【Redis合集-04】Redis 单线程模型深度拆解:事务、管道、Lua 与大 Key 治理
目录
1. Redis 各版本线程模型的实际变迁
| 版本 | 命令执行线程 | 后台辅助线程 | 网络 IO 线程 |
|---|---|---|---|
| < 4.0 | 纯单线程 | 无 | 无 |
| 4.0 | 单线程 | 有(异步删除等场景) | 无 |
| 6.0/7.0 | 单线程 | 有 | 有(多线程 IO) |
命令的执行永远在单线程里串行进行。 这个设计贯穿了 Redis 整个并发模型的始终。
-
4.0 之前,确实只有一个线程,从网络读取到命令执行到响应写回,全部自己干。遇到删除大键这类耗时操作时,会直接把整个实例卡住。
-
4.0 开始引入了后台线程(
bio),专门负责内存释放这类繁重的工作,比如UNLINK。但命令执行本身依旧单线程。 -
6.0 / 7.0 更进一步,把网络协议的解析和 socket 数据搬运分摊给多个 IO 线程,而最终的键值读写、数据结构操作仍旧集中在主线程中顺序执行。
2. 单线程支撑高并发
单线程能扛住高负载,核心靠的是非阻塞 IO 和 IO 多路复用。
2.1 非阻塞 IO
Redis 为每个客户端连接套接字设置 O_NONBLOCK 标志。这样调用 read() 时,如果 socket 缓冲区没有数据,内核不会让线程挂起等待,而是立即返回 EAGAIN。Redis 主线程可以毫不费力地去检查其他连接。
2.2 epoll 多路复用
如果没有多路复用,主线程就需要轮询所有 socket,上万连接轮一遍 CPU 就耗光了。Linux 的 epoll 机制解决了这个问题:
-
Redis 把所有客户端 socket 的文件描述符注册到 epoll 实例中。
-
主线程调用
epoll_wait()等待事件,直到有 socket 变为可读或可写。 -
epoll 只返回“就绪”的 socket 列表,Redis 只处理这些活跃连接。
