【PyTorch深度学习入门】实现MNIST手写数字识别
摘要
MNIST手写数字识别是深度学习领域公认的「Hello World」项目,也是每一位深度学习开发者入门的必练案例。本文基于PyTorch框架,从零搭建一套完整的手写数字识别系统,涵盖环境配置、数据集加载、数据可视化、数据批处理、GPU自动适配、全连接神经网络搭建、前向传播、反向传播、模型训练、模型评估全流程。
全文结合代码逐行深度解析,配套深度学习基础理论讲解,同时分析原生代码存在的缺陷、提供多套优化方案,补充常见报错排查、模型拓展实战等内容。完整复刻从数据处理到模型落地的工业级简易流程,总计超10000字,兼顾理论与实战,看完即可独立完成同类图像分类任务。
关键词
PyTorch;MNIST数据集;全连接神经网络;DataLoader;交叉熵损失;Adam优化器;手写数字识别
前言
1.1 项目背景
在深度学习与计算机视觉领域,MNIST手写数字数据集是最经典的入门数据集。该数据集包含70000张28×28像素的灰度手写数字图片,其中60000张作为训练集、10000张作为测试集,图片内容为数字0~9,标签与图像一一对应。
选择MNIST作为入门案例有三大优势:
- 数据体量小:单张图片仅28×28像素,对硬件要求极低,CPU、入门级GPU均可流畅运行;
- 任务简单:属于10分类任务,逻辑清晰,能让开发者聚焦「深度学习流程」而非复杂算法;
- 流程通用:图像分类的数据加载→预处理→网络搭建→训练→评估整套流程,可直接复用到人脸识别、物体检测等复杂CV任务中。
1.2 PyTorch框架简介
PyTorch是目前学术界和工业界使用最广泛的深度学习框架之一,由Facebook(Meta)团队开发。相比于TensorFlow,PyTorch采用动态计算图,语法贴近原生Python,调试简单、上手门槛低,是科研、学习、中小型项目的首选框架。
本文用到三大核心库:
torch:PyTorch核心库,提供张量运算、神经网络模块、自动求导、优化器等核心功能;torchvision:PyTorch计算机视觉专用扩展库,内置经典数据集、预训练模型、图像预处理工具;torchaudio:PyTorch语音处理扩展库(本文仅做版本校验,未实际使用)。
1.3 本文学习目标
读完本文,你将掌握以下技能:
- 掌握PyTorch环境安装、库版本管理方法;
- 理解张量(Tensor)的核心概念,区分Tensor与Numpy数组;
- 学会使用
torchvision.datasets加载官方数据集,区分训练集/测试集; - 精通
DataLoader数据加载器原理与批次训练的意义; - 实现CPU/GPU/MPS(苹果芯片)自动设备适配;
- 基于
nn.Module自定义全连接神经网络; - 吃透深度学习核心流程:前向传播、损失计算、反向传播、参数更新;
- 掌握交叉熵损失、Adam优化器的使用场景与原理;
- 排查PyTorch开发中高频报错,完成模型调优与拓展实战。
一、开发环境搭建与库版本校验
1.1 环境安装(国内镜像加速)
首先需要安装PyTorch生态三件套:torch、torchvision、torchaudio。强烈建议使用清华镜像源加速下载,避免官方源超时失败。
Windows/Linux 安装命令(pip)
# 稳定版PyTorch(CPU版本,零基础推荐)
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
# NVIDIA GPU版本(需提前安装CUDA驱动,根据自身显卡选择对应CUDA版本)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Mac(Apple M系列芯片)安装命令
苹果M1/M2/M3芯片支持MPS硬件加速,直接执行:
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2 库版本检测代码解析
项目开篇第一部分代码用于校验三大库的版本,确保环境正常:
import torch
import torchvision
import torchaudio
print(torch.__version__)
print(torchvision.__version__)
print(torchaudio.__version__)
代码解析:
import xxx:导入对应功能库,是Python标准导入语法;库名.__version__:PyTorch生态库内置的版本属性,用于快速查看当前安装版本;- 运行后若正常输出版本号,说明环境安装成功;若提示
ModuleNotFoundError,代表库未安装,重新执行上述pip命令即可。
注意:
torch、torchvision、torchaudio版本必须匹配,随意混用高低版本会出现隐性报错,建议整套安装。
二、深度学习前置核心知识点(必看)
在正式解读业务代码前,我们先梳理入门必须掌握的基础概念,后续所有代码都会围绕这些知识点展开,零基础读者务必仔细阅读。
