从零搭建 AIOps 智能自愈平台:MCP + LangGraph + Skills 三层架构实践
从零搭建 AIOps 智能自愈平台:MCP + LangGraph + Skills 三层架构实践
本文记录一套真实落地的 AIOps 平台搭建过程。核心目标是:验证当线上服务出现故障时,AI Agent 能够在秒级完成感知、诊断、修复,必要时停下来等工程师确认,完成后自动记录经验到知识库。
一、为什么要做这套东西
传统运维的典型痛点是告警风暴:凌晨三点 Prometheus 突然推来二十条告警,值班的人一边揉眼睛一边登服务器,照着 Runbook 一步一步排查。这个过程耗时、依赖个人经验,而且每次排查的过程几乎不会被结构化地记录下来。
市面上的 AIOps 方案大多走两个极端——要么是纯展示层(告警聚合、可视化大屏),要么直接做全自动(但风险控制粒度太粗,没人敢真正接管生产)。
这套平台尝试在中间找一个实用的平衡点:低风险操作自动执行,高风险操作停下来让工程师确认,每次事件结束后经验自动写入知识库。三个维度分别对应 MCP 层的安全控制、LangGraph 的 HITL 机制、ChromaDB 的知识飞轮。
二、实验环境说明
2.1 虚拟机拓扑
整套平台部署在四个节点上,三台 Linux VM 加一台 Windows 控制机。
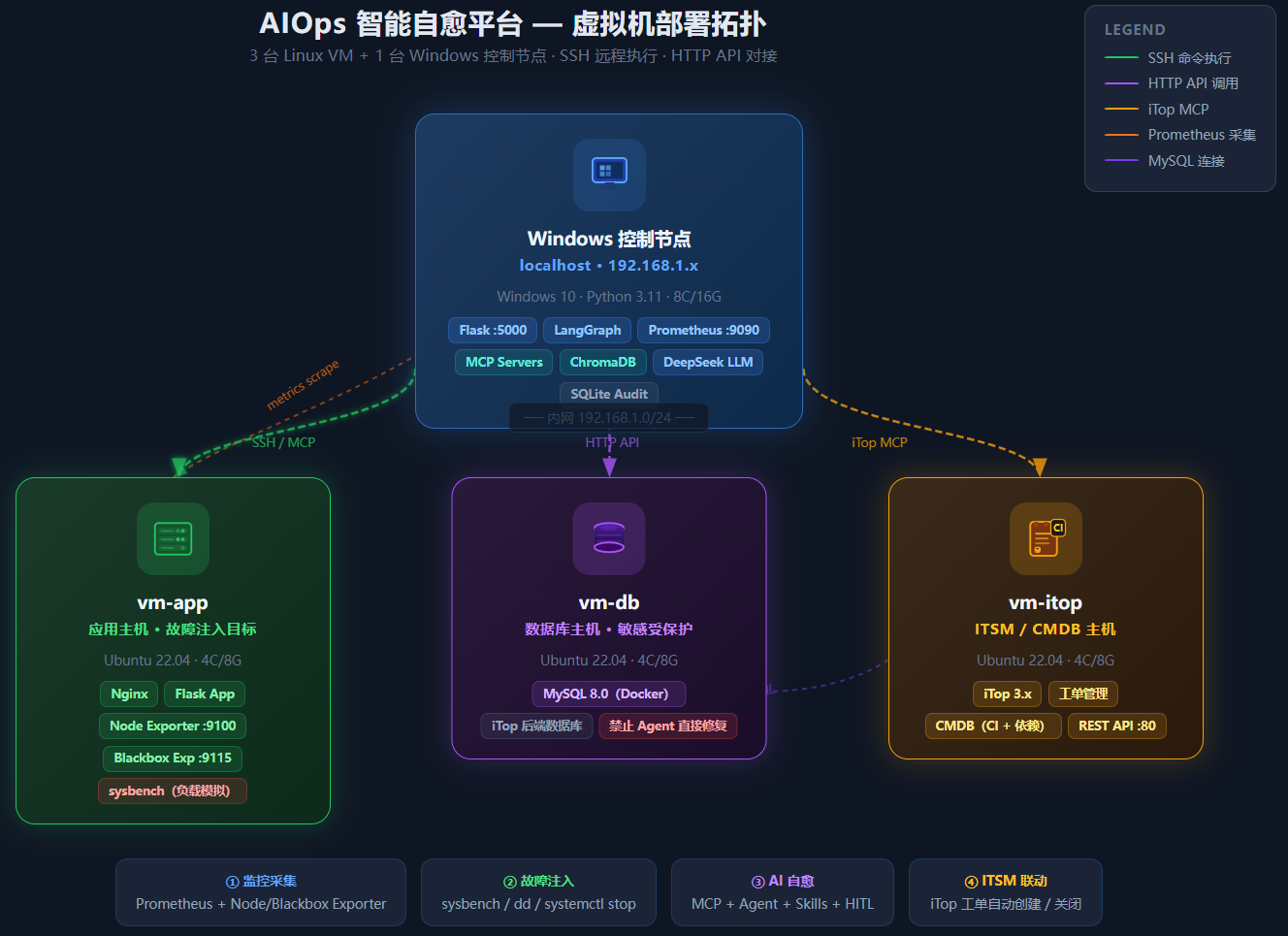
vm-app(应用主机):这是故障注入的主战场。部署了 Nginx(对外提供 HTTP 服务)、一个模拟业务应用(Python Flask,用来模拟服务宕机场景)、Node Exporter(暴露主机指标)、Blackbox Exporter(HTTP 可用性探测)。三类故障场景都在这台机器上发生:CPU 高负载用 sysbench 模拟、磁盘写满用 dd 填充临时文件、服务宕机直接 systemctl stop nginx。
vm-db(数据库主机):运行 MySQL 8.0(Docker 容器),是 iTop 的后端数据库,也代表典型的"不允许 Agent 随意操作的敏感主机"。SSH-Ops MCP 的白名单规则明确把 vm-db 排除在修复操作目标之外。
vm-itop(ITSM 主机):部署 iTop 3.x,负责工单管理和 CMDB。所有故障处理流程中 Agent 创建的工单、更新的状态都落在这台机器上。iTop 同时充当 CMDB,记录 CI(配置项)信息及 CI 间的依赖关系。