简单类比:一个服务员要同时照看 100 桌客人。如果他每隔几秒去每桌问一次“要点菜吗”,就算跑断腿也服务不了几桌;但如果每张桌子都有个呼叫按钮,他只需在吧台看哪个指示灯亮,就去哪桌,效率天差地别。
2.3 事件循环骨架
Redis 服务端的核心就是一个不断循环的事件处理引擎,伪代码大致如下:
while (1) {
// 1. 阻塞等待 epoll 返回就绪事件
int numevents = aeApiPoll(eventLoop, tvp);
for (int i = 0; i < numevents; i++) {
int fd = eventLoop->fired[i].fd; // 就绪的文件描述符
int mask = eventLoop->fired[i].mask; // 事件类型(可读/可写)
if (mask & AE_READABLE) {
// 有客户端发来命令,读取并执行
fe->rfileProc(eventLoop, fd, fe->clientData, mask);
}
if (mask & AE_WRITABLE) {
// 可以向客户端写回结果
fe->wfileProc(eventLoop, fd, fe->clientData, mask);
}
}
}重点在于:rfileProc 内部会解析命令、查找键、执行修改,这些操作对于所有客户端来说都是串行化的。一个命令的执行过程不会掺杂进任何其他客户端的命令。
3. 命令排队:单线程的执行模型
当多个客户端同时发送请求时,服务器端的情况可以这样理解:
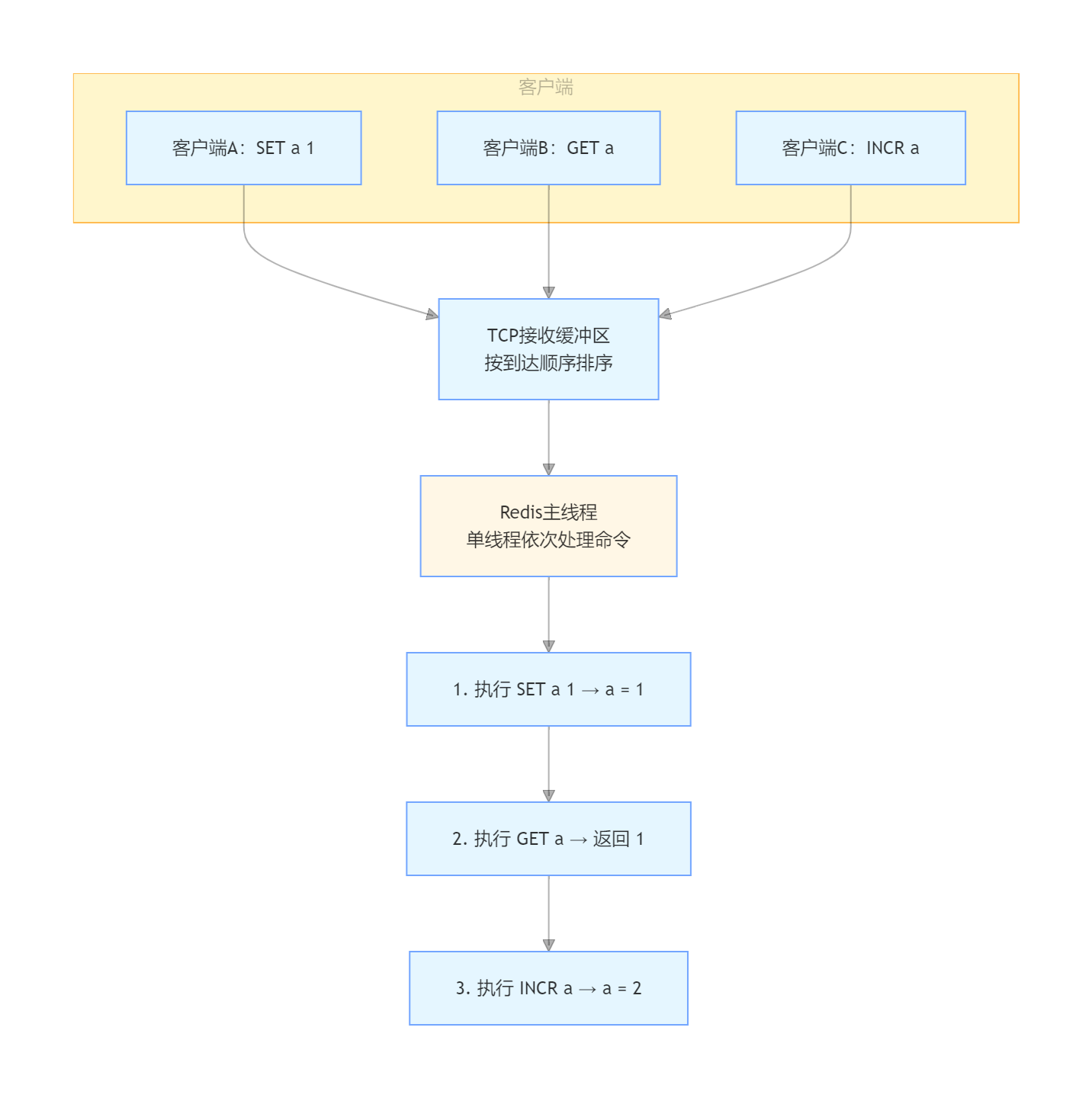
“一个命令没执行完,下一个命令不会开始”,这是 Redis 所有并发语义的基石。
锁是不需要的;上下文切换是不存在的。但也意味着,如果某个命令执行耗时 200 毫秒,这 200 毫秒内所有其他请求都会被阻塞。
4. Redis 事务的原子性来源
