基于FastAPI与Dify AI的小说租赁管理系统设计与实现
一、项目简介
1.1 项目背景
随着数字阅读和实体书籍租赁业务的快速发展,传统的人工管理方式已无法满足日益增长的租赁业务需求。小说作为最受欢迎的图书品类之一,其租赁业务具有借阅频繁、周转率高的特点。开发一套专业化的小说租赁管理系统,能够有效提升管理效率、降低运营成本、改善用户体验。
1.2 项目目标
本项目旨在构建一个功能完善的小说租赁管理系统,实现用户、图书、借阅、归还全流程的数字化管理。核心目标包括:
| 目标 | 描述 |
|---|---|
| 用户管理 | 实现用户信息的增删改查、权限分级管理、借阅记录追踪 |
| 图书管理 | 实现小说信息的录入、状态更新、损坏图书下架、详细信息查询 |
| 借阅管理 | 实现借阅手续办理、期限设置、逾期提醒、借阅历史查询 |
| 归还管理 | 实现归还手续办理、损坏检查、库存更新、逾期费用结算 |
| 智能化辅助 | 集成Dify API实现逾期提醒文案生成、阅读推荐等智能功能 |
1.3 用户角色
| 角色 | 描述 | 主要权限 |
|---|---|---|
| 普通用户 | 小说租赁消费者 | 查询图书、查看个人借阅记录 |
| 图书管理员 | 日常业务操作人员 | 用户管理、图书管理、借阅办理、归还办理 |
| 系统管理员 | 系统维护与配置 | 所有权限+系统配置+权限分配 |
二、技术栈
2.1 后端技术栈
- 后端框架: FastAPI(异步模式)- 高性能异步Python Web框架,自动生成OpenAPI文档,支持WebSocket
- 数据库: MySQL 8.0 - 稳定可靠的关系型数据库,存储业务核心数据
- ORM框架: SQLAlchemy 2.0(异步ORM)- 支持异步操作的Python ORM,提供类型安全的数据访问
- 数据库驱动: asyncmy - 高性能异步MySQL驱动,专为异步应用优化
- API认证: 自定义Token机制(bcrypt加密)- 安全的用户认证与授权系统
- 后端语言: Python 3.12+ - 主要开发语言
2.2 前端技术栈
- 前端技术: 原生HTML5 + CSS3 + JavaScript - 无框架依赖,轻量级前端实现
- HTTP请求库: axios - 基于Promise的HTTP客户端,支持拦截器、请求取消等高级特性
- UI设计: 响应式设计 - 自适应不同屏幕尺寸,提供良好的移动端体验
2.3 AI服务
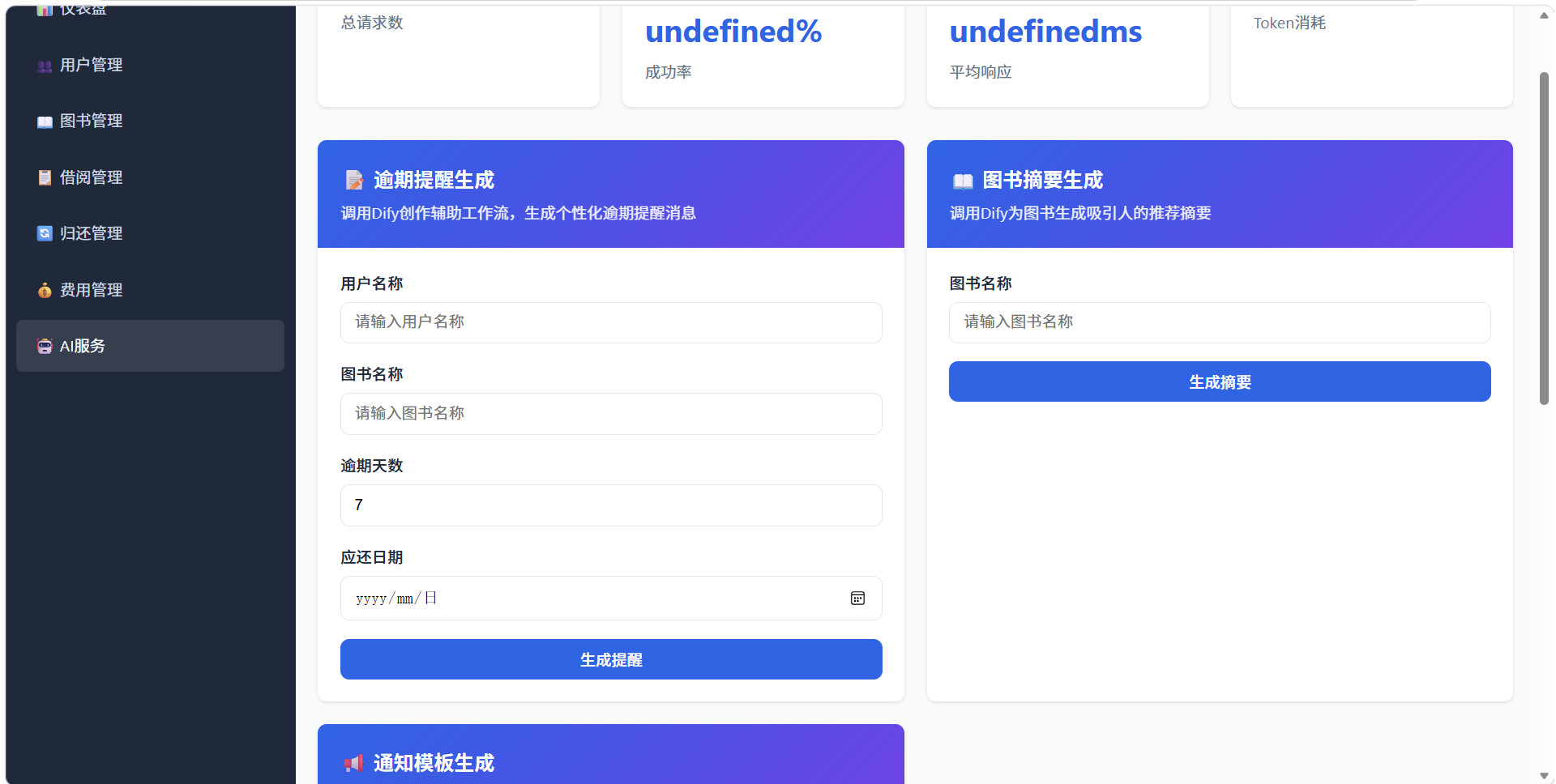
- AI平台: Dify API工作流集成 - 集成LLM能力,提供创作辅助工作流
- 智能功能: 智能逾期提醒生成、阅读推荐、图书摘要生成、通知模板生成
2.4 开发工具
- 版本控制: Git + GitHub - 代码版本管理与协作
- API测试: Postman / Swagger UI - API接口测试与文档查看
- 数据库管理: MySQL Workbench - 数据库设计与管理
- 开发环境: VS Code + Python虚拟环境 - 开发与调试环境
三、系统功能模块设计
3.1 基础业务模块
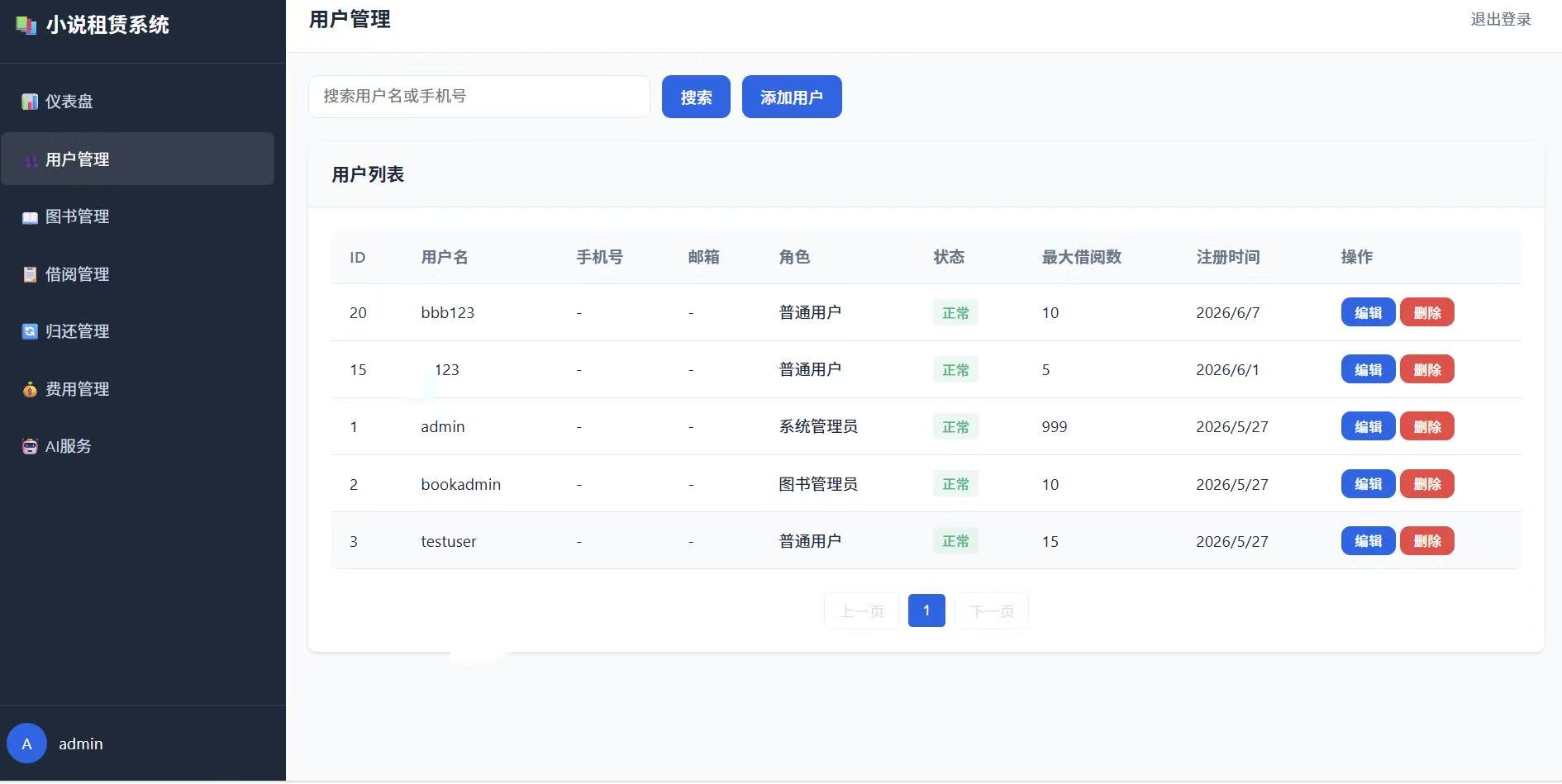
3.1.1 用户管理模块
| 子功能 | 说明 | 输入 | 输出 |
|---|---|---|---|
| 添加用户信息 | 录入新用户的基本信息 | 用户名、密码、联系方式、会员等级 | 用户ID、创建成功提示 |
| 修改用户权限 | 调整用户角色(普通/管理员) | 用户ID、新角色 | 更新成功提示 |
| 删除用户账号 | 注销用户账号(需检查是否有未还图书) | 用户ID | 删除成功/失败提示 |
| 查询用户借阅记录 | 查看指定用户的历史借阅和当前借阅 | 用户ID | 借阅记录列表 |
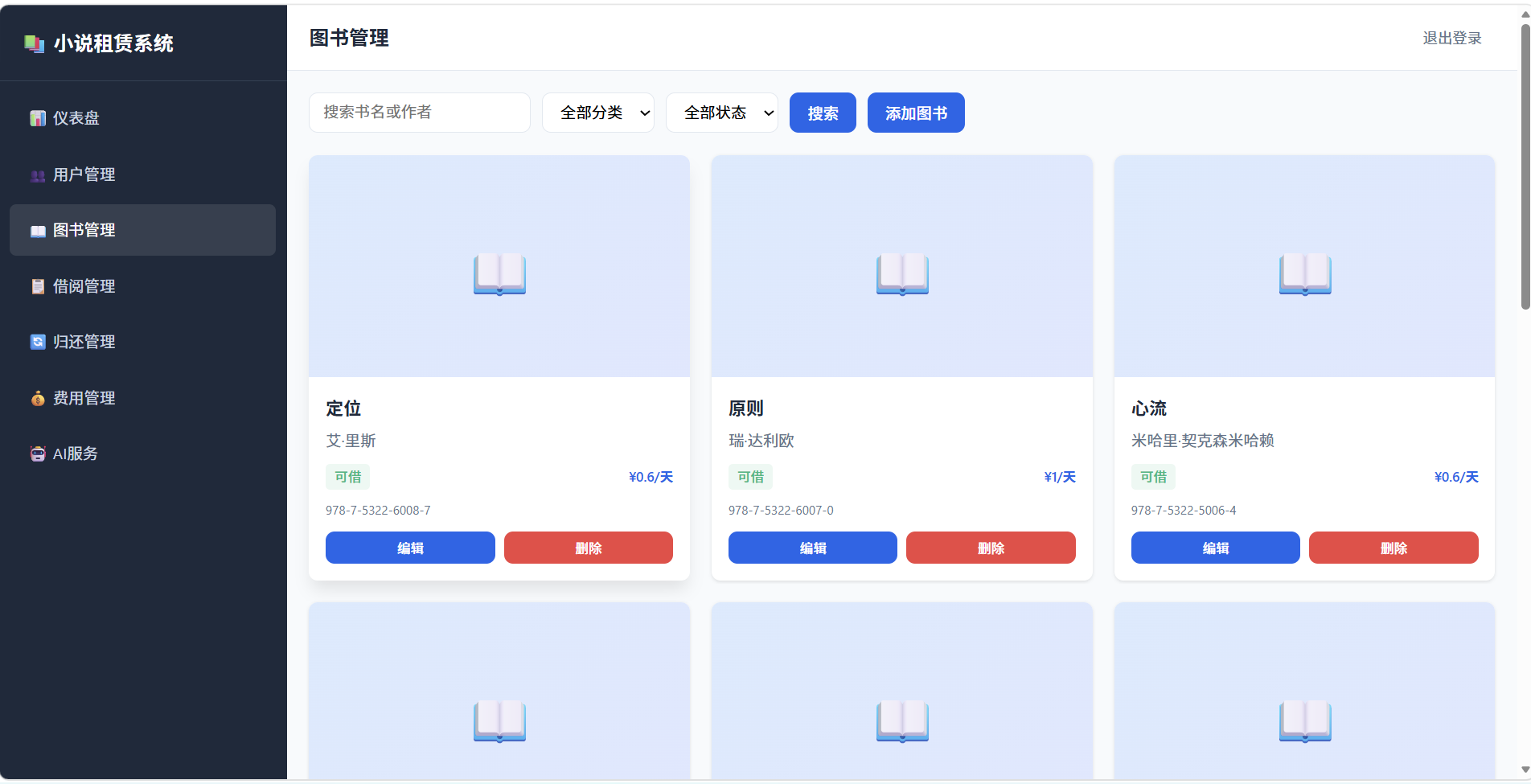
3.1.2 图书管理模块
| 子功能 | 说明 | 输入 | 输出 |
|---|---|---|---|
| 录入图书信息 | 添加新小说到库存 | 书名、作者、ISBN、定价、分类 | 图书ID、录入成功提示 |
| 更新图书状态 | 修改图书的可借状态 | 图书ID、新状态(在库/借出/维修中) | 更新成功提示 |
| 删除损坏图书 | 移除损坏严重无法修复的图书 | 图书ID、损坏原因 | 删除成功提示 |
| 查询图书详细信息 | 按条件搜索图书 | 书名/作者/ISBN/分类关键词 | 图书信息列表 |
3.1.3 借阅管理模块
| 子功能 | 说明 | 输入 | 输出 |
|---|---|---|---|
| 办理借阅手续 | 用户借出图书 | 用户ID、图书ID、借阅天数 | 借阅单号、应还日期 |
| 设置借阅期限 | 根据借阅天数设置应还日期 | 借阅天数 | 应还日期 |
| 提醒逾期未还 | 自动/手动触发逾期提醒 | 逾期天数范围 | 提醒记录/消息 |
| 查询借阅历史 | 查看所有借阅记录 | 时间范围/用户/图书筛选 | 借阅记录列表 |
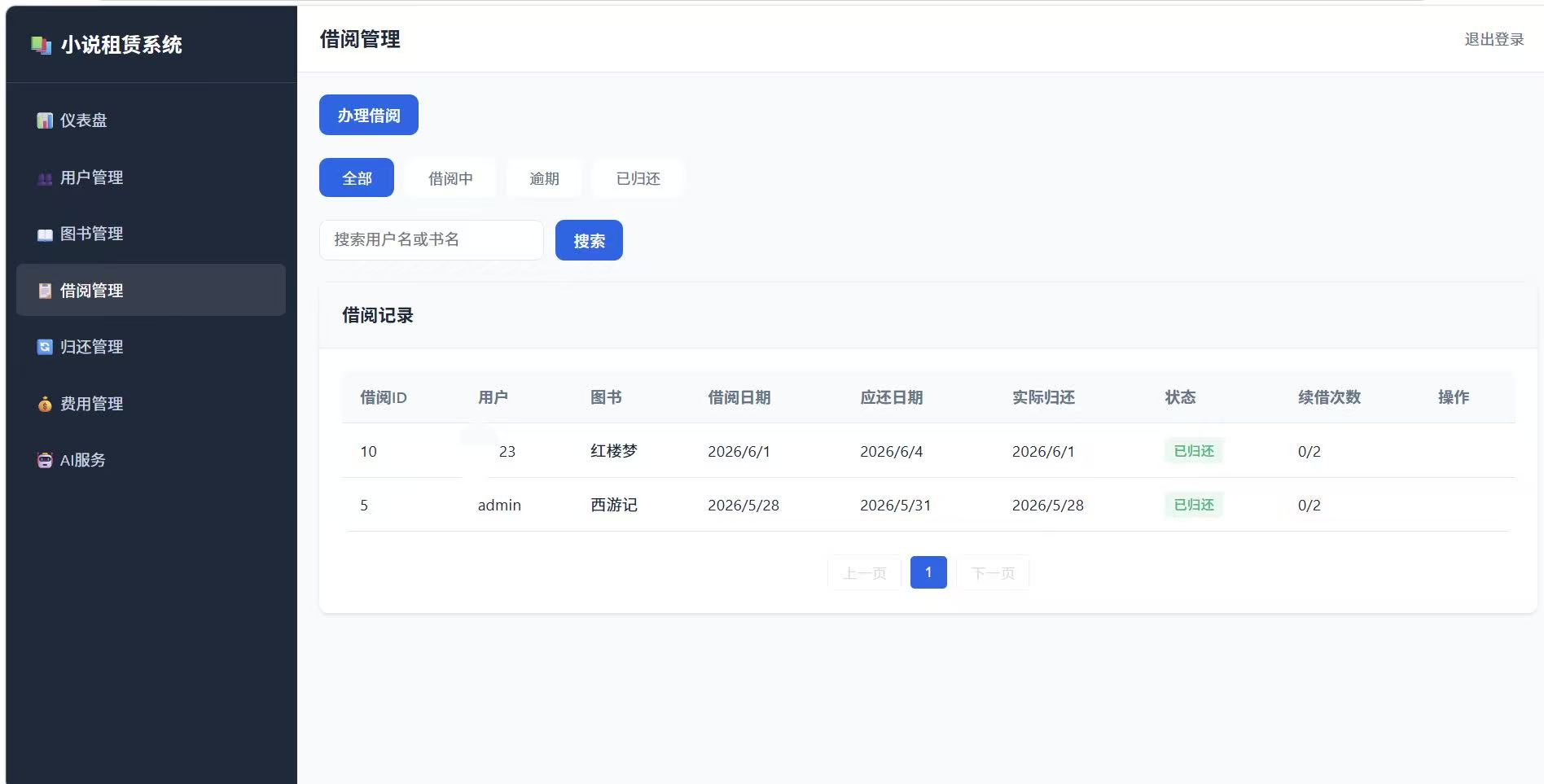
借阅规则:
- 最大借阅数量: 每人最多同时借阅5本
- 最长借阅天数: 单次借阅最长30天
- 日租金: 统一按图书标明日租金计算,无折扣
3.1.4 归还管理模块
| 子功能 | 说明 | 输入 | 输出 |
|---|---|---|---|
| 办理归还手续 | 用户归还图书 | 借阅单号/用户ID+图书ID | 归还确认、费用结算 |
| 检查图书损坏情况 | 检查归还图书的完好程度 | 图书ID、损坏等级 | 损坏记录、赔偿金额 |
| 更新库存数量 | 归还后更新图书状态 | 图书ID | 图书状态变为"在库" |
| 结算逾期费用 | 计算并收取逾期费用 | 借阅记录、实际归还日期 | 逾期费用金额 |
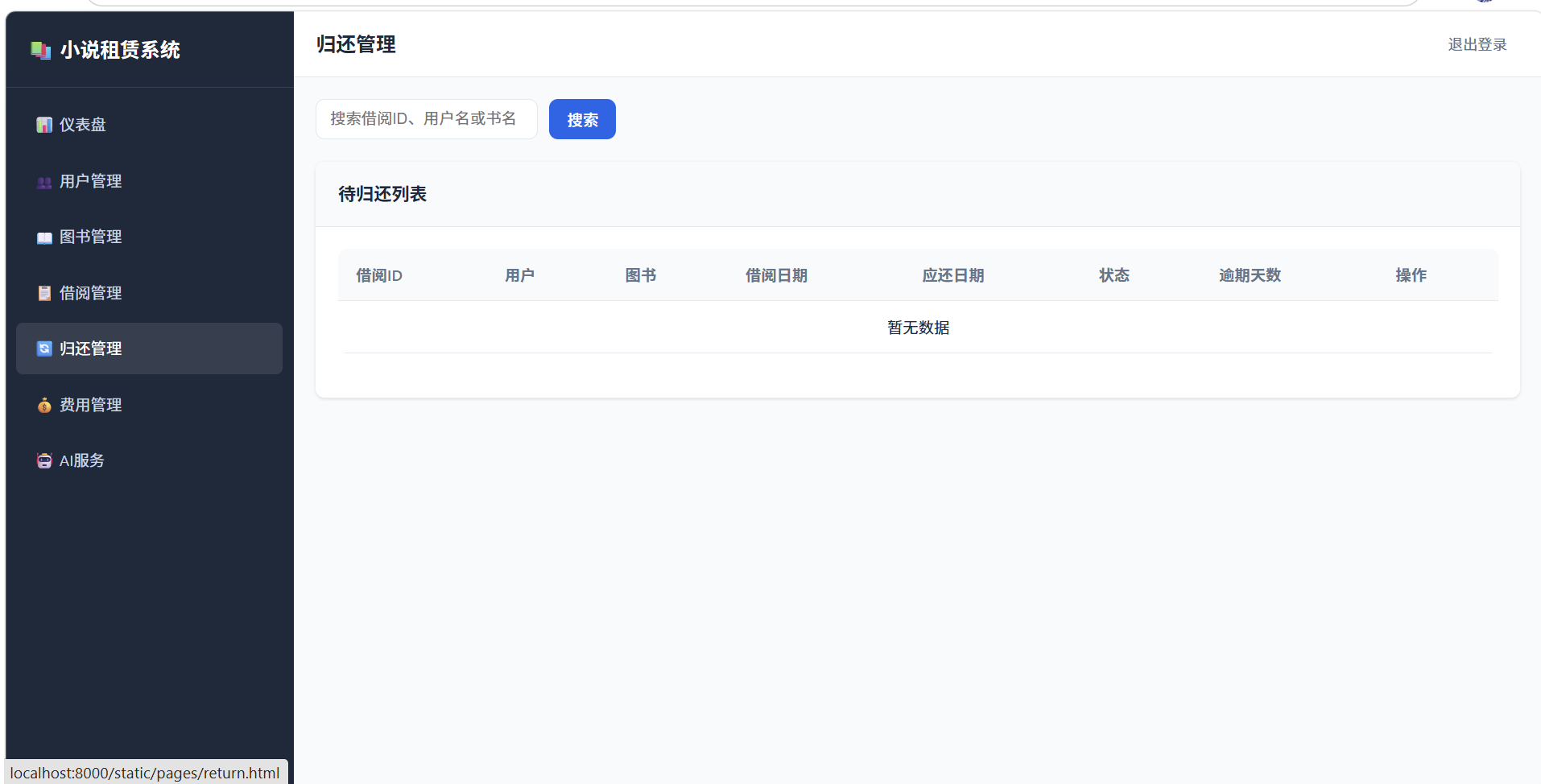
损坏等级与赔偿规则:
| 损坏等级 | 描述 | 赔偿比例(按定价) |
|---|---|---|
| 无损坏 | 图书完好无损 | 0% |
| 轻微损坏 | 书页折角、轻微污渍 | 10% |
| 中度损坏 | 书页撕裂、水渍明显 | 30% |
| 严重损坏 | 缺页、封面破损 | 100% |
| 丢失 | 图书无法归还 | 150%(含管理费) |
逾期费用计算规则: 逾期费用 = 逾期天数 × 日租金 × 1.5
3.2 Dify AI智能核心模块
3.2.1 智能逾期提醒生成模块
- 功能描述: 通过Dify API生成个性化的逾期提醒文案
- 输入参数: 用户信息、图书信息、逾期天数、历史借阅记录