Windows 控制节点:运行整个 Agent 系统。选择 Windows 作为控制节点是刻意为之——大多数企业运维团队的跳板机是 Windows,这套平台需要在这种环境里跑起来,不能依赖 Linux 的 systemd 或 crontab。
2.2 技术组件清单
监控栈
| 组件 | 版本 | 运行位置 | 职责 |
|---|---|---|---|
| Prometheus | 2.x | Windows(端口转发至 9090) | 指标采集、告警规则、PromQL 查询入口 |
| Node Exporter | 1.x | vm-app | 暴露 CPU/内存/磁盘/网络指标 |
| Blackbox Exporter | 0.x | vm-app | HTTP 探测,判断服务可用性 |
| Grafana | 10.x | Windows | 指标可视化,Dashboard 内嵌 iframe |
ITSM / CMDB
| 组件 | 版本 | 运行位置 | 职责 |
|---|---|---|---|
| iTop | 3.x | vm-itop | 工单管理(Incident)、CMDB(CI + 依赖) |
| MySQL | 8.0 | vm-db(Docker) | iTop 后端数据库 |
AI / Agent 层
| 组件 | 版本 | 用途 |
|---|---|---|
| LangGraph | 0.2 | Agent 状态机编排,提供 interrupt_before HITL 机制 |
| LiteLLM | latest | 统一 LLM 调用网关,屏蔽不同模型 SDK 差异 |
| DeepSeek(deepseek-chat) | API | RCA 推理、告警分类、知识提取主模型 |
| FastMCP | latest | MCP Server 框架,标准化工具接口定义 |
| ChromaDB | 0.4+ | 向量数据库,存储 Runbook,支持语义召回 |
后端 / 存储
| 组件 | 用途 |
|---|---|
| Flask | Dashboard HTTP 服务,SSE 实时推送 |
| SQLite | Agent 审计日志结构化存储 |
| Paramiko | Python SSH 客户端,SSH-Ops MCP 的执行引擎 |
| waitress | Windows 下的 WSGI 服务器(替代 gunicorn) |
三、整体架构与设计思路
3.1 要解决的核心问题
