山东大学软件学院创新实训——MarketClaw(五):从功能原型到可运行闭环的阶段性推进
一、本阶段工作背景
前一阶段我们主要完成了 MarketClaw 项目的方向确认和基础功能的试验。本周开始,项目进入更偏工程实现的阶段:把核心流程拆成可以运行、可以记录、可以展示的数据链路。
MarketClaw 的目标是做一个面向商品营销场景的私人产品营销助理。用户输入商品营销需求后,系统能够自动完成商品分析、热点匹配、小红书风格文案生成,并记录任务过程、Skill 调用日志、Token 消耗等。这篇博客重点记录我在本阶段对系统闭环、数据结构和前后端联调的理解与推进。
二、本周项目完成情况
目前项目已经完成了一个最小可运行版本。后端使用 FastAPI、SQLAlchemy 和 SQLite 搭建,前端使用 Vue 3、Vite、Element Plus、Pinia 和 Vue Router 实现基础页面。系统已经具备登录、首页看板、聊天生成、任务记录、任务详情和 Skill 管理等页面。
后端已经实现的接口包括:
- POST /api/auth/login:模拟用户登录。
- GET /api/dashboard/summary:统计用户数、任务数、Token 消耗、内容资产数量、Skill 成功率等指标。
- POST /api/chat/send:接收用户输入,创建营销生成任务。
- GET /api/tasks:查看历史任务列表。
- GET /api/tasks/{task_id}:查看任务详情、最终输出、Skill 调用链和内容资产。
