τ0-WM:统一视频-动作世界模型 — 技术细节与设计原理全解
前言:
说实在的最近罗老师课题组真的是高产呀,不过也可以看得出来,整体的布局还是世界模型和真机分布式集群的强化学习论文解读:Learning while Deploying (LWD)—— 面向通用机器人策略的集群级强化学习框架,大家知道未来的方向了吧,不过这篇文章整体思路倒不是说新提出来的,比如快慢思考逻辑,这部分在智驾已经再用了,我觉得我比较关注的一个点是推理效率,之前发布的世界动作模型在机器人上应用最大的一个难点是推理效率,这份工作也展示了他们在单张5090推理起来。
待更:等我在反复细品一下更多继续细节再更新
论文:τ0-WM: A Unified Video-Action World Model for Robotic Manipulation
机构:上海创智学院(SII)、智元机器人具身研究中心(AGIBOT Finch)
代码:https://github.com/sii-research/tau-0-wm
模型:https://huggingface.co/sii-research/tau-0-wm
项目页:τ0-WM: A Unified Video-Action World Model for Robotic Manipulation - Research - AGIBOT Finch
一、论文概述
1.1 核心问题
机器人操作需要模型同时具备两种能力:
- 预测动作后果:如果执行这个动作,场景将如何变化?
- 生成可执行动作:机器人应该做什么?
现有方法的困境:
- 纯策略模型(如 π0.5):看到场景就输出动作,是"条件反射"——在面对长程、接触丰富的精细操作时容易一步错步步错
- 纯世界模型:能预测未来但无法生成动作,且训练数据与机器人控制空间不对齐
- 关键矛盾:大规模视频数据有丰富的物体交互动态但无动作标签;真机数据有动作标签但覆盖范围有限
1.2 核心思路
统一的视频-动作框架:异构数据源只监督它真正包含的信号——
- 有视频就监督视觉预测
- 有动作就监督动作生成
- 有进度标签就监督任务进度评估
三种能力围绕共享的预测表示构建:策略接口回答"做什么",模拟器接口回答"做了会怎样",测试时组合为"提议→评估→修正"循环。
1.3 一句话总结
τ0-WM = 27,300h 多源异构数据预训练 + 共享视频 DiT 骨干 + VAM(动作+视频联合预测)+ ACVS(动作条件视频模拟器)+ RCS/LAR 测试时推理 = 5B 参数的最大开源具身世界模型
二、模型架构
2.1 整体架构:共享骨干 + 双接口
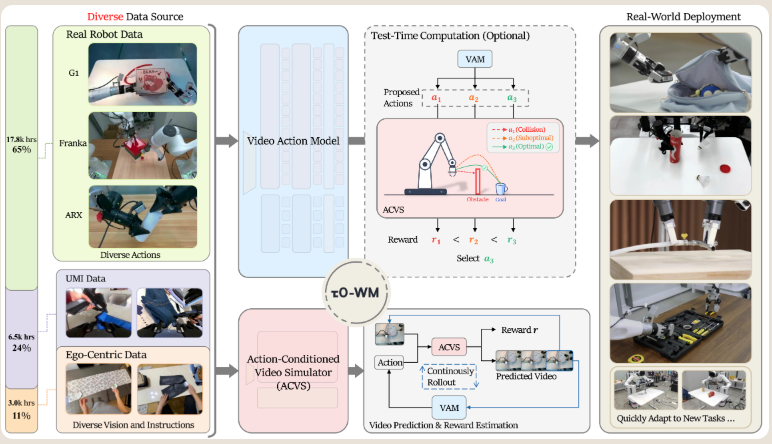
τ0-WM 的核心是一个视频动作模型 (VAM),它使用共享的视频扩散骨干网络,接收多视角观测数据、语言指令和机器人状态,并联合预测未来的视觉潜能和连续动作块。视频分支捕捉时间结构化的场景动态,而动作分支则通过逐层交叉注意力机制关注中间视频表征,从而预测可执行的控制。这种耦合使得未来预测成为与控制相关的训练目标:动作分支被鼓励使用能够编码场景在操作下可能演变方式的表征。除了 VAM 之外,共享表征还使 τ0-WM 能够作为动作条件模拟器:给定当前的观测数据、指令和候选动作块,它可以预测多视角下的未来结果,以及从子任务进度标签和失败数据中学习到的密集任务进度轨迹,从而从视觉合理性和任务推进两个方面评估动作。
┌─────────────────────────────────────────────────────────┐
│ 输入层 │
│ 多视角图像(3路相机)+ 语言指令 + 机器人状态 │
