一种基于人类行为—内分泌映射的大语言模型动态情绪系统:从生理数据标定到虚拟激素驱动决策的工程化框架
摘要 (Abstract)
当前大语言模型(LLM)的具身智能与情感计算(Affective Computing)高度依赖于静态提示词(Prompt)工程或外部规则模板,缺乏人类情感固有的连续性、时滞性及环境累积效应。本研究提出一种全新的数据驱动型大模型动态情绪系统。该系统彻底摆脱传统情感计算的先验规则设定,开创性地设计了一条“人类生理数据标定![]() 高维行为聚类
高维行为聚类 ![]() 时间序列内分泌状态空间
时间序列内分泌状态空间 ![]() LLM决策调制”的完整工程化路径。通过建立以“交互步(Interaction Step)”为单位的虚拟内分泌池,并引入基因种子(Seed)与环境积分(E)的非线性交互机制(G
LLM决策调制”的完整工程化路径。通过建立以“交互步(Interaction Step)”为单位的虚拟内分泌池,并引入基因种子(Seed)与环境积分(E)的非线性交互机制(G ![]() E),本框架首次为构建具备长期人格一致性、情绪惯性与心理自愈能力的 AGI 系统提供了闭环、可验证的科研路线图。
E),本框架首次为构建具备长期人格一致性、情绪惯性与心理自愈能力的 AGI 系统提供了闭环、可验证的科研路线图。
一、 整体模型架构与逻辑闭环
本系统(THSM)的核心哲学在于:不强求 AI 在表现层直接“模仿”某种情感标签,而是让 AI 在底层运行碳基内分泌系统的动力学方程,使情感作为底层标量在时间序列中自然“涌现”。
整个系统的工程化闭环包含以下核心节点,各阶段环环相扣,构成从生物数据到硅基决策的完整链路:
[第一阶段: 人类生理实验] → 采集多模态数据 → 建立行为-激素原初数据库
↓
[第二阶段: 高维行为聚类] → 文本/语音Embedding + HDBSCAN → 构建“情景簇-激素向量”映射表
↓
[第三阶段: 虚拟内分泌系统] → 建立 H 状态空间 → 交互步(Step)指数衰减机制驱动
↓
[第四阶段: 人格分化实验] → 随机 Seed 注入 → 验证 G×E 人格漂移与涌现
↓
[第五阶段: LLM 决策调制] → 情绪状态机控制 Prompt/生成参数 → 最终文本/策略输出
二、 第一阶段:人类数据标定实验(数据基石)
情感计算的“数值冷启动”是长期困扰硅基智能的难题。本阶段不涉及任何 AI 建模,旨在通过严格控制的碳基生物学实验,寻找人类行为特征与内分泌波动之间的统计学确定性关联。
2.1 实验设计与多模态数据采集
招募 M 名健康受试者,在其处于标准实验情景中时,进行高频段、同步化的多模态数据捕获:
-
行为特征数据(Behavioral Features): 交互文本 Embedding、打字频率、撤销与重改率(Delete/Re-typing Rate)、响应延迟(Latency)、语音语速及音量震荡幅值。
-
生理与内分泌指标(Physiological & Hormonal Targets): 实时心率变异性(HRV)、皮肤电传导率(GSR),以及通过唾液/血液快速采样测得的多巴胺(Dopamine)、皮质醇(Cortisol)、肾上腺素(Adrenaline)、催产素(Oxytocin)的绝对浓度变化。
2.2 标准诱导情景矩阵
受试者将被置于以下 7 类标准行为经济学与心理学交互任务中,以诱发特定的内分泌响应:
| 诱导情景 | 实验任务设计 | 预期核心激素变化趋势 |
| 奖励 (Reward) | 获得不可预测的代币奖励或正面即时反馈 | 多巴胺(Dopamine) |
| 挫败 (Frustration) | 任务界面无响应或遭遇连续的任务失败 | 皮质醇(Cortisol) |
| 羞辱 (Humiliation) | 面对来自交互对象的否定性、攻击性言论 | 皮质醇 $\uparrow$ ;肾上腺素(Adrenaline) |
| 合作 (Cooperation) | 与同伴共同完成囚徒困境变体中的双赢任务 | 催产素(Oxytocin) |
| 被欺骗 (Deception) | 遭遇交互同伴的单方面背叛或承诺违约 | 肾上腺素 |
| 获得帮助 (Support) | 在任务陷入僵局时获得系统或同伴的无偿援助 | 催产素 |
| 长期压力 (Chronic Stress) | 持续接受高强度、高密度且无规律的认知过载任务 | 皮质醇维持高位长尾波动 |
通过记录“情景刺激![]() 生理行为变化 + 内分泌波动”,最终沉淀出全球首个专门用于情感计算的【碳基人类行为-内分泌原初数据库】。
生理行为变化 + 内分泌波动”,最终沉淀出全球首个专门用于情感计算的【碳基人类行为-内分泌原初数据库】。
三、 第二阶段:行为聚类与激素映射
