HTTP响应是 ⼀头⼀体
// 流式响应:只有⼀个响应头,但响应体被拆分成多个块(chunks)陆续发送,即⼀头多块
// 响应头处理(检查状态码): 状态码不是200时,记录错误信息
req.response_handler = [&](const httplib::Response& res) {
int statusCode = res.status;
if(200 != statusCode){
gotError = true;
errorMsg = "HTTP Error:" + std::to_string(statusCode);
return false; // 终⽌请求
}
return true; // 继续接收数据
};
// 响应体处理(流式回调)
// data:指向当前接收到的数据块的指针
// len:当前数据块的长度
// offset:当前数据块在响应体中的偏移量
// totalLength:响应体的总长度
// 流式响应 主要关注前两个参数 data 和 len 就足够了。因为在流式响应的场景下,总长度通常未知,需要持续接收直到 [DONE] 标记出现
req.content_receiver = [&](const char* data, size_t len, uint64_t offset, uint64_t totalLength)
{
// 如果http请求头出错,就不需要再继续接收了
if(gotError)
{
return false;
}
// 追加新数据到缓冲区
buffer.append(data, len);
DBG("buffer: {}", buffer);
// 处理所有完整的事件,事件和事件之间以\n\n分隔
size_t pos = 0;
while((pos = buffer.find("\n\n")) != std::string::npos)
{
std::string event = buffer.substr(0, pos);
buffer.erase(0, pos+2); // 移除已经处理的事件
// 处理空⾏和注释, 以:开头的是注释行
if(event.empty() || event[0] == ':')
{
continue;
}
// 检查事件类型: data: JSON字符串
if(event.compare(0, 6, "data: ") == 0)
{
std::string jsonStr = event.substr(6);
// 反序列化:将JSON字符串 转换为 Json::Value对象
Json::Value chunk;
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
std::string errs;
bool read_ret = srd->parse(jsonStr.c_str(), jsonStr.c_str() + jsonStr.size(), &chunk, &errs);
if(!read_ret)
{
ERR("Json反序列化失败: {}", errs);
return false;
}
//// 关键代码:处理结束标记(判断流式响应是否结束) /////
// ChatGPT流式响应结束靠 finish_reason字段判断,finish_reason字段为null,代表流式响应继续,
// finish_reason字段不为null(被设置为"stop",代表正常结束;被设置为"length",代表达到 max_tokens 限制),
// 代表流式响应结束
if(chunk.isMember("choices") && chunk["choices"].isArray() &&
!chunk["choices"].empty() && chunk["choices"][0].isMember("finish_reason") &&
chunk["choices"][0]["finish_reason"].isString() &&
!chunk["choices"][0]["finish_reason"].isNull())
{
callback("", true); // 返回true, 代表流式响应结束
streamFinish = true; // 标记流式响应结束
return true;
}
// 提取Json::Value对象中的 content字段
if(chunk.isMember("choices") && chunk["choices"].isArray() &&
!chunk["choices"].empty() && chunk["choices"][0].isMember("delta") &&
chunk["choices"][0]["delta"].isMember("content"))
{
std::string content = chunk["choices"][0]["delta"]["content"].asString();
// 累积到完整响应
fullResponse += content;
callback(content, false); // 调用回调函数处理增量内容, false代表流式响应未结束
}
}
}
return true; // 继续接收数据
};
////////////////////////////// HTTP请求构建结束 /////////////////////////////
// 发送HTTP请求并处理结果
auto res = client.send(req);
// send的返回值类型是Result类型,Result类型内部实现了operator bool(), 允许将Result类型的实例隐式转换为bool类型
if(!res)
{
// 请求连接失败,⽹络问题、DNS解析失败等
ERR("HTTP Post error: {}", httplib::to_string(res.error()));
return "";
}
// 确保流正常结束
if(!streamFinish){
WARN("Stream ended without stop marker");
callback("", true);
}
return fullResponse;
}
.......
} // namespace ai_chat_sdk
5. Gemini大模型接入
5.1 Gemini提供的API接口
官方文档: https://ai.google.dev/gemini-api/docs?hl=zh-cn
Base URL: https://generativelanguage.googleapis.com
请求URL: POST /v1beta/openai/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| messages | array | 历史对话,内部为每个对话的object,包含role(user:用户的问题;assistant:模型的回答)和 content两个字段 |
| model | string | 模型名称(“gemini-2.5-flash” / “gemini-2.5-pro”) |
| temperature | number | 采样温度,介于 0 和 2 之间。更高的值,如 0.8,会使输出更随机,而更低的值,如 0.2,会使其更加集中和确定。 |
| max_tokens | integer | 限制一次请求中模型生成 completion 的最大 token 数 |
| stream | boolean | - 未设置时,默认为 false - 如果设置为 true,将会以 SSE(server-sent events)的形式以流式发送消息增量。消息流以 data: [DONE] 结尾。 |
5.2 大模型初始化
在使用 Gemini前,需要先配置好 Gemini需要的一些参数信息,比如 api-key、base url、model、temperature、max_tokens等信息,否则无法正常使用 Gemini的api。
api-key 和 base url 这两个参数的内容基本是固定的,在模型初始化时设置好,后续进行对话时直接使用设置好的参数即可
- GeminiProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class GeminiProvider : public LLMProvider {
public:
// 初始化模型(初始化模型的API Key和base url)
bool init_Model(const std::map<std::string, std::string>& model_config) override;
// 检测模型是否有效
bool isAvailable() override;
// 获取模型名称
std::string getModelName() override;
// 获取模型描述信息
std::string getModelDesc() override;
......
};
} // namespace ai_chat_sdk
- GeminiProvider.cpp(部分)
#include "../include/GeminiProvider.h"
#include "../include/util/mylog.h"
#include <jsoncpp/json/json.h>
#include <httplib.h>
#include <sstream>
#include <iostream>
#include <memory>
#include <map>
namespace ai_chat_sdk{
// 初始化模型(初始化模型的API Key和base url)
bool GeminiProvider::init_Model(const std::map<std::string, std::string>& model_config)
{
auto it = model_config.find("api_key");
if(it == model_config.end()) {
ERR("api_key is not found in model_config");
return false;
}
_api_key = it->second;
it = model_config.find("base_url");
if(it == model_config.end()) {
ERR("base_url is not found in model_config");
return false;
}
_base_url = it->second;
// 设置初始化成功标记
_isAvailable = true;
INFO("init success!!!!");
INFO("DeepSeek provider init successs with base_url : {}", _base_url);
return true;
}
bool GeminiProvider::isAvailable() {
return _isAvailable;
}
std::string GeminiProvider::getModelName() {
return "gemini-2.5-flash";
}
std::string GeminiProvider::getModelDesc() {
return "Gemini-2.5-Flash 是谷歌面向高并发、实时性场景的轻量化多模态模型, 平衡性能与成本, 适用于开发者构建高效AI应用";
}
} // namespace ai_chat_sdk
5.3 发送消息-全量返回
Base URL: https://generativelanguage.googleapis.com
请求URL: POST /v1beta/openai/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | gemini-2.5-flash |
| temperature | number | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| max_tokens | integer | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| stream | boolean | false(全量返回,设置为false) |
请求体示例(json格式):
{
"messages": [
{
"content": "你是谁",
"role": "user"
}
],
"model": "gemini-2.5-flash",
"temperature ": 0.8,
"max_tokens ": 2048,
"stream": false
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "我是⼀个⼤型语言模型,由 Google 训练。\n",
"role": "assistant"
}
}
],
"created": 1754897666,
"id": "Ap2ZaPGBEMS1nvgPu6DPwAg",
"model": "gemini-2.5-flash",
"object": "chat.completion",
"usage": {
"completion_tokens": 12,
"prompt_tokens": 3,
"total_tokens": 15
}
}
- GeminiProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class GeminiProvider : public LLMProvider {
public:
......