│ Wan VAE 编码 → 隐变量画布(视角沿空间宽度拼接) │
└───────────────────────┬─────────────────────────────────┘
↓
┌───────────────────────────────────────────────────────────┐
│ 策略接口:VAM(Video Action Model) │
│ ┌───────────────────────────────────────────────────┐ │
│ │ 视频 DiT 骨干(5B,Wan2.2-TI2V-5B) │ │
│ │ 输入:干净视觉上下文 + 加噪未来视觉槽位 │ │
│ │ 条件:语言指令 + 机器人状态 │ │
│ │ 输出:去噪后的未来视觉隐变量 │ │
│ └─────────────────────┬─────────────────────────────┘ │
│ │ 层级交叉注意力 │
│ ┌─────────────────────▼─────────────────────────────┐ │
│ │ 动作 DiT 解码器(0.5B) │ │
│ │ 输入:动作 token + 视频中间层特征(交叉注意力) │ │
│ │ 输出:连续动作块(action chunk) │ │
│ └───────────────────────────────────────────────────┘ │
│ 训练目标:Flow Matching(视频隐变量 + 动作块) │
└───────────────────────────────────────────────────────────┘
┌───────────────────────────────────────────────────────────┐
│ 评估接口:ACVS(Action-Conditioned Video Simulator) │
│ ┌───────────────────────────────────────────────────┐ │
│ │ 视频 DiT 骨干(复用 VAM 骨干,移除动作分支) │ │
│ │ 输入:干净视觉上下文 + 加噪未来槽位 │ │
│ │ 条件:语言指令 + 机器人状态 + 候选动作块 │ │
│ │ 动作条件化:MLP → 扩散时间嵌入 + AdaLN 调制 │ │
│ │ 输出: │ │
│ │ 1. 多视角未来视频 rollout │ │
│ │ 2. 密集任务进度轨迹(子任务级奖励) │ │
│ └───────────────────────────────────────────────────┘ │
│ 训练目标:Flow Matching(视频隐变量)+ 密集奖励回归 │
└───────────────────────────────────────────────────────────┘2.2 VAM:视频动作模型(策略接口)
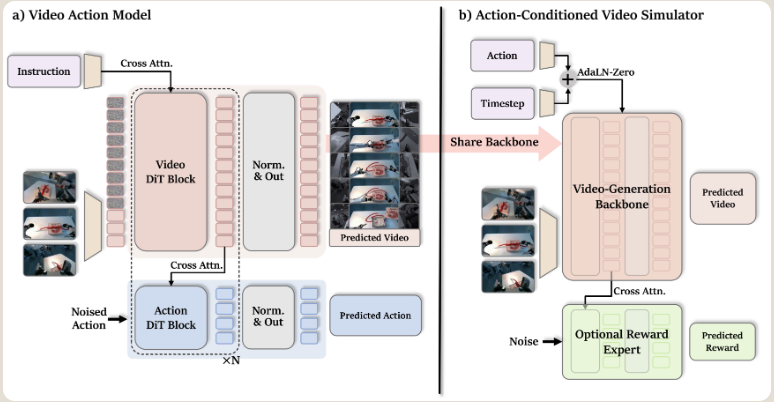
2.2.1 视频分支
|
项目 |
内容 |
|
基座模型 |
Wan2.2-TI2V-5B(5B 参数视频扩散 Transformer) |
|
VAE |
Wan 预训练时空 VAE,将各相机视角独立编码为隐变量 |
|
多视角处理 |
同步多视角隐变量沿空间宽度维度拼接,形成时序对齐的隐变量画布 |
|
条件输入 |
当前观测(干净视觉上下文)+ 语言指令 + 机器人状态 |
|
目标 |