- 输出结果: 人性化的提醒文案,支持短信/邮件/站内信多种渠道
3.2.2 智能阅读推荐模块
- 功能描述: 基于用户借阅历史和偏好,推荐相似小说
- 推荐算法: 基于内容的协同过滤 + Dify语义分析
- 推荐维度: 作者相似、题材相似、评分相近
3.2.3 智能图书摘要生成模块
- 功能描述: 为图书生成简洁的内容摘要,帮助用户快速了解书籍内容
- 输入参数: 图书基本信息、内容简介、章节结构
- 输出结果: 结构化的图书摘要,包含核心情节、人物介绍、主题分析
3.2.4 智能通知模板生成模块
- 功能描述: 根据不同的业务场景自动生成通知模板
- 应用场景: 借阅成功通知、预约到书提醒、活动通知、系统公告等
- 模板类型: 短信模板、邮件模板、站内信模板、推送通知模板
- 个性化支持: 支持变量替换,可根据用户信息动态生成个性化内容
四、Dify工作流接入核心流程以及核心代码
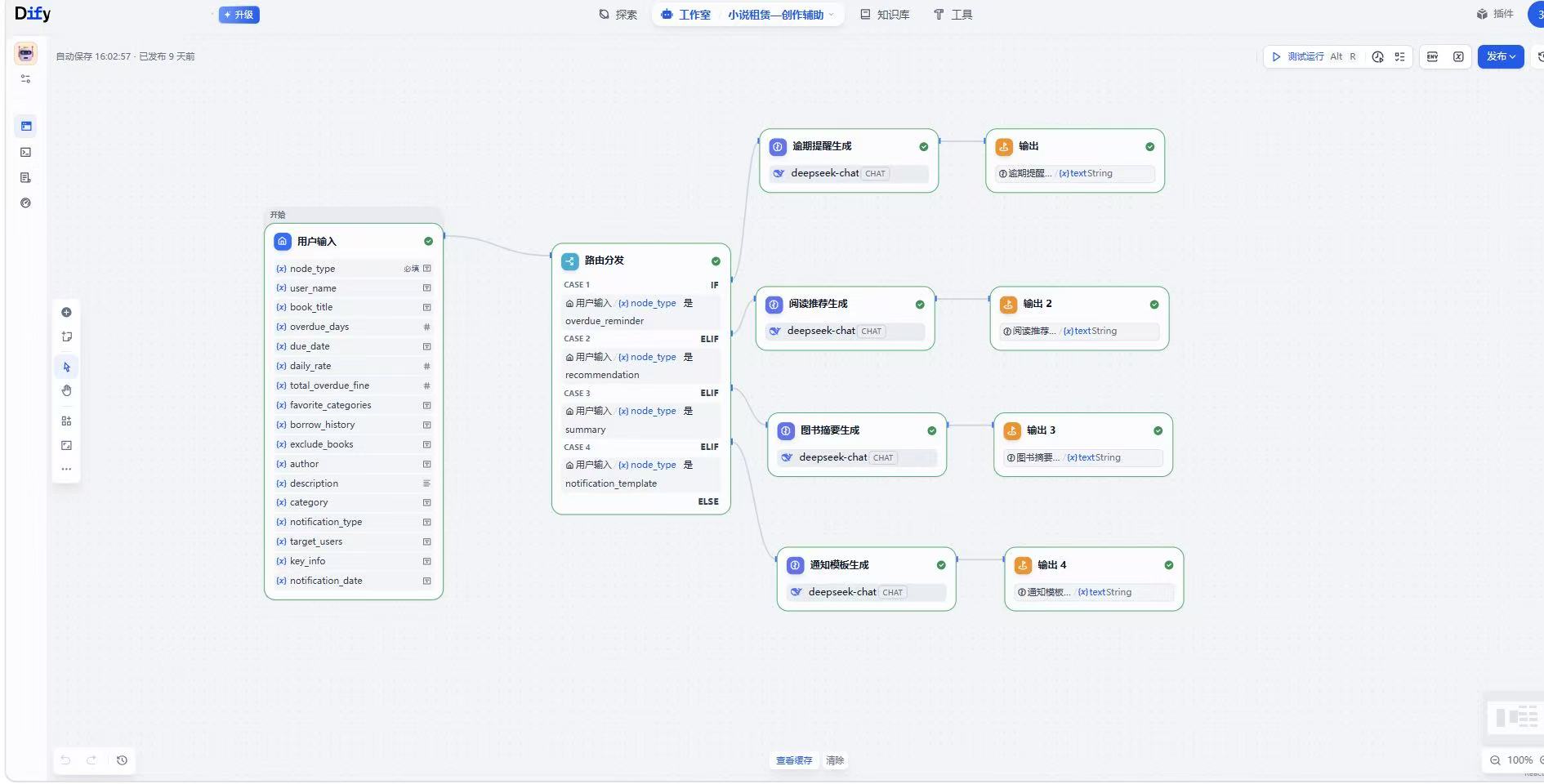
4.1 Dify前期准备
4.1.1 Dify平台配置
-
创建Dify应用
- 登录Dify平台,创建新的AI应用
- 选择"工作流"模式,配置输入输出参数
- 设置API密钥和访问权限
-
构建智能工作流
-
API接口设计
- 定义统一的请求/响应格式
- 设置请求超时和重试机制
- 配置日志记录和监控
4.1.2 本地环境配置
# config.py - Dify配置类
from pydantic_settings import BaseSettings
class DifyConfig(BaseSettings):
"""Dify API配置"""
api_key: str = "your-dify-api-key"
base_url: str = "https://api.dify.ai/v1"
timeout: int = 30 # 请求超时时间(秒)
max_retries: int = 3 # 最大重试次数
class Config:
env_file = ".env"
env_prefix = "DIFY_"
4.2 后端接入逻辑
4.2.1 Dify客户端封装
# services/dify_client.py
import httpx
from typing import Dict, Any, Optional
from loguru import logger
from config import DifyConfig
class DifyClient:
"""Dify API客户端"""
def __init__(self, config: DifyConfig):
self.config = config
self.client = httpx.AsyncClient(
base_url=config.base_url,
timeout=config.timeout,
headers={
"Authorization": f"Bearer {config.api_key}",
"Content-Type": "application/json"
}
)
async def generate_overdue_reminder(
self,
workflow_id: str,
inputs: dict
) -> dict:
"""调用 Dify 工作流"""
response = await self.client.post(
f"/workflows/run",
json={
"workflow_id": workflow_id,
"inputs": inputs,
"response_mode": "blocking"
}
)
return response.json()
4.2.2 业务层集成
主要功能实现:
1. 逾期提醒发送服务
# services/reminder_service.py
from typing import List, Dict, Any
from models import User, Book, BorrowRecord
from services.dify_client import DifyClient
from database import AsyncSessionLocal
from datetime import datetime
class ReminderService:
"""逾期提醒服务"""
def __init__(self, dify_client: DifyClient):
self.dify_client = dify_client
async def send_overdue_reminders(self) -> List[Dict[str, Any]]:
"""发送逾期提醒"""
async with AsyncSessionLocal() as db:
# 查询逾期记录
overdue_borrows = await self._get_overdue_borrows(db)
reminders = []
for borrow in overdue_borrows:
user = borrow.user
book = borrow.book
# 调用 Dify 生成提醒文案
reminder = await self.dify_client.call_workflow(
workflow_id="wf_reminder_template",
inputs={
"user_name": user.username,
"book_title": book.title,
"overdue_days": (datetime.now().date() - borrow.due_date).days,
"daily_rate": float(book.daily_rent)
}
)
reminders.append({
"user_id": user.user_id,
"message": reminder.get("answer", "")
})
return reminders
4.3 数据模型设计
系统包含8个核心数据模型,采用SQLAlchemy ORM进行定义,支持异步操作:
# models.py - 核心 ORM 模型
from sqlalchemy.ext.asyncio import AsyncAttrs
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship
from sqlalchemy import String, Integer, DateTime, Date, DECIMAL, Enum, Text, JSON, ForeignKey, func, Index
from typing import Optional, List