// 发送消息给模型
std::string sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param) override;
......
};
} // namespace ai_chat_sdk
- GeminiProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 发送消息(非流式响应)
std::string GeminiProvider::sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建请求体
Json::Value request_body;
request_body["model"] = getModelName();
request_body["messages"] = messages_array;
request_body["stream"] = false;
request_body["temperature"] = temperature;
request_body["max_tokens"] = max_tokens;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
/////////////////////////////// http相关内容(我还不太了解) ///////////////////////////////
// 创建HTTP客户端
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(60, 0); // 60秒读取超时
// 设置请求头 (Content-Type是请求体的类型,和post最后一个参数重复)
httplib::Headers headers = {
{"Authorization", "Bearer " + _api_key},
/*{"Content-Type", "application/json"}*/
};
// 发送POST请求 (最后一个参数是请求体的类型, 这里是"application/json")
httplib::Result res = client.Post("/v1beta/openai/chat/completions", headers,
request_body_str, "application/json");
// Result类型的 operator->重载 返回的是 Response对象的指针
if(!res || res->status != 200) {
ERR("POST请求失败, status code : {}", res->status);
return "";
}
DBG("POST请求成功, response body : {}", res->body);
////////////////////////////////////////////////////////////////////////////////////////
// 解析响应体(字符串格式的JSON字符串)为 Json::Value对象
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
Json::Value resp;
std::string error;
bool parse_ret = srd->parse(res->body.c_str(),res->body.c_str() + res->body.size(), &resp, &error);
if(!parse_ret) {
ERR("Json解析失败, error : {}", error);
return "";
}
// 从解析后的Json::Value对象中提取响应内容
if(resp.isMember("choices") && resp["choices"].isArray() && !resp["choices"].empty())
{
Json::Value choice = resp["choices"][0];
if(choice.isMember("message") && choice["message"].isObject()) {
Json::Value message = choice["message"];
if(message.isMember("content") && message["content"].isString())
{
DBG("message content : {}", message["content"].asString());
return message["content"].asString();
}
}
}
// 解析失败,返回错误信息
ERR("Invalid response format from Gemini API");
return "";
}
.......
} // namespace ai_chat_sdk
5.4 发送消息-流式返回
Base URL: https://generativelanguage.googleapis.com
请求URL: POST /v1beta/openai/chat/completions
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | gemini-2.5-flash |
| temperature | number | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| max_tokens | integer | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
| stream | boolean | true(设置为true,开启流式响应) |
请求体示例(json格式):
{
"messages": [
{
"content": "你是谁",
"role": "user"
}
],
"model": "gemini-2.5-flash",
"temperature ": 0.8,
"max_tokens ": 2048,
"stream": true
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
data: {
"choices": [
{
"delta": {
"content": " 通常",
"role": "assistant"
},
"finish_reason": null,
"index": 0
}
],
"created": 1756720923,
"id": "Gm-1aKjSM-ag7dcP77rtoAs",
"model": "gemini-2.5-flash",
"object": "chat.completion.chunk",
}
......
data: {
"choices": [
{
"delta": {
"content": "你在研究股票市场吗?\n",
"role": "assistant"
},
"finish_reason": "stop",
"index": 0
}
],
"id": "Gm-1aKjSM-ag7dcP77rtoAs",
"model": "gemini-2.5-flash",
"object": "chat.completion.chunk",
}
data: [DONE]
- GeminiProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class GeminiProvider : public LLMProvider {
public:
......
// 发送消息给模型-流式返回
std::string sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback) override;
......
};
} // namespace ai_chat_sdk
- GeminiProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 实现流式响应
std::string GeminiProvider::sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建请求体
Json::Value request_body;
request_body["model"] = getModelName();
request_body["messages"] = messages_array;
request_body["stream"] = true; // 开启流式响应
request_body["temperature"] = temperature;
request_body["max_tokens"] = max_tokens;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
///////////////////////////// 与非流式响应有区别的内容 ///////////////////////////////
// 创建HTTP Client
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(300, 0); // 流式响应需要更⻓的时间
// 设置请求头
httplib::Headers headers = {
{"Authorization", "Bearer " + _api_key},
{"Content-Type", "application/json"},
{"Accept", "text/event-stream"} // 流式响应需要设置Accept头为text/event-stream
};
// 流式处理变量
std::string buffer; // 接收流式响应的数据块
bool gotError = false; // 响应是否成功(成功false,失败true)
std::string errorMsg; // 错误描述符
int statusCode = 0; // 状态码
bool streamFinish = false; // 标记流式返回数据是否结束
std::string fullResponse; // 累积完整的响应
///////////////////////////// 构建HTTP请求(设置处理函数) //////////////////////////////
// 创建请求对象
httplib::Request req;
req.method = "POST";
req.path = "/v1beta/openai/chat/completions";
req.headers = headers;
req.body = request_body_str;
// HTTP协议响应的格式:
// ⼀个状态⾏:HTTP/1.1 200 OK
// ⼀组响应头:Content-Type,Content-Length
// 空⾏:\r\n\r\n
// 响应体
// 普通的HTTP响应是 ⼀头⼀体
// 流式响应:只有⼀个响应头,但响应体被拆分成多个块(chunks)陆续发送,即⼀头多块
// 响应头处理(检查状态码): 状态码不是200时,记录错误信息
req.response_handler = [&](const httplib::Response& res) {
int statusCode = res.status;
if(200 != statusCode){
gotError = true;
errorMsg = "HTTP Error:" + std::to_string(statusCode);
return false; // 终⽌请求
}
return true; // 继续接收数据
};
// 响应体处理(流式回调)
// data:指向当前接收到的数据块的指针
// len:当前数据块的长度
// offset:当前数据块在响应体中的偏移量
// totalLength:响应体的总长度
// 流式响应 主要关注前两个参数 data 和 len 就足够了。因为在流式响应的场景下,总长度通常未知,需要持续接收直到 [DONE] 标记出现
req.content_receiver = [&](const char* data, size_t len, uint64_t offset, uint64_t totalLength)
{
// 如果http请求头出错,就不需要再继续接收了
if(gotError)
{
return false;
}
// 追加新数据到缓冲区
buffer.append(data, len);
DBG("buffer: {}", buffer);
// 处理所有完整的事件,事件和事件之间以\n\n分隔
size_t pos = 0;
while((pos = buffer.find("\n\n")) != std::string::npos)
{
std::string event = buffer.substr(0, pos);
buffer.erase(0, pos+2); // 移除已经处理的事件
// 处理空⾏和注释, 以:开头的是注释⾏
if(event.empty() || event[0] == ':')
{
continue;
}
// 检查事件类型: data: JSON字符串
if(event.compare(0, 6, "data: ") == 0)
{
std::string jsonStr = event.substr(6);
////// 关键代码:处理结束标记(判断流式响应是否结束) ///////
if(jsonStr == "[DONE]")
{
callback("", true); // 返回true, 代表流式响应结束
streamFinish = true; // 标记流式响应结束
return true;
}
// 反序列化:将JSON字符串 转换为 Json::Value对象
Json::Value chunk;
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
std::string errs;
bool read_ret = srd->parse(jsonStr.c_str(), jsonStr.c_str() + jsonStr.size(), &chunk, &errs);
if(!read_ret)
{
ERR("Json反序列化失败: {}", errs);
return false;
}
// 提取Json::Value对象中的 content字段
if(chunk.isMember("choices") && chunk["choices"].isArray() &&
!chunk["choices"].empty() && chunk["choices"][0].isMember("delta") &&
chunk["choices"][0]["delta"].isMember("content"))
{
std::string content = chunk["choices"][0]["delta"]["content"].asString();
// 累积到完整响应
fullResponse += content;
callback(content, false); // 调用回调函数处理增量内容, false代表流式响应未结束
}
}
}
return true; // 继续接收数据
};
///////////////////////////// HTTP请求构建结束 /////////////////////////////
// 发送HTTP请求并处理结果
auto res = client.send(req);
// send的返回值类型是Result类型,Result类型内部实现了operator bool(), 允许将Result类型的实例隐式转换为bool类型
if(!res)
{
// 请求连接失败,网络问题、DNS解析失败等
ERR("HTTP Post error: {}", httplib::to_string(res.error()));
return "";
}
// 确保流正常结束
if(!streamFinish){
WARN("Stream ended without [DONE] marker");
callback("", true);
}
return fullResponse;
}
} // namespace ai_chat_sdk
6. Ollama本地接入Deepseek
6.1 为什么需要本地接入大模型
各大模型厂商已经提供了网页版的大模型使用服务,比如 DeepSeek、ChatGPT等,用户直接在网页上提问,就能得到需要的答案,为什么还要本地接入大模型呢?