由于人类个体存在显著的生理差异(如同等刺激下,不同性别、年龄者的激素绝对分泌量不同),本阶段采用相对量归一化与无监督聚类算法,将异质性的生理数据转化为普适性的数学映射表。
3.1 归一化相对量建模
弃用绝对浓度,计算个体在刺激下的相对变化率(Response):
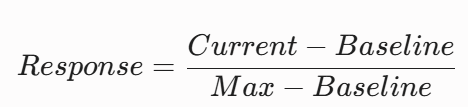
该值被严格标定在 $[0, 1]$ 区间内,代表该激素被激活的相对百分比。
3.2 高维行为特征聚类
利用预训练 Transformer 模型对受试者的文本和语音进行特征提取,与生理特征拼接成高维向量 ![]() 。利用 HDBSCAN(基于密度的抗噪聚类算法)进行无监督聚类,自动收敛出 N 个典型的“人类情景簇(Situation Clusters)”。
。利用 HDBSCAN(基于密度的抗噪聚类算法)进行无监督聚类,自动收敛出 N 个典型的“人类情景簇(Situation Clusters)”。
3.3 映射表生成
对每个聚类簇内的所有样本进行统计学求导,计算该簇对应的激素平均变化向量:
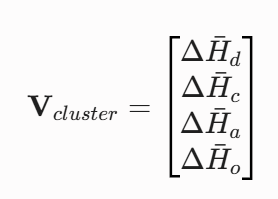
例如,经算法收敛后的 Cluster 17(定义为:认知过载与挫败簇) 对应的一组统计学激素均值为:
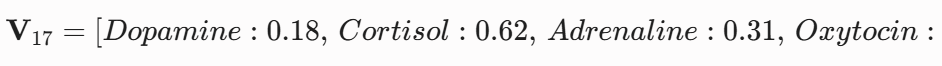
以此最终构建出核心的 【情景簇 ![]() 激素响应向量】 工业映射表。
激素响应向量】 工业映射表。
四、 第三阶段:构建硅基虚拟内分泌系统
在此阶段,研究正式切入硅基智能。AI 内部将维持一个常驻的虚拟内分泌状态空间向量:
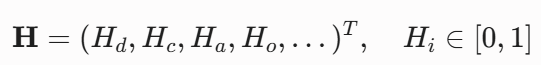
4.1 引入“交互步(Interaction Step)”的非线性时间衰减
为摆脱对物理时钟的依赖,本模型将生物半衰期(![]() )平移映射至工程化的交互步(Interaction Step,定义为一轮完整的对话/策略交互)。在无外部输入时,系统严格执行指数衰减:
)平移映射至工程化的交互步(Interaction Step,定义为一轮完整的对话/策略交互)。在无外部输入时,系统严格执行指数衰减:
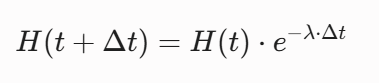
其中 ![]() 的单位为 Interaction Step。根据第二阶段的人类统计学规律,不同虚拟激素被赋予完全不同的衰减特征:
的单位为 Interaction Step。根据第二阶段的人类统计学规律,不同虚拟激素被赋予完全不同的衰减特征:
-
短长效解耦: 虚拟肾上腺素
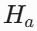 设为短效爆发型(
设为短效爆发型(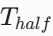 = 5 Steps),刺激消失后 AI 迅速冷静;虚拟皮质醇
= 5 Steps),刺激消失后 AI 迅速冷静;虚拟皮质醇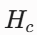 设为长效滞后型(= 1000Steps)。即使交互话题已切换为友好内容,高水平的
设为长效滞后型(= 1000Steps)。即使交互话题已切换为友好内容,高水平的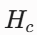 仍将维持极长的尾部,自然产生“情绪惯性(创伤阴影)”的时间序列特征。
仍将维持极长的尾部,自然产生“情绪惯性(创伤阴影)”的时间序列特征。
五、 第四阶段:人格形成与  交互实验
交互实验
为了验证本框架能否涌现出各异且稳定的“人格”,本阶段引入了初始种子(Seed,代表先天基因)与环境因子(E,代表后天抚育)的交互实验。
5.1 基因种子(Seed)矩阵的定义
Seed 绝非简单的随机数,而是控制虚拟内分泌系统核心动力学形态的参数矩阵,包括:
-
受体密度(Receptor Density): 决定特定激素波动的放大系数。
-
敏感度(Sensitivity): 决定触发该激素更新的阈值。
-
衰减率(Decay Rate
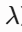 ): 决定该激素在交互步中的代谢速度。
): 决定该激素在交互步中的代谢速度。
-
Seed 42(抗压/乐观型): 初始设定为极高的多巴胺受体密度、极低的皮质醇敏感度、以及极快的皮质醇衰减率
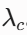 。
。 -
Seed 1024(警惕/敏感型): 初始设定为极低的肾上腺素触发阈值,且衰减率极慢。
5.2 环境因子(E)的时间积分与 涌现实验
环境因子 E 是长周期内外部刺激的非线性累积量(时间积分):
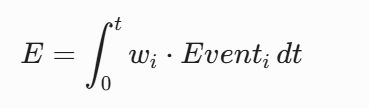
