11|Netty 学习路线与源码阅读地图:从会用到真正看懂高并发网络框架
11|Netty 学习路线与源码阅读地图:从会用到真正看懂高并发网络框架
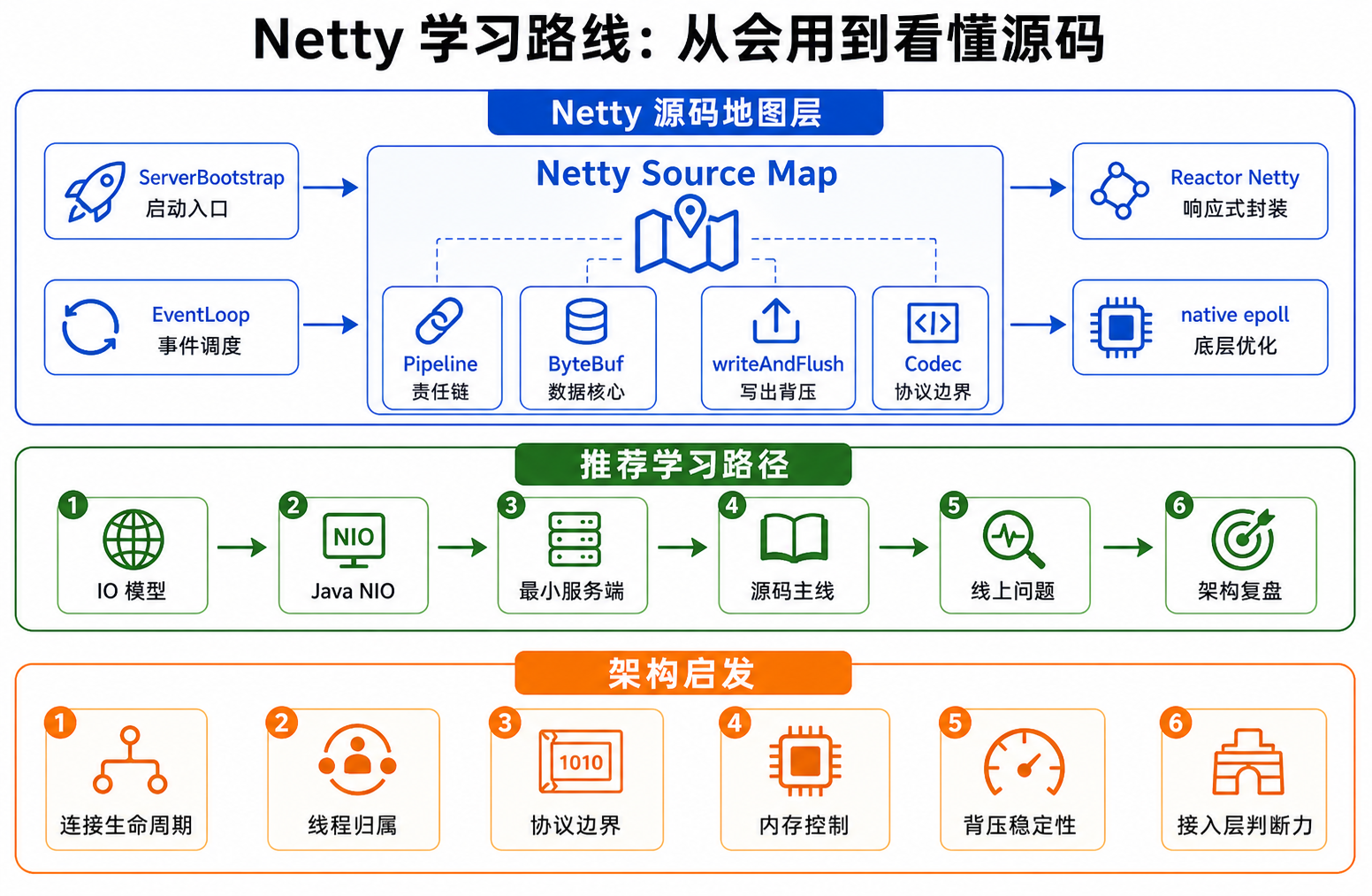
到这里,Netty 专题已经写了十篇:
01 Netty 不只是 TCP 框架:它解决的是高并发业务系统的组织问题
02 ServerBootstrap.bind() 启动源码主线
03 BossGroup / WorkerGroup / EventLoop 线程模型
04 ChannelPipeline 责任链
05 ByteBuf 与内存管理
06 writeAndFlush、写队列与背压
07 半包粘包与编解码
08 Reactor Netty / WebFlux / Spring Cloud Gateway
09 Netty 线上问题排查
10 native epoll 与零拷贝
这些文章覆盖了 Netty 的核心骨架。
但学 Netty 最容易遇到一个问题:
概念都听过,但源码还是不知道从哪里看。
或者:
会写 Echo Server,但一到线上问题就不知道怎么排查。
所以这篇文章不再展开某一个源码细节,而是整理一张学习路线和源码阅读地图。
目标是回答:
- Netty 到底应该按什么顺序学?