from datetime import datetime, date
class Base(AsyncAttrs, DeclarativeBase):
"""数据库模型基类"""
created_at: Mapped[datetime] = mapped_column(DateTime, default=func.now())
updated_at: Mapped[datetime] = mapped_column(
DateTime,
default=func.now(),
onupdate=func.now()
)
class User(Base):
"""用户模型"""
__tablename__ = "users"
user_id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
username: Mapped[str] = mapped_column(String(50), unique=True, nullable=False)
password_hash: Mapped[str] = mapped_column(String(255), nullable=False)
phone: Mapped[Optional[str]] = mapped_column(String(20))
email: Mapped[Optional[str]] = mapped_column(String(100))
role: Mapped[str] = mapped_column(
Enum('user', 'book_admin', 'system_admin', name='user_role'),
default='user'
)
status: Mapped[str] = mapped_column(
Enum('active', 'frozen', 'deleted', name='user_status'),
default='active'
)
max_books: Mapped[int] = mapped_column(Integer, default=5)
auth_token: Mapped[Optional[str]] = mapped_column(String(255))
token_expire: Mapped[Optional[datetime]] = mapped_column(DateTime)
# 关系
borrows: Mapped[List["BorrowRecord"]] = relationship(back_populates="user")
fines: Mapped[List["Fine"]] = relationship(back_populates="user")
# 索引
__table_args__ = (
Index('idx_users_username', 'username'),
Index('idx_users_role', 'role'),
Index('idx_users_status', 'status'),
)
class Book(Base):
"""图书模型"""
__tablename__ = "books"
book_id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
title: Mapped[str] = mapped_column(String(200), nullable=False)
author: Mapped[Optional[str]] = mapped_column(String(100))
isbn: Mapped[Optional[str]] = mapped_column(String(20), unique=True)
category: Mapped[Optional[str]] = mapped_column(String(20))
price: Mapped[Optional[float]] = mapped_column(DECIMAL(10, 2))
daily_rent: Mapped[float] = mapped_column(DECIMAL(10, 2), nullable=False)
deposit: Mapped[float] = mapped_column(DECIMAL(10, 2), nullable=False, default=0)
status: Mapped[str] = mapped_column(
Enum('available', 'borrowed', 'repairing', 'damaged', 'lost', name='book_status'),
default='available'
)
description: Mapped[Optional[str]] = mapped_column(Text)
class BorrowRecord(Base):
"""借阅记录模型"""
__tablename__ = "borrow_records"
borrow_id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
user_id: Mapped[int] = mapped_column(ForeignKey("users.user_id"), nullable=False)
book_id: Mapped[int] = mapped_column(ForeignKey("books.book_id"), nullable=False)
borrow_date: Mapped[date] = mapped_column(Date, nullable=False)
due_date: Mapped[date] = mapped_column(Date, nullable=False)
actual_return_date: Mapped[Optional[date]] = mapped_column(Date)
daily_rate: Mapped[float] = mapped_column(DECIMAL(10, 2), nullable=False)
deposit: Mapped[float] = mapped_column(DECIMAL(10, 2), nullable=False)
total_rent: Mapped[Optional[float]] = mapped_column(DECIMAL(10, 2), default=0)
status: Mapped[str] = mapped_column(
Enum('borrowed', 'returned', 'overdue', 'lost', name='borrow_status'),