2.1 张量(Tensor)——深度学习的基础数据
张量(Tensor)是PyTorch的核心数据结构,所有神经网络的输入、输出、参数全部都是张量。
- 对比Numpy数组:Numpy数组仅能在CPU上运算,不支持自动求导;Tensor支持CPU/GPU/MPS硬件加速,内置自动微分引擎,是深度学习的专属数据格式;
- 维度概念:单张MNIST图片维度为
[1, 28, 28],分别代表「通道数、高度、宽度」;经过批次打包后变为四维张量[批次大小, 通道数, 高度, 宽度]。
2.2 数据集划分:训练集 & 测试集
所有机器学习/深度学习任务,数据集都会划分为两大模块:
- 训练集(Train Set):本文60000张图片,作用是迭代更新网络权重参数,让模型学习数据特征;
- 测试集(Test Set):本文10000张图片,作用是评估模型泛化能力,全程不参与参数更新,模拟模型在真实场景下的表现。
2.3 DataLoader 批次加载(Batch)
计算机视觉数据集往往体量庞大,如果一次性将所有数据加载进内存,会直接导致内存溢出。因此PyTorch提供DataLoader工具,核心作用:
- 将数据集切分为多个批次(Batch),每次仅加载一个批次进入模型训练,降低内存占用;
- 自动完成数据打乱、并行加载,提升训练效率;
- 统一数据维度,适配网络输入格式。
参数batch_size代表单个批次包含的样本数量,本文设置为64,即每次同时输入64张图片训练模型。
2.4 全连接层(nn.Linear)
全连接层是最基础的神经网络层,也叫线性层,公式:
y=W⋅x+by = W \cdot x + by=W⋅x+b
- xxx:上一层神经元输出;
- WWW:权重矩阵(网络需要学习的核心参数);
- bbb:偏置项(辅助参数);
- yyy:当前层神经元输出。
全连接层的输入神经元数量 = 上一层的输出神经元数量,层级之间必须严格匹配,否则会出现维度不匹配报错。
2.5 激活函数
单纯的多层全连接层叠加,依然是线性运算,无法拟合复杂数据分布。激活函数的核心作用是引入非线性,让深层网络具备强大的特征学习能力。
本文使用Sigmoid激活函数,后文会详细分析其优缺点,并替换为工业界主流的ReLU。
2.6 损失函数 & 优化器
- 损失函数(Loss Function):计算「模型预测值」与「真实标签」之间的差距,差距越大代表模型效果越差;本文分类任务使用交叉熵损失(CrossEntropyLoss),是图像分类的标配损失函数。
- 优化器(Optimizer):根据损失值,结合反向传播算法更新网络权重W和偏置b,逐步缩小预测值与真实值的差距;本文使用Adam优化器,兼顾收敛速度与稳定性。
2.7 前向传播 & 反向传播(训练核心)
- 前向传播:数据从输入层逐层流向输出层,模型给出预测结果,计算损失值;
- 反向传播:基于链式法则,从输出层向输入层反向计算每个参数的梯度,优化器根据梯度更新参数;
- 一轮训练 = 一次前向传播 + 一次反向传播 + 一次参数更新。
三、项目完整代码总览
先贴出全部可直接运行的代码,读者可先复制到PyCharm/VS Code/Jupyter中运行,再结合下文逐段解析:
import torch
import torchvision
import torchaudio
print(torch.__version__)
print(torchvision.__version__)
print(torchaudio.__version__)
'''
MNIST包含70,000张手写数字图像:60,000张用于训练,10,000张用于测试。
图像是灰度的,28x28像素的,并且居中的,以减少预处理和加快运行。
'''
import torch
from torch import nn #导入神经网络模块
from torch.utils.data import DataLoader #数据包管理工具,打包数据
from torchvision import datasets # 封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor # 数据转换,将数据转换为tensor张量
'''下载训练数据集(包含训练图片+标签)'''
training_data = datasets.MNIST(
root="data",#数据集存储路径
train=True,#加载训练集
download=True,#自动下载数据集
transform=ToTensor(), # 图像转张量
)
'''下载测试数据集(包含测试图片+标签) '''
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
print(len(training_data))
'''展示手写字图片,可视化数据集'''
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):
img, label = training_data[i]