- 源码应该从哪几条主线切进去?
- 学到什么程度才算真正掌握?
- 如何通过实验验证自己理解对不对?
但对我来说,这张路线图还有另一层意义:它不是为了把 Netty 源码背下来,而是为了补齐业务架构师在高并发通信系统里的底层判断力。
在云边协同、设备接入、媒体链路、Gateway、MQTT、大文件上传这些系统里,很多架构问题最后都会落到几类基础能力上:
- 连接如何被管理;
- 消息如何被切分和解析;
- 数据如何被缓冲和释放;
- 写出速度和消费速度如何匹配;
- 慢客户端、慢下游、大文件、媒体流如何隔离;
- 出问题时如何从线程、内存、队列、协议和链路上定位。
所以这一篇的路线图,不只是“Netty 学习顺序”,也是一张从源码阅读走向系统设计和线上排障的能力地图。
一、不要从全量源码开始
Netty 源码很大。
如果一上来就从包结构开始全量阅读,很容易迷路。
你会看到大量类:
Bootstrap
Channel
EventLoop
Pipeline
ByteBuf
Promise
Future
Allocator
Codec
Resolver
Transport
每个类都很重要,但不是每个类都适合作为入口。
学习 Netty 最好的方式不是:
按包名读源码。
而是:
按问题读源码。
比如:
服务端是怎么启动的?
连接是怎么注册的?
EventLoop 在循环什么?
数据是怎么读进来的?
Pipeline 怎么传播事件?
writeAndFlush 后发生了什么?
ByteBuf 为什么要 release?
每个问题对应一条源码主线。
把这些主线串起来,Netty 的骨架就立住了。
二、第一阶段:先建立 IO 模型基础
学 Netty 之前,最好先理解几个底层概念:
用户态 / 内核态
阻塞 IO
非阻塞 IO
IO 多路复用
select / poll / epoll
线程调度
零拷贝
TCP 字节流
半包粘包
为什么?
因为 Netty 不是凭空出现的。
它是对这些底层机制的工程化封装。
如果不了解 epoll,就很难理解:
EventLoop 为什么可以用少量线程管理大量连接。
如果不了解 TCP 字节流,就很难理解:
为什么必须有 ByteToMessageDecoder。
如果不了解零拷贝,就很难理解:
FileRegion / transferTo 的价值。
所以学习路线应该是:
不要反过来。
三、第二阶段:先会写最小服务端
学习 Netty 的第一个代码目标很简单:
写一个 Echo Server。
最小代码包含:
NioEventLoopGroup
ServerBootstrap
NioServerSocketChannel
ChannelInitializer
ChannelInboundHandlerAdapter
bind
你要能解释每一行:
bossGroup 是什么?
workerGroup 是什么?
为什么要指定 Channel 类型?
childHandler 是给谁用的?
ChannelPipeline 是什么时候创建的?
bind 返回的 ChannelFuture 是什么?
如果这些解释不清楚,直接看源码会很吃力。
最小服务端不是为了写业务,而是为了建立源码入口。
四、第三阶段:读 ServerBootstrap 启动主线
第一条源码主线建议从:
ServerBootstrap.bind()
开始。
阅读路径:
这条主线要解决:
NioServerSocketChannel 是什么时候创建的?
Pipeline 是什么时候初始化的?
ServerBootstrapAcceptor 是什么时候加入的?
Channel 是怎么注册到 EventLoop 的?
真正 bind 发生在哪里?
读完这条线,你应该能画出:
这是 Netty 服务端的入口地图。
五、第四阶段:读 EventLoop 核心循环
第二条源码主线是:
NioEventLoop.run()
阅读路径:
这条线要解决:
EventLoop 到底是不是线程?
Selector 在哪里阻塞?
IO 事件怎么分发?
普通任务在哪里执行?
为什么不能阻塞 EventLoop?
读完以后,你应该能理解:
一个 EventLoop ≈ 一个线程 + 一个 Selector + 一个任务队列 + 一个事件循环。
这也是 Netty 最核心的心智模型。
六、第五阶段:读 Pipeline 传播主线
第三条源码主线是:
DefaultChannelPipelineAbstractChannelHandlerContext
阅读路径:
出站路径:
这条线要解决:
Pipeline 为什么是责任链?