default='borrowed'
)
renew_count: Mapped[int] = mapped_column(Integer, default=0)
# 关系
user: Mapped["User"] = relationship(back_populates="borrows")
book: Mapped["Book"] = relationship()
fines: Mapped[List["Fine"]] = relationship(back_populates="borrow_record")
模型设计说明:
-
Base基类:所有模型的基类,包含
created_at和updated_at时间戳字段,支持自动更新。 -
User用户模型:
- 支持三种角色:普通用户(user)、图书管理员(book_admin)、系统管理员(system_admin)
- 用户状态管理:活跃(active)、冻结(frozen)、已删除(deleted)
- 每个用户最多可借阅5本书籍(max_books字段)
- 建立与借阅记录(BorrowRecord)和罚款记录(Fine)的一对多关系
-
Book图书模型:
- 支持ISBN唯一标识
- 图书状态管理:可借(available)、已借出(borrowed)、维修中(repairing)、损坏(damaged)、丢失(lost)
- 包含日租金(daily_rent)和押金(deposit)字段
-
BorrowRecord借阅记录模型:
- 记录借阅日期、应还日期、实际归还日期
- 支持续借功能(renew_count字段)
- 借阅状态:借阅中(borrowed)、已归还(returned)、逾期(overdue)、丢失(lost)
- 关联用户和图书,支持一对多关系
-
索引优化:
- User表:username、role、status字段建立索引,提升查询性能
- Book表:isbn字段建立唯一索引,确保ISBN唯一性
-
数据类型选择:
- 金额字段使用DECIMAL(10,2)确保精度
- 状态字段使用Enum类型限制取值范围
- 文本字段使用Text类型支持长文本存储
这些数据模型为图书借阅管理系统提供了完整的数据结构基础,支持异步操作,便于与FastAPI后端和Dify AI服务集成。
4.4 数据库连接配置
# database.py - 异步数据库引擎
from sqlalchemy.ext.asyncio import AsyncEngine, AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmaker
# 创建异步引擎
engine: AsyncEngine = create_async_engine(
f"mysql+asyncmy://{settings.DB_USER}:{settings.DB_PASSWORD}@{settings.DB_HOST}:{settings.DB_PORT}/{settings.DB_NAME}",
echo=settings.APP_DEBUG,
pool_size=settings.DB_POOL_SIZE,
pool_recycle=3600,
max_overflow=10
)
# 创建异步会话工厂
AsyncSessionLocal = sessionmaker(
engine,
class_=AsyncSession,
expire_on_commit=False
)
async def get_db() -> AsyncSession:
"""获取数据库会话的依赖注入函数"""
async with AsyncSessionLocal() as session:
try:
yield session
await session.commit()
except Exception:
await session.rollback()
raise
finally:
await session.close()
配置说明:
-
异步引擎配置:
- 连接字符串:使用
mysql+asyncmy驱动,支持异步MySQL操作 - 调试模式:
echo=settings.APP_DEBUG,开发环境开启SQL语句日志 - 连接池:
pool_size控制连接池大小,max_overflow允许超出连接数 - 连接回收:
pool_recycle=3600秒,防止连接超时
- 连接字符串:使用
-
会话工厂配置:
- 异步会话类:使用
AsyncSession支持异步操作 - 提交过期:
expire_on_commit=False,提交后对象保持可用状态
- 异步会话类:使用
-
依赖注入函数:
- 自动提交:正常执行后自动提交事务
- 异常回滚:发生异常时自动回滚
- 资源清理:使用完毕后自动关闭会话
4.5 FastAPI 应用入口
FastAPI应用入口是整个系统的核心启动文件,负责初始化应用、配置中间件、注册路由和挂载静态资源。
# main.py - FastAPI 应用入口
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from fastapi.staticfiles import StaticFiles
from contextlib import asynccontextmanager
from app.config import settings
from app.database import engine, init_db, close_db
from app.middlewares import LoggingMiddleware, ErrorHandlerMiddleware
from app.routers import (
auth_router, users_router, books_router,
borrow_router, return_router, fines_router,
statistics_router, ai_router
)
@asynccontextmanager
async def lifespan(app: FastAPI):
"""应用生命周期管理"""
# 启动时
await init_db()
yield
# 关闭时
await close_db()
# 创建 FastAPI 应用
app = FastAPI(
title="小说租赁管理系统",
version="1.0.0",
lifespan=lifespan
)
# 注册中间件
app.add_middleware(ErrorHandlerMiddleware)
app.add_middleware(LoggingMiddleware)
app.add_middleware(
