开源一个 Codex 文件整理 Skill:一句话列出本次会话生成的文档、截图和交付物
开源一个 Codex 文件整理 Skill:一句话列出本次会话生成的文档、截图和交付物
很多人用 AI Agent 写文档、生成截图、整理表格、导出 HTML 页面时,都会遇到一个小问题:
Agent 明明已经帮你做了很多东西,但最后你还要反过来问一句:刚才生成的文件都在哪里?
尤其是一次会话里连续做了几件事:
- 写了几篇 Markdown 草稿;
- 生成了一张使用截图;
- 更新了 README;
- 保存了 HTML 模板;
- 又同步了一些文件到 GitHub。
这时候,真正麻烦的不是“文件有没有生成”,而是“怎么把这些产物快速找出来、点开、复查、交付”。
所以我写了一个 Codex Skill:Artifact Radar。
仓库地址:
https://github.com/huajiexiewenfeng/artifact-radar-skill
效果大概是这样: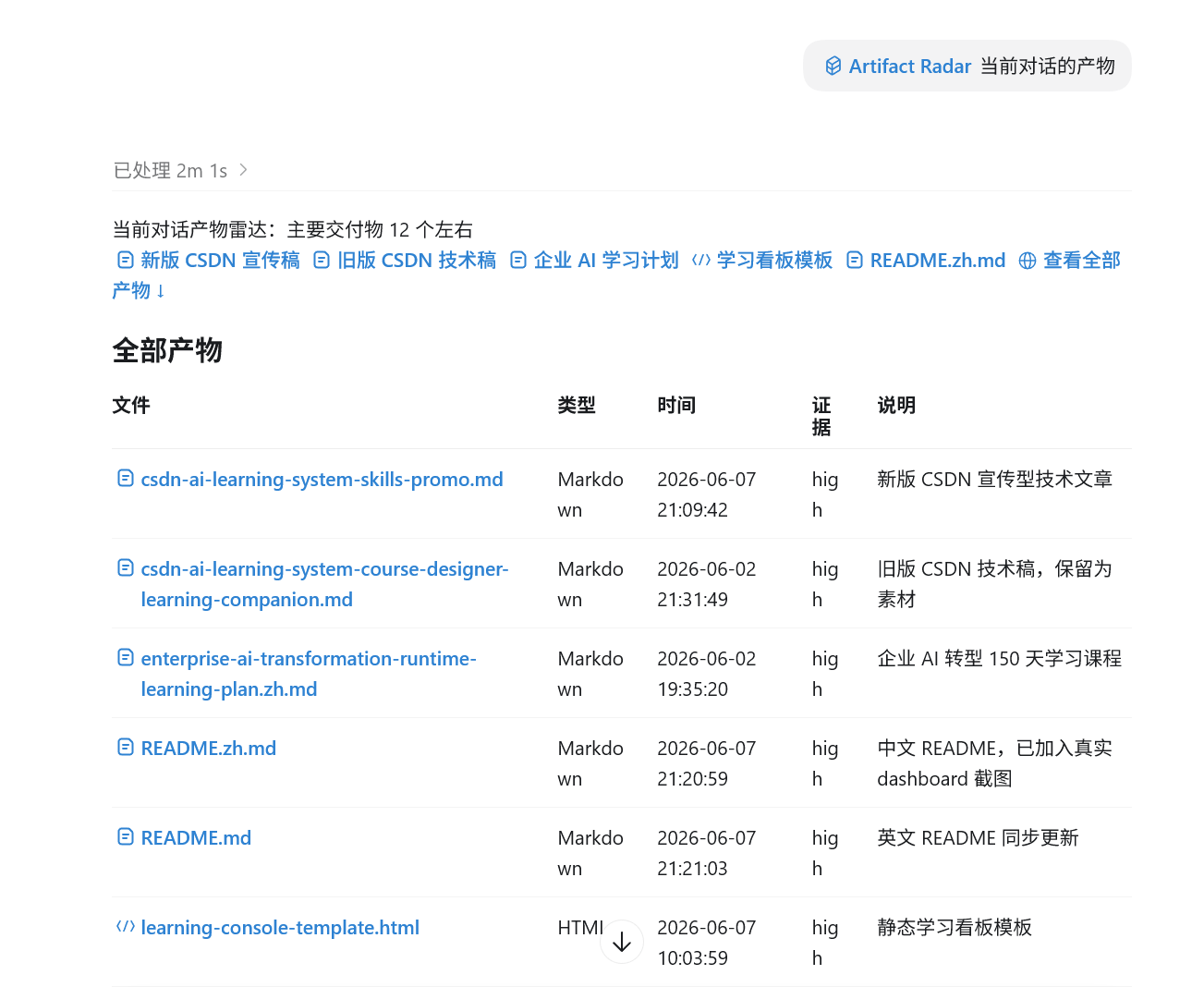
它解决的不是“搜索文件”,而是“交付物收口”
普通文件搜索关注的是:
某个文件在哪里?
