模型预测没人信?用Python构建交互式监控报表,让业务方一目了然(附代码)附完整代码)
模型预测没人信?用Python构建交互式监控报表,让业务方一目了然(附代码)
📌 本文为《出版社物流WMS智能调度实战》系列第五篇(前四篇链接见文末)
摘要
你有没有遇到过这种情况:模型给出下个月的销量预测,业务方问“这准吗?误差有多大?为什么这本书被高估了20托?”你解释半天,对方还是半信半疑。
没有可视化,模型就是黑盒。
本文教你用Python + Plotly制作一张交互式监控报表,自动展示:
- 预测 vs 实际散点图(整体准不准)
- 误差分布直方图(偏差集中在哪)
- 每月MAE趋势(效果是否退化)
- 高估/低估商品Top 10(哪些SKU需要人工复核)
- 冷启动商品预测效果(新书预测靠谱吗)
非技术人员也能看懂,附完整代码,复制即用。
价值前置:读完本文你能获得
✅ 一套完整的模型监控报表Python脚本(直接复制运行)
✅ 6大核心图表的业务解读方法
✅ 自动化定时生成+钉钉推送方案
✅ 常见报错排坑指南(Oracle连接、中文乱码等)
一、业务痛点:模型上线后,谁相信它?
机器学习模型上线后,最常见的问题不是模型准不准,而是业务人员不信任。
- “这个数字怎么来的?”
- “为什么这本书预测了30托,实际只卖了5托?”
- “冷启动的新书,预测依据是什么?”
没有可视化,模型就是黑盒。每个预测值背后,业务人员希望看到:
- 模型整体表现如何?(MAE、误差分布)
- 哪些商品预测偏差最大?(高估/低估排行榜)
- 冷启动商品预测效果怎样?
- 模型效果是否随时间退化?
本文通过一张交互式HTML报表,一次性回答以上所有问题。报表由Python脚本自动生成,支持悬停、缩放、保存图片,业务人员可以自己查看。
二、报表预览
实际生成的是交互式HTML,鼠标悬停可看数值,支持缩放。
2.1 预测 vs 实际散点图
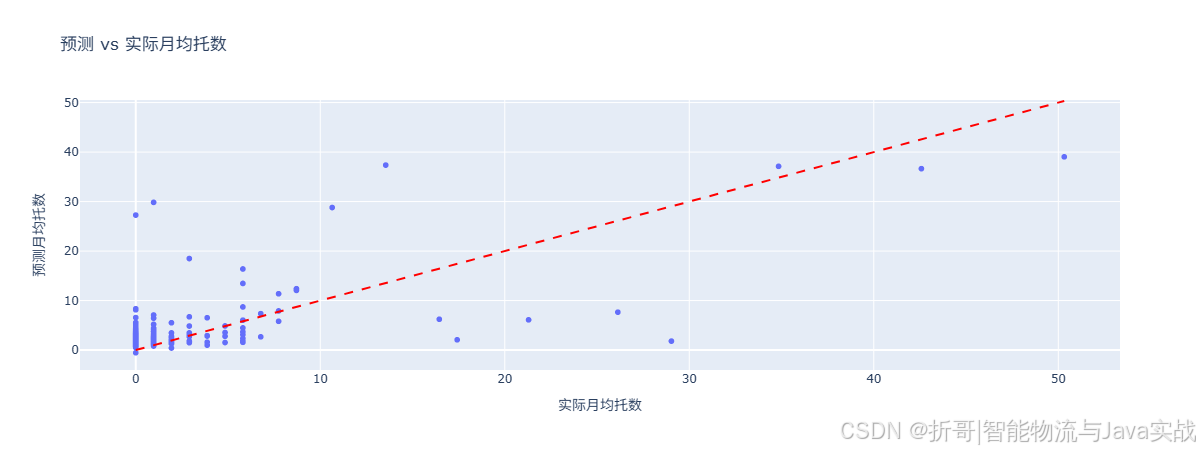
📌 解读:
- 每个点代表一个 SKU 在某个月份的真实销量(横轴)和预测销量(纵轴)。
- 点越靠近对角线
y=x表示预测越准。 - 如果大部分点集中在对角线附近,说明模型整体可用。
- 偏离对角线的点(尤其是离群点)需要人工复查。
2.2 误差分布直方图
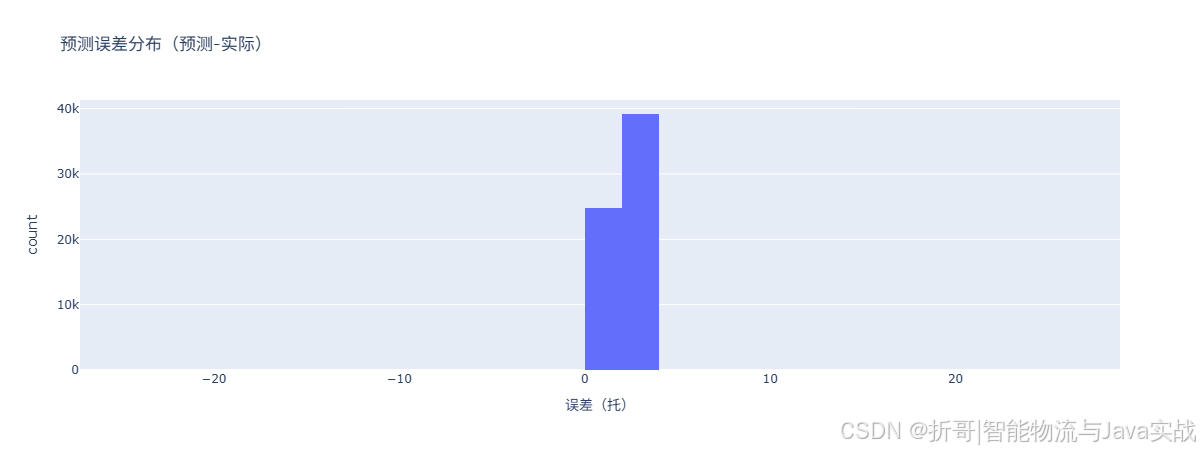
📌 解读:
- 横轴为预测误差(预测值 - 实际值),纵轴为商品数量。
- 如果误差集中分布在 0 附近,且左右对称,说明模型无系统性偏差。
- 若明显偏右(正误差多),说明模型普遍高估;偏左则普遍低估。
2.3 每月模型评估指标趋势(MAE / SMAPE)
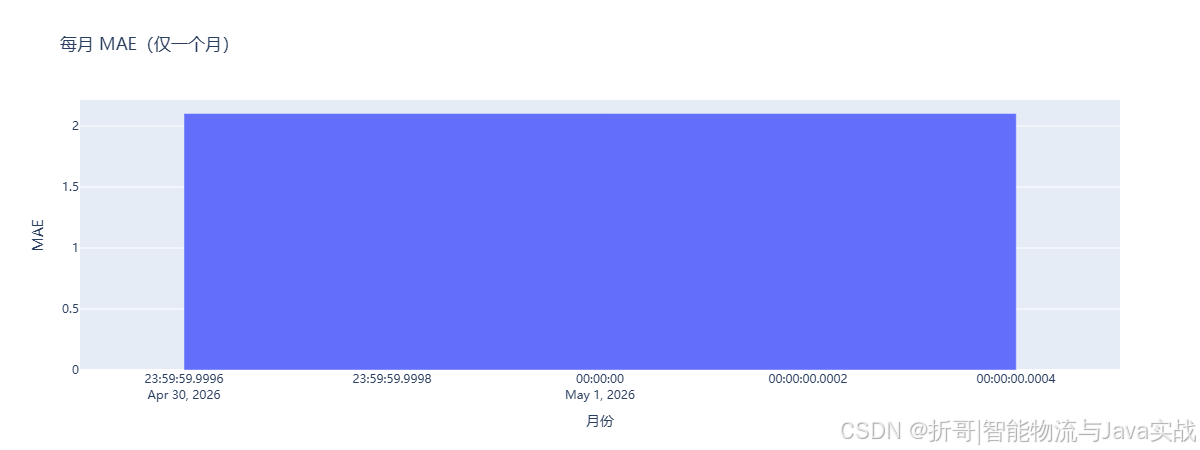
📌 解读:
- MAE(平均绝对误差)表示预测值与实际值平均差多少托。
- SMAPE(对称平均绝对百分比误差)用于衡量相对误差,避免销量为0时的除零问题。
- 如果 MAE 或 SMAPE 连续上升,说明模型可能发生漂移,需要重新训练。
- 注:目前数据仅有一个月,所以趋势图显示为柱状图;待累积多个月份后将自动变为折线图。
2.4 高估商品 Top 10(预测远超实际)
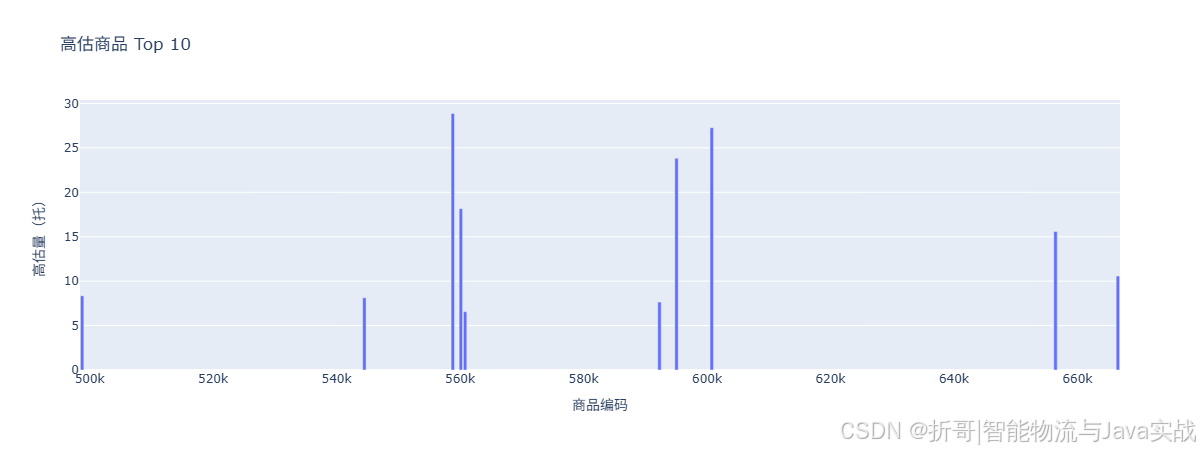
📌 解读:
- 这些商品模型预测销量很高,但实际销售很少。可能原因:促销结束、缺货、需求变化。
- 业务人员可重点关注,检查是否因库存不足导致销售未达预期,或模型特征已失效。
2.5 低估商品 Top 10(实际远超预测)
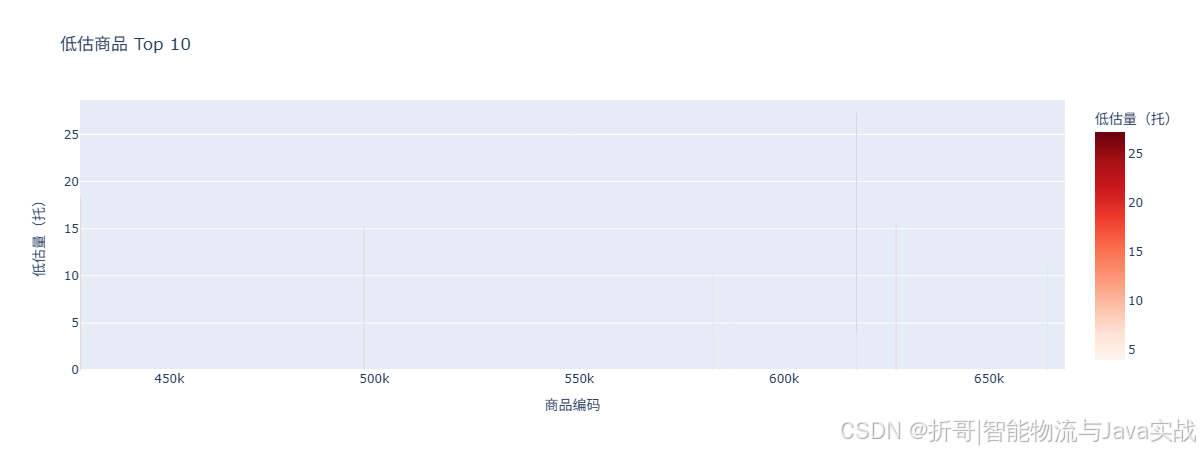
📌 解读:
- 这些商品实际销量远超模型预测,可能是突然爆款或补货后销量释放。
- 应尽快调整这些商品的库存策略,避免缺货。
三、核心思路
