AIGC(生成式AI)试用 52 -- 个人知识库 DocsGpt(chat参数)
个人知识库 DocsGpt,Request Parameters
Left Issue
1) 回复结果的稳定性、一致性
2)通过prompt模拟Agent生成
3)Agent调用 + 外部资源调用(rag?)
4)chat名可以自定义吗?
1. api/answer, stream的区别
-
Question: Who are you? api/answer stream I’m DocsGPT—a conversational AI created to help you with information, explanations, code snippets, diagrams, and more. Think of me as a reliable virtual assistant that can read and analyze documents you upload, answer questions, and even generate charts or example code. Let me know how I can assist you today! I
’m
**
Docs
GPT
**,
a
conversational
AI
designed
to
help
you
create
,
understand
,
......(此处略去N行)
!2. System, Assistant, User的区别(百度 ai)
- System:幕后指令设定者,定义 AI 的身份、风格、规则或上下文约束(如“你是一名资深医生,回答需简洁专业”),不直接参与对话,但全局引导 AI 行为。-- 系统约束
- User:提问者或指令发起者,代表人类输入(如“如何煮咖啡?”),推动对话方向。-- 提示输入
- Assistant:AI 的回应化身,根据 System 和 User 的输入生成内容,在多轮对话中承接上下文(即你看到的 AI 回复)。-- 提问反馈
3. Prompt 与 Agent
- Prompt = LLM + 问题
对话:一次性、无状态对话、建议输出 - Agent = LLM + Planning + Memory + Tools + Prompt
活动:循环、自主、决策、完成并输出最终结果 - Agent = 有组织、有目的、有约束的Prompt集 + 工具
-
4. API调用
- 最简单调用def ask_ai(question): payload = { "question": question, "model_id": "docsgpt-local", } response = requests.post(purl["purl_answer"], json=payload) if response.status_code == 200: result = response.json() return result['answer'] else: return response.text if __name__ == "__main__": answer = ask_ai("who are you") print("--> ", f"{answer}") ###################3 --> I’m DocsGPT, a large‑language‑model AI trained by OpenAI. I can help you with a wide range of tasks—from answering questions and explaining concepts to writing code, generating documentation, and visualizing data. If you have any specific requests, just let me know! ['who are you', 'I’m DocsGPT, a large‑language‑model AI trained by OpenAI. \nI can help you with a wide range of tasks—from answering questions and explaining concepts to writing code, generating documentation, and visualizing data. If you have any specific requests, just let me know!']- 参数(Request Parameters0
Field Type Required Applies to Notes question string Yes /api/answer, /stream User query. api_key string Usually /api/answer, /stream Recommended for agent API use. Loads agent config from key. conversation_id string No /api/answer, /stream Continue an existing conversation. history string (JSON-encoded array) No /api/answer, /stream Used for new conversations. Format: .[{\"prompt\":\"...\",\"response\":\"...