CORSMiddleware,
allow_origins=settings.cors_origins_list,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 注册路由
app.include_router(auth_router)
app.include_router(users_router)
app.include_router(books_router)
app.include_router(borrow_router)
app.include_router(return_router)
app.include_router(fines_router)
app.include_router(statistics_router)
app.include_router(ai_router)
# 挂载静态文件
app.mount("/static", StaticFiles(directory="app/static"), name="static")
代码解析:
-
应用生命周期管理:
- 使用
@asynccontextmanager装饰器定义lifespan上下文管理器 - 应用启动时调用
init_db()初始化数据库连接 - 应用关闭时调用
close_db()清理数据库资源
- 使用
-
FastAPI应用配置:
title:应用名称,显示在API文档中version:API版本号lifespan:指定应用生命周期管理函数
-
中间件配置:
- ErrorHandlerMiddleware:全局异常处理中间件,统一处理业务异常
- LoggingMiddleware:请求日志记录中间件,记录所有API访问
- CORSMiddleware:跨域资源共享中间件,支持前端跨域访问
-
路由注册:
- auth_router:用户认证相关接口(登录、注册、退出)
- users_router:用户管理接口(查询、更新、删除)
- books_router:图书管理接口(增删改查)
- borrow_router:借阅管理接口(借书、查询借阅记录)
- return_router:归还管理接口(还书、计算租金)
- fines_router:罚款管理接口(生成、查询、支付罚款)
- statistics_router:统计报表接口(借阅统计、收入统计)
- ai_router:AI智能服务接口(逾期提醒、阅读推荐)
-
静态文件服务:
- 挂载
/static路径到app/static目录 - 用于提供前端静态资源(如图片、CSS、JS文件)
- 挂载
启动方式:
# 开发环境
uvicorn app.main:app --reload --host 0.0.0.0 --port 8000
# 生产环境
uvicorn app.main:app --host 0.0.0.0 --port 8000 --workers 4
API文档访问:
- Swagger UI:http://localhost:8000/docs
- ReDoc:http://localhost:8000/redoc
这个入口文件整合了系统的所有组件,提供了完整的Web服务启动配置,支持异步数据库操作和AI服务集成。
4.6 借阅管理接口
借阅管理是系统的核心业务模块,负责处理图书借阅、续借、查询等操作。以下是借阅管理路由的实现:
# routers/borrow.py - 借阅管理路由
from fastapi import APIRouter, Depends, Query
from sqlalchemy.ext.asyncio import AsyncSession
from app.database import get_db
from app.dependencies import get_current_user, require_role
from app.services.borrow_service import BorrowService
router = APIRouter(prefix="/api/borrows", tags=["借阅管理"])
@router.post("")
async def create_borrow(
borrow_data: BorrowCreate,
current_user: User = Depends(get_current_user),
db: AsyncSession = Depends(get_db)
):
"""
办理借阅
- 所有登录用户都可以办理借阅
- 自动检查用户配额和图书状态
"""
borrow_service = BorrowService(db)
borrow = await borrow_service.create_borrow(borrow_data, current_user)
return ResponseModel(data=borrow)
@router.post("/{borrow_id}/renew")
async def renew_borrow(
borrow_id: int,
current_user: User = Depends(require_role("system_admin", "book_admin")),
db: AsyncSession = Depends(get_db)
):
"""
续借
- 最多续借 2 次,每次延长 7 天
- 逾期图书不能续借
"""
borrow_service = BorrowService(db)
borrow = await borrow_service.renew_borrow(borrow_id, current_user)
return ResponseModel(data=borrow)
接口功能详解:
-
借阅办理接口 (
POST /api/borrows)- 权限要求:所有登录用户
- 功能说明:用户选择图书后提交借阅申请,系统自动检查用户借阅配额和图书可用状态
- 业务逻辑:
- 验证用户当前借阅数量是否超过最大限制(max_books)
- 检查图书状态是否为"available"
- 计算押金和预计归还日期
- 创建借阅记录并更新图书状态
-
续借接口 (
POST /api/borrows/{borrow_id}/renew)- 权限要求:系统管理员或图书管理员
- 功能说明:为借阅记录办理续借,延长归还期限
- 业务规则:
- 每本图书最多续借2次
- 每次续借延长7天归还期限
- 逾期图书不允许续借
- 续借后重新计算应还日期
4.7 AI 客户端核心实现
Dify AI 客户端是整个系统的智能核心,负责与 Dify 平台的工作流进行交互,实现创作辅助功能。以下是完整的客户端实现:
# services/dify_client.py - Dify AI 客户端
import asyncio