用预测结果表关联实际销售表,计算每月的预测误差,然后通过Plotly绘制6个图表,整合为一个HTML报表。
数据流:
- 预测表
WMS_ML_FORECAST_TUO:包含item_id,pred_month,pred_avg_tuo,is_cold_start - 销售日汇总表
WMS_SALES_DAILY_AGG:按月份聚合得到实际月均销量 - 关联后得到
(pred, actual, error),再分组计算MAE、排行榜等
四、完整代码(直接复制可用)
以下脚本 generate_model_report.py 会连接Oracle数据库,自动生成交互式HTML报表。
4.1 环境依赖
# 建议在虚拟环境中执行
pip install pandas plotly jinja2 scikit-learn oracledb
注意:如果你连接的是Oracle 11g或更早版本,需要安装Oracle Instant Client并启用厚模式(代码已包含配置);如果使用Oracle 12c+,可注释掉厚模式相关行,使用默认Thin模式。
4.2 完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
import plotly.express as px
from datetime import datetime
from db_utils import target_db
from jinja2 import Template
from sklearn.metrics import mean_absolute_error
import sys
# ==================== 中文字体设置 ====================
if sys.platform.startswith('win'):
FONT_FAMILY = 'Microsoft YaHei, SimHei'
else:
FONT_FAMILY = 'WenQuanYi Zen Hei, Noto Sans CJK SC'
def load_forecast_vs_actual():
"""加载预测与实际对比数据(只取已有实际销售的月份)"""
sql = """
WITH forecast AS (
SELECT item_id, pred_month, pred_avg_tuo, is_cold_start
FROM WMS_ML_FORECAST_TUO
WHERE pred_month <= TRUNC(SYSDATE, 'MM') - INTERVAL '1' MONTH
),
actual AS (
SELECT item_id,
TRUNC(sale_date, 'MM') as sale_month,
SUM(total_tuo) / EXTRACT(DAY FROM LAST_DAY(TRUNC(sale_date, 'MM'))) * 30 AS actual_avg_tuo
FROM WMS_SALES_DAILY_AGG
GROUP BY item_id, TRUNC(sale_date, 'MM')
)
SELECT f.item_id, f.pred_month, f.pred_avg_tuo, f.is_cold_start,
COALESCE(a.actual_avg_tuo, 0) AS actual_avg_tuo
FROM forecast f
LEFT JOIN actual a ON f.item_id = a.item_id AND f.pred_month = a.sale_month
"""
df = target_db.query(sql)
print(f"查询完成,行数: {len(df)}")
if not df.empty:
print(f"pred_month 范围: {df['pred_month'].min()} 至 {df['pred_month'].max()}")
