零基础看懂 Transformer!用“抄作业“类比讲透 AI 最重要的一篇论文
**原创声明**:本文为作者原创技术科普文章,所涉及的 Transformer 架构及 Attention Is All You Need 论文均为公开学术成果。文中观点仅代表个人理解,欢迎交流指正。
摘要
2017 年谷歌发布的《Attention Is All You Need》,是 AI 界公认的关键论文。如今爆火的 GPT、文心一言、通义千问等 AI 大模型,底层都基于它提出的 Transformer 架构。
本文不讲难懂的公式,也不用生僻专业词汇,用生活案例、代码示例和常见误区澄清,从零讲透这篇论文的核心思想、解决的问题、核心机制,适合零基础入门学习与技术复盘。
阅读时长:约 15 分钟
代码示例:Python 伪代码(可直接运行理解)
难度等级:⭐⭐(零基础可懂)
关键词:
Attention Transformer 注意力机制 AI 大模型 深度学习入门 NLP 自然语言处理
目录
1. 一、前言:为什么这篇论文被称为 AI 基石?
2. 二、旧版 AI 有多拉胯?带你看懂痛点
3. 三、论文核心创新:注意力机制到底是什么?
4. 四、论文两大核心亮点(小白必懂)
5. 五、补充理解:Q/K/V 到底在干什么?
6. 六、Transformer 整体架构(极简解读)
7. 七、位置编码:并行计算背后的"小补丁"
8. 八、残差连接与层归一化:让模型训练更稳
9. 九、这篇论文到底有多重要?
10. 十、初学者常踩的 5 个坑
11. 十一、全文总结
一、前言:为什么这篇论文被称为 AI 基石?
在 2017 年之前,AI 做翻译、聊天、理解文字,主要依赖 RNN(循环神经网络)这类模型。它们虽然在不断进步,但确实存在一些明显的局限性——处理速度慢、长句容易"遗忘"信息。
直到谷歌 8 位研究者发表了这篇只有 11 页的论文,直接提出了一种全新的架构思路:
人工智能不需要复杂的循环结构、不需要卷积,只需要「注意力」就够了!
这也是论文标题 《Attention Is All You Need》 的真正含义。这篇论文提出的 Transformer 架构,成为了后来几乎所有大语言模型的基石。
一个震撼的事实
GPT 系列(ChatGPT 的底层):基于 Transformer 解码器(Encoder)
BERT 系列(谷歌搜索、文本理解):基于 Transformer 编码器(Decoder)
国内大模型(通义千问、豆包、文心一言):全部沿用该架构核心
Vision Transformer(ViT):将 Transformer 应用于图像识别
AlphaFold 2:利用 Transformer 预测蛋白质三维结构,获 2024 年诺贝尔化学奖
一句话总结:看完这篇论文,你就掌握了理解现代 AI 大模型的钥匙。
二、旧版 AI 有多拉胯?带你看懂痛点
在 Transformer 诞生前,AI 处理文字主要靠 RNN 循环网络。
RNN 就像"逐字抄作业的学生"
必须一个字、一个字按顺序看。看完第一个字,才能看第二个字,绝对不能跳着看、批量看。
这就导致两个明显的缺陷:
1. 速度受限
一整句话只能挨个处理,不能同时运算。句子越长,处理速度越慢,训练模型要耗费大量时间和算力。
2. 长距离信息容易"遗忘"
比如这句话:"小明今天淋雨感冒了,所以他请假回家休息。"
RNN 读到最后"休息"的时候,开头的主语"小明"的信息已经变得很弱了,经常搞混人物、搞错语义,导致翻译和理解准确率下降。
简单总结:旧 AI 的三大痛点
问题 表现 后果
串行处理 必须逐字处理 速度慢,训练时间长
长句易忘 长距离信息丢失 翻译错误、理解偏差
速度受限 无法并行计算 模型难以放大
三、论文核心创新:注意力机制到底是什么?