既然单线程保证命令不会交叉执行,那么把一组命令打包成原子操作就变得非常简单,这就是 Redis 事务的实现方式。
4.1 基本事务操作
事务通过 MULTI、EXEC 和 DISCARD 三个命令完成:
MULTI # 进入事务模式
SET user:1:name "张三" # 暂不执行,加入事务队列
SET user:1:age "25" # 同上
INCR user:count # 同上
EXEC # 将所有命令按顺序一次性执行,并返回结果流程解析:
-
MULTI将客户端标记为“事务状态”。 -
后续每个命令都被压入该客户端的私有事务队列,并不立即执行。
-
EXEC触发队列中所有命令不间断地依次执行,中间不会插入其他客户端的命令。 -
所有结果打包返回。
若在 MULTI 之后执行 DISCARD,则清空事务队列并退出事务状态。
4.2 不支持回滚的设计逻辑
Redis 的事务不提供回滚能力,如果在事务中某条命令执行出错(比如对字符串执行 INCR),后续命令依然会继续执行。
MULTI
SET key1 "hello" # 合法
INCR key1 # 类型错误,执行时报错
SET key2 "world" # 仍会执行
EXEC
# 返回:OK, (error) ERR value is not an integer..., OK这种设计的原因:
-
Redis 单线程执行事务,不会出现并发事务交叉修改数据的情况,因此不需要因为并发冲突而回滚。
-
语法错误应在开发阶段被发现,运行时引入回滚机制会显著增加复杂度,与 Redis 追求简单高效的哲学相悖。
-
对于需要“条件判断再决定是否执行”的场景,有更合适的
WATCH乐观锁机制。
4.3 乐观锁:WATCH 命令
WATCH 可以在事务执行前监视一个或多个键。如果被监视的键在 EXEC 之前被其他客户端修改,整个事务将被拒绝。
# 初始余额为 100
SET balance 100
# --- 客户端1 ---
WATCH balance # 监视 balance