对加噪的未来视觉隐变量去噪,预测未来多视角视频 |
|
参数量 |
5B |
设计原理:
- 选择 Wan2.2 而非 VLM:视频扩散模型天然建模时序动态,是"想象未来"的最佳骨干
- 沿空间宽度拼接而非通道拼接:保持空间结构不被破坏,不同视角的物体位置关系在拼接后仍然保持
- 当前观测作为干净上下文保留:避免去噪过程中的信息损失,为模型提供精确的当前状态
2.2.2 动作分支
|
项目 |
内容 |
|
架构 |
0.5B 参数 DiT 风格动作解码器 |
|
输入 |
动作 token(自回归/块预测) |
|
信息融合 |
通过层级交叉注意力(layer-wise cross-attention)关注视频分支中间层特征 |
|
输出 |
连续动作块(action chunk) |
|
训练目标 |
Flow Matching(与视频分支联合训练) |
设计原理:
- 为什么不直接从视频特征预测动作? 层级交叉注意力让动作解码器在每一层都能获取与当前预测时步相关的视觉动态信息,而不是只在最后一层做一次粗粒度融合
- 为什么用独立的动作解码器而非共享? 动作生成的粒度和语义层级与视频预测不同。独立解码器可以针对动作空间做专门优化,同时通过交叉注意力利用视频分支的丰富中间表示
- 为什么 Flow Matching 而非自回归? Flow Matching 对连续动作块建模更自然,训练更稳定,且支持少步采样推理
2.3 ACVS:动作条件视频模拟器(评估接口)
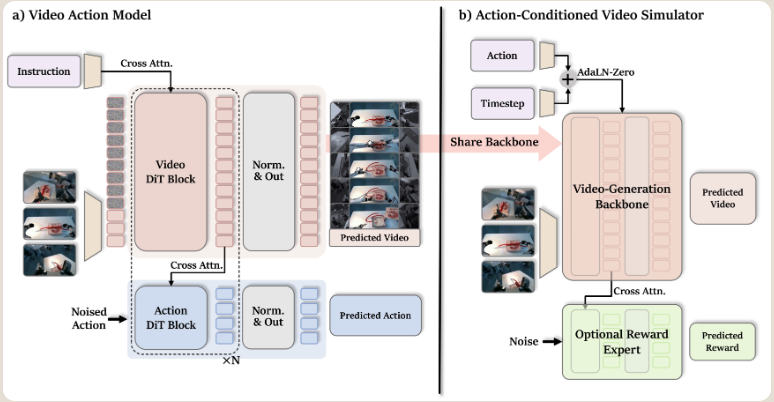
|
项目 |
内容 |
|
骨干 |
复用 VAM 的视频 DiT 骨干(移除动作分支) |
|
输入 |
干净视觉上下文 + 语言指令 + 机器人状态 + 候选动作块 |
|
动作条件化 |
遵循 Cosmos 设计:每个未来隐变量槽位,时序对齐的动作通过轻量 MLP 投影为扩散时间嵌入和 AdaLN 调制嵌入,广播至对应槽位的空间 token 和相机视角 |
|
输出1 |
多视角未来视频 rollout |
|
输出2 |
密集任务进度轨迹(reward trajectory) |
|
观测槽位 |
无动作条件化 |
设计原理:
- 复用视觉骨干而非独立模型:共享预训练权重使得 ACVS 可以零成本获得 VAM 已学习的视觉动态先验,且维护成本极低
- AdaLN 调制嵌入动作条件:轻量、高效,不增加骨干参数量,通过仿射变换将动作信息注入每个未来时间步的特征
- 观测槽位无条件化:当前观测是事实(不需要动作条件化),只有未来需要以动作为条件预测——这明确了因果关系
三、数据处理流程
3.1 三源异构数据
|
数据源 |
规模 |
设备 |
提供的监督信号 |
特点 |
|
真实机器人遥操作 |
17,800h |
AGIBOT-G01、ARX、双臂 Franka |
视频 + 动作 + 进度标签 |
动作标签最可靠,与部署对齐,但成本高、多样性有限 |
|
UMI 式演示数据 |
6,500h |
手持夹爪式采集设备 |
视频 + 弱动作信号 |
环境多样性高,成本低,但与目标机器人弱对齐 |
|
第一视角人体视频 |
3,000h |
人体佩戴相机 |
仅视频 |
物体交互最广泛,无动作标签,与机器人视角差异大 |
三种数据的互补逻辑:
- 真机数据:动作 grounding 的基石——将模型锚定在可执行的机器人控制空间
- UMI 数据:扩大操作行为和环境的多样性——提供弱动作信号的中等成本选项
- 人体视频:最广泛的视觉交互学习——让模型见过各种物体怎么动、怎么接触、怎么变化