(1) 使用云端大模型的优点:
- 效果强: 云端算力足、模型大,输出质量通过高于本地模型
- 即开即用: 无需下载和配置,注册后即可使用
- 自动升级: 官方会不断更新和优化模型
- 插件生态: ChatGPT plus、Gemini Advanced等往往自带额外功能
(2) 使用云端大模型的缺陷:
- 隐私风险: 输入的数据会传送到云端,虽然大厂承诺,但仍有顾虑。许多行业(如医疗、金融、法律、政府)的数据高度敏感,法律禁止将数据上传到第三方。而且企业内部的战略文档、代码库、设计图等核心资产,如果通过API发送给第三方,存在泄露的风险
- 费用问题: ⼤规模调用API需要付费,费用可能很高。虽然官网按token收费看起来单价不高,但对于高频使用的企业或个人开发者来说,长期积累的成本非常巨大
- 网络依赖: 需要网络,有时访问受限,延迟高。在无网络请求下无法使用,比如保密单位、偏远地区等,而且网络高峰期可能还会遇到无法响应情况
- 可控性差: 无法选择模型版本的内部细节,比如调整参数、控制模型输出格式、集成自定义函数等
(3) 本地部署大模型优点
- 隐私保护: 数据完全在本地处理,不会上传云端
- 零调用费用: 模型下载后随便用,不会产生API调用费用
- 离线可用: 没有网络也能用,非常适合边缘场景
- 灵活可控: 可以随时切换模型,甚至加载自己的训练模型
(4) 本地部署大模型的缺陷
- 硬件要求高: 对显卡、内容要求比较高
- 效果有限: 在低成本下效果有限
- 初始成本高: 模型下载很大,运行时占用资源多
因此对于普通用户和非敏感任务,直接使用官网的云端服务是最简单、最经济的选择。 但对于企业、有隐私或特殊需求的用户,就需要本地部署大模型。
(5)本地接入大模型步骤:

6.2 Ollama
6.2.1 Ollama介绍
Linux下安装Ollama的命令: curl -fsSL https://ollama.com/install.sh | sh
正常情况下,下载速度极慢,因为是国外软件。可通过网络代理 加快下载速度
Ollama官方主页: https://ollama.com/
Ollama官方仓库: https://github.com/ollama/ollama
Get up and running with large language models.
“快速启动并运行大语言模型”,官方的宣传语简洁地概括了 Ollama的核心功能 和 价值主张。
Ollama 是一个开源的大型语言模型服务工具,旨在帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以通过一条命令轻松启动 和 运行开源的大型语言模型。 它提供了一个简洁易用的命令行界面 和 服务器,专为构建大型语言模型应用而设计。用户可以轻松下载、运行 和 管理各种开源 LLM。与传统 LLM 需要复杂配置 和 强大硬件不同,Ollama 能够让用户在消费级的 PC 上体验 LLM 的强大功能。
Ollama 会自动监测本地计算资源,如有 GPU 的条件,会优先使用 GPU 的资源,同时模型的推理速度也更快。如果没有 GPU 条件,直接使用 CPU 资源。
Ollama特点:
• 开源免费: Ollama 及其支持的模型完全开源且免费,用户可以随时访问 和 使用这些资源,而无需支付任何费用。
• 简单易用: Ollama 无需复杂的配置 和 安装过程,只需几条简单的命令即可启动 和 运行,为用户节省了大量时间 和 精力。
• 支持多平台: Ollama 提供了多种安装方式,支持 Mac、Linux 和 Windows 平台,并提供 Docker镜像,满足不同用户的需求。
• 模型丰富: Ollama 支持包括 DeepSeek-R1、 Llama3.3、Gemma2、Qwen2 在内的众多热门开源 LLM,用户可以轻松一键下载 和 切换模型,享受丰富的选择。