GET balance # 读取到 100
MULTI
DECRBY balance 50 # 暂存入队列
EXEC # 提交事务
# 如果客户端2在客户端1 EXEC 之前执行了:
# SET balance 200
# 那么客户端1的 EXEC 将返回 nil,事务未执行底层原理:
-
WATCH会记录客户端的关注键。 -
当其它客户端修改这些键时,Redis 会将其标记为
dirty。 -
EXEC执行前会检查所有被监视的键是否dirty,若是则拒绝执行整个事务。 -
检查与执行之间是原子的,因为整个过程在单线程中一气呵成。
5. 管道(Pipeline):减少网络往返
事务与管道经常被一起讨论,因为两者在客户端都可能表现为“打包一批命令发送”。但它们是截然不同的机制。
5.1 管道解决什么问题
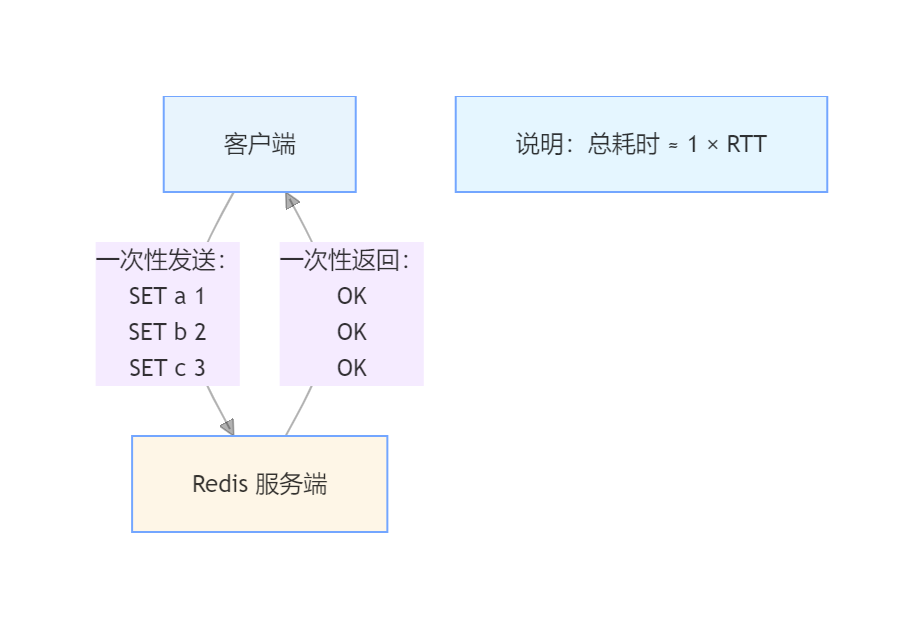
在没有管道的情况下,每发送一个命令就要等待一个回复,花费的时间与网络往返次数成正比:
发送 "SET a 1" → 等待 OK → 收到 OK
发送 "SET b 2" → 等待 OK → 收到 OK
发送 "SET c 3" → 等待 OK → 收到 OK
总耗时 ≈ 3 × RTT
管道允许客户端将多个命令一次性发出,再一次性收回所有结果:
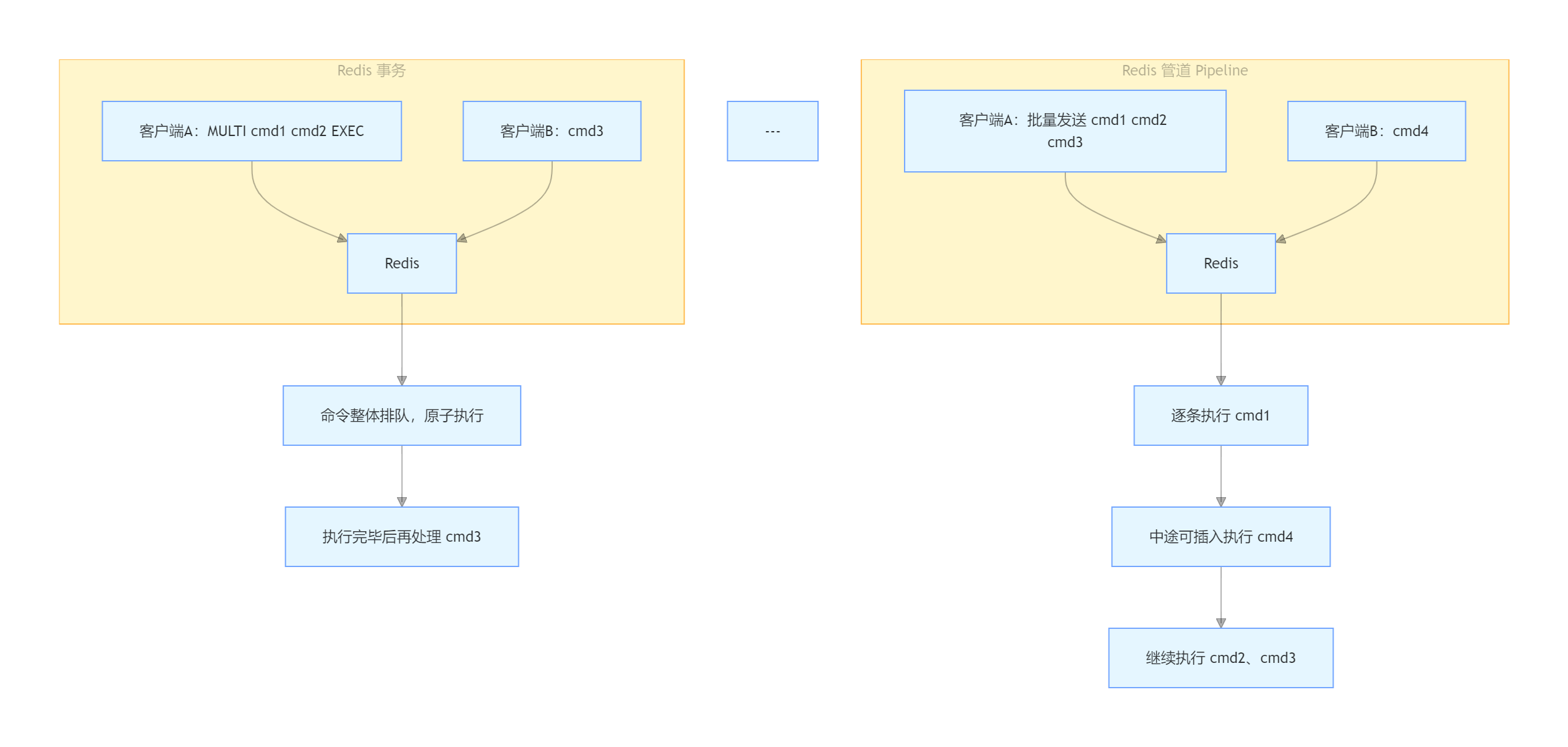
5.2 管道与事务的核心区别
| 维度 | 事务(MULTI/EXEC) | 管道(Pipeline) |
|---|---|---|
| 原子性 | 有。队列中的命令连续执行,中间不插入其他命令 | 无。命令各自独立执行,可能被其他客户端命令穿插 |
| 实现位置 | 服务端。命令被缓存在事务队列,等待 EXEC 触发 |
客户端。打包发送,但服务端仍逐条独立处理 |
| 主要目的 | 保证一组操作的原子性 | 降低网络往返次数,提升吞吐 |
图示对比:
5.3 管道实践:批量写入与读取
在命令行下可以通过 redis-cli --pipe 或直接 echo 模拟管道。
# 准备一个命令文件 commands.txt
# 每行一条 Redis 命令
# SET batch:key1 value1
# SET batch:key2 value2
# ...
# 通过管道导入,大幅减少交互次数
cat commands.txt | redis-cli --pipe
# 简单测试也可以用 echo -e 转义换行符
echo -e "SET k1 v1\nSET k2 v2\nSET k3 v3" | redis-cli在 Java 中,Spring Data Redis 提供了 executePipelined 方法:
public void batchSetWithPipeline() {
// executePipelined 会将内部操作打包成一次网络请求
List<Object> results = redisTemplate.executePipelined(
new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection)
throws DataAccessException {
StringRedisConnection stringConn =
(StringRedisConnection) connection;
// 批量设置 100 个 key(命令会暂存在客户端发送缓冲区)
for (int i = 0; i < 100; i++) {
stringConn.set("batch:key:" + i, "value:" + i);
}
// 也可以混合读取操作
for (int i = 0; i < 100; i++) {
stringConn.get("batch:key:" + i);
}
return null; // 返回值无实际意义
}
}
);
// results 列表包含所有命令的结果,按顺序排列
System.out.println("共执行 " + results.size() + " 条命令");
}使用管道的注意事项:
-
管道不保证原子性,若需要“要么全成功要么全失败”,必须用事务或 Lua 脚本。
-
每批命令量不宜过大,建议控制在 1000 ~ 10000 条,避免占用过多客户端与服务端的内存缓冲区。
-
在高延迟网络(跨地域专线、公网)下,管道带来的收益尤其明显。
6. Lua 脚本:最强的原子执行单元
事务的局限性在于不能在命令执行期间做逻辑判断。例如“如果库存大于 0 就减库存”,用事务很难直接实现,因为事务队列中的命令在 EXEC 之前不会返回中间结果。
Lua 脚本弥补了这个空缺。整个脚本在 Redis 的单线程中执行,中间绝不打岔,而且支持条件、循环、变量等编程能力。
6.1 脚本的原子性与优势
-
原子执行:脚本一旦开始执行,其他所有命令只能排队等待。
-
减少网络开销:一段复杂逻辑原本需要多次请求和响应,现在一个
EVAL请求即可。 -
逻辑下沉:计算直接在数据所在的服务端完成,避免了大量数据在网络间的搬运。
6.2 示例:安全扣减库存
-- 扣减库存脚本
-- KEYS[1]: 库存键,如 "stock:1001"
-- ARGV[1]: 扣减数量
-- 返回 1 表示成功,0 表示库存不足
local key = KEYS[1] -- 库存键
local amount = tonumber(ARGV[1]) -- 请求扣减的数量
local current = tonumber(redis.call('GET', key) or 0) -- 当前库存
if current >= amount then
redis.call('DECRBY', key, amount) -- 执行扣减
return 1
else
return 0
end将这段脚本预加载到 Redis 中,或者直接使用 EVAL 执行。
Java 调用方式:
public boolean deductStock(String stockKey, int amount) {
// Lua 脚本内容
String script =
"local key = KEYS[1]\n" +
"local amount = tonumber(ARGV[1])\n" +
"local current = tonumber(redis.call('GET', key) or 0)\n" +
"if current >= amount then\n" +
" redis.call('DECRBY', key, amount)\n" +
" return 1\n" +
"else\n" +
" return 0\n" +
"end";
// 创建脚本对象,指定返回值类型
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
redisScript.setResultType(Long.class);
// 执行脚本
Long result = redisTemplate.execute(
redisScript,
Collections.singletonList(stockKey), // KEYS 列表
String.valueOf(amount) // ARGV 参数
);
return result != null && result == 1;
}6.3 编写 Lua 脚本的注意点
-
脚本要短:长时间执行会阻塞整个 Redis 实例,绝对避免死循环。
-
避免依赖随机结果:如果在脚本里生成随机数,AOF 重放时可能产生不一致。Redis 7 提供了部分改善。
-
复用脚本:使用
SCRIPT LOAD将脚本缓存到服务端,之后通过EVALSHA调用,省去每次传输脚本正文的开销。 -
Redis 7 支持只读脚本:
EVAL_RO允许在只读副本上执行脚本,分担主节点压力。
7. 单线程的性能瓶颈与大 Key 治理
单线程串行执行是双刃剑:简单稳定,但一个耗时操作就能拖累全体。在所有阻塞风险中,大 Key(Big Key) 是最常见也最具破坏力的一类。
7.1 典型阻塞问题
-
KEYS *:全量扫描键空间,数据量一大直接卡死。 -
FLUSHALL/FLUSHDB:删除大量数据时的阻塞。 -
DEL删除包含百万级元素的集合或哈希。 -
复杂的聚合操作如
ZUNIONSTORE、SORT等。
但这些命令如果偶尔执行,尚可在低峰期操作,真正持续引发性能灾难的,往往是潜伏在业务中的大 Key。
7.2 大 Key 的定义与危害
大 Key 并不是一个精确的绝对值,而是一个根据场景变化的阈值。通常可以这样界定:
-
String 类型:单个 value 超过 10 KB 即可视为大 Key,超过 1 MB 则是严重问题。
-
集合类型(List、Hash、Set、ZSet):元素个数超过 5000 即应关注,超过几十万甚至上百万则是巨型大 Key
大 Key 带来的影响是多维度的:
-
客户端超时阻塞:单次读取或操作大 Key 耗时上升,导致客户端请求堆积。
-
网络带宽挤占:一个大 Key 的读取可能瞬间消耗几十 MB 流量,影响其他请求。
-
