【VLM】GLM-5V-Turbo模型简析
note
- 两阶段预训练CogViT:
- 基于蒸馏的掩码图像建模:把图片遮住一部分,让学生 ViT 猜被遮住的区域,同时学习两个老师的视觉特征(SigLIP2 提供语义表示,DINOv3 提供纹理特征)
- 对比式图文预训练:支持变尺寸图片、SigLIP loss + 64K batch、80 亿中英文图文语料
- 感知仍是更高级多模态能力的基石:多模态编程和 grounding 任务被证明是有效的感知“代理任务”,如在预训练中加入学科图像与对应 SVG 代码的配对数据,对下游 STEM 问题求解有正向收益;在 RL 阶段加强 grounding 训练,则能改善 GUI Agent 表现。在 GUI Agent 的指令微调中,我们引入了针对推理过程错误(如误读界面、错认元素、错误决策)的 critic 数据,明显减少了几类反复出现的感知失败模式。
- Agent 能力更适合用分层优化而非单一端到端训练构建
- 端到端长程任务的关键不在长度,而在清晰的任务设定、可靠的结果验证和可控的评估流程
文章目录
一、GLM-5V-Turbo简介
【GLM-5V-Turbo模型】
1、优化点:新视觉编码器 CogViT、对大规模基础设施友好的多模态多 token 预测 MMTP、覆盖感知-推理-Agent 的广覆盖联合训练,以及一套面向大规模多模态强化学习(RL)的基础设施。
2、围绕 OpenClaw、AutoClaw 和 Claude Code 等框架,我们还提供了 15 项官方 skills,包括:原生 skills(如 PDF 转网页/PPT、网页复刻、PRD 转应用)、外部工具 skills(如图像描述、视觉 grounding、文档写作)以及基于专用模型 GLM-OCR、GLM-Image 的专项技能,并配有统一的 master skill 入口。
官方 Skills 集合:
- https://github.com/zai-org/GLM-skills
- Master Skill:https://clawhub.ai/jaredforreal/glm-master-skill
新视觉编码器 CogViT、对大规模基础设施友好的多模态多 token 预测 MMTP、覆盖感知-推理-Agent 的广覆盖联合训练,以及一套面向大规模多模态强化学习(RL)的基础设施。
相关效果: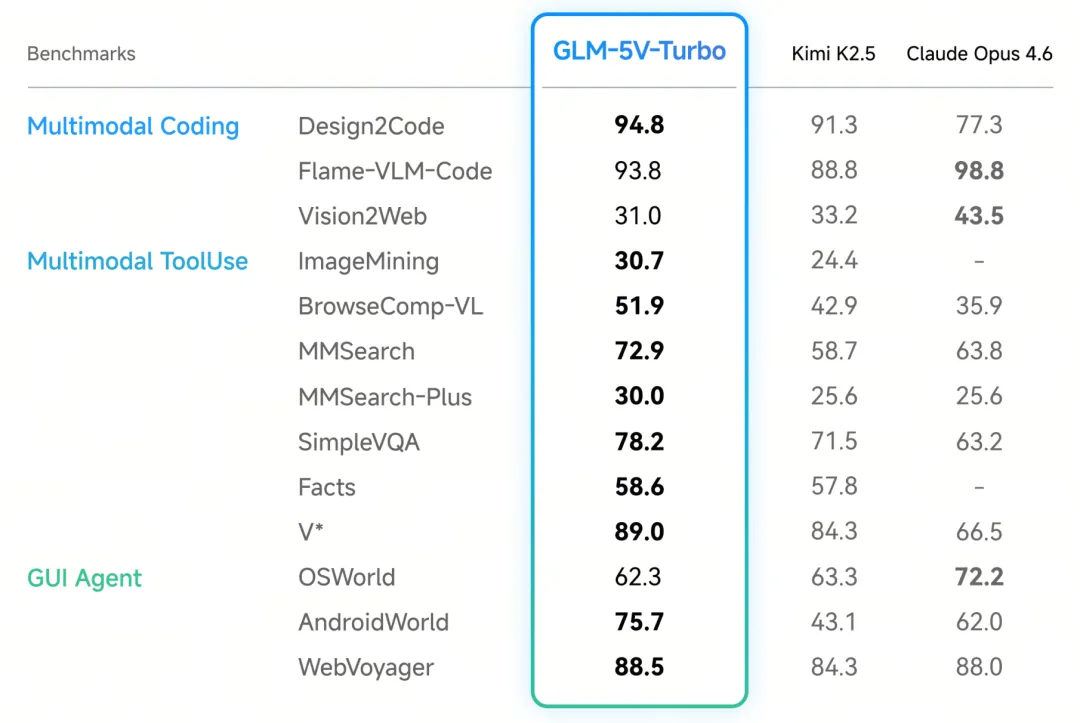
二、GLM-5V-Turbo模型
1、CogViT:参数高效的视觉编码器
从零构建了面向多模态感知和下游 Agent 任务的视觉编码器:CogViT。我们采用两阶段预训练:
第一阶段使用基于蒸馏的掩码图像建模,让学生 ViT 在 224×224 输入、35% 掩码率下重建被遮挡区域,并同时对齐两个教师模型的特征(SigLIP2 提供语义表示,DINOv3 提供纹理特征)。训练数据按“质量感知”混合,包括 80% 高质量自然图像、10% 指令跟随数据、10% 科学图像。优化器则使用 Muon,并引入 QK-Norm 在注意力计算前对 Query 和 Key 做归一化,缓解了 logit 爆炸、提升了大规模训练稳定性。
第二阶段切换为对比式图文预训练,把视觉与文本特征对齐到同一嵌入空间。该阶段共有 3 处关键升级:用 NaFlex 方案替代固定 224×224 输入,支持变尺寸、保留原始长宽比;用 sigmoid 形式的 SigLIP loss 把全局批次扩到 64K,并配合双向分布式实现;使用 80 亿规模的中英文双语图文语料,提升跨语言理解能力。
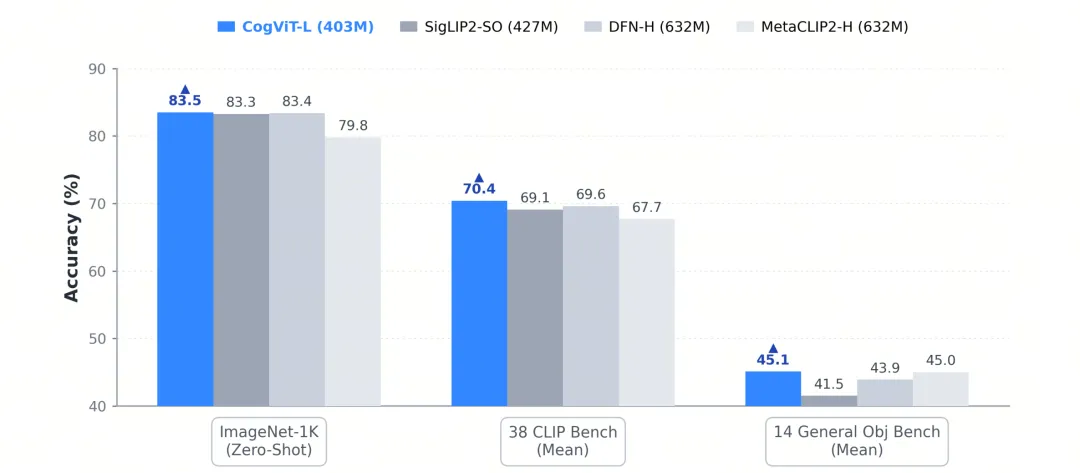
CogViT 在通用识别、细粒度理解和空间感知上同时表现良好。403M 的 CogViT-L 的 ImageNet-1K 零样本分数为 83.5、38 项 CLIP Bench 分数平均为 70.4、14 项通用目标 Bench 分数平均为 45.1,在多数指标上超过 SigLIP2-SO (427M) 和 DFN-H (632M)
2、大规模多模态RL基础设施
多任务多模态 RL 对训练系统提出了更严苛的要求,prompt 与回复长度差异大、任务有单步也有多步、每个任务可能挂着不同的规则验证器或模型验证器。为此,GLM-5V-Turbo 团队从 4 个维度重构了训练栈。
- 统一任务与奖励抽象:构建 VLM RL Gym 提供统一的环境接口;引入独立奖励系统集中编排多个验证器,规则验证器本地同步执行,模型验证器通过 API 异步调用,输出按可配置策略聚合。每条样本带数据源标签,便于按来源汇报奖励与 pass@k。
- 全管线解耦与异步:rollout 推理、奖励评估、批(batch)构建、权重传输四阶段最大化重叠。为推理请求注册完成回调函数,单条结束就触发奖励计算,避免被长尾请求拖累;参考模型(reference model)的参数常驻 CPU 内存,在前向传播前异步预取到 GPU、用完即释放。系统还支持基于完成数或时间阈值的提前 abort,被 abort 的 prompt 可缓存复用。
- 面向多模态的细粒度内存管理:传统重计算策略主要面向纯文本设计,难以应对多模态输入带来的内存压力。我们为 ViT 与 projector 模块设计独立的内存管理策略,结合细粒度定向重计算与 CPU offload,避免激活内存随图像数量线性膨胀。