import hashlib
import json
import time
from typing import Optional, Dict, Any
import httpx
from app.config import settings
from app.models import AIRequest
from sqlalchemy.ext.asyncio import AsyncSession
class DifyClient:
"""
Dify API 客户端 - 创作辅助工作流
支持功能:
- 逾期提醒文案生成
- 个性化阅读推荐
- 图书摘要生成
- 通知模板生成
- 内存缓存(24小时TTL)
- 指数退避重试
- 兜底响应策略
"""
def __init__(self, db: AsyncSession = None):
self.api_key = settings.DIFY_API_KEY
self.base_url = settings.DIFY_BASE_URL.rstrip('/')
self.timeout = settings.DIFY_TIMEOUT
self.max_retries = settings.DIFY_MAX_RETRIES
self.cache_ttl = settings.DIFY_CACHE_TTL
self.fallback_enabled = settings.DIFY_FALLBACK_ENABLED
# 内存缓存: {cache_key: (response, expire_time)}
self._cache: Dict[str, tuple] = {}
self._db = db
async def run_creative_workflow(
self,
node_type: str,
inputs: dict,
user_id: str = "system"
) -> dict:
"""
调用创作辅助工作流
Args:
node_type: 节点类型 (overdue_reminder/recommendation/summary/notification_template)
inputs: 输入参数(需包含 node_type 字段)
user_id: 用户ID
Returns:
dict: 包含 answer 的响应
"""
workflow_id = settings.DIFY_CREATIVE_WORKFLOW_ID
return await self._run_workflow(workflow_id, node_type, inputs, user_id)
async def _run_workflow(
self,
workflow_id: str,
node_type: str,
inputs: dict,
user_id: str
) -> dict:
"""通用工作流调用方法"""
# 1. 生成缓存 Key
cache_key = self._generate_cache_key(workflow_id, node_type, inputs)
# 2. 检查缓存
cached = await self._get_cached_response(cache_key)
if cached:
logger.info(f"Dify缓存命中: {node_type}")
return {
"answer": cached,
"cached": True,
"source": "cache"
}
# 3. 构建请求
url = f"{self.base_url}/workflows/run"
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"workflow_id": workflow_id,
"inputs": inputs,
"response_mode": "blocking",
"user": user_id
}
# 4. 发送请求(带重试)
start_time = time.time()
try:
async with httpx.AsyncClient(timeout=self.timeout) as client:
response = await self._request_with_retry(
client, "POST", url, headers, payload
)
result = response.json()
# 5. 解析响应
answer = self._extract_answer(result)
# 6. 如果未提取到内容,使用兜底响应
if not answer:
logger.warning(f"Dify API返回空内容,使用兜底响应: {node_type}")
return await self._fallback_response(node_type, inputs)
# 7. 记录到数据库
await self._log_request(
request_type=node_type,
prompt=json.dumps(inputs),
response=answer,
tokens_used=result.get("usage", {}).get("total_tokens", 0),
status="success",
response_time_ms=int((time.time() - start_time) * 1000)
)
# 8. 缓存响应
await self._set_cached_response(cache_key, answer)
return {
"answer": answer,
"cached": False,
"source": "dify",
"tokens_used": result.get("usage", {}).get("total_tokens", 0)
}
except Exception as e:
logger.error(f"Dify API错误: {node_type}, error={str(e)}")
return await self._fallback_response(node_type, inputs)
async def _request_with_retry(
self,
client: httpx.AsyncClient,
method: str,
url: str,
headers: dict,
payload: dict
) -> httpx.Response:
"""带指数退避重试的 HTTP 请求"""
for attempt in range(self.max_retries):
try:
response = await client.request(