这篇论文最大的贡献:抛弃了逐步处理的循环结构,全程靠「自注意力机制(Self-Attention)」来理解文本。
用最通俗的话解释注意力机制:
AI 学会了抓重点、找关系,不再逐字读文本。
举个生活化的例子
还是这句话:
"小明今天淋雨感冒了,所以他请假回家休息。"
人类读句子时,会自动找关联:
看到"淋雨" → 自动关联"感冒"(因果关系)
看到"请假" → 自动关联主语"小明"(人物关系)
忽略"今天、所以"这些次要的虚词
注意力机制就是让 AI 拥有类似人类的阅读方式:
不是:挨个读每个字
而是:直接精准抓取句子里的重点字词和前后关联,高效理解整句话的逻辑
注意力机制的核心思想:
每个词都能"看到"句子里的所有其他词,并根据需要自动调整关注度。
比如:
"感冒"会高度关注"淋雨"(因为因果关系强)
"他"会高度关注"小明"(因为指代关系)
"今天"可能关注度较低(因为是次要信息)
四、论文两大核心亮点(小白必懂)
1. 并行计算:从"逐字处理"变"全员同时开工"

实际效果:在处理长文本时,速度可以提升数倍甚至数十倍。这也是现在大模型训练效率大幅提升的核心原因之一。
2. 多头注意力:让 AI 从"多个视角"理解文本
很多初学者觉得"多头注意力(Multi-Head Attention)"很难理解,其实核心思路很简单:
单头注意力:只有一组"视角",只能捕捉一种特征模式
多头注意力:同时用多组"视角"(原论文中是 8 个),每个"头"在不同的子空间中捕捉不同的语言特征
每个头可能关注不同的方面:
头 1:可能关注语法结构(主谓宾关系)
头 2:可能关注语义关联(因果关系、同义词)
头 3:可能关注指代关系("他"指代谁?)
头 4-8:可能关注情感、时态、修饰关系等
最后将所有头的结果合并起来,得到更全面的理解。
生活类比:
就像让 8 个人同时读同一篇文章,每个人关注不同的方面(人物、因果、修饰、情感等),最后大家汇报各自的发现,汇总成一个完整的理解。
五、补充理解:Q/K/V 到底在干什么?
如果你再深入一点点,会经常看到 Q、K、V 这三个字母。别怕,它们其实很直觉:
Q / K / V 的通俗解释
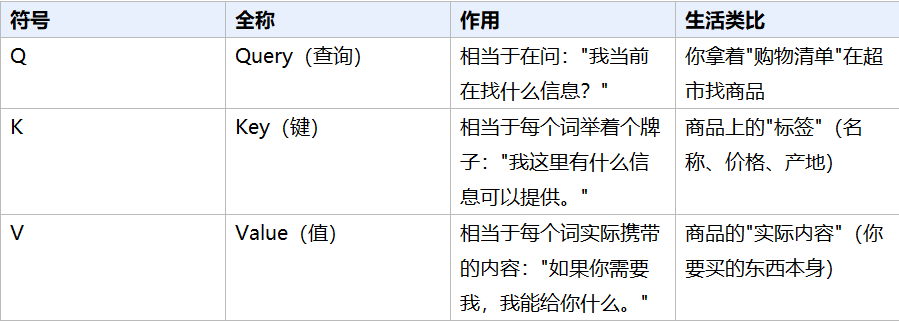
注意力计算过程(三步)
本质上就是:拿当前的 Q 去和所有词的 K 做匹配(计算相关度),匹配度高的词,就多拿一些它的 V 来用。最终得到一个"加权混合"后的结果——这就是注意力机制的核心逻辑。
生活类比:"超市购物"
1. Q(购物清单):你拿着清单,上面写着"我要买苹果、牛奶"
2. K(商品标签):每个商品都有标签(名称、价格、产地)
3. 匹配过程:你拿清单(Q)去对比每个商品的标签(K),找到最匹配的
4. V(实际商品):匹配成功后,你把商品(V)放进购物车
5. 加权求和:你买了很多苹果(权重高)、只买了一盒牛奶(权重低),最终购物车里的东西就是"加权混合"的结果
代码示例:Q/K/V 注意力计算
import numpy as np
def softmax(x):
"""Softmax 函数:把分数变成概率分布"""
exp_x = np.exp(x - np.max(x)) # 数值稳定技巧
return exp_x / exp_x.sum(axis=-1, keepdims=True)
def attention(Q, K, V):
"""
注意力机制核心计算
参数:
- Q: Query 矩阵,shape = (seq_len, d_k)
- K: Key 矩阵,shape = (seq_len, d_k)
- V: Value 矩阵,shape = (seq_len, d_v)
返回:
- output: 注意力加权后的输出
"""
# Step 1: 计算 Q 和 K 的匹配分数(点积)
scores = Q @ K.T # shape = (seq_len, seq_len)
# Step 2: 缩放(防止点积太大导致 softmax 梯度消失)
d_k = Q.shape[1]
