从零搭建带数据库的文件上传系统:FastAPI + Streamlit + SQLite+加上日志
【学习记录】从零搭建带数据库的文件上传系统:FastAPI + Streamlit + SQLite
在上一篇文章中,我们使用 FastAPI 和 Streamlit 实现了一个基础的文件上传系统。但在实际应用中,我们往往需要记录谁在什么时候上传了什么文件,以便后续审计、管理和检索。本文在原有基础上增加 SQLite 数据库,记录上传的原始文件名、保存路径、文件大小、用户 ID 和上传时间。同时提供查询接口,前端可以展示用户的历史上传记录。文章最后附带面试官常见问题及回答策略,帮助你应对技术面试中的相关考察。
📌 技术栈升级
| 组件 | 作用 | 新增内容 |
|---|---|---|
| FastAPI | 后端 API | 增加数据库记录、异步插入、查询接口 |
| Streamlit | 前端界面 | 增加用户 ID 输入、显示历史记录 |
| SQLite | 嵌入式数据库 | 存储上传记录(轻量、无需额外服务) |
| aiosqlite | 异步 SQLite 驱动 | 支持异步数据库操作 |
| sqlite3 | 同步驱动 | 用于初始化数据库(避免异步开销) |
🗂️ 项目结构
file_upload_system/
├── backend.py # FastAPI 后端(含数据库)
├── frontend.py # Streamlit 前端(含记录查询)
├── uploaded_files/ # 文件存储目录
├── upload_records.db # SQLite 数据库文件(自动生成)
└── requirements.txt
🔧 环境准备
新增依赖 aiosqlite:
fastapi
uvicorn
streamlit
requests
python-multipart
aiosqlite
安装命令:
pip install -r requirements.txt
🖥️ 后端实现(FastAPI + SQLite)
1. 数据库表结构
CREATE TABLE IF NOT EXISTS upload_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
original_filename TEXT NOT NULL,
saved_filename TEXT NOT NULL,
saved_path TEXT NOT NULL,
file_size INTEGER NOT NULL,
user_id TEXT,
upload_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
2. 完整后端代码(backend.py)
import os
import shutil
import uuid
from datetime import datetime
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import JSONResponse
from fastapi.middleware.cors import CORSMiddleware
import aiosqlite
import sqlite3
# ------------------- 配置 -------------------
UPLOAD_DIR = "./uploaded_files"
DATABASE_PATH = "./upload_records.db"
MAX_FILE_SIZE = 50 * 1024 * 1024 # 50 MB
os.makedirs(UPLOAD_DIR, exist_ok=True)
# ------------------- 初始化 SQLite 数据库(同步,只运行一次)-------------------
def init_db():
conn = sqlite3.connect(DATABASE_PATH)
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS upload_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
original_filename TEXT NOT NULL,
saved_filename TEXT NOT NULL,
saved_path TEXT NOT NULL,
file_size INTEGER NOT NULL,
user_id TEXT,
upload_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
conn.commit()
conn.close()
# ------------------- 异步插入记录 -------------------
async def insert_upload_record(original_filename, saved_filename, saved_path, file_size, user_id=None):
async with aiosqlite.connect(DATABASE_PATH) as db:
await db.execute('''
INSERT INTO upload_records
(original_filename, saved_filename, saved_path, file_size, user_id, upload_time)
VALUES (?, ?, ?, ?, ?, ?)
''', (original_filename, saved_filename, saved_path, file_size, user_id, datetime.now()))
await db.commit()
# ------------------- 创建 FastAPI 应用 -------------------
app = FastAPI(title="文档上传服务")
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.on_event("startup")
async def startup_event():
init_db()
@app.get("/")
async def root():
return {"message": "文档上传服务运行中"}
@app.post("/upload")
async def upload_document(file: UploadFile = File(...), user_id: str = None):
# 1. 检查文件大小
file.file.seek(0, 2)
size = file.file.tell()
if size > MAX_FILE_SIZE:
raise HTTPException(status_code=413, detail=f"文件大小超过 {MAX_FILE_SIZE // (1024*1024)} MB 限制")
file.file.seek(0)
# 2. 生成唯一文件名
original_filename = file.filename
ext = os.path.splitext(original_filename)[1]
unique_filename = f"{uuid.uuid4().hex}{ext}"
save_path = os.path.join(UPLOAD_DIR, unique_filename)
# 3. 保存文件
try:
with open(save_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
except Exception as e:
raise HTTPException(status_code=500, detail=f"文件保存失败: {str(e)}")
# 4. 插入数据库记录
await insert_upload_record(
original_filename=original_filename,
saved_filename=unique_filename,
saved_path=save_path,
file_size=size,
user_id=user_id
)
# 5. 返回成功信息
return JSONResponse(content={
"status": "success",
"message": "文件上传成功",
"original_filename": original_filename,
"saved_filename": unique_filename,
"saved_path": save_path,
"file_size": size,
"user_id": user_id
})
# ------------------- 查询上传记录 -------------------
@app.get("/records")
async def get_records(user_id: str = None, limit: int = 50):
async with aiosqlite.connect(DATABASE_PATH) as db:
if user_id:
cursor = await db.execute('''
SELECT * FROM upload_records WHERE user_id = ? ORDER BY upload_time DESC LIMIT ?