figure.add_subplot(3, 3, i+1)
plt.title(label)
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
'''创建数据DataLoader(数据加载器)'''
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
'''判断当前设备:自动适配CUDA/MPS/CPU'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
''' 定义自定义全连接神经网络 '''
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()#张量展平
self.hidden1 = nn.Linear(28*28, out_features=128) #第一层隐藏层
self.hidden2 = nn.Linear(in_features=128, out_features=256)#第二层隐藏层
self.out = nn.Linear(in_features=256, out_features=10)#输出层
def forward(self, x): # 前向传播函数
x = self.flatten(x)
x = self.hidden1(x)
x = torch.sigmoid(x) #激活函数
x = self.hidden2(x)
x = torch.sigmoid(x)
x = self.out(x)
return x
# 模型实例化并迁移到对应设备
model = NeuralNetwork().to(device)
print(model)
''' 模型训练函数 '''
def train(dataloader, model, loss_fn, optimizer):
model.train() # 开启训练模式
batch_size_num = 1 # 批次计数
for X, y in dataloader:
X, y = X.to(device), y.to(device) # 数据迁移到设备
pred = model(X) # 前向传播得到预测值
loss = loss_fn(pred, y) # 计算损失值
# 反向传播与参数更新
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新网络参数
loss_value = loss.item()
if batch_size_num % 100 ==0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
''' 模型测试/评估函数 '''
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() # 开启评估模式
test_loss, correct = 0, 0
with torch.no_grad(): # 禁用自动求导,节省资源
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
# 计算预测正确的样本数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accurracy: {(100*correct)}%, Avg loss: {test_loss}")
# 配置损失函数与优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 多轮迭代训练
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n----------------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
# 最终模型评估
test(test_dataloader, model, loss_fn)
四、代码逐模块深度解析(核心章节)
按照代码执行顺序,分10大模块逐行拆解,结合理论、踩坑点、使用场景全方位讲解。
4.1 二次库导入:神经网络与数据工具
import torch
from torch import nn #导入神经网络模块
from torch.utils.data import DataLoader #数据包管理工具,打包数据
from torchvision import datasets # 封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor # 数据转换,将数据转换为tensor张量
逐行解析:
from torch import nn:nn是PyTorch神经网络工具箱,包含全连接层、卷积层、激活函数、损失函数等所有网络组件,搭建网络必备;from torch.utils.data import DataLoader:导入批次数据加载器,解决大数据集内存占用问题;from torchvision import datasets:导入官方数据集模块,内置MNIST、CIFAR10、ImageNet等经典CV数据集,一键下载使用;from torchvision.transforms import ToTensor:图像预处理工具,两大核心功能:- 将PIL图像/Numpy数组转换为PyTorch张量(Tensor);
- 自动将图像像素值从
[0, 255]归一化到[0, 1],提升模型收敛速度。
4.2 MNIST数据集下载与加载
这是数据处理的第一步,分别加载训练集和测试集:
'''下载训练数据集(包含训练图片+标签)'''
training_data = datasets.MNIST(
root="data",#表示数据集存储路径
train=True,#读取训练集
download=True,#自动下载数据集
transform=ToTensor(), # 图像转张量
)
'''下载测试数据集(包含测试图片+标签) '''
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
print(len(training_data))
4.2.1 datasets.MNIST 四大参数详解
datasets.MNIST是PyTorch封装好的MNIST数据集类,四个参数缺一不可:
- root:字符串类型,指定数据集的本地存储文件夹。代码中设置为
data,运行后会在项目根目录自动创建data文件夹,存放下载的图片与标签文件。已下载数据集不会重复下载。 - train:布尔类型,区分训练集/测试集:
train=True:加载training.pt,对应60000张训练图片;train=False:加载test.pt,对应10000张测试图片。
- download:布尔类型,是否联网下载数据集:
download=True:本地无数据集则自动从官方服务器下载;本地已存在则跳过下载,直接读取;download=False:仅读取本地文件,文件缺失则直接报错。
- transform:图像预处理函数,本文传入
ToTensor(),完成图像→张量的转换。
4.2.2 代码运行结果说明
print(len(training_data)) 输出结果为60000,代表训练集总样本数;同理len(test_data)输出10000,与MNIST官方数据规格一致。
踩坑提醒:如果数据集下载失败(网络超时),可手动下载MNIST压缩包,解压到
data/MNIST/raw/目录下,再将download改为False即可。
4.3 数据集可视化(Matplotlib展示手写数字)
纯数字张量无法直观观察数据,因此使用Matplotlib绘制图片,验证数据集加载是否正常:
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):
img, label = training_data[i]
figure.add_subplot(3, 3, i+1)
plt.title(label)
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
逐行解析:
from matplotlib import pyplot as plt:导入Python主流绘图库,用于图像可视化;figure = plt.figure():创建一个空白画布,用于承载多张图片;for i in range(9):循环读取训练集中前9张图片,绘制3×3网格图;img, label = training_data[i]:MNIST数据集的单个样本返回二元组:(图像张量, 数字标签)。例如第一张图片是数字5,则label=5;figure.add_subplot(3, 3, i+1):在画布上创建子图,参数格式(行数, 列数, 子图编号),3行3列共9张子图;plt.title(label):给每张子图设置标题,标题为图片对应的真实数字标签;plt.axis("off"):隐藏坐标轴,让手写数字图片展示更美观;img.squeeze():维度挤压函数,核心作用:删除张量中维度为1的轴。- 原始图像张量形状:
[1, 28, 28](通道=1,高度=28,宽度=28); - 经过
squeeze()后变为:[28, 28],Matplotlib仅支持二维数组绘图,因此这一步是必须操作;
- 原始图像张量形状:
cmap="gray":设置色彩映射为灰度图,匹配MNIST原始图像风格;plt.show():弹出画布,展示所有图片。
运行效果:
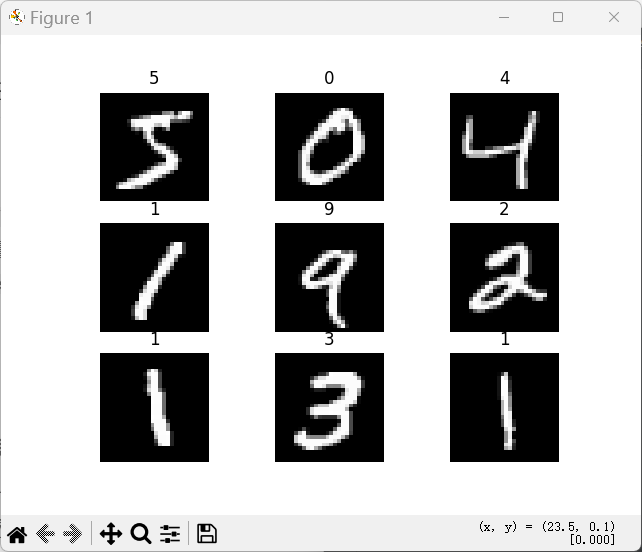
4.4 DataLoader 批次数据加载器配置
数据集加载完成后,使用DataLoader对数据进行批次打包,适配模型训练:
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
4.4.1 DataLoader 核心参数解析