- GET /api/skills:查看各 Skill 的调用次数、成功率、平均耗时和 Token 消耗。
- POST /api/skills/{skill_name}/run:单独运行某个 Skill,便于调试。
当前系统中已经落地的核心链路是:
用户输入商品营销需求 → 创建会话和任务 → 调用商品分析 Skill → 调用热点匹配 Skill → 调用小红书文案生成 Skill → 汇总最终结果 → 写入消息、任务日志、Token 记录。
虽然目前 Skill 还是 mock 实现,没有完全接入真实大模型和真实平台数据,但它已经把后续接入真实模型所需要的数据流、接口边界和日志结构先跑通了。这一点对后续开发很重要,因为只有先确定任务如何创建、结果如何传递、日志如何沉淀,后面的模型替换和功能扩展才不会变成零散代码的堆叠。
三、我的个人工作与理解
本阶段我重点关注的是“任务链路如何被完整记录下来”。在最开始设计时,我们容易只盯着文案生成结果,也就是用户最终看到的一段小红书文案。但真正做成一个可展示、可验收、可迭代的智能体系统,不能只保存最后结果,还要保存中间过程。
因此我把一次营销生成任务拆成了几个关键对象:
- 用户和会话:记录是谁发起了任务,以及任务属于哪一次营销对话。
- 消息:保存用户输入和系统回复,形成对话历史。
- AgentTask:记录一次完整营销任务的状态、输入、输出、耗时和 Token 总量。
- SkillCallLog:记录每个 Skill 的输入、输出、状态、耗时和 Token 消耗。