Artifact Radar 关注的是:
当前这次 AI 会话到底产出了哪些可以交付、可以打开、可以继续使用的文件?
这两个问题不一样。
在 Agent 工作流里,文件往往不是单独出现的,而是随着一轮对话不断生成:
| 场景 | 常见问题 | Artifact Radar 的处理方式 |
|---|---|---|
| 写文章 | 多个 .md 草稿散在工作区里 |
按最近修改时间和会话证据整理 |
| 做设计稿 | 图片、HTML、README 同时生成 | 把不同类型文件统一列出 |
| 做交付物 | 用户只想快速点开结果 | 输出可点击链接,而不是只给路径 |
| 长会话 | 不确定哪些文件是刚才做的 | 标注时间、证据和置信度 |
| Git 仓库内工作 | 新增、修改文件混在一起 | 优先读取 git status 作为高置信证据 |
它本质上是一个“会话产物索引器”,不是一个全盘文件扫描器。
它会列哪些文件?
Artifact Radar 默认关注用户真正可能要交付、查看、复用的文件,例如:
- Markdown / 文本文档:
.md、.txt、.rst - Word / PDF:
.docx、.doc、.pdf - 表格:
.xlsx、.xls、.csv、.tsv - PPT:
.pptx、.ppt - 图片:
.png、.jpg、.jpeg、.webp、.gif、.svg - Web 页面:
.html、.htm - 数据或交接文件:
.json、.yaml、.yml - 脚本类交付物:
.ps1、.sh、.bat、.cmd - 压缩包:
.zip、.7z、.tar、.gz
它默认会排除源码、依赖目录、构建缓存、日志和内部二进制文件。
原因也很简单:用户问“这次产出了什么”时,通常不是想看 node_modules、target、.git 或构建中间文件。
它的判断逻辑:不要假装自己有完美记账本
我在这个 Skill 里刻意加了一条原则:
不要声称运行时有一个完美的 session artifact ledger。
也就是说,它不会假装自己一定知道“当前会话生成的全部文件”。
它会根据证据做一个 best-effort 索引,优先级大致是:
- 当前对话里明确创建、编辑、复制、导出、渲染过的文件;
- Git staged、unstaged、untracked 文件;
- 工作区里最近修改过的交付物文件;
- 对话中提到过的输出目录、图片目录、导出目录;
- 用户额外指定的根目录、文件类型或时间范围。
然后给每个文件打上置信度:
| 置信度 | 含义 |
|---|---|
high |
对话中明确生成/修改,或出现在 git status |
medium |
在相关目录和时间窗口内匹配到的交付物 |
low |
只有文件名相似或宽泛最近扫描证据 |
这个设计看起来保守,但对 Agent 工作流很重要。
因为一旦 Agent 把“可能相关的文件”说成“全部文件”,用户后面就会基于错误信心做交付。Artifact Radar 更愿意把边界说清楚:扫描了哪些目录、时间窗口是多少、哪些结果是高置信,哪些只是可能相关。
安装方式
推荐直接用 npx skills add 安装:
npx skills add huajiexiewenfeng/artifact-radar-skill
然后重启 Codex,让新的 Skill 被加载。
仓库结构很简单:
.