''', (user_id, limit))
else:
cursor = await db.execute('''
SELECT * FROM upload_records ORDER BY upload_time DESC LIMIT ?
''', (limit,))
rows = await cursor.fetchall()
columns = [description[0] for description in cursor.description]
return [dict(zip(columns, row)) for row in rows]
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8001)
代码要点解释:
- 异步数据库操作:使用
aiosqlite,避免阻塞 FastAPI 的事件循环。 - 文件大小检查:通过
seek(0,2)移动指针到末尾获取文件大小,然后seek(0)复位。 - 唯一文件名:使用
uuid.uuid4().hex生成 32 位随机字符串,保留原扩展名。 - 记录查询:支持按
user_id过滤,按上传时间倒序,默认返回最近 50 条。
🎨 前端实现(Streamlit)
前端增加:
- 用户 ID 输入框(模拟登录用户)
- 显示上传记录按钮
import streamlit as st
import requests
API_URL = "http://localhost:8001/upload"
RECORDS_URL = "http://localhost:8001/records"
st.set_page_config(page_title="文档上传工具", page_icon="📄")
st.title("📄 文档上传到后端服务器")
# 用户标识
user_id = st.text_input("用户ID(用于标识上传者)", value="guest")
# 文件上传组件
uploaded_file = st.file_uploader("选择文件", type=None)
if uploaded_file is not None:
st.write(f"**文件名:** {uploaded_file.name}")
st.write(f"**文件大小:** {uploaded_file.size} 字节")
st.write(f"**文件类型:** {uploaded_file.type}")
if st.button("上传到服务器"):
files = {"file": (uploaded_file.name, uploaded_file.getvalue(), uploaded_file.type)}
data = {"user_id": user_id}
try:
with st.spinner("上传中..."):
response = requests.post(API_URL, files=files, data=data)
if response.status_code == 200:
resp_data = response.json()
st.success("✅ 上传成功!")
st.json(resp_data)
else:
st.error(f"❌ 上传失败: {response.status_code} - {response.text}")
except Exception as e:
st.error(f"❌ 连接后端失败: {e}")
# 显示历史记录
st.markdown("---")
if st.button("显示我的上传记录"):
try:
params = {"user_id": user_id} if user_id else {}
resp = requests.get(RECORDS_URL, params=params)
if resp.status_code == 200:
records = resp.json()
if records:
st.write("### 📋 上传记录")
for rec in records:
st.markdown(
f"- **{rec['original_filename']}** (保存为 `{rec['saved_filename']}`) \n"
f" 上传时间: {rec['upload_time']} | 大小: {rec['file_size']} 字节"
)
else:
st.info("暂无上传记录")
else:
st.error("获取记录失败")
except Exception as e:
st.error(f"连接失败: {e}")
前端改进点:
- 用户 ID 通过
data参数作为表单字段提交,后端通过user_id: str = None接收。 - 查询记录时携带
user_id参数,返回该用户的所有上传历史。
🚀 运行与测试
启动后端
python backend.py
默认运行在 http://0.0.0.0:8001
启动前端
streamlit run frontend.py
访问 http://localhost:8501
测试流程
- 在用户 ID 输入框中输入
test_user。 - 选择一个文件上传。
- 点击“显示我的上传记录”查看该用户的所有上传历史。
- 可以切换不同用户 ID 测试隔离性。
验证数据库
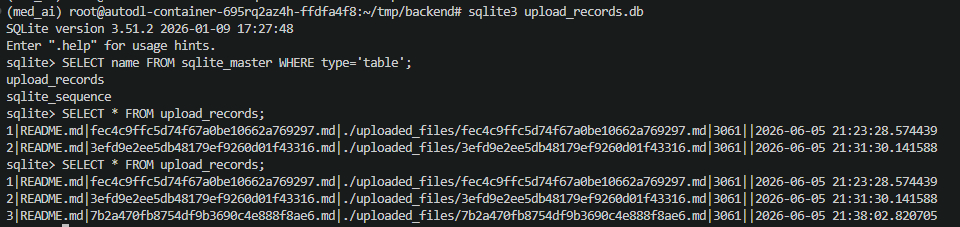
使用命令行工具检查数据:
sqlite3 upload_records.db "SELECT * FROM upload_records;"
🧠 面试官常见问题 & 回答策略
Q1:为什么选择 SQLite 而不是其他数据库(如 PostgreSQL、MySQL)?