scores = scores / np.sqrt(d_k)
# Step 3: Softmax 归一化,变成概率分布
attn_weights = softmax(scores) # 每一行的和 = 1
# Step 4: 加权求和 V
output = attn_weights @ V
return output, attn_weights
# 示例使用
seq_len = 5 # 句子长度(5 个词)
d_k = 64 # 每个词的向量维度
# 随机初始化 Q、K、V(实际训练中这些是通过神经网络学习的)
Q = np.random.randn(seq_len, d_k)
K = np.random.randn(seq_len, d_k)
V = np.random.randn(seq_len, d_k)
# 计算注意力
output, attn_weights = attention(Q, K, V)
print("注意力权重矩阵(每一行表示一个词对其他所有词的关注度):")
print(attn_weights)
print("\n输出形状:", output.shape)
六、Transformer 整体架构(极简解读)
论文提出的 Transformer 模型,结构非常清晰,由两大核心部分组成:
1. Encoder(编码器):负责"读懂"输入
相当于 AI 的阅读理解模块。负责接收输入的文字,通过多层注意力机制读懂整句话的意思、逻辑和关联。
典型应用场景:
文本分类(这句话是正面还是负面?)
语义理解(这句话的核心意思是什么?)
情感分析(用户是开心还是生气?)
2. Decoder(解码器):负责"生成"输出
相当于 AI 的写作输出模块。基于编码器理解的信息,逐步生成通顺的文字。
典型应用场景:
机器翻译(把中文翻译成英文)
聊天对话(AI 回复你的问题)
文案生成(AI 写广告语、写文章)
核心逻辑
编码器负责理解、解码器负责输出,两者通过注意力机制联动,结构简洁高效。
Transformer 架构示意图
输入文本: "小明今天淋雨感冒了"
↓
[Embedding 层] 把每个词转换成向量
↓
[Positional Encoding] 加上位置信息
↓
┌─────────────────────────────────┐
│ Encoder (6 层) │
│ ┌───────────────────────────┐ │
│ │ Multi-Head Attention │ │
│ │ + Add & Norm │ │
│ │ + Feed Forward Network │ │
│ │ + Add & Norm │ │
│ └───────────────────────────┘ │
└─────────────────────────────────┘
↓
[Encoder 的输出:理解了输入的意思]
↓
┌─────────────────────────────────┐
│ Decoder (6 层) │
│ ┌───────────────────────────┐ │
│ │ Masked Multi-Head Attn │ │
│ │ + Cross Attention │ │
│ │ + Feed Forward Network │ │
│ │ + Add & Norm │ │
│ └───────────────────────────┘ │
└─────────────────────────────────┘
↓
输出文本: "Xiao Ming caught a cold today"
注意:
Encoder有 6 层(原论文设置),每层包含:Multi-Head Attention + 前馈网络
Decoder 也有 6 层,但多了交叉注意力(Cross-Attention)层,用来"看到"Encoder 的输出
实际的大模型(如 GPT-3)可能用 96 层甚至更多!
