AMD AI9 HX370 小主机跑 Qwen3.6-27B:8.5 t/s 的“养慢虾“哲学
上回折腾完 P104 矿卡的 30 t/s,有人问:“那你日常用的是什么?”
答案可能让你意外——我还有个 <1L 的小主机,安静地跑着 27B 稠密大模型,速度只有 8.5 t/s。
慢吗?慢。但这是我目前最满意的一套本地 AI 部署方案。
这篇文章不追求压榨极限性能,而是聊聊为什么"慢但聪明"比"快但笨"更适合日常使用。
一、硬件:一升空间,装下 270 亿参数
先亮家底:
|
项目 |
规格 |
|
CPU |
AMD AI9 HX370 (12C24T, 3.8-5.2GHz) |
|
GPU |
AMD Radeon 890M (RDNA 3, 12 CUs, 共享显存) |
|
内存 |
DDR5 96GB (系统内存 + 显存) |
|
体积 |
<1L 小主机 |
|
噪音 |
几乎无声,放在桌面不吵 |
|
功耗 |
整机 <65W,电费 <10 元/月 |
没有独立显卡,没有水冷,没有风扇狂转。 就是一台安静的小盒子,24 小时开着。
模型是
Qwen3.6-27B-MTP-Q4_K_M.gguf,270 亿参数,稠密架构(非 MoE),Q4 量化后约 16GB。
为什么选这个模型?
- 稠密 > MoE:对于日常对话和代码生成,稠密模型的推理质量更稳定
- 27B 是甜点:太小不够聪明,太大跑不动
- MTP 支持推测解码:这是提速的关键
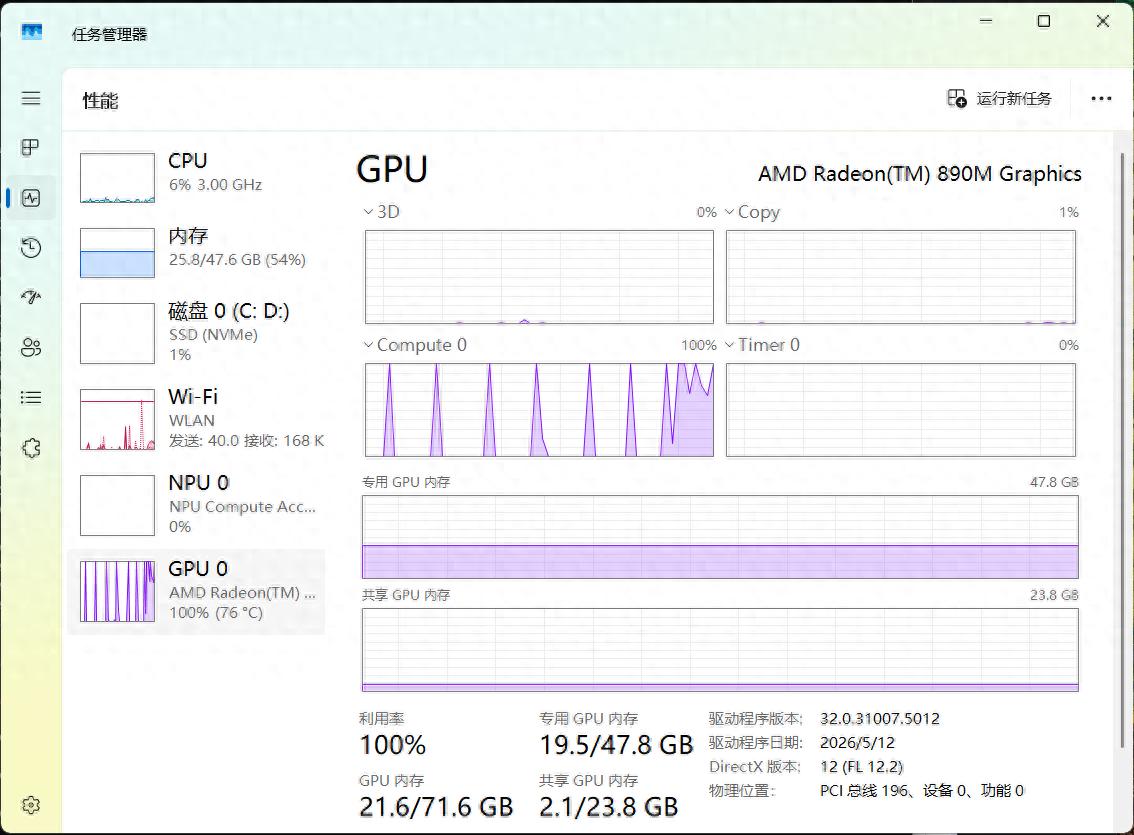
二、配置:能动的旋钮,一个个拧
llama.cpp 的启动命令:
.\llama-server.exe ^
-m "Qwen3.6-27B-MTP-Q4_K_M.gguf" ^
-t 12 ^
-ngl 99 ^
-c 52536 ^
-ctk q4_0 ^
-ctv q4_0 ^
--spec-type draft-mtp ^
--spec-draft-n-max 6 ^
--reasoning-budget 4096 ^
--no-mmap ^
-fa 1 ^
--port 8002
关键参数解读
-ngl 99:全部层进 GPU
和 P104 那篇的 -ngl 999 一样,能进则进。Radeon 890M 虽然是集成显卡,但共享系统内存,27B Q4 量化约 16GB,64GB 内存完全装得下。
-t 12:12 线程
HX370 是 12 核 24 线程,12 线程是测试后的甜点值。试过 16 线程,反而因为线程调度开销掉速。
-c 52536:52K 上下文
够用就行。日常对话很少超过 10K tokens,52K 是为了应对长文档分析和代码库扫描。
-ctk q4_0 / -ctv q4_0:KV 缓存量化
这是省显存的关键。Q4 量化的 KV 缓存比 FP16 小一半以上。对于 52K 上下文,这能省下几个 GB 的显存压力。
–spec-type draft-mtp / --spec-draft-n-max 6:推测解码
这是提速的核心。Qwen3.6-27B-MTP 模型内置了多 token 预测头,llama.cpp 可以用它来生成"草稿 token",然后大模型一次性验证。
实际效果:76.7% 的接受率(23 个草稿 / 30 个生成),相当于每 30 次前向传播,只花了 7 次的代价。
–no-mmap:禁用内存映射
强制加载模型到内存,避免随机 I/O。对于 SSD 上的大模型文件,这能减少加载延迟。
三、实测:日志里藏着真相
不跑 llama-bench,直接看实际请求的日志——这才是你日常使用的真实速度。
一次典型请求
5192.16.062.557 I srv params_from_: Chat format: peg-native