Handler 和 Context 有什么区别?
Inbound 和 Outbound 为什么方向相反?
HeadContext 和 TailContext 是什么?
为什么 ctx.write 和 channel.write 不完全一样?
读懂 Pipeline,才能读懂:
- 编解码器
HTTP HandlerRPC Handler- Gateway Filter 到底如何接入底层网络。
七、第六阶段:读 ByteBuf 和内存管理
第四条源码主线是:
ByteBufPooledByteBufAllocatorReferenceCounted
重点不一定要一口气读完整内存池源码。
先掌握几个问题:
ByteBuf 为什么不用 ByteBuffer?
readerIndex / writerIndex 如何工作?
堆内和堆外有什么区别?
池化分配解决什么问题?
retain / release 为什么重要?
slice / duplicate / copy 有什么区别?
这条线读懂以后,你会真正理解:
Netty 的高性能不只是 IO,也包括内存复用。
很多线上问题也会变得清晰:
- Direct Memory 为什么涨?
- 为什么出现 ByteBuf leak?
- 为什么跨线程传 ByteBuf 要 retain?
八、第七阶段:读 writeAndFlush 写出主线
第五条源码主线是:
writeAndFlushChannelOutboundBufferdoWrite
阅读路径:
这条线要解决:
write 和 flush 有什么区别?
writeAndFlush 是不是马上发到网卡?
写不完的数据放在哪里?
ChannelOutboundBuffer 是什么?
isWritable 怎么判断?
高水位和低水位有什么用?
这条线非常重要。
因为很多高并发问题都和写出有关:
慢客户端
写队列堆积
内存暴涨
响应延迟
背压失效
九、第八阶段:读编解码主线
第六条源码主线是:
ByteToMessageDecoderLengthFieldBasedFrameDecoderMessageToByteEncoder
阅读路径:
这条线要解决:
TCP 为什么没有消息边界?
半包数据放在哪里?
decode 为什么可能被循环调用?
readerIndex 为什么不能乱动?
LengthFieldBasedFrameDecoder 参数怎么理解?
maxFrameLength 为什么重要?
读懂它,你就能写自定义协议。
RPC、IM、游戏网关、消息队列通信层,都绕不开这条线。
十、第九阶段:连接 Reactor Netty 和 Gateway
学完 Netty 本体后,再看上层框架。
典型链路:
这时你要理解:
WebFlux 不等于 Netty
Reactor Netty 是 Netty 的响应式封装
Gateway 是 IO 编排型系统
NettyRoutingFilter 用 Reactor Netty HttpClient 转发请求
NettyWriteResponseFilter 写回响应
这一步的意义是:
把 Netty 源码理解和真实框架里的工程约束对照起来。
看 Gateway 性能问题时,你就不会只说:
WebFlux 是响应式。
而能具体判断:
EventLoop 是否阻塞?
下游连接池是否耗尽?
写队列是否堆积?
DataBuffer 是否泄漏?
Filter 是否做了阻塞调用?
十一、第十阶段:做实验验证
只读文章不够。
Netty 必须做实验。
建议做几个小实验。
实验一:阻塞 EventLoop。
在 Handler 中写:
Thread.sleep(5000);
然后用多个客户端连接测试。
观察:
同一个 EventLoop 上其他连接是否被拖慢。
实验二:模拟慢客户端。
客户端连接后读取很慢。
服务端不断发送数据。
观察:
channel.isWritable()
ChannelOutboundBuffer 堆积
内存变化
实验三:制造 ByteBuf 泄漏。
在 Handler 中消费 ByteBuf,但不 release。
打开:
-Dio.netty.leakDetection.level=ADVANCED
观察泄漏日志。
实验四:半包粘包。
客户端分多次发送一条消息,或者一次发送多条消息。
观察:
ByteToMessageDecoder 如何累积和解码。
实验五:FileRegion 发送文件。
用:
DefaultFileRegion
发送本地文件。
观察它和普通分块读取写出的差异。
通过这些实验,源码理解会变得非常扎实。
十二、学到什么程度算掌握 Netty?
不用追求记住每个类。
真正掌握 Netty,应该能回答这些问题。
启动流程:
ServerBootstrap.bind() 背后发生了什么?
NioServerSocketChannel 和 NioSocketChannel 有什么区别?
ServerBootstrapAcceptor 做什么?
线程模型:
- EventLoop 是什么?
- 一个 Channel 为什么绑定一个 EventLoop?
- 为什么不能阻塞 EventLoop?
Pipeline:
- Inbound 和 Outbound 怎么传播?