3.2 统一监督掩码(Modality-Specific Supervision Mask)
这是 τ0-WM 数据融合的核心机制:
┌──────────────────┬────────────┬────────────┬──────────────┐
│ 数据源 │ 视频预测 │ 动作生成 │ 任务进度评估 │
├──────────────────┼────────────┼────────────┼──────────────┤
│ 真机遥操作 │ ✅ │ ✅ │ ✅ │
│ UMI 数据 │ ✅ │ ✅ │ 部分 │
│ 人体视频 │ ✅ │ ❌ │ ❌ │
│ Rollout 轨迹 │ ✅ │ ✅ │ 失败标签 │
│ 失败轨迹 │ ✅ │ ✅ │ 负奖励 │
└──────────────────┴────────────┴────────────┴──────────────┘具体实现:
- 每个样本的监督掩码指定:哪些输入被观测、哪些目标被预测、哪些损失被激活
- 缺失的相机视角 → 掩码屏蔽
- 人体视频 → 动作损失掩码为 0,仅视频预测损失激活
- 失败轨迹 → 进度预测中对应段赋予负奖励
设计原理:
- 不强制所有数据源提供相同类型的监督,而是"各自贡献自己能贡献的"
- 异构性不再是噪声或预处理负担,而是互补的监督来源
- 人体视频虽然无动作标签,但其视觉动态知识可以迁移到动作生成(通过共享的视频骨干)
3.3 密集奖励构建
与 ViVa 的二值成功标签不同,τ0-WM 构建了子任务级别的密集奖励:
- 将每项操作任务分解为子任务序列
- 在子任务级别分配进度标签
- 通过蒙特卡洛传播估计帧级奖励
- 失败数据被有意纳入:对于失败的子任务段,对应轨迹上的奖励赋予负值
设计原理:
- 密集奖励比二值成功标签提供更细粒度的任务进度信号
- 负奖励使 ACVS 能识别导致失败的动作后果(如空抓、掉落、错位),而非只标记"最终未成功"
- 蒙特卡洛传播将稀疏的子任务标签扩展为帧级信号,无需逐帧人工标注
四、训练细节
4.1 预训练
|
项目 |
内容 |
|
模型规模 |
5B(视频 DiT 骨干)+ 0.5B(动作 DiT 解码器) |
|
训练数据 |
≈ 27,300h 异构数据 |
|
训练目标 |
Flow Matching |
|
核心思想 |
围绕共享预测表示,异构数据各自贡献可监督的信号 |
VAM 的联合训练目标:
L_VAM = λ_video · L_FM(z_video) + λ_action · L_FM(a_chunk)- 视频分支:对加噪的未来视觉隐变量做流匹配去噪
- 动作分支:对动作块做流匹配去噪
- 两个分支通过层级交叉注意力耦合
- 人体视频样本:λ_action = 0(仅监督视频预测)
ACVS 的训练目标:
L_ACVS = L_FM(z_video) + λ_reward · L_reward(reward_trajectory)- 视频预测:与 VAM 共享的流匹配目标
- 奖励预测:密集任务进度的回归损失
- 动作通过 AdaLN 调制嵌入,非交叉注意力
4.2 监督微调(SFT)
在目标任务的少量真机演示数据上微调,适应特定的机器人本体和任务配置。
4.3 机器人平台
|
机器人 |
类型 |
部署场景 |
|
AGIBOT-G01 |
双臂人形机器人 |
工具收纳、羽毛球装盒 |
|
ARX 机械臂 |
双臂协作 |
书包操作 |
|
双臂 Franka |
双臂 Franka Panda |
水龙头管件对接 |
五、测试时计算:提议–评估–修正
这是 τ0-WM 最具创新性的推理策略,将"先想清楚再做"的系统化思维引入机器人控制。