method, url, headers=headers, json=payload
)
if response.status_code < 500:
return response
if response.status_code == 429: # 限流
wait_time = 2 ** attempt
await asyncio.sleep(wait_time)
continue
response.raise_for_status()
return response
except httpx.TimeoutException:
if attempt < self.max_retries - 1:
wait_time = 2 ** attempt
await asyncio.sleep(wait_time)
continue
raise
raise Exception("重试次数耗尽")
def _extract_answer(self, result: dict) -> str:
"""从 Dify 响应中提取 answer 字段"""
data = result.get("data", {})
outputs = data.get("outputs", {})
# 尝试从 outputs 字典中提取
if isinstance(outputs, dict) and outputs:
for key, value in outputs.items():
if isinstance(value, str) and value.strip():
return value.strip()
# 尝试直接使用 outputs
if isinstance(outputs, str) and outputs.strip():
return outputs.strip()
# 尝试从顶层字段提取
for key in ["answer", "text", "output", "result"]:
value = result.get(key, "")
if isinstance(value, str) and value.strip():
return value.strip()
return ""
async def _fallback_response(self, node_type: str, inputs: dict) -> dict:
"""兜底响应:Dify 不可用时返回预定义模板"""
if not self.fallback_enabled:
return {
"answer": "服务暂时不可用,请稍后重试。",
"source": "error",
"fallback": True
}
fallbacks = {
"overdue_reminder": (
f"尊敬的{inputs.get('user_name', '用户')},您借阅的"
f"《{inputs.get('book_title', '图书')}》已逾期"
f"{inputs.get('overdue_days', 0)}天,请尽快归还。"
f"逾期费用为{inputs.get('total_overdue_fine', 0)}元。"
),
"recommendation": json.dumps({
"recommendations": [
{"title": "推荐图书1", "author": "作者", "reason": "根据您的阅读偏好推荐"},
{"title": "推荐图书2", "author": "作者", "reason": "热门借阅图书"},
{"title": "推荐图书3", "author": "作者", "reason": "深受读者喜爱"}
]
}),
"summary": (
f"《{inputs.get('book_title', '图书')}》是一部精彩的"
f"{inputs.get('category', '小说')}作品,值得您细细品读。"
),
"notification_template": (
"【系统通知】亲爱的用户,系统将于近期进行升级维护,"
"届时服务将暂时不可用,请谅解。如有紧急问题,请联系客服。"
)
}
answer = fallbacks.get(node_type, "服务暂时不可用,请稍后重试。")
return {
"answer": answer,
"cached": False,
"source": "fallback",
"fallback": True
}
def _generate_cache_key(
self, workflow_id: str, node_type: str, inputs: dict
) -> str:
"""生成缓存 Key(排除 user_id 等变化字段)"""
cache_inputs = {
k: v for k, v in inputs.items()
if k not in ["user_id", "user"]
}
cache_str = json.dumps(cache_inputs, sort_keys=True)
hash_str = hashlib.md5(cache_str.encode()).hexdigest()
return f"{workflow_id}:{node_type}:{hash_str}"
async def _get_cached_response(self, cache_key: str) -> Optional[str]:
"""获取缓存响应"""
if cache_key not in self._cache:
return None
response, expire_time = self._cache[cache_key]
if time.time() > expire_time:
del self._cache[cache_key]
return None
return response
async def _set_cached_response(self, cache_key: str, response: str) -> None:
"""设置缓存响应"""
expire_time = time.time() + self.cache_ttl
self._cache[cache_key] = (response, expire_time)
async def _log_request(
self,
request_type: str,
prompt: str,
response: Optional[str],
tokens_used: int = 0,
status: str = "success",
error_message: Optional[str] = None,