- TokenUsage:用于后续统计模型调用成本。
- ContentAsset:把最终生成的小红书标题、正文、标签作为内容资产沉淀下来。
- UserPreference 和 MemoryItem:为长期记忆和用户偏好做数据结构准备。
我对这个设计的理解是:MarketClaw 不只是一个“输入一句话,返回一段文案”的工具,而应该是一个能够追踪过程、沉淀经验、持续优化的营销智能体。比如用户这次生成的是运动手表文案,系统不仅要返回标题和正文,还应该知道这次调用了哪些 Skill、每一步产出了什么、用了多少 Token、最终资产能否复用。这样后面做效果分析、爆款策略迭代、用户偏好学习时,才有数据基础。
四、关键技术点:用任务链串起多个 Skill
本周我印象最深的是任务服务层的设计。后端不是在接口函数里直接写所有逻辑,而是把核心业务流程集中到 run_marketing_task 这样的服务函数中处理。
这个函数承担了三个职责:
第一,创建任务上下文。用户输入内容后,系统先创建或复用会话,再写入用户消息,然后创建一个状态为 running 的任务。
第二,串联多个 Skill。系统依次调用商品分析、热点匹配和小红书文案生成。后一个 Skill 的输入会包含前一个 Skill 的输出,例如热点匹配会参考商品分析结果,文案生成会同时参考商品分析、热点匹配、用户偏好和记忆信息。