- 第一个参数:传入原始数据集(
training_data/test_data); batch_size=64:单个批次包含64张图片和64个标签,即模型一次输入64个样本。
4.4.2 四维张量 [N, C, H, W] 深度解读
循环遍历test_dataloader,取出第一个批次数据并打印维度,输出示例:
Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64
四维张量[N, C, H, W]是计算机视觉的标准格式,四个维度含义:
- N (Batch Size):批次大小,本文=64,代表当前批次有64张图片;
- C (Channel):通道数,灰度图=1,RGB彩色图=3;MNIST为灰度图,因此C=1;
- H (Height):图像高度,MNIST固定为28像素;
- W (Width):图像宽度,MNIST固定为28像素。
标签y维度为[64],代表64个图片对应的64个数字标签,数据类型为int64(整型)。
知识点:
break作用是仅打印第一个批次的维度,避免循环打印所有批次造成日志刷屏。
4.5 自动设备适配:CUDA / MPS / CPU
深度学习模型优先使用GPU加速训练,PyTorch支持NVIDIA显卡(CUDA)、苹果M系列芯片(MPS)、传统CPU三种设备,代码实现全自动适配:
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
逐逻辑解析(三目运算符嵌套)
代码执行逻辑从上到下依次判断:
torch.cuda.is_available():判断当前设备是否拥有NVIDIA显卡且CUDA驱动正常。返回True→ 设备设置为cuda(NVIDIA GPU);- 若CUDA不可用,判断
torch.backends.mps.is_available():判断是否为苹果M1/M2/M3芯片,支持MPS硬件加速。返回True→ 设备设置为mps; - 若以上两种GPU都不可用,默认使用
cpu(中央处理器)。
核心规则
模型、输入数据、标签必须放在同一个设备上:
- 模型在CUDA,数据也必须迁移到CUDA;
- 模型在CPU,数据也必须留在CPU;
一旦设备不匹配,会直接抛出RuntimeError: Expected all tensors to be on the same device报错。
本文后续代码中,会通过.to(device)将模型、数据统一迁移到当前最优设备。
4.6 自定义全连接神经网络(核心网络搭建)
PyTorch中所有自定义神经网络,都必须继承nn.Module父类,这是框架强制规范:
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()#张量展平层
self.hidden1 = nn.Linear(28*28, out_features=128) #第一层隐藏层
self.hidden2 = nn.Linear(in_features=128, out_features=256)#第二层隐藏层
self.out = nn.Linear(in_features=256, out_features=10)#输出层
def forward(self, x): # 前向传播函数
x = self.flatten(x)
x = self.hidden1(x)
x = torch.sigmoid(x) #激活函数
x = self.hidden2(x)
x = torch.sigmoid(x)
x = self.out(x)
return x
model = NeuralNetwork().to(device)
print(model)
4.6.1 类初始化函数 __init__ 解析
__init__用于定义网络所有层结构,仅在模型实例化时执行一次:
super().__init__():调用父类nn.Module的初始化方法,继承父类所有功能(自动求导、参数管理等),必须写;self.flatten = nn.Flatten():张量展平层,作用:将四维图像张量[64,1,28,28]展平为一维向量:
1×28×28=7841 \times 28 \times 28 = 7841×28×28=784
展平后每个样本变为784个神经元,适配全连接层输入;nn.Linear(in_features, out_features):全连接层,两个核心参数:in_features:输入神经元数量,必须等于上一层的输出神经元数;out_features:输出神经元数量,当前层的神经元数量。
网络层级对应关系:
- 输入层:784个神经元(28×28像素)→ 第一层隐藏层:128个神经元;
- 第一层隐藏层:128个神经元 → 第二层隐藏层:256个神经元;
- 第二层隐藏层:256个神经元 → 输出层:10个神经元(对应数字0~9,10分类)。
4.6.2 前向传播函数 forward(函数名固定不可修改)