├── SKILL.md
├── agents/
│ └── openai.yaml
├── scripts/
│ └── find-artifacts.ps1
├── assets/
│ └── artifact-radar-usage.png
└── README.md
怎么触发?
你可以直接问 Codex:
- 当前 session 生成了哪些文件?
- 列出刚才生成的图片和文档
- 给我一个可以点击查看的产物清单
- where are the files you created?
- show generated artifacts with timestamps
- make an artifact index for this session
它会尽量把结果整理成两层:
第一层是“产物条”,让你快速点开最重要的几个文件。
第二层是完整明细,包括文件类型、时间、证据、说明和置信度。
内置扫描脚本
这个 Skill 里还带了一个 PowerShell 扫描脚本:
.\scripts\find-artifacts.ps1 -Roots . -Hours 8
如果你只想看 Git 里新增或修改的交付物,可以用:
.\scripts\find-artifacts.ps1 -Roots . -GitChangedOnly
如果还有额外的生成目录,比如图片生成目录,可以加 -ExtraRoots:
.\scripts\find-artifacts.ps1 -Roots . -ExtraRoots "$env:USERPROFILE\.codex\generated_images" -Hours 8
脚本会输出类似这样的字段:
LastWriteTime Extension SizeKB Evidence FullName
Agent 再根据这些结果组织成更适合用户阅读的交付物列表。
一个实际使用流程
在一次 Codex 会话里,我可能连续做这些事:
- 让 Codex 写一篇 CSDN 草稿;
- 让它生成或保存一张截图;
- 让它更新 README;
- 让它同步到 GitHub;
- 最后问:当前会话产物有哪些?
这时候 Artifact Radar 会优先从当前工作目录、Git 状态、最近修改时间和已知输出目录里找交付物。
最终你得到的不是一堆裸路径,而是一份可以直接点击的交付物清单。
这对长会话很有用。
因为 AI Agent 的输出不再只是聊天窗口里的文字,而是落在文件系统里的真实资产。当文件越来越多时,交付物索引本身就变成了工作流的一部分。
适合什么人用?
我觉得这个 Skill 特别适合几类用户:
- 经常用 Codex 写技术文章、README、方案文档的人;
- 用 Agent 生成图片、HTML、PDF、表格等多种产物的人;
- 一次会话里会频繁创建、修改、导出文件的人;
- 需要把 AI 生成结果交付给别人复查的人;
- 希望把“AI 做了什么”沉淀成文件清单的人。
如果你只是偶尔让 Agent 改一个源代码文件,它可能没那么必要。
但如果你的 Agent 工作流已经从“问答”变成“持续生产文档、脚本、截图、模板和交付物”,那它会节省很多回头找文件的时间。
使用时的几个建议
-
尽量在项目目录里运行
这样
git status、最近修改文件和输出目录都更容易收敛。 -
不要让它默认扫整个磁盘
Artifact Radar 的定位是“当前会话产物”,不是全盘文件管理器。
-
长会话最好指定时间范围
比如“列出最近 2 小时生成的产物”,结果会更干净。
-
交付前让它再跑一次
尤其是写文章、做 README、生成截图、导出 HTML 后,最后用它收口一次,会更容易确认有没有漏掉文件。
-
把高置信和中低置信分开看
high通常可以直接信任,medium和low更适合作为补充线索。
小结
Artifact Radar 不是一个复杂工具。
它解决的是 Agent 工作流里一个很具体的问题:当 AI 在文件系统里连续生成交付物时,用户需要一个干净、可点击、带时间和证据的产物清单。
仓库在这里:
https://github.com/huajiexiewenfeng/artifact-radar-skill
如果你也经常让 Codex 帮你写文章、做文档、生成图片或整理交付物,可以试试看。
有时候,让 AI 真正进入工作流,不只是让它“会写”,还要让它“知道刚才交付了什么”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)