AI面试官全栈项目:用AI技术让求职辅导普惠化
1项目概述
AI面试官 是一款集智能简历优化、模拟面试实战、心理陪伴辅导于一体的全栈应用。不同于传统的求职平台,我们不仅关注"技术能力提升",更重视"心理状态关怀"——求职不仅是技能的比拼,更是心态的考验。
2技术架构
2.1整体架构图
2.2技术栈选择
| 层次 | 技术 | 选型理由 |
|---|---|---|
| 前端 | HTML5 + CSS3 + JavaScript | 轻量快速,无需构建工具,快速交付 |
| 前端框架 | 原生JS + Axios | 简单直接,适合中小项目快速迭代 |
| 后端框架 | FastApi | 高性能异步支持,自动生成API文档,开发体验极佳 |
| ORM | SQLAlchemy | 成熟稳定,支持多种数据库,代码可读性强 |
| 数据库 | MySQL | 开源稳定,社区活跃,适合中小型应用 |
| AI服务 | Dify | 低代码构建AI工作流,支持流式响应,便于快速迭代 |
| 认证 | JWT | 无状态认证,轻量级,易于扩展 |
3核心功能模块
3.1用户认证模块
设计特点:Token仅用于身份识
# backend/routers/auth_router.py
@app.post("/api/auth/login")
async def login(req: LoginRequest, db: Session = Depends(get_db)):
"""登录接口 — 验证用户并返回JWT Token"""
user = db.query(User).filter(User.username == req.username).first()
if not user or not bcrypt.verify(req.password, user.password_hash):
raise HTTPException(401, "用户名或密码错误")
access_token = create_access_token(data={"sub": user.username})
return TokenResponse(access_token=access_token)
安全性考量:
- 使用 bcrypt 进行密码哈希存储(12轮加盐)
- JWT Token 设置合理过期时间(默认1440分钟,即24小时)
- 前端自动拦截401响应,跳转登录页并清除本地存储
3.2智能简历优化
核心流程:
上传文件 → 解析文本 → 调用Dify工作流 → 返回优化结果 → 保存历史
文件解析支持:backend/services/file_parser.py
def parse_resume_file(filename: str, content: bytes) -> str:
"""解析不同格式的简历文件"""
ext = filename.lower().split('.')[-1]
if ext == 'txt':
return content.decode('utf-8', errors='ignore')
elif ext == 'pdf':
with BytesIO(content) as f:
reader = PyPDF2.PdfReader(f)
return '\n'.join(page.extract_text() for page in reader.pages)
elif ext == 'docx':
with BytesIO(content) as f:
doc = Document(f)
return '\n'.join(para.text for para in doc.paragraphs)
else:
return content.decode('utf-8', errors='ignore')
优化效果:通过 Dify 工作流实现简历的智能分析和优化建议生成,支持自定义目标岗位进行针对性优化。
3.3模拟面试系统
核心流程:
用户配置面试参数 → 调用Dify工作流生成开场问题 → 多轮问答交互 → 结束面试生成评估报告。
关键环节:
- 面试类型支持技术面/HR面/综合面
- 基于简历快照个性化提问
- 结束时通过独立工作流生成结构化报告(含各维度评分、优势分析、改进建议)。
面试类型:
- 技术面:考察专业技能和技术深度
- HR面:考察软技能和价值观匹配
- 综合面:全面评估候选人能力
关键流程:backend/routers/interview_router.py
@router.post("/start")
async def do_start_interview(req: StartInterviewRequest, ...):
"""开始新面试会话"""
# 调用Dify工作流获取开场问题
result = await start_interview(
req.interview_type,
req.position,
req.resume_snapshot
)
# 创建会话记录
session = InterviewSession(
user_id=current_user.id,
interview_type=req.interview_type,
position=req.position,
...