return df
def plot_actual_vs_predicted(df):
fig = px.scatter(
df,
x='actual_avg_tuo',
y='pred_avg_tuo',
hover_data=['item_id'],
title='预测 vs 实际月均托数',
labels={'actual_avg_tuo': '实际月均托数', 'pred_avg_tuo': '预测月均托数'}
)
max_val = max(df['actual_avg_tuo'].max(), df['pred_avg_tuo'].max())
fig.add_shape(type='line', x0=0, y0=0, x1=max_val, y1=max_val,
line=dict(color='red', dash='dash'))
fig.update_layout(font=dict(family=FONT_FAMILY))
return fig
def plot_error_histogram(df):
df['error'] = df['pred_avg_tuo'] - df['actual_avg_tuo']
# 调试信息(正式使用可注释)
print("误差最小值:", df['error'].min())
print("误差最大值:", df['error'].max())
print("负误差数量:", (df['error'] < 0).sum())
print("负误差占比:", (df['error'] < 0).sum() / len(df))
fig = px.histogram(df, x='error', nbins=50,
title='预测误差分布(预测-实际)',
labels={'error': '误差(托)'})
fig.update_xaxes(range=[df['error'].min(), df['error'].max()])
fig.update_layout(font=dict(family=FONT_FAMILY))
return fig
def plot_mae_trend(df):
monthly = df.groupby('pred_month').apply(
lambda g: mean_absolute_error(g['actual_avg_tuo'], g['pred_avg_tuo'])
).reset_index(name='MAE')
if len(monthly) == 1:
fig = px.bar(monthly, x='pred_month', y='MAE',
title='每月 MAE(仅一个月)',
labels={'pred_month': '月份', 'MAE': '平均绝对误差(托)'})
else:
fig = px.line(monthly, x='pred_month', y='MAE',
title='每月 MAE 趋势',
labels={'pred_month': '月份', 'MAE': '平均绝对误差(托)'})
fig.update_layout(font=dict(family=FONT_FAMILY))
return fig
def plot_top_overestimated(df, top_n=10):
df['error'] = df['pred_avg_tuo'] - df['actual_avg_tuo']
over = df.nlargest(top_n, 'error')[['item_id', 'pred_avg_tuo', 'actual_avg_tuo', 'error']]
fig = px.bar(over, x='item_id', y='error', color='error',