内存倾斜:在 Cluster 模式下,大 Key 会导致某个分片内存暴涨,打破数据均匀分布。
-
删除时阻塞:直接
DEL一个大集合会阻塞主线程数百毫秒甚至数秒。 -
过期引发的死机式卡顿:大 Key 过期时,如果未开启 lazy free,Redis 会同步释放内存,同样会严重阻塞。
7.3 大 Key 的排查方法
要治理大 Key,首先得找到它们。排查通常分为离线扫描和在线监测两种思路。
7.3.1 使用 redis-cli --bigkeys
这是最快速的排查工具,非破坏性扫描,适合初步摸底。
# 扫描整个实例,输出各类数据结构的最大 key 统计
redis-cli --bigkeys
# 如果实例有密码或非默认端口
redis-cli -h 127.0.0.1 -p 6379 -a yourpassword --bigkeys它会输出类似下面的信息:
Biggest string found: "article:content:98765" has 2048576 bytes
Biggest hash found: "user:session:all" has 50000 fields
限制:--bigkeys 只返回每种类型最大的那个键,且采样不完整。如果想找出所有大 Key,需要更细致的扫描。
7.3.2 使用 MEMORY USAGE 命令精确度量
对于怀疑的 Key,可以直接查看其实际内存占用:
# 返回 key 的内存占用字节数(Redis 4.0+)
MEMORY USAGE user:session:all结合 DEBUG OBJECT 可以得到更多信息(如序列化长度),但在生产环境需谨慎使用,它有一定开销。
7.3.3 编写脚本进行全量扫描
当 --bigkeys 不够细致时,可以通过 Lua 或客户端编程遍历所有键,按类型统计大小并输出超过阈值的 Key。一个简单的 Python 示例:
import redis
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
BIGKEY_THRESHOLD = 10240 # 10 KB
cursor = 0
while True:
cursor, keys = r.scan(cursor, count=1000)
for key in keys:
key_type = r.type(key)
if key_type == 'string':
size = r.memory_usage(key)
if size and size > BIGKEY_THRESHOLD:
print(f"[大Key] {key} 类型=string 大小={size} 字节")
elif key_type in ('hash', 'list', 'set', 'zset'):
length = r.object('encoding', key) # 实际可用 llen/hlen/scard/zcard 获取元素数
# 这里简化演示,实际应调用 len 方法
print(f"[检查] {key} 类型={key_type} (需进一步判断元素数量)")
if cursor == 0:
break在实际项目中,更推荐使用现成的工具如 redis-rdb-tools 对 RDB 文件离线分析,这样对线上服务无任何影响。
7.3.4 通过 RDB 文件离线分析
# 安装 redis-rdb-tools
pip install rdbtools python-lzf
# 分析 RDB 文件,生成内存报告
rdb -c memory /path/to/dump.rdb > memory_report.csv
# 查看最大的 20 个键
awk -F, '{print $4,$2}' memory_report.csv | sort -nr | head -20这种方法可以得到全量且精确的内存分布,是定期排查大 Key 的最稳妥手段。
7.4 大 Key 的解决方案
找到大 Key 后,不能直接 DEL 了事,那样反而会引发阻塞事故。解决方案要视情况而定。
7.4.1 异步删除(Lazy Free)
自 4.0 版本起,Redis 引入了后台线程处理内存释放。用 UNLINK 代替 DEL 是删除大 Key 的首选方式。
# 同步删除:直接阻塞主线程
DEL big_hash_key
# 异步删除:主线程仅解除键引用,后台线程负责内存回收
UNLINK big_hash_key同时建议在配置中打开全局 lazy free 开关:
# redis.conf
lazyfree-lazy-eviction yes # 内存淘汰异步释放
lazyfree-lazy-expire yes # 过期键异步释放
lazyfree-lazy-server-del yes # 内部隐式删除异步化
replica-lazy-flush yes # 从库异步清理开启后,即便大 Key 过期或内存淘汰,也不会造成明显阻塞。
7.4.2 化整为零:分批删除集合元素
当大 Key 是集合类型时,可以分批次逐步删除,每批少量,让主线程有足够间隙处理其他请求。
思路是配合 SCAN 族命令(HSCAN、SSCAN、ZSCAN)逐批取出元素,再用 HDEL/SREM/ZREM 等批量删除。
以删除一个大 Hash 为例:
public void deleteBigHash(String key, int batchSize) {
Cursor<Map.Entry<Object, Object>> cursor =
redisTemplate.opsForHash().scan(key, ScanOptions.scanOptions().count(batchSize).build());
int deletedCount = 0;
while (cursor.hasNext()) {
Map.Entry<Object, Object> entry = cursor.next();
redisTemplate.opsForHash().delete(key, entry.getKey());
deletedCount++;
// 每批删除后可以短暂休眠,让出 CPU(视紧急程度决定)
if (deletedCount % batchSize == 0) {
try {
Thread.sleep(10); // 10ms 暂停,避免过度占用主线程
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
}对于 List,可以反复 LPOP/RPOP 分批弹出;对于 ZSet,可以按排名范围 ZREMRANGEBYRANK 或 ZREMRANGEBYSCORE 分段删除。
7.4.3 拆解数据:避免大 Key 产生
治理的根本在于避免大 Key 产生,这需要从业务设计上入手。
String 类型:避免将巨大的 JSON 或序列化对象完整存储。只缓存必要的摘要字段,详细数据按需从数据库加载。
Hash 类型:当字段极多时(比如一个 Key 存了所有用户信息),应进行横向拆分。例如原本 users:all 存放所有用户,可改为按用户 ID 哈希分片:
users:shard:0 → hash (id % 10 == 0)
users:shard:1 → hash (id % 10 == 1)
...