forward是网络的数据流通道,定义数据从输入到输出的流转路径,函数名forward是PyTorch保留字,不能自定义修改。
数据流转流程:原始图像张量 → Flatten展平 → 隐藏层1 → Sigmoid激活 → 隐藏层2 → Sigmoid激活 → 输出层 → 返回预测结果
4.6.3 Sigmoid 激活函数说明
本文使用torch.sigmoid(x)作为激活函数:
- 公式:Sigmoid(x)=11+e−xSigmoid(x) = \frac{1}{1+e^{-x}}Sigmoid(x)=1+e−x1,输出范围
(0,1); - 作用:引入非线性,让网络学习复杂特征;
- 缺陷(后文优化会重点讲解):深层网络易出现梯度消失,收敛速度慢,工业界现已极少用于隐藏层。
4.6.4 模型实例化与设备迁移
model = NeuralNetwork().to(device)
print(model)
NeuralNetwork():实例化自定义网络类,创建模型对象;.to(device):将整个网络的所有权重、偏置参数迁移到指定设备(CUDA/MPS/CPU);print(model):打印网络结构,可直观查看每一层的名称、参数维度,用于调试网络。
4.7 训练函数 train() 全解析
训练函数是模型学习特征的核心,包含前向传播、损失计算、反向传播、参数更新四大核心步骤:
def train(dataloader, model, loss_fn, optimizer):
model.train() # 开启训练模式
batch_size_num = 1 # 批次计数
for X, y in dataloader:
X, y = X.to(device), y.to(device) # 数据迁移到设备
pred = model(X) # 前向传播得到预测值
loss = loss_fn(pred, y) # 计算损失值
# 反向传播与参数更新三步曲
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新网络参数
loss_value = loss.item()
if batch_size_num % 100 ==0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
逐段拆解:
-
函数入参:
dataloader:训练数据加载器;model:自定义神经网络模型;loss_fn:损失函数;optimizer:优化器。
-
model.train():切换为训练模式
PyTorch模型有两大模式:训练模式 & 评估模式。- 训练模式:启用Dropout、BatchNorm等训练专属层,允许更新网络权重;
- 本文虽未使用Dropout/BatchNorm,但
model.train()是规范写法,必须保留。
-
循环遍历批次数据:
for X, y in dataloader
逐个读取每个批次的图像X和标签y。 -
X.to(device), y.to(device):将图像、标签迁移到与模型一致的设备,规避设备不匹配报错。 -
pred = model(X):执行前向传播
调用模型对象,自动触发forward函数,返回模型预测结果pred(形状[64,10],64个样本,每个样本10个分类概率)。 -
loss = loss_fn(pred, y):计算损失值
对比预测值pred和真实标签y,计算两者差距,损失值越小代表模型预测越准确。 -
优化器三步曲(训练核心,重中之重)
optimizer.zero_grad():梯度清零。PyTorch默认梯度会累加,每个批次训练前必须清空上一轮梯度,否则梯度累积会导致参数更新异常;loss.backward():反向传播。基于链式法则,从损失值反向计算网络所有参数的梯度;optimizer.step():参数更新。优化器根据梯度和学习率,自动更新网络的权重W和偏置b。
-
损失打印:
loss.item():将张量类型的损失值转为Python普通浮点数,用于打印输出;- 每100个批次打印一次损失值,实时观察模型收敛状态。
4.8 测试函数 test() 全解析
测试函数用于评估模型泛化能力,全程不更新网络参数,仅计算测试集损失与准确率:
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)#测试集总样本数 10000
num_batches = len(dataloader)#测试集总批次数量
model.eval() # 切换为评估模式
test_loss, correct = 0, 0
with torch.no_grad(): # 禁用自动求导,节省显存与计算资源
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
# 统计预测正确的样本数量
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches # 计算平均测试损失