5192.16.063.549 I slot get_availabl: id 0 | task -1 | selected slot by LCP similarity, sim_best = 0.146 (> 0.100 thold), f_keep = 0.144
5192.16.063.559 I srv get_availabl: updating prompt cache
5192.16.064.230 W srv prompt_save: - saving prompt with length 2376, total state size = 200.764 MiB (draft: 9.327 MiB)
5192.16.216.026 I srv load: - looking for better prompt, base f_keep = 0.144, sim = 0.146
... ...
5192.42.980.787 I slot create_check: id 0 | task 35105 | created context checkpoint 3 of 32 (pos_min = 2343, pos_max = 2343, n_tokens = 2344, size = 158.827 MiB)
5192.46.330.804 I slot print_timing: id 0 | task 35105 | prompt eval time = 26994.11 ms / 2025 tokens ( 13.33 ms per token, 75.02 tokens per second)
5192.46.330.821 I slot print_timing: id 0 | task 35105 | eval time = 3056.15 ms / 26 tokens ( 117.54 ms per token, 8.51 tokens per second)
5192.46.330.823 I slot print_timing: id 0 | task 35105 | total time = 30050.26 ms / 2051 tokens
5192.46.330.824 I slot print_timing: id 0 | task 35105 | graphs reused = 29621
5192.46.330.827 I slot print_timing: id 0 | task 35105 | draft acceptance = 0.76667 ( 23 accepted / 30 generated)
5192.46.330.866 I statistics draft-mtp: #calls(b,g,a) = 624 30818 30818, #gen drafts = 30818, #acc drafts = 27908, #gen tokens = 184890, #acc tokens = 122900, dur(b,g,a) = 1.979, 3757891.824, 72.847 ms
5192.46.331.074 I slot release: id 0 | task 35105 | stop processing: n_tokens = 2376, truncated = 0
5192.46.331.115 I srv update_slots: all slots are idleprompt eval time = 26994 ms / 2025 tokens → 75 t/s
eval time = 3056 ms / 26 tokens → 8.5 t/s
total time = 30050 ms / 2051 tokens
draft acceptance = 0.76667 (23 accepted / 30 generated)
解读:
- Prompt 处理:75 t/s
- 2025 个 token 的上下文,花了 27 秒。这个速度对于集成显卡来说不错——GPU 在 prefill 阶段利用率很高。