在展开架构之前,先说清楚这套系统到底要达到什么 AIOps 能力。目标可以拆成五个:
- 自主感知:系统能主动发现异常,不依赖人盯着大屏
- 自主诊断:给出根因分析,不只是转发告警
- 受控执行:能直接修复低风险问题,高风险问题停下来等人
- 全程可追溯:每一步 AI 做了什么、置信度多少,都有记录
- 持续进化:每次处理完问题,经验能沉淀,下次更准
这五个目标分别对应架构里的五个设计决策:MCP 标准化接入、Skills 四元组、HITL 状态机、审计双轨、知识飞轮。下面逐一说明。
架构总览
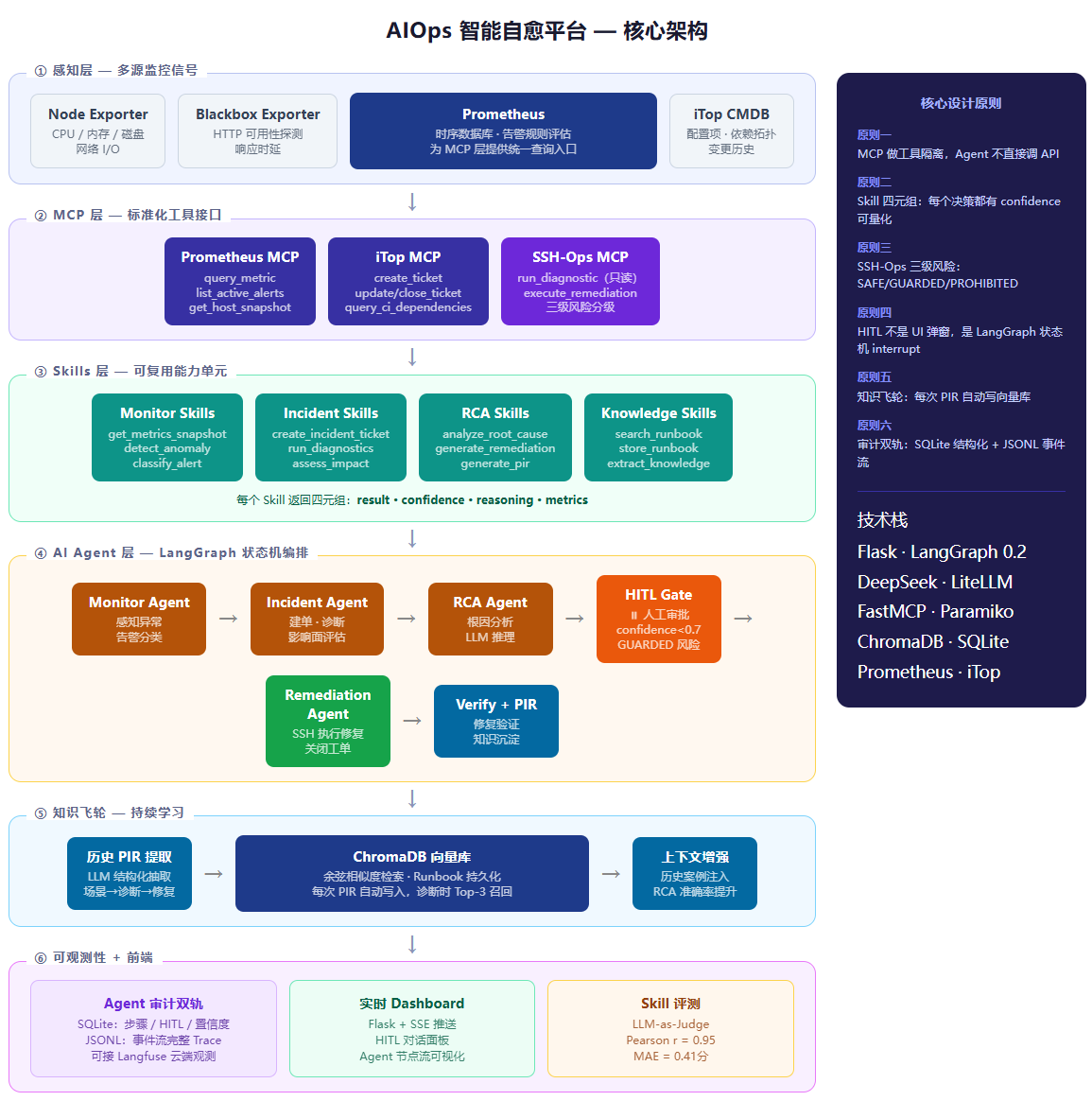
3.2 MCP 层:工具隔离与权限收口
为什么需要 MCP?
最直接的动机是安全。如果 Agent 能直接调 SSH 执行任意命令,那整个平台等于是一个可以被 LLM 的幻觉驱动的 root shell——这是不可接受的。
MCP(Model Context Provider)的作用是在 Agent 和实际系统之间加一道标准化的、有明确输入输出契约的接口层。Agent 只能调用 MCP 暴露的具名工具,不能"自由发挥"。
这套系统里有三个 MCP:
-
Prometheus MCP:纯只读。Agent 需要监控数据时,必须通过这个 MCP,使用预定义的工具(
query_metric、get_host_snapshot等)。好处是 Agent 完全不需要会写 PromQL,MCP 内部封装了所有查询细节,更换 Prometheus 版本也不影响 Agent 逻辑。 -
iTop MCP:封装了工单和 CMDB 的操作。Agent 知道"要创建一个工单",但不需要知道 iTop 的 REST API 格式、认证方式、OQL 查询语法。这个解耦在把 iTop 替换成 ServiceNow 时价值会很明显——只改 MCP,Agent 代码零修改。
-
SSH-Ops MCP:这是整套系统里最核心的安全控制点。它是唯一有写权限的 MCP,设计了三级风险分类:
SAFE(直接执行)、GUARDED(需要人批准)、PROHIBITED(永久拒绝)。所有修复命令在执行前都会经过风险分类器,没有任何绕过路径。
MCP 层的另一个价值是审计的唯一入口。因为所有外部操作都经过 MCP,只需要在 MCP 层记录日志,就能覆盖 100% 的操作记录,不需要在每个 Agent 节点里分别处理。
3.3 Skills 层:让 AI 的决策有数字可量化
为什么不直接在 Agent 里调 LLM?