• 功能齐全: Ollama 将模型权重、配置和数据捆绑成一个包,定义为 Modelfile,使得模型管理更加简便 和 高效。
• 支持工具调用: Ollama 支持使用 Llama 3.1 等模型进行工具调用。这使模型能够使用它所知道的工具来响应给定的提示,从而使模型能够执行更复杂的任务。
• 资源占用低: Ollama 优化了设置和配置细节,包括 GPU 使用情况,从而提高了模型运行的效率,确保在资源有限的环境下也能顺畅运行。
• 隐私保护: Ollama 所有数据处理都在本地机器上完成,可以保护用户的隐私。
• 社区活跃: Ollama 拥有一个庞大且活跃的社区,用户可以轻松获取帮助、分享经验,并积极参与到模型的开发和改进中,共同推动项目的发展。
6.2.2 Ollama常用指令
| 命令 | 描述 |
|---|---|
| ollama serve | 启动Ollama |
| ollama show + 模型名 | 显示模型信息 |
| ollama run + 模型名 | 运行模型 |
| ollama stop + 模型名 | 停止正在运行的模型 |
| ollama pull | 从ollama官方维护的模型库中拉去模型 ollama官方维护的模型库 |
| ollama list | 列出所有可用模型 |
| ollama ps | 列出正在运行模型 |
| ollama rm + 模型名 | 删除模型 |
| ollama help | 显示任意命令的帮助信息 |
| 标志 | 描述 |
|---|---|
| -h 、–help | 显示Ollama的帮助信息 |
| -v、–version | 显示版本信息 |
注意: ollama serve 启动的是一个前台进程,终端关闭进程也就关闭了。在生产环境中,推荐使用 systemctl 来管理 Ollama 服务,该种方式下 Ollama 服务在后台运行,即使终端关闭服务仍会继续运行。
sudo systemctl start ollama # 启动服务
sudo systemctl stop ollama # 停⽌服务
sudo systemctl restart ollama # 重启服务
sudo systemctl status ollama # 查看服务状态
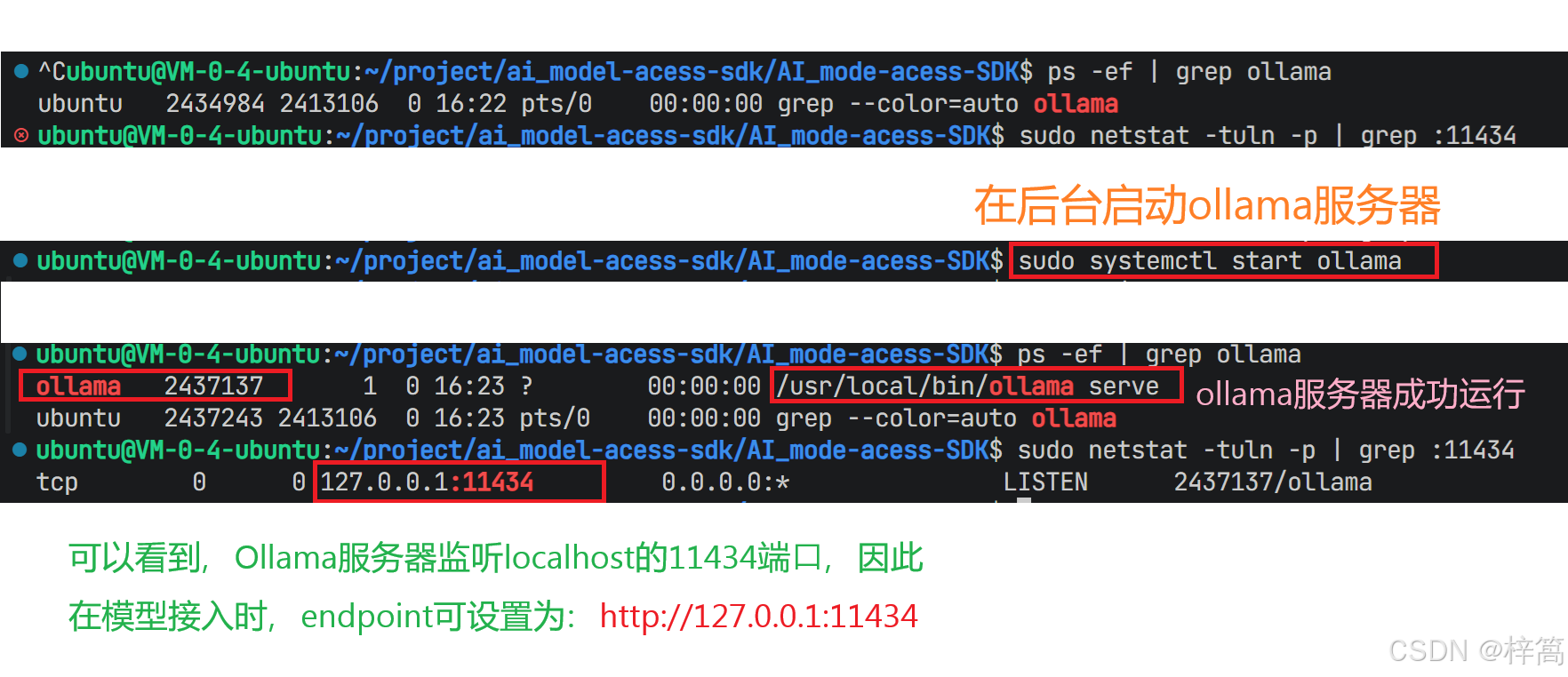
6.2.3 在后台启动Ollama服务器,使用Ollama客户端运行本地模型
-
在后台启动Ollama服务器
-
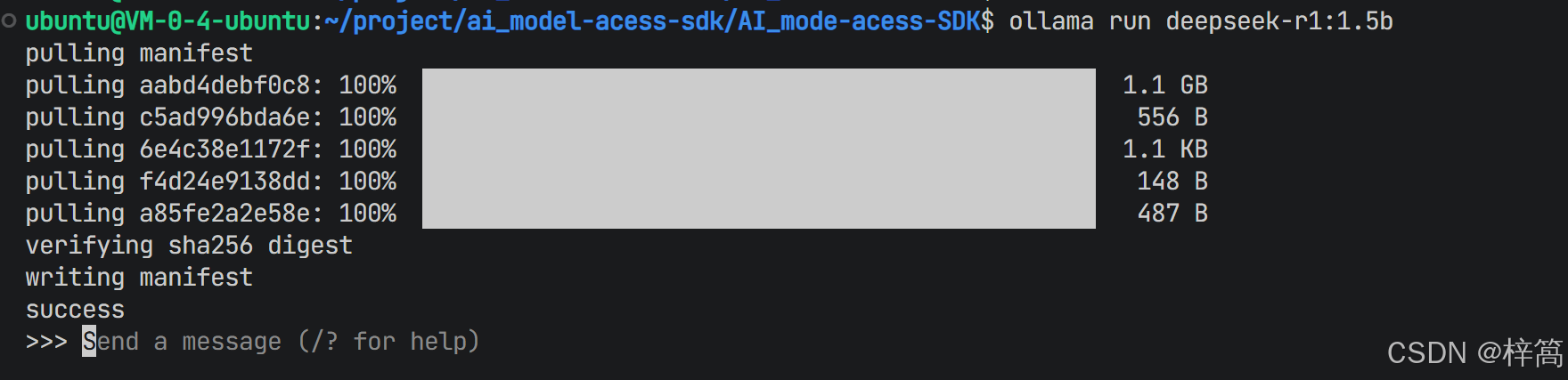
使用Ollama客户端运行本地模型
ollama run deepseek-r1:1.5b # ollama 会⾃动下载 deepseek-r1:1.5b模型,⼤概1.1GB
如未提前下载deepseek-r1:1.5b本地模型,第一次运行该模型时,会自动下载该模型

deepseek-r1:1.5b本地模型下载好后,后续可以直接启动该模型
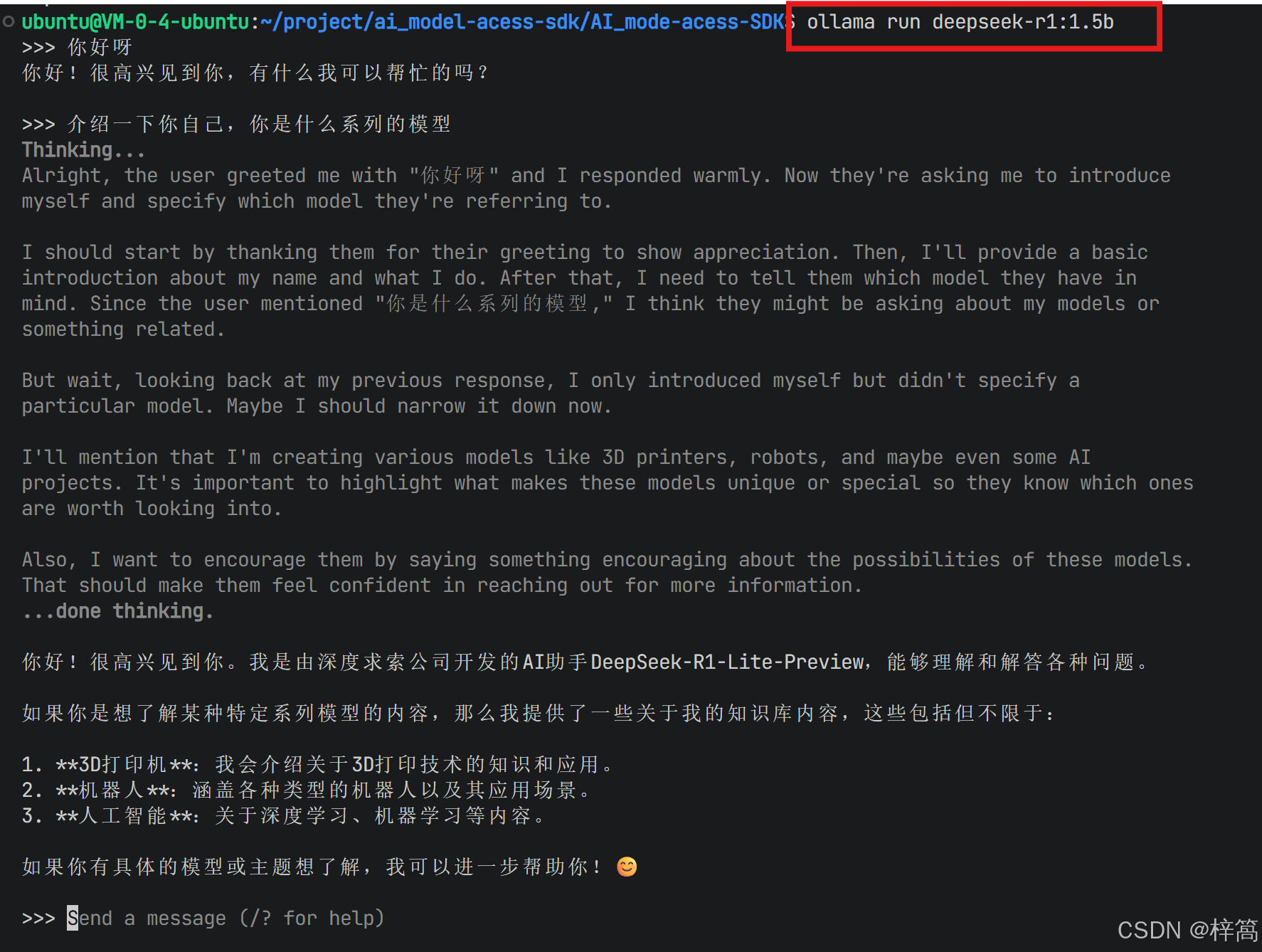
/bye:结束与模型对话

6.3 ollama提供的API接口
由于现在是通过Ollama本地接入某个大模型,Ollama实际是在本地搭建了一个服务器,用户可以通过 Ollama下载需要接入的模型,Ollma会替用户管理模型,并真正和大模型对接,用户通过 Ollama提供的HTTP接口访问。用户向大模型发的消息实际是,先发给Ollama服务器,Ollama服务器将消息发给大模型,大模型响应之后,Ollama再将消息返回给用户,用户不直接和大模型交互,因此初始化时不需要设置 api key进行身份认证。
Ollama服务器监听本地的11434端口
注意:本地部署可以在自己的本地机器上,也可以在企业自己的局域网 或 云服务器上。
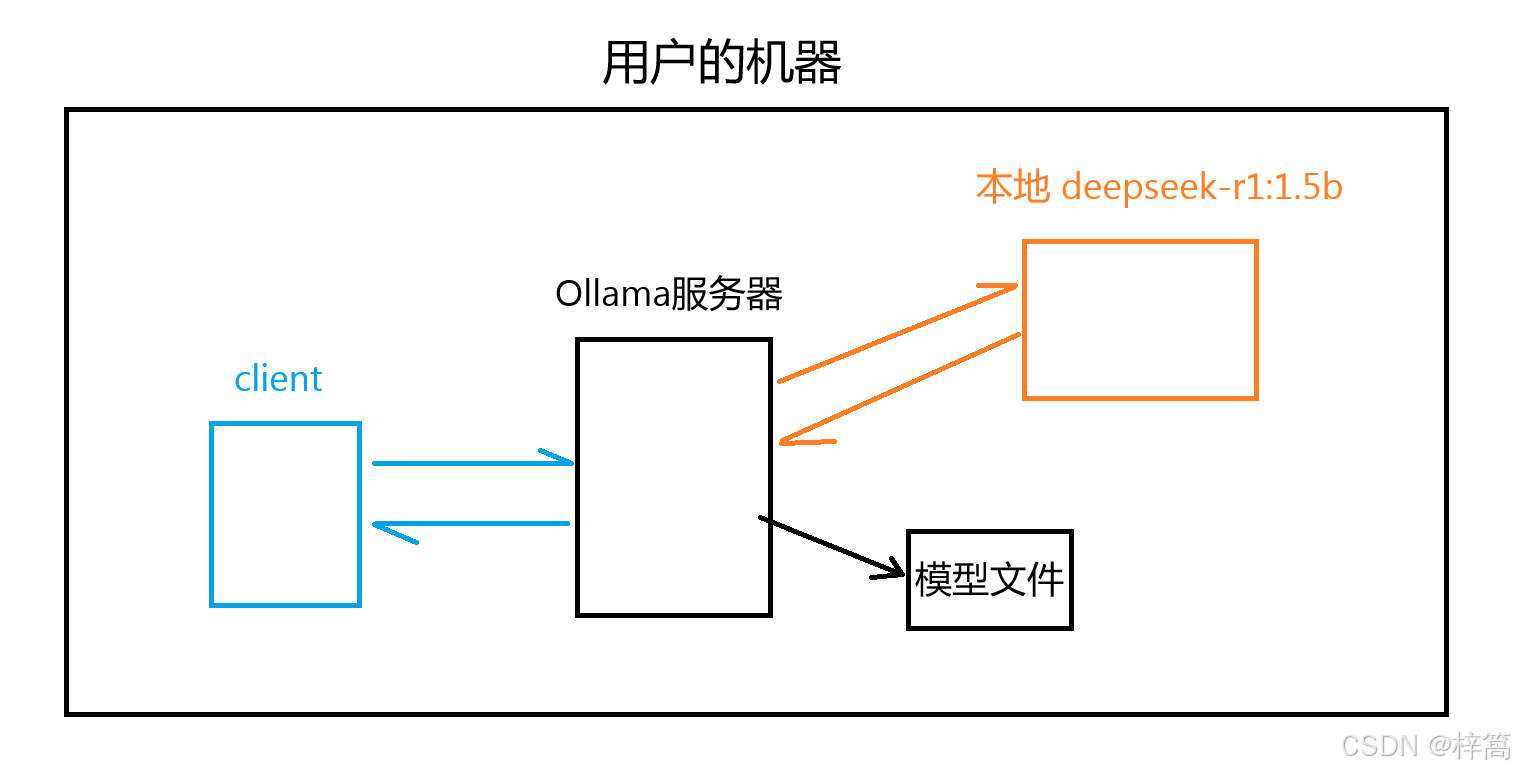
用户使用 客户端 与ollama服务器交互。