- 生成速度:8.5 t/s
- 26 个 token 的回复,花了 3 秒。这就是你感受到的"慢"。
- 推测解码:76.7% 接受率
- 小模型草稿帮大模型省了大量计算。没有 MTP 推测解码,实测只有 4.57 t/s——8.5 t/s 几乎是翻倍。
- 5192.46: 已经运行了5192分钟46秒,也就是3天14小时32分钟46秒。
KV 缓存状态
cache state: 8 prompts, 7532 MiB / 8192 MiB limit8GB 的 KV 缓存上限,当前用了 7.5GB,管理着 8 个会话。
其中几个大会话:
- 27K tokens → 1.5GB
- 22K tokens → 874MB
- 2K tokens → 667MB
缓存快满了,但自动 LRU 淘汰机制在正常工作。 当新请求进来时,最旧的缓存项会被清除,腾出空间。
四、为什么 8.5 t/s 够用?
场景对比
|
场景 |
Token 数 |
耗时 |
体验 |
|
日常问答 |
50-100 |
6-12s |
✅ 可接受 |
|
代码生成 |
200-300 |
24-35s |
⚠️ 需要等待 |
|
长文写作 |
500+ |
60s+ |
⚠️ 适合后台 |
|
工具调用 |
20-50 |
2-6s |
✅ 流畅 |
关键洞察
1. Prompt 处理快于生成
75 t/s 的 prefill 速度意味着:即使上下文有 2000 tokens,也只花 27 秒。一旦开始生成,8.5 t/s 对于短回复完全够用。
2. 推测解码是隐形的加速器
76.7% 的接受率意味着:每 30 个草稿 token,23 个被大模型接受。相当于免去了 23 次完整的前向传播。
没有推测解码,8.5 t/s 直接掉到 4.57 t/s。这差距,呵呵。
五、三条经验教训
折腾完这一套,我脑海里只剩三条体验:
1. 集成显卡跑大模型,内存带宽是瓶颈
Radeon 890M 共享系统内存,模型加载、KV 缓存、推测解码,全部走 DDR5 带宽。8.5 t/s 的生成速度,本质上是内存带宽的限制,比起 Max395的GPU 还是有较大的距离的。统一内存是他的优势,
别指望通过调参数突破这个天花板。 能做的只是优化内存使用(KV 缓存量化、推测解码),让带宽利用率更高。
2. 推测解码接受率 > 70% 就是有效的
Qwen3.6-27B-MTP 的 MTP 头设计得不错,76.7% 的接受率意味着小模型草稿和大模型判断高度一致。
如果接受率低于 50%,说明草稿质量太差,反而浪费计算。 选模型时,优先选支持 MTP 的版本。
3. 稳定 > 速度,对于日常使用
|
方案 |
速度 |
稳定性 |
噪音 |
功耗 |
|
RTX 4090 |
50+ t/s |
⚠️ 驱动/显存问题 |
风扇 loud |
450W |
|
Cloud API |
100+ t/s |
⚠️ 网络/限流 |
- |
- |
|
HX370 + 890M |
8.5 t/s |
✅7×24 稳定 |
✅无声 |
✅<65W |
你不需要 GPT-4 的速度,你需要 GPT-4 的智能。 8.5 t/s 对于日常对话、代码生成、文档处理,完全够用。
六、写在最后
从 P104 矿卡的 30 t/s,到 HX370 小主机的 8.5 t/s,两套方案,两种哲学:
- P104:压榨极限,把"电子垃圾"变成"Token FREE 推理机"
- HX370:追求平衡,用"慢但聪明"换取"安静稳定"
没有最好的方案,只有最适合你的方案。
如果你也需要一台 24 小时运行的本地 AI,不追求极致速度,但想要稳定、安静、低功耗——一台 HX370 小主机,或许就是答案。
我知道还有说慢的,不过这速度养虾是足够了,欢迎来辩。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)