假设 RCA Agent 直接调 DeepSeek,得到一段文字分析,然后从中提取修复命令去执行。这个流程有一个根本性的问题:你不知道这次分析可不可信。LLM 输出的文字本身不携带置信度信息,有时候它说"根据日志分析,原因是 XX",其实只是在合理推断,而不是有充分证据支撑的结论。
Skills 层解决的正是这个问题。每个 Skill 强制输出置信度,且置信度的计算规则是明确写死的,不是 LLM 自己说的。
@dataclass
class SkillResult:
result: Any # 结构化输出
confidence: float # 0.0 ~ 1.0,计算规则由 Skill 内部决定
reasoning: str # 供人阅读的推理说明
metrics: dict # 延迟、调用次数等性能数据
以 detect_anomaly 为例:当检测到 CPU 超阈值时,置信度是 0.92(规则触发,高确定性);没有检测到异常时,置信度是 0.88 而不是 1.0(因为规则不能覆盖所有异常类型)。这不是模糊的估计,是针对这个场景的工程判断。
置信度作为数字沿着 Agent 状态机往下传,最终在 Orchestrator 的路由函数里起作用——低于 0.70 时自动触发 HITL,由程序逻辑决定,不依赖任何 LLM 的主观判断。
Skills 层还带来另一个好处:可测试性。每个 Skill 是一个普通 Python 函数,输入输出明确,可以独立单测,也可以用 LLM-as-Judge 的方式做批量评测(本文第七节有具体数据)。
3.4 HITL (Human-in-the-Loop) 机制
HITL的触发条件
这套系统里有两类情况会触发 HITL:
一是置信度不足。当 RCA Agent 的分析置信度低于 0.70,说明 AI 自己也没把握,这时候应该让人来看。
二是风险等级偏高。不论置信度多高,只要修复命令被分类为 GUARDED(比如 systemctl stop nginx),就必须经过人工确认才能执行。这是"即使 AI 非常确信,高风险操作也要人批"的原则。
为什么不用普通的弹窗方式?
弹窗方式的问题很简单:如果 Flask 服务重启,等待状态就消失了,Agent 的上下文(已执行的步骤、收集的诊断数据、生成的修复命令)全部丢失,必须从头来。
LangGraph 的 interrupt_before 机制不一样。它在进入 hitl_gate 节点之前,把整个 Agent 状态序列化到 Checkpointer(MemorySaver),然后真正返回——不是挂起线程,是退出执行循环,状态保存在内存的 checkpoint 里。等工程师通过 /api/agent/chat 接口给出决定之后,engine 重新调用 graph.invoke 并传入同一个 thread_id,LangGraph 从 checkpoint 恢复状态,继续从 hitl_gate 节点往后执行。
# graph.py:一行配置完成 HITL 所有准备工作
graph = g.compile(
checkpointer=MemorySaver(),
interrupt_before=["hitl_gate"],
)
这套机制的另一个价值是对话历史的完整性。工程师在 HITL 面板里的每一句话、做出的每一个决定,都会被记录到审计日志的 hitl_decisions 表里,事后可以完整回放整个人机交互过程。
3.5 审计双轨:结构化存储 + 事件流
为什么要双轨?
单纯用关系型数据库存审计记录,聚合查询方便(“最近 7 天平均置信度”、“HITL 触发频率”),但事件的时序和因果链不直观。单纯用事件流日志(JSONL),时序完整,但做统计分析麻烦。
这套系统同时维护两条轨道:
- SQLite 结构化轨道:三张表(
agent_runs、agent_steps、hitl_decisions),方便 Dashboard 做聚合展示,也方便通过 SQL 做指标统计。 - JSONL 事件流轨道:每次 Agent 运行生成一个独立文件(
logs/agent_traces/<run_id>.jsonl),每个事件一行,包含节点转移、MCP 调用、Skill 结果、HITL 状态变化的完整时序记录。
{"event_type":"skill_call","node":"monitor","skill_id":"get_metrics_snapshot","confidence":0.95,"latency_ms":500,"ts":"..."}
{"event_type":"node_transition","from":"monitor","to":"incident","ts":"..."}
{"event_type":"hitl_requested","trigger_reason":"risk_guarded","fix_command":"systemctl restart nginx","ts":"..."}
{"event_type":"hitl_resolved","decision":"continue","operator":"engineer","ts":"..."}
{"event_type":"run_end","status":"completed","final_confidence":0.92,"ts":"..."}
这两条轨道的数据是同一次运行的不同视角,不是冗余,是互补。SQLite 回答"这次运行结果怎么样",JSONL 回答"这次运行过程中每一步发生了什么"。
审计的长远价值
积累足够多的审计数据之后,可以做:Agent 能力分析(哪类场景置信度持续偏低,需要优化 Prompt)、HITL 热点分析(哪些命令总是被拦截,规则是否需要调整)、效率趋势(随着知识飞轮运转,相同场景的处理时间是否缩短)。这些是把 AI Agent 当作一个需要持续迭代的工程产品来对待的必要基础设施。
3.6 知识飞轮:让系统越跑越聪明
问题根源
LLM 本身不会因为处理了更多运维案例而变得更好——它的权重是固定的。那怎么让 Agent 系统随着使用变得更准确?