用户向本地大模型发送消息(必须指定大模型名称),先发给Ollama服务器,Ollama服务器会解析出模型名称,如果发现该本地模型没有在运行,还会查找模型文件将该模型加载到内存中,然后将用户消息经过处理后,发送给指定本地大模型,大模型响应之后,Ollama再将模型回复内容经过处理后,返回给用户,用户不直接和大模型交互
Ollama可以接入许多大模型,具体接入那个大模型看用户选择,因此需加入_model_name 和 _model_desc来保存接入的大模型的名称 和 描述信息。
Base URL: http://127.0.0.1:11434
请求URL: POST /api/chat
- 请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
- 请求体参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| messages | array | 历史对话,内部为每个对话的object,包含role(user:用户的问题;assistant:模型的回答)和 content两个字段 |
| model | string | 模型名称(“deepseek-r1:1.5b” 或 其它本地模型) |
| stream | boolean | - 未设置时,默认为 false - 如果设置为 true,将会以 SSE(server-sent events)的形式以流式发送消息增量。消息流以 data: [DONE] 结尾。 |
| options | object | 设置⼀些高级的可选参数,比如:temperature、最大tokens数。 注意:Ollama的最大 tokens字段为 num_ctx |
// 使⽤curl给ollama发送请求
curl -s -X POST "http://127.0.0.1:11434/api/chat" -H "Content-Type: application/json"
-d '{"model" : "deepseek-r1:1.5b", "stream" : false,
"messages" : [{"role" : "user", "content" : "你是谁?"}],
"options" : {"temperature" : 0.7, "num_ctx" : 2048}}'
6.4 本地大模型初始化
在使用 本地deepseek-r1:1.5b模型前,需要先配置好deepseek-r1:1.5b需要的一些参数信息,比如 base url、model名称、temperature、max_tokens等信息,否则无法正常使用 deepseek的api。
base url 这个参数的内容基本是固定的,model名称最好在初始化时指定(ollama管理很多本地大模型,指定model名称确定向哪一个本地大模型提问),模型描述 与 本地大模型对应(不同本地大模型 对应 不同模型描述),所以也可以在初始化时一并传入
- OllamaProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class OllamaProvider : public LLMProvider {
public:
// 初始化模型的 模型名称、模型描述 和 base url
// 与本地大模型通信,不需要API Key
bool init_Model(const std::map<std::string, std::string>& model_config) override;
// 检测模型是否有效
bool isAvailable() override;
// 获取模型名称
std::string getModelName() override;
// 获取模型描述信息
std::string getModelDesc() override;
......
