AI 系统性能工程:数据预处理与推理流水线优化
AI 系统性能工程:数据预处理与推理流水线优化
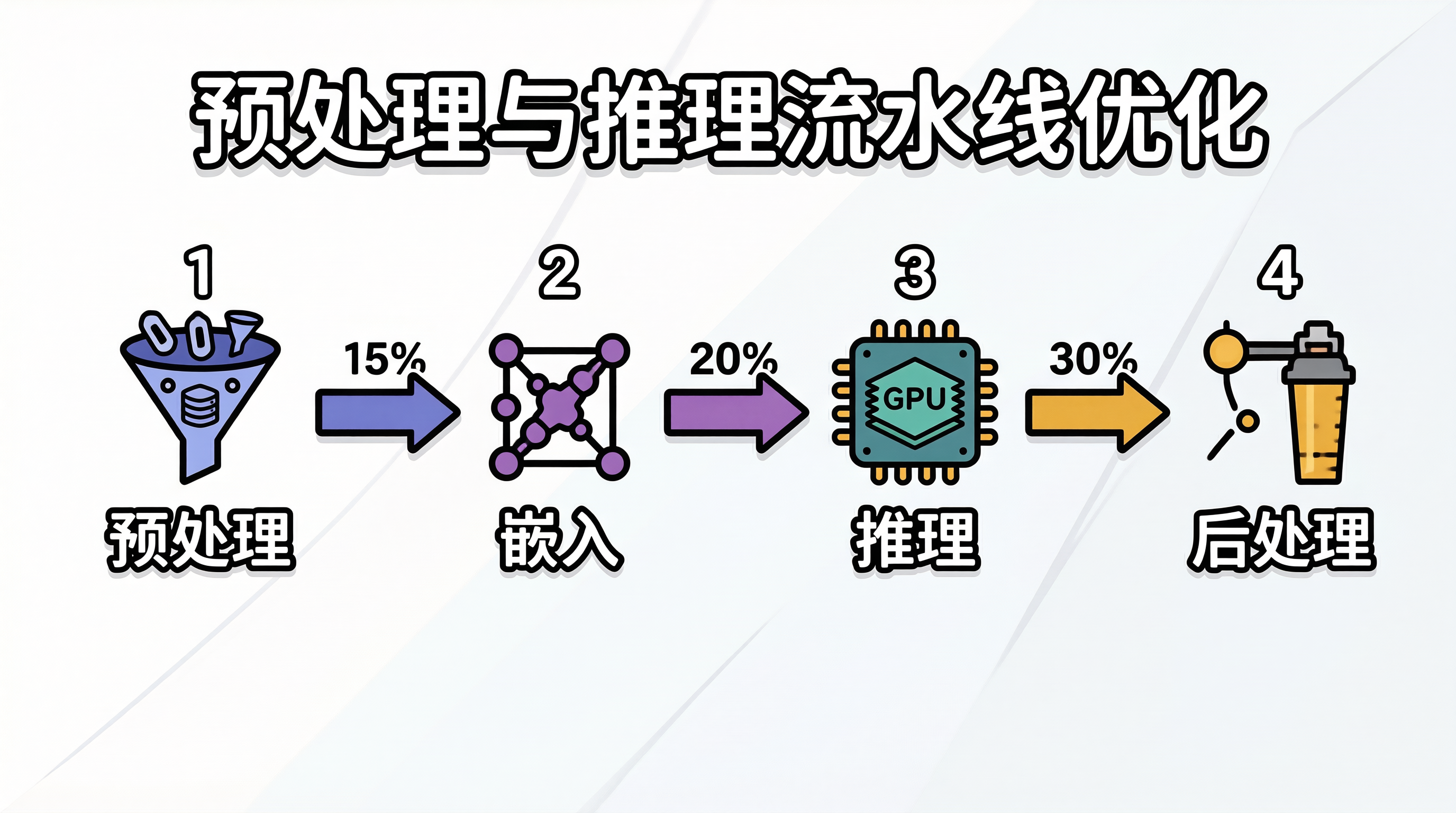
一、AI 推理流水线的全链路瓶颈
在 AI 推理服务的性能分析中,一个常见的盲区是:只关注模型推理本身的延迟,而忽略了数据预处理和后处理的开销。实测数据显示,在一个典型的 RAG 服务中,端到端延迟的分布大约为:数据预处理(Tokenization + Embedding)占 15%~20%,模型推理占 40%~50%,后处理(排序 + 格式化)占 20%~30%,网络传输占 10%~15%。
当模型推理通过量化、批处理等手段优化到极致后,数据预处理和后处理可能成为新的瓶颈。例如,一个经过 INT4 量化的 7B 模型,推理延迟仅 50ms,但 Tokenization 需要 30ms,Embedding 计算需要 40ms——预处理占总延迟的 60%。这种"木桶效应"要求性能优化必须覆盖全链路,而非仅关注模型推理环节。
二、推理流水线的性能模型与瓶颈定位
全链路性能优化的第一步是建立精确的性能模型,量化每个环节的耗时占比。
graph LR
A[请求接收] --> B[数据预处理]
B --> B1[Tokenization: 15~30ms]
B --> B2[Embedding 计算: 20~50ms]
B --> B3[检索与排序: 10~30ms]
B1 --> C[模型推理]
B2 --> C
B3 --> C
C --> C1[Prefill: 20~100ms]
C --> C2[Decode: 50~500ms]
C1 --> D[后处理]
C2 --> D
D --> D1[排序与过滤: 5~20ms]
D --> D2[格式化输出: 2~10ms]
D1 --> E[响应返回]
D2 --> E
style B fill:#ff9999
style C fill:#99ff99
style D fill:#9999ff
瓶颈定位的关键指标是各环节的 P99 延迟和吞吐量。当某个环节的 P99 延迟显著高于均值时,通常意味着存在长尾问题(如缓存未命中、GC 停顿)。
三、全链路优化的工程实现
3.1 异步预处理流水线
import asyncio
import time
from dataclasses import dataclass, field
from typing import Any, Optional
import logging
logger = logging.getLogger(__name__)
@dataclass
class InferenceRequest:
request_id: str
prompt: str
token_ids: Optional[list[int]] = None
embeddings: Optional[list[float]] = None
retrieved_docs: Optional[list[dict]] = None
model_output: Optional[str] = None
final_response: Optional[dict] = None
timings: dict[str, float] = field(default_factory=dict)
class AsyncPipeline:
"""异步推理流水线,各阶段并行执行"""
def __init__(self, tokenizer, embedder, retriever, model):
self._tokenizer = tokenizer
self._embedder = embedder
self._retriever = retriever
self._model = model
async def process(self, request: InferenceRequest) -> InferenceRequest:
"""执行完整的推理流水线"""
# 阶段 1: Tokenization 和 Embedding 可以并行
token_task = asyncio.create_task(self._tokenize(request))
embed_task = asyncio.create_task(self._embed(request))
# 等待 Embedding 完成后立即开始检索
await asyncio.gather(token_task, embed_task)
# 阶段 2: 检索(依赖 Embedding 结果)
await self._retrieve(request)
# 阶段 3: 模型推理(依赖 Tokenization 和检索结果)
await self._infer(request)
# 阶段 4: 后处理
await self._postprocess(request)
return request
async def _tokenize(self, request: InferenceRequest) -> None:
start = time.monotonic()
# 在线程池中执行 CPU 密集的 Tokenization
loop = asyncio.get_event_loop()
request.token_ids = await loop.run_in_executor(
None, self._tokenizer.encode, request.prompt
)
request.timings["tokenize_ms"] = (time.monotonic() - start) * 1000
async def _embed(self, request: InferenceRequest) -> None:
start = time.monotonic()
request.embeddings = await self._embedder.embed_async(request.prompt)
request.timings["embed_ms"] = (time.monotonic() - start) * 1000
async def _retrieve(self, request: InferenceRequest) -> None:
start = time.monotonic()
if request.embeddings:
request.retrieved_docs = await self._retriever.search(
request.embeddings, top_k=5
)
request.timings["retrieve_ms"] = (time.monotonic() - start) * 1000
async def _infer(self, request: InferenceRequest) -> None:
start = time.monotonic()
# 构建增强 Prompt
context = ""
if request.retrieved_docs:
context = "\n".join(
doc["content"] for doc in request.retrieved_docs[:3]
)
augmented_prompt = f"上下文:\n{context}\n\n问题: {request.prompt}"
request.model_output = await self._model.generate_async(augmented_prompt)
request.timings["inference_ms"] = (time.monotonic() - start) * 1000
async def _postprocess(self, request: InferenceRequest) -> None:
start = time.monotonic()
# 过滤低置信度片段、格式化输出
output = request.model_output or ""
request.final_response = {
"answer": output.strip(),
"sources": [
{"title": d.get("title", ""), "score": d.get("score", 0)}
for d in (request.retrieved_docs or [])
if d.get("score", 0) > 0.5
],
"timings_ms": request.timings,
}
request.timings["postprocess_ms"] = (time.monotonic() - start) * 1000
3.2 Tokenization 缓存与优化
import hashlib
from functools import lru_cache
class CachedTokenizer:
"""带缓存的 Tokenizer,避免重复编码相同文本"""
def __init__(self, tokenizer, max_cache_size: int = 10000):
self._tokenizer = tokenizer
self._cache: dict[str, list[int]] = {}
self._max_cache_size = max_cache_size
self._hits = 0
self._misses = 0
def encode(self, text: str) -> list[int]:
"""编码文本,命中缓存时直接返回"""
cache_key = self._make_key(text)
if cache_key in self._cache:
self._hits += 1
return self._cache[cache_key]
self._misses += 1
token_ids = self._tokenizer.encode(text)
# 缓存管理:LRU 淘汰
if len(self._cache) >= self._max_cache_size:
oldest_key = next(iter(self._cache))
del self._cache[oldest_key]
self._cache[cache_key] = token_ids
return token_ids
def decode(self, token_ids: list[int]) -> str:
return self._tokenizer.decode(token_ids)
@property
def hit_rate(self) -> float:
total = self._hits + self._misses
return self._hits / total if total > 0 else 0.0
@staticmethod
def _make_key(text: str) -> str:
return hashlib.md5(text.encode()).hexdigest()
class BatchTokenizer:
"""批量 Tokenizer,利用并行化加速大量文本的编码"""
def __init__(self, tokenizer, batch_size: int = 32):
self._tokenizer = tokenizer
self._batch_size = batch_size