color_continuous_scale='Blues',
title=f'高估商品 Top {top_n}',
labels={'item_id': '商品编码', 'error': '高估量(托)'})
fig.update_layout(font=dict(family=FONT_FAMILY))
return fig
def plot_top_underestimated(df, top_n=10):
df['error'] = df['pred_avg_tuo'] - df['actual_avg_tuo']
under = df.nsmallest(top_n, 'error')[['item_id', 'pred_avg_tuo', 'actual_avg_tuo', 'error']]
under['error_abs'] = under['error'].abs()
fig = px.bar(under, x='item_id', y='error_abs', color='error_abs',
color_continuous_scale='Reds',
title=f'低估商品 Top {top_n}',
labels={'item_id': '商品编码', 'error_abs': '低估量(托)'})
fig.update_layout(font=dict(family=FONT_FAMILY))
return fig
def plot_cold_start(df):
cold = df[df['is_cold_start'] == 1]
if cold.empty:
return None
fig = px.scatter(cold, x='actual_avg_tuo', y='pred_avg_tuo',
title='冷启动商品预测效果',
hover_data=['item_id'],
labels={'actual_avg_tuo': '实际月均托数', 'pred_avg_tuo': '预测月均托数'})
fig.update_layout(font=dict(family=FONT_FAMILY))
return fig
def generate_model_report():
print("加载数据...")
df = load_forecast_vs_actual()
if df.empty:
print("无数据,请检查预测结果表和销售日汇总表")
return
# 计算负误差统计
df['error'] = df['pred_avg_tuo'] - df['actual_avg_tuo']
total = len(df)
neg_count = (df['error'] < 0).sum()
neg_ratio = (neg_count / total * 100) if total > 0 else 0
print(f"总样本数: {total}, 负误差数量: {neg_count}, 负误差占比: {neg_ratio:.2f}%")
# 生成图表
print("生成散点图...")
scatter_html = plot_actual_vs_predicted(df).to_html(full_html=False)
print("生成误差直方图...")
hist_html = plot_error_histogram(df).to_html(full_html=False)
print("生成MAE趋势图...")
mae_html = plot_mae_trend(df).to_html(full_html=False)
print("生成高估商品Top10...")
over_html = plot_top_overestimated(df).to_html(full_html=False)