};
} // namespace ai_chat_sdk
- OllamaProvider.cpp(部分)
#include "../include/OllamaProvider.h"
#include "../include/util/mylog.h"
#include <jsoncpp/json/json.h>
#include <httplib.h>
#include <sstream>
#include <iostream>
#include <memory>
#include <map>
namespace ai_chat_sdk{
// 初始化模型的 模型名称、模型描述 和 base url
bool OllamaProvider::init_Model(const std::map<std::string, std::string>& model_config)
{
// 初始化模型名称
auto it = model_config.find("model_name");
if(it == model_config.end())
{
ERR("Ollama model name is empty!");
return false;
}
_model_name = it->second;
// 初始化模型描述
it = model_config.find("model_desc");
if(it == model_config.end())
{
ERR("Ollama model desc is empty!");
return false;
}
_model_desc = it->second;
// 初始化base url
it = model_config.find("base_url");
if(it == model_config.end()) {
ERR("base_url is not found in model_config");
return false;
}
_base_url = it->second;
// 设置初始化成功标记
_isAvailable = true;
INFO("init success!!!!");
INFO("DeepSeek provider init successs with base_url : {}", _base_url);
return true;
}
bool OllamaProvider::isAvailable() {
return _isAvailable;
}
std::string OllamaProvider::getModelName() {
return _model_name;
}
std::string OllamaProvider::getModelDesc() {
return _model_desc;
}
} // namespace ai_chat_sdk
6.5 发送消息-全量返回
Base URL: http://127.0.0.1:11434
请求URL: POST /api/chat
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | deepseek-r1:1.5b |
| stream | boolean | false(全量返回,设置为false) |
| options | object | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
请求体示例(json格式):
{
"messages": [
{
"role": "user",
"content": "你是谁?"
}
],
"model": "deepseek-r1:1.5b",
"stream": false,
"options":{
"temperature": 0.7
"num_ctx": 2048
}
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
{
"model":"deepseek-r1:1.5b",
"created_at":"2025-09-02T09:24:03.117965426Z",
"message":{
"role":"assistant",
"content":"\n\n\u003c/think\u003e\n\n你好!很⾼兴见到你,有什么我可以帮忙的吗?"
},
"done_reason":"stop",
"done":true,
"total_duration":24879553617,
"load_duration":97011891,
"prompt_eval_count":2,
"prompt_eval_duration":133646497,
"eval_count":181,
"eval_duration":24647987800
}
- OllamaProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class OllamaProvider : public LLMProvider {
public:
......
// 发送消息给模型
std::string sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param) override;
......
};
} // namespace ai_chat_sdk
- OllamaProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 发送消息(非流式响应)
std::string OllamaProvider::sendMessage(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建 options_obj 对象
Json::Value options_obj(Json::objectValue);
options_obj["temperature"] = temperature;
options_obj["num_ctx"] = max_tokens;
// 构建请求体
Json::Value request_body;
request_body["model"] = getModelName();
request_body["messages"] = messages_array;
request_body["stream"] = false;
request_body["options"] = options_obj;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
/////////////////////////////// http相关内容(我还不太了解) ///////////////////////////////
// 创建HTTP客户端
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(60, 0); // 60秒读取超时
// 设置请求头
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// 发送POST请求
httplib::Result res = client.Post("/api/chat", headers,
request_body_str, "application/json");
// Result类型的 operator->重载 返回的是 Response对象的指针
if(!res || res->status != 200) {
ERR("POST请求失败, status code : {}", res->status);
return "";
}
DBG("POST请求成功, response body : {}", res->body);
////////////////////////////////////////////////////////////////////////////////////////
// 解析响应体(字符串格式的JSON字符串)为 Json::Value对象
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
Json::Value resp;
std::string error;
bool parse_ret = srd->parse(res->body.c_str(),res->body.c_str() + res->body.size(), &resp, &error);
if(!parse_ret) {
ERR("Json解析失败, error : {}", error);
return "";
}
// 从解析后的Json::Value对象中提取响应内容
if(resp.isMember("message") && resp["message"].isObject())
{
Json::Value message = resp["message"];
if(message.isMember("content") && message["content"].isString())
{
DBG("message content : {}", message["content"].asString());
return message["content"].asString();
}
}
// 解析失败,返回错误信息
ERR("Invalid response format from Ollama API");
return "";
}
} // namespace ai_chat_sdk
6.6 测试代码:测试全量返回
- test.cpp
#include <gtest/gtest.h>
#include "../sdk/include/util/mylog.h"
#include "../sdk/include/OllamaProvider.h"
TEST(OllamaProviderTest, sendMessageOllama)
{
// 创建OllamaProvider实例
auto OllamaProvider = std::make_shared<ai_chat_sdk::OllamaProvider>();
ASSERT_TRUE(OllamaProvider != nullptr);
// 初始化模型配置
std::map<std::string, std::string> model_config;
model_config["model_name"] = "deepseek-r1:1.5b";
model_config["model_desc"] = "一款实用性强、中文优化的通用对话助手,适合日常问答与创作";
model_config["base_url"] = "http://127.0.0.1:11434";
OllamaProvider->init_Model(model_config);
ASSERT_TRUE(OllamaProvider->isAvailable());
// 测试发送消息(全量返回)
std::vector<ai_chat_sdk::Message> messages;
messages.push_back({"user", "你好"});
std::map<std::string, std::string> param_map = {
{"temperature", "0.7"},
{"max_tokens", "2048"}
};
std::string response = OllamaProvider->sendMessage(messages, param_map);
ASSERT_FALSE(response.empty());
INFO("fulldata : {}", response);
}
int main(int argc, char *argv[])
{
// 初始化gtest库
testing::InitGoogleTest(&argc, argv);
// 初始化⽇志库
MyLog::Logger::instance().init_logger("sync_logger", spdlog::level::level_enum::debug, "stdout");
// 运⾏所有测试
return RUN_ALL_TESTS();
}
- CMakeLists.txt
客户端直接与Ollama服务器通信,Ollama服务器的base_url为:http://127.0.0.1:11434,支持http协议,因此在编译时不需要链接 OpenSSL开发库 去启用SSL
# CMake 最低版本要求
cmake_minimum_required(VERSION 3.10)
# 项目名称
project(test_DeepSeekProvider)
# 设置C++标准
set(CMAKE_CXX_STANDARD 17)
# 设置构建类型为Debug
set(CMAKE_BUILD_TYPE Debug)
# 添加可执行文件
add_executable(test_provider
test.cpp
../sdk/src/util/mylog.cpp
../sdk/src/OllamaProvider.cpp
)
# 链接库
target_link_libraries(test_provider PRIVATE fmt gtest spdlog jsoncpp)
- 代码运行结果:
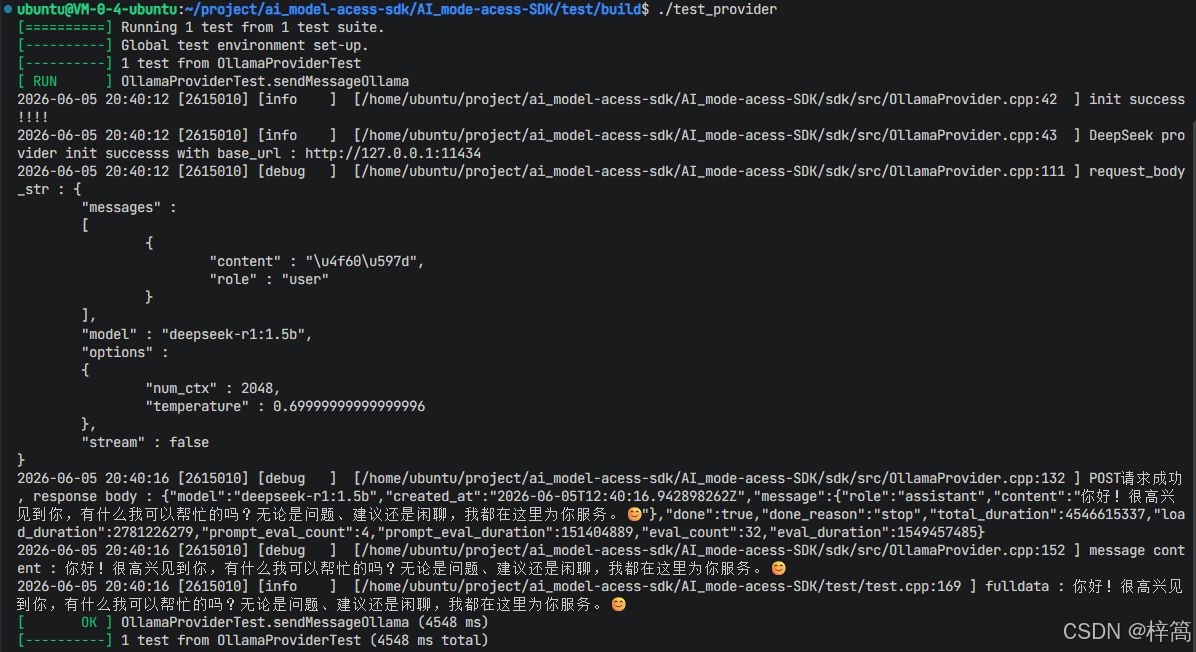
6.7 发送消息-流式返回
Base URL: http://127.0.0.1:11434
请求URL: POST /api/chat
- 请求头参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| Content-Type | string | application/json |
- 请求体参数:
| 字段名称 | 字段类型 | 设置值 |
|---|---|---|
| messages | array | 通过参数 const std::vector< Message >& messages 获取 |
| model | string | deepseek-r1:1.5b |
| stream | boolean | true(设置未true,开启流式返回) |
| options | object | 通过参数 const std::mapstd::string,std::string& request_param 获取 |
请求体示例(json格式):
{
"messages": [
{
"role": "user",
"content": "你是谁?"