\"}] model_id string No /api/answer, /stream Override model for this request. save_conversation boolean No /api/answer, /stream Default . If , no conversation is persisted.true false passthrough object No /api/answer, /stream Dynamic values injected into prompt templates. prompt_id string No /api/answer, /stream Ignored when already defines prompt.api_key active_docs string or string[] No /api/answer, /stream Overrides active docs when not using key-owned source config. retriever string No /api/answer, /stream Retriever type (for example ).classic chunks number No /api/answer, /stream Retrieval chunk count, default .2 isNoneDoc boolean No /api/answer, /stream Skip document retrieval. agent_id string No /api/answer, /stream Alternative to when using authenticated user context.api_key Streaming-only fields: attachments string[] No List of attachment IDs from success result./api/task_status index number No Update an existing query index. If provided, is required.conversation_id -
- history,上下文记忆
chat_history = [] chat_history.append("string") history = json.dumps(chat_history, ensure_ascii=False) { ... "history": history, ... } ########################################################### History: [{'role': 'user', 'content': 'who are you?'}, {'role': 'user', 'content': '**问题**:who are you? \n\n**评估**:不明确。 \n\n**不明确之处** \n1. **对象不确定**:问题没有说明“你”指的是谁或什么(人、机器人、系统、组织等)。 \n2. **上下文缺失**:缺少交互场景或背景信息,使得无法判断期望回答的具体内容(例如身份认证、角色介绍、人工智能服务等)。 \n3. **答案范围不定**:可能回答为个人信息、职业身份、AI助手、角色扮演等,缺乏限定。 \n\n如果你想得到特定的答案,请补充上下文或说明你期望得到的“身份”范围。'}] ########################################################### # calling error1 { ... "history": ["string"], ... } # "error": "the JSON object must be str, bytes or bytearray, not list" # calling error2 { ... "history": "string", ... } # "error": "Expecting value: line 1 column 1 (char 0)"- passthrough,系统提示词(提示词补充、限制)
-
passthrough = { "Time": time.ctime(), "sysprompt": "分析以下问题是否明确,如不明确则列出不明确之处,如明确则输出结果:", } "question": f"{passthrough['sysprompt']}{question}", ##################################################### **评估**:不明确。 **不明确之处** 1. **对象不确定**:问题没有说明“你”指的是谁或什么(人、机器人、系统、组织等)。 2. **上下文缺失**:缺少交互场景或背景信息,使得无法判断期望回答的具体内容(例如身份认证、角色介绍、人工智能服务等)。 3. **答案范围不定**:可能回答为个人信息、职业身份、AI助手、角色扮演等,缺乏限定。 如果你想得到特定的答案,请补充上下文或说明你期望得到的“身份”范围。- history + passthrough 调用
def ask_ai(question):
chat_history = []
chat_history.append(
{"role": "user",
"content": question}
)
history = json.dumps(chat_history, ensure_ascii=False)
passthrough = {
"Time": time.ctime(),
"sysprompt": "分析以下问题是否明确,如不明确则列出不明确之处,如明确则输出结果:",
}
payload = {
"question": f"{passthrough['sysprompt']}{question}",
"history": history,
## "conversation_id": "string",
"model_id": "docsgpt-local",
"passthrough": passthrough,
}
response = requests.post(purl["purl_answer"], json=payload)
if response.status_code == 200:
result = response.json()
chat_history.append(
{"role": "user",
"content": result['answer']}
)
return result['answer'], chat_history