每次操作时先计算分片,再定位到对应的 Key。这样每个 Hash 的大小可控,也利于 Cluster 模式下数据分布。
Set 或 ZSet:如果集合元素达到百万级,考虑使用二级索引或按时间段拆分。例如排行榜每月一个 Key:rank:202401、rank:202402。
List:如果用作消息队列或日志收集,务必设置长度上限,使用 LTRIM 保持固定长度:
# 保留最新的 1000 条记录
LPUSH logs "new log entry"
LTRIM logs 0 9997.4.4 大 Key 的持久化与过期风险
大 Key 不仅在读写时可能阻塞,在 RDB 持久化和 AOF 重写时也会引起高负载。处理思路:
-
调整
save配置:避免频繁全量 RDB,降低大 Key 带来的 I/O 风暴。 -
适当关闭 RDB:如果架构中有从库负责持久化,主库可以只开 AOF,减少瞬时压力。
-
监控过期时间:尽量避免集中给大量大 Key 设置相同的过期时间,否则可能同时触发无数 lazy free 任务,间接拉高 CPU。可以在过期时间上加一个随机浮动值。
7.5 大 Key 问题总结
排查路径可概括为:
-
先用
redis-cli --bigkeys或 RDB 离线分析工具快速定位最大的那些键。 -
对于业务中频繁访问的疑似大 Key,用
MEMORY USAGE确认其真实内存占比。 -
删除时一律使用
UNLINK,或编写分批删除脚本。 -
从根源上修改数据模型,将大 Key 拆解为多个小 Key,并控制集合长度。
-
开启 lazy free 相关配置作为保底。
8. Redis 6/7 的多线程 IO:界限分明
Redis 6.0 引入“多线程”,经常被误解为命令执行多线程,实际上只是将网络 IO 拆到了多个线程中。
8.1 拆分目标
随着万兆网卡普及,网络数据的解析、搬运转为 CPU 消耗大户。单线程既要忙网络 IO,又要执行命令,容易在解析协议上花掉大量时间。因此 Redis 决定将网络协议解析和 socket 数据读写交给多个 IO 线程并行处理,而命令执行仍旧保持单线程。