}
],
"model": "deepseek-r1:1.5b",
"stream": true,
"options":{
"temperature": 0.7
"num_ctx": 2048
}
}
模型回复 的响应体示例(json格式):
最终是要提取 “content” 对应的内容(里面是模型的回复信息)
DeepSeek流式响应回复的每一个chunk块之间由 “/n/n” 隔开,且 DeepSeek流式响应结束时,会发 data: [DONE];但 Ollama服务器会对 deepseek-r1:1.5b流式响应返回的结果进行简化处理
简化处理后,Ollama流式响应返回的每一个chunk之间由一个"\n"分隔,流式响应结束靠 done字段(Bool类型)判断,done字段为false,代表流式响应继续,done字段为true,代表流式响应结束
{
"model":"deepseek-r1:1.5b",
"created_at":"2025-09-02T10:38:24.054739072Z",
"message":{
"role" : "assistant",
"content" : "您好"
},
"done":false
}
...
{
"model":"deepseek-r1:1.5b",
"created_at":"2025-09-02T10:38:28.49268141Z",
"message":{
"role":"assistant",
"content":"帮助"
},
"done":false
}
{
"model":"deepseek-r1:1.5b",
"created_at":"2025-09-02T10:38:28.626182393Z",
"message":{
"role":"assistant",
"content":"。"
},
"done":false
}
{
"model":"deepseek-r1:1.5b",
"created_at":"2025-09-02T10:38:28.760770641Z",
"message":{
"role":"assistant",
"content":""
},
"done_reason":"stop",
"done":true,
"total_duration":5720171892,
"load_duration":90386941,
"prompt_eval_count":6,
"prompt_eval_duration":383758775,
"eval_count":40,
"eval_duration":5245057118
}
- OllamaProvider.h(部分)
#pragma once
#include "LLMProvider.h"
namespace ai_chat_sdk{
class OllamaProvider : public LLMProvider {
public:
......
// 发送消息给模型-流式返回
std::string sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback) override;
......
};
} // namespace ai_chat_sdk
- OllamaProvider.cpp(部分)
namespace ai_chat_sdk{
.......
// 实现流式响应
std::string OllamaProvider::sendMessageStream(const std::vector<Message>& messages,
const std::map<std::string,std::string>& request_param,
std::function<void(const std::string&, bool)> callback)
{
// 检查模型是否初始化成功
if(!_isAvailable) {
ERR("model is not available");
return "";
}
// 获取采样温度 和 max_tokens
double temperature = 0.7;
int max_tokens = 2048;
if(request_param.find("temperature") != request_param.end()) {
temperature = std::stod(request_param.at("temperature"));
}
if(request_param.find("max_tokens") != request_param.end()) {
max_tokens = std::stoi(request_param.at("max_tokens"));
}
// 构建历史消息(含最新请求消息)
Json::Value messages_array(Json::arrayValue);
for(const auto& msg : messages) {
Json::Value msg_obj;
msg_obj["role"] = msg._role;
msg_obj["content"] = msg._content;
messages_array.append(msg_obj);
}
// 构建 options_obj对象
Json::Value options_obj(Json::objectValue);
options_obj["temperature"] = temperature;
options_obj["max_tokens"] = max_tokens;
// 构建请求体对象
Json::Value request_body(Json::objectValue);
request_body["model"] = getModelName();
request_body["messages"] = messages_array;
request_body["stream"] = true; // 开启流式响应
request_body["options"] = options_obj;
// 序列化请求体(将Json::Value对象 转换为 字符串格式的JSON字符串)
Json::StreamWriterBuilder swber;
std::unique_ptr<Json::StreamWriter> swb(swber.newStreamWriter());
std::stringstream ss;
int write_ret = swb->write(request_body, &ss);
if(write_ret != 0)
{
ERR("Json序列化失败!");
return "";
}
std::string request_body_str = ss.str();
DBG("request_body_str : {}", request_body_str);
////////////////////////////// 与非流式响应有区别的内容 ///////////////////////////////
// 创建HTTP Client
httplib::Client client(_base_url);
client.set_connection_timeout(30, 0); // 30秒超时
client.set_read_timeout(300, 0); // 流式响应需要更⻓的时间
// 设置请求头
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// 流式处理变量
std::string buffer; // 接收流式响应的数据块
bool gotError = false; // 响应是否成功(成功false,失败true)
std::string errorMsg; // 错误描述符
int statusCode = 0; // 状态码
bool streamFinish = false; // 标记流式返回数据是否结束
std::string fullResponse; // 累积完整的响应
/////////////////////////// 构建HTTP请求(设置处理函数) ////////////////////////////
// 创建请求对象
httplib::Request req;
req.method = "POST";
req.path = "/api/chat";
req.headers = headers;
req.body = request_body_str;
// HTTP协议响应的格式:
// ⼀个状态⾏:HTTP/1.1 200 OK