else:
return response.text, chat_history
if __name__ == "__main__":
answer, history = ask_ai("who are you?")
print(f"-->Answer: {answer}\n-->History: {history}")
#############################################################
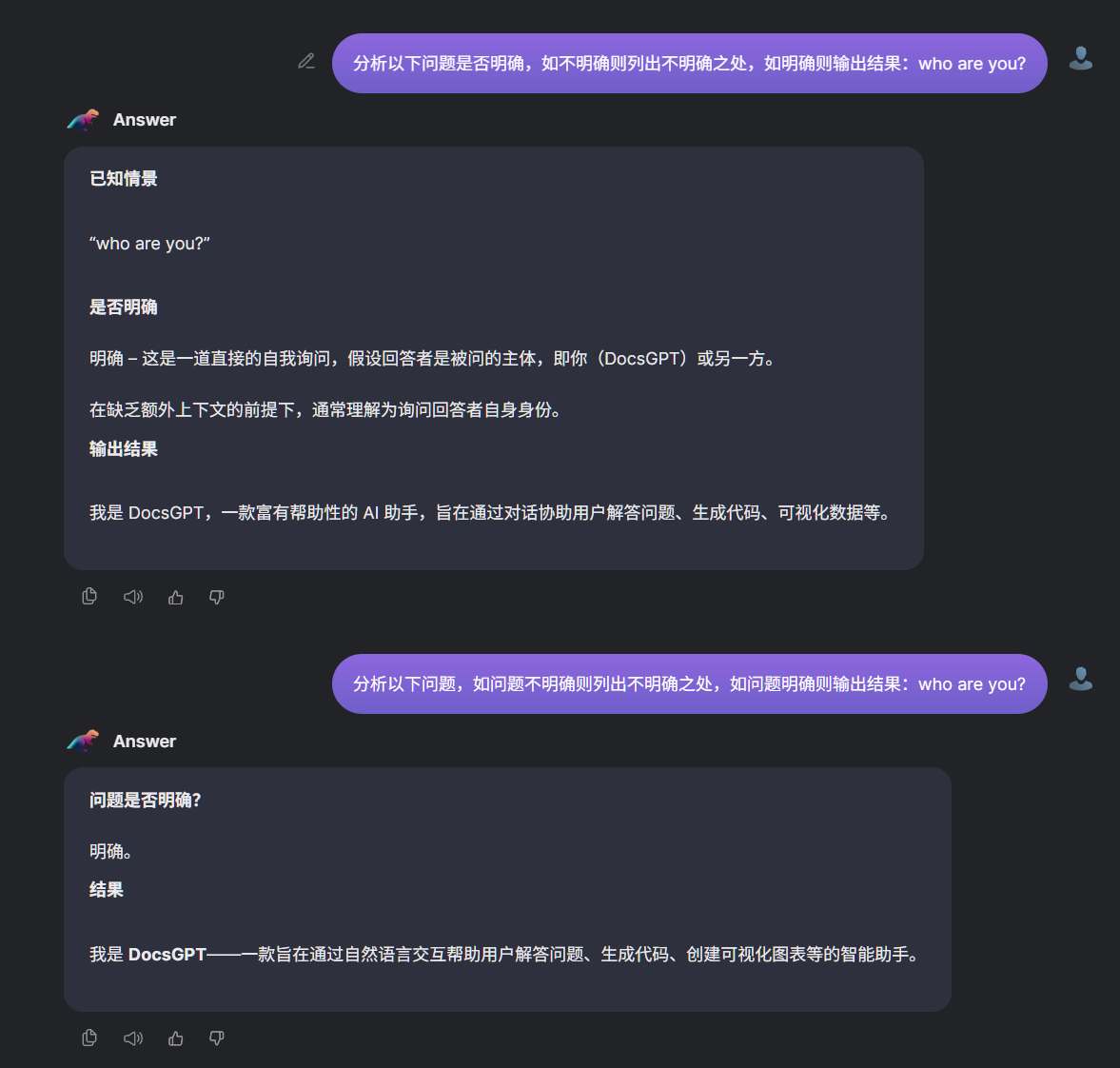
-->Answer: **问题**:who are you?
**是否明确**
*明确* – 这是一道直接的自我询问,假设回答者是被问的主体,即你(DocsGPT)或另一方。
在缺乏额外上下文的前提下,通常理解为询问回答者自身身份。
**输出结果**
> 我是 DocsGPT,一款富有帮助性的 AI 助手,旨在通过对话协助用户解答问题、生成代码、可视化数据等。
-->History:
[{'role': 'user', 'content': 'who are you?'},
{'role': 'user', 'content': '**已知情景** \n> “who are you?”
\n\n**是否明确** \n*明确* – 这是一道直接的自我询问,假设回答者是被问的主体,即你(DocsGPT)或另一方。
\n在缺乏额外上下文的前提下,通常理解为询问回答者自身身份。\n\n**输出结果**
\n> 我是 DocsGPT,一款富有帮助性的 AI 助手,旨在通过对话协助用户解答问题、生成代码、可视化数据等。'}]- 修改 passthrough,并加入 conversation_id 调用
passthrough = {
"Time": time.ctime(),
"sysprompt": "分析以下问题,如问题不明确则列出不明确之处,如问题明确则输出结果:",
}
##################################################
{'answer': '**问题是否明确?** \n明确。\n\n**结果** \n\n
> 我是 **DocsGPT**——一款旨在通过自然语言交互帮助用户解答问题、生成代码、创建可视化图表等的智能助手。', 'conversation_id': '6a2524f29404e7c57b19e98b', 'sources': [], 'thought': '', 'tool_calls': []}
-->Answer: **问题是否明确?**
明确。
**结果**
> 我是 **DocsGPT**——一款旨在通过自然语言交互帮助用户解答问题、生成代码、创建可视化图表等的智能助手。
-->History: [{'role': 'user', 'content': 'who are you?'},
{'role': 'user', 'content': '**问题是否明确?** \n明确。\n\n**结果** \n\n> 我是 **DocsGPT**——一款旨在通过自然语言交互帮助用户解答问题、生成代码、创建可视化图表等的智能助手。'}]
- conversations
Operations Desc. GET/api/delete_all_conversations Deletes all conversations for a specific user POST/api/delete_conversation Deletes a conversation by ID POST/api/feedback Submit feedback for a conversation GET/api/get_conversations Retrieve a list of the latest 30 sidebar conversations (visibility = listed) GET/api/get_single_conversation Retrieve a single conversation by ID GET/api/messages/{message_id}/tail Current state of one conversation_messages row, scoped to the authenticated user. Used to reconnect to an in-flight stream after a refresh. GET/api/search_conversations Search the authenticated user's conversations by name or message content (case-insensitive substring match). Mirrors the visibility filter and response shape of /get_conversations, and additionally returns match_field(name,promptorresponse) andmatch_snippet(a short excerpt of the matched text centered on the query) for each result.POST/api/update_conversation_name Updates the name of a conversation ## GET/api/get_conversations ## GET/api/get_single_conversation API_URL = f"http://localhost:7091/api/get_conversations", API_URLs = f"http://localhost:7091/api/get_single_conversation", cov_get= requests.get(API_URL) result = cov_get.json() print(f"--> Conversation: {cov_get}\n{result}") for