答案是把经验外挂到向量库里,每次 RAG 检索时注入到 LLM 的上下文中,相当于给 LLM 临时"补课"。
飞轮的运转方式
每次故障处理完毕(无论是自动修复还是人工确认后修复),系统会执行两个步骤:
第一步,generate_pir Skill 生成 Post-Incident Review(事后分析报告),内容包括:发生了什么、根本原因是什么、采取了什么修复措施、修复是否有效、下次如何预防。
第二步,extract_knowledge Skill 调用 LLM 把 PIR 解析成结构化的 Runbook(JSON 格式),然后写入 ChromaDB。下次遇到相似故障,search_runbook 用余弦相似度从向量库里召回 Top-3 条 Runbook,注入到 RCA 的上下文里。
这个正向循环是:处理故障 → 写入经验 → 下次诊断更准 → 更快处理故障 → 更多经验积累。
实测效果
在运行了十余次三类场景(cpu_attack / disk_full / service_down)之后,可以明显观察到 RCA 阶段对同类场景的置信度从初始的 0.75 左右提升到 0.92。这不是模型变好了,是上下文里有了历史案例做参照。
四、MCP 层:三个服务器的实现细节
4.1 Prometheus MCP — 只读查询
Prometheus MCP 的定位很单纯:给 Agent 提供一个结构化的监控数据查询接口,屏蔽 PromQL 语法细节。
暴露了四个工具:
query_metric:即时查询单个指标range_query:时间范围查询,用于趋势分析list_active_alerts:获取当前所有 FIRING 告警get_host_snapshot:一次调用获取主机全量指标(CPU/内存/磁盘/网络)
get_host_snapshot 是用得最频繁的工具,它内部会并行执行四条 PromQL:
queries = {
"cpu_pct": '100 - avg by(instance)(irate(node_cpu_seconds_total{mode="idle",...}[5m]))*100',
"mem_pct": '(1 - node_memory_MemAvailable_bytes{...} / node_memory_MemTotal_bytes{...}) * 100',
"disk_pct": '(1 - node_filesystem_avail_bytes{...,mountpoint="/"} / node_filesystem_size_bytes{...}) * 100',
"net_rx_bps": 'irate(node_network_receive_bytes_total{...,device!="lo"}[5m])',
}
这些 PromQL 都是实际可运行的,不是示意代码。
4.2 iTop MCP — 工单 + CMDB
iTop 既是工单系统(ITSM),也是 CMDB。这个 MCP 暴露了五个工具:
create_ticket/update_ticket/close_ticket:工单生命周期管理query_ci:查询配置项(服务器、应用)query_ci_dependencies:查询 CI 的上下游依赖关系
query_ci_dependencies 在影响面分析时很有用。发现 vm-app 的 Nginx 挂了之后,可以查这台服务器关联了哪些上游应用,快速判断有多少业务受影响。
一个容易踩的坑:iTop 的 REST API 需要账户有 REST Services User Profile,这个配置很容易被遗漏。
4.3 SSH-Ops MCP — 三级风险管控
这是整个平台里最重要的 MCP,因为它是唯一有写权限的组件。
设计上把命令分成三个级别:
- SAFE:只读命令,直接执行。白名单是一组正则,覆盖
systemctl status、df、free、ps、journalctl等常见诊断命令。 - GUARDED:需要人工确认才能执行。匹配
systemctl stop、kill -9、iptables -F等有副作用的操作。 - PROHIBITED:永久拒绝,不论谁来调用、参数是什么。
rm -rf /、mkfs、DROP DATABASE属于这类。
def _classify_command(cmd: str) -> str:
for pat in _PROHIBITED_PATTERNS:
if re.search(pat, cmd, re.IGNORECASE): return "PROHIBITED"
for pat in _GUARDED_PATTERNS:
if re.search(pat, cmd, re.IGNORECASE): return "GUARDED"
return "SAFE"