七、位置编码:并行计算背后的"小补丁"
前面说过,Transformer 的优势之一是并行计算——所有词同时处理。但这也带来了一个问题:
模型天生不知道词的顺序!
为什么这是个问题?
比如下面两句话:
1. "猫吃鱼"
2. "鱼吃猫"
如果没有位置信息,模型会觉得这两句话完全一样(因为都有"猫、吃、鱼"这三个词)。但实际上意思完全相反!
解决方案:位置编码(Positional Encoding)
论文引入了位置编码:给每个位置生成一个独特的向量,加到每个词的表示上。这样模型就能区分"谁在前谁在后"了。
你可以把它理解为:给每个词贴了一个"座位号"标签,让模型知道每个词在句子中的具体位置。
位置编码的公式:
原论文用的是正弦余弦函数来生成位置编码(不是简单的 1, 2, 3...):

为什么用正弦余弦?
可以让模型轻松学会相对位置(比如"第 5 个词"和"第 6 个词"的关系)
可以泛化到比训练时更长的句子(因为正弦余弦是连续的)
八、残差连接与层归一化:让模型训练更稳定
Transformer 的每一层(注意力层和前馈网络层)都搭配了两个重要的"辅助机制":
1. 残差连接(Residual Connection):"抄近道"
简单说就是:每一层的输入会直接加到输出上,这样即使中间层没学到什么有用信息,原始信息也不会丢失。
代码示例:
# 残差连接的实现(极简版)
def residual_block(x, sublayer):
"""
x: 输入
sublayer: 某一层(比如注意力层或前馈网络)
"""
return x + sublayer(x) # 输入直接加到输出上!
为什么这很重要?
如果没有残差连接,深层网络(比如 96 层)会出现梯度消失问题
有了残差连接,梯度可以直接"流"回去,深层网络也能稳定训练
2. 层归一化(Layer Normalization):"标准化"
对每一层的输出做标准化处理,让数值保持在一个合理的范围内,防止训练过程中出现数值爆炸或消失的问题。
这两个机制看似简单,但对于深层网络的稳定训练至关重要。没有它们,Transformer 叠很多层就很难训练好。
九、这篇论文到底有多重要?
一句话概括:它定义了现代 AI 的底层架构范式。
2017 年之后的 AI 世界:
2017 年之前,AI 圈还在争论"RNN 好还是 CNN 好";2017 年之后,几乎所有主流的 AI 大模型都基于这篇论文的 Transformer 架构:

它带来的三大革命
1. 速度革命:并行计算让训练速度提升数倍甚至数十倍
2. 规模革命:深层 Transformer 可以稳定训练,催生了"大模型"(参数从 1 亿 → 1750 亿 → 1.76 万亿)
3. 跨学科革命:Transformer 不仅用于 NLP,还征服了计算机视觉、蛋白质预测、音乐生成等领域
一个震撼的事实
《Attention Is All You Need》只有 11 页,却被引用了 10 万+ 次(截至 2026 年),成为计算机科学领域被引用次数最多的论文之一。
它的影响力,怎么夸张都不为过。
十、初学者常踩的 5 个坑
为了帮你少走弯路,我总结了初学者最容易混淆的 5 个概念:
坑 1:"Attention 就是 Transformer"
错误理解:Attention(注意力机制)和 Transformer 是一回事。
正确理解:Attention是一种机制(计算 Q、K、V 的加权求和)。
Transformer 是一个完整架构(包含 Encoder、Decoder、FFN、残差连接等)
关系:Transformer 使用了Attention,但不只有 Attention
类比:Attention 是"发动机",Transformer 是"整车"。
坑 2:"多头越多越好"
错误理解:多头注意力中,头的数量越多,模型效果越好。
正确理解:
多头数量是一个超参数(原论文用 8 头)
增加头数 = 增加计算成本(8 头比 4 头慢约 2 倍)
不是越多越好:实验表明,8-16 头已经足够,再多收益递减
实践建议:
小模型(几千万参数):用 4-8 头
大模型(几十亿参数):用 32-64 头
坑 3:"Transformer 只能处理文本"
错误理解:Transformer 是 NLP(自然语言处理)专属架构。
正确理解:
Vision Transformer(ViT):把图片切成小块,每个小块当成一个"词",用 Transformer 处理
Audio Transformer:把音频转成频谱图,用 Transformer 处理
Multimodal Transformer:同时处理文字 + 图片
结论:Transformer 是一个通用的序列建模架构,可以处理任何可以表示为"序列"的数据!