5.1 整体流程
┌─────────────────────────────────────────────┐
│ Step 1: 提议(Proposal) │
│ VAM 采样 N 个候选动作块 │
│ a_1, a_2, ..., a_N │
└──────────────────┬──────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ Step 2: 评估(Evaluation) │
│ 对每个候选计算重去噪一致性评分 RCS │
│ RCS(a_i) = -1/K Σ ||v_θ(a_i^τ, τ, c) - v|| │
│ 选取 RCS 最高的候选 a* │
└──────────────────┬──────────────────────────┘
↓
RCS(a*) >= 阈值?
/ \
是 否
↓ ↓
直接执行 a* ┌────────────────────────────┐
│ Step 3: 修正(Revision) │
│ ACVS 对每个候选 rollout │
│ 预测未来视频 + 密集奖励轨迹 │
│ 选取最大任务进度的 rollout │
│ 将最佳未来隐变量注入 VAM │
│ VAM 生成修正动作块 a_revise │
│ 执行 a_revise │
└────────────────────────────┘5.2 重去噪一致性评分(RCS)
核心问题:VAM 采样多个动作候选后,如何快速判断哪个最好?
方法:
- 对候选动作 a_i,随机采样 K 个流时间步 τ_1, ..., τ_K
- 按训练时的流匹配过程对 a_i 重新加噪:a_i^τ = (1-τ)·a_i + τ·ε
- 由 VAM 的动作向量场 v_θ 评估去噪误差
- RCS 定义为平均重去噪误差的负值
RCS(a_i) = -(1/K) Σ_k ||v_θ(a_i^{τ_k}, τ_k, c) - v_true||设计原理:
- RCS 衡量候选动作与所学条件化动作分布的一致性——越一致的候选,重去噪误差越小,RCS 越高
- 计算开销极低:只需K次前向传播的动作分支(不涉及视频分支),远小于完整 rollout
- 本质上是一种分布内检测器:高分候选属于已学习的动作流形,低分候选可能是分布外的次优采样
5.3 低质量动作修正(LAR)
触发条件:最佳候选的 RCS 低于可靠性阈值
方法:
- 对每个候选动作块,ACVS 预测想象出的 rollout 和密集奖励轨迹
- 以 imagined rollout 中达到的最大任务进度作为该候选的 rollout 价值
- 选取最高价值的 rollout 作为最有希望的未来
- 将该未来的隐变量作为额外条件注入 VAM
- VAM 基于该高价值未来条件,生成明确朝向该未来的修正动作块
设计原理:
- RCS 是"快思考":计算便宜但只能筛选已有候选的质量
- LAR 是"慢思考":计算昂贵但能在所有候选都不好时,通过模拟想象来发现更好的动作
- 将最佳未来的隐变量作为 VAM 的额外条件 → 类似于"先确定目标状态,再生成通往目标的动作"——这是一种目标条件化的策略
5.4 计算效率
|
模式 |
延迟 |
说明 |
|
纯动作模式 |
~220ms/query |
仅 VAM 生成动作块 |
|
缓存文本表示 |
~180ms/query |
复用文本编码 |
|
+ 交叉注意力 KV 缓存 + torch.compile |
~140ms/query |
工程优化后 |
|
启用 RCS 评估 |