回答:SQLite 是嵌入式数据库,无需单独部署服务,适合原型开发、轻量级应用和单机场景。它的文件存储方式使得迁移和备份非常简单。在本项目中,为了演示快速搭建,SQLite 是理想选择。如果未来需要高并发、多写入或分布式部署,可以无缝迁移到 PostgreSQL(只需更改连接字符串和驱动)。
Q2:为什么需要异步数据库操作(aiosqlite)?直接使用 sqlite3 可以吗?
回答:FastAPI 是基于 ASGI 的异步框架,如果使用同步的 sqlite3 库进行数据库操作,会阻塞整个事件循环,降低并发处理能力。使用 aiosqlite 可以将数据库操作委托给线程池,释放事件循环,从而保持高并发性能。在文件上传这种涉及 I/O 操作的场景中,异步尤为重要。
Q3:如何防止文件上传时的安全风险(例如恶意文件、路径遍历攻击)?
回答:我们可以采取以下措施:
- 文件类型白名单:检查
file.content_type或扩展名,只允许特定类型(如application/pdf、image/jpeg)。 - 重命名文件:使用
uuid重命名,避免用户提供的文件名包含../等路径穿越字符。 - 限制文件大小:在接收完整文件前检查
Content-Length或流式读取部分字节。 - 病毒扫描:可集成 ClamAV 等扫描服务。
- 隔离存储:将文件保存在非 Web 可访问的目录,通过授权接口访问。
Q4:如何处理大文件上传(例如超过 1GB)?当前代码有什么瓶颈?
回答:当前代码将整个文件读入内存(file.file.read() 实际上在 shutil.copyfileobj 中是以块的形式写入,内存友好)。但 shutil.copyfileobj 是同步的,可能阻塞事件循环。对于超大文件,建议:
- 使用 分块上传(前端分片,后端合并)。
- 使用 流式上传(后端直接写入磁盘,不缓存到内存)。
- 使用 异步文件写入(如
aiofiles)避免阻塞。
当前代码对大文件(< 100 MB)性能尚可,超过该范围需要优化。
Q5:如何设计用户认证?代码中的 user_id 是明文传输,如何保证安全?
回答:生产环境不应依赖明文 user_id。应该集成 OAuth2 或 JWT 认证:
- 用户登录后获得一个签名 Token。
- 前端在请求头中携带
Authorization: Bearer <token>。 - 后端验证 Token 后从中解析出
user_id,而不是从表单参数获取。
这可以防止用户伪造身份。
Q6:如何实现上传进度条?Streamlit 能做到吗?
回答:Streamlit 原生不支持文件上传进度条。但可以通过以下方式模拟:
- 使用
st.progress结合requests的流式上传(需要分块并计算进度)。 - 或使用其他前端框架(如 React + FastAPI)实现更精细的进度控制。
对于简单场景,Streamlit 的st.spinner已足够。
Q7:你如何测试文件上传接口?包括单元测试和集成测试。
回答:可以使用 FastAPI 提供的 TestClient 进行测试:
from fastapi.testclient import TestClient
from backend import app
client = TestClient(app)
def test_upload():
with open("test.txt", "rb") as f:
response = client.post("/upload", files={"file": ("test.txt", f)}, data={"user_id": "tester"})
assert response.status_code == 200
assert response.json()["original_filename"] == "test.txt"
集成测试可以启动后端和前端真实服务,使用 requests 库模拟用户行为。
Q8:如果并发上传大量文件,SQLite 能否承受?如何优化?
回答:SQLite 在默认配置下写并发性能较差(写锁会阻塞其他写操作)。优化方法:
- 启用 WAL 模式:
PRAGMA journal_mode=WAL; - 增加缓存大小:
PRAGMA cache_size=-20000; - 使用连接池(
aiosqlite默认支持连接复用)。
如果并发要求很高(> 100 写请求/秒),应迁移到 PostgreSQL 或 MySQL。
🎯 总结与扩展
通过本文,你学会了:
- ✅ 在 FastAPI 中集成 异步 SQLite 数据库,记录文件上传历史。
- ✅ 使用 Streamlit 构建带用户标识和记录查询的前端界面。
- ✅ 应对面试官关于文件上传、数据库安全、性能优化的常见问题。
可以进一步扩展的功能:
- 使用
aiofiles异步写入磁盘,进一步提升并发性能。 - 集成 JWT 认证,保护上传和查询接口。
- 添加文件检索功能(按文件名、时间范围搜索)。
- 对接云存储(阿里云 OSS、MinIO)实现分布式存储。
- 提供文件下载接口,并通过数据库路径定位文件。
这套系统可作为文档管理平台、RAG 知识库上传组件的基础,希望对你有所帮助!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)