line in result: print("--> ") for k in line.keys(): print(f"{k}: {line[k]}") cov_gets = requests.get(f"{API_URLs }?id={line['id']}") result = cov_gets.json() print(f"--> Conversation Single: {cov_gets}\n{result}") ######################################### --> Conversation: <Response [200]> [{'agent_id': None, 'id': '6a315b4d712f9cd019ba3426', 'is_shared_usage': False, 'name': '关于skills', 'shared_token': None}, {'agent_id': None, 'id': '6a2524f29404e7c57b19e98b', 'is_shared_usage': False, 'name': '已明确', 'shared_token': None}] --> agent_id: None id: 6a315b4d712f9cd019ba3426 is_shared_usage: False name: 关于skills shared_token: None --> Conversation Single: <Response [200]> {'agent_id': None, 'is_shared_usage': False, 'queries': [{'attachments': [], 'model_id': 'docsgpt-local', 'prompt': '关于skills', 'response': '你好!关于 **skills(技能)**,我可以从以下几个角度为你提供帮助:\n\n## 我作为 DocsGPT 的核心技能\n\n作为你的 AI 助手,我具备以下能力:\n\n| 技能领域 | 具体能力 |\n|---------|---------|\n| 📄 **文档智能** | 分析上传的文档、论文、手册,基于内容精准问答 |\n| 💻 **代码辅助** | 编写、解释、调试代码,支持多种编程语言 |\n| 📊 **可视化** | 使用 Mermaid 语法绘制流程图、架构图、时序图等 |\n| ✅ **任务管理** | 协助创建、管理和追踪待办事项(Todo List)|\n| 🌐 **多语言** | 支持中文、英文等多种语言交流 |\n| 🔍 **知识检索** | 结合上下文和上传资料,提供定制化回答 |\n\n## 你可以告诉我\n\n为了更精准地帮助你,请告诉我你具体想了解:\n\n1. **职业技能发展**(如编程、写作、项目管理等技能学习路径)\n2. **技能管理系统**(如何用待办事项或工具追踪技能学习进度)\n3. **文档/代码相关技能**(具体技术问题的解答)\n4. **其他特定领域**(数据分析、语言学习等)\n\n**你现在想了解哪方面的 skills 呢?** 如果有具体文档或问题,也可以上传或描述给我!', 'sources': [], 'thought': '', 'timestamp': 'Tue, 16 Jun 2026 14:18:45 GMT', 'tool_calls': []}], 'shared_token': None} --> agent_id: None id: 6a2524f29404e7c57b19e98b is_shared_usage: False name: 已明确 shared_token: None --> Conversation Single: <Response [200]> {'agent_id': None, 'is_shared_usage': False, 'queries': [{'attachments': None, 'model_id': 'docsgpt-local', 'prompt': ..................................... - source
Source document management operationsOperations Desc. POST/api/add_chunk Adds a new chunk to the document GET/api/combine Redirects /api/combine to /api/sources for backward compatibility DELETE/api/delete_chunk Deletes a specific chunk from the document. GET/api/delete_old Deletes old indexes and associated files GET/api/directory_structure Get the directory structure for a document GET/api/get_chunks Retrieves chunks from a document, optionally filtered by file path and search term POST/api/manage_source_files Add files, remove files, or remove directories from an existing source POST/api/manage_sync Manage sync frequency for sources POST/api/remote Uploads remote source for vectorization. Honors an optional Idempotency-Key header:
a repeat request with the same key within 24h returns the original cached response without re-enqueuing.