~200ms 额外 |
N=8, K=4 |
|
启用 LAR |
~1-2s 额外 |
ACVS rollout + 二次 VAM 生成 |
|
部署硬件 |
单张 RTX 5090 |
- |
六、实验结果
6.1 评测任务
四个预训练数据中未出现的长程精细操作任务:
|
任务 |
描述 |
机器人 |
难点 |
|
Toolbox |
将桌面工具收纳至工具箱对应位置 |
AGIBOT-G01 |
精确放置、多阶段 |
|
School Bag |
拉开书包拉链、放入物品并拉合 |
ARX |
连续拉链操作、精细对齐 |
|
Faucet |
将软管连接至水龙头并固定 |
双臂 Franka |
极高几何精度要求 |
|
Badminton |
收纳羽毛球并关闭盖子 |
AGIBOT-G01 |
柔性物体、多步操作 |
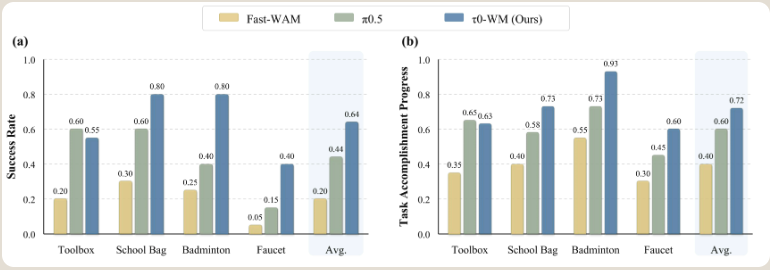
6.2 定量结果
预训练数据组合消融(零样本 + SFT):
|
训练数据 |
零样本平均 SR |
SFT 后SR(整洁桌面) |
SFT 后SR(杂乱桌面) |
|
仅真机遥操作 |
0.14 |
较高 |
一般 |
|
+ UMI 数据 |
↑ 显著 |
↑ |
↑ |
|
+ UMI + 人体视频 |
0.55 |
最高 |
最高 |
关键发现:异构数据的收益在零样本设置下最为显著(0.14 → 0.55),且 SFT 后在杂乱场景下仍有明显提升——说明预训练改善的是泛化能力和鲁棒性,而非仅仅是收敛速度。
测试时计算策略消融:
|
策略 |
平均成功率 |
|
标准执行(单次采样) |
0.43 |
|
+ 分类器自由引导(CFG) |
略有提升 |
|
+ 动作一致性引导(ACG) |
略有提升 |
|
+ RCS |
0.50 |
|
+ RCS + LAR |
0.60 |
关键发现:
- RCS 将成功率从 0.43 提升到 0.50:相当一部分失败是因为选择了次优动作样本,而非策略能力不足
- LAR 进一步提升到 0.60:通过模拟想象找到更好的未来,再目标条件化地生成修正动作
6.3 定性行为差异
在 Toolbox 任务中,基线策略常在工具插入正确槽位后即停止,即使插入不完整或工具仍松散。τ0-WM 倾向于执行额外的修正动作(如进一步推压或按压工具),然后再终止 episode。
原因推测:对未来视觉结果的显式建模,促使策略优化最终场景配置的质量,而非仅仅达到中间任务完成状态。
七、关键技术设计原理总结
|
技术设计 |
做法 |
背后的原理与思考 |
|
视频 DiT 做骨干而非 VLM |
Wan2.2-TI2V-5B |
世界模型的核心是"预测未来",视频生成模型正好被优化来预测未来帧;VLM 只看静态图,无法建模时序动态 |
|
共享预测表示 |
VAM 和 ACVS 共享视频骨干 |
策略学习和动力学建模不应分离:预测未来的能力直接帮助生成更好的动作,动作执行的知识也帮助预测更准确的未来 |
|
层级交叉注意力 |
动作分支每层关注视频中间特征 |
低层视觉特征编码空间结构(物体在哪),高层编码语义动态(物体怎么变化),动作生成需要两者 |
|
独立动作解码器 |
0.5B DiT(不与视频骨干共享 FFN) |
动作空间与视觉空间的粒度和语义不同,独立解码器可以专门优化,交叉注意力只做信息传递 |
|
多视角宽度拼接 |
隐变量沿空间宽度拼接 |
保持每个视角的空间分辨率和结构不被破坏,比通道拼接更自然 |
|
统一监督掩码 |
异构数据各自贡献能监督的信号 |
不强制所有数据提供相同类型监督,异构性是互补而非噪声 |