第三,持久化全过程。每次 Skill 调用都会记录到日志表,同时写入 TokenUsage。任务结束后,系统把总结果写入 final_output,把文案保存为 ContentAsset,并追加 assistant 消息。
这种写法让我更清楚地理解了“智能体编排”和普通接口开发的区别。普通接口可能只关心一次请求和一次响应,而智能体系统更关心过程:中间步骤是否可追踪,失败时能否定位,后续能否根据日志优化每一个 Skill。
五、前端展示与联调进展
前端目前已经实现了几个基础页面:
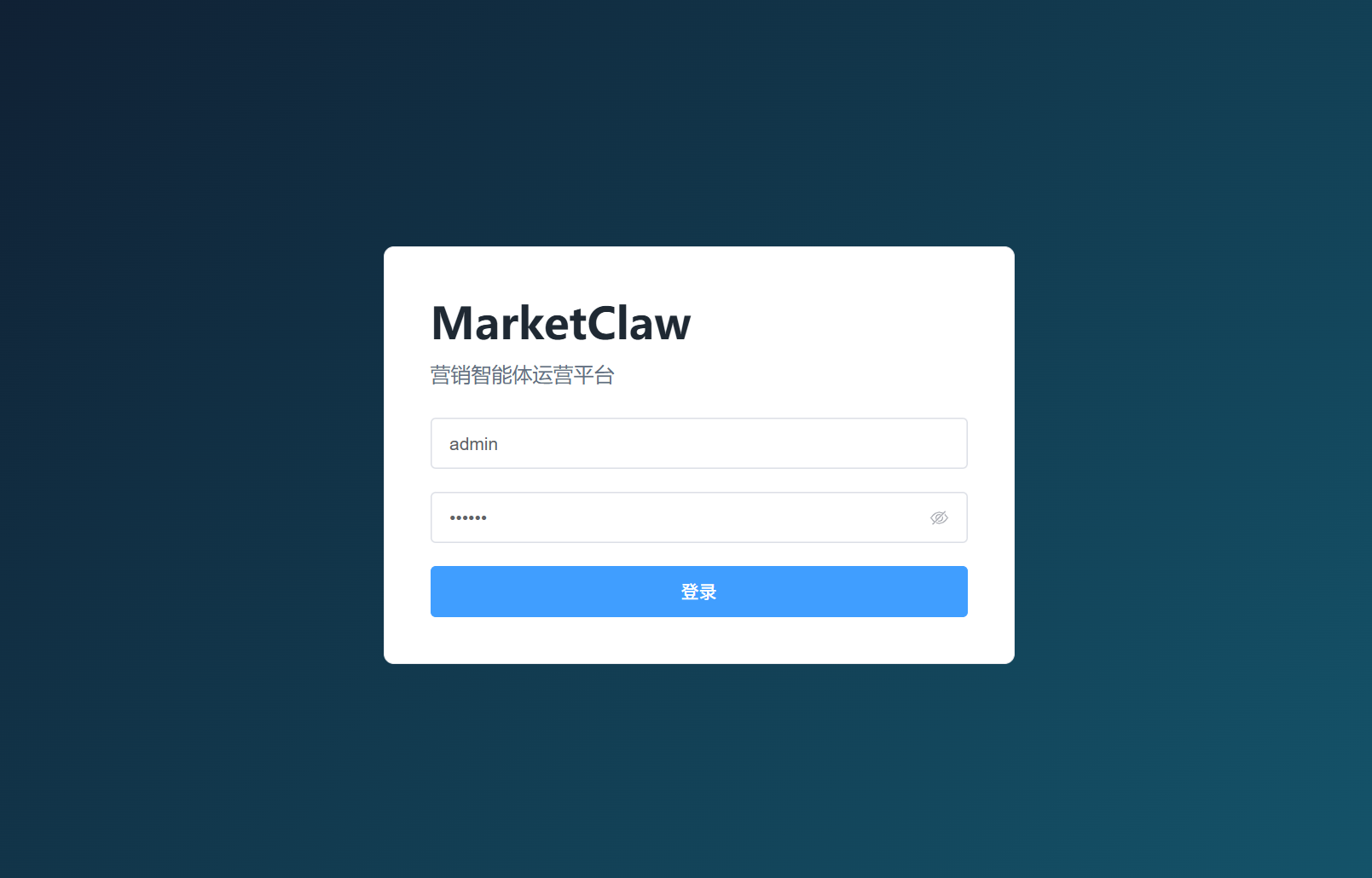
- 登录页:使用测试账号进入系统。
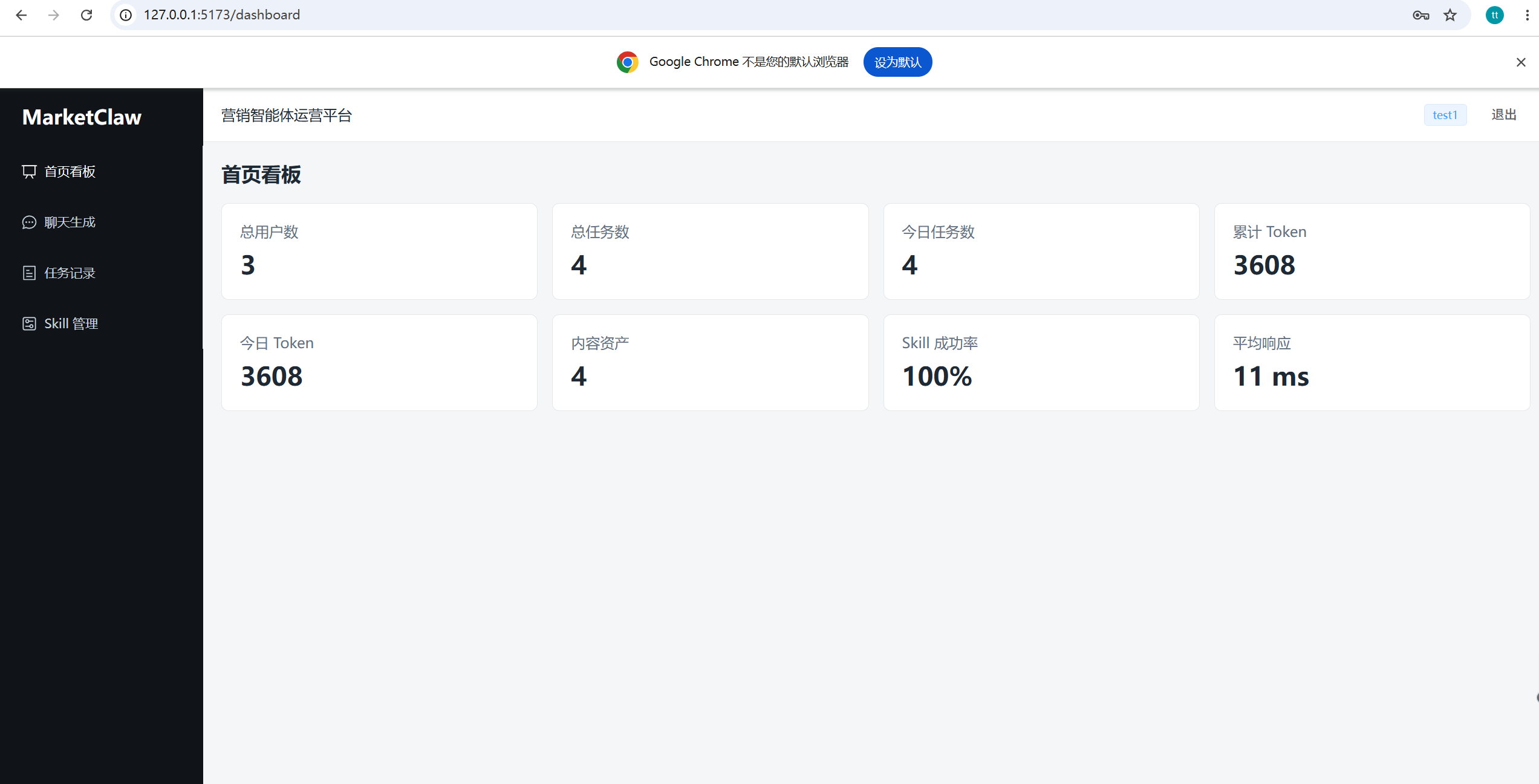
- 首页看板:展示总用户数、任务数、Token、内容资产、Skill 成功率等指标。
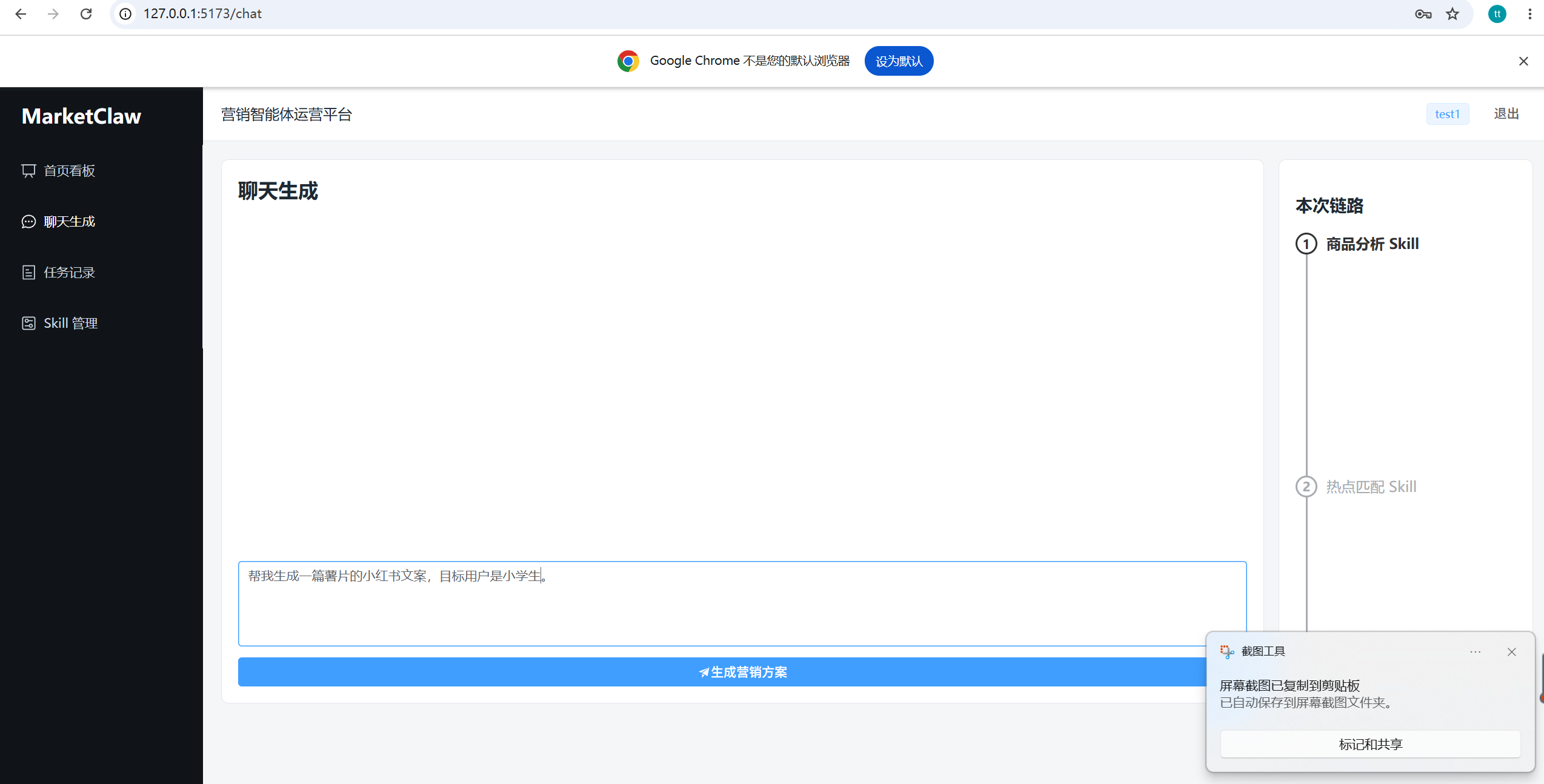
- 聊天生成页:输入商品营销需求,触发后端生成流程,并展示返回结果。
- 任务记录页:查看历史任务。
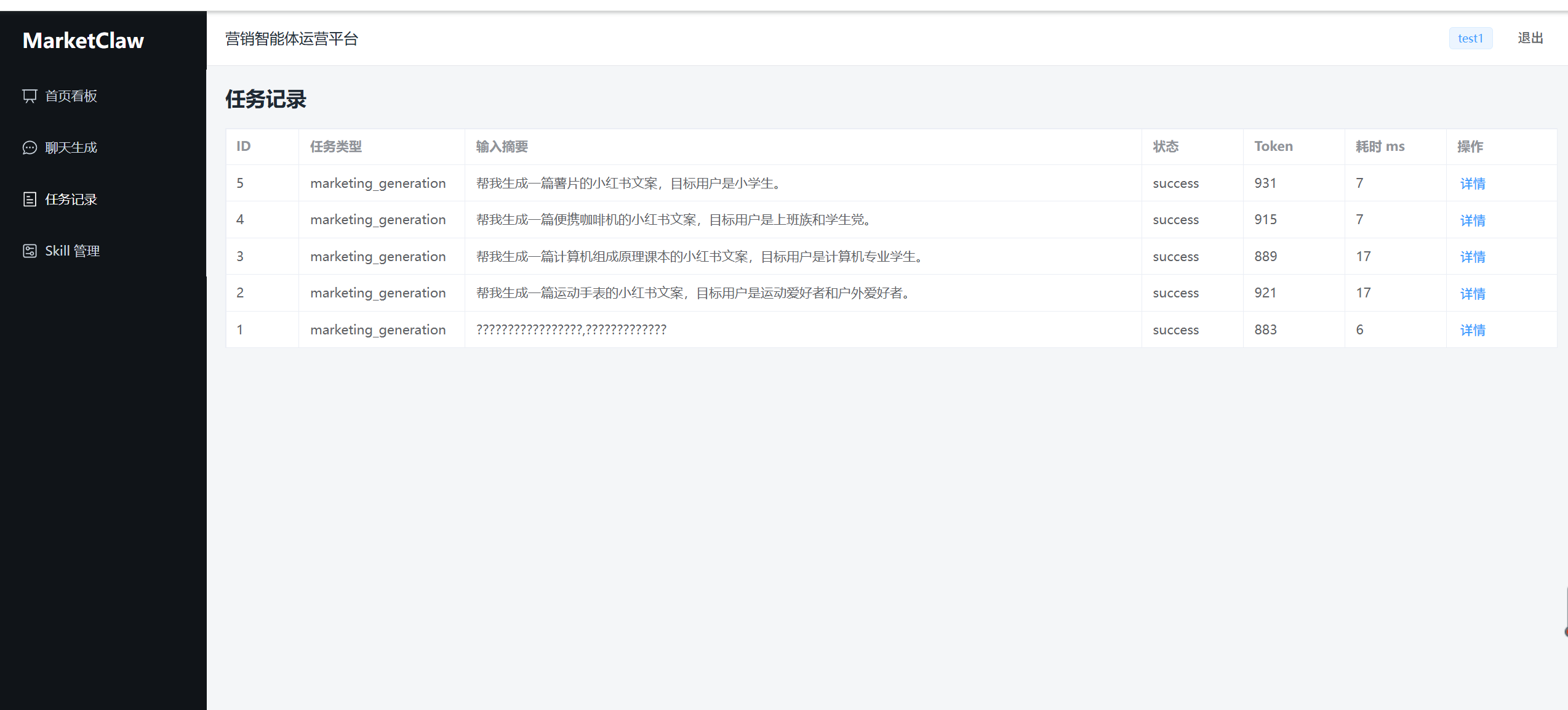
- 任务详情页:展示任务输入、最终输出、Skill 调用链和内容资产。
- Skill 管理页:展示每个 Skill 的调用统计。
我认为前端现阶段最大的意义不是视觉完整,而是把后端数据结构可视化出来。比如任务详情页能看到 Skill 调用链,这就让项目展示不只停留在“生成了一篇文案”,而是能解释系统如何一步步完成分析、匹配、生成。
六、AI 辅助开发记录