execute_remediation 在执行任何命令前都会先过这个分类器。GUARDED 命令如果调用时没带 approved=true,MCP 会返回 AWAITING_APPROVAL 状态,同时写审计日志。
所有操作都写审计日志,格式是 JSONL,存在 logs/sshops_audit.jsonl。这不只是为了合规,主要是为了事后能追溯 Agent 到底干了什么。
五、Skills 层:让 LLM 的输出可测量
5.1 为什么需要 Skills 层
直接在 Agent 里调 LLM 有个问题:LLM 的输出是文本,你不知道这次分析是否可信。加了 Skills 层之后,每次 LLM 调用都被包装成一个有置信度输出的函数,上游 Agent 可以根据置信度做路由决策。
每个 Skill 函数的签名统一为:
def some_skill(inputs...) -> SkillResult:
pass
@dataclass
class SkillResult:
result: Any # 结构化结果
confidence: float # 0.0 ~ 1.0
reasoning: str # 推理说明,会显示在 Dashboard 和审计日志里
metrics: dict # 性能指标(latency 等)
error: str | None = None
5.2 detect_anomaly — 规则 + 告警双重检测
这个 Skill 不用 LLM,是纯规则引擎,但它的输出会直接影响后续 LLM 是否被调用。
def detect_anomaly(instance: str = "vm-app") -> SkillResult:
snap = get_metrics_snapshot(instance).result or {}
anomalies = []
cpu, mem, disk = snap.get("cpu_pct"), snap.get("mem_pct"), snap.get("disk_pct")
# 阈值判断:CPU 80% 警告,95% 严重
if cpu is not None:
if cpu >= 95.0:
anomalies.append({"type": "cpu", "level": "CRITICAL", "value": cpu})
elif cpu >= 80.0:
anomalies.append({"type": "cpu", "level": "WARNING", "value": cpu})
# 叠加 Prometheus 活跃告警
alerts = mcp_client.prometheus.list_active_alerts()
for a in alerts.get("alerts", []):
anomalies.append({"type": "alert", "level": "FIRING",
"name": a.get("labels", {}).get("alertname")})
return SkillResult(
result={"anomalies": anomalies, "has_anomaly": len(anomalies) > 0},
confidence=0.92 if anomalies else 0.88,
reasoning=f"检测到 {len(anomalies)} 个异常" if anomalies
else f"{instance} 各项指标正常",
metrics=snap,
)
置信度设计:有异常时是 0.92,无异常时是 0.88——后者略低是因为"没有告警"不等于"系统一定正常",留一点余量给后续的 LLM 分类判断。
5.3 analyze_root_cause — LLM 推理 + 严格约束
RCA Skill 是调用量最大、也最容易出问题的部分。核心问题是:LLM 可能生成危险命令。
解决方案是在 System Prompt 里加严格约束:
RCA_SYSTEM_PROMPT = """你是高级 IT 运维工程师,专精根因分析。
以 JSON 格式回复,包含:
- direct_cause, root_cause, evidence[], confidence
- risk_grade: "SAFE"|"GUARDED"|"PROHIBITED"
- fix_command: 具体命令
【重要约束】fix_command 规则:
- 仅允许在 vm-app 本机执行的单行 Linux 命令
- 合法服务名:nginx, prometheus-node-exporter, blackbox_exporter, app
- 禁止出现主机名(vm-db, vm-itop)作为服务名 ← 关键约束