def encode_batch(self, texts: list[str]) -> list[list[int]]:
"""批量编码文本,利用 Tokenizer 的原生批处理能力"""
results = []
for i in range(0, len(texts), self._batch_size):
batch = texts[i:i + self._batch_size]
# HuggingFace Tokenizer 支持原生批处理
encoded = self._tokenizer(
batch,
padding=True,
truncation=True,
max_length=2048,
return_tensors=None,
)
results.extend(encoded["input_ids"])
return results
3.3 全链路性能监控
from collections import defaultdict
import statistics
import time
class PipelineProfiler:
"""推理流水线性能分析器"""
def __init__(self, window_size: int = 1000):
self._window_size = window_size
self._timings: dict[str, list[float]] = defaultdict(list)
def record(self, stage: str, duration_ms: float) -> None:
"""记录阶段耗时"""
self._timings[stage].append(duration_ms)
# 滑动窗口
if len(self._timings[stage]) > self._window_size:
self._timings[stage] = self._timings[stage][-self._window_size:]
def get_report(self) -> dict:
"""生成性能报告"""
report = {}
total_p50 = 0.0
for stage, durations in sorted(self._timings.items()):
if not durations:
continue
p50 = statistics.median(durations)
p99 = sorted(durations)[int(len(durations) * 0.99)]
avg = statistics.mean(durations)
total_p50 += p50
report[stage] = {
"p50_ms": round(p50, 2),
"p99_ms": round(p99, 2),
"avg_ms": round(avg, 2),
"pct_of_total": 0, # 稍后计算
}
# 计算各阶段占比
for stage in report:
if total_p50 > 0:
report[stage]["pct_of_total"] = round(
report[stage]["p50_ms"] / total_p50 * 100, 1
)
report["total_p50_ms"] = round(total_p50, 2)
return report
def identify_bottleneck(self) -> Optional[str]:
"""识别当前瓶颈阶段"""
report = self.get_report()
max_pct = 0
bottleneck = None
for stage, metrics in report.items():
if stage == "total_p50_ms":
continue
if metrics["pct_of_total"] > max_pct:
max_pct = metrics["pct_of_total"]
bottleneck = stage
return bottleneck
四、全链路优化的工程权衡
异步并行的复杂度代价:将 Tokenization 和 Embedding 并行化后,代码复杂度显著增加——需要处理任一阶段失败的情况、管理共享状态、确保错误传播正确。在 QPS 低于 100 的场景中,串行处理的简单实现可能更可靠。建议仅在性能基准测试确认预处理是瓶颈时才引入异步并行。
缓存的一致性问题:Tokenization 缓存在 Prompt 模板化场景中效果显著(相似 Prompt 共享前缀),但在自由对话场景中命中率可能低于 10%。缓存还需要考虑 Tokenizer 版本变更后的一致性——模型升级后 Tokenizer 可能改变,旧缓存需要失效。
批处理与延迟的矛盾:Embedding 计算的批处理可以提升 GPU 利用率,但需要等待凑批,增加 TTFT。对于实时对话场景,建议 Embedding 使用 CPU 模型(如 ONNX 优化的 MiniLM)避免 GPU 资源竞争,同时保持低延迟。
监控开销:全链路性能监控本身也有开销——每次记录耗时涉及字典操作和时间戳计算。在高 QPS 场景下,建议使用采样监控(每 100 个请求记录 1 次)而非全量记录。
五、总结
AI 推理服务的性能优化必须覆盖全链路,而非仅关注模型推理。建立精确的性能模型,量化各环节的耗时占比,是定位瓶颈的前提。Tokenization 缓存和异步并行是预处理优化的两大手段,批处理和量化是推理优化的核心策略。在工程落地时,优化的优先级应基于实际瓶颈而非假设——先测量,再优化。全链路性能监控应作为基础设施持续运行,确保优化效果可量化、退化可感知。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)