本阶段我使用 AI 时,主要不是让它直接替我完成整个项目,而是把它当成一个工程协作工具,用来梳理模块边界和检查实现思路。
本阶段使用过的典型提示词包括:
我们要做一个营销智能体系统,后端使用 FastAPI 和 SQLAlchemy。 请帮我设计一次营销生成任务需要记录哪些数据库表, 要求能够追踪用户输入、Skill 调用链、Token 消耗和最终内容资产。
请根据“商品分析 -> 热点匹配 -> 小红书文案生成”的流程, 设计一个服务层函数,把多个 mock skill 串起来, 并在每一步记录输入、输出、耗时和 token。
前端使用 Vue 3 和 Element Plus, 请帮我规划几个页面:仪表盘、聊天生成、任务列表、任务详情、Skill 管理。 任务详情页要能展示最终输出和 Skill 调用日志。
AI 给出的建议主要帮助我确认了两个方向:第一,智能体系统需要保留中间过程,不能只保存最终结果;第二,前端页面应该围绕任务和 Skill 调用链组织,而不是只做一个简单聊天框。之后我再根据项目实际情况进行简化,实现了当前这个最小可运行版本。
七、遇到的问题与解决思路
本阶段遇到的第一个问题是功能规划和当前开发进度之间的取舍。任务书中规划了五个 Skill,包括热点采集、小红书自动发布、账号预热、爆款分析和长期记忆等。但如果一开始就同时开发所有功能,很容易导致每个模块都只有半成品。因此我们当前优先完成核心闭环:商品输入、分析、生成、记录、展示。这样即使后续继续扩展,也有一个稳定的主流程作为基础。