- Handler 和 Context 有什么区别?
- ctx.write 和 channel.write 有什么差别?
内存:
ByteBuf 为什么有 readerIndex / writerIndex?
retain/release 什么时候用?
如何避免 ByteBuf 泄漏?
写出:
- write 和 flush 有什么区别?
- 写不完的数据在哪里?
- 如何响应 isWritable?
协议:
- 为什么 TCP 有半包粘包?
- LengthFieldBasedFrameDecoder 参数怎么配置?
- maxFrameLength 为什么重要?
工程排查:
- EventLoop 阻塞怎么查?
- Direct Memory 泄漏怎么查?
- 慢连接怎么处理?
- 写队列堆积怎么办?
如果这些问题能讲清楚,就已经超过大多数“只会用 Netty API”的水平了。
十三、推荐阅读顺序
如果你是从零开始,可以按这个顺序读本专题:
01 Netty 不只是 TCP 框架:它解决的是高并发业务系统的组织问题
02 ServerBootstrap.bind() 启动源码主线
03 BossGroup / WorkerGroup / EventLoop 线程模型
04 ChannelPipeline 责任链
05 ByteBuf 与内存管理
06 writeAndFlush、写队列与背压
07 半包粘包与编解码
08 Reactor Netty / WebFlux / Spring Cloud Gateway
09 Netty 线上问题排查
10 native epoll 与零拷贝
11 Netty 学习路线与源码阅读地图
如果你已经会用 Netty,想补源码,可以从第 2 篇开始。
如果你做 Gateway / WebFlux,可以重点看:
03 EventLoop
06 writeAndFlush
08 Reactor Netty / Gateway
09 线上问题排查
如果你做自定义协议,可以重点看:
04 Pipeline05 ByteBuf- 07 半包粘包与编解码
如果你做文件传输或网关性能优化,可以重点看:
06 writeAndFlush- 09 线上问题排查
- 10 native epoll 与零拷贝
十四、结论
Netty 学习的难点不是 API 多,而是层次多。
它同时涉及:
操作系统 IO
Java NIO
事件循环
线程模型
责任链
内存管理
协议设计
异步写出
背压
线上排查
所以学习 Netty 最重要的是建立地图。
不要陷入:
我看了很多类,但不知道它们连起来干什么。
正确路线应该是:
- 先理解 IO 模型
- 再写最小服务端
- 再抓启动、EventLoop、Pipeline、ByteBuf、write、codec 六条源码主线
- 最后连接到 Reactor Netty、Gateway 和线上排查
用一句话总结:
- Netty 不是一个简单的网络 API,
- 而是 Java 世界对高并发网络系统的工程化表达。
读源码的目的,也不是背类名,而是看懂这套工程表达如何把底层 IO 组织成稳定、可扩展、可排查的系统。
对我的架构判断有什么用?
这个专题最后真正要沉淀的,不是“我读过 Netty 源码”,而是我能在真实系统里做出更稳定的判断。
可以把前面十篇对应到一张能力地图:
| 文章主线 | 表面学习点 | 架构判断能力 |
|---|---|---|
| ServerBootstrap | 服务如何启动 | 一个接入服务从监听端口到接收连接的生命周期 |
| EventLoop | 线程模型 | 哪些代码绝不能阻塞,慢任务该如何隔离 |
| Pipeline | 责任链 | 协议、网关、业务处理如何分层组织 |
| ByteBuf | 内存管理 | 大包、媒体数据、消息体是否会造成内存压力 |
| writeAndFlush | 写出与背压 | 慢客户端、慢下游、写队列堆积如何影响系统 |
| Codec | 半包粘包 | public/private 协议、消息边界、版本兼容如何治理 |
| Reactor Netty / Gateway | 上层框架 | HTTP 网关为什么是 IO 编排型系统 |
| 线上排查 | 故障定位 | 线程、内存、队列、连接、协议如何互相印证 |
| epoll / 零拷贝 | 操作系统能力 | 连接事件和数据搬运分别应该怎么优化 |
所以以后我判断一个系统,不会只看功能是否做完,而会继续问:
- 这个系统的控制面、数据面、媒体面是否分清了?
- 哪些链路是短请求,哪些链路是长连接或持续流?
- 哪些地方可能出现阻塞、堆积、泄漏、重复消费或回环?
- 大文件和媒体流是否会拖垮普通业务接口?
- 网关层是在做协议治理,还是把业务复杂度堆到了入口?
- 出问题时,能不能从指标和源码模型反推出压力位置?
如果能做到这一点,Netty 专题就不是一组源码笔记,而是我从“能做业务”走向“能设计高并发业务系统”的一块底座。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)