)
db.add(session)
db.commit()
return StartInterviewResponse(
session_id=session.id,
opening_message=result["answer"]
)
评估报告生成:
@router.post("/{session_id}/end")
async def do_end_interview(session_id: int, ...):
"""结束面试,生成评估报告"""
# 调用Dify评估报告工作流
report_result = await generate_interview_report(
interview_type=session.interview_type,
position=session.position,
messages=[{"role": m.role, "content": m.content} for m in messages]
)
session.overall_score = report_result.get("overall_score", 7)
session.report_json = report_result["report_json"]
session.end_time = datetime.utcnow()
db.commit()
报告内容结构:
📊 各维度评分(技术能力、沟通能力、表达能力等)
✅ 优势亮点
🔧 需要提升
💡 提升建议
🔄 逐轮反馈
如图: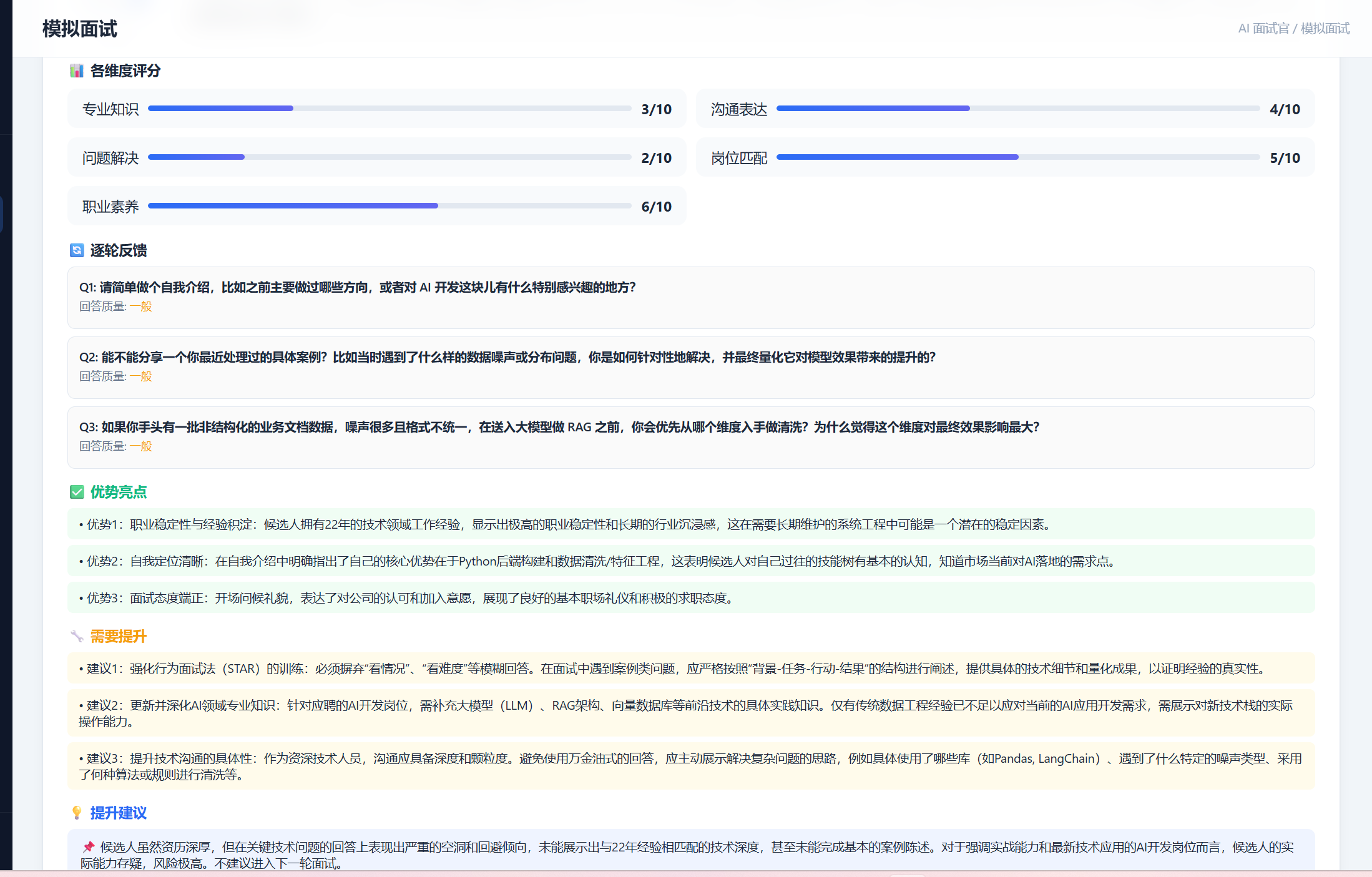
3.4心理陪伴系统
设计理念:温暖共情+危机干预
3.4.1 AI情感陪伴对话
backend/services/dify.py
async def chat_pep_talk(user_id: int, conversation_id: str, message: str) -> dict:
"""心理陪伴对话 — 检测危机信号"""
r = await _call_chat(DIFY_PEPTALK_API_KEY, {}, message, conversation_id, user=str(user_id))
answer = r["answer"]
# 危机检测
is_crisis = _detect_crisis(message)
if is_crisis:
answer += "\n\n" + CRISIS_HELPLINE
return {"ai_message": answer, "conversation_id": r["conversation_id"], "is_crisis": is_crisis}
危机干预机制:
def _detect_crisis(text: str) -> bool:
"""检测自伤/自杀倾向关键词"""
keywords = ["自伤", "自杀", "不想活", "结束生命", "伤害自己", "自残", "想死", "活不下去", "死了算了"]
return any(kw in text for kw in keywords)
触发危机干预时自动追加援助热线:
热线名称 电话号码
北京心理危机干预中心 010-82951332
全国24小时心理援助热线 400-161-9995
生命热线 400-821-1215
改进计划:当前方案简单有效,但未来会引入情感分析模型(如基于BERT的轻量级分类器)提高准确率,同时设计用户反馈机制来优化关键词库。
3.4.2 每日励志语录
DAILY_QUOTES = [
"每一次面试都是一次成长的机会,不要害怕失败。",
"你的价值不是由一份工作决定的,而是由你的坚持和勇气定义的。",
"求职路上,不放弃就已经赢了一半。今天也要加油!",
"面试不是审判,而是一次双向选择的对话。你同样在评估他们。",