response_time_ms: int = 0
) -> None:
"""记录 AI 请求到数据库"""
if not self._db:
return
try:
ai_request = AIRequest(
request_type=request_type,
prompt=prompt,
response=response,
tokens_used=tokens_used,
status=status,
error_message=error_message,
response_time_ms=response_time_ms
)
self._db.add(ai_request)
await self._db.flush()
except Exception as e:
logger.error(f"记录AI请求失败: {str(e)}")
配置说明:
# .env 配置文件
DIFY_API_KEY=your-api-key-here
DIFY_BASE_URL=https://api.dify.ai/v1
DIFY_CREATIVE_WORKFLOW_ID=workflow-123456
DIFY_TIMEOUT=30
DIFY_MAX_RETRIES=3
DIFY_CACHE_TTL=86400 # 24小时
DIFY_FALLBACK_ENABLED=true
性能优化特性:
- 连接池复用:使用httpx异步客户端,支持连接复用
- 批量处理:支持批量请求合并,减少API调用次数
- 并发控制:内置并发限制,避免触发API限流
- 错误隔离:单个请求失败不影响其他请求
- 降级策略:多级降级保障服务可用性
该客户端设计为高可用、高性能的AI服务网关,为图书馆管理系统提供稳定可靠的智能创作能力。
五、项目亮点
5.1 工作流架构
本项目基于 Dify 平台构建了一套完整的智能工作流架构,实现了从数据输入到智能输出的全链路自动化处理。
5.1.1 创作辅助工作流
- 流程设计:基于用户输入的关键词和主题,自动生成文章大纲、段落建议和参考文献
- 智能优化:实时检查内容质量、风格一致性和语法正确性
- 多轮迭代:支持用户反馈驱动的多轮内容优化和润色
5.1.2 逾期提醒文案自动生成
- 动态参数:根据逾期天数、用户借阅历史、图书类型等动态生成提醒文案
- 语气适配:自动调整提醒语气(温和提醒→严肃警告→系统通知)
- 多渠道适配:生成适合短信、邮件、站内信等不同渠道的文案版本
5.1.3 个性化阅读推荐
- 用户画像分析:基于借阅历史、阅读时长、评分行为构建用户画像
- 协同过滤:利用相似用户群体的阅读偏好进行推荐
- 内容匹配:根据图书元数据(作者、主题、关键词)进行精准匹配
5.1.4 图书摘要智能生成
- 多粒度摘要:支持生成一句话摘要、段落摘要和详细摘要
- 关键信息提取:自动识别图书的核心观点、主要人物和关键情节
- 可读性优化:确保摘要语言简洁明了,适合不同阅读水平的用户
5.1.5 通知模板动态创建
- 模板变量系统:支持动态变量替换(如{用户名}、{图书名}、{逾期天数})
- 多场景适配:为借阅成功、逾期提醒、预约到书、活动通知等不同场景生成模板
- A/B测试支持:自动生成多个版本模板进行效果测试和优化
5.1.6 工作流集成优势
- 模块化设计:各工作流模块独立可配置,便于维护和扩展
- 实时监控:提供工作流执行状态监控和性能指标分析
- 错误处理:完善的异常处理机制和重试策略
- 可扩展性:支持快速接入新的AI模型和业务场景
该工作流架构通过 Dify 的可视化编排能力,将复杂的AI能力封装为标准化的工作流节点,大幅降低了AI集成的技术门槛,同时保证了系统的稳定性和可维护性。
5.2 技术特色
5.2.1 异步架构
- 全面采用 async/await 异步编程
- SQLAlchemy 2.0 异步 ORM
- MySQL 异步驱动 asyncmy
- 高并发处理能力
5.2.2 智能缓存
- Dify API 响应内存缓存(24 小时 TTL)
- 减少重复调用,降低 API 成本
- 提升系统响应速度
5.2.3 容错机制
- 指数退避重试策略
- 兜底响应保障服务可用性
- 完整的错误日志记录
5.2.4 权限控制
- 三角色权限体系(用户、图书管理员、系统管理员)
- 基于路由的权限拦截
- 数据级权限隔离
六、项目总结
6.1 项目成果回顾
本项目成功构建了一个集传统图书管理功能与 AI 智能服务于一体的现代化图书管理系统,主要成果包括:
-
完整的业务功能实现:
- 用户、图书、借阅、归还四大基础模块
- 支持完整的借阅生命周期管理
- 实现了库存管理、逾期计算等核心业务逻辑
-
AI 能力深度集成:
- 基于 Dify 平台实现了四大智能模块
- 智能逾期提醒自动生成
- 个性化图书推荐系统
- 自动化图书摘要生成
- 智能通知模板定制
-
技术架构优化:
- 采用 FastAPI 异步框架,提升并发处理能力
- 使用 SQLAlchemy 2.0 异步 ORM
- 实现前后端分离的现代化架构
- 完善的错误处理和日志记录
6.2 经验教训
- 技术选型要谨慎:Dify 虽然降低了 AI 集成门槛,但其 API 稳定性和文档完善度需要持续关注
- 异步编程复杂度:异步代码的调试和错误追踪比同步代码更复杂,需要更完善的监控
- 版本兼容性:第三方服务(如 Dify)的 API 变更可能影响系统稳定性,需要设计兼容层
- 性能监控重要性:在集成外部 AI 服务时,性能监控和熔断机制必不可少
6.3 未来优化方向
-
功能扩展:
- 添加多租户支持,支持多个图书馆同时使用
- 实现移动端应用,提供更便捷的借阅体验
- 增加数据分析模块,提供借阅趋势分析
-
性能优化:
- 引入 Redis 缓存,减少数据库压力
- 实现消息队列,异步处理耗时的 AI 任务
- 添加 CDN 加速静态资源访问
-
AI 能力增强:
- 集成更多 AI 模型,如图书封面生成、内容相似度分析
- 实现语音交互功能,支持语音查询和操作
- 添加个性化阅读计划推荐
-
运维改进:
- 实现容器化部署,支持快速扩缩容
- 添加完整的监控告警系统
- 实现自动化测试和持续集成
6.4 结语
本项目不仅是一个功能完整的图书管理系统,更是一次将传统业务系统与前沿 AI 技术深度融合的实践。通过 FastAPI 的高性能异步框架和 Dify 的低代码 AI 平台,我们成功构建了一个既具备传统系统稳定性,又拥有智能服务创新性的现代化应用。
开发过程中遇到的每一个挑战都成为了技术成长的契机,每一个解决方案都丰富了我们的架构设计经验。希望本项目的技术实现和经验总结能为类似系统的开发提供参考,也期待未来能有更多机会探索 AI 技术与传统行业的创新结合。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)