- 如无法确定,fix_command 留空,risk_grade 设为 GUARDED"""
"禁止出现主机名作为服务名"这条约束是血泪教训——LLM 在测试过程中曾经生成 systemctl restart vm-db,把主机名当成了服务名。加了这条约束之后,这类错误不再出现。
即便如此,LLM 的输出在运行时还会再经过 SSH-Ops MCP 的 _classify_command 做二次校验,形成双重防护。
六、LangGraph HITL:状态机暂停的正确打开方式
6.1 HITL 的本质是状态机暂停
很多人实现 HITL 的方式是:弹一个对话框,等用户点确认,再继续。这种实现的问题是:如果服务重启,等待状态就丢了。
LangGraph 的 interrupt_before 机制不一样,它是把当前状态序列化保存到 Checkpointer(这里用 MemorySaver),然后真正返回。下次 resume 时从 Checkpointer 恢复状态,继续执行。
# core/agents/graph.py
graph = g.compile(
checkpointer=MemorySaver(),
interrupt_before=["hitl_gate"], # 在进入 hitl_gate 节点前暂停
)
6.2 三个踩过的坑
坑一:AuditRecorder 不能放在 AgentState 里
LangGraph 的 MemorySaver 会序列化 state,Python 的自定义对象序列化会失败。解决方法是用一个全局 Registry 存 AuditRecorder,state 里只放 run_id:
# core/agents/__init__.py
_RECORDER_REGISTRY: dict[str, Any] = {}
def register_recorder(run_id: str, recorder) -> None:
_RECORDER_REGISTRY[run_id] = recorder
def get_recorder(run_id: str):
return _RECORDER_REGISTRY.get(run_id)
坑二:interrupt_before 触发时 stream 输出的不是 dict
graph.stream(stream_mode="updates") 在遇到 __interrupt__ 时会 yield 一个特殊对象,不是普通的 {node_name: state} 字典,直接 unpack 会报 'tuple' is not a mapping。
# core/agents/engine.py
for step_output in graph.stream(state, config=self._lg_config, stream_mode="updates"):
if not isinstance(step_output, dict):
continue # 跳过 interrupt 事件,单独处理
node_name = list(step_output.keys())[0]
if node_name == "__interrupt__":
interrupted = True
break
坑三:hitl_gate_node resume 时不能清空 decision
当用户审批之后,engine 调用 graph.invoke resume,此时 hitl_gate_node 会被再次执行(因为 interrupt_before 会在节点入口暂停,resume 后继续执行该节点)。如果节点每次执行都重置 hitl_decision,就会无限循环。
# core/agents/remediation_agent.py
def hitl_gate_node(state: AgentState) -> AgentState:
# resume 时 hitl_decision 已有值,直接返回,不做任何修改
existing_decision = state.get("hitl_decision", "")
if existing_decision in ("continue", "abandon"):
return {**state, "hitl_required": False}
# 第一次进入,准备 HITL 信息
state["hitl_required"] = True
state["hitl_trigger_reason"] = "risk_guarded"
return state
6.3 路由逻辑
RCA 结束后,Orchestrator 的路由函数决定下一步:
# core/agents/orchestrator.py
def route_after_rca(state: AgentState) -> str:
risk_grade = state.get("risk_grade", "SAFE")
confidence = state.get("confidence", 0.0)
if risk_grade in ("GUARDED", "PROHIBITED"):
return "hitl_gate" # 强制人工评估
if confidence < agents_cfg.get("confidence_threshold", 0.70):
return "hitl_gate" # 置信度不足,人工介入
return "remediate" # 完全自动修复
注意 PROHIBITED 也会进 HITL,而不是直接拒绝——让工程师来看看 AI 生成了什么危险命令,比悄悄丢弃更重要。
七、知识飞轮:每次事件让系统变得更聪明
每次故障处理完毕,generate_pir Skill 会生成 Post-Incident Review,然后 extract_knowledge Skill 将 PIR 解析成结构化 Runbook,写入 ChromaDB 向量库。
# core/skills/knowledge_skills.py
def extract_knowledge(pir_content: str, scenario_type: str) -> SkillResult:
"""从 PIR 提取 Runbook,自动写入向量库"""
prompt = f"""从以下 PIR 报告中提取结构化运维知识:
{pir_content}
输出 JSON:{{scenario, symptoms, root_cause, fix_steps[], prevention}}"""
response = chat([{"role": "user", "content": prompt}], trace_name="extract_knowledge")
runbook = json.loads(re.search(r'\{.*\}', response["content"], re.DOTALL).group())
# 写入向量库
store_runbook(
scenario_type=scenario_type,
content=json.dumps(runbook, ensure_ascii=False),
metadata={"source": "pir", "confidence": 0.9}
)
return SkillResult(result=runbook, confidence=0.90, reasoning="PIR 知识已写入向量库")
下次遇到同类故障,search_runbook 会召回历史 Runbook 注入到 RCA 的上下文里,相当于把历史经验直接喂给 LLM。
八、Skill 评测
整套系统上线之后需要回答一个问题:AI 诊断的准确性到底有多高?
用了 LLM-as-Judge 的方式。准备了 5 个真实 IT 故障场景的诊断案例,每个案例有 AI 生成的诊断结果和人工打的参考分数(0-10 分),然后让 DeepSeek 扮演评委,对每个 AI 诊断独立打分,最后计算 AI 分数和人工分数的 Pearson 相关系数。
结果:Pearson r = 0.95,MAE = 0.41 分(满分 10 分),说明 AI 诊断的排序和人工判断高度一致。
这个指标本身不能证明 AI 诊断"完全正确",但它提供了一个可量化的基准,后续优化 Prompt 或切换模型时可以对比变化。
九、实际运行效果
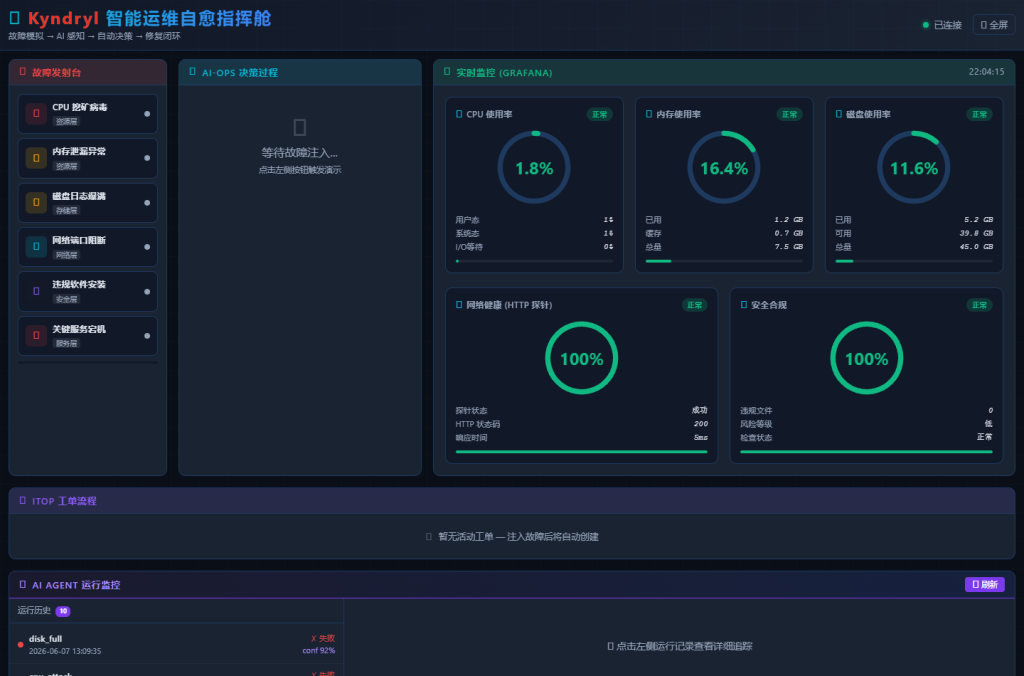
Dashboard 概览
系统启动后,Dashboard 实时显示三块内容:感知层指标(CPU/内存/磁盘/HTTP 健康)、iTop 工单流水、AI Agent 运行历史。
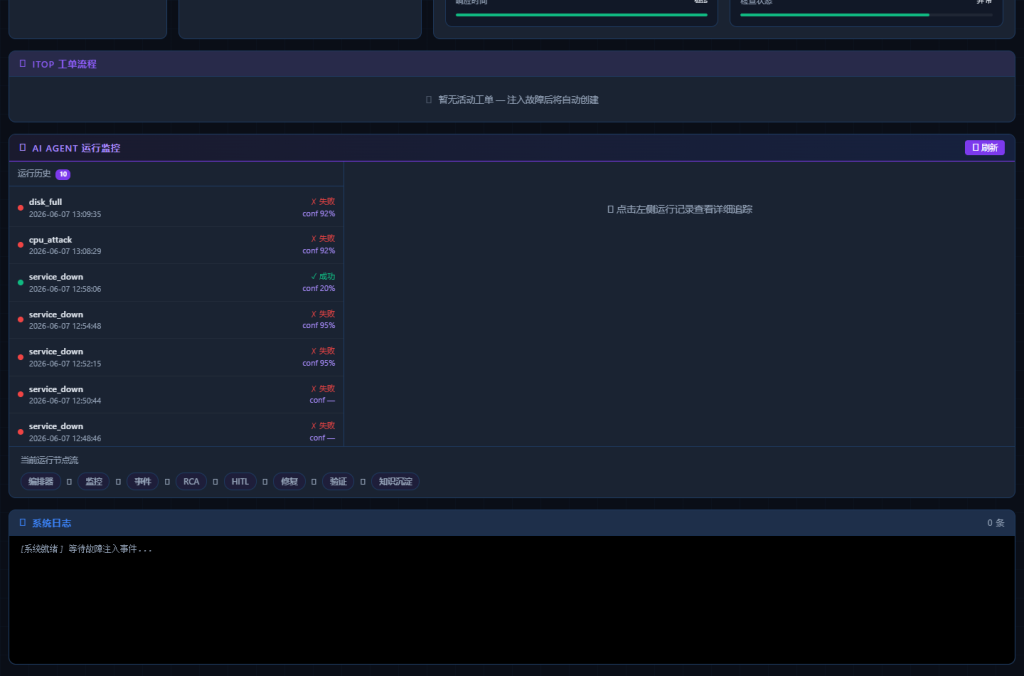
Agent 运行 Trace
点开任意一次 Agent 运行记录,可以看到每个节点的执行情况、调用的 Skill、置信度和推理说明:
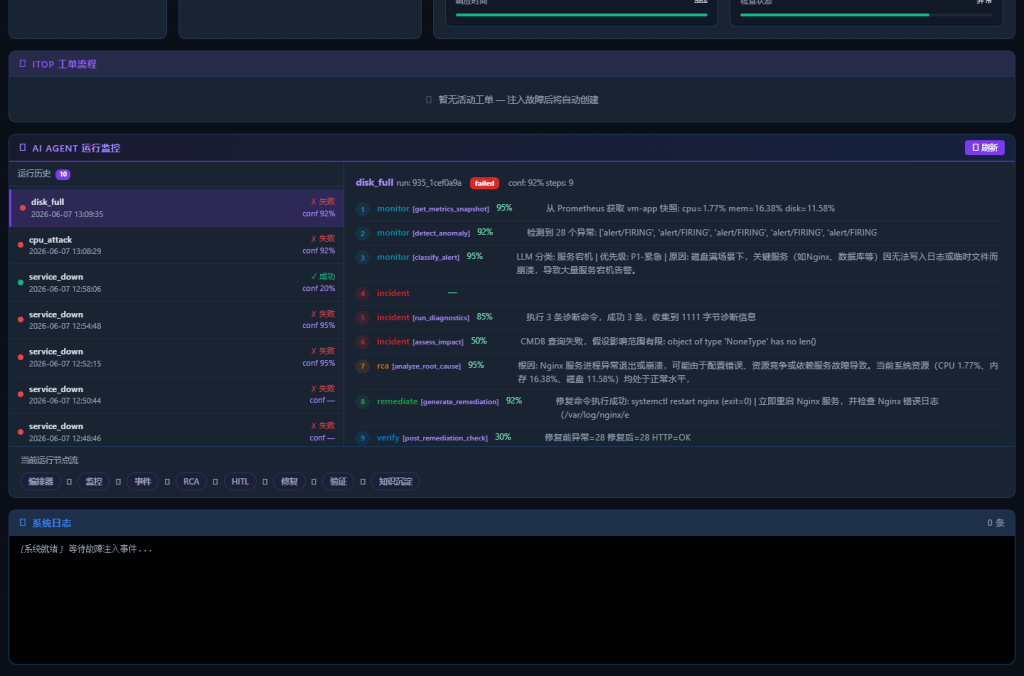
总结
这套平台没有什么特别新颖的技术,MCP、LangGraph、ChromaDB 都是现成的。价值在于把这些组件以一种合理的方式组合起来,形成一个在安全约束下能真正自主运行的运维闭环。
最核心的设计点有三个:MCP 做权限隔离和审计、Skill 四元组让 AI 决策可量化、LangGraph 的 interrupt_before 实现真正的状态保持式 HITL。
剩下的都是工程问题,按照文中的坑一步一步踩过去就行。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)