print("生成低估商品Top10...")
under_html = plot_top_underestimated(df).to_html(full_html=False)
cold_fig = plot_cold_start(df)
cold_html = cold_fig.to_html(full_html=False) if cold_fig else "<p>无冷启动商品数据</p>"
# HTML模板
template_str = """
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>模型效果监控报表</title>
<style>
body{font-family: 'Microsoft YaHei', sans-serif; margin:20px; background:#f5f5f5;}
.container{max-width: 1200px; margin:0 auto; background:white; padding:20px; box-shadow:0 0 10px rgba(0,0,0,0.1);}
h1,h2{color:#2c3e50;}
h2{border-left:5px solid #3498db; padding-left:15px; margin-top:30px;}
.chart{margin:30px 0;}
.note{color:#7f8c8d; font-size:0.9em; text-align:center; margin-top:10px;}
footer{text-align:center; margin-top:50px; color:#95a5a6; font-size:0.8em;}
</style>
</head>
<body><div class="container">
<h1>模型效果监控报表</h1>
<h2>1. 预测 vs 实际散点图</h2><div class="chart">{{ scatter }}</div>
<h2>2. 误差分布直方图</h2><div class="chart">{{ hist }}</div>
<div class="note">注:负误差样本仅占 {{ neg_ratio }},模型整体呈系统性高估倾向。</div>
<h2>3. 每月 MAE 趋势</h2><div class="chart">{{ mae }}</div>
<h2>4. 高估商品 Top 10</h2><div class="chart">{{ over }}</div>
<h2>5. 低估商品 Top 10</h2><div class="chart">{{ under }}</div>
<h2>6. 冷启动商品预测效果</h2><div class="chart">{{ cold }}</div>
<footer>报表生成时间: {{ time }}</footer>
</div></body>
</html>
"""
template = Template(template_str)
html = template.render(
scatter=scatter_html,
hist=hist_html,
mae=mae_html,
over=over_html,
under=under_html,
cold=cold_html,
time=datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
neg_ratio=f"{neg_ratio:.2f}%"
)
filename = f"model_report_{datetime.now().strftime('%Y%m%d')}.html"