// ⼀组响应头:Content-Type,Content-Length
// 空⾏:\r\n\r\n
// 响应体
// 普通的HTTP响应是 ⼀头⼀体
// 流式响应:只有⼀个响应头,但响应体被拆分成多个块(chunks)陆续发送,即⼀头多块
// 响应头处理(检查状态码): 状态码不是200时,记录错误信息
req.response_handler = [&](const httplib::Response& res) {
int statusCode = res.status;
if(200 != statusCode){
gotError = true;
errorMsg = "HTTP Error:" + std::to_string(statusCode);
return false; // 终⽌请求
}
return true; // 继续接收数据
};
// 响应体处理(流式回调)
// data:指向当前接收到的数据块的指针
// len:当前数据块的长度
// offset:当前数据块在响应体中的偏移量
// totalLength:响应体的总长度
// 流式响应 主要关注前两个参数 data 和 len 就足够了。因为在流式响应的场景下,总长度通常未知,需要持续接收直到 [DONE] 标记出现
req.content_receiver = [&](const char* data, size_t len, uint64_t offset, uint64_t totalLength)
{
// 如果http请求头出错,就不需要再继续接收了
if(gotError)
{
return false;
}
// 追加新数据到缓冲区
buffer.append(data, len);
DBG("buffer: {}", buffer);
// 处理所有完整的事件,事件和事件之间以\n分隔
size_t pos = 0;
while((pos = buffer.find("\n")) != std::string::npos)
{
std::string event = buffer.substr(0, pos);
buffer.erase(0, pos+1); // 移除已经处理的事件
// 处理空⾏和注释, 以:开头的是注释⾏
if(event.empty())
{
continue;
}
// 反序列化:将JSON字符串 转换为 Json::Value对象
Json::Value chunk;
Json::CharReaderBuilder srder;
std::unique_ptr<Json::CharReader> srd(srder.newCharReader());
std::string errs;
bool read_ret = srd->parse(event.c_str(), event.c_str() + event.size(), &chunk, &errs);
if(!read_ret)
{
ERR("Json反序列化失败: {}", errs);
return false;
}
////// 关键代码:处理结束标记(判断流式响应是否结束) ///////
if(chunk.isMember("done") && chunk["done"].isBool() && chunk["done"].asBool())
{
callback("", true); // 返回true, 代表流式响应结束
streamFinish = true; // 标记流式响应结束
return true;
}
// 提取Json::Value对象中的 content字段
if(chunk.isMember("message") && chunk["message"].isObject() &&
chunk["message"].isMember("content"))
{
std::string content = chunk["message"]["content"].asString();
// 累积到完整响应
fullResponse += content;
callback(content, false); // 调用回调函数处理增量内容, false代表流式响应未结束
}
}
return true; // 继续接收数据
};
////////////////////////////// HTTP请求构建结束 /////////////////////////////
// 发送HTTP请求并处理结果
auto res = client.send(req);
// send的返回值类型是Result类型,Result类型内部实现了operator bool(), 允许将Result类型的实例隐式转换为bool类型
if(!res)
{
// 请求连接失败,网络问题、DNS解析失败等
ERR("HTTP Post error: {}", httplib::to_string(res.error()));
return "";
}
// 确保流正常结束
if(!streamFinish){
WARN("Stream ended without done:true marker");
callback("", true);
}
return fullResponse;
}
} // namespace ai_chat_sdk
6.8 测试代码:测试流式返回
- test.cpp
#include <gtest/gtest.h>
#include "../sdk/include/util/mylog.h"
#include "../sdk/include/OllamaProvider.h"
TEST(OllamaProviderTest, sendMessageOllama)
{
// 创建OllamaProvider实例
auto OllamaProvider = std::make_shared<ai_chat_sdk::OllamaProvider>();
ASSERT_TRUE(OllamaProvider != nullptr);
// 初始化模型配置
std::map<std::string, std::string> model_config;
model_config["model_name"] = "deepseek-r1:1.5b";
model_config["model_desc"] = "一款实用性强、中文优化的通用对话助手,适合日常问答与创作";
model_config["base_url"] = "http://127.0.0.1:11434";
OllamaProvider->init_Model(model_config);
ASSERT_TRUE(OllamaProvider->isAvailable());
// 测试发送消息(流式响应)
std::vector<ai_chat_sdk::Message> messages;
messages.push_back({"user", "你好"});
std::map<std::string, std::string> param_map = {
{"temperature", "0.7"},
{"max_tokens", "2048"}
};
auto write_chunk = [&](const std::string& chunk, bool last){
INFO("chunk : {}", chunk);
if(last){
INFO("[DONE]");
}
};
std::string response = OllamaProvider->sendMessageStream(messages, param_map, write_chunk);
ASSERT_FALSE(response.empty());
INFO("fulldata : {}", response);
}
int main(int argc, char *argv[])
{
// 初始化gtest库
testing::InitGoogleTest(&argc, argv);
// 初始化⽇志库
MyLog::Logger::instance().init_logger("sync_logger", spdlog::level::level_enum::debug, "stdout");
// 运⾏所有测试
return RUN_ALL_TESTS();
}
- 代码运行结果:
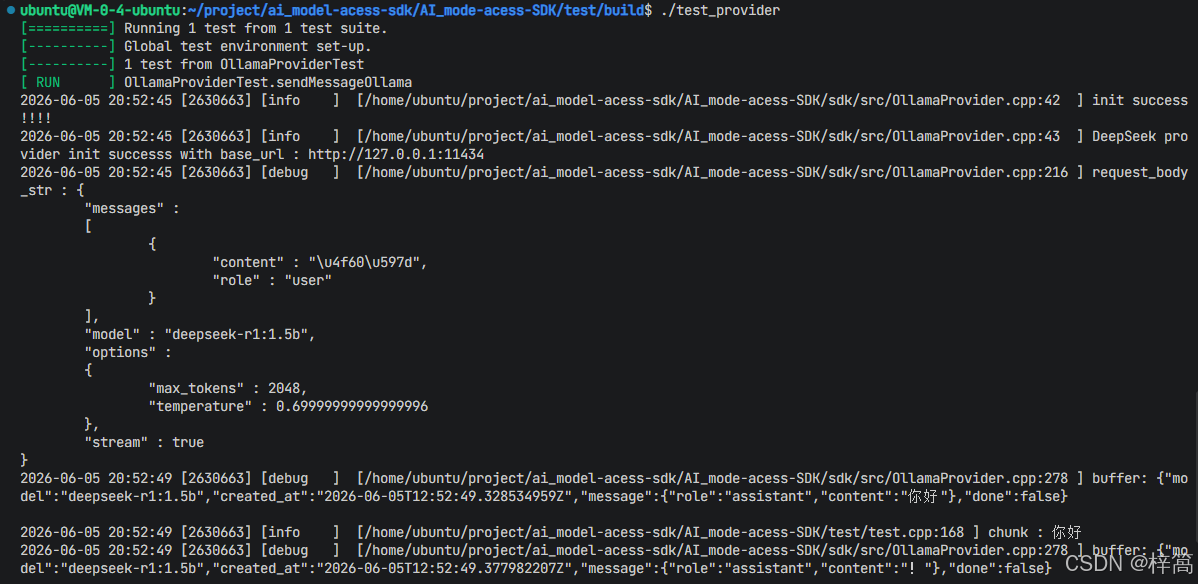
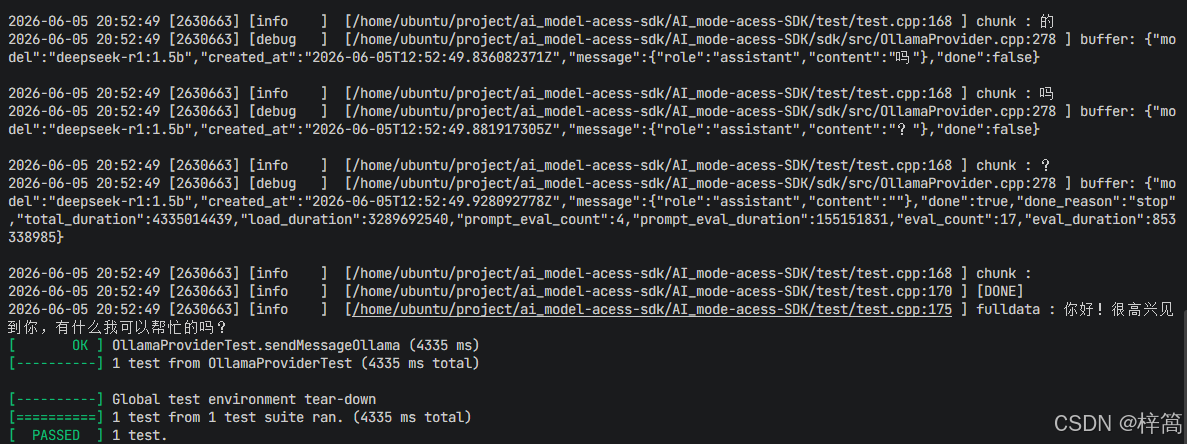

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)