第二个问题是 mock Skill 和真实大模型之间的边界。现在 mock Skill 只是返回固定结构的数据,但我在设计时尽量让它的输入输出接近真实模型调用后的结构。例如商品分析输出商品名称、品类、卖点、目标人群和使用场景;热点匹配输出话题、标签和内容角度;文案生成输出标题、正文、标签、评论引导和封面建议。这样后续替换为真实 API 时,只需要修改 Skill runner 内部逻辑,服务层和前端页面可以尽量少改。
第三个问题是长期记忆的落地方式。目前系统已经有 UserPreference 和 MemoryItem 表,也会在任务完成后写入简单的偏好和记忆记录。它还不是完整的 HOT/WARM/COLD 三层记忆机制,但已经为后续扩展留下了入口。下一步可以继续补充记忆分层、重要性评分更新、记忆召回和用户纠错记录。
八、本阶段总结
这周的工作让我对 MarketClaw 的定位有了更清晰的认识。它不是一个单点文案生成器,而是一个围绕营销任务展开的智能体系统。对于这样的系统,最重要的不是某一次生成结果有多漂亮,而是任务能否被完整追踪、Skill 能否被独立调试、数据能否沉淀为后续优化依据。
目前项目已经完成了从用户输入到任务创建、Skill 编排、结果生成、日志记录和前端展示的基础闭环。虽然距离任务书中完整的小红书自动化执行、爆款分析和策略迭代还有距离,但当前版本已经具备了继续扩展的工程基础。下一步我会继续围绕真实模型接入、长期记忆和演示稳定性推进个人工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)