坑 4:"位置编码就是 1, 2, 3..."
错误理解:位置编码就是给每个词标上 1, 2, 3, 4...
正确理解:
原论文用的是正弦余弦函数生成位置编码(不是简单的 1, 2, 3)
为什么不用 1, 2, 3?
- 1, 2, 3 是离散的,无法泛化到更长的句子
- 正弦余弦是连续的,可以轻松泛化到比训练时更长的句子
相对位置 vs 绝对位置:正弦余弦编码可以让模型轻松学会相对位置
坑 5:"Self-Attention 和 Attention 是一回事"
错误理解:Self-Attention(自注意力)和 Attention(注意力)是同一个东西。
正确理解:
Attention(交叉注意力):Q 来自一个序列,K/V 来自另一个序列
- 例子:机器翻译中,Decoder 的 Q 去"看"Encoder 的输出(K/V)
Self-Attention(自注意力):Q、K、V 都来自同一个序列
- 例子:Encoder 中,每个词去"看"句子里的所有其他词(包括自己)
关系:Self-Attention 是 Attention 的特例(Q=K=V 来源相同)。
十一、全文总结
让我们回顾一下本文的核心内容:
旧模型 RNN 的三大痛点
逐字排队处理 → 速度慢
长句容易遗忘前文信息 → 翻译错误
无法并行计算 → 模型难以放大
论文核心创新
抛弃循环结构,以注意力机制为核心
让 AI 学会抓重点、找关系、全局思考
两大优势
1. 并行计算:所有词同时处理,速度提升数倍甚至数十倍
2. 多头注意力:从多个视角理解文本,捕捉更丰富的特征
关键组件
Q/K/V:实现注意力计算(Query 查、Key 匹配、Value 取内容)
位置编码:保留词序信息(用正弦余弦函数)
残差连接 + 层归一化:保障深层网络稳定训练
架构核心
Encoder(编码器):负责理解输入
Decoder(解码器):负责生成输出
两者通过交叉注意力**联动
行业地位
《Attention Is All You Need》之所以影响深远,不是因为公式多么复杂,而是因为思想做到了极致的简洁与高效。
它告诉所有人:
人工智能理解语言的核心,就是学会像人一样抓重点、找关联、全局思考。
看懂这篇论文,就掌握了理解现代 AI 大模型的关键基础。希望这篇大白话解读能帮到你!
最后大家可以一起讨论:这些模型是真正的在理解语言结构呢,还是仅仅只是模式匹配?
感谢你耐心读完这篇文章!
如果你觉得这篇文章对你有帮助,欢迎:
👍 **点赞**(让更多人看到)
⭐ **收藏**(方便日后复习)
💬 **评论**(交流疑问、指正错误)
你的每一个互动,都是我继续创作的动力!
版权声明
本文为原创技术科普文章,所涉及的 Transformer 架构及 Attention Is All You Need 论文均为公开学术成果。文中观点仅代表个人理解,欢迎交流指正。
未经授权,禁止转载。如需转载,请联系作者。
—— END ——

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)