GET/api/sources Provide JSON file with combined available indexes GET/api/sources/paginated Get document with pagination, sorting and filtering 获取带有分页、排序和筛选功能的文档
POST/api/sources/reingest Re-run ingestion for a source — e.g. to recover a stalled embed flagged by the reconciler. POST/api/sync_source Trigger an immediate sync for a source GET/api/task_status Get celery job status PUT/api/update_chunk Updates an existing chunk in the document. POST/api/upload Uploads a file to be vectorized and indexed. Honors an optional Idempotency-Key header:
a repeat request with the same key within 24h returns the original cached response without re-enqueuing.* Idempotency-Key: 幂等键,客户端生成的唯一标识符,用于确保重复请求只执行一次业务操作,防止因网络重试、重复点击等导致的数据重复问题
{'date': 'Sat, 20 Jun 2026 12:14:47 GMT', 'id': '6a3684368f31aefdd99463ed', 'is_nested': True, 'location': 'local', 'model': 'huggingface_sentence-transformers/all-mpnet-base-v2', 'name': '20251025105453.jpg', 'retriever': 'classic', 'syncFrequency': None, 'tokens': '0', 'type': 'local'}## GET/api/sources API_URL = f"http://localhost:7091/api/sources", sr_dir= requests.get(API_URL) result = sr_dir.json() print(f"{sr_dir}\n{list(result)}") print(f"-->2") for line in result: print(f"dirName: {line['name']}") ######################################### -->1 <Response [200]> [{'date': 'default', 'location': 'remote', 'model': 'huggingface_sentence-transformers/all-mpnet-base-v2', 'name': 'Default', 'retriever': 'classic', 'tokens': ''}, {'date': 'Sat, 20 Jun 2026 12:14:47 GMT', 'id': '6a3684368f31aefdd99463ed', 'is_nested': True, 'location': 'local', 'model': 'huggingface_sentence-transformers/all-mpnet-base-v2', 'name': '20251025105453.jpg', 'retriever': 'classic', 'syncFrequency': None, 'tokens': '0', 'type': 'local'}, {'date': 'Thu, 01 Jan 2026 13:49:17 GMT', 'id': '69567b5c0b7a430ac258a10c', 'is_nested': True, 'location': 'local', 'model': 'huggingface_sentence-transformers/all-mpnet-base-v2', 'name': 'SAP.pdf', 'retriever': 'classic', 'syncFrequency': None, 'tokens': '4969', 'type': 'local'}, {'date': 'Wed, 31 Dec 2025 07:18:25 GMT', 'id': '6954ce1a204c7414e7906051', 'is_nested': True, 'location': 'local', 'model': 'huggingface_sentence-transformers/all-mpnet-base-v2', 'name': '面向开发者的+LLM+入门课程.pdf', 'retriever': 'classic', 'syncFrequency': None, 'tokens': '230039', 'type': 'local'}, {'date': 'Wed, 31 Dec 2025 07:13:47 GMT', 'id': '6954cd2b204c7414e7906050', 'is_nested': True, 'location': 'local', 'model': 'huggingface_sentence-transformers/all-mpnet-base-v2', 'name': 'software.txt', 'retriever': 'classic', 'syncFrequency': None, 'tokens': '0', 'type': 'local'}] -->2 dirName: Default dirName: 20251025105453.jpg dirName: SAP.pdf dirName: 面向开发者的+LLM+入门课程.pdf dirName: software.txt -->Answer: **问题是否明确**## GET/api/sources/paginated sr = { "source_id": "6a3684368f31aefdd99463ed" } result = sr_paginated.json() print(f"-->1\n{sr_paginated}\n{list(result)}") ####################################### <Response [200]> ['currentPage', 'paginated', 'total', 'totalPages'] - attachment
Operations Desc. GET/api/images/{image_path} Serve an image from storage POST/api/store_attachment Stores one or multiple attachments without vectorization or training.Supports user or API key authentication. 存储一个或多个附件,不进行向量化或训练。支持用户或API密钥认证。
POST/api/stt Transcribe an uploaded audio file 转录上传的音频文件
POST/api/stt/live/chunk Transcribe a chunk for a live speech-to-text session 转录一段实时语音转文字会话
POST/api/stt/live/finish Finish a live speech-to-text session POST/api/stt/live/start Start a live speech-to-text session POST/api/tts Synthesize audio speech from text image_path = "inputs/local/20251025105453.jpg/20251025105453.jpg" API_URL = f"http://localhost:7091/api/images/{image_path}", img = requests.get(API_URL) print(img, "\n", list(img)) ######################################### <Response [200]> Squeezed text(237 lines)
参考:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)