|
密集任务进度 + 负奖励 |
子任务级标签 + 蒙特卡洛传播 + 失败数据负值 |
比二值成功标签更细粒度,失败数据使模型能识别"错的动作长什么样" |
|
RCS 快速过滤 |
重去噪一致性评分 |
计算便宜,能有效筛选"属于已学习分布"的候选动作 |
|
LAR 慢思考修正 |
ACVS rollout + 目标条件化再生成 |
当所有候选都不好时,通过想象找到最有希望的未来,再围绕该未来重新生成动作 |
|
AdaLN 动作条件化 |
MLP → 时间嵌入 + AdaLN 调制 |
轻量、无额外骨干参数、通过仿射变换将动作信息注入未来预测 |
|
Flow Matching 统一训练 |
视频 + 动作都用流匹配 |
统一的训练框架,支持异构数据联合优化,训练稳定 |
八、数据处理详细流程
原始数据(三源异构)
│
├─ 真机遥操作(17,800h):AGIBOT-G01 + ARX + 双臂 Franka
├─ UMI 数据(6,500h):手持夹爪式采集
└─ 人体视频(3,000h):第一视角人体操作
│
▼
[1] 视角对齐与编码
├── 三路相机图像 → Wan VAE 独立编码 → 隐变量
├── 多视角隐变量 → 沿空间宽度拼接 → 隐变量画布
└── 语言指令 → 文本编码器
│
▼
[2] 时序对齐
├── 图像帧率同步
├── 机器人状态与图像时间戳对齐
└── 动作块与视频帧时序对齐
│
▼
[3] 子任务标注与奖励构建
├── 人工分解任务为子任务序列
├── 子任务级进度标签分配
├── 蒙特卡洛传播 → 帧级密集奖励
└── 失败子任务段 → 负奖励
│
▼
[4] 监督掩码构建
├── 根据数据源类型确定哪些损失激活
├── 人体视频:视频预测 ✅ / 动作生成 ❌ / 进度评估 ❌
├── UMI:视频预测 ✅ / 动作生成 ✅(弱) / 进度评估 部分
├── 真机:视频预测 ✅ / 动作生成 ✅ / 进度评估 ✅
└── 缺失视角 → 掩码屏蔽
│
▼
[5] 潜变量序列组装
├── 当前观测 → 干净视觉上下文(条件帧)
├── 未来槽位 → 加噪隐变量(目标帧)
├── 动作块 → 动作 DiT 输入
└── 候选动作(ACVS)→ MLP + AdaLN 调制嵌入
│
▼
训练就绪数据九、数据集与开源资源
9.1 论文相关资源
|
资源 |
说明 |
地址 |
|
论文 PDF |
τ0-WM 完整论文 |
|
|
代码仓库 |
模型实现与推理代码 |
|
|
模型权重 |
HuggingFace 模型卡 |
|
|
项目主页 |
可视化与补充材料 |
τ0-WM: A Unified Video-Action World Model for Robotic Manipulation - Research - AGIBOT Finch |
9.2 预训练数据集
|
数据集 |
规模 |
类型 |
说明 |
地址 |
|
AgiBot 真机遥操作数据 |
17,800h |
真机遥操作 |
AGIBOT-G01、ARX、双臂 Franka |
|
|
UMI 数据 |
6,500h |
UMI 式手持采集 |
多样化环境、弱动作信号 |
|
|
第一视角人体视频 |
3,000h |
人体操作视频 |
无动作标签,仅视觉监督 |
Ego4D 等开源数据集 |
9.3 基座模型
|
资源 |
说明 |
地址 |
|
Wan2.2-TI2V-5B |
视频扩散 Transformer 基座 |
|
|
Cosmos |
动作条件化设计参考 |
9.4 相关基准与对比模型
|
资源 |
说明 |
地址 |