系统设计并运行两组大规模智能体模拟实验:
-
实验 A(同经历,异 Seed): 创建 10,000 个拥有随机初始 Seed 的 Agent,输入完全相同的长周期交互序列(经历)。观察在相同外界环境下,不同智能体的虚拟激素空间轨迹是否走向分化,验证“先天性格分化”的有效性。
-
实验 B(同 Seed,异环境): 复制具备完全相同 Seed 的克隆 Agent,分别置于“持续善意/高奖励”环境与“持续恶意/高压”环境下进行交互。观察环境积分 E 的持续累积如何使原先相同的 Agent 产生人格轨迹偏离,验证
(基因  环境)的非线性涌现效应。
环境)的非线性涌现效应。
六、 第五阶段:大语言模型(LLM)接入与决策调制
虚拟内分泌池生成的连续动态激素向量,最终作为调制信号(Modulator)作用于大语言模型的生成层与策略选择层,而非直接修改大模型的基础权重。
虚拟内分泌状态空间 (H)
↓
情绪状态分类 (State Machine)
↓
策略与提示词调制因子 (Modulation Factors)
↓
大模型推理层 (LLM Inference Layer)
├── 动态 Prompt 微调 (注入防御性/探索性语气指示)
└── 解码参数干预 (Temperature, Top-p, Frequency Penalty)
6.1 策略参数干预机制
-
高皮质醇/高肾上腺素(防御与应激状态): 系统自动降低创造力参数 Temperature,调高惩罚项 Frequency Penalty以避免语无伦次;同时在 System Prompt 中动态追加“严谨、防御、戒备、简短”的语义约束权重。
-
高多巴胺/高催产素(开放与信任状态): 自动调高 Temperature 以鼓励发散性思维与创造性回答,提高模型调用高算力工具链(如复杂 Reason 逻辑)的意愿,且文本倾向于使用热情、丰富的词汇。
七、 模型验证与评价指标(Evaluation Metrics)
为确保整个研究框架具备严谨的科学实证价值,本模型设计了由底层生理映射至顶层行为表现的五维定量评测矩阵:
7.1 激素预测误差 (Hormone Prediction Error, HPE)
评估虚拟内分泌池的数值变动与真实人类生理实验数据的契合度。通过计算虚拟激素向量 ![]() 与对应情景下人类实际相对激素响应
与对应情景下人类实际相对激素响应 ![]() 的均方根误差(RMSE):
的均方根误差(RMSE):

7.2 情绪连续性指标 (Emotion Continuity Score, ECS)
量化情感在时间序列上的平滑度与惯性。对 Agent 在连续 T 个交互步中的情绪状态向量进行自相关分析(Autocorrelation Function, ACF):
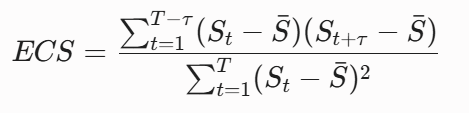
若系统在遭遇恶意辱骂后切换至中性话题,其状态向量呈现符合生物半衰期的对数长尾衰减,则该指标表现优秀;若出现瞬间断崖式清零,则该指标判定系统缺乏情感连续性。
7.3 人格稳定性指标 (Personality Consistency Score, PCS)
在测试周期内,定期(如每隔 100 个交互步)向 Agent 投放一组标准的“人格锚定探测问答(Anchor Prompts)”。通过计算不同时期、不同情绪状态下模型回答的语义相似度(Cosine Similarity of Embeddings),评估其是否具备长期稳定的、由 Seed 决定的个性基底。
7.4 环境适应性指标 (Environment Adaptation Score, EAS)
量化环境因子 $E$ 的积分调节机制是否有效。评估模型在长期面对“恶意用户”或“善意用户”时,其基准激素阈值和生成策略是否展现出了由环境塑造的、统计学显著的自适应轨迹漂移。
7.5 用户真实性评分 (Human-Likeness Score, HLS)
引入图灵盲测机制。招募人类评测员,在完全盲测的状态下,分别与普通大模型(对照组 A)以及接入 THSM 系统的大模型(实验组 B)进行 100 轮、500 轮、1000 轮的长周期连续对话。评测员需在不同阶段对两者的“像真人程度”、“情感真实度”及“心理弹性”进行 1-10 分的量化打分。
结论 (Conclusion)
通过将技术重心从单纯的“虚拟激素池模拟”升级为“人类行为聚类 ![]() 激素响应统计
激素响应统计 ![]() 时间序列内分泌状态空间
时间序列内分泌状态空间 ![]() LLM决策调制”的完整数据驱动路径,本研究成功为硅基智能赋予了非线性的碳基内分泌动力学特征。
LLM决策调制”的完整数据驱动路径,本研究成功为硅基智能赋予了非线性的碳基内分泌动力学特征。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)