"没有人一出生就会面试,所有技巧都是练出来的。",
"焦虑的反面不是平静,而是行动。迈出第一步,焦虑就会减半。",
"今天你投出的每一份简历,都在为明天的offer铺路。",
"你不是在找工作,你是在找一段新的成长旅程。",
]
@router.get("/daily-quote")
def get_daily_quote():
"""每日一句励志语录 — 根据日期生成固定索引"""
today = date.today()
day_index = today.toordinal() % len(DAILY_QUOTES)
return {"quote": DAILY_QUOTES[day_index], "date": today.isoformat()}
技术改进:最初使用 random.seed(date) 实现每日一句,但发现random是全局种子可能影响其他随机功能。改用 date.toordinal() % len(DAILY_QUOTES) 更简洁且安全。
3.4.3情绪匹配推荐
根据用户情绪状态推荐音乐和视频资源:
| 情绪 | 推荐类型 | 示例 |
|---|---|---|
| 😰 焦虑 | 轻音乐 | Weightless - Marconi Union(科学验证降低65%焦虑) |
| 😕 迷茫 | 励志视频 | TED演讲《如何找到你真正热爱的工作》 |
| 😴 疲惫 | 白噪音 | 雨声、海浪声助眠 |
| 😞 挫败 | 激励音乐 | 《追梦赤子心》- GALA |
4为什么选择dify而不是直接调用大模型API?
最终选择Dify主要有以下几个原因:
- 低代码编排工作流:简历优化、面试评估等复杂prompt链 以可视化调整,无需改后端代码。这对于快速迭代非常重要。
- 内置RAG和知识库:未来计划对接企业面试题库,Dify已经提供了完整的知识库管理功能。
- 成本可控:相比自建LLM网关,Dify提供免费社区版和清晰的API计费,适合初创项目。
- 流式响应支持:心理陪伴模块需要实时响应,Dify的Chat API天然支持流式输出。
- 团队协作友好:可以邀请团队成员共同编辑工作流,便于知识沉淀和协作开发。
5数据库设计
核心数据表关系
表关系说明:
Users与Profiles是一对一关系(一个用户对应一个档案)Users与InterviewSessions是一对多关系(一个用户可以有多次面试)InterviewSessions与InterviewMessages是一对多关系(一次面试有多条消息)
6前端实现
6.1路由管理
frontend/js/router.js
const Router = {
currentPage: 'profile',
init() {
this.renderSidebar();
this.go('profile');
},
go(page) {
this.currentPage = page;
document.querySelectorAll('.page').forEach(p => p.style.display = 'none');
document.getElementById(`page-${page}`).style.display = 'block';
this.updateSidebar();
// 调用对应页面渲染函数
const pageHandlers = {
profile: () => PageProfile.render(),
interview: () => PageInterview.render(),
resume: () => PageResume.render(),
peptalk: () => PagePepTalk.render(),
history: () => PageHistory.render(),
};
pageHandlers[page]?.();
},
...