8.2 工作流程
-
主线程接收连接,并将待处理的 socket 分发给 IO 线程。
-
多个 IO 线程并行读取 socket 数据,解析出完整的命令。
-
主线程汇总所有解析好的命令,按顺序逐个执行。
-
执行结果交给 IO 线程,由它们并行写回客户端。
命令执行环节没有任何并行化,因此:
-
原子性、事务语义完全不变。
-
无需加锁,数据一致性没有任何额外风险。
8.3 配置与适用场景
# 设置 IO 线程数,一般设为 CPU 核心数(建议 ≤ 8)
io-threads 4
# 默认只对写启用多线程,读也需要手动开启
io-threads-do-reads yes多线程 IO 并非万能,只有达到一定负载时才有收益。实测在 QPS 超过 10 万的场景下,吞吐通常能提升 20% ~ 50%;低负载时线程切换开销反而可能使性能略微下降。是否开启需要根据实际压测结果决定。
9. 为什么命令执行坚决不做多线程
这是 Redis 设计中的一个关键取舍:
-
CPU 极少是 Redis 的瓶颈。内存带宽、网络带宽往往先于 CPU 被耗尽。
-
一旦命令执行并行化,锁、竞态、死锁等问题会迅速让代码复杂化,稳定性下降。
-
简单正是 Redis 的核心价值。单线程执行模型几乎杜绝了并发 Bug。
-
需要横向扩展时,Redis Cluster 通过分片将请求分散到多个节点,每个节点内部仍然保持单线程,这是更清晰的并行路线。
实际生产中,单个 Redis 实例纯内存读写的吞吐可达数十万 QPS,绝大多数系统受限于后端数据库或业务逻辑,而非 Redis 本身。
10. 总结
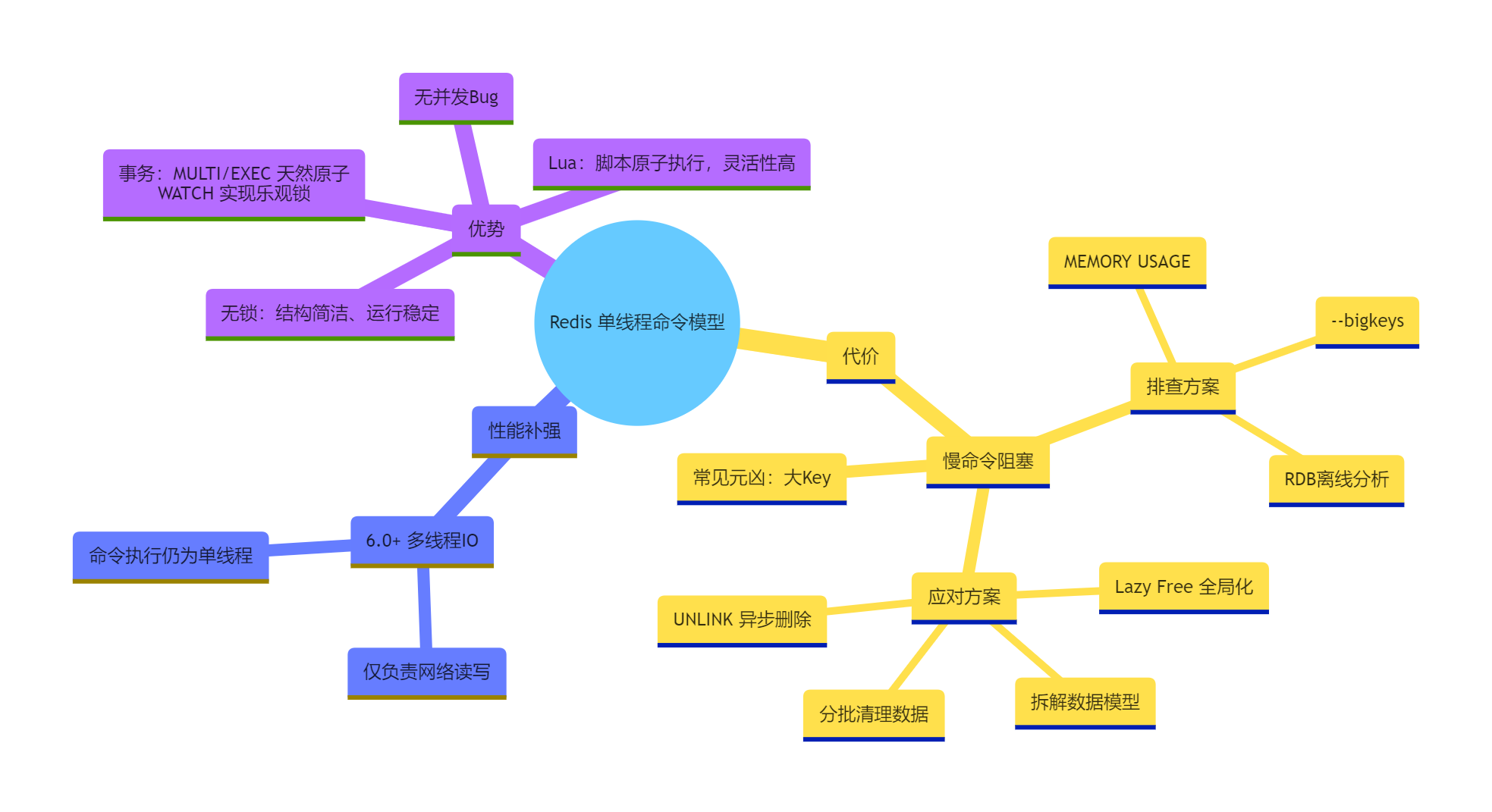
最后,如有改进之处欢迎指正,觉得有帮助的话不妨点赞收藏支持一下,感谢!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)