计算机毕业设计之高校毕业数据预测与分析系统设计与实现
摘要
高校毕业数据预测与分析系统是一项旨在提升高校毕业生就业竞争力及高校教育质量的重要研究。该系统整合了多源异构数据,包括但不限于学生的学业成绩、课外活动、实习经历、就业信息等,通过大数据和机器学习技术进行深度分析和预测。系统能够预测毕业生的就业趋势、薪资水平及职业发展路径,为高校的教学改革、专业设置、就业指导等提供数据支持和决策依据。同时,系统也为毕业生提供个性化的就业建议,帮助他们更好地适应就业市场,提升就业竞争力。此外,该系统还能为政府和企业提供宝贵的决策支持数据,促进社会经济的可持续发展。
本研究采用文献综述、系统分析、实证研究等方法,对高校毕业数据预测与分析系统的需求、设计、实现及应用进行了全面研究。研究结果表明,该系统能够有效提升高校毕业生的就业竞争力,促进高校教育质量的提升。同时,系统也为政府和企业提供了有价值的决策支持数据,有助于社会经济的可持续发展。未来,随着人工智能和大数据技术的不断发展,该系统将更加智能化、个性化,为高校毕业生提供更加精准的就业指导和服务。
系统概述
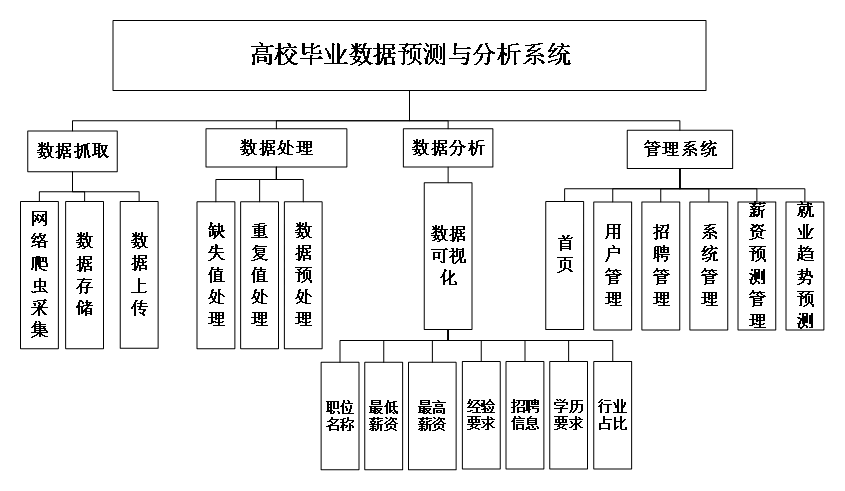
高校毕业数据预测与分析系统是一个综合性的数据处理和分析平台,其功能模块主要包括数据抓取、数据处理、数据分析和管理系统四个部分。以下是每个模块的具体功能和作用:
网络爬虫采集:该子模块负责从五八同城互联网上自动获取与高校毕业生相关的各种数据,如招聘信息、行业动态、职位要求等。通过设定特定的爬虫规则和目标网站,系统能够高效地收集大量原始数据,为后续的分析和处理奠定基础。
数据存储:采集到的数据将被存储在数据库中,以便于管理和查询。这一步骤确保了数据的完整性和可靠性,同时也方便了数据的检索和使用。
数据上传:为了实现数据的共享和更新,系统提供了数据上传的功能。用户可以将自己收集到的数据上传至系统,丰富数据库的内容,提高数据的时效性和全面性。
2. 数据处理模块
缺失值处理:在实际数据中,常常会出现某些字段缺失的情况。缺失值处理子模块能够识别并填补这些缺失的数据,保证数据的连续性和完整性,从而提高分析的准确性和可靠性。
重复值处理:为了避免数据冗余和干扰,系统会对数据进行去重处理。通过比较相似度和唯一标识符等方法,去除重复的数据记录,确保每条信息的独特性和有用性。
数据预处理:这一步是对数据进行清洗、转换和格式化的过程。通过规范化处理,将不同来源、不同格式的数据统一成标准格式,便于后续的分析和应用。
3. 数据分析模块
数据可视化:将复杂的数值型数据和文本型数据转换为直观易懂的可视化图形,如柱状图、折线图、饼状图等。这样可以帮助用户更快速地理解数据背后的含义和趋势,做出明智的决策。
首页:作为系统的入口页面,首页通常包含了系统的整体概览和一些核心指标的展示。用户可以通过首页快速了解当前的就业形势和市场动态,以及自己的职业发展规划进度。
用户管理:用于管理注册用户的信息和行为记录。包括用户的权限分配、个人信息维护等功能,以确保系统的安全和稳定运行。
招聘管理:涉及企业发布的职位信息的管理和维护。包括职位的审核、编辑、删除等功能,以及与企业沟通协调的工作流程。
薪资预测管理:利用历史数据和算法模型对薪资水平进行预测。这对于企业和个人来说都具有重要的参考价值,可以帮助他们制定合理的薪酬策略和发展规划
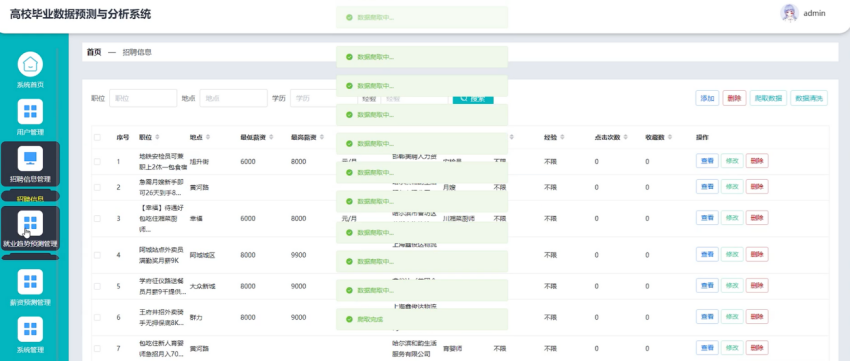
管理员点击招聘信息管理模块可以对展现在系统前台的所有招聘信息进行查看,修改,删除、数据爬取和新增的操作。数据爬取采用Python的爬虫框架,Scrapy结合HTTP请求库如Requests,从58同城网址等目标源获取数据。爬取过程中,通过设置合理的爬取频率和遵守robots.txt规则,确保数据获取的合法性和效率。
数据爬取采用Python的爬虫框架,Scrapy结合HTTP请求库如Requests,从网站等目标源获取数据。爬取过程中,通过设置合理的爬取频率和遵守robots.txt规则,确保数据获取的合法性和效率。获取原始数据后,进入数据清洗阶段,利用Python的Pandas库对数据进行预处理,包括去除空值、异常值,格式统一,以及处理重复数据。此外,通过正则表达式对文本数据进行清洗,提取有用信息。数据清洗还涉及数据类型转换、缺失值填充等操作,确保数据的质量和一致性。最终,清洗后的数据存储于数据库,为后续的数据分析和业务应用提供准确、可靠的数据基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)