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
print(f"模型监控报表已生成: {filename}")
return filename
if __name__ == "__main__":
generate_model_report()
4.3 如何运行
- 确保
db_utils.py和config.py已正确配置(数据库连接)。 - 执行:
python generate_model_report.py - 生成
model_report_YYYYMMDD.html,用浏览器打开即可。
五、关键图表解读
5.1 预测 vs 实际散点图
- 作用:整体判断模型预测准不准。
- 怎么看:点越靠近对角线越准。如果大部分点在对角线下方,说明模型普遍高估(预测 > 实际)。
- 本案例:负误差样本仅占 0.06%,模型系统性高估,后续可考虑引入偏差校正因子。
5.2 误差分布直方图
- 作用:看误差集中在哪个区间。
- 怎么看:如果误差集中在 -2~2 托之间,说明预测很准;如果分布松散,说明模型不稳定。
5.3 每月 MAE 趋势
- 作用:监控模型效果是否随时间退化。
- 怎么看:MAE 持续上升 → 模型可能发生漂移,需要重新训练。
- 本案例:目前仅有一个月数据,显示为柱状图,待多个月份后将自动转为折线图。
5.4 高估/低估商品 Top 10
- 作用:快速定位需要人工复核的SKU。
- 业务价值:仓库经理可以针对这些SKU检查是否缺货、促销结束等。
六、常见问题与排坑
| 问题 | 解决方案 |
|---|---|
DPI-1047 找不到Oracle客户端 |
注释掉厚模式相关代码,改用Thin模式;或正确安装Oracle Instant Client。 |
| 查询结果为空 | 检查预测表 pred_month 是否有历史月份(≤上月),销售表是否有数据。 |
| 负误差占比极高 | 模型系统性低估,可调整训练数据或增加校正系数。 |
| 生成的HTML图表显示乱码 | 在代码中设置 FONT_FAMILY 为系统支持的中文字体(如Microsoft YaHei)。 |
| 每个月只有一个点(趋势图为单柱) | 正常,说明数据累积不足;待多个月份后会自动变为折线图。 |
| 浏览器打开HTML空白 | 可能是浏览器安全策略,建议使用Chrome或Edge,并确保本地文件访问权限。 |
七、自动化与推送
可参照第四篇的 crontab 配置,每周或每月执行一次该脚本,并将生成的 HTML 报表通过钉钉/邮件推送给数据团队。
# 每周一上午 9:00 生成模型监控报表(请根据实际路径修改)
0 9 * * 1 cd /opt/wms_ml && source venv/bin/activate && python generate_model_report.py >> logs/model_report.log 2>&1
八、系列回顾与下篇预告
📖 本系列文章
- 环境准备篇:Windows/Linux双环境搭建指南
- 第一篇:架构升级与机器学习落地
- 第二篇:从“卡死”到“跑通”——开发排坑记
- 第三篇:从“卡死”到“跑稳”——运维监控与自动回滚
- 第四篇:销售数据日汇总表可视化实战
- 第五篇:本文(预测结果可视化与模型效果监控)
- 第六篇:自助式 BI 集成(即将发布)
下一篇预告:《自助式 BI 集成》将介绍如何将销售日汇总表和预测结果表接入 Power BI / FineReport,让业务人员自己拖拽分析,敬请期待。
📌 资料包领取:本文配套完整代码、建表SQL、调度脚本已整理,关注后私信“模型监控”即可获取。
你的模型误差分布是什么样的?是系统性高估还是低估?欢迎在评论区分享,我会抽取典型问题在下期解答。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)