- 拓扑感知的视觉输入分区:常规实现中,每个 rank 要先持有完整 patch 张量再重新分发,造成不必要的内存与通信开销。我们把上下文并行(CP)和张量并行(TP)策略前移到数据加载阶段,与下采样组对齐分组边界,再通过异步 all-to-all 精确传输;将大型 Python 对象从 GPU 通信路径搬到 CPU 路径,实测减少了约 7GB 的 GPU 通信缓存开销。对 rollout 阶段产生的变长序列,还在序列长度和 ViT token 数两个维度上联合做 bin-packing
3、MMTP:让多token预测适配多模态
对比了 3 种方案:(1)直接把 LLM 主干的视觉嵌入传给 MTP head;(2)在 MTP head 输入端把所有视觉 token 掩码掉,退化为纯文本 MTP;(3)保留视觉位置信息,但把所有视觉 token 替换成一个共享可学习的图像特殊 token。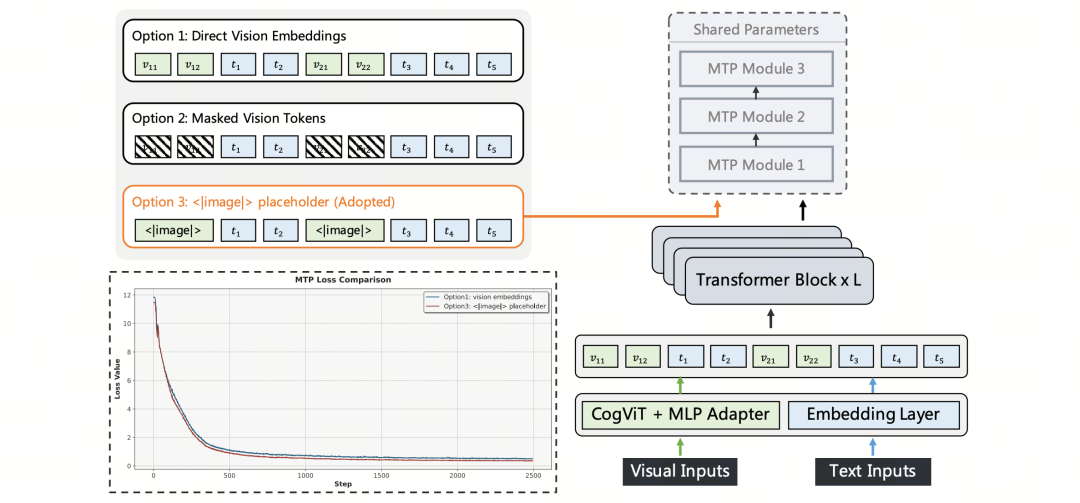
GLM-5V-Turbo 采用了第 3 种方案。相比直接传视觉嵌入,图像占位符方案不需要在流水线并行的多个 stage 之间传递视觉嵌入,显著降低了通信复杂度;在 0.5B 模型上的消融实验显示,该方案训练损失更低、收敛更稳。这是因为 MTP head 通常较轻,难以有效吸收分布上与文本差异显著的视觉表示,统一形式的占位 token 反而更易优化。同时,相比“完全掩码”方案,这种设计天然兼容序列并行和上下文并行,无需额外处理视觉嵌入的分区与对齐。
三、工具
多模态工具:覆盖通用识别(植物、地点、人物)、多模态搜索(文本搜索、以图搜图、相似图搜索、学术搜索)、浏览器工具、图像处理(裁剪、绘制 2D/3D 边界框、绘制点标注、视频对象跟踪)、Web 与 PPT 创建,以及面向深度研究的工具集。

四、官方skills
围绕 OpenClaw、AutoClaw 和 Claude Code 等框架,我们还提供了 15 项官方 skills,包括:原生 skills(如 PDF 转网页/PPT、网页复刻、PRD 转应用)、外部工具 skills(如图像描述、视觉 grounding、文档写作)以及基于专用模型 GLM-OCR、GLM-Image 的专项技能,并配有统一的 master skill 入口。
官方 Skills 集合:https://github.com/zai-org/GLM-skillsMaster Skill:https://clawhub.ai/jaredforreal/glm-master-skill
Reference
[1] GLM-5V-Turbo技术报告:多模态Agent基座模型探索
[2] https://arxiv.org/pdf/2604.26752

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)