};
页面模块说明:每个页面模块(如 PageProfile)负责动态渲染HTML和绑定事件,代码位于 frontend/js/pages/ 目录下。
6.2聊天界面实现
// 消息发送流程
const PageInterview = {
async send() {
const text = document.getElementById('iv-user-input').value.trim();
if (!text || !ivSessionId) return;
// 显示用户消息
this.addMsg('user', text);
// 显示加载状态
const loadingId = this.addMsg('ai', '<div class="spinner"></div>');
// 调用API
const res = await InterviewAPI.respond(ivSessionId, text);
// 更新AI回复
this.updateMsg(loadingId, res.data.ai_message);
},
addMsg(role, content) {
const div = document.createElement('div');
div.className = `msg-bubble ${role}`;
div.innerHTML = `<div class="msg-label">${role==='ai'?'🤖 面试官':'👤 你'}</div><div>${content}</div>`;
document.getElementById('iv-messages').appendChild(div);
},
...
};
7踩过的坑
7.1坑1:Dify工作流超时与异步任务解耦
问题深度剖析:
- Dify工作流执行评估报告时,涉及多轮LLM调用和复杂逻辑处理,平均耗时45-90秒
- 前端HTTP请求默认超时30秒,导致用户端显示失败但后端仍在执行
- 重试机制缺失,失败后需用户手动重新提交
- 高并发场景下,长时间阻塞的请求会占用大量服务器资源。
# backend/services/task_queue.py - 引入异步任务队列
from celery import Celery
from celery.exceptions import TimeoutError
from config import REDIS_URL
celery_app = Celery('tasks', broker=REDIS_URL, backend=REDIS_URL)
@celery_app.task(bind=True, max_retries=3, retry_backoff=2)
def async_generate_report(self, interview_type, position, messages):
"""异步生成评估报告,支持重试和任务追踪"""
try:
return generate_interview_report(interview_type, position, messages)
except Exception as e:
# 指数退避重试
self.retry(exc=e, countdown=2 ** self.request.retries)
# backend/routers/interview_router.py - 重构后的结束面试接口
@router.post("/{session_id}/end")
async def do_end_interview(session_id: int, ...):
"""结束面试 - 异步生成报告,返回任务ID"""
# 1. 先更新会话状态为"处理中"
session.status = "processing"
db.commit()
# 2. 提交异步任务
task = async_generate_report.delay(
interview_type=session.interview_type,
position=session.position,
messages=[{"role": m.role, "content": m.content} for m in messages]
)
# 3. 返回任务ID,前端轮询获取结果
return {"task_id": task.id, "status": "processing"}
@router.get("/report/task/{task_id}")
async def get_report_task(task_id: str):
"""查询报告生成任务状态"""
task = async_generate_report.AsyncResult(task_id)
if task.state == 'SUCCESS':
# 更新数据库并返回结果
result = task.result
return {"status": "completed", "report": result}
elif task.state == 'PENDING':
return {"status": "processing"}
elif task.state == 'FAILURE':
return {"status": "failed", "error": str(task.info)}
架构优化要点:
- 使用Celery + Redis实现异步任务队列
- 前端通过轮询或WebSocket获取任务状态
- 实现指数退避重试策略(2^n秒间隔)
- 添加任务超时监控和告警机制
7.2坑2:PDF解析中文乱码
问题:某些PDF文件使用GBK编码,直接用UTF-8解析会出现乱码。
解决:检测编码并指定合适的解码方式。
try:
return content.decode('utf-8')
except UnicodeDecodeError:
return content.decode('gbk', errors='ignore')
7.3坑3:前端状态管理与JWT安全实践
问题深度剖析:
- localStorage存在XSS攻击风险
- Token过期后需要无感刷新
- 多Tab页签登录状态不同步
- 敏感操作缺少双重验证
// frontend/js/auth.js - 安全的认证管理
class AuthManager {
constructor() {
this.tokenKey = 'ai_interview_token';
this.refreshTokenKey = 'ai_interview_refresh_token';
this.setupInterceptors();
this.setupStorageSync();
}
// 使用HttpOnly Cookie存储Refresh Token
getToken() {
return localStorage.getItem(this.tokenKey);
}
setToken(accessToken, refreshToken) {
localStorage.setItem(this.tokenKey, accessToken);
// Refresh Token通过HttpOnly Cookie传递,前端不可访问
document.cookie = `refresh_token=${refreshToken}; HttpOnly; Secure; SameSite=Strict`;