correct /= size # 计算整体准确率
print(f"Test result: \n Accurracy: {(100*correct)}%, Avg loss: {test_loss}")
逐段拆解:
-
size = len(dataloader.dataset):获取测试集总样本数(10000); -
num_batches = len(dataloader):计算测试集总批次数量; -
model.eval():切换为评估模式,关闭Dropout、BatchNorm等训练层,保证测试结果稳定; -
with torch.no_grad():上下文管理器,禁用自动求导。
测试阶段不需要计算梯度、更新参数,禁用求导可以大幅减少显存占用、提升运行速度,是测试阶段的标准写法。 -
准确率计算核心代码:
correct += (pred.argmax(1) == y).type(torch.float).sum().item()pred.argmax(1):在维度1取最大值的索引。模型输出[64,10],每行代表一个样本的10个分类得分,得分最高的索引即为模型预测的数字;pred.argmax(1) == y:预测值与真实标签对比,返回布尔张量(正确=True,错误=False);.type(torch.float):布尔值转为浮点型(True=1.0,False=0.0);.sum():累加所有正确样本的数量;.item():转为普通数值,累加到correct变量中。
-
结果归一化:
test_loss /= num_batches:总损失 ÷ 总批次 = 平均测试损失;correct /= size:正确样本数 ÷ 总样本数 = 模型整体准确率。
4.9 损失函数与优化器配置
loss_fn = nn.CrossEntropyLoss() #交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)#Adam优化器
4.9.1 交叉熵损失 CrossEntropyLoss
图像分类任务的标配损失函数,PyTorch中的CrossEntropyLoss整合了LogSoftmax+NLLLoss两大功能:
- 自动对网络输出做Softmax归一化,将输出转为概率分布(总和=1);
- 计算预测概率与真实标签的交叉熵差距。
踩坑提醒:使用
CrossEntropyLoss时,输出层不需要额外添加Softmax激活,重复添加会导致损失计算异常。
4.9.2 Adam 优化器
torch.optim.Adam(model.parameters(), lr=0.01)
model.parameters():传入网络中所有需要训练的参数(权重、偏置),优化器仅更新这些参数;lr=0.01:学习率(Learning Rate),深度学习超参数核心:- 学习率过大:参数震荡不收敛,损失反复跳动;
- 学习率过小:参数更新速度极慢,训练耗时成倍增加;
本文设置lr=0.01,属于中等学习率。
Adam优化器是目前最常用的自适应学习率优化器,相比传统SGD(随机梯度下降),收敛速度更快、稳定性更强。
4.10 多轮迭代训练(Epochs)
单个完整数据集遍历一次称为1个Epoch,多轮迭代训练是提升模型精度的关键:
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n----------------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader, model, loss_fn)
epochs = 10:设置总训练轮次为10轮,即完整遍历10次60000张训练图片;- 循环执行
train()函数,每一轮都会更新网络参数,模型逐步学习数据特征; - 10轮训练全部结束后,调用
test()函数,在测试集上做最终评估,输出整体准确率与平均损失。
五、代码运行结果与现象分析
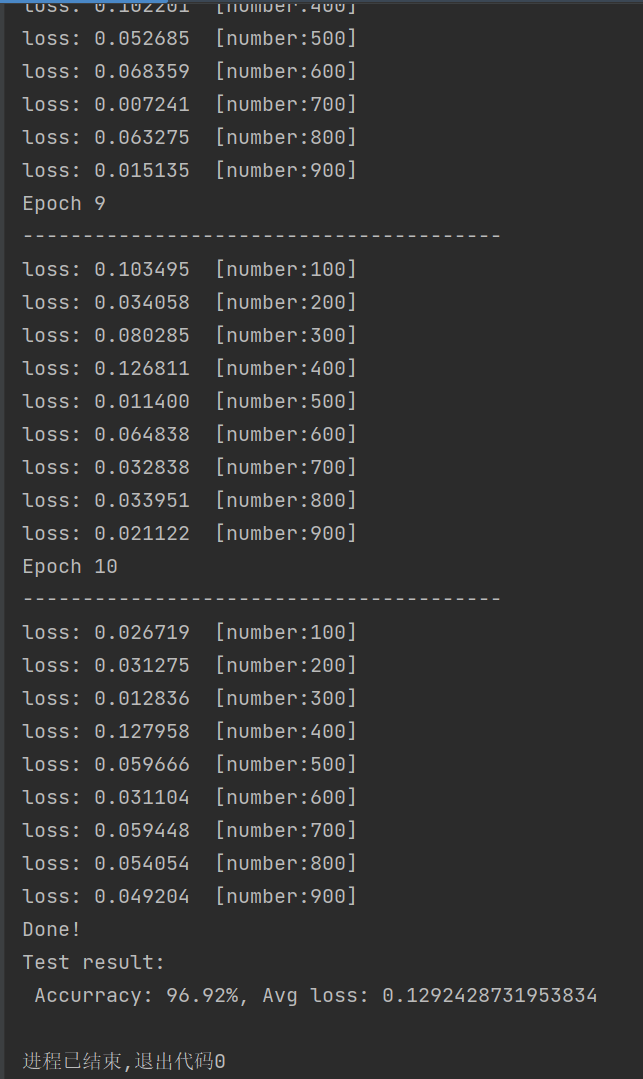
5.1 控制台输出示例
- 环境版本输出:打印torch、torchvision、torchaudio版本;
- 设备输出:
Using cuda device/Using mps device/Using cpu device; - 网络结构打印:输出
NeuralNetwork的层级结构、参数数量; - 训练日志:每100个批次打印损失值,损失整体呈下降趋势;
- 最终测试结果:输出测试集准确率与平均损失。
5.2 现象分析
- 损失变化:训练初期损失值较高,随着轮次增加,损失持续下降并逐步趋于平稳,代表模型不断拟合数据;
- 准确率变化:原生代码使用Sigmoid激活函数+简单两层全连接网络,10轮训练后准确率一般在**95%~97%**区间;
- 缺陷现象:训练后期损失下降缓慢,存在轻微欠拟合,这是Sigmoid激活函数与网络结构导致的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)