|
π0.5 |
对比基线 VLA |
|
|
Fast-WAM |
对比基线世界动作模型 |
- |
|
Open X-Embodiment |
最大跨本体数据集 |
|
|
AgiBot World Challenge |
ICRA 2026 世界模型赛道 |
十、与相关工作对比
|
维度 |
τ0-WM |
ViVa |
π0.5 |
π0.6/RECAP |
|
核心定位 |
统一世界模型(动作+视频+评估) |
视频生成价值模型 |
开放世界泛化 VLA |
RL 微调 VLA |
|
视频预测 |
✅ 多视角未来视频 |
✅ 未来本体感知(隐式) |
❌ |
❌ |
|
动作生成 |
✅ VAM 动作分支 |
❌ 仅价值估计 |
✅ Flow Matching |
✅ Flow Matching |
|
价值/进度评估 |
✅ ACVS 密集进度 |
✅ 标量价值 |
❌ |
✅ VLM 价值函数 |
|
测试时推理 |
✅ RCS + LAR |
❌ |
❌ |
✅ 优势条件化 |
|
多源数据联合训练 |
✅ 统一监督掩码 |
❌ |
✅ 协同训练 |
❌ |
|
骨干 |
Wan2.2 5B |
Wan2.2 14B |
PaliGemma 3B |
Gemma 4B |
|
预训练数据 |
27,300h |
数百小时 |
大规模 |
中等 |
十一、局限与未来方向
|
方向 |
说明 |
|
触觉感知 |
当前仅视觉输入,接触丰富操作(如插入、紧固)可能需要触觉反馈 |
|
更长时域预测 |
当前预测时域有限,扩展至更长时域可增强规划能力 |
|
不确定性估计 |
更可靠的不确定性量化可改善 RCS 阈值设定和 LAR 触发条件 |
|
实时推理 |
LAR 修正需 1-2s 额外延迟,对高速操作仍受限 |
|
更有效的搜索 |
当前采样 N 个候选,更高效的搜索策略可提升动作选择质量 |
|
持续学习 |
从在线交互中持续改进世界模型和策略 |
十二、参考资源
- 📄 论文:https://finch-static.agibot.com/VAM/blog/tau_0_wm.pdf
- 💻 代码:https://github.com/sii-research/tau-0-wm
- 🤗 模型:https://huggingface.co/sii-research/tau-0-wm
- 🌐 项目页:τ0-WM: A Unified Video-Action World Model for Robotic Manipulation - Research - AGIBOT Finch
- 📚 Wan2.2:https://github.com/Wan-Video/Wan2.2
- 📚 UMI:https://github.com/real-stanford/universal_manipulation_interface
- 📚 AgiBot World:AGIBOT WORLD
- 📚 Open X-Embodiment:https://github.com/google-deepmind/open_x_embodiment
- 📚 Cosmos:https://github.com/NVIDIA/Cosmos
- 📄 ViVa(视频生成价值模型):[2604.08168] ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
- 📄 π0.5:[2504.16054] $π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)