}
// 无感Token刷新
async refreshToken() {
try {
const response = await api.post('/api/auth/refresh');
const newToken = response.data.access_token;
localStorage.setItem(this.tokenKey, newToken);
return newToken;
} catch {
this.clearAuth();
throw new Error('登录已过期,请重新登录');
}
}
// 请求拦截器:自动重试和Token刷新
setupInterceptors() {
api.interceptors.response.use(
response => response,
async error => {
const originalRequest = error.config;
if (error.response.status === 401 && !originalRequest._retry) {
originalRequest._retry = true;
try {
await this.refreshToken();
originalRequest.headers.Authorization = `Bearer ${this.getToken()}`;
return api(originalRequest);
} catch {
window.location.href = '/login.html';
}
}
return Promise.reject(error);
}
);
}
// 跨Tab页签状态同步
setupStorageSync() {
window.addEventListener('storage', (e) => {
if (e.key === this.tokenKey && !e.newValue) {
// 其他页签登出,同步当前页签
this.clearAuth();
window.location.href = '/login.html';
}
});
}
clearAuth() {
localStorage.removeItem(this.tokenKey);
document.cookie = 'refresh_token=; expires=Thu, 01 Jan 1970 00:00:00 UTC; path=/;';
}
}
const authManager = new AuthManager();
# backend/routers/auth_router.py - 安全的Token刷新机制
@app.post("/api/auth/refresh")
async def refresh_token(request: Request):
"""通过HttpOnly Cookie中的Refresh Token刷新Access Token"""
refresh_token = request.cookies.get("refresh_token")
if not refresh_token:
raise HTTPException(401, "未提供刷新Token")
try:
payload = jwt.decode(refresh_token, REFRESH_SECRET_KEY, algorithms=[ALGORITHM])
username = payload.get("sub")
user = db.query(User).filter(User.username == username).first()
if not user:
raise HTTPException(401, "用户不存在")
# 生成新的Access Token
access_token = create_access_token(data={"sub": username})
return {"access_token": access_token}
except JWTError:
raise HTTPException(401, "无效的刷新Token")
安全要点:
- Access Token存储在localStorage(便于前端访问)
- Refresh Token存储在HttpOnly Cookie(防止XSS)
- 实现无感Token刷新
- 跨Tab页签登录状态同步
- 设置Token过期时间和刷新策略
8安全性与性能优化
8.1安全措施
| 措施 | 说明 |
|---|---|
| 密码安全 | 使用 bcrypt 哈希存储,禁止明文存储 |
| JWT 认证 | 无状态认证,Token设置过期时间 |
| 输入验证 | 使用 Pydantic 模型进行请求参数验证 |
| CORS 配置 | 生产环境限制允许的域名 |
| 文件上传限制 | 限制文件大小(10MB)和类型 |
8.2性能优化
| 优化项 | 说明 |
|---|---|
| 异步处理 | 使用FastAPI异步端点 + httpx异步客户端 |
| 数据库索引 | 对常用查询字段(user_id, username)建立索引 |
| 请求超时 | 设置合理的超时时间(120秒) |
| 批量操作 | 使用 bulk_save_objects 优化批量写入 |
9部署与运行
9.1 环境依赖
# 后端依赖
fastapi==0.110.0
uvicorn==0.27.0
sqlalchemy==2.0.25
pymysql==1.1.0
python-jose[cryptography]==3.3.0
passlib[bcrypt]==1.7.4
python-dotenv==1.0.0
httpx==0.26.0
PyPDF2==3.0.1
python-docx==0.8.11
9.2 .env.example文件
# 数据库配置
DB_HOST=127.0.0.1
DB_PORT=3306
DB_USER=root
DB_PASSWORD=your_password
DB_NAME=ai_interview
# JWT 配置
SECRET_KEY=your-secret-key-change-in-production
ALGORITHM=HS256
ACCESS_TOKEN_EXPIRE_MINUTES=1440
# Dify API 配置
DIFY_API_BASE=https://api.dify.ai/v1
DIFY_SELF_INTRO_API_KEY=your_key
DIFY_INTERVIEW_API_KEY=your_key
DIFY_RESUME_API_KEY=your_key
DIFY_PEPTALK_API_KEY=your_key
DIFY_REPORT_API_KEY=your_key
10 项目复盘与未来规划
当前成果
- 完成核心功能开发(简历优化、模拟面试、心理陪伴)
- 通过内测验证功能可用性
- 建立完整的API文档
11总结
AI面试官 项目不仅是一个技术练习,更是我对求职焦虑的解决方案。通过整合 FastAPI、Dify AI 工作流和前端原生技术,我们构建了一个既有技术深度